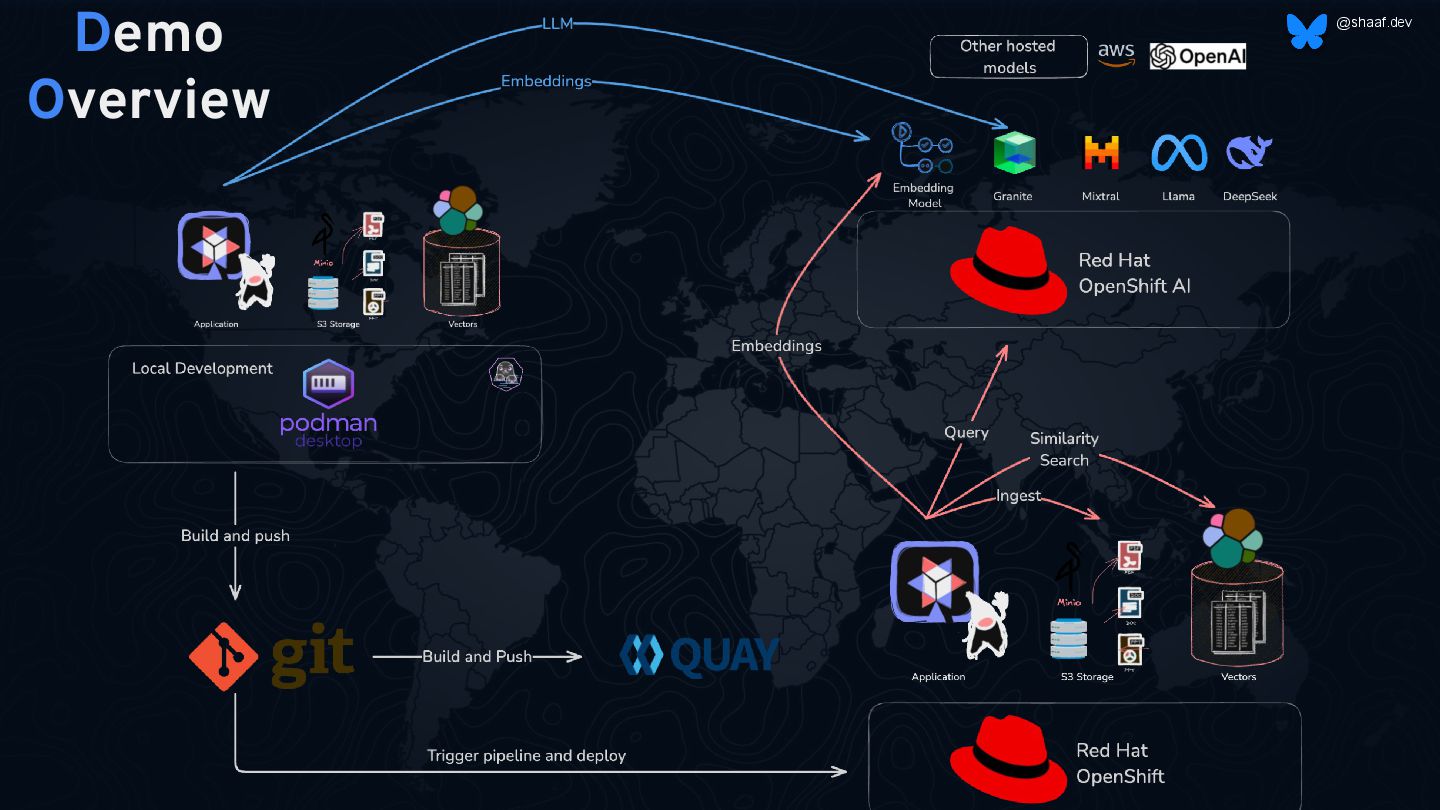
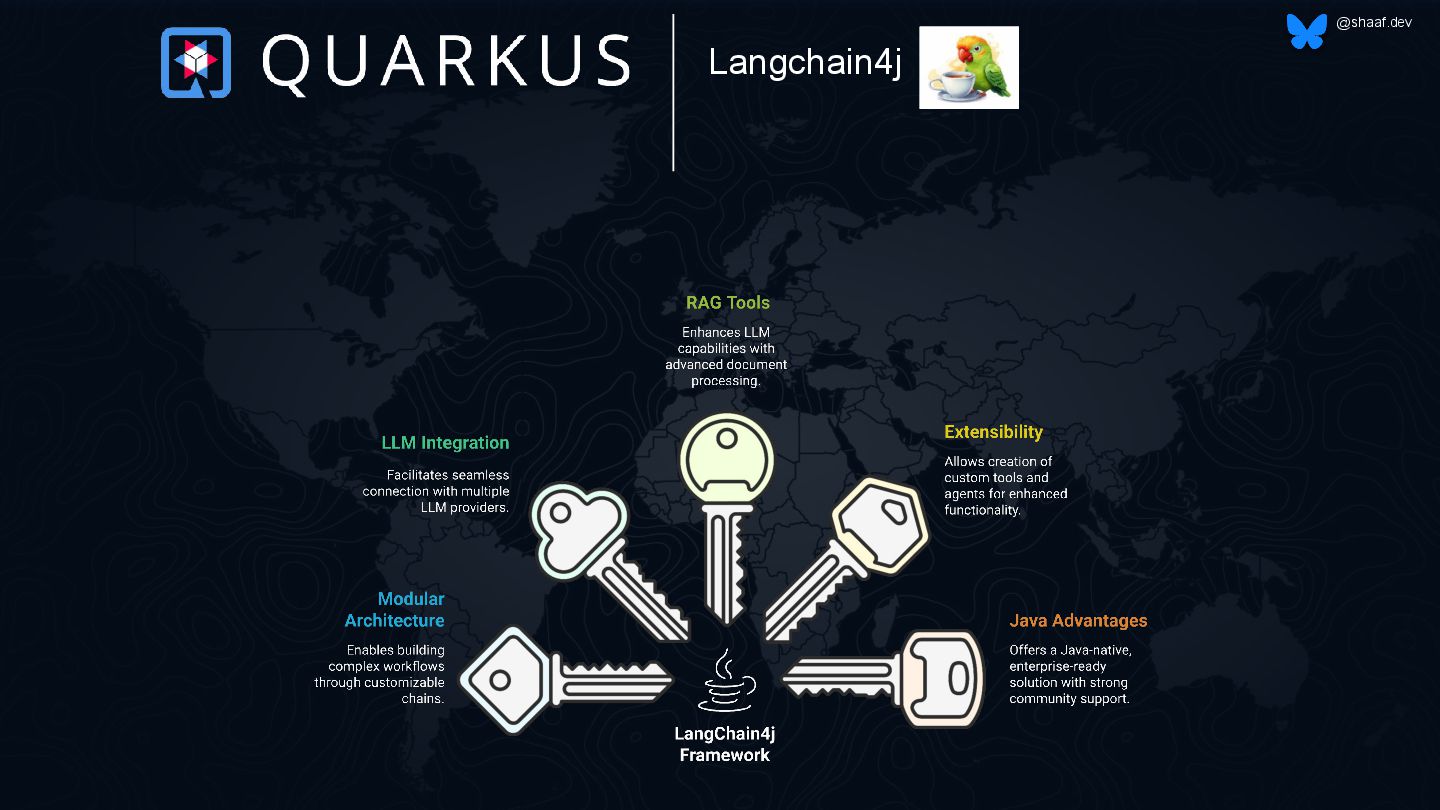
The talk explores how to build and deploy a Retrieval Augmented Generation (RAG) application using OpenShift AI and Podman AI Lab. He will introduce the Podman AI Lab extension, demonstrating how it enables local model testing before deploying into production environments. The session covers vector search fundamentals, demonstrating how Elasticsearch handles vector embeddings for efficient information retrieval. He will also discuss RAG use cases, showcasing how this approach enhances chatbot responses by combining LLMs with real-time data. Finally, he will walk through a live demo of deploying a chatbot on OpenShift AI, integrating Elasticsearch for vector search using LangChain. Attendees will gain a practical understanding of vector-based applications and how to bring them to production environments.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}