really need it? • Prepare data (small data < transfer learning + domain adapta9on, cover problem space, balance classes, lower dimensionality). • Find analogy (CNN, RNN/LSTM/GRU, RL). • Create a simple, small & easy baseline model, visualize & debug. • Fine-tune (evalua9on metrics - test data, loss func9on - training). (Smith: Best Prac0ces for Applying Deep Learning to Novel ... , 2017) 42
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
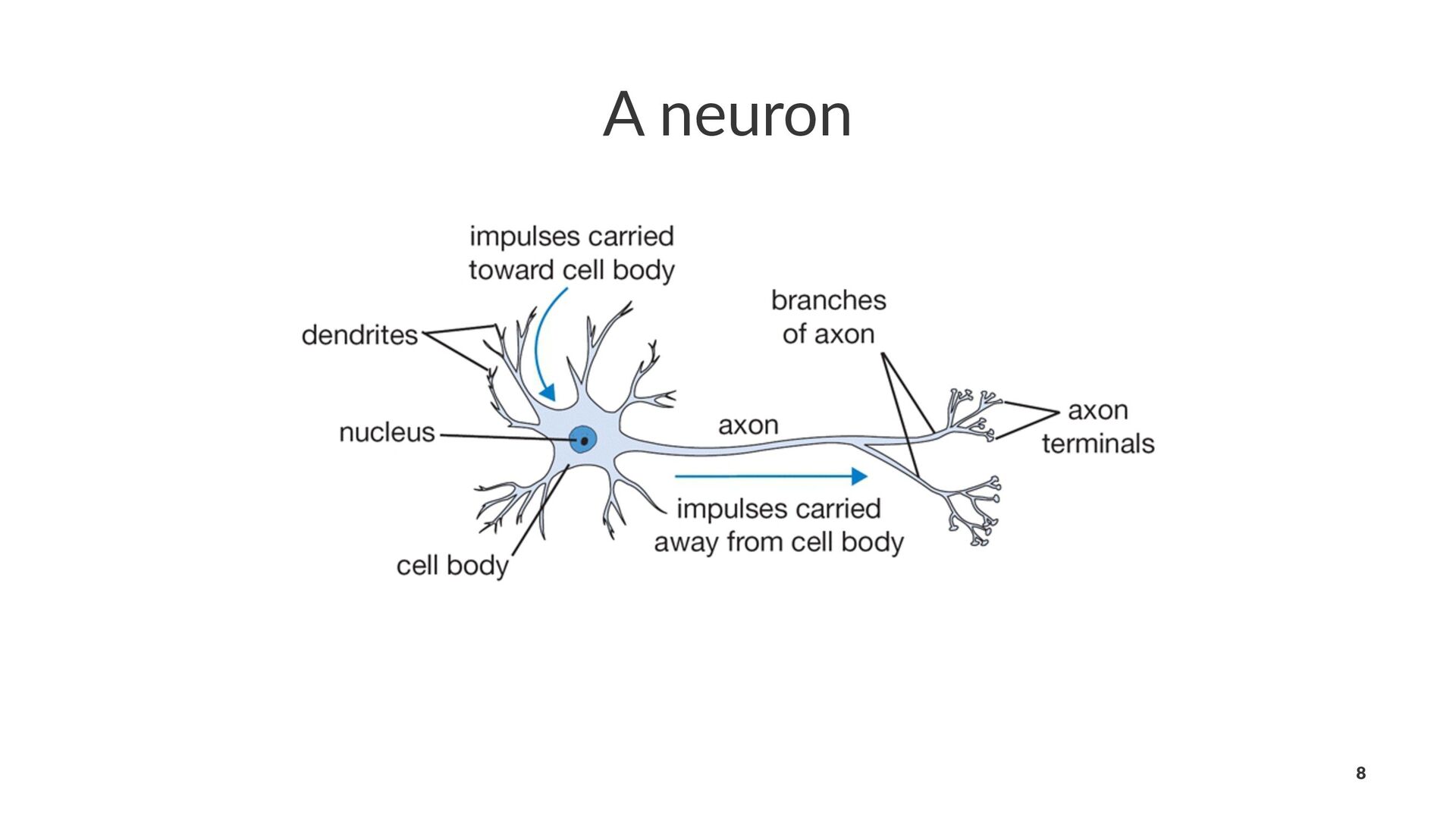{kind=link}
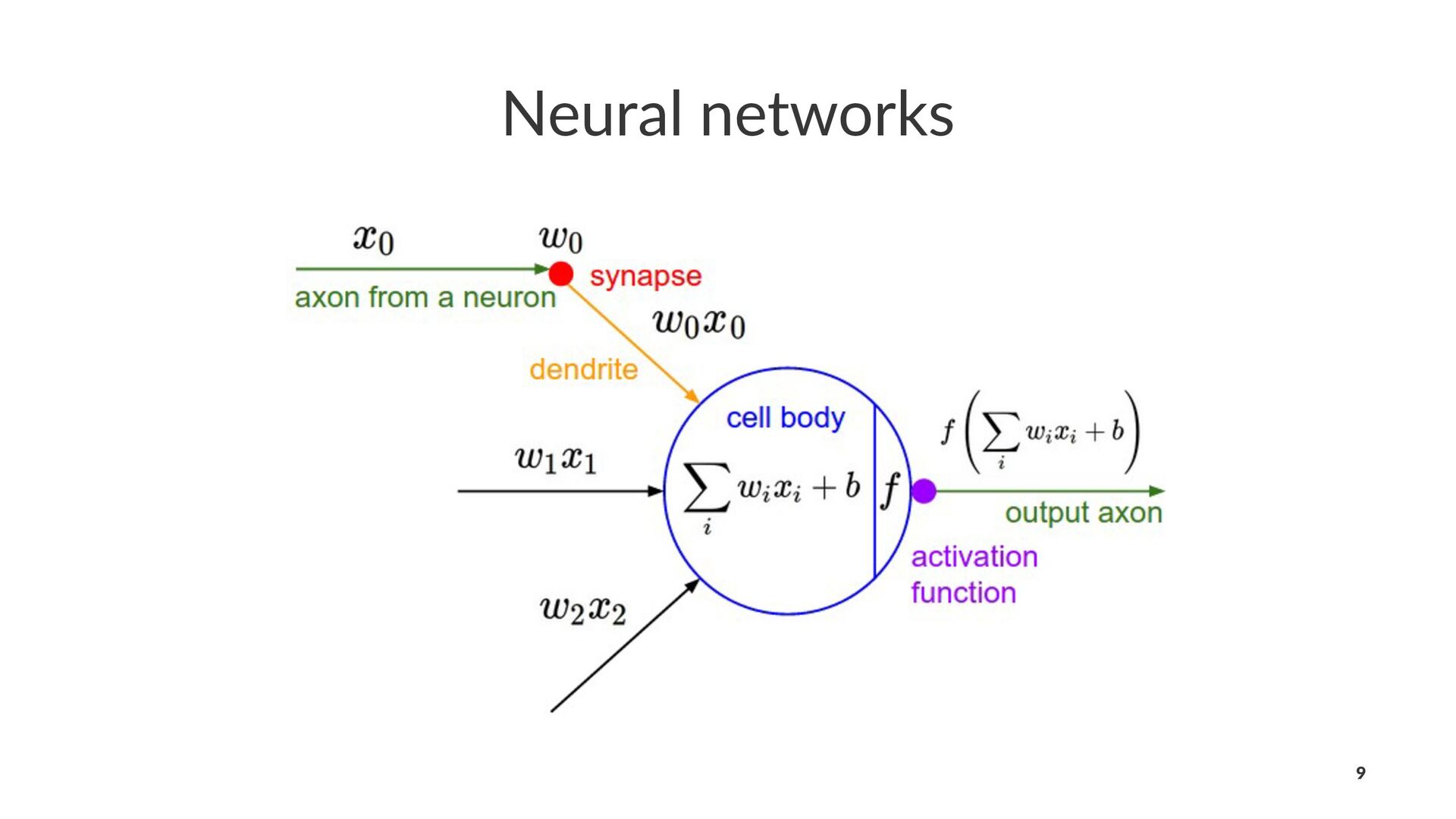{kind=link}
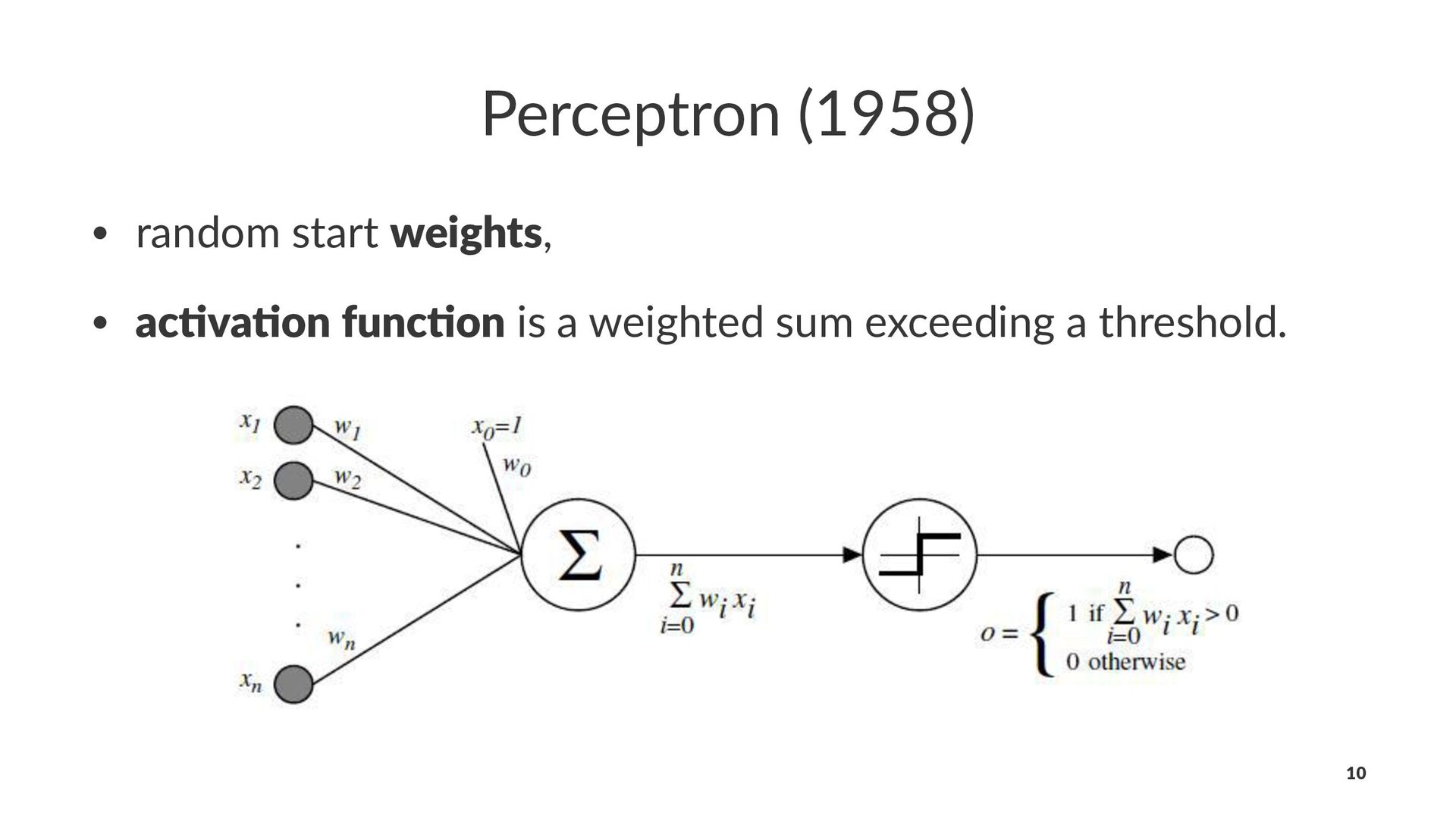{kind=link}
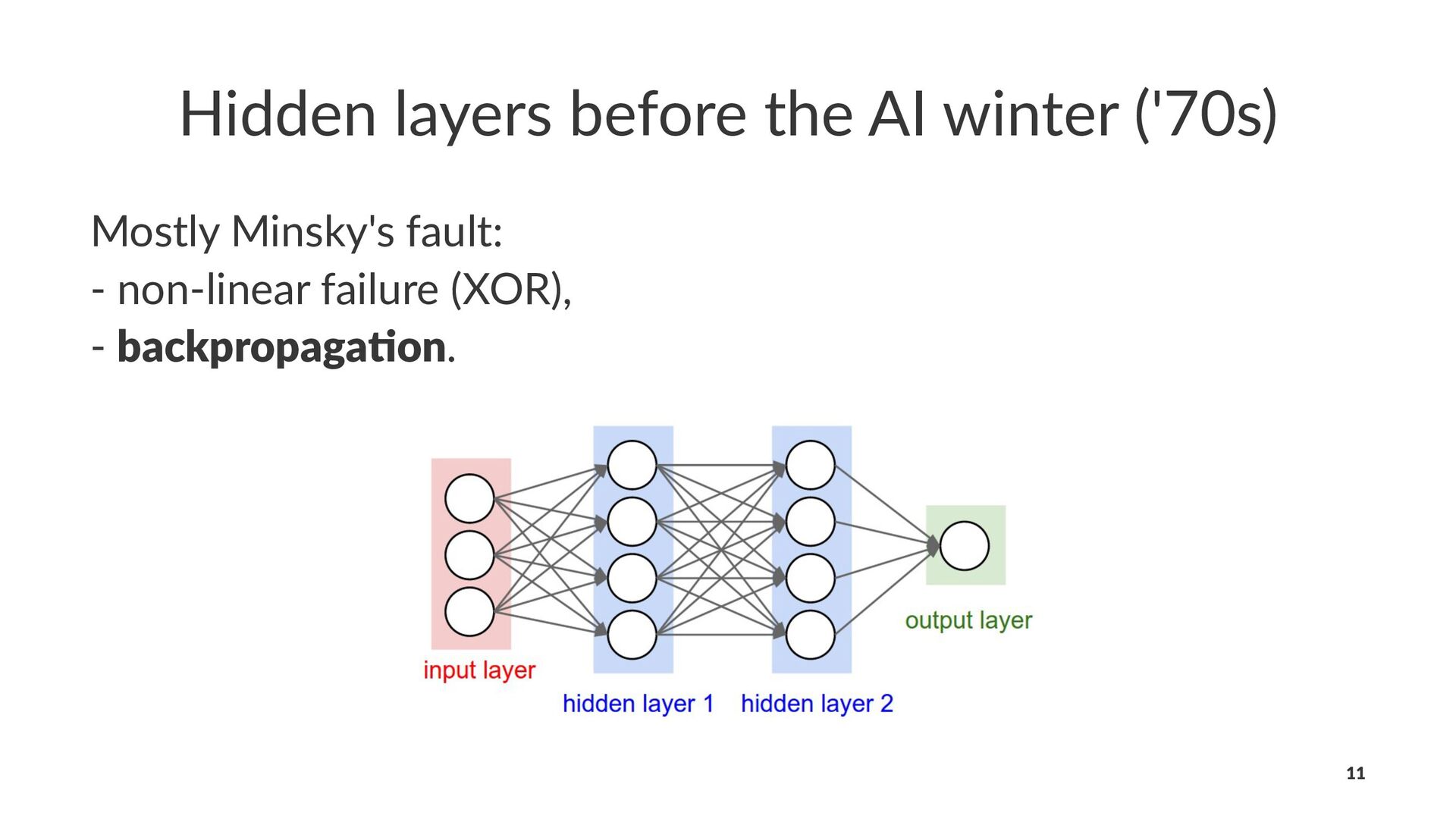{kind=link}
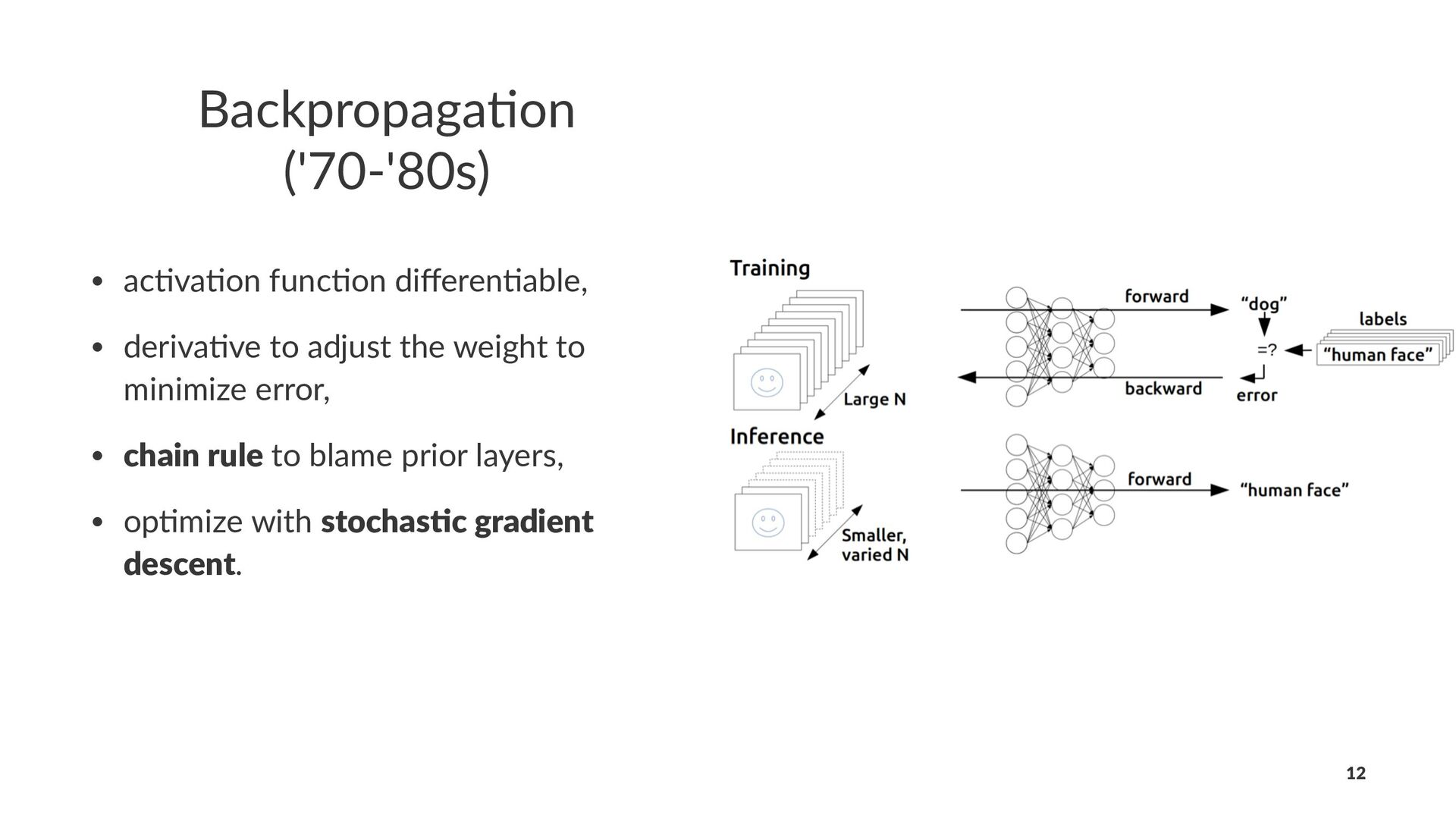{kind=link}
{kind=link}
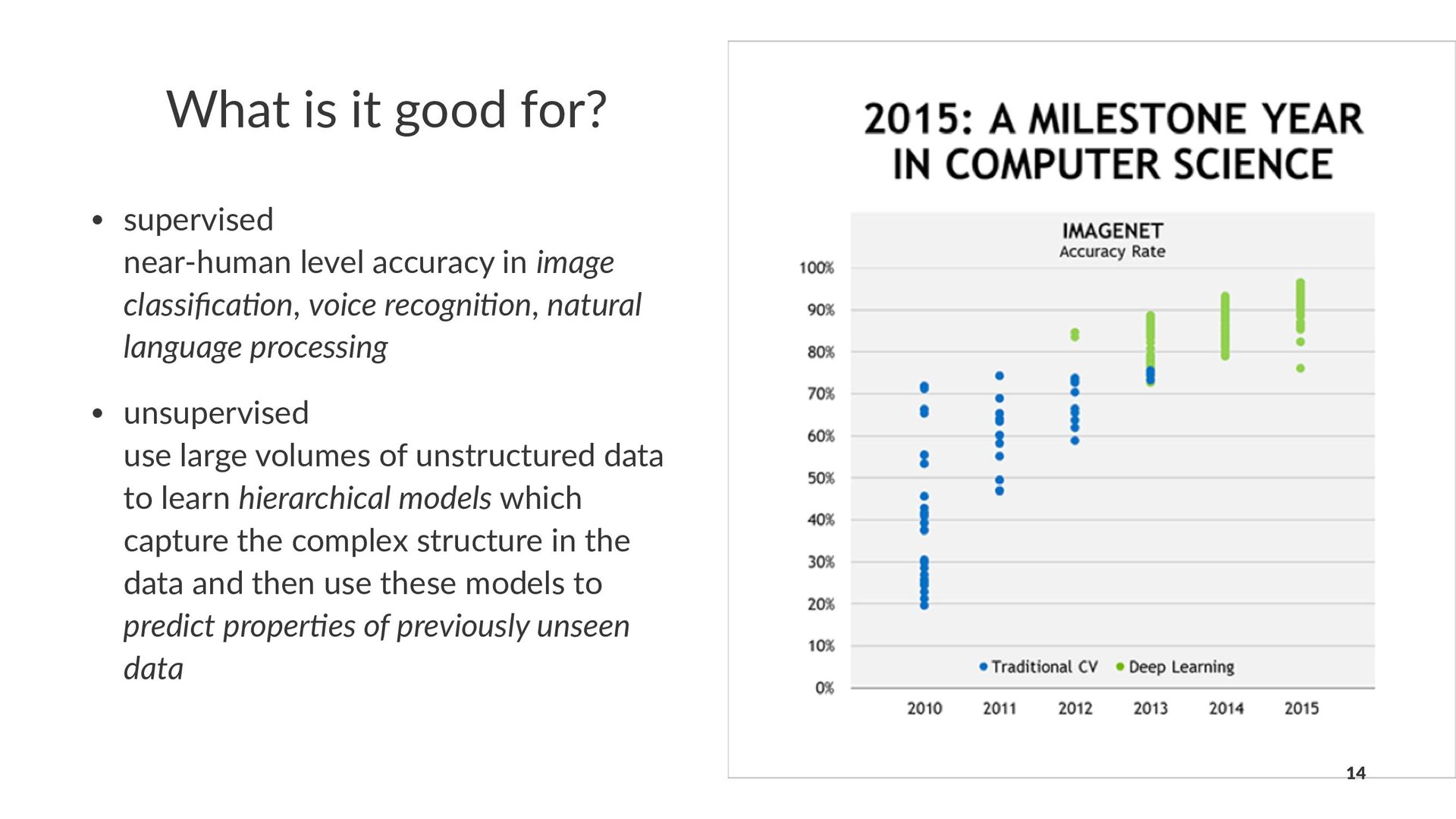{kind=link}
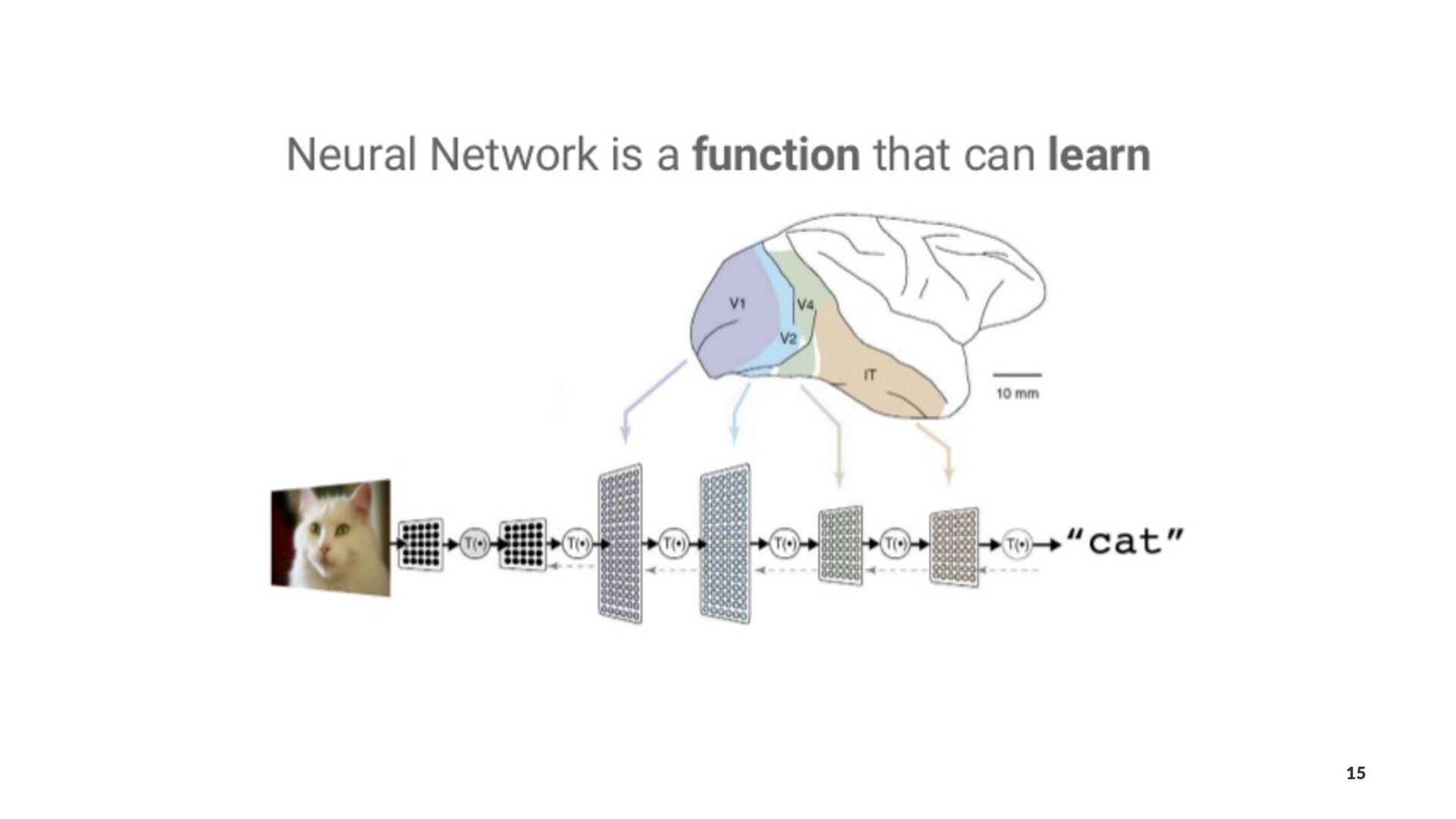{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
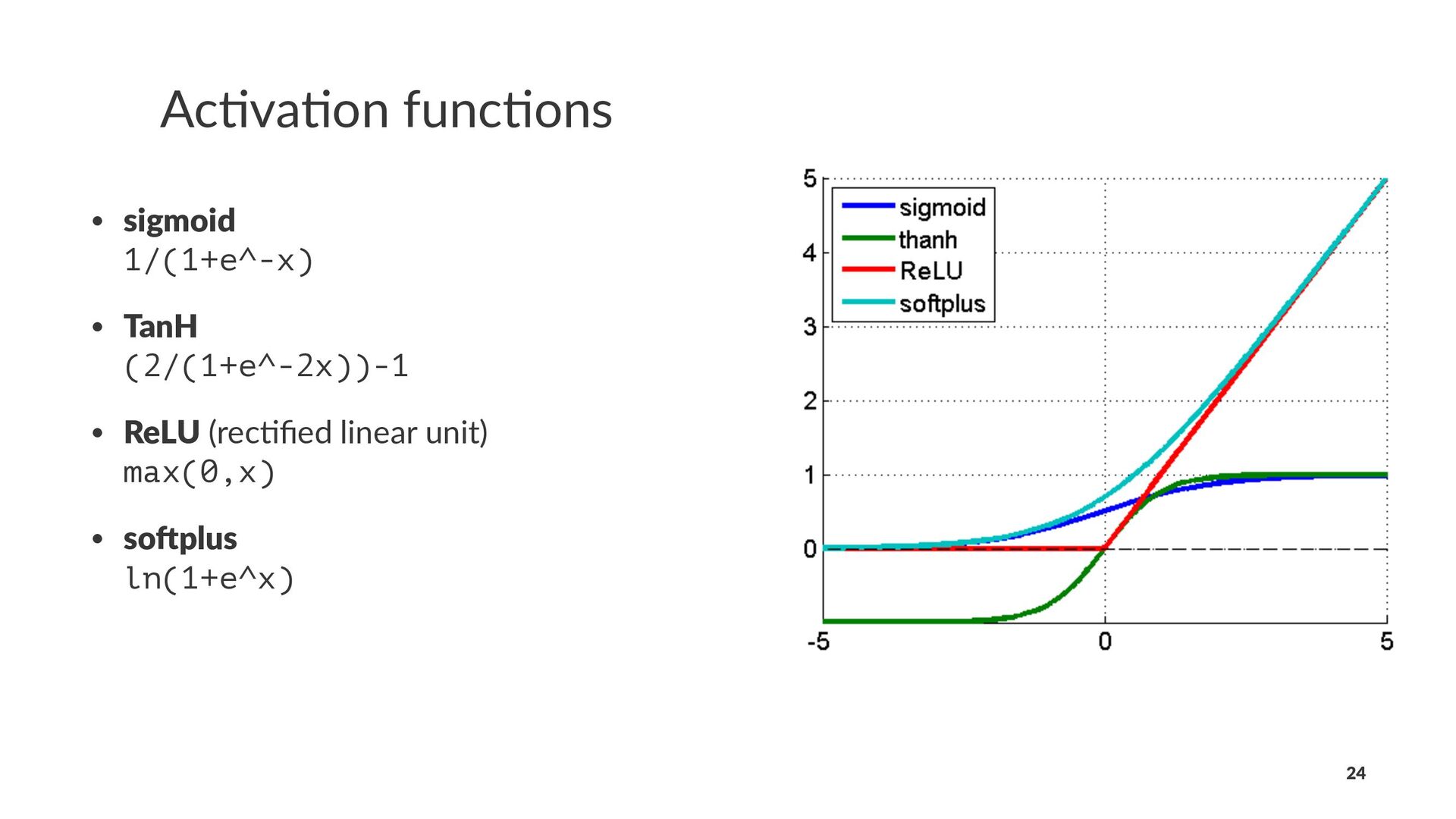{kind=link}
{kind=link}
{kind=link}
{kind=link}
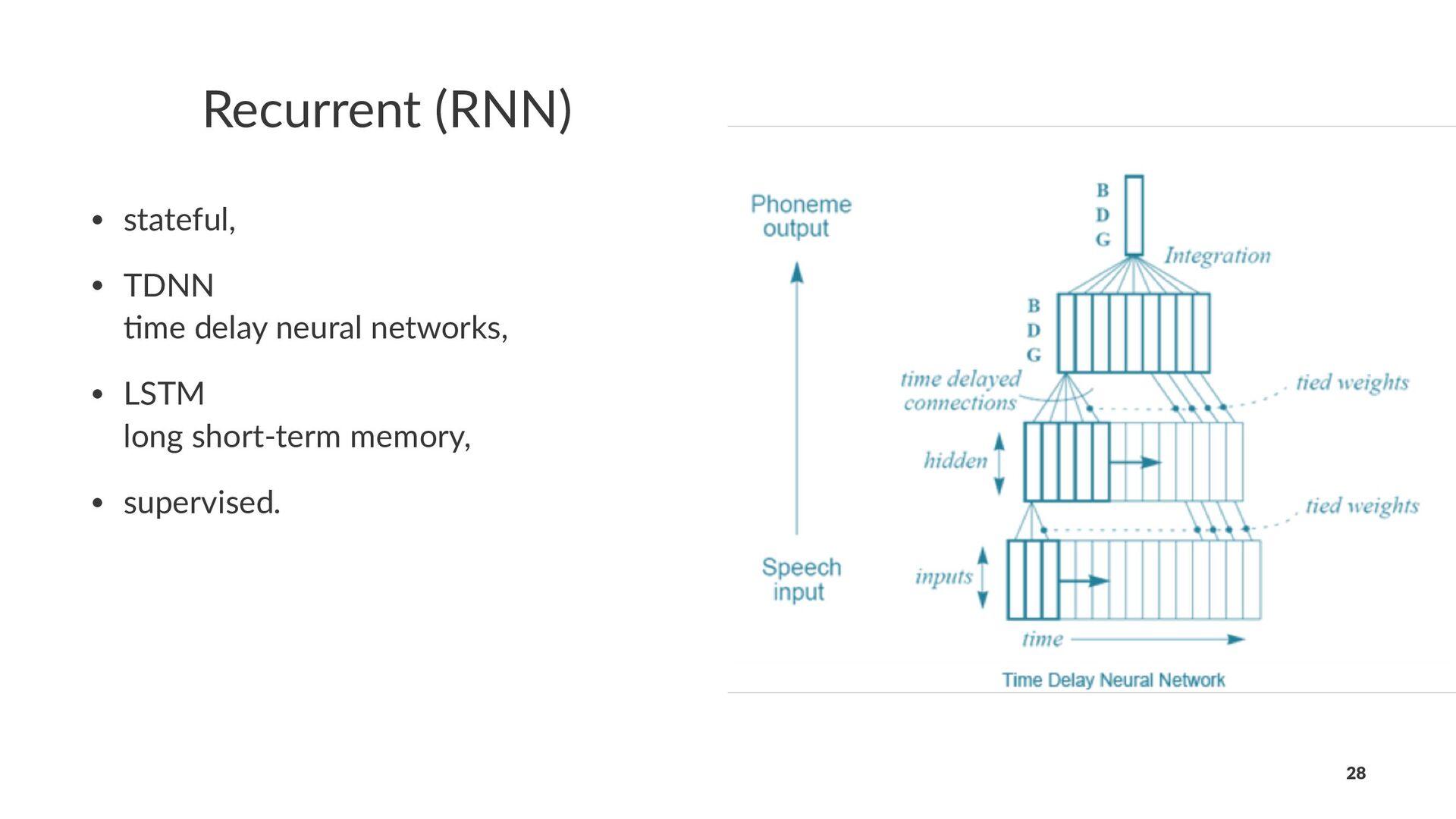{kind=link}
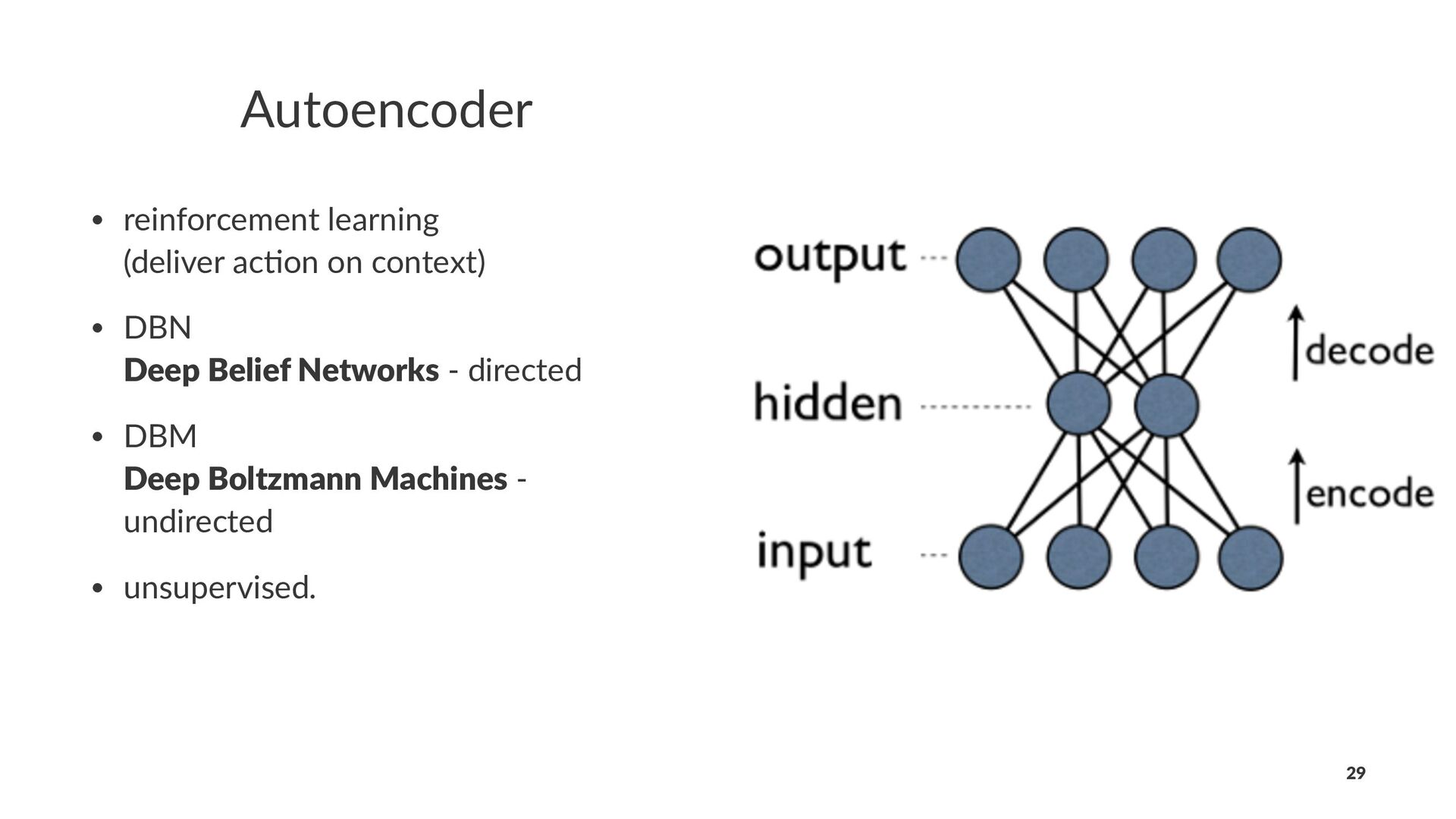{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}