на блоки по 8KB, их называют страницами чтобы удобно считывать и кэшировать в RAM части данных на одной страничке может быть N строк таблицы данные хранятся неупорядоченно — в порядке вставки а после обновления и удаления строк и в ещё более хаотичном порядке новая строка может сохраниться там, где была старая версия строки (PostgreSQL не изменяет строки, а работает с MVCC) 3
на 10 млн строк, нужны 3 строки, 9 999 997 строк каждый раз считываются с диска зря а чтение с диска медленное запросы медленные всё тупит все грустят деняк нет 6
CLUSTER по индексу это физически перестраивает таблицу в соответствии с порядком в индексе сие помогает быстрее выполнять выборки с between, например но уже нужен индекс:) CLUSTER разово перестраивает таблицу, порядок рушится со временем 9
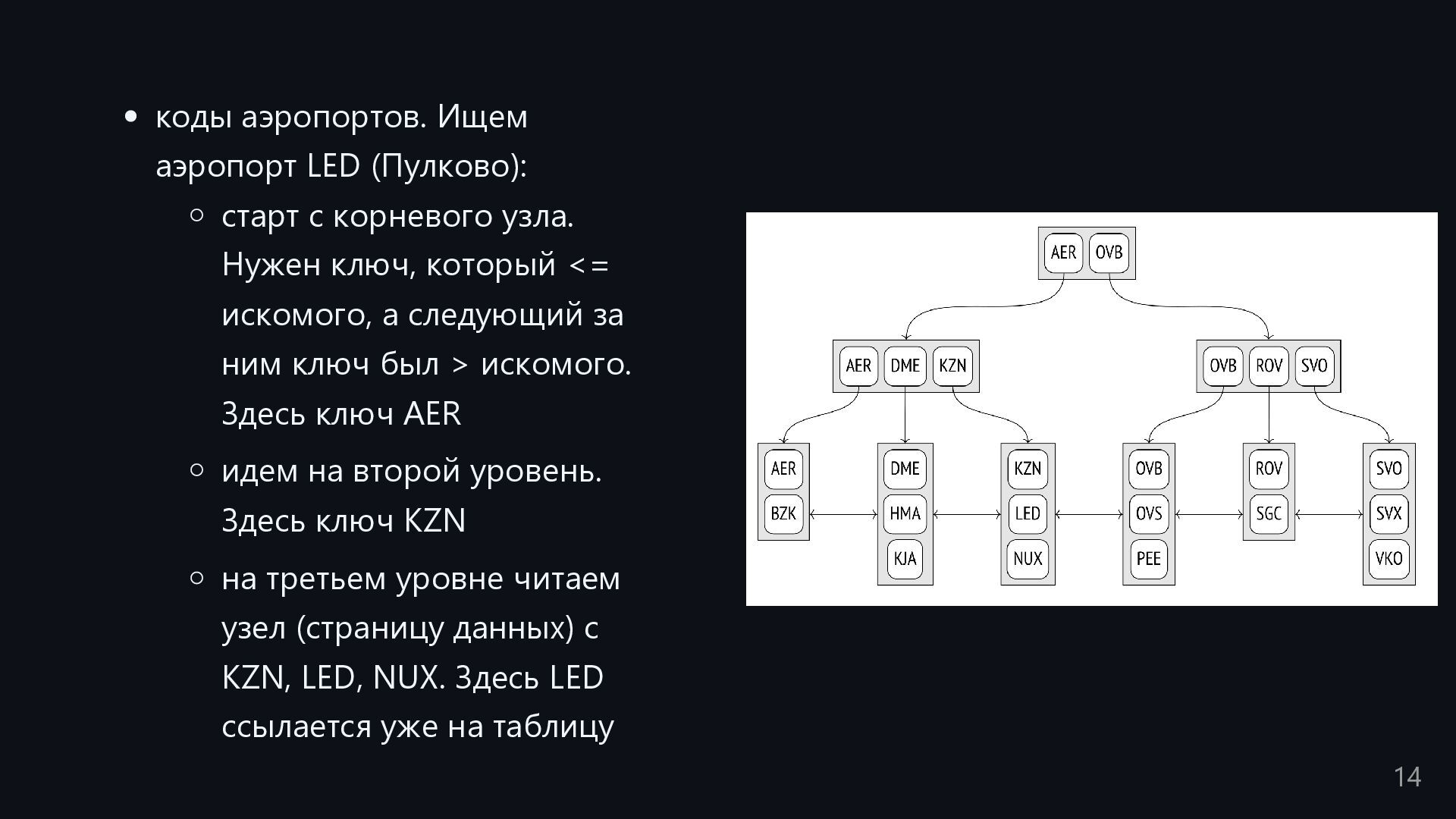
Нужен ключ, который <= искомого, а следующий за ним ключ был > искомого. Здесь ключ AER идем на второй уровень. Здесь ключ KZN на третьем уровне читаем узел (страницу данных) c KZN, LED, NUX. Здесь LED ссылается уже на таблицу 14
для всех листовых узлов все пути от корня до листьев имеют одинаковую длину одинаковое время поиска для всех записей 4-5 уровней достаточно для хранения миллиарда записей каждый узел — страница, 8 килобайт в наборе данных на миллиард записей можно найти одну запись, прочитав с диска всего 4 страницы по 8 килобайт — легко и быстро 15
одну запись без индекса? Это значит, что надо прочитать миллиард строк. Сколько это страниц? например, в таблице хранятся два поля — bigint, 8 байт, и текст на 150 байт, плюс метаданные, итого 185 байт для каждой строки на одной странице помещается 44 строки для хранения миллиарда строк нам нужно 22.7 млн страниц на диске это ровно то число страниц, которое потенциально надо прочитать с диска, чтобы найти в миллиарде строк одну строку без индекса против 4-5 страниц для индекса 16
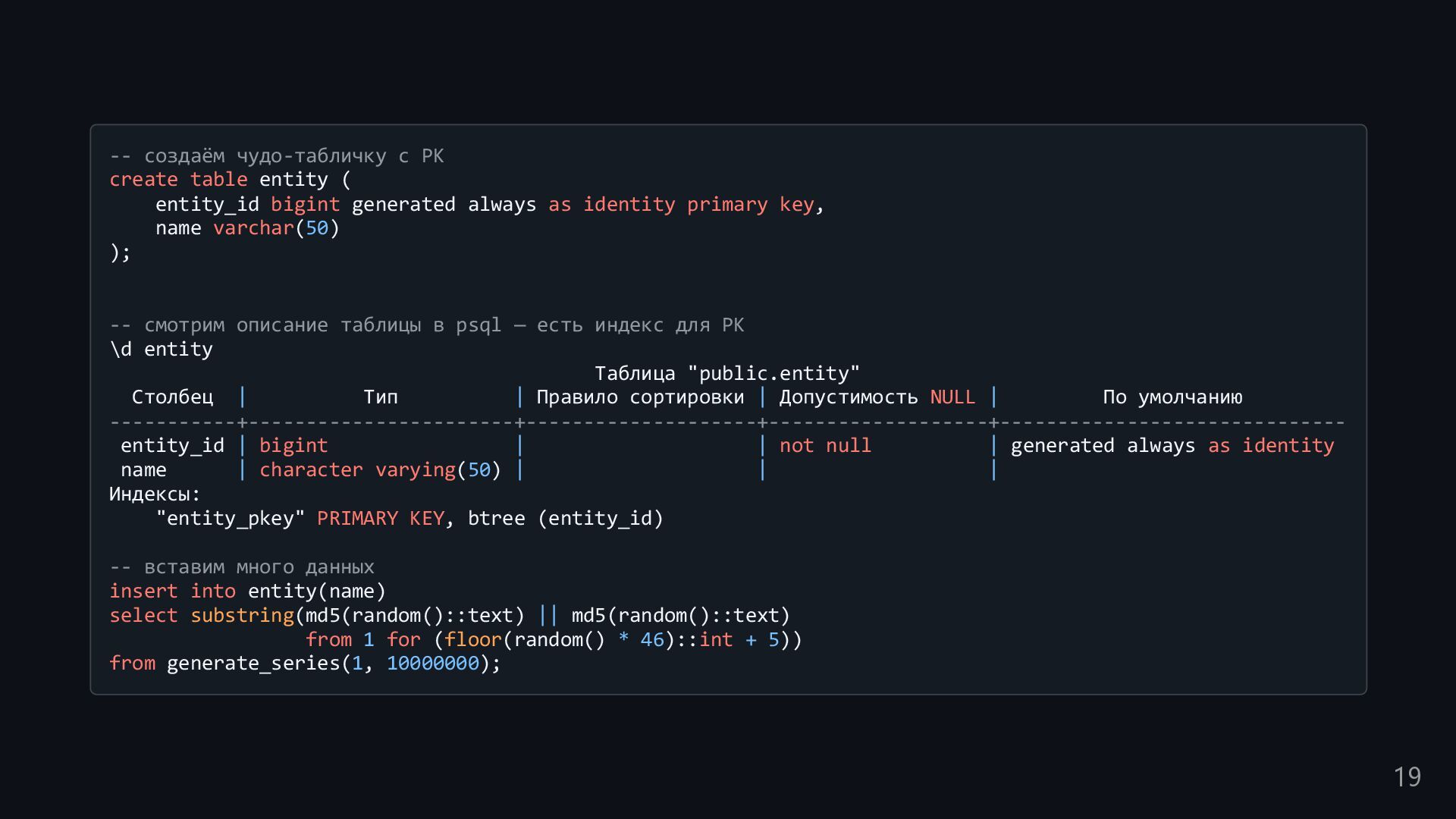
bigint generated always as identity primary key, name varchar(50) ); -- смотрим описание таблицы в psql — есть индекс для PK \d entity Таблица "public.entity" Столбец | Тип | Правило сортировки | Допустимость NULL | По умолчанию -----------+-----------------------+--------------------+-------------------+------------------------------ entity_id | bigint | | not null | generated always as identity name | character varying(50) | | | Индексы: "entity_pkey" PRIMARY KEY, btree (entity_id) -- вставим много данных insert into entity(name) select substring(md5(random()::text) || md5(random()::text) from 1 for (floor(random() * 46)::int + 5)) from generate_series(1, 10000000); 19
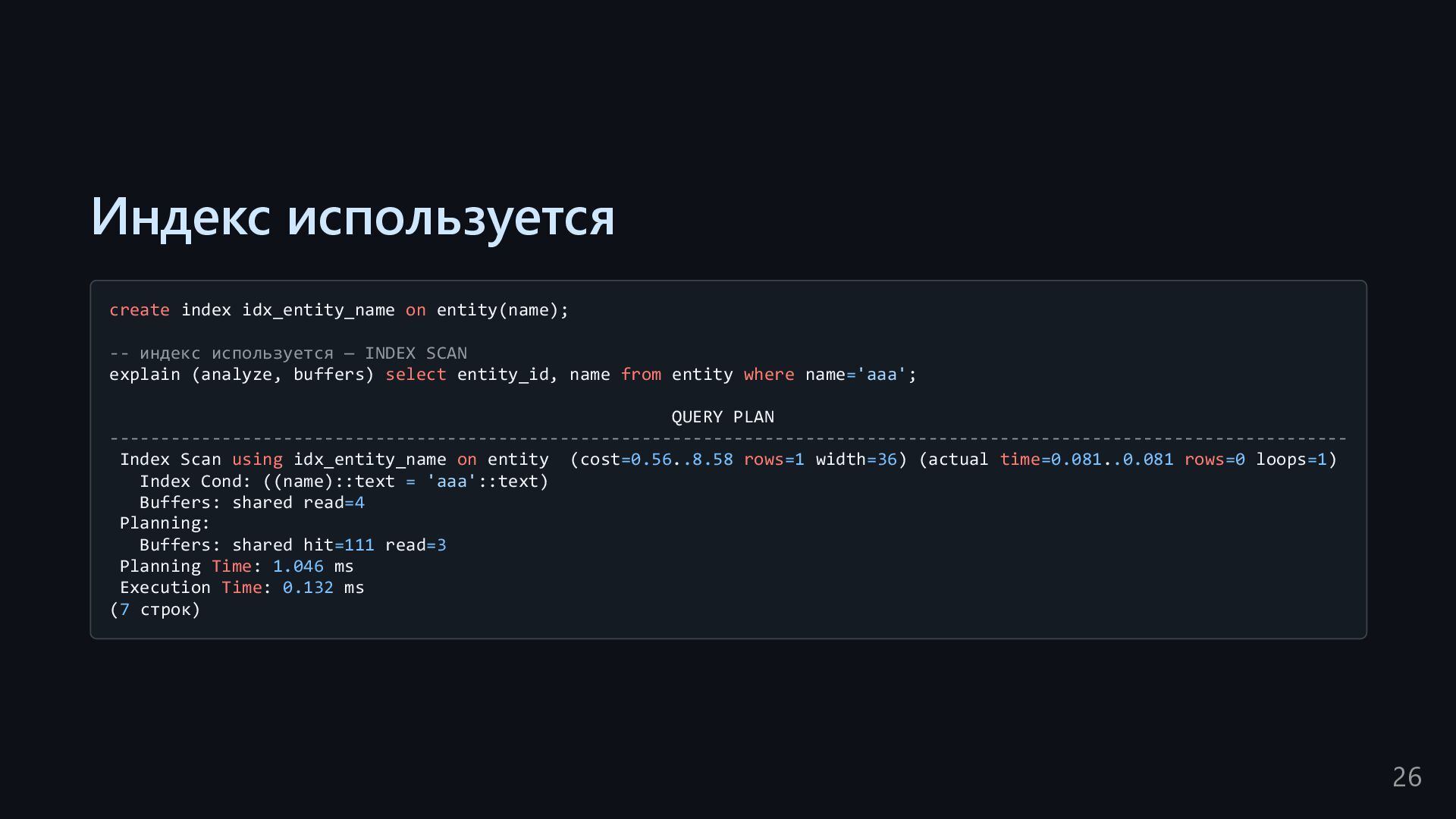
— INDEX SCAN explain (analyze, buffers) select entity_id, name from entity where name='aaa'; QUERY PLAN ------------------------------------------------------------------------------------------------------------------------- Index Scan using idx_entity_name on entity (cost=0.56..8.58 rows=1 width=36) (actual time=0.081..0.081 rows=0 loops=1) Index Cond: ((name)::text = 'aaa'::text) Buffers: shared read=4 Planning: Buffers: shared hit=111 read=3 Planning Time: 1.046 ms Execution Time: 0.132 ms (7 строк) 26
( client_id bigint generated always as identity primary key, first_name varchar(50) not null, last_name varchar(50) not null, sex char(1) not null check (sex in ('m', 'f')) ); -- вставляем половину мужчин, половину женщин -- создаём индекс и собираем статистику create index client_sex_idx on client(sex); vacuum analyze client; explain analyze select * from client where sex='f'; -- seq scan explain analyze select * from client where sex='m'; -- seq scan 27
то это запрос с высокой селективностью и такой запрос будет использовать индекс если надо достать всю маленькую табличку или много данных большой таблицы — запрос с низкой селективностью и такой запрос не будет использовать индекс а зачем? Он не даст ускорения проще сразу пойти лопатить SEQ SCAN 28
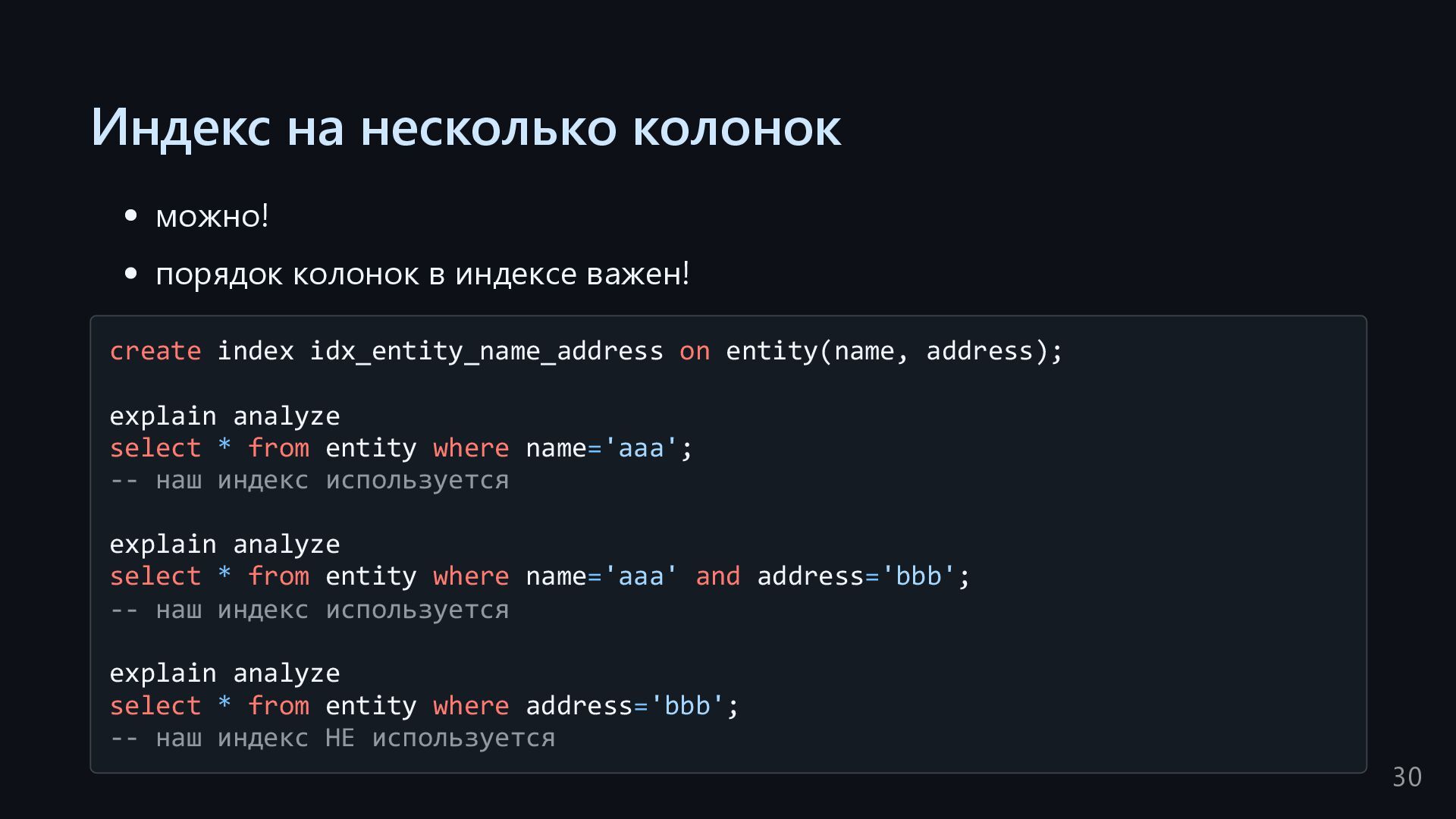
create index idx_entity_name_address on entity(name, address); explain analyze select * from entity where name='aaa'; -- наш индекс используется explain analyze select * from entity where name='aaa' and address='bbb'; -- наш индекс используется explain analyze select * from entity where address='bbb'; -- наш индекс НЕ используется 30
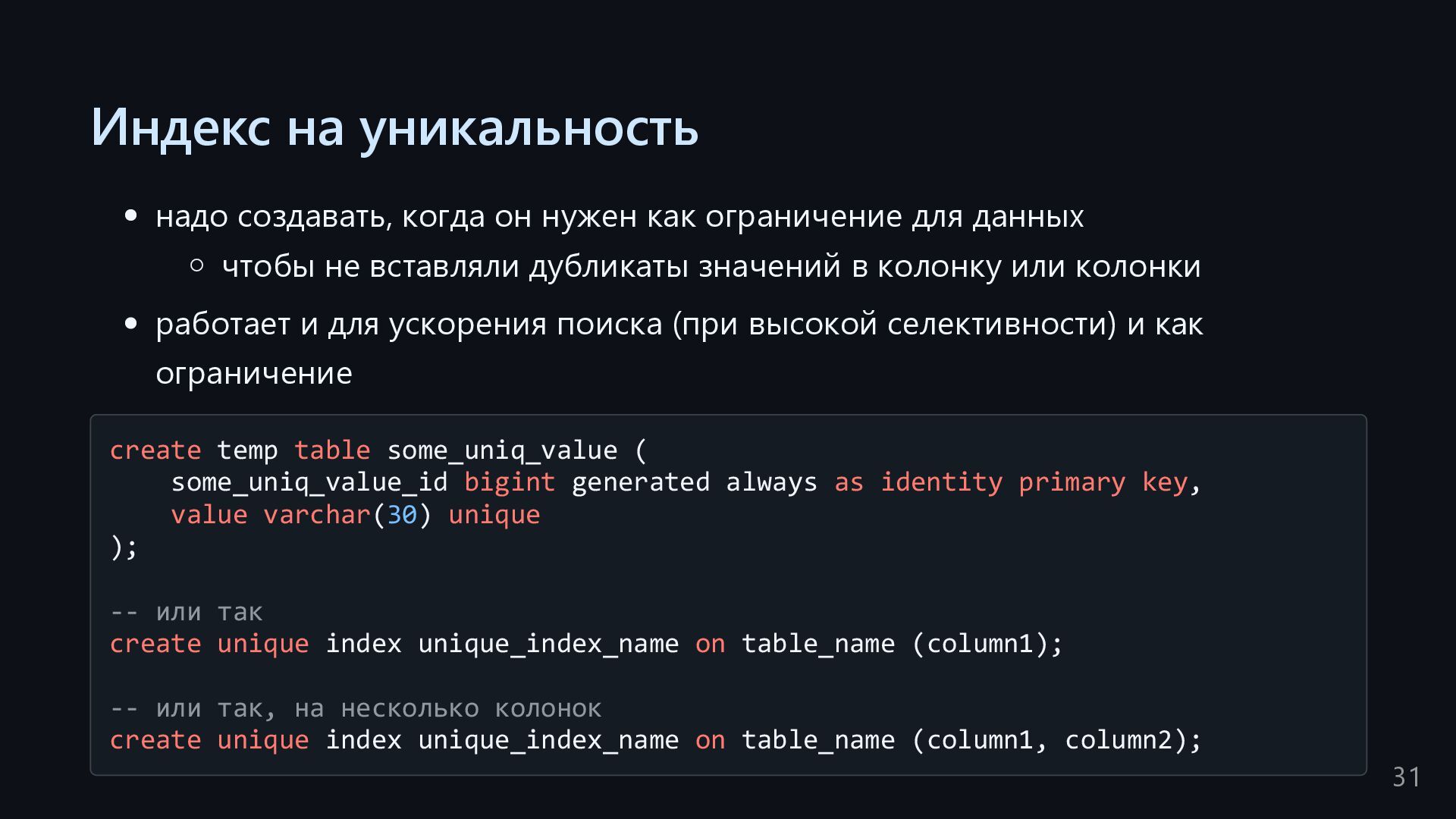
для данных чтобы не вставляли дубликаты значений в колонку или колонки работает и для ускорения поиска (при высокой селективности) и как ограничение create temp table some_uniq_value ( some_uniq_value_id bigint generated always as identity primary key, value varchar(30) unique ); -- или так create unique index unique_index_name on table_name (column1); -- или так, на несколько колонок create unique index unique_index_name on table_name (column1, column2); 31
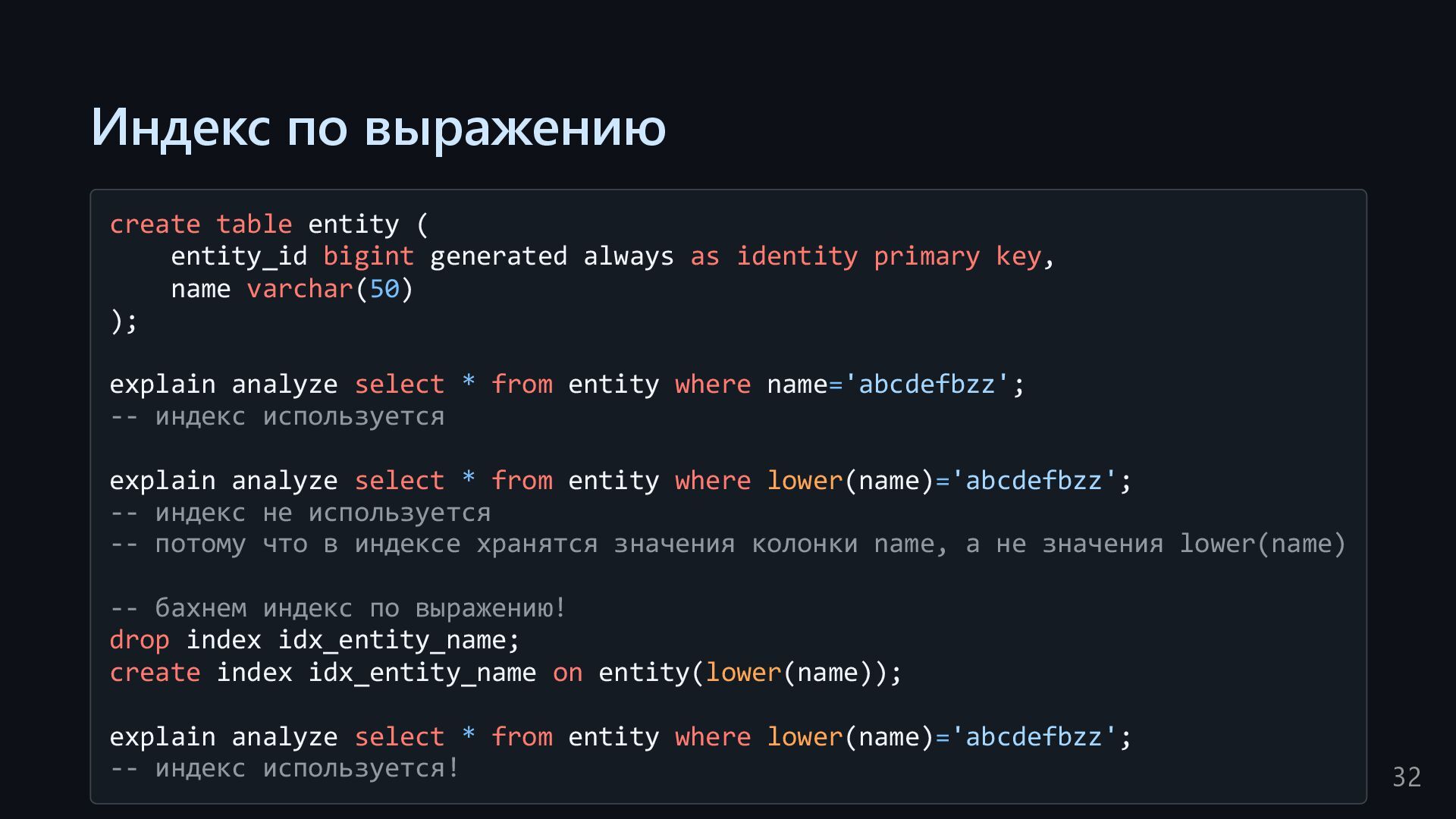
always as identity primary key, name varchar(50) ); explain analyze select * from entity where name='abcdefbzz'; -- индекс используется explain analyze select * from entity where lower(name)='abcdefbzz'; -- индекс не используется -- потому что в индексе хранятся значения колонки name, а не значения lower(name) -- бахнем индекс по выражению! drop index idx_entity_name; create index idx_entity_name on entity(lower(name)); explain analyze select * from entity where lower(name)='abcdefbzz'; -- индекс используется! 32
небольшой и очень эффективный create table client ( client_id bigint generated always as identity primary key, name varchar(50) not null, phone varchar(12) ); -- телефоны есть только у небольшой части клиентов create index client_phone_idx on client(phone); -- индекс весит 68 MB explain analyze select * from client where phone='1000057666'; -- этот индекс используется 34
on client(phone) where phone is not null; -- 3 MB вместо 68 MB! explain analyze select * from client where phone='1827879406'; -- по-прежнему используется 35
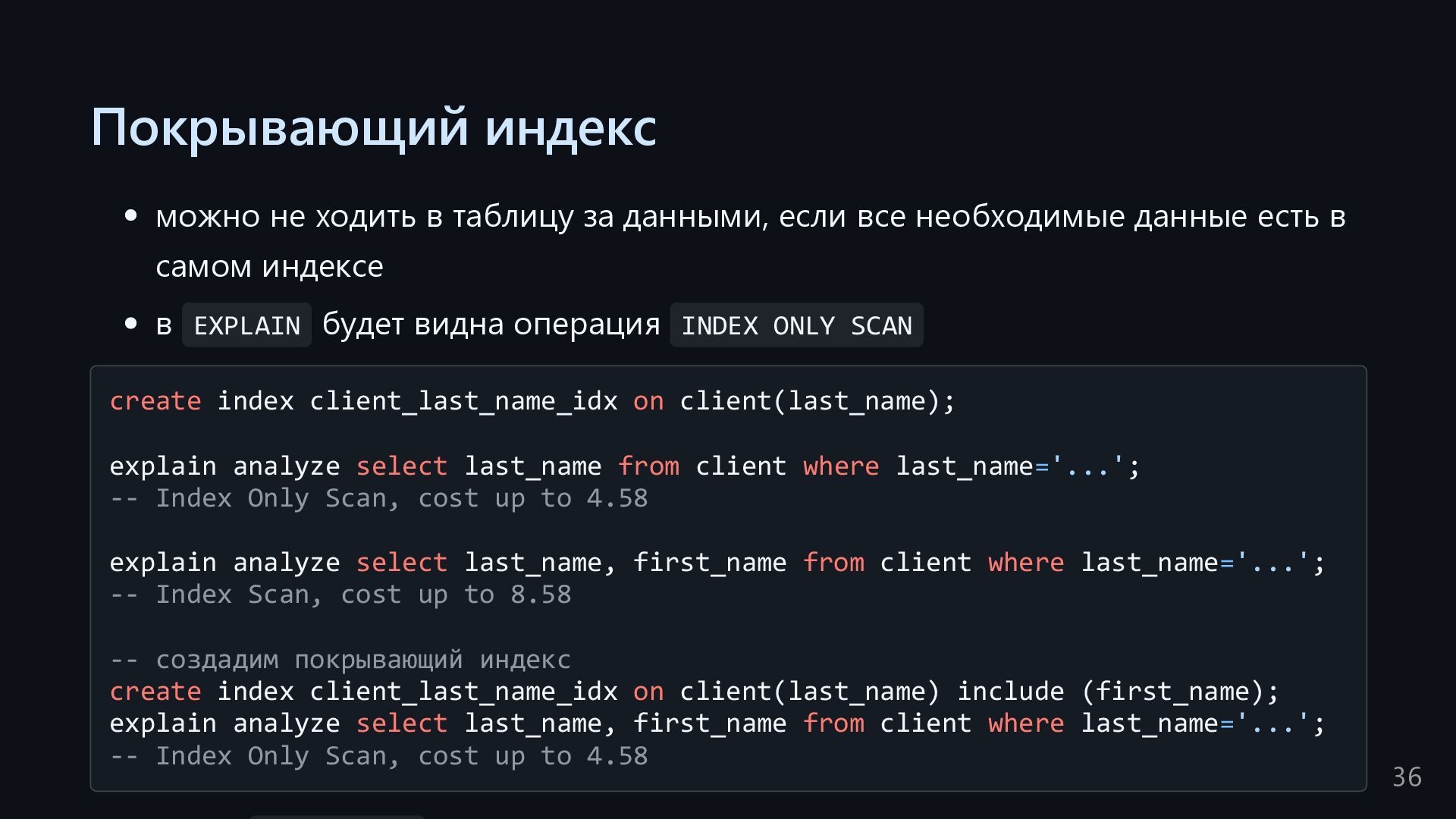
все необходимые данные есть в самом индексе в EXPLAIN будет видна операция INDEX ONLY SCAN create index client_last_name_idx on client(last_name); explain analyze select last_name from client where last_name='...'; -- Index Only Scan, cost up to 4.58 explain analyze select last_name, first_name from client where last_name='...'; -- Index Scan, cost up to 8.58 -- создадим покрывающий индекс create index client_last_name_idx on client(last_name) include (first_name); explain analyze select last_name, first_name from client where last_name='...'; -- Index Only Scan, cost up to 4.58 36
индекса create index concurrently idx_entity_name_address on entity(name, address); но надо проверить, что статус индекса после создания нормальный, не invalid (в \d , например) если invalid — просто пересоздать индекс снова 37
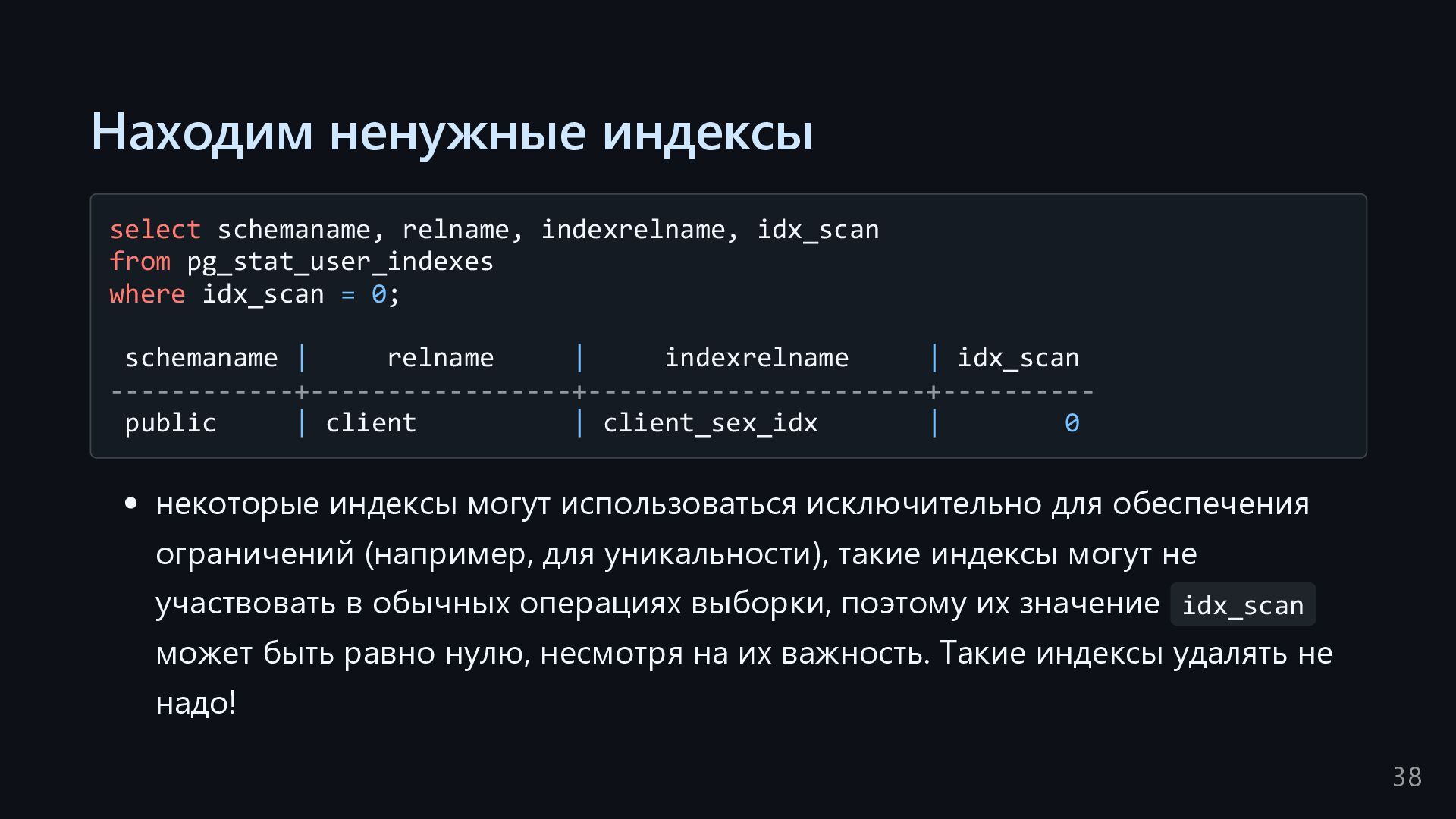
where idx_scan = 0; schemaname | relname | indexrelname | idx_scan ------------+-----------------+----------------------+---------- public | client | client_sex_idx | 0 некоторые индексы могут использоваться исключительно для обеспечения ограничений (например, для уникальности), такие индексы могут не участвовать в обычных операциях выборки, поэтому их значение idx_scan может быть равно нулю, несмотря на их важность. Такие индексы удалять не надо! 38
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}