specs.map {|col, type| "#{col} #{type}"}.join(", ") %> ) SORTKEY(id); # Load data into the temporary table from S3 COPY #notes_staging ( <%= columns.join "," %> ) FROM '<%= s3file %>' WITH CREDENTIALS <%= aws_creds %> GZIP TRUNCATECOLUMNS DELIMITER '\001' ESCAPE REMOVEQUOTES; # Updating the changed values UPDATE notes SET <%= updates.join "," %> FROM #notes_staging u WHERE ( u.deleted_at IS NOT NULL OR u.updated_at > notes.updated_at ) AND notes.id = u.id; # Inserting the new rows INSERT INTO notes ( <%= columns.join "," %> ) ( SELECT <%= columns.join "," %> FROM #notes_staging u WHERE u.id NOT IN (SELECT id FROM notes) );
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
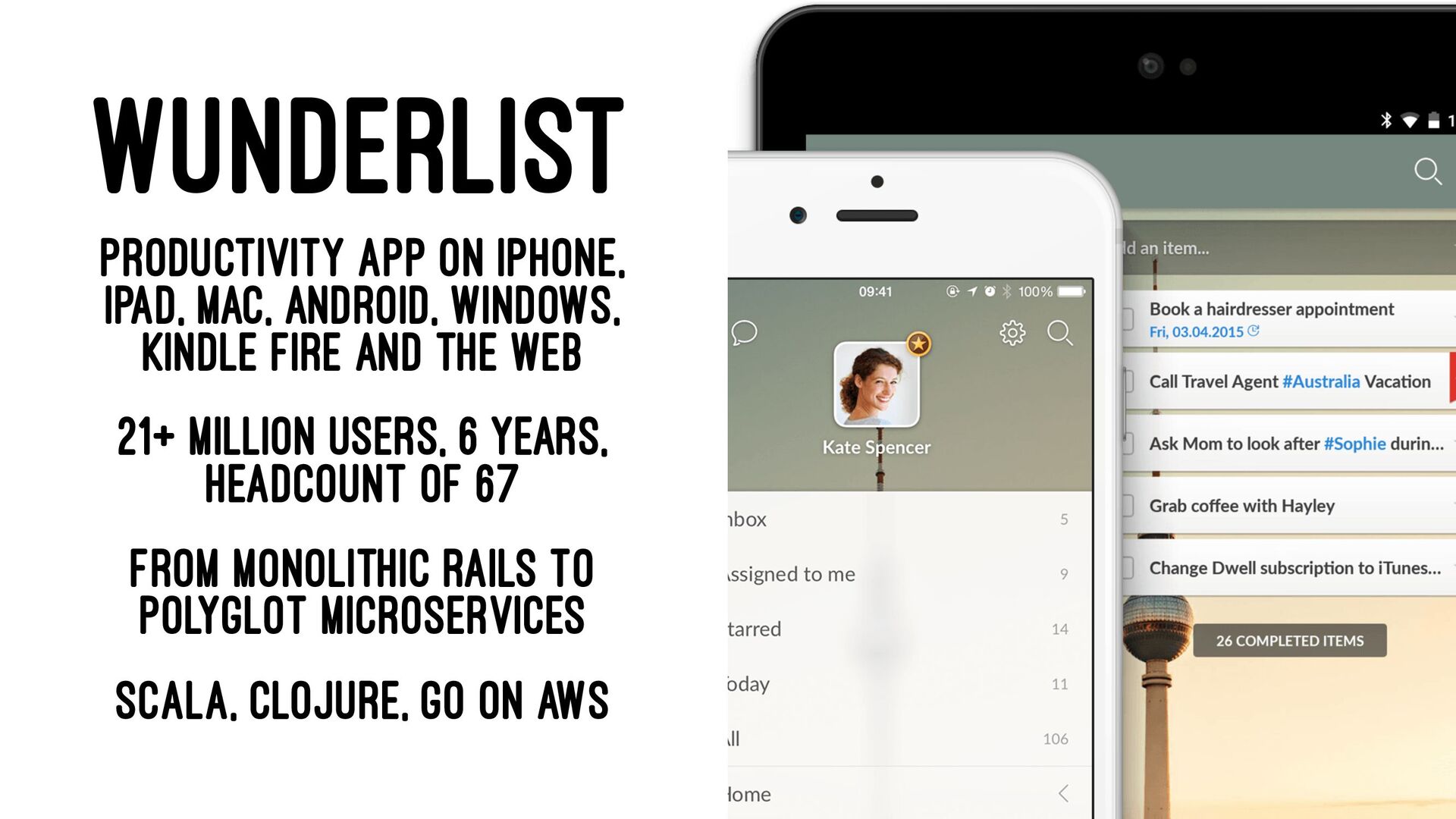{kind=link}
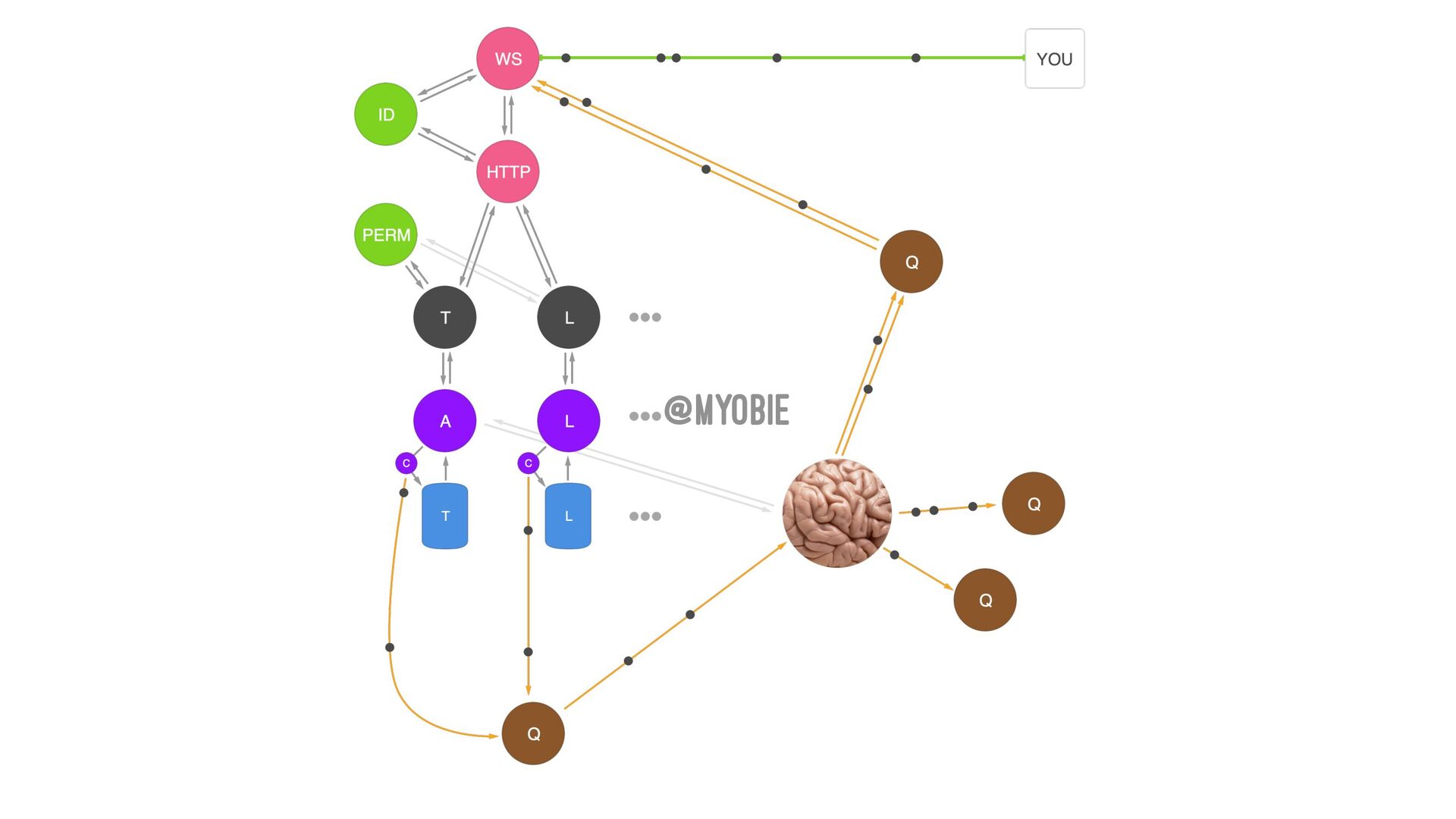{kind=link}
{kind=link}
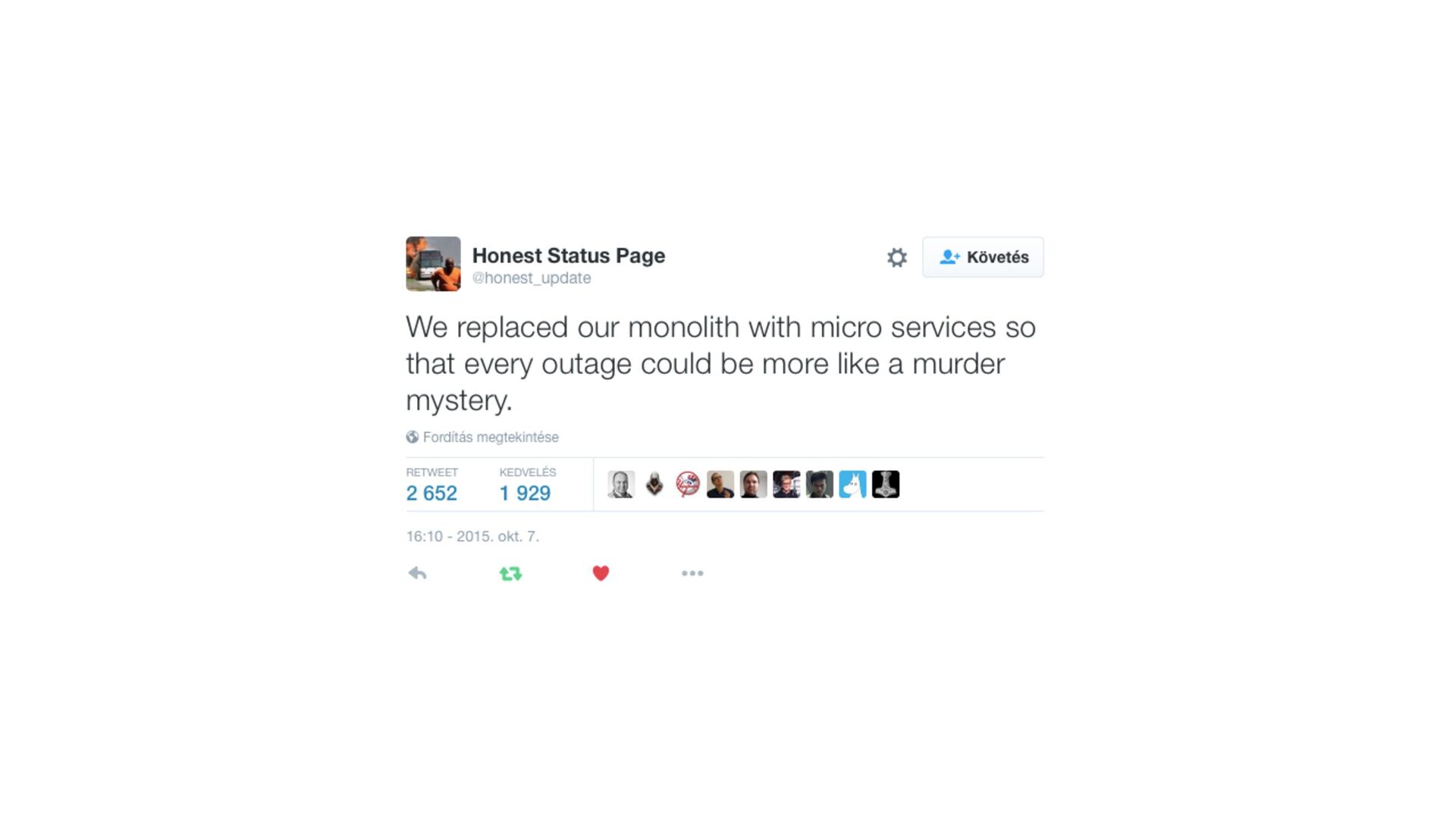{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
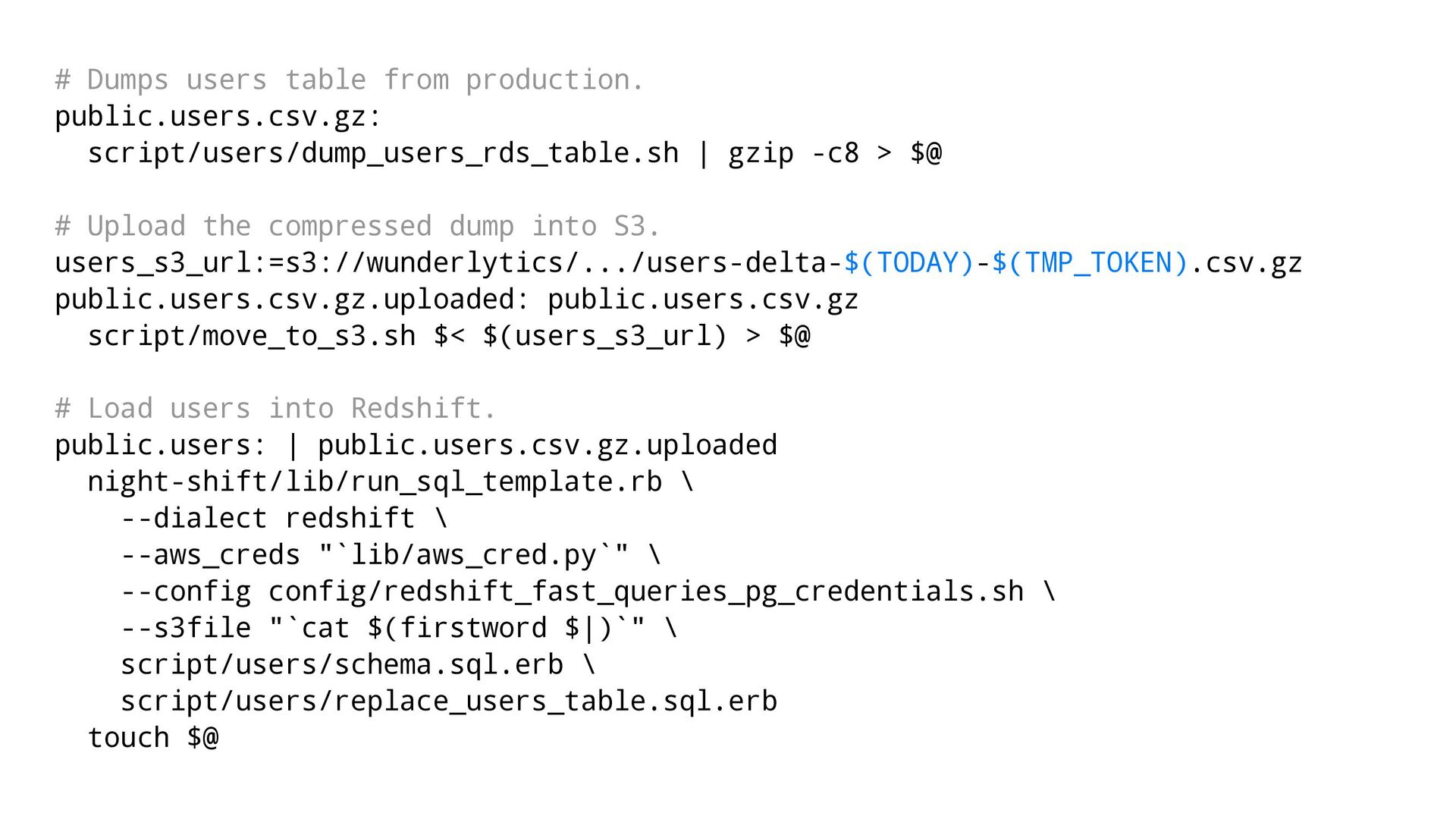{kind=link}
{kind=link}
{kind=link}
{kind=link}
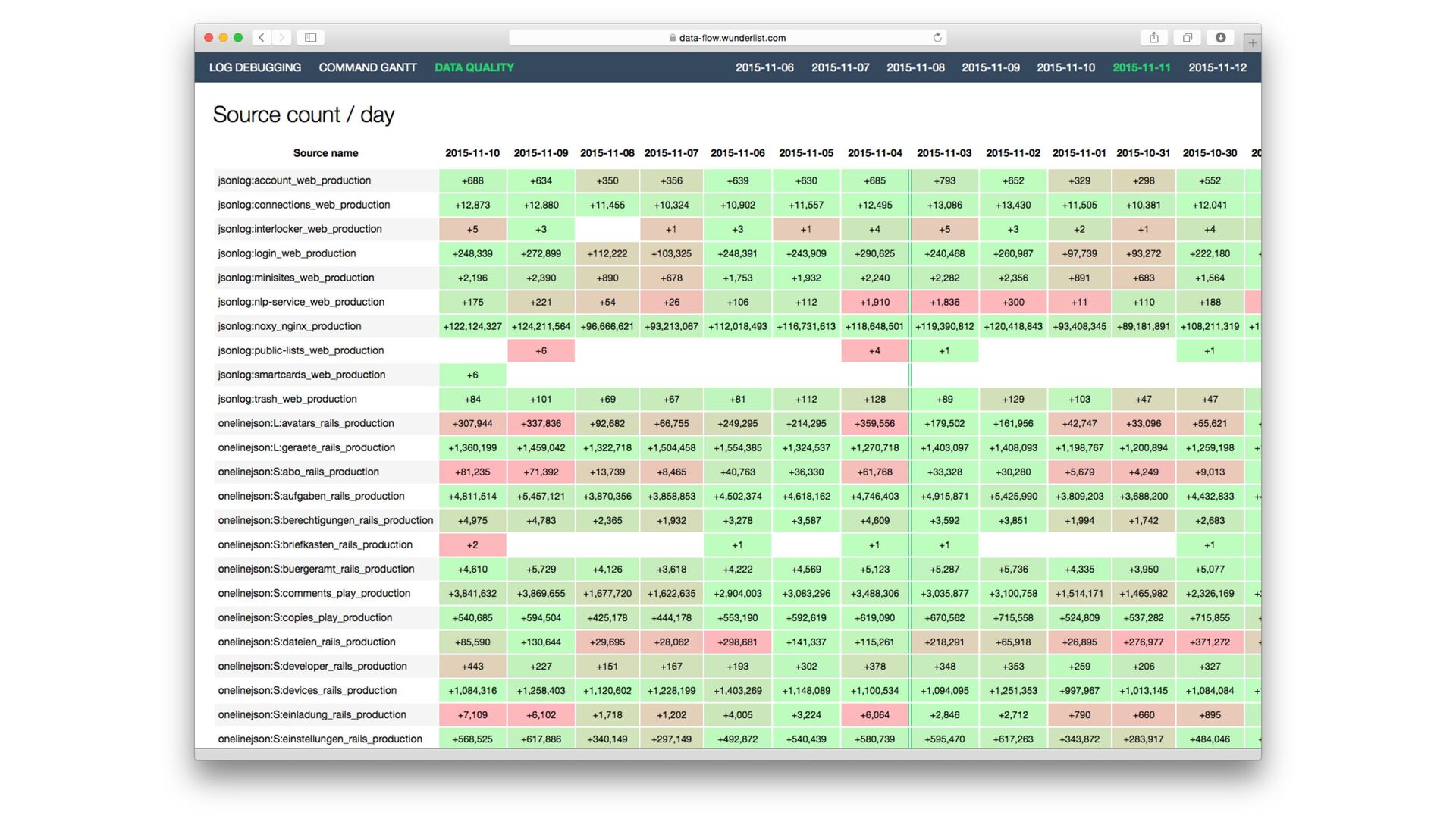{kind=link}
{kind=link}
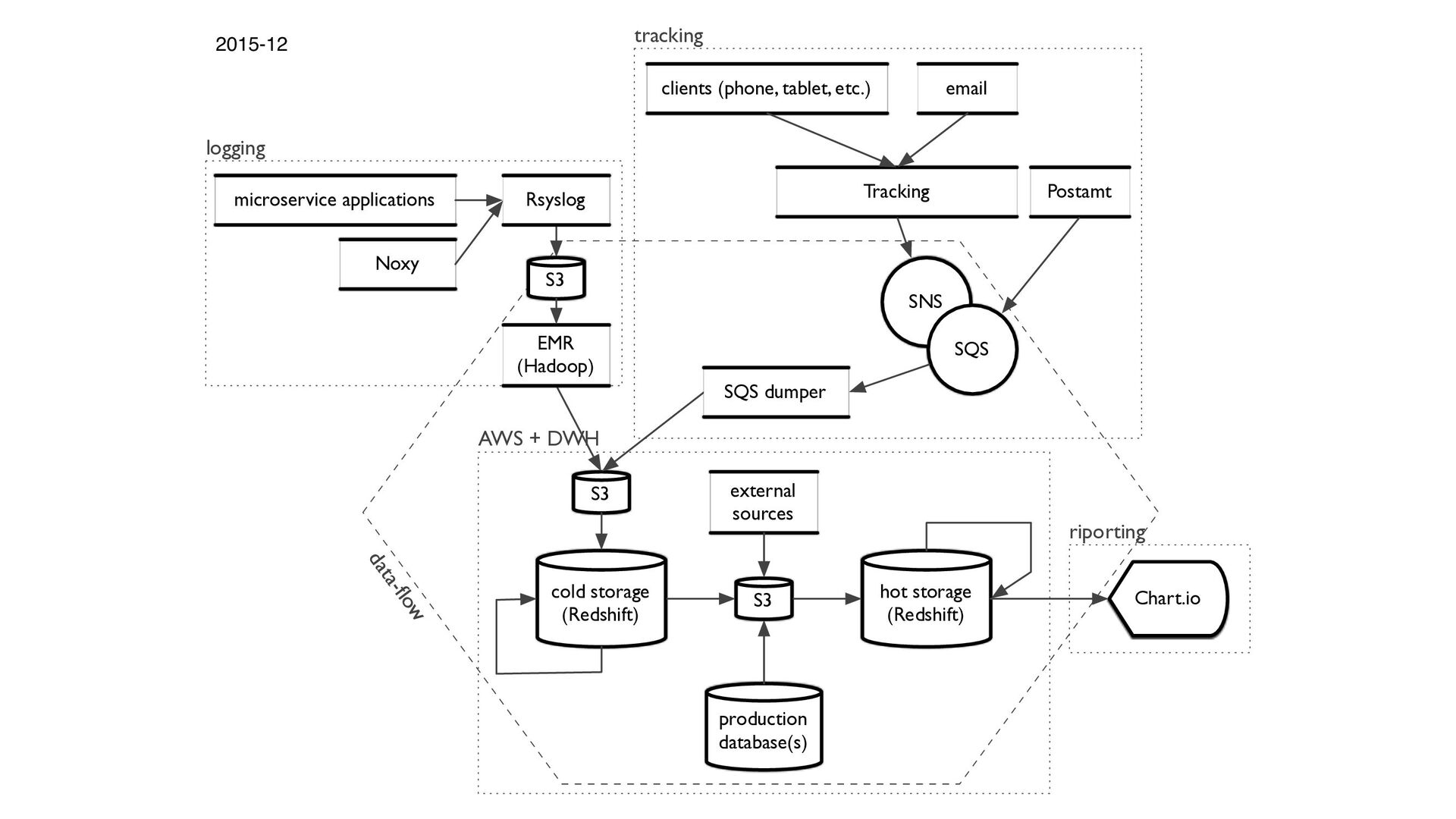{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
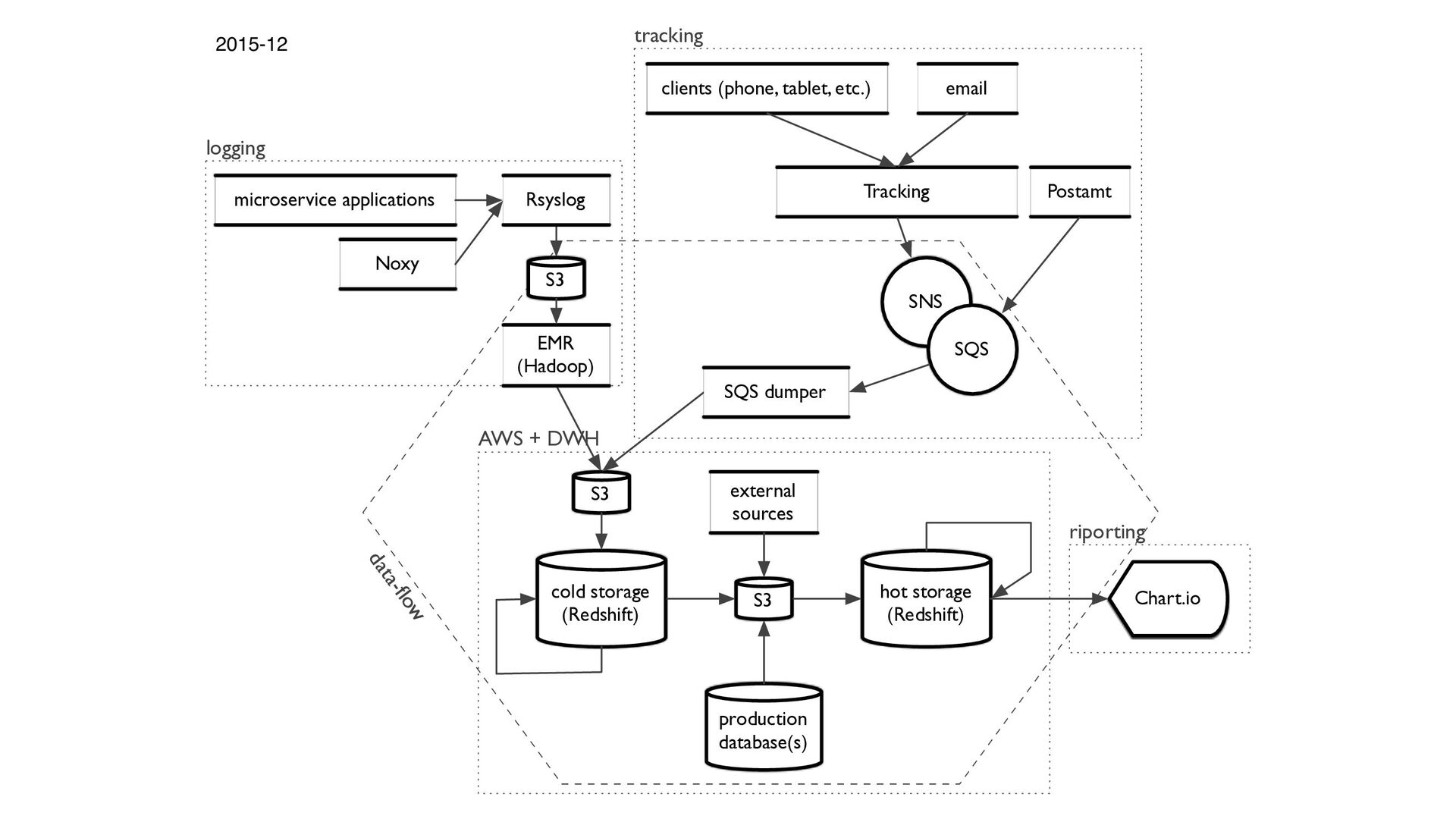{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
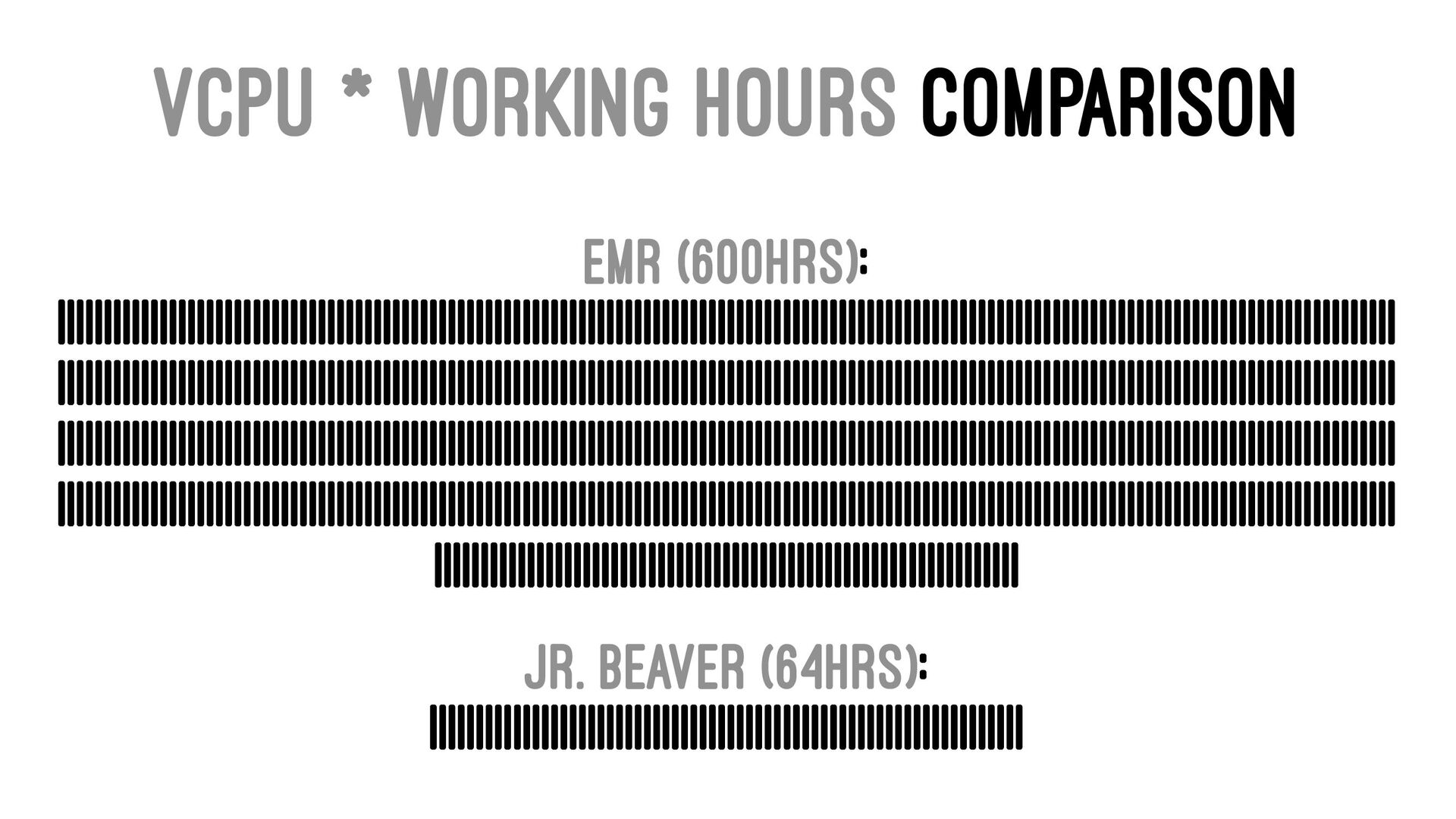{kind=link}
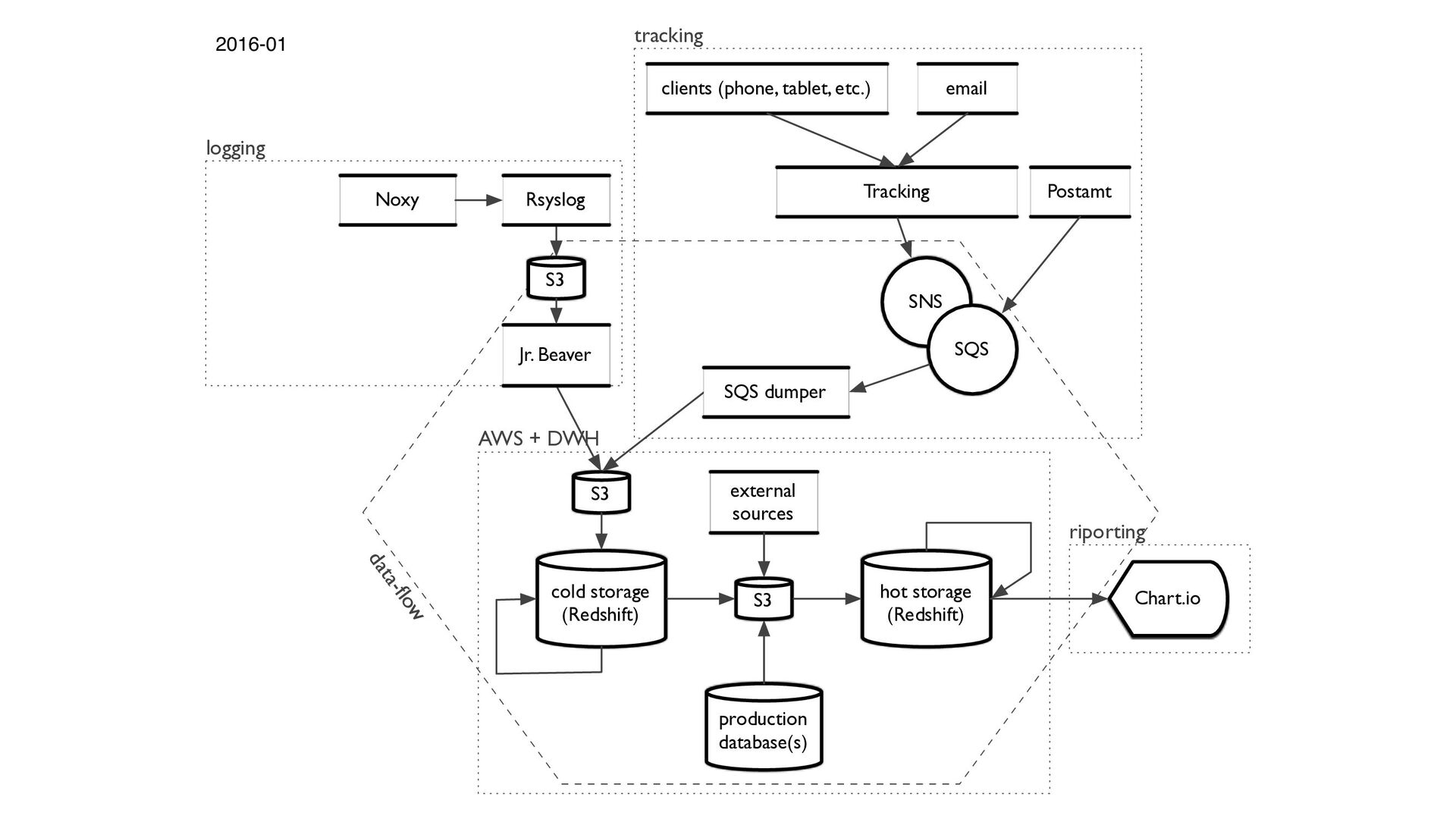{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
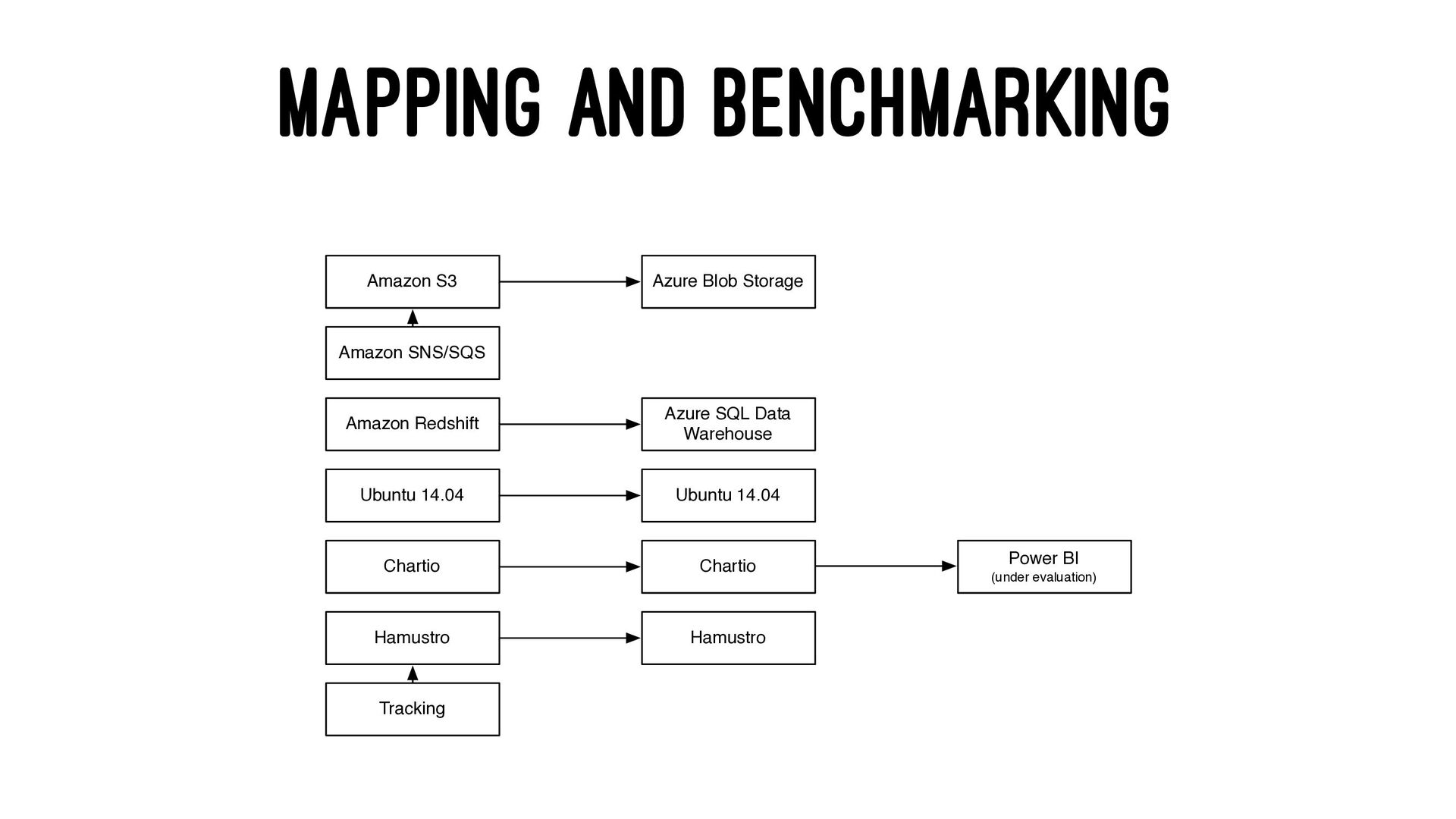{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
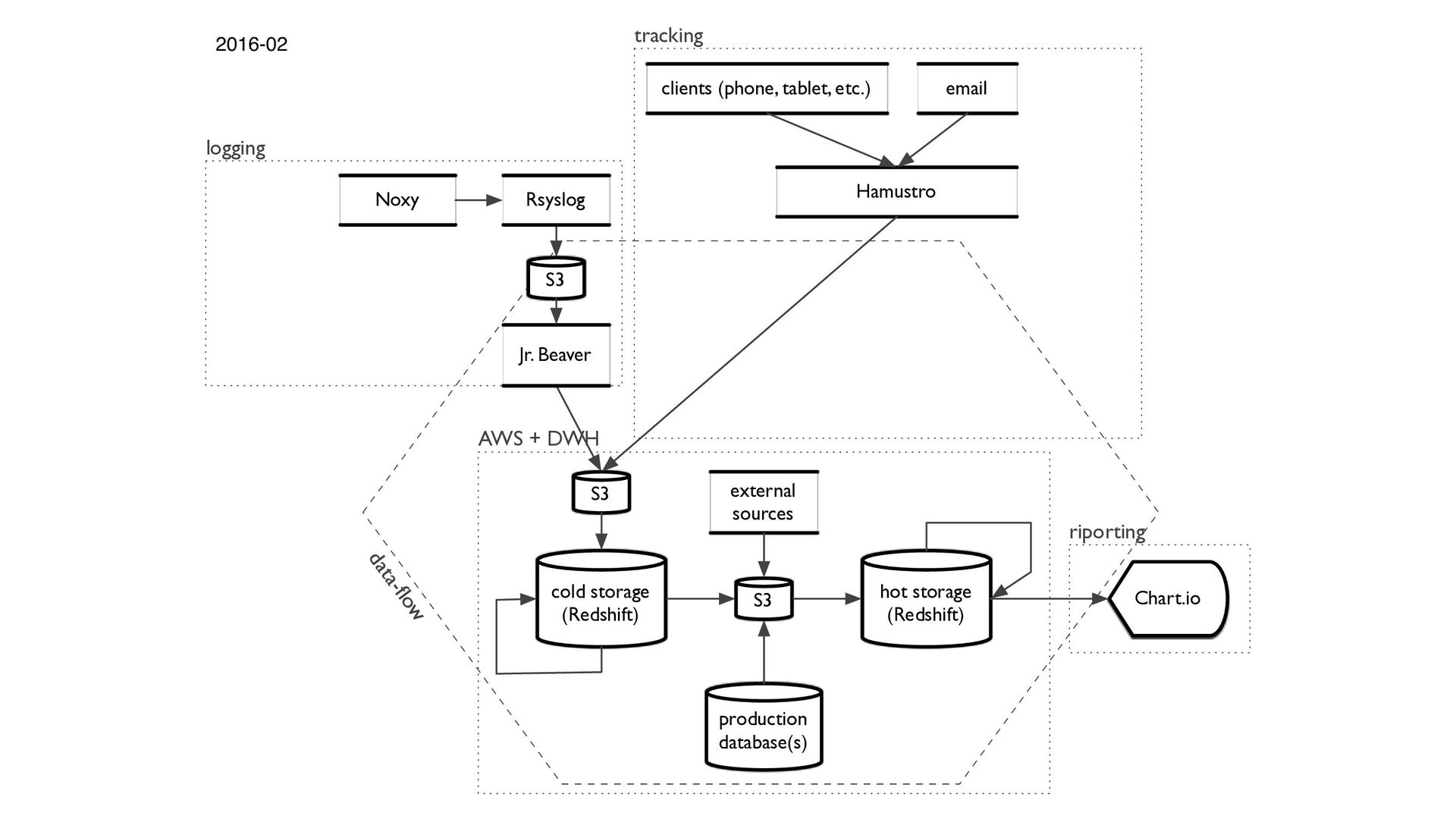{kind=link}
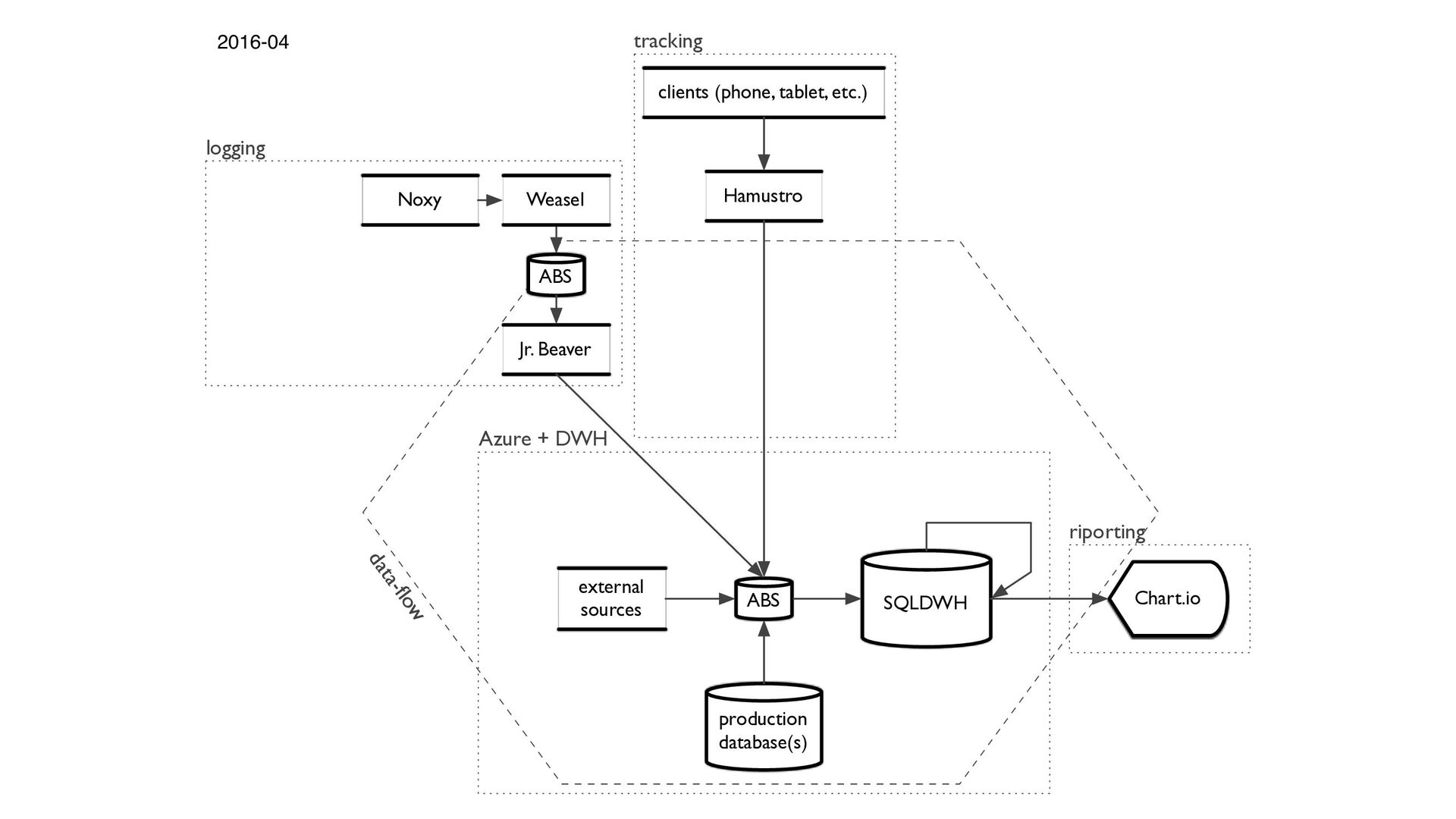{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}