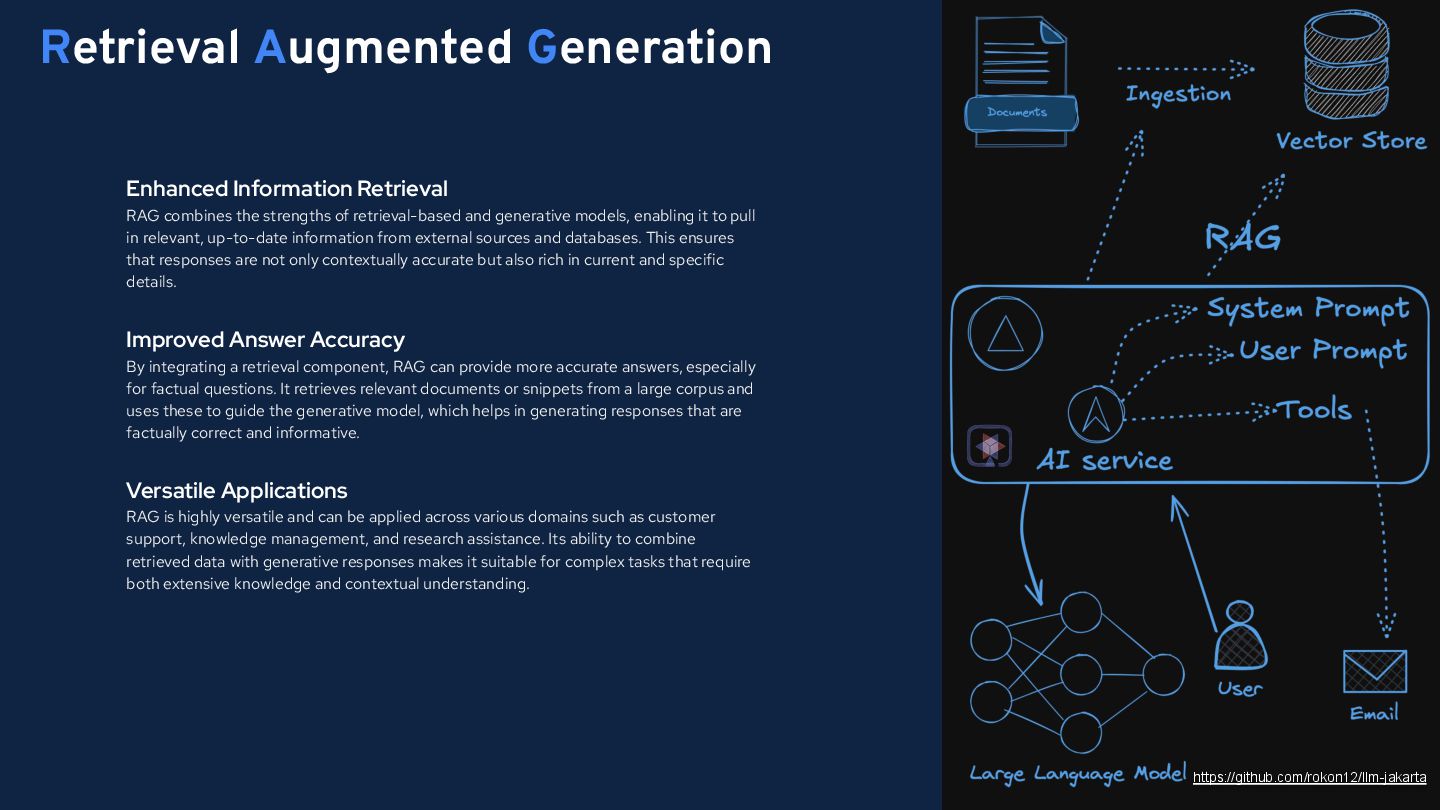
AI is revolutionizing the software landscape. However, for many Java developers, integrating these powerful AI tools into existing enterprise applications or a new one can feel daunting. This hands-on session will demystify the process and show you how to build LLM-powered features directly into your Java codebase. Using Jakarta EE and the LangChain4j library, we'll explore RAG, a cutting-edge technique that combines the vast knowledge of LLMs with the precision of your own data. We'll explore how to create both few-shot and zero-shot RAG models and then add practical features like summarization and similarity search, backed by an Embedding database. Through a live coding demo, we’ll walk you through constructing an AI-powered online store backend and provide practical insights into the architecture and code. Whether you're familiar with AI or just getting started, this session will give you the confidence and skills to harness the potential of LLMs in your Java projects.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}