Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
SSII2025[PT2]AI研究の未来を拓くチームビルディング
Search
画像センシングシンポジウム
PRO
May 26, 2025
1.3k
2
Share
SSII2025[PT2]AI研究の未来を拓くチームビルディング
画像センシングシンポジウム
PRO
May 26, 2025
More Decks by 画像センシングシンポジウム
See All by 画像センシングシンポジウム
SSII2025 [OS3] どの論文でもダメなんだけど! 〜実応用とその課題〜
ssii
PRO
2
1.8k
SSII2025 [OS3-01] End-to-End自動運転の実応用の現場から
ssii
PRO
6
3.5k
SSII2025 [OS3-02] 広告における画像生成技術の実応用の現状
ssii
PRO
6
1.5k
SSII2025 [OS3-03] 有機ミニトマト農場におけるロボット開発と基礎研究
ssii
PRO
0
1.1k
SSII2025 [OS2-01] 自動運転の性能と共に進化するセンシングデバイス
ssii
PRO
2
2.1k
SSII2025 [TS3] 医工連携における画像情報学研究
ssii
PRO
3
1.5k
SSII2025 [OS2] 新たなセンシングの潮流
ssii
PRO
1
730
SSII2025 [OS2-02] イベントカメラの研究紹介と可視光通信への応用
ssii
PRO
1
1.5k
SSII2025 [OS2-03] マルチ/ハイパースペクトル領域における高度な画像撮影および処理技術
ssii
PRO
3
1.6k
Featured
See All Featured
Amusing Abliteration
ianozsvald
1
170
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.3k
How to build a perfect <img>
jonoalderson
1
5.5k
Jess Joyce - The Pitfalls of Following Frameworks
techseoconnect
PRO
1
150
A Modern Web Designer's Workflow
chriscoyier
698
190k
Abbi's Birthday
coloredviolet
2
7.6k
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
340
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.5k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.7k
Paper Plane (Part 1)
katiecoart
PRO
0
7.6k
Transcript
AI研究の未来を拓くチームビルディング 小塚 和紀 (パナソニック ホールディングス株式会社) 2025.5.30
1/77 自己紹介 名前:小塚 和紀(こづか かずき) 博士(工学), MBA 所属:パナソニックホールディングス株式会社 DX・CPS本部 デジタル・AI技術センター
AIソリューション部 1課 スタンフォード大学 人工知能研究所 客員研究員 (2016.4-2019.3) Supervisor:FeiFei Li(世界最大の画像データセットImageNetの開発者) 専門分野:人工知能/コンピュータビジョン/パターン認識 世界最大の行動認識向けマルチモーダルデータセット Home Action Genome, オープンボキャブラリなマルチモーダル基盤モデル HIPIE, 国内最大規模の日本語LLM Panasonic-LLM-100b, 対話型マルチモーダル基盤モデル SegLLM等を開発 マルチモーダルデータセット Home Action Genome マルチモーダル基盤モデル HIPIE 日本語LLM Panasonic-LLM-100b
AI研究環境の現状と課題
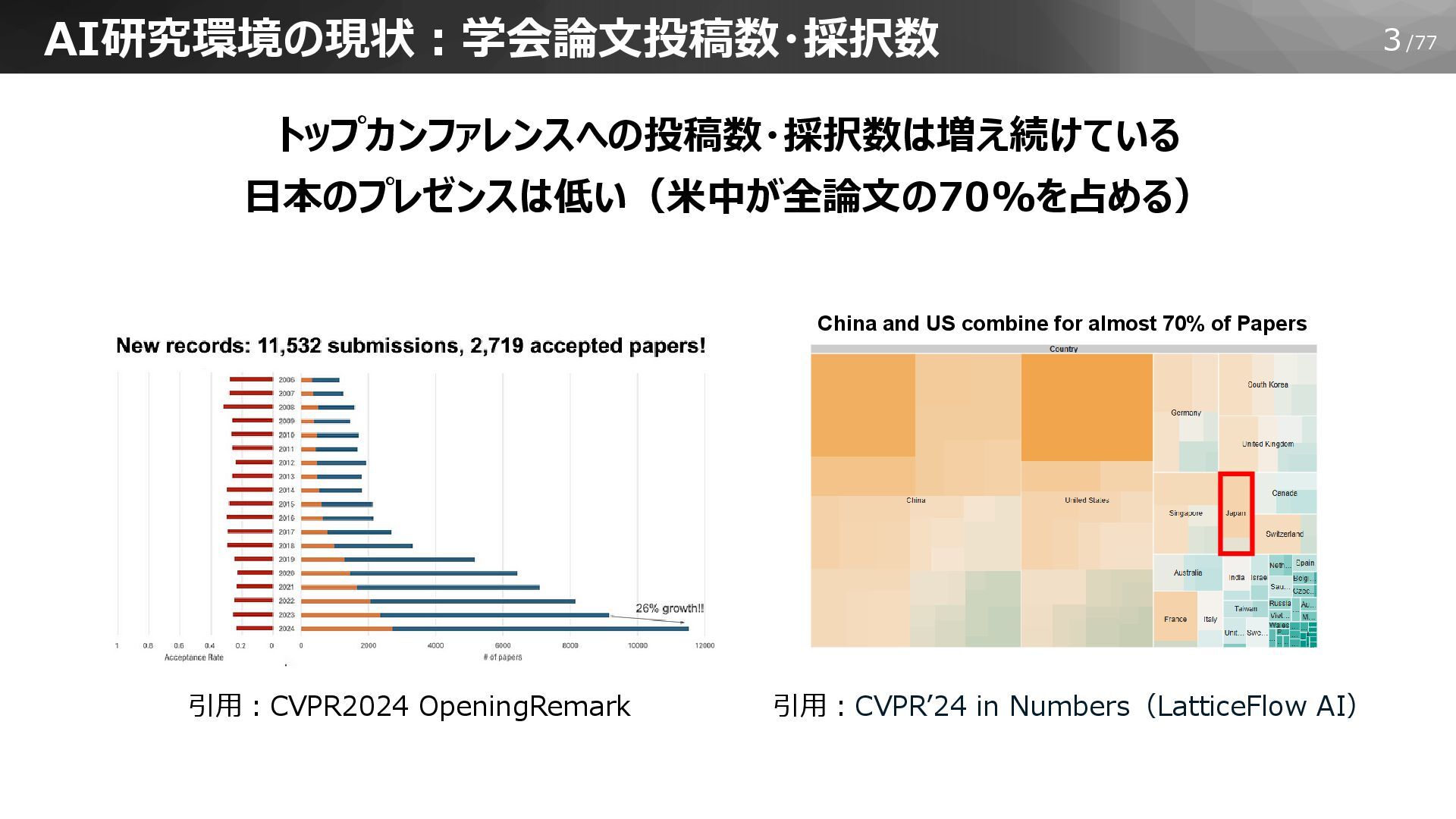
3/77 AI研究環境の現状:学会論文投稿数・採択数 トップカンファレンスへの投稿数・採択数は増え続けている 日本のプレゼンスは低い(米中が全論文の70%を占める) 引用:CVPR2024 OpeningRemark 引用:CVPR’24 in Numbers(LatticeFlow AI)
China and US combine for almost 70% of Papers
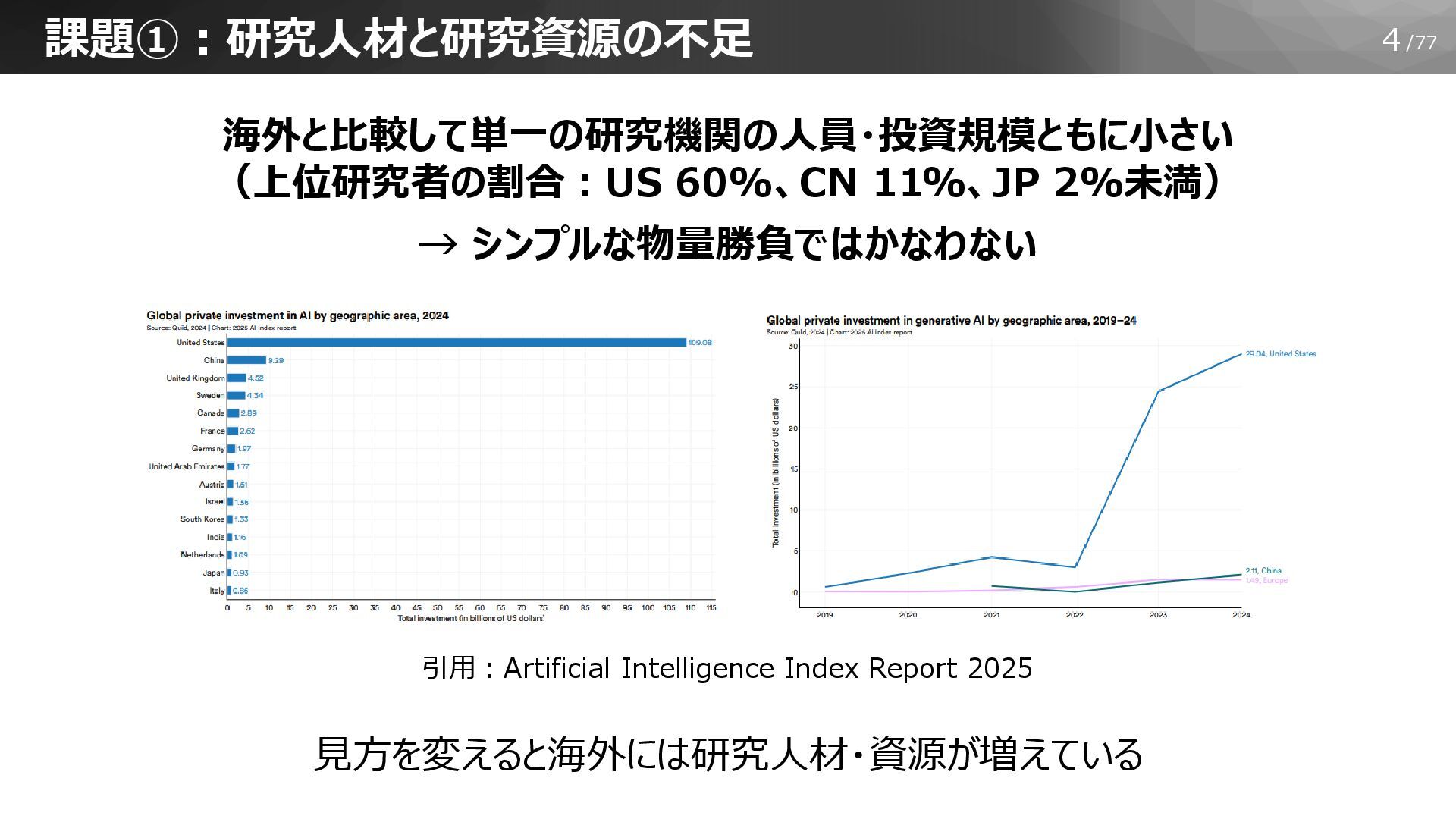
4/77 課題①:研究人材と研究資源の不足 海外と比較して単一の研究機関の人員・投資規模ともに小さい (上位研究者の割合:US 60%、CN 11%、JP 2%未満) → シンプルな物量勝負ではかなわない 見方を変えると海外には研究人材・資源が増えている
引用:Artificial Intelligence Index Report 2025
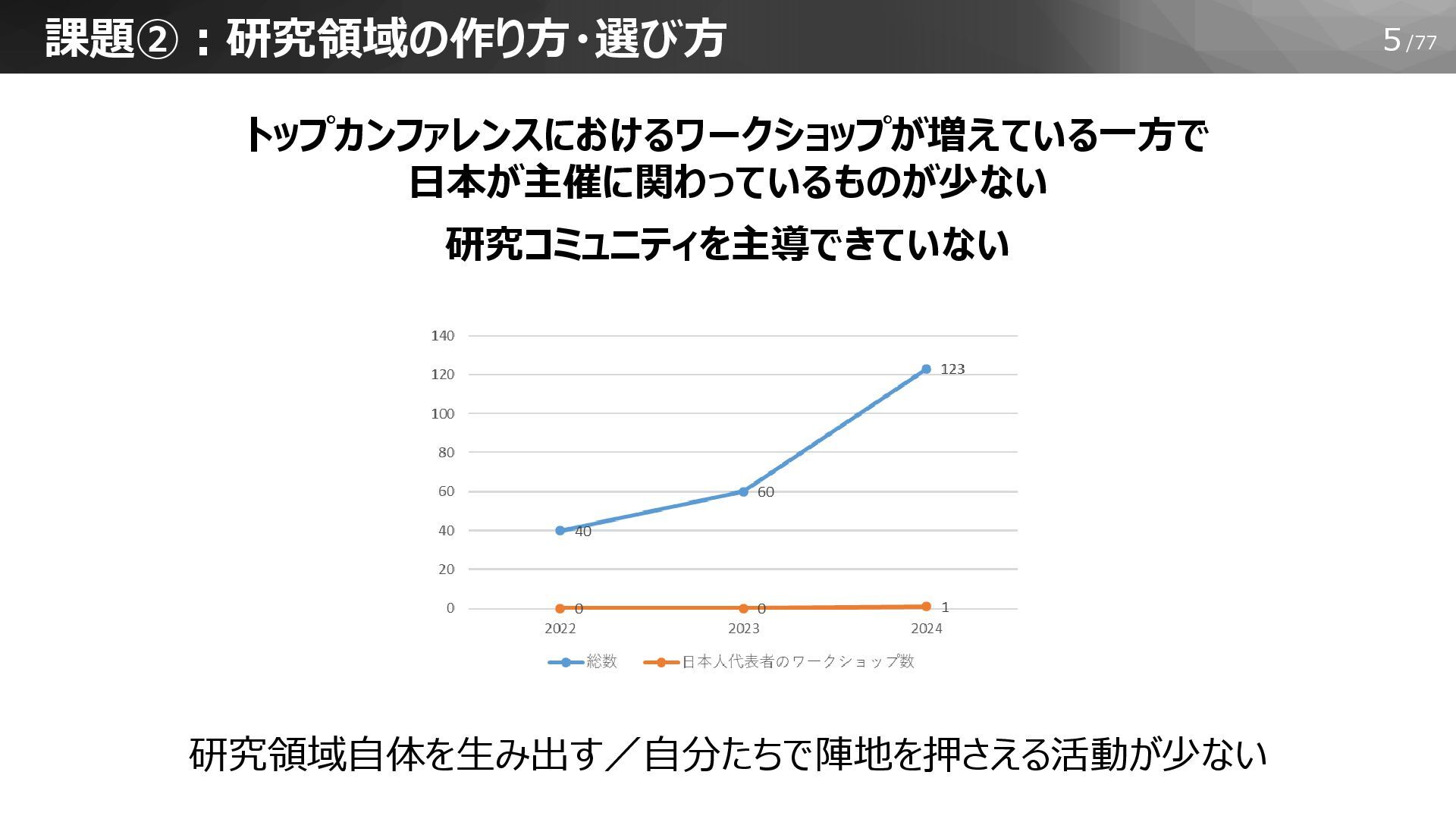
5/77 課題②:研究領域の作り方・選び方 トップカンファレンスにおけるワークショップが増えている一方で 日本が主催に関わっているものが少ない 研究コミュニティを主導できていない 研究領域自体を生み出す/自分たちで陣地を押さえる活動が少ない
6/77 課題③:チームビルディング体制 CVPRの日本人著者の比率、日本人著者を含む論文比率は低下 → 世界の伸びについていけていない コミュニティやチームが国内に閉じていて、世界で増えている資源をうまく活用できていない? [%] 「ResearchPortトップカンファレンス定点観測 vol.13」から作成
7/77 AI研究環境の現状と課題:まとめとヒント トップカンファレンスへの投稿数・採択数は増え続けている一方で 日本のプレゼンスは低いまま(人員・投資規模ともに小さい) → 日本だけで考えると規模は小さいが世界は規模が急激に拡大 まだ、研究のチームやコミュニティの範囲が狭く 国際的な研究コミュニティを主導できていない → 外部で拡大する資源をうまく使いこなせていない
外部をうまく使いこなすことができれば、少ない資源しかなくても十分戦えるのでは?
本講演のトピック
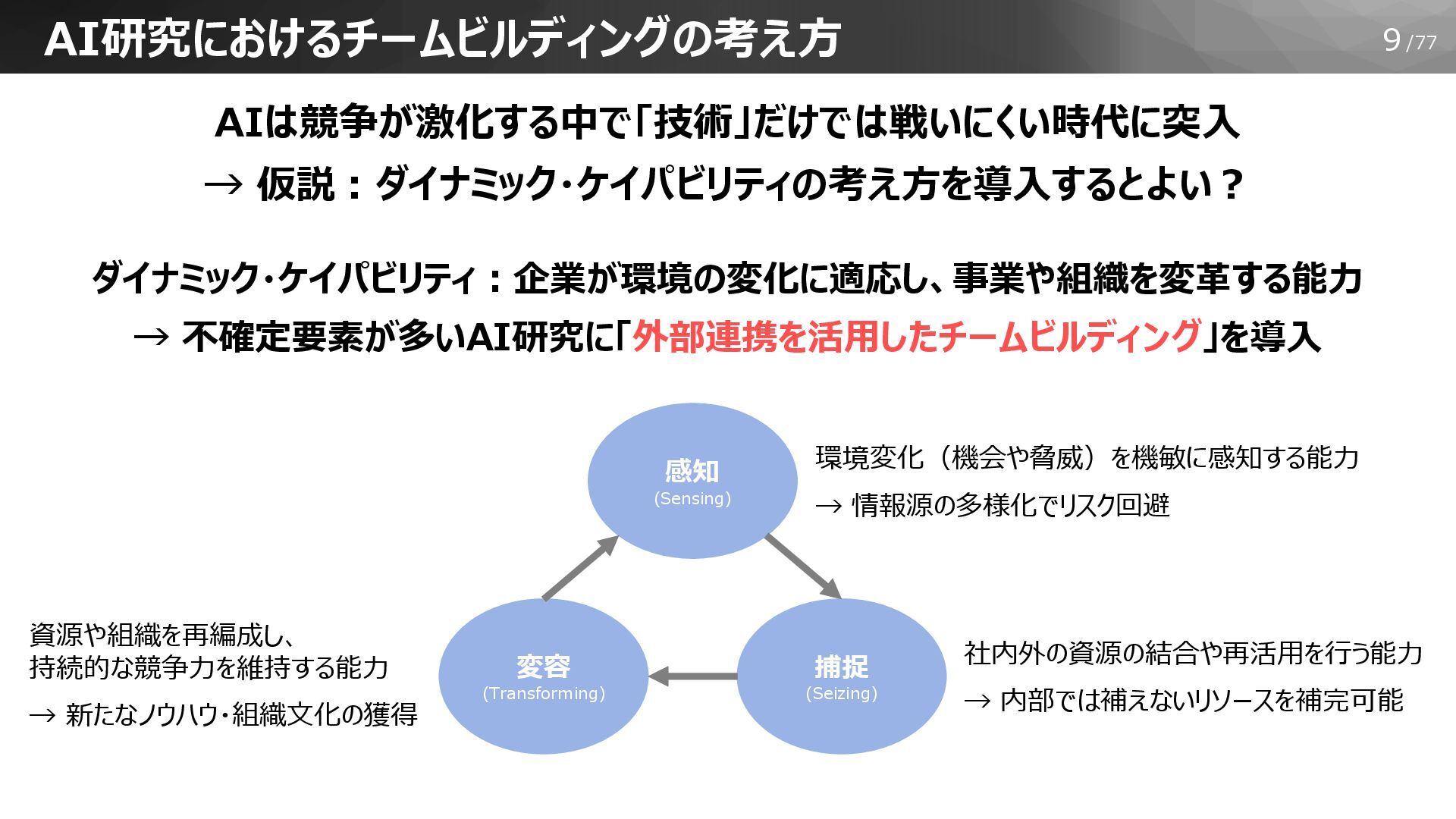
9/77 AI研究におけるチームビルディングの考え方 AIは競争が激化する中で「技術」だけでは戦いにくい時代に突入 → 仮説:ダイナミック・ケイパビリティの考え方を導入するとよい? ダイナミック・ケイパビリティ:企業が環境の変化に適応し、事業や組織を変革する能力 → 不確定要素が多いAI研究に「外部連携を活用したチームビルディング」を導入 感知 (Sensing)
捕捉 (Seizing) 変容 (Transforming) 環境変化(機会や脅威)を機敏に感知する能力 → 情報源の多様化でリスク回避 社内外の資源の結合や再活用を行う能力 → 内部では補えないリソースを補完可能 資源や組織を再編成し、 持続的な競争力を維持する能力 → 新たなノウハウ・組織文化の獲得
10/77 今回の講演 AI研究の最前線における外部連携を活用したチームビルディングの事例について紹介 大学との連携事例: 1.スタンフォード人工知能研究所との連携 → 大規模データセット構築、国際ワークショップ主催に関する事例 2.UC Berkeleyとの連携 →
バーチャルラボ体制の構築と基盤モデル開発の事例 スタートアップとの連携事例: 3.ストックマーク株式会社との協業による大規模言語モデルの開発 4.FastLabel株式会社との協業によるデータアノテーション効率化 → AIの社会実装に向けた外部連携の事例
パナソニックにおけるAI研究の実践と チームビルディング
12/77 家電に加えて,住宅設備,電気自動車向けバッテリー,運搬向けロボットなど 身の回りにある多くのモノを製造・販売 パナソニックグループの特徴
13/77 パナソニックのAIに対する考え方 Cyber Physical AI 安定品質のものづくりで、 実世界に価値を送り続ける 産業に破壊的な価値をもたらす ソフトウェア技術 “REAL”
IoT Company 実世界のデータをサイバー空間で分析し くらしを豊かにし社会課題の解決を行う Cyber-Physical 実世界のデータをサイバー空間で分析する Cyber Physicalに注力 → クラウド上だけではなく,実空間に近い領域でのAI活用がパナソニックの優位性
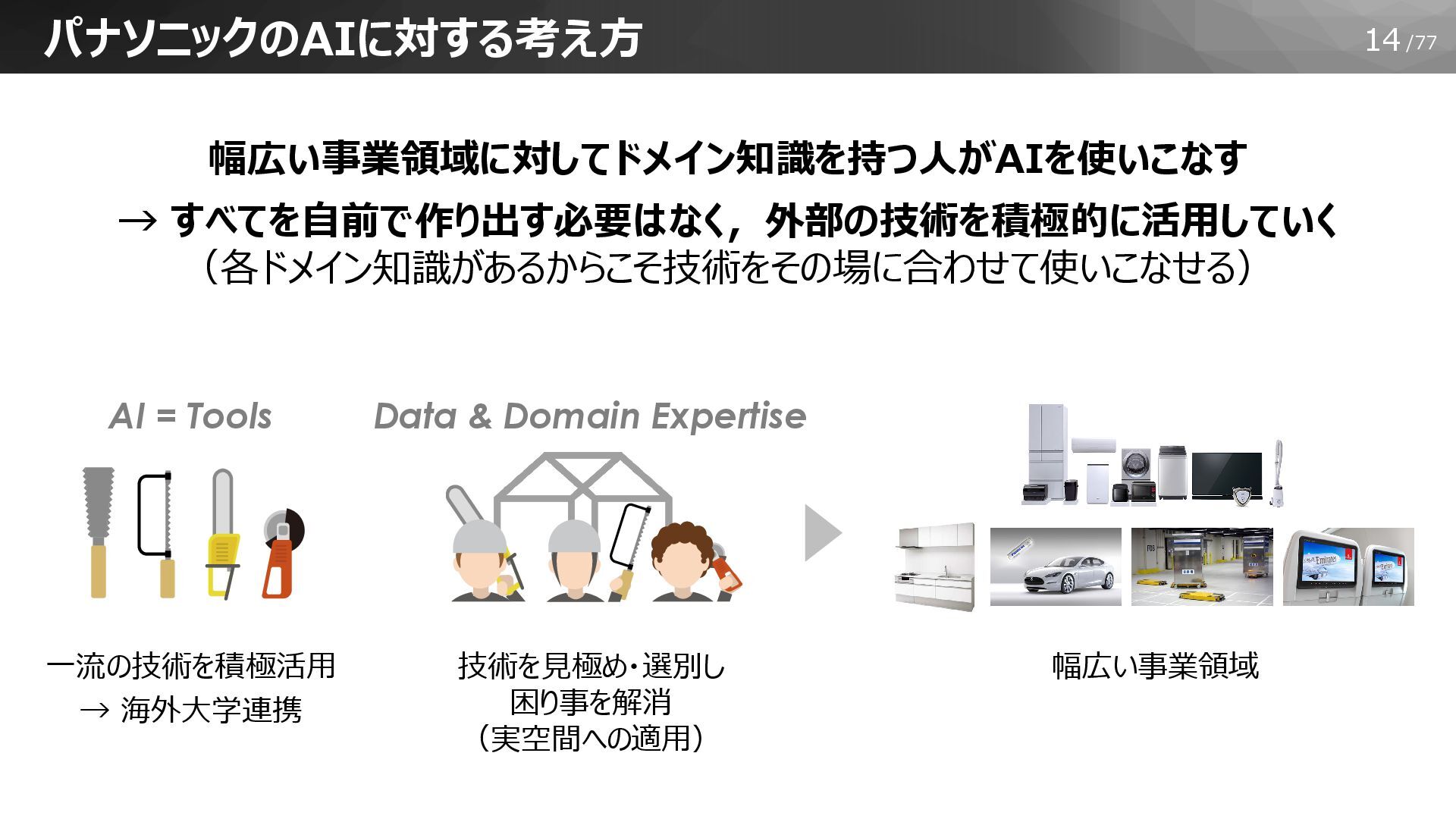
14/77 パナソニックのAIに対する考え方 幅広い事業領域に対してドメイン知識を持つ人がAIを使いこなす → すべてを自前で作り出す必要はなく,外部の技術を積極的に活用していく (各ドメイン知識があるからこそ技術をその場に合わせて使いこなせる) AI = Tools 一流の技術を積極活用
→ 海外大学連携 技術を見極め・選別し 困り事を解消 (実空間への適用) Data & Domain Expertise 幅広い事業領域
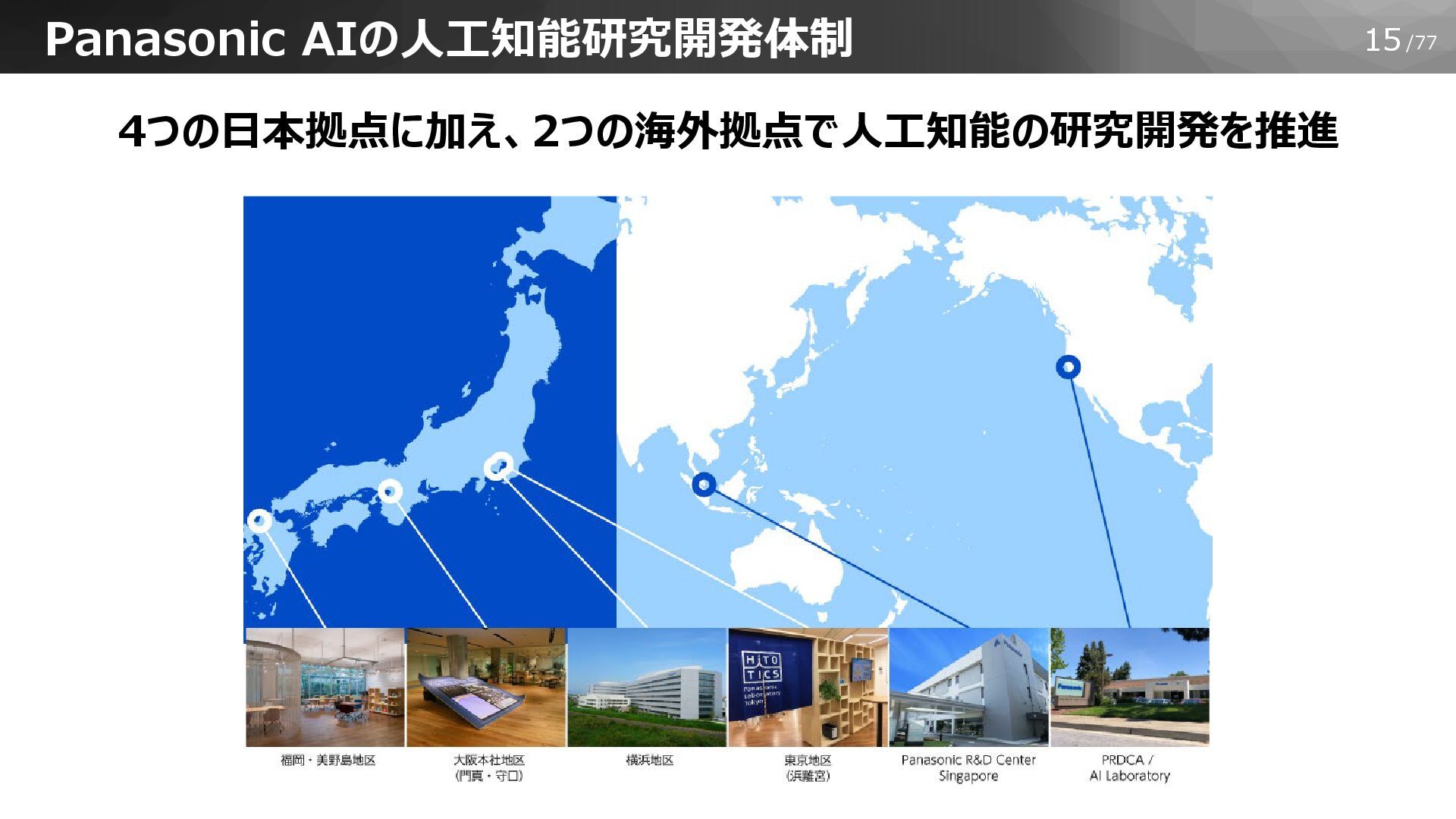
15/77 Panasonic AIの人工知能研究開発体制 4つの日本拠点に加え、2つの海外拠点で人工知能の研究開発を推進
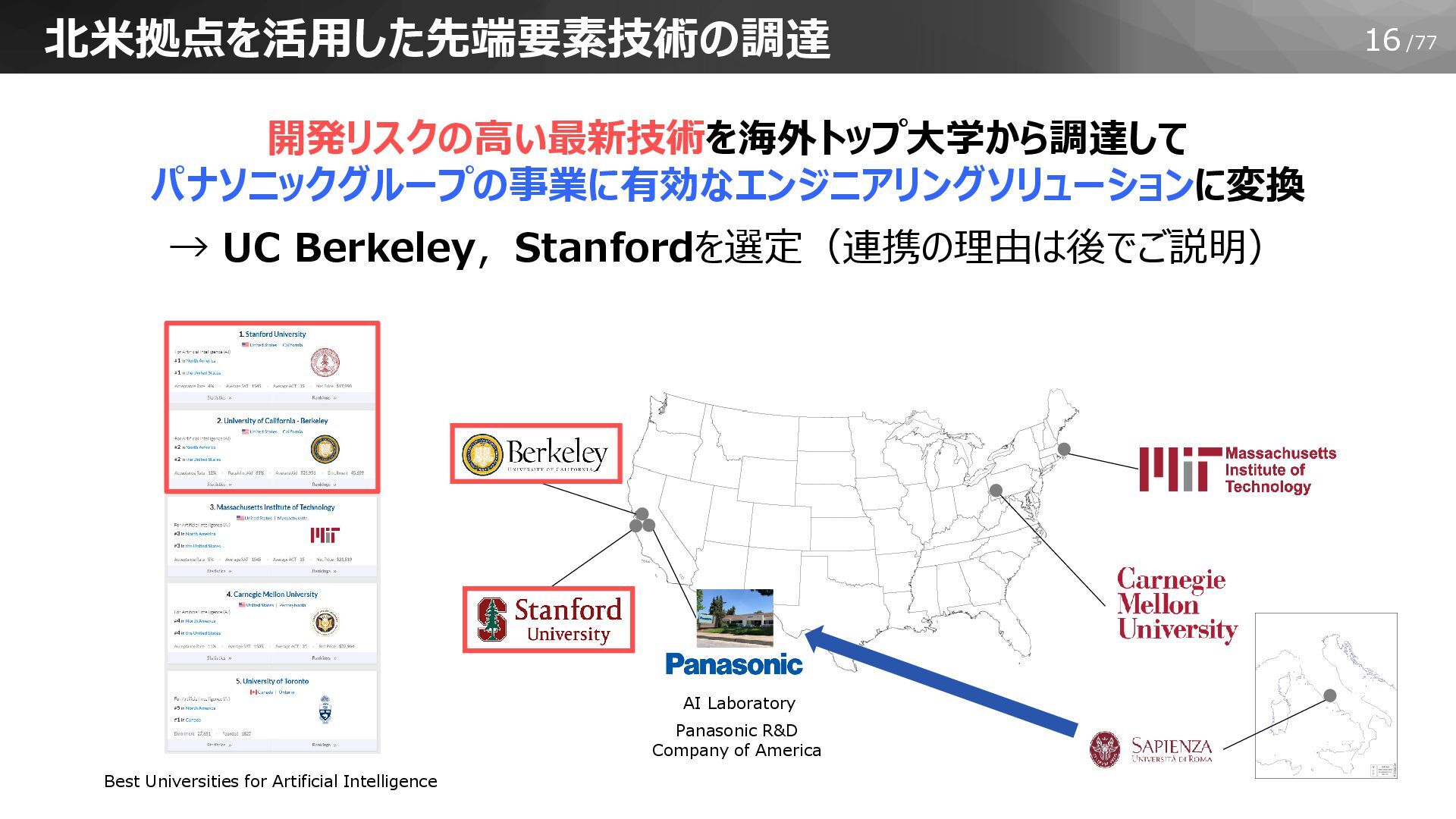
16/77 北米拠点を活用した先端要素技術の調達 開発リスクの高い最新技術を海外トップ大学から調達して パナソニックグループの事業に有効なエンジニアリングソリューションに変換 → UC Berkeley,Stanfordを選定(連携の理由は後でご説明) Best Universities for
Artificial Intelligence AI Laboratory Panasonic R&D Company of America
スタンフォード人工知能研究所との連携と 大規模データセット構築
18/77 スタンフォード人工知能研究所(SAIL) 世界トップクラス研究者が多数在籍する人工知能研究機関 → 基盤モデル等インパクトが大きい研究を数多く発信 引用:Stanford AI Lab On the
Opportunities and Risks of Foundation Models Mobile ALOHA AI Index Report
19/77 SAILのトップ研究者:FeiFei Li Deep Learningが流行るきっかけとなったデータセットImageNetを構築・公開 人間を中心としたAI技術、およびアプリケーションを研究していく新たな組織 Human-Centered AI Institute(HAI)を設立(2019年3月) 引用:FeiFei
Li TED talk How we're teaching computers to understand pictures 引用:Stanford Institute for Human- Centered Artificial Intelligence (HAI)
20/77 スタンフォード大の戦い方(特にFeiFei Li) モデル単体よりもインパクトを重視した発信 過去の事例:AIの研究で必要となるデータを押さえることで分野を牽引 Deep Learningはデータによるタスクのコントロールが可能 一方で,データの構築は,膨大な資金力と期間が必要になる (学生が着手しにくく敵が少なくなる,引用される寿命が長い) 画像分類
行動認識 シーン記述 詳細行動認識 大規模データセット:ImageNet→ActivityNet→Visual Genome→Action Genome (徐々に認識内容が高度になっていっている)
21/77 スタンフォード大の戦い方(特にFeiFei Li) ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
Deep Learningが出現した2012年から数年で性能が99%に到達 (2017年でアカデミアによるコンペティションを終了する宣言) → 新たな認識タスクを作る&その分野を流行らせるをセットにしている 引用:Large Scale Visual Recognition Challenge (ILSVRC) 2017
22/77 着想:ゴールドラッシュ 1850年頃にアメリカで起きた金脈を探し当てて 一攫千金を狙う採掘者が殺到した出来事 実際に儲けたのは,金の採掘者ではなく,つるはし,鉄道,ジーンズの会社 引用:Ballou’s Pictorial Drawing-Room Companion 引用:リーバイス広告(1950年代)
AI研究でも同じようなことが起こっている?
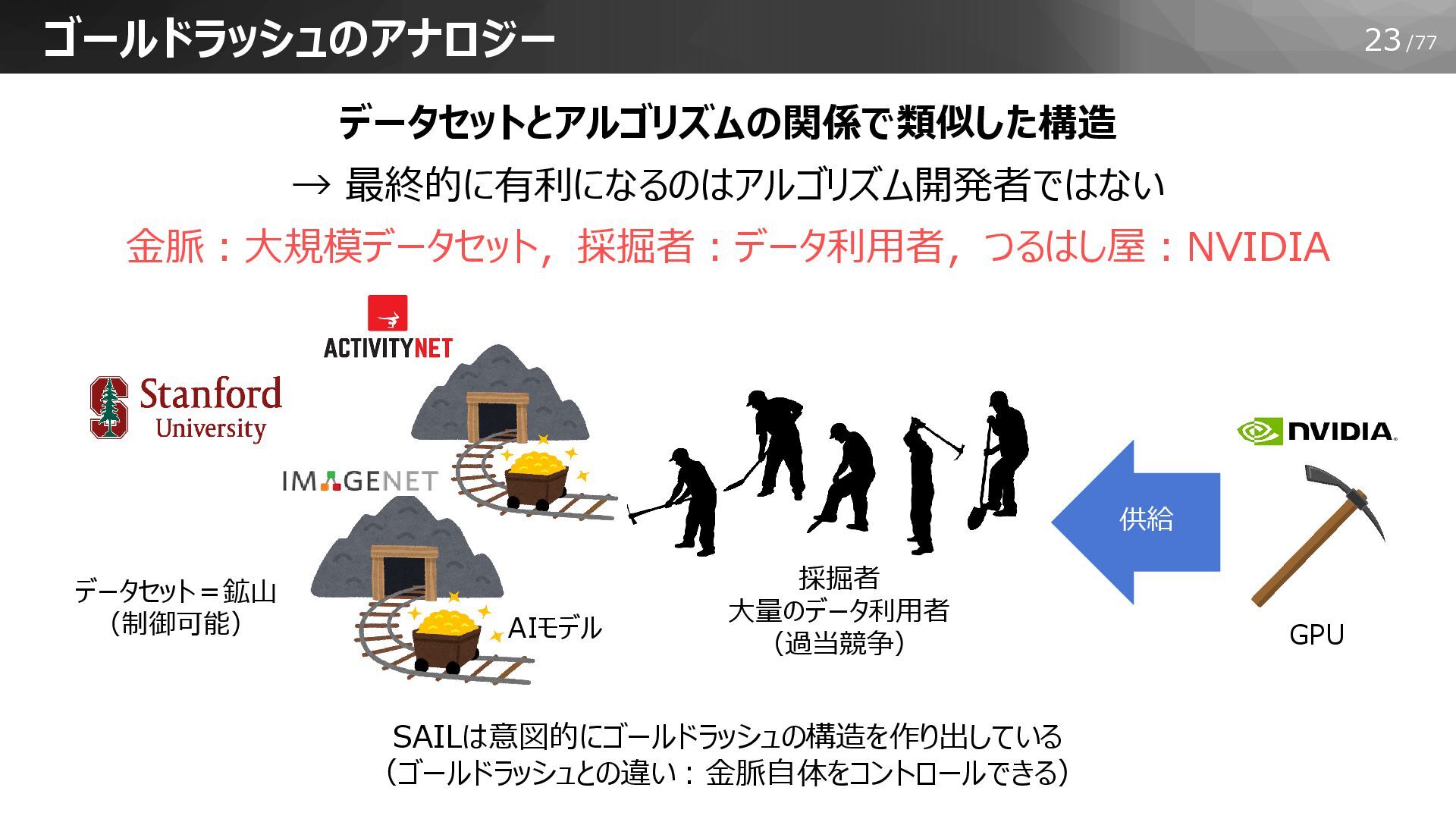
23/77 ゴールドラッシュのアナロジー データセットとアルゴリズムの関係で類似した構造 → 最終的に有利になるのはアルゴリズム開発者ではない 金脈:大規模データセット,採掘者:データ利用者,つるはし屋:NVIDIA データセット=鉱山 (制御可能) 採掘者 大量のデータ利用者
(過当競争) AIモデル GPU 供給 SAILは意図的にゴールドラッシュの構造を作り出している (ゴールドラッシュとの違い:金脈自体をコントロールできる)
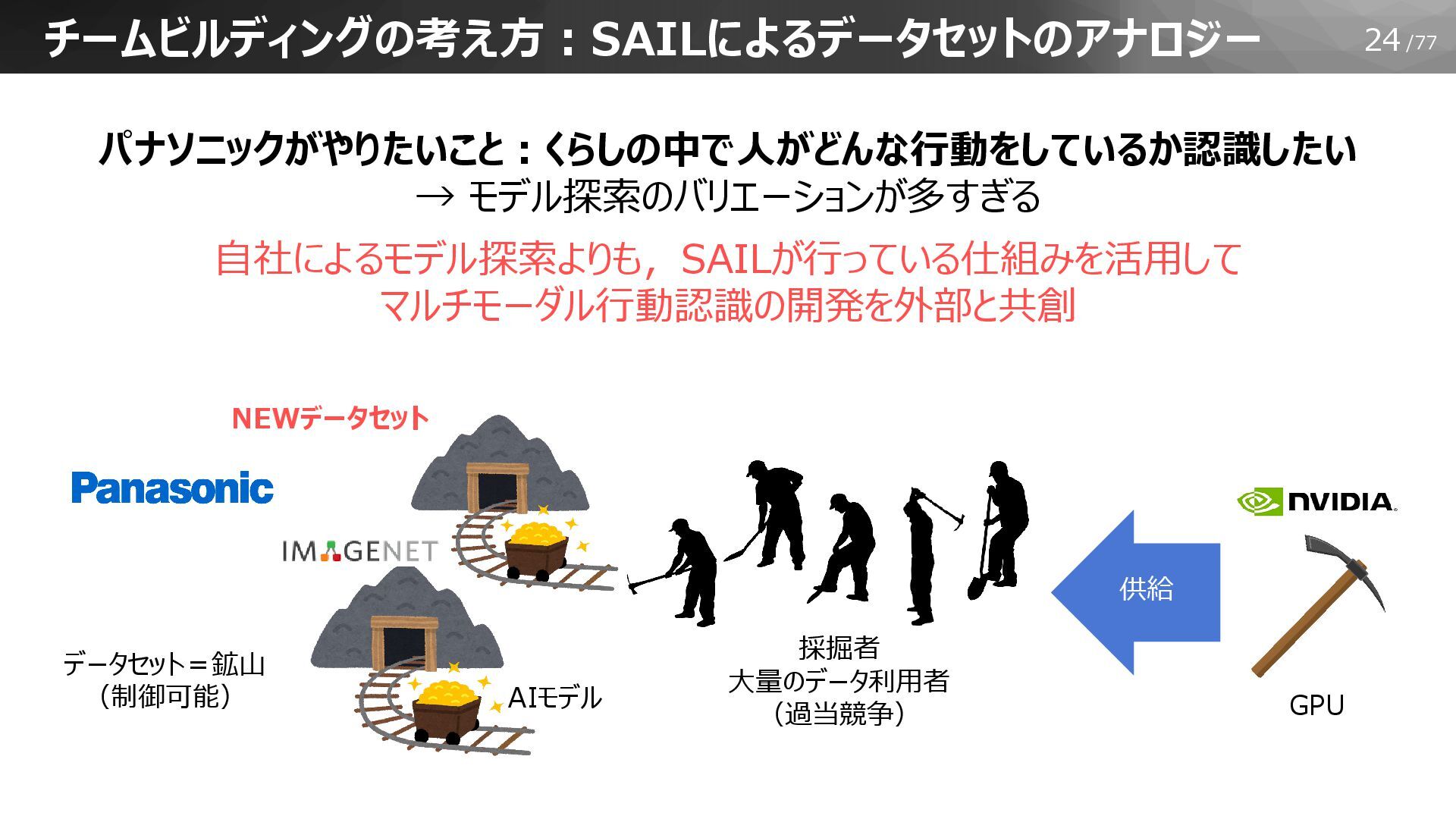
24/77 チームビルディングの考え方:SAILによるデータセットのアナロジー パナソニックがやりたいこと:くらしの中で人がどんな行動をしているか認識したい → モデル探索のバリエーションが多すぎる 自社によるモデル探索よりも,SAILが行っている仕組みを活用して マルチモーダル行動認識の開発を外部と共創 採掘者 大量のデータ利用者 (過当競争)
AIモデル GPU 供給 NEWデータセット データセット=鉱山 (制御可能)
25/77 研究を開始するにあたって行った仕掛け:SAILが抱えていた課題 SAILの課題意識:データセットの倫理問題 TinyImagesの問題が指摘される2020年より前からSAILでは問題の可能性を把握 インターネット上から取得しなくてよい安全なデータを欲しがっていた → 2018年あたりからパナソニックとStanfordでデータセット倫理の解決策を議論開始 Large image datasets:
A pyrrhic win for computer vision?, WACV2021
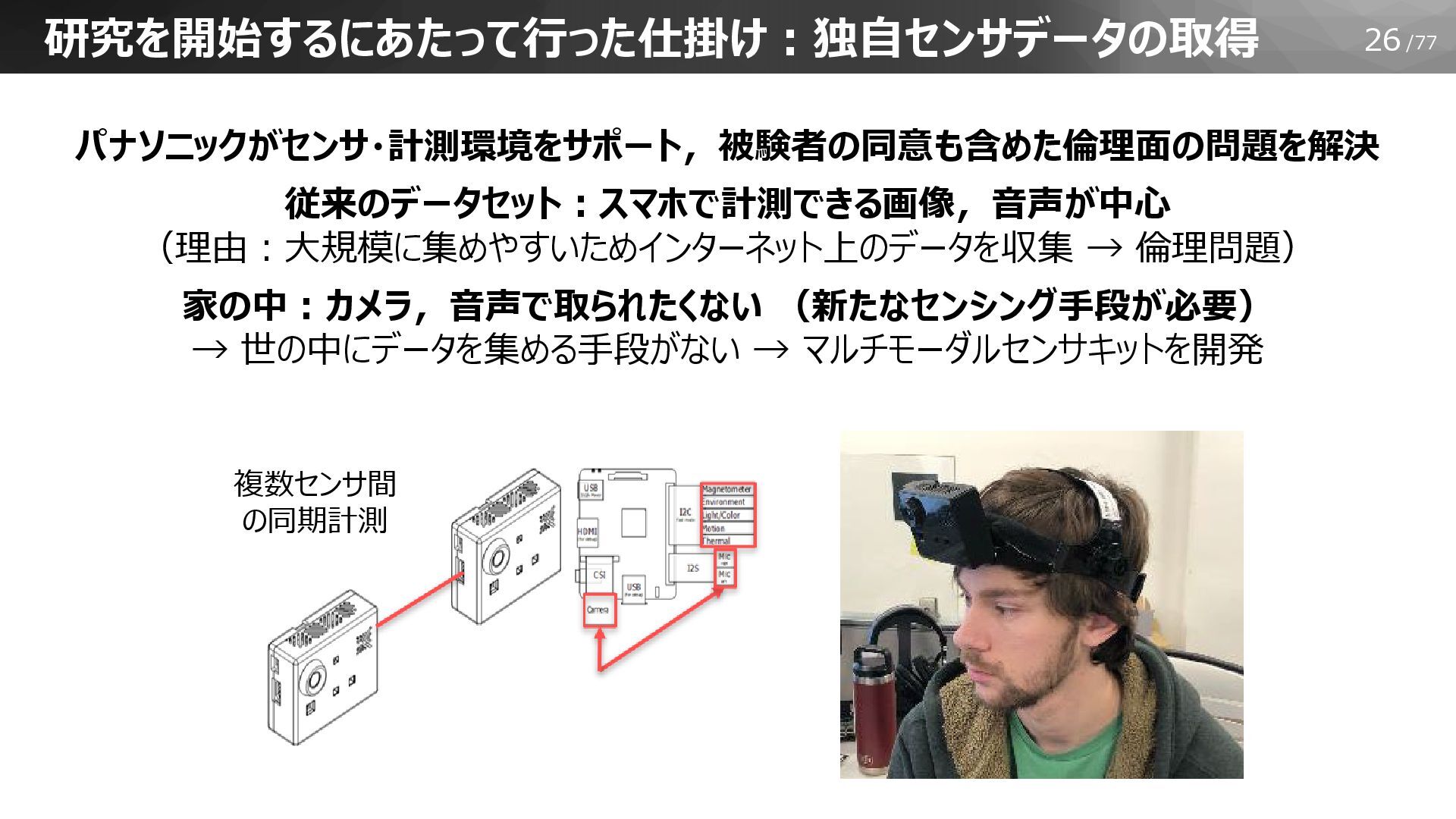
26/77 研究を開始するにあたって行った仕掛け:独自センサデータの取得 パナソニックがセンサ・計測環境をサポート,被験者の同意も含めた倫理面の問題を解決 従来のデータセット:スマホで計測できる画像,音声が中心 (理由:大規模に集めやすいためインターネット上のデータを収集 → 倫理問題) 家の中:カメラ,音声で取られたくない (新たなセンシング手段が必要) →
世の中にデータを集める手段がない → マルチモーダルセンサキットを開発 複数センサ間 の同期計測
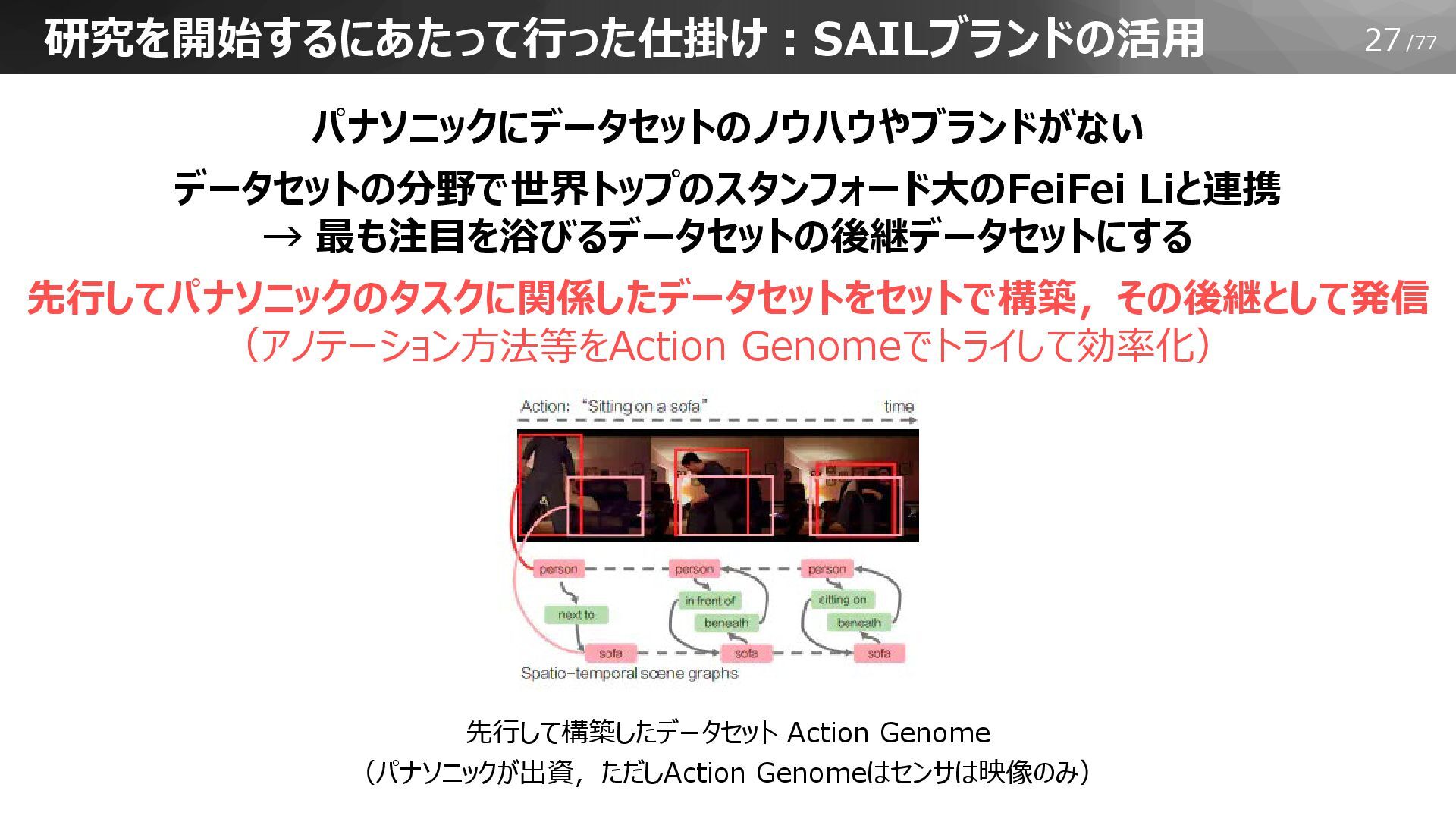
27/77 研究を開始するにあたって行った仕掛け:SAILブランドの活用 パナソニックにデータセットのノウハウやブランドがない データセットの分野で世界トップのスタンフォード大のFeiFei Liと連携 → 最も注目を浴びるデータセットの後継データセットにする 先行してパナソニックのタスクに関係したデータセットをセットで構築,その後継として発信 (アノテーション方法等をAction Genomeでトライして効率化)
先行して構築したデータセット Action Genome (パナソニックが出資,ただしAction Genomeはセンサは映像のみ)
28/77 Home Action Genome 住空間における世界最大の行動認識データセット Home Action Genomeを構築・公開,CVPRへの採択 (https://homeactiongenome.org/) ※研究用途であればダウンロード&使用可能です
29/77 Home Action Genome マルチモーダルデータ カメラだけでなく,家庭内に設置可能なセンサにより ユーザ行動を認識 ※パナソニックが保有する実験ハウス(US)で計測を 実施 行動ラベル(アノテーション情報)
家庭内で発生する行動を網羅 家庭内の行動(Activity): 70種類 行動内の詳細動作(Atomic Action): 453種類 住空間における多くのユーザ行動を検出可能になる 日常行動3,500シーンを収録
30/77 人が集まる仕組みの再現:ワークショップ,コンペティションの主催 カメラ,赤外線アレイ,マイクx2,RGB光,光,加速度,角速度, 人感,磁気,気圧,湿度,温度 複数視点から撮影(俯瞰,一人称)プライバシーを考慮した複数種類のセンサを導入
31/77 CAMP workshop ImageNet Large Scale Visual Recognition Challenge (ILSVRC)
と同様の認識コンペティションを開催して,AI研究者と行動認識モデルを共創 International Challenge on Compositional and Multimodal Perception(CAMP) をAIのトップカンファレンス(CVPR,ICCV,ECCV)で主催
32/77 CAMP workshop SAILでデータセットを作ったメンバー全員を主催者にすることで ワークショップの採択の確率・注目度を上げる → ワークショップ提案はブラインド式ではないため 投稿メンバーと多様性を特に重視(出身エリアが全世界をカバーするように調整)
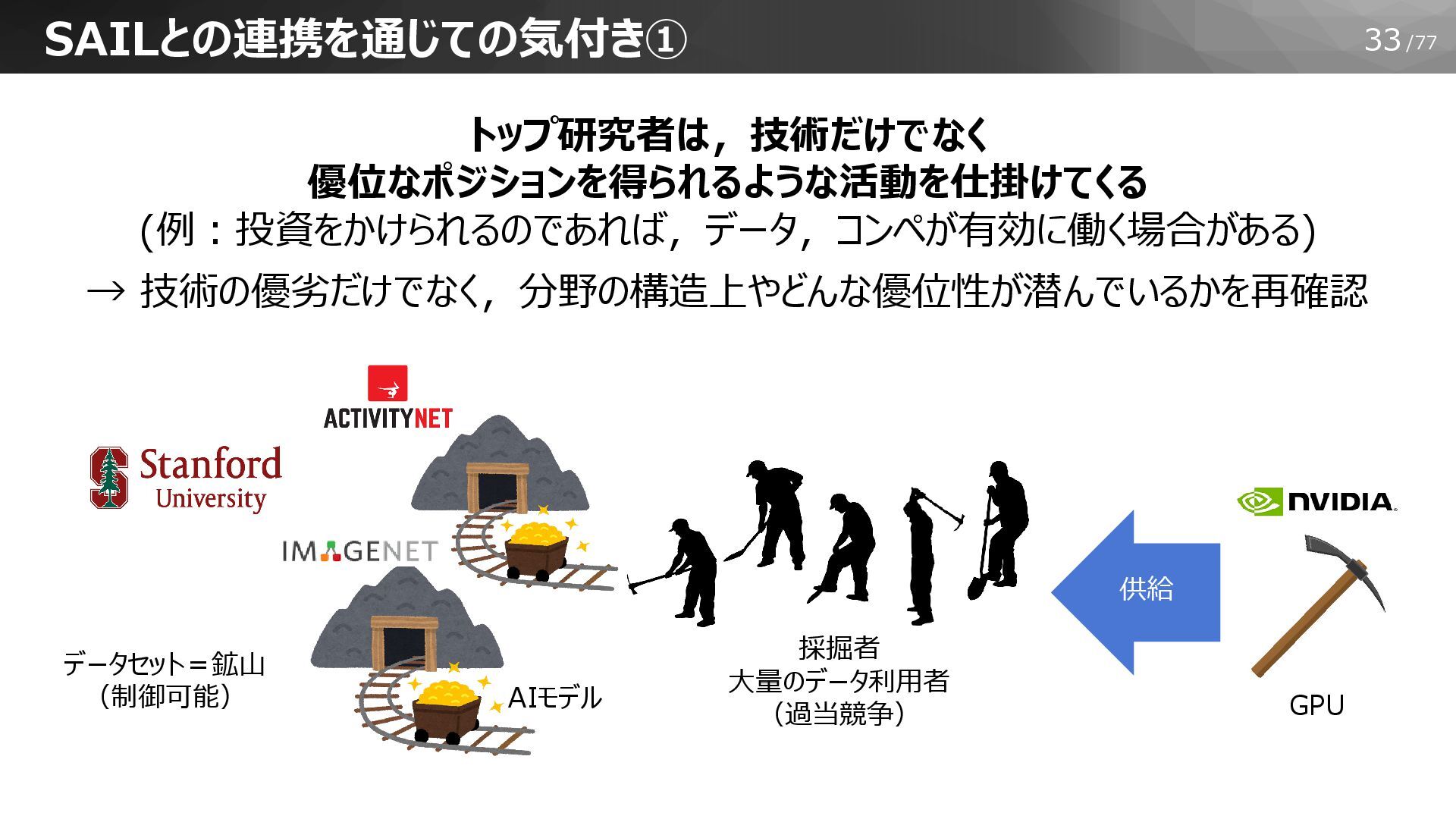
33/77 SAILとの連携を通じての気付き① 採掘者 大量のデータ利用者 (過当競争) AIモデル GPU 供給 トップ研究者は,技術だけでなく 優位なポジションを得られるような活動を仕掛けてくる
(例:投資をかけられるのであれば,データ,コンペが有効に働く場合がある) → 技術の優劣だけでなく,分野の構造上やどんな優位性が潜んでいるかを再確認 データセット=鉱山 (制御可能)
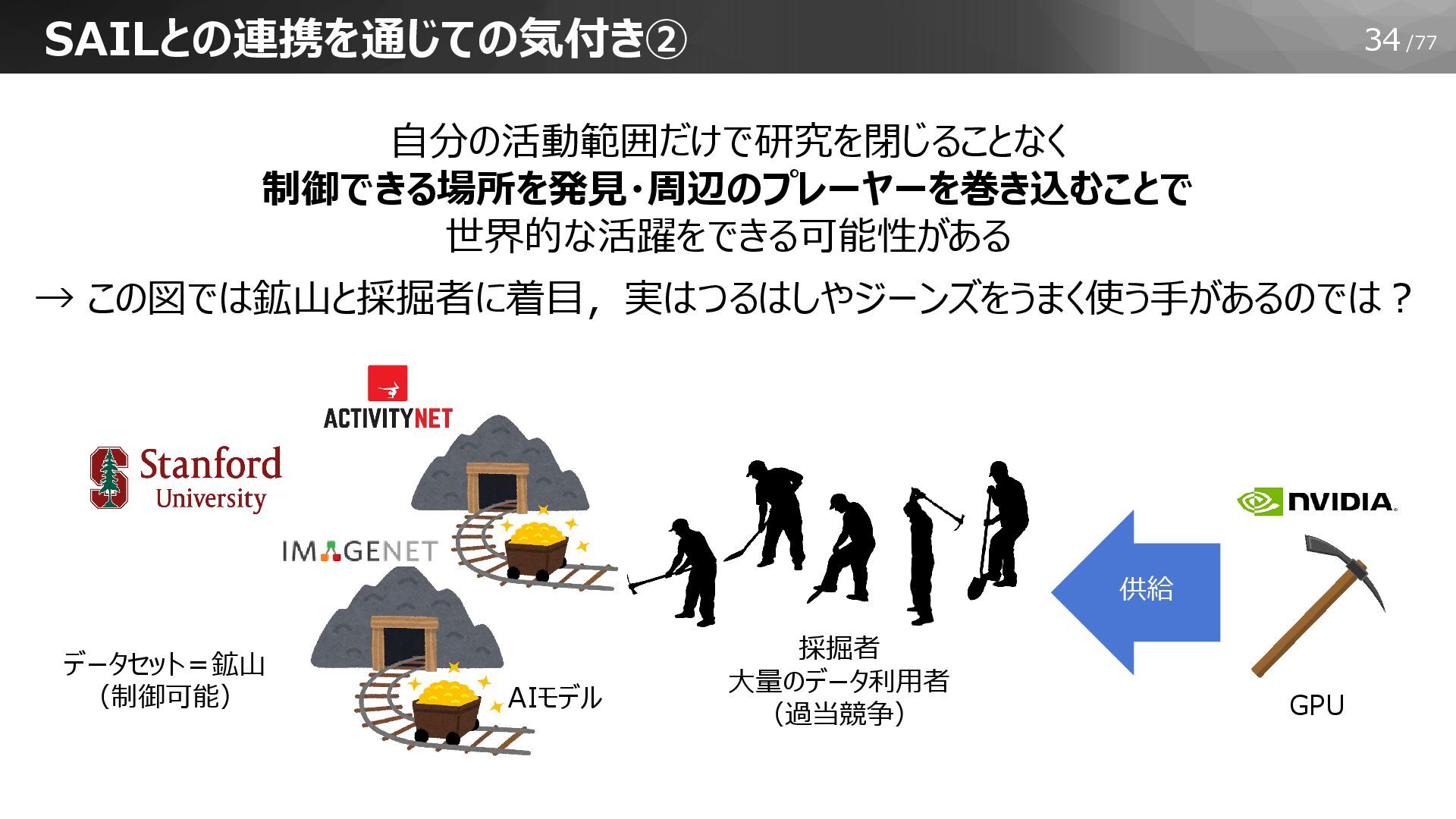
34/77 SAILとの連携を通じての気付き② 採掘者 大量のデータ利用者 (過当競争) AIモデル GPU 供給 自分の活動範囲だけで研究を閉じることなく 制御できる場所を発見・周辺のプレーヤーを巻き込むことで
世界的な活躍をできる可能性がある → この図では鉱山と採掘者に着目,実はつるはしやジーンズをうまく使う手があるのでは? データセット=鉱山 (制御可能)
UC Berkeleyとの連携と 基盤モデル開発
36/77 UC Berkeleyとの連携 350名以上の研究者が所属する世界トップクラスの人工知能研究機関 パナソニックは産学連携プログラムBAIRオープンリサーチコモンズに参画 Kurt Keutzer 軽量アルゴリズムの 世界トップ研究者 Trevor
Darrell 画像認識の 世界トップ研究者 引用:Berkeley Artificial Intelligence Research (BAIR)
37/77 産学連携プログラム BAIR Commons パナソニックHDはUC Berkeleyの産学連携プログラム BAIRオープンリサーチコモンズ(BAIR Commons)に参画 → BAIR参画企業で開発した資産を参画企業でシェアする仕組み
(BMW, Bosch, Electronic Arts, Google, Meta, Panasonic, Picsart, Samsung, Sony, …) 自社以外の企業の開発資産にもアクセス可能(AIの使い方が他の参画企業と異なるパナソニックにとっては有利な仕組み)
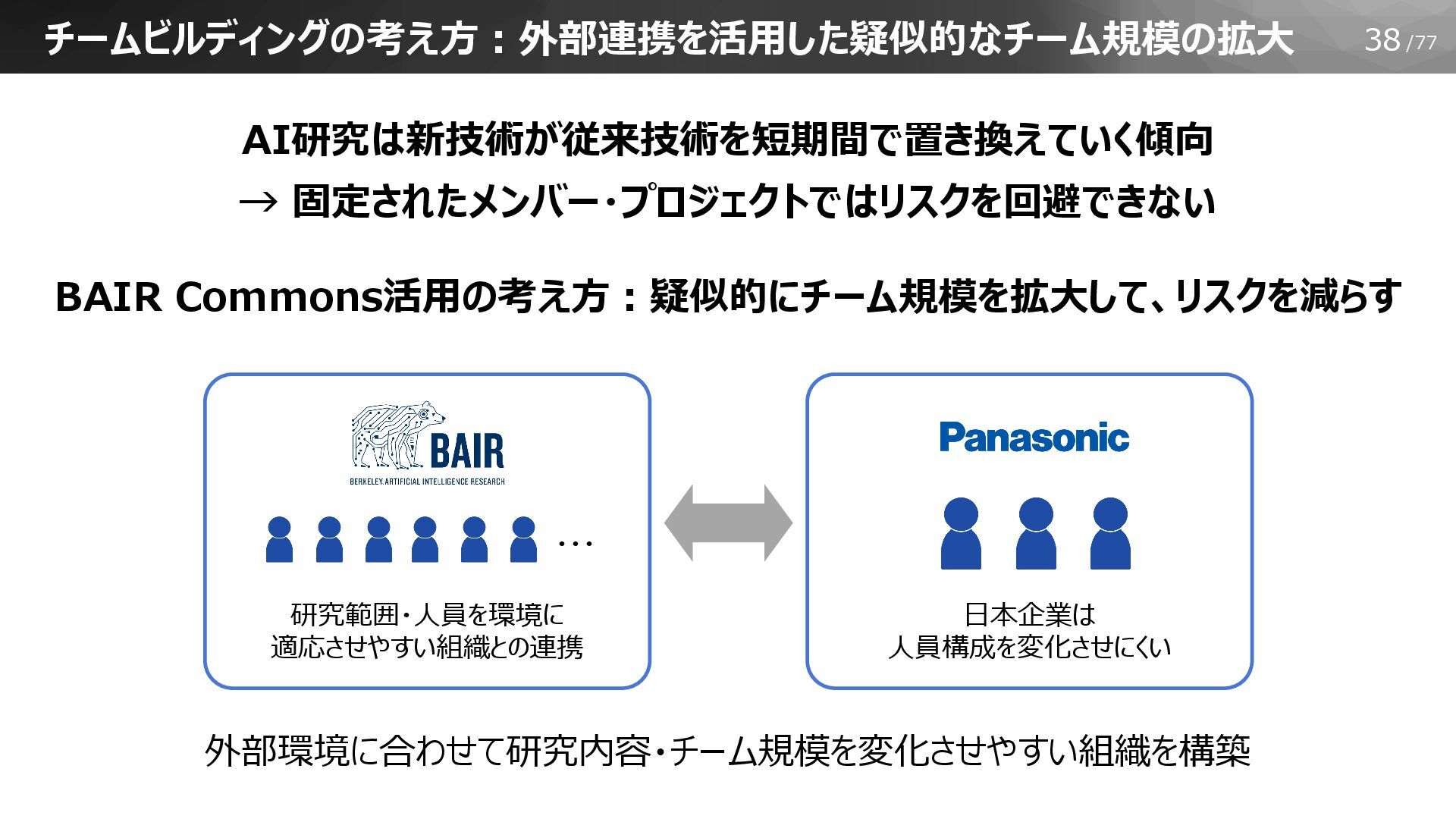
38/77 AI研究は新技術が従来技術を短期間で置き換えていく傾向 → 固定されたメンバー・プロジェクトではリスクを回避できない BAIR Commons活用の考え方:疑似的にチーム規模を拡大して、リスクを減らす チームビルディングの考え方:外部連携を活用した疑似的なチーム規模の拡大 外部環境に合わせて研究内容・チーム規模を変化させやすい組織を構築 日本企業は 人員構成を変化させにくい
研究範囲・人員を環境に 適応させやすい組織との連携 ・・・
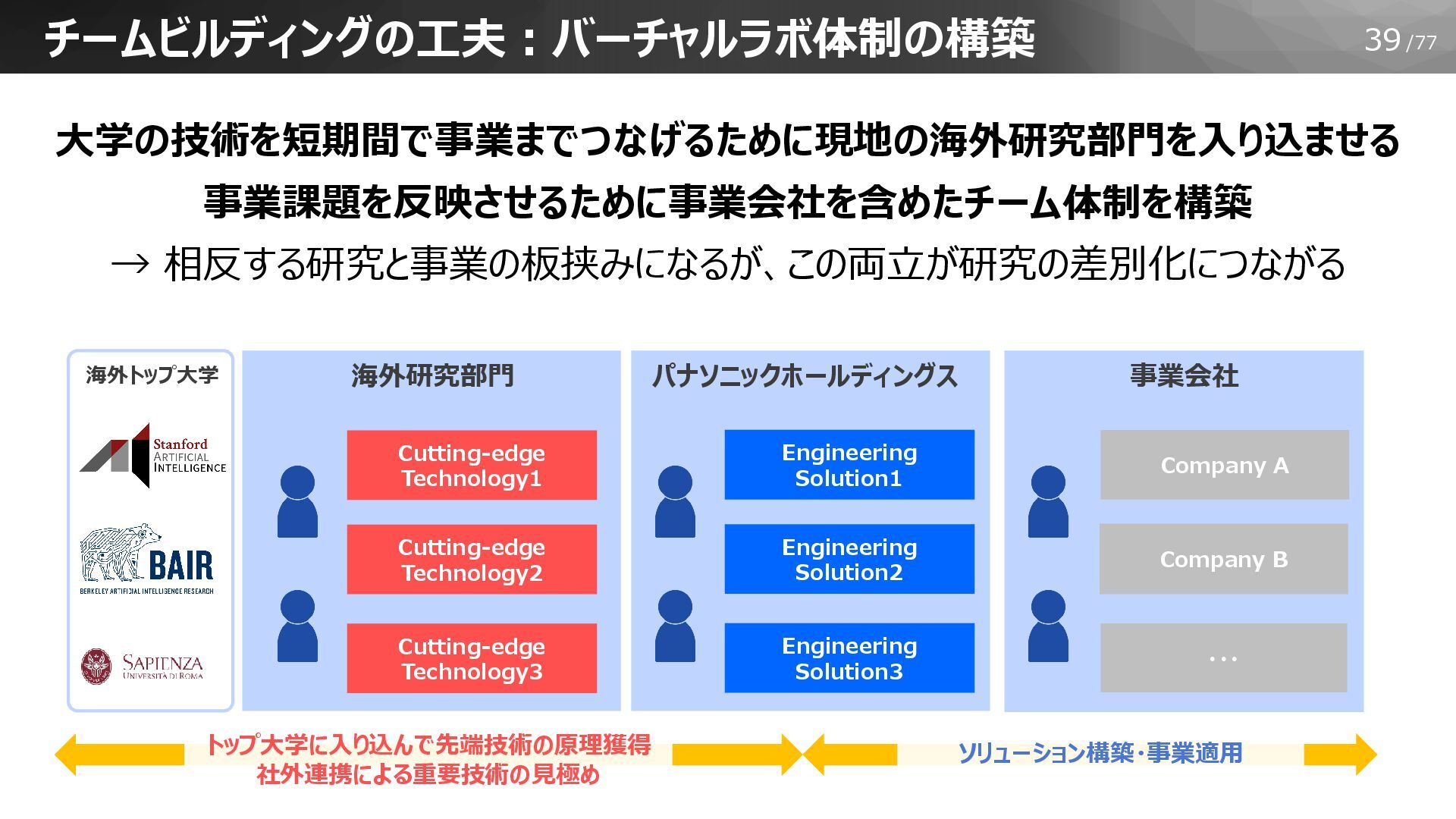
39/77 チームビルディングの工夫:バーチャルラボ体制の構築 海外研究部門 パナソニックホールディングス 事業会社 Company A Company B ・・・
Engineering Solution1 Engineering Solution2 Engineering Solution3 トップ大学に入り込んで先端技術の原理獲得 社外連携による重要技術の見極め ソリューション構築・事業適用 海外トップ大学 Cutting-edge Technology1 Cutting-edge Technology2 Cutting-edge Technology3 大学の技術を短期間で事業までつなげるために現地の海外研究部門を入り込ませる 事業課題を反映させるために事業会社を含めたチーム体制を構築 → 相反する研究と事業の板挟みになるが、この両立が研究の差別化につながる
40/77 PanasonicのAI活用における特徴と課題 パナソニックグループのAIの特徴:とにかく幅広い事業 x リアルな空間での適用 → AIにとっては適用しにくい条件になりやすい 理由:現場ごとのデータ構築・チューニングの手間がかかりスケールしにくい
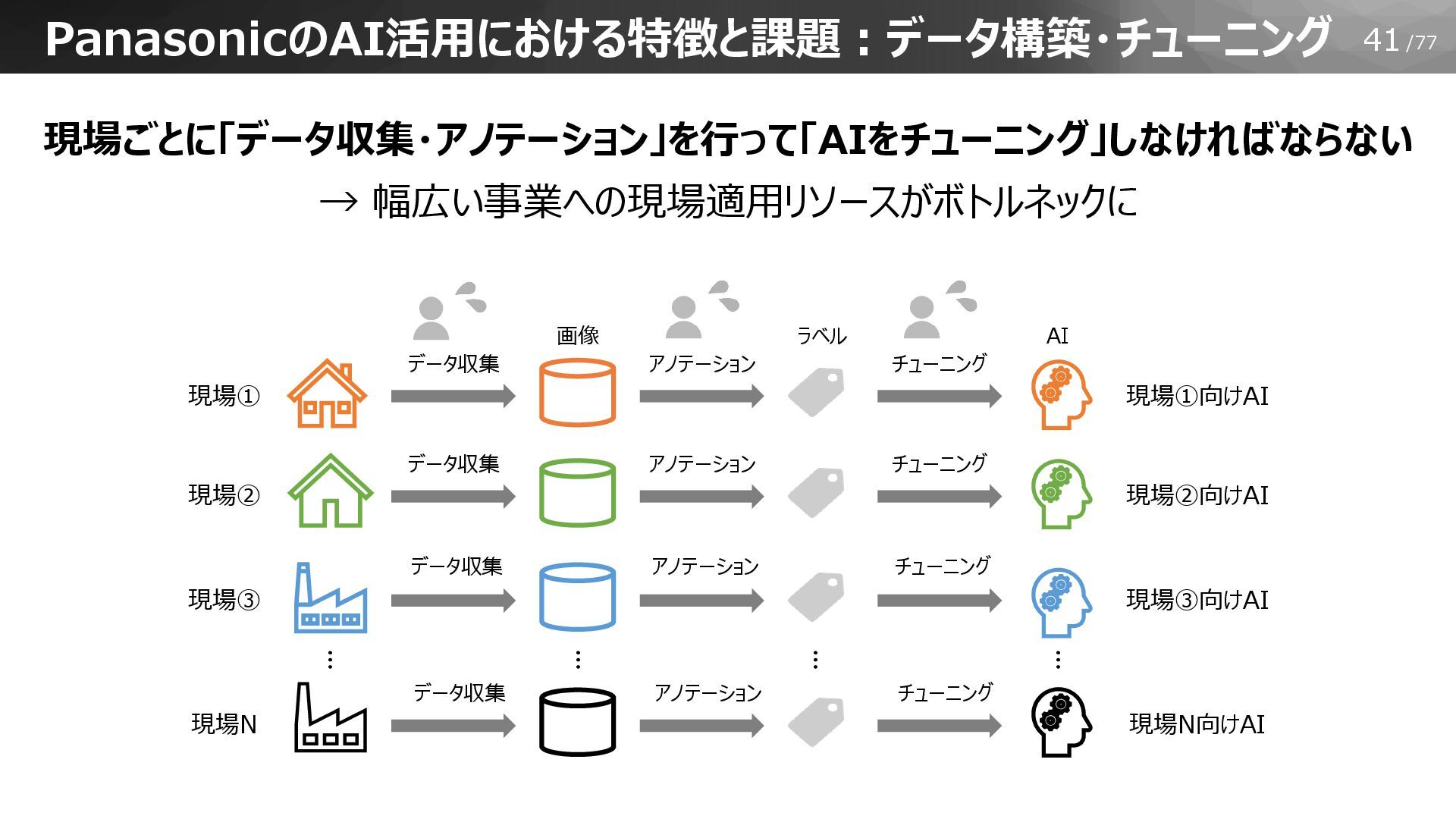
41/77 PanasonicのAI活用における特徴と課題:データ構築・チューニング 現場ごとに「データ収集・アノテーション」を行って「AIをチューニング」しなければならない → 幅広い事業への現場適用リソースがボトルネックに … アノテーション チューニング アノテーション チューニング
アノテーション チューニング アノテーション チューニング 現場①向けAI 現場① 現場②向けAI 現場② 現場③向けAI 現場③ 現場N向けAI 現場N 画像 ラベル データ収集 データ収集 データ収集 データ収集 … … … AI
42/77 解決に向けた注力技術:基盤モデル 大量かつ多様なデータで訓練され,多様な用途におけるタスクに適応できるモデル 例:ChatGPTで使用されている「GPT-4」は自然言語領域の基盤モデル R. Bommasani et al., “On the
Opportunities and Risks of Foundation Models”, arXiv: 2108.07258v3, 2021.
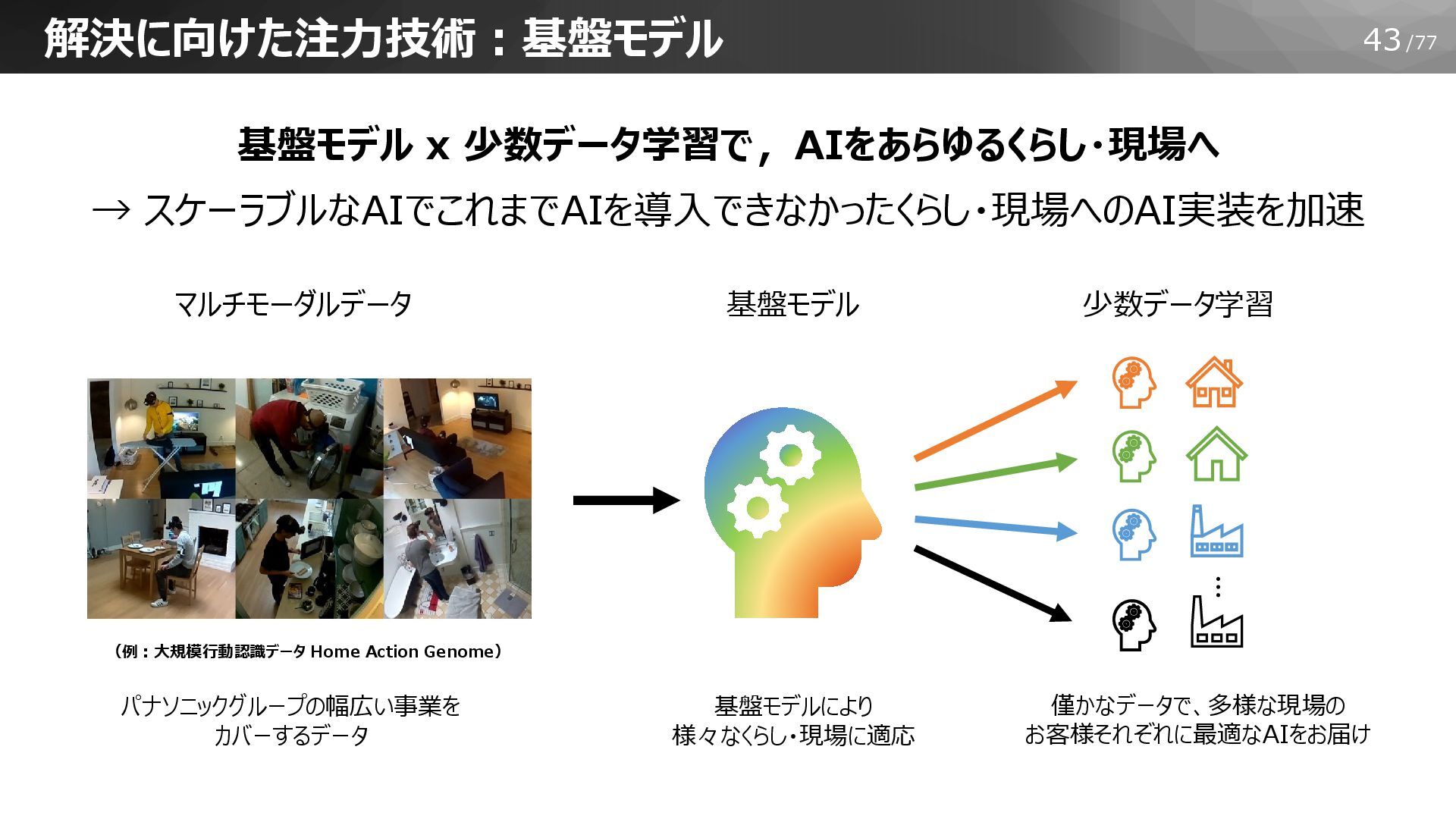
43/77 解決に向けた注力技術:基盤モデル 少数データ学習 基盤モデル マルチモーダルデータ … 僅かなデータで、多様な現場の お客様それぞれに最適なAIをお届け 基盤モデルにより 様々なくらし・現場に適応
パナソニックグループの幅広い事業を カバーするデータ (例:大規模行動認識データ Home Action Genome) 基盤モデル x 少数データ学習で,AIをあらゆるくらし・現場へ → スケーラブルなAIでこれまでAIを導入できなかったくらし・現場へのAI実装を加速
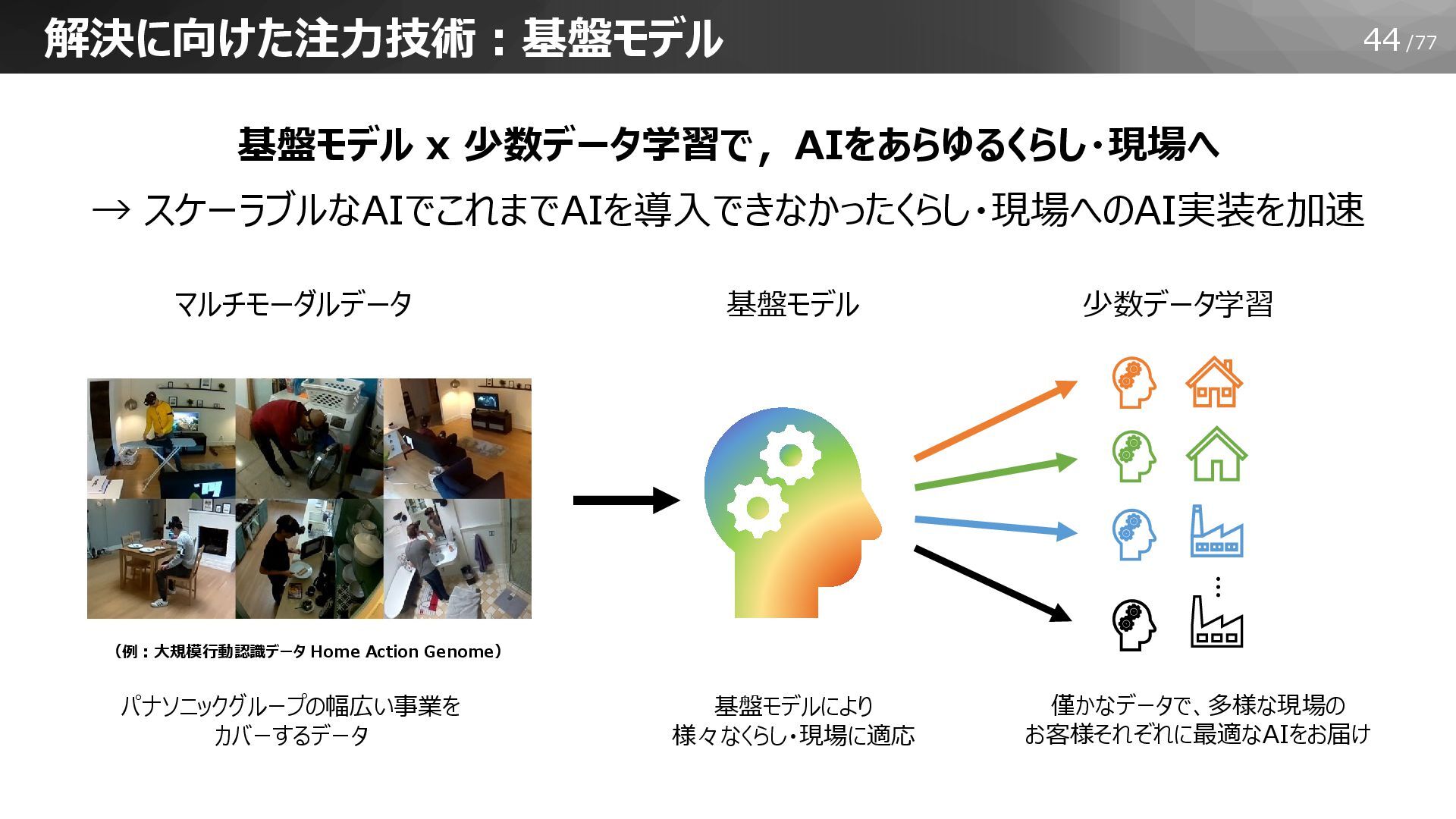
44/77 解決に向けた注力技術:基盤モデル 少数データ学習 基盤モデル マルチモーダルデータ … 僅かなデータで、多様な現場の お客様それぞれに最適なAIをお届け 基盤モデルにより 様々なくらし・現場に適応
パナソニックグループの幅広い事業を カバーするデータ (例:大規模行動認識データ Home Action Genome) 基盤モデル x 少数データ学習で,AIをあらゆるくらし・現場へ → スケーラブルなAIでこれまでAIを導入できなかったくらし・現場へのAI実装を加速
45/77 UC Berkeleyと連携して開発した技術:HIPIE HIPIE: Hierarchical Open-vocabulary Universal Image Segmentation テキスト入力で任意の階層の
画像認識やセグメンテーションを行える汎用基盤モデル
46/77 UC Berkeleyと連携して開発した技術:HIPIE HIPIE: Hierarchical Open-vocabulary Universal Image Segmentation テキスト入力で任意の階層の
画像認識やセグメンテーションを行える汎用基盤モデル
47/77 UC Berkeleyと連携して開発した技術:HIPIE HIPIE: Hierarchical Open-vocabulary Universal Image Segmentation テキスト入力で任意の階層の
画像認識やセグメンテーションを行える汎用基盤モデル
48/77 UC Berkeleyと連携して開発した技術:HIPIE HIPIE: Hierarchical Open-vocabulary Universal Image Segmentation テキスト入力で任意の階層の
画像認識やセグメンテーションを行える汎用基盤モデル
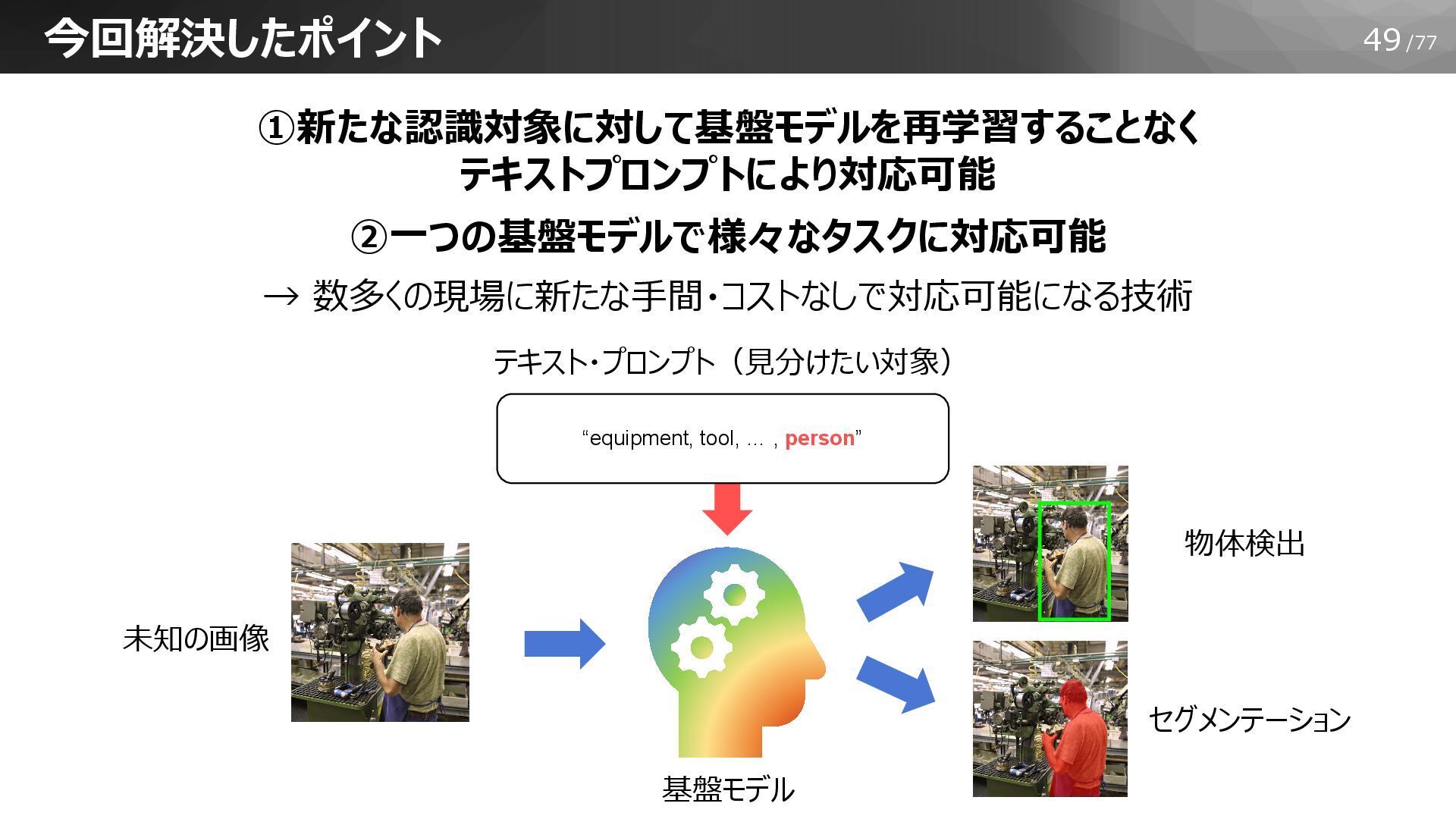
49/77 ①新たな認識対象に対して基盤モデルを再学習することなく テキストプロンプトにより対応可能 ②一つの基盤モデルで様々なタスクに対応可能 → 数多くの現場に新たな手間・コストなしで対応可能になる技術 今回解決したポイント 基盤モデル 未知の画像 物体検出
セグメンテーション “equipment, tool, … , person” テキスト・プロンプト(見分けたい対象)
50/77 HIPIEはどんなことに使える? ①現場で取り扱う物品,新商品による認識対象の変化に対して テキストプロンプトを追加するだけで認識可能になる ②物体名ではない曖昧な対象に対してもテキストプロンプトで認識対象にすることが可能 基盤モデル 環境が変化 ・新たな工場 ・部品の更新 “equipment,
tool, … , conveyor” テキスト・プロンプト(見分けたい対象) 基盤モデル 黄色い 服装の人を カウントしたい “equipment, tool, … , person wearing yellow jacket” テキスト・プロンプト(見分けたい対象) → 新たな環境で見分けたいものを再学習なしで追加 → データ構築時にはクラスを定義しにくい詳細な対象
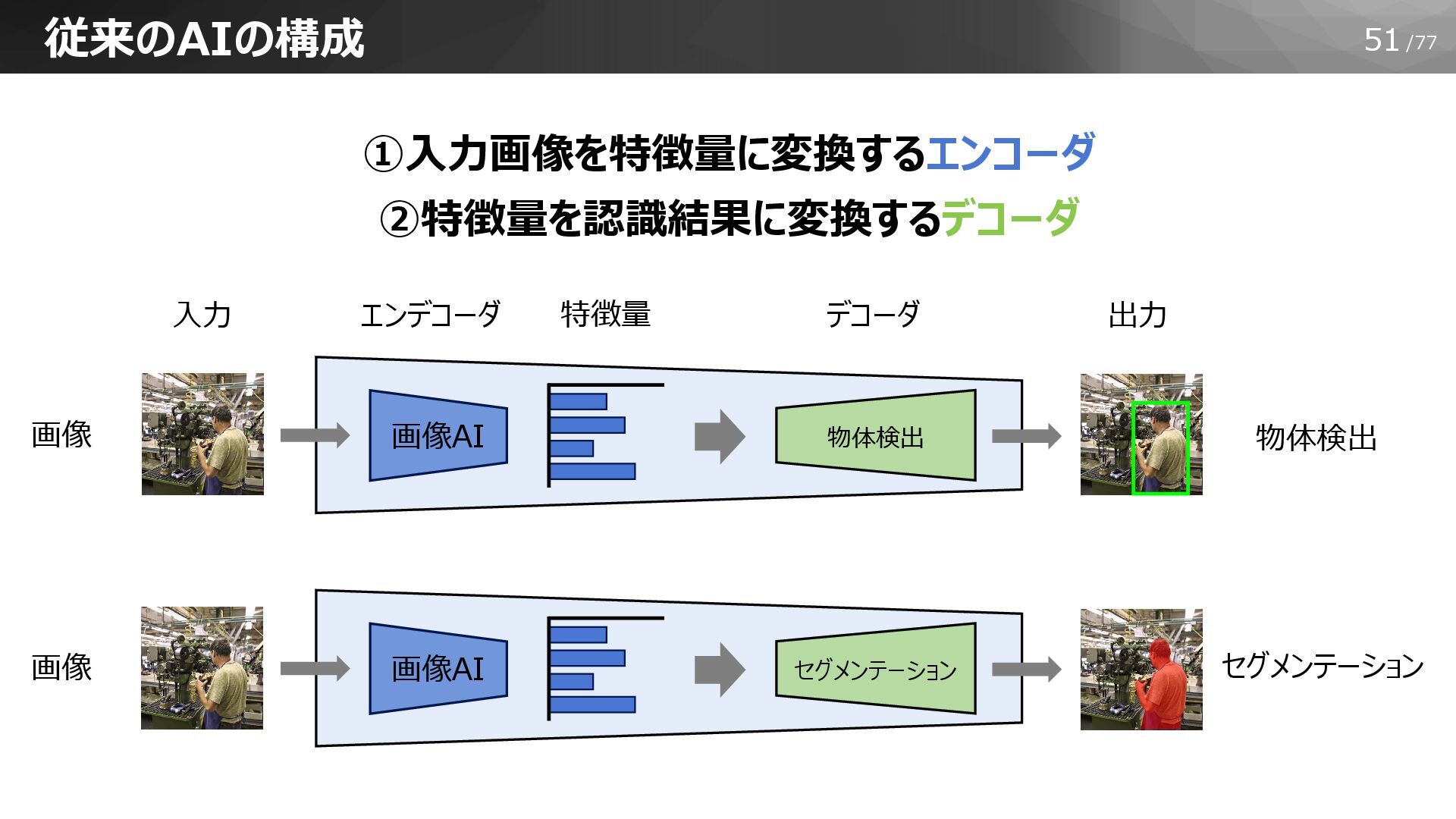
51/77 従来のAIの構成 画像AI 物体検出 セグメンテーション 物体検出 デコーダ 画像 画像AI セグメンテーション
画像 エンデコーダ ①入力画像を特徴量に変換するエンコーダ ②特徴量を認識結果に変換するデコーダ 出力 入力 特徴量
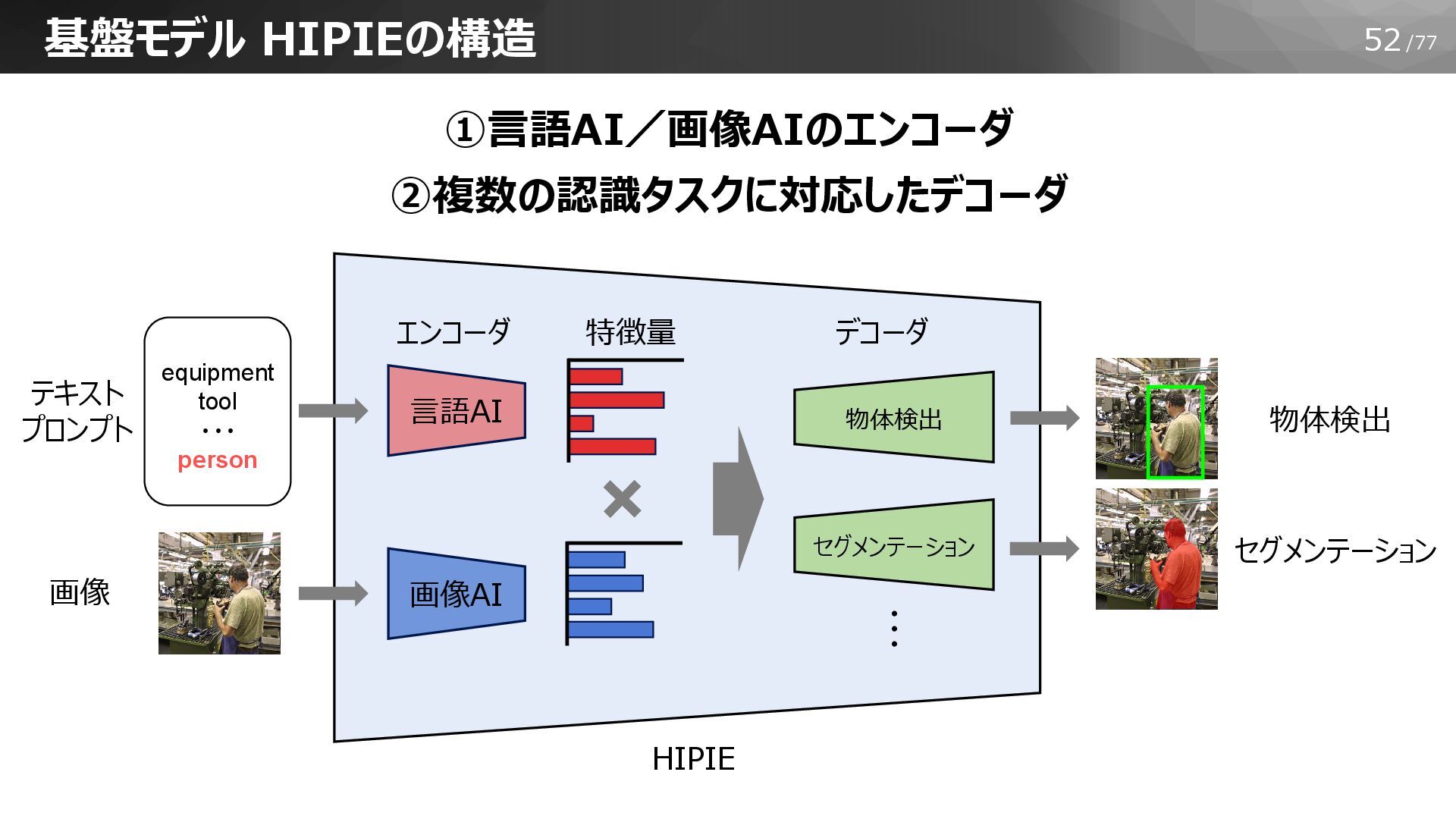
52/77 基盤モデル HIPIEの構造 特徴量 画像AI 言語AI 物体検出 セグメンテーション HIPIE ①言語AI/画像AIのエンコーダ
②複数の認識タスクに対応したデコーダ 物体検出 セグメンテーション エンコーダ デコーダ テキスト プロンプト 画像 ・・・ equipment tool ・・・ person
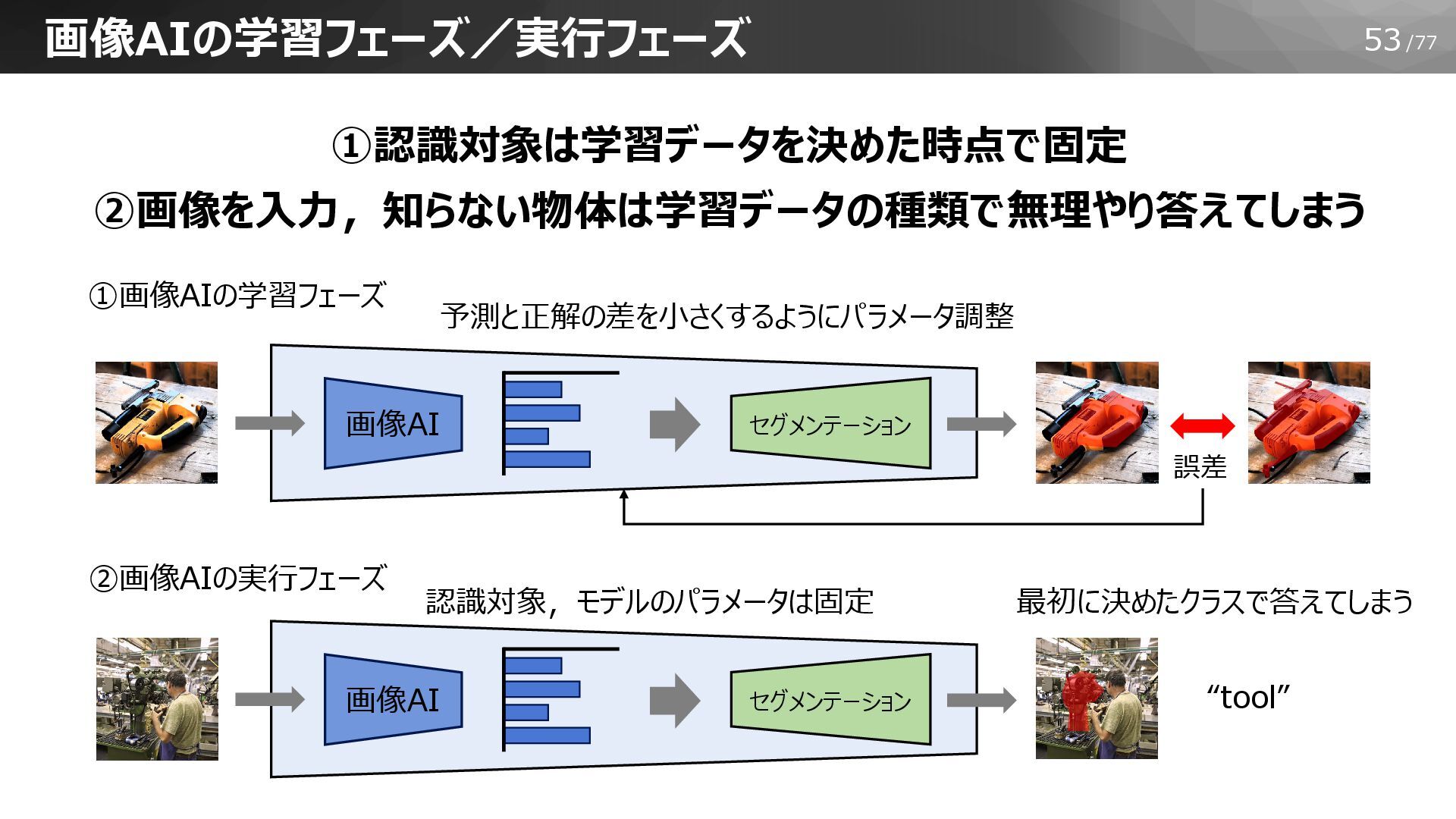
53/77 画像AIの学習フェーズ/実行フェーズ 予測と正解の差を小さくするようにパラメータ調整 画像AI セグメンテーション 画像AI セグメンテーション ①認識対象は学習データを決めた時点で固定 ②画像を入力,知らない物体は学習データの種類で無理やり答えてしまう ①画像AIの学習フェーズ
②画像AIの実行フェーズ 最初に決めたクラスで答えてしまう “tool” 誤差 認識対象,モデルのパラメータは固定
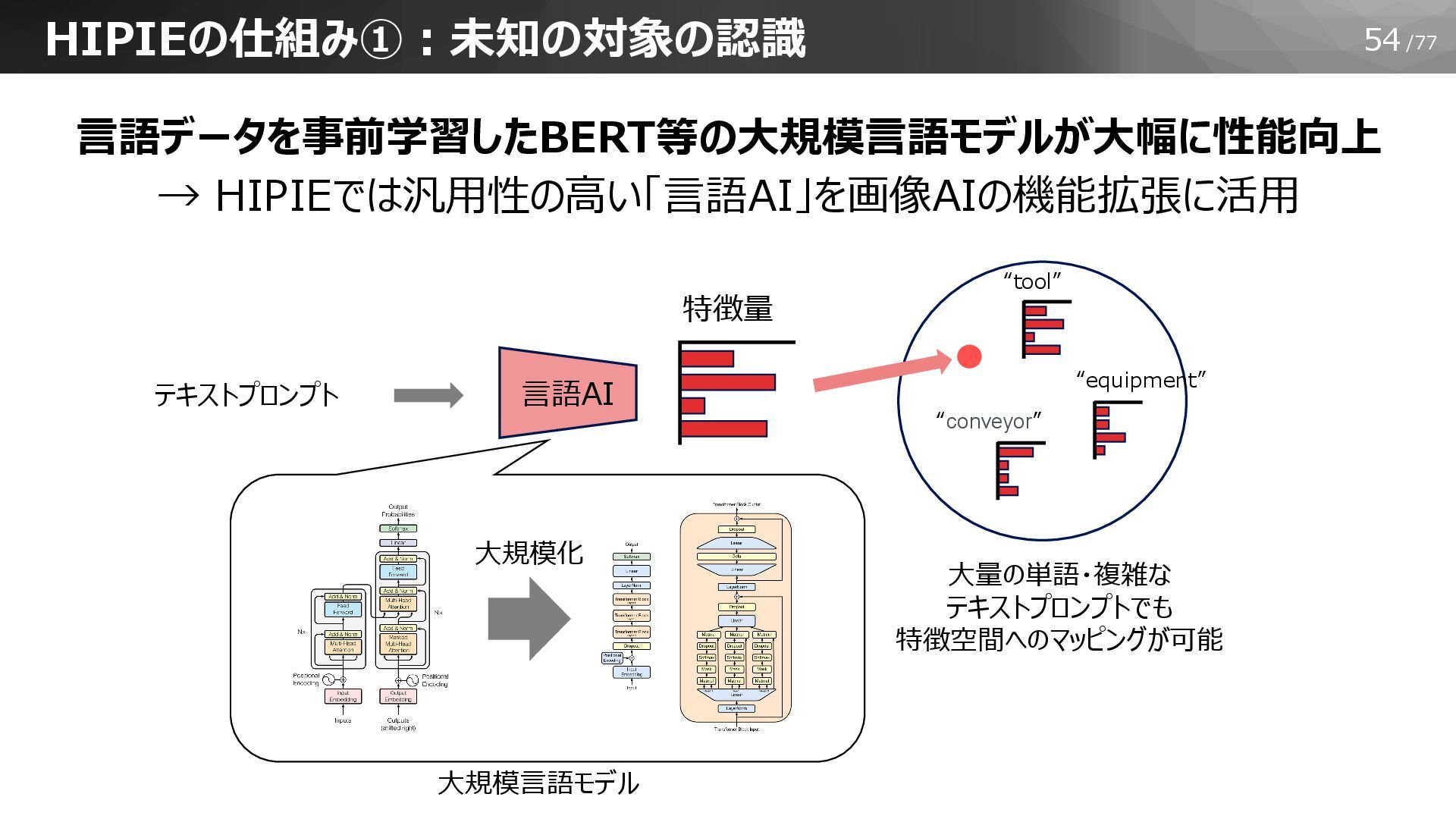
54/77 HIPIEの仕組み①:未知の対象の認識 特徴量 言語AI “tool” “equipment” “conveyor” テキストプロンプト 言語データを事前学習したBERT等の大規模言語モデルが大幅に性能向上 →
HIPIEでは汎用性の高い「言語AI」を画像AIの機能拡張に活用 大規模言語モデル 大量の単語・複雑な テキストプロンプトでも 特徴空間へのマッピングが可能 大規模化
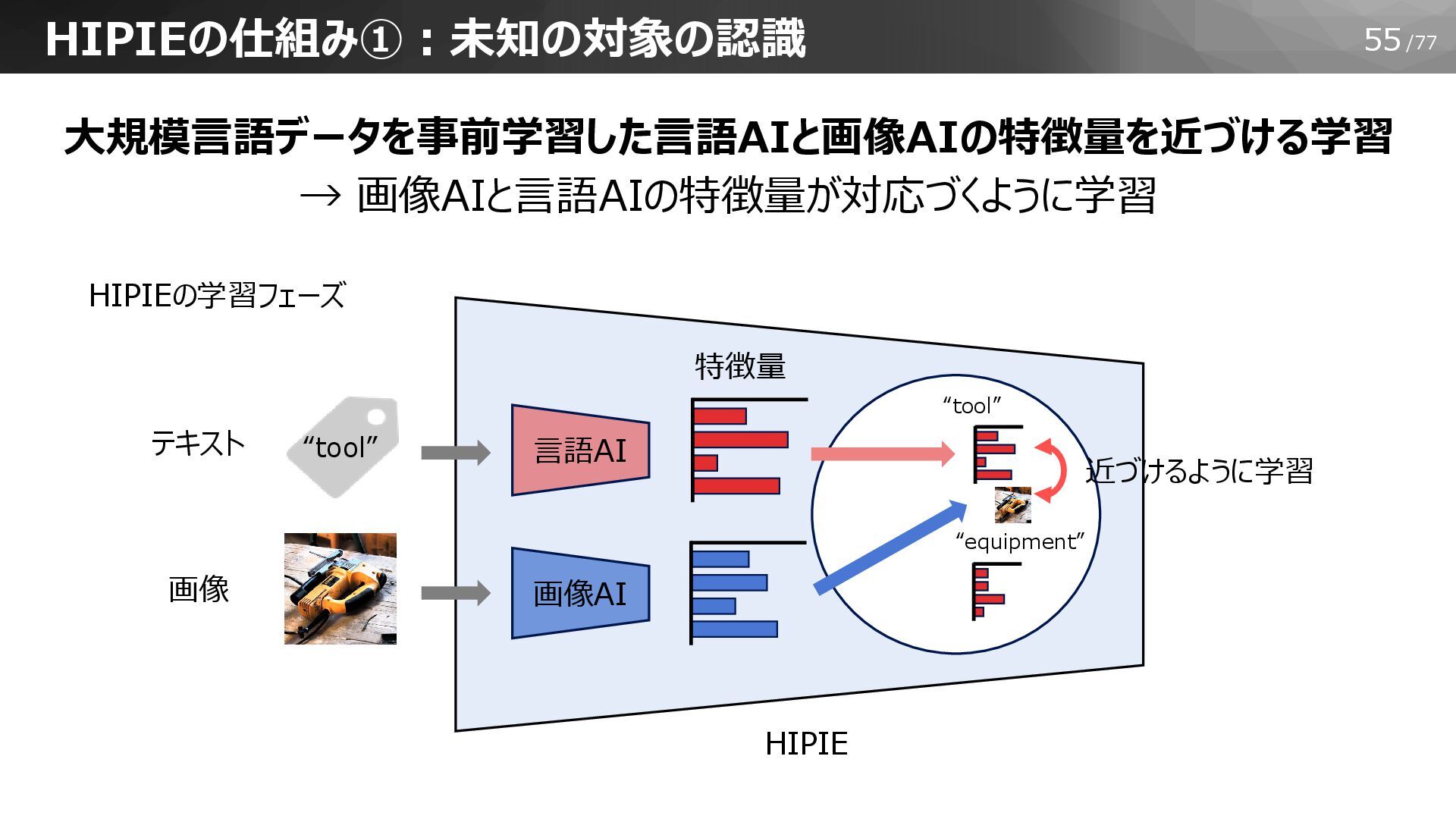
55/77 “tool” “equipment” 画像AI HIPIEの仕組み①:未知の対象の認識 大規模言語データを事前学習した言語AIと画像AIの特徴量を近づける学習 → 画像AIと言語AIの特徴量が対応づくように学習 言語AI “tool”
HIPIEの学習フェーズ 近づけるように学習 テキスト 画像 特徴量 HIPIE
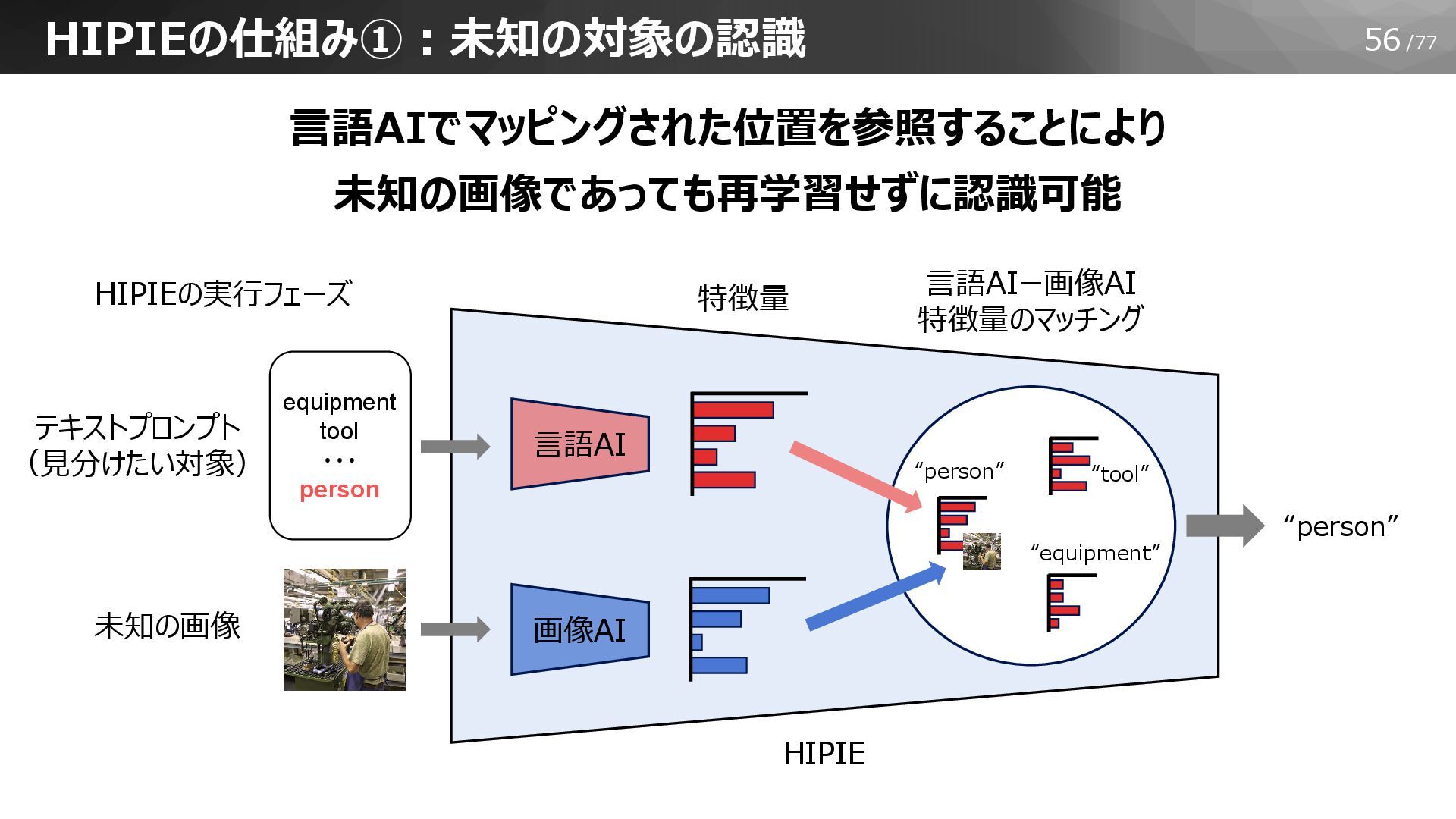
56/77 言語AIでマッピングされた位置を参照することにより 未知の画像であっても再学習せずに認識可能 HIPIEの仕組み①:未知の対象の認識 画像AI 言語AI HIPIEの実行フェーズ 未知の画像 特徴量 HIPIE
“person” “tool” “equipment” “person” 言語AIー画像AI 特徴量のマッチング テキストプロンプト (見分けたい対象) equipment tool ・・・ person
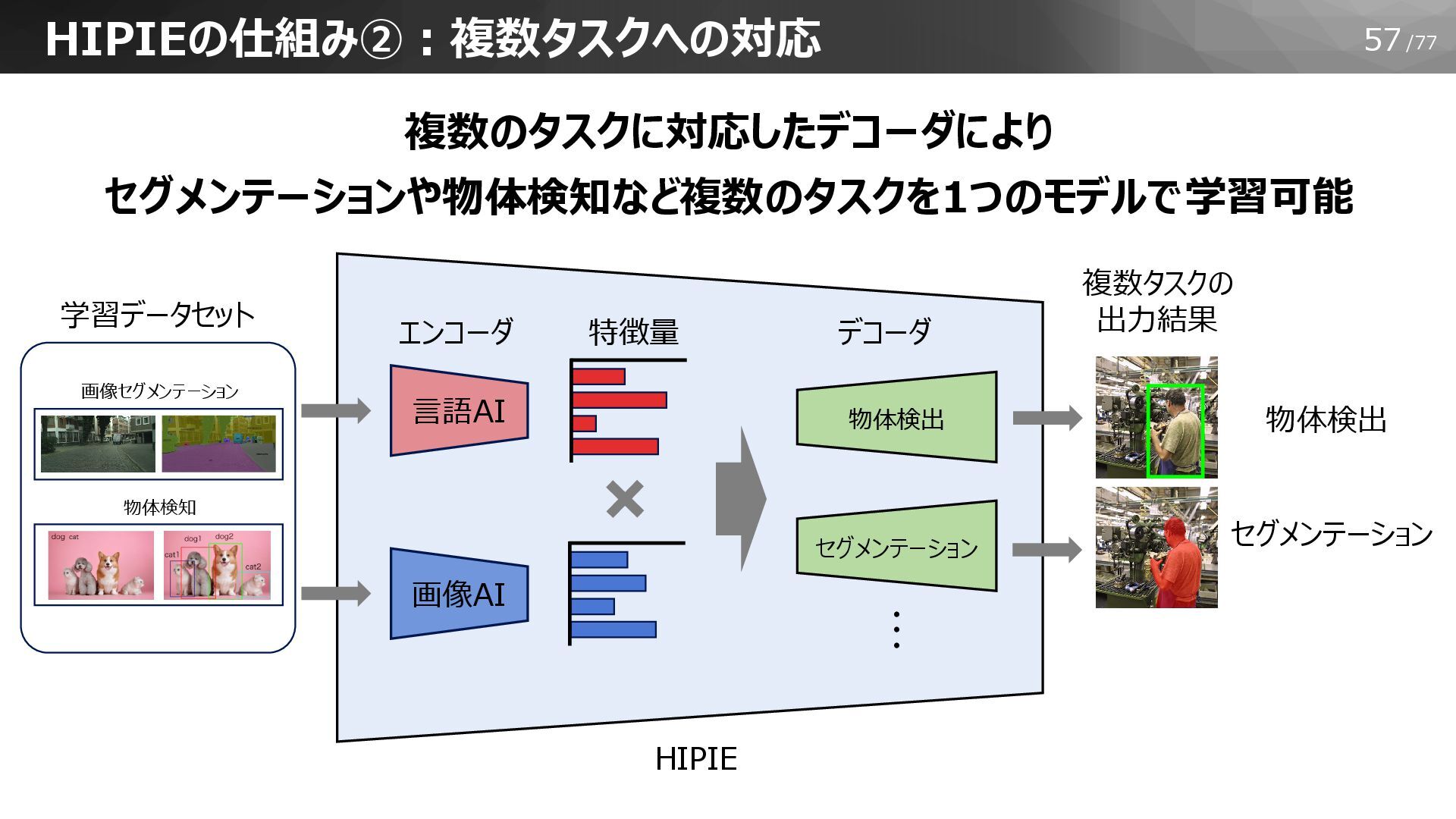
57/77 HIPIEの仕組み②:複数タスクへの対応 特徴量 画像AI 言語AI 物体検出 セグメンテーション HIPIE 複数のタスクに対応したデコーダにより セグメンテーションや物体検知など複数のタスクを1つのモデルで学習可能
物体検出 セグメンテーション エンコーダ デコーダ ・・・ 学習データセット 画像セグメンテーション 物体検知 複数タスクの 出力結果
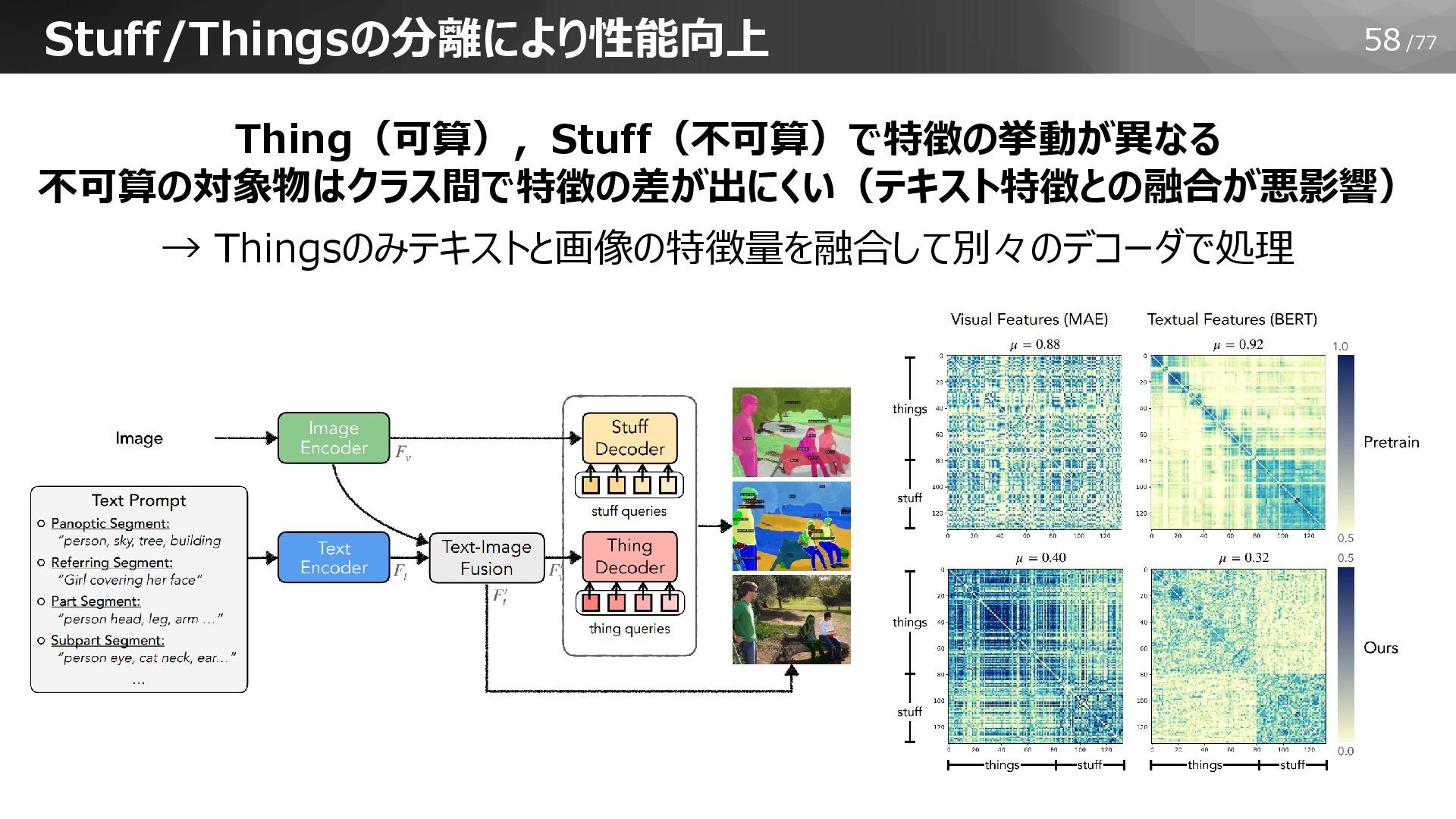
58/77 Thing(可算),Stuff(不可算)で特徴の挙動が異なる 不可算の対象物はクラス間で特徴の差が出にくい(テキスト特徴との融合が悪影響) → Thingsのみテキストと画像の特徴量を融合して別々のデコーダで処理 Stuff/Thingsの分離により性能向上
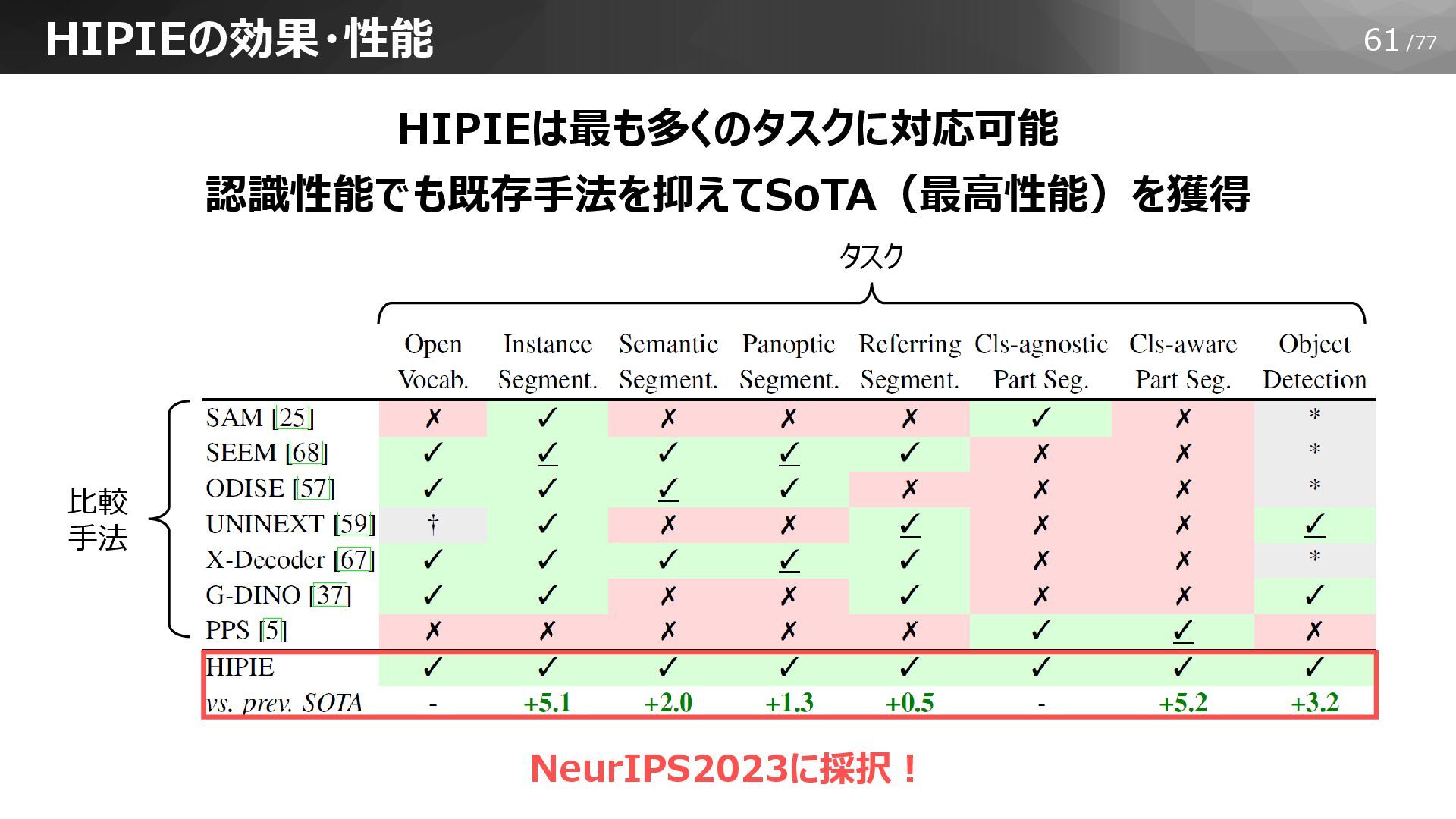
59/77 HIPIEの効果・性能 基盤モデルの効能:一つのモデルで多数のタスクに適用可能 → 全てのセグメンテーションタスクに対応可能できるのはHIPIEのみ Instance Segmentation Semantic Segmentation Panoptic
Segmentation Part Segmentation Reference Segmentation 数えられる対象物 (前景クラス)で構成 数えられない自然対象 (背景クラス)で構成 前景,背景 両方に対応 動物・ヒトの個体毎に 体の各部位をマスク 指示文で 特定個体のみをマスク
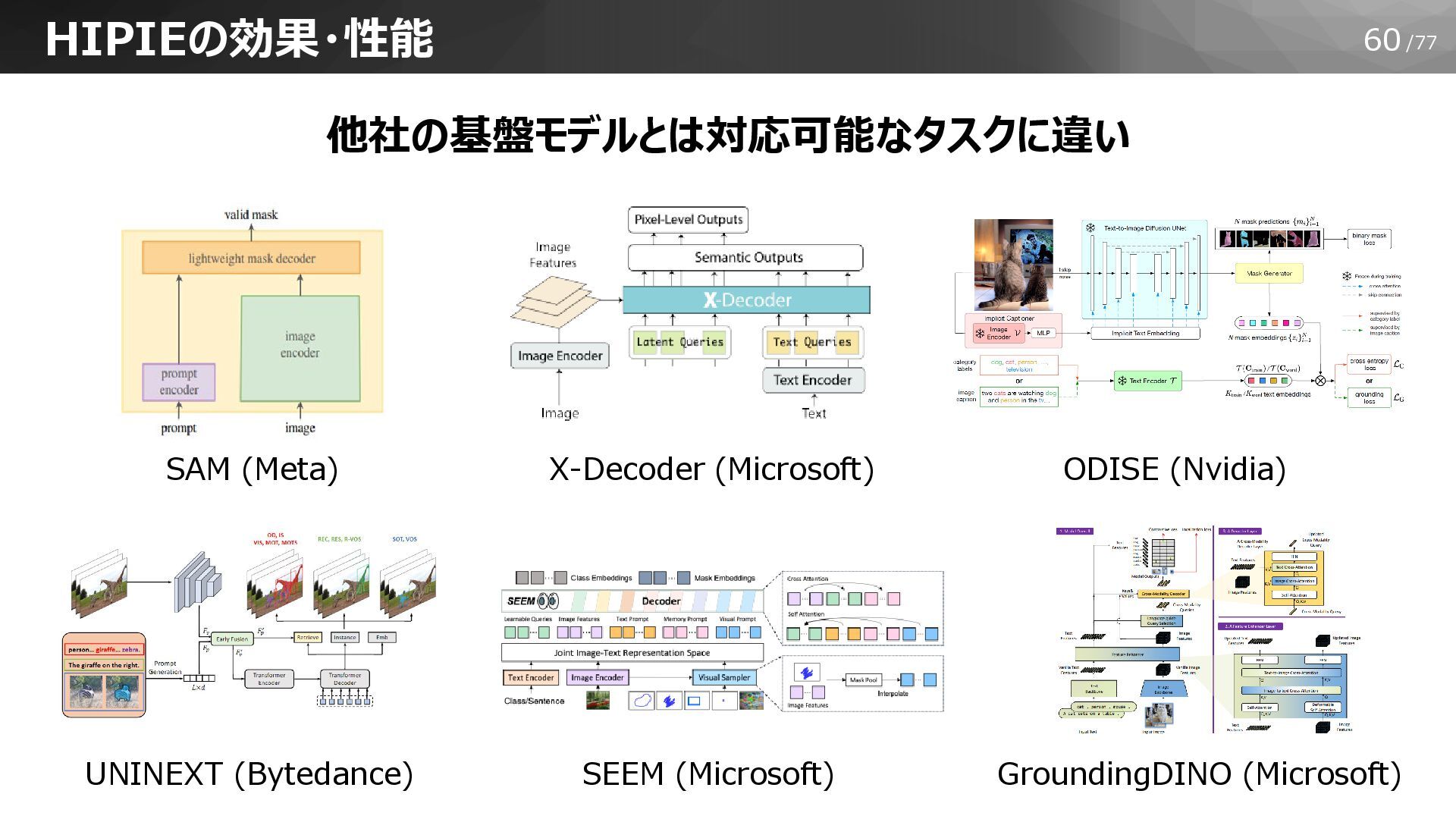
60/77 HIPIEの効果・性能 他社の基盤モデルとは対応可能なタスクに違い SAM (Meta) X-Decoder (Microsoft) ODISE (Nvidia) UNINEXT
(Bytedance) SEEM (Microsoft) GroundingDINO (Microsoft)
61/77 HIPIEの効果・性能 HIPIEは最も多くのタスクに対応可能 認識性能でも既存手法を抑えてSoTA(最高性能)を獲得 NeurIPS2023に採択! タスク 比較 手法
62/77 BAIRとの連携を通じての気付き 基盤モデル開発では,実験バリエーションが重要になるため 疑似的なチーム規模の拡大が有効に働く 基盤モデルは適用先のタスクが多く・評価するデータセットのバリエーションが重視される (HIPIEでは40種類以上のデータセットで評価を実施) データセット構築での連携よりも,役割を分離しにくくなるため連携の難易度は上がる → バーチャルラボ体制による連携先への入り込みと密な連携調整が重要 HIPIE
evaluation on 35 object detection datasets
ストックマーク株式会社との協業による 大規模言語モデルの開発
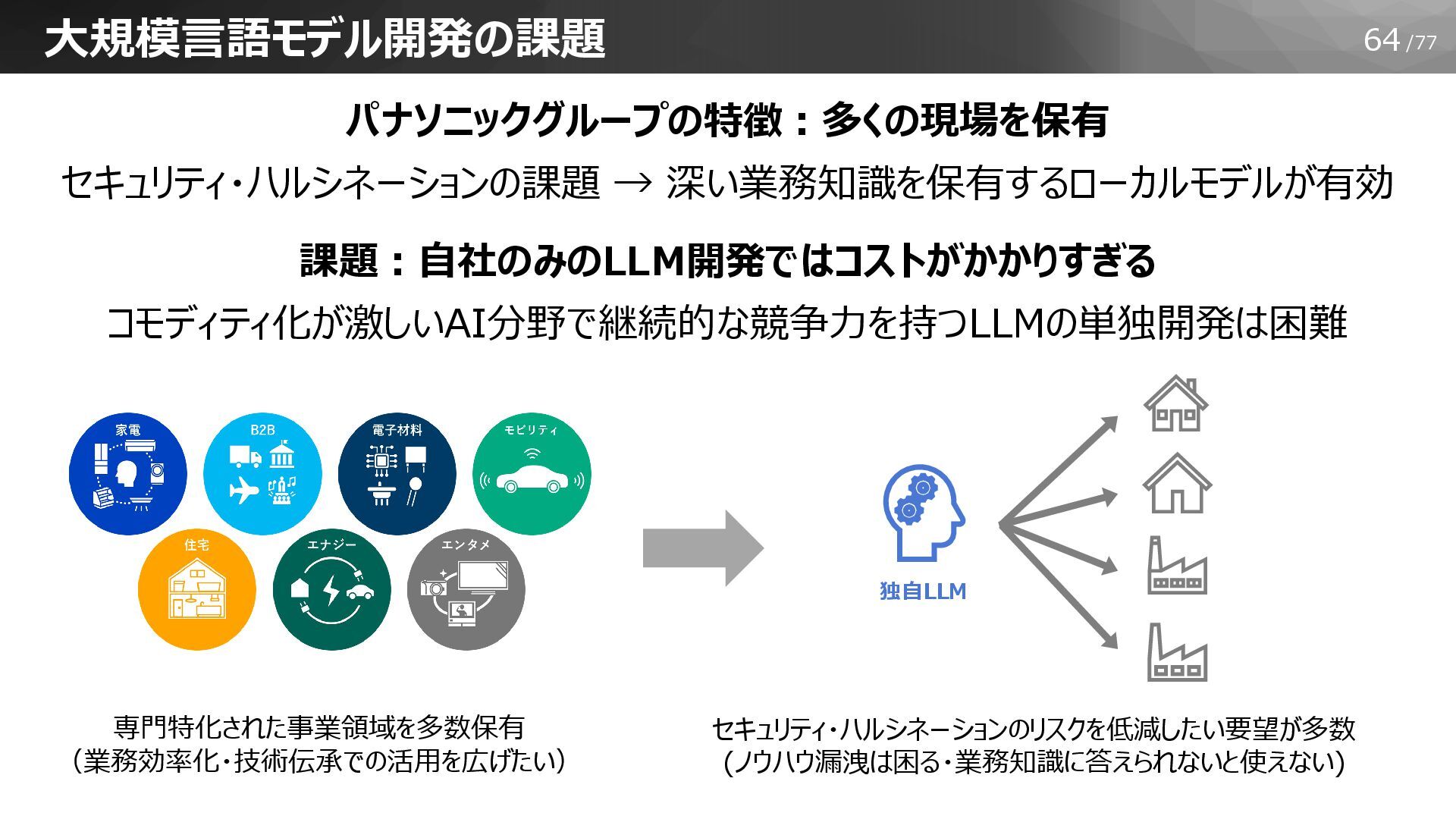
64/77 大規模言語モデル開発の課題 パナソニックグループの特徴:多くの現場を保有 セキュリティ・ハルシネーションの課題 → 深い業務知識を保有するローカルモデルが有効 課題:自社のみのLLM開発ではコストがかかりすぎる コモディティ化が激しいAI分野で継続的な競争力を持つLLMの単独開発は困難 独自LLM 専門特化された事業領域を多数保有
(業務効率化・技術伝承での活用を広げたい) セキュリティ・ハルシネーションのリスクを低減したい要望が多数 (ノウハウ漏洩は困る・業務知識に答えられないと使えない)
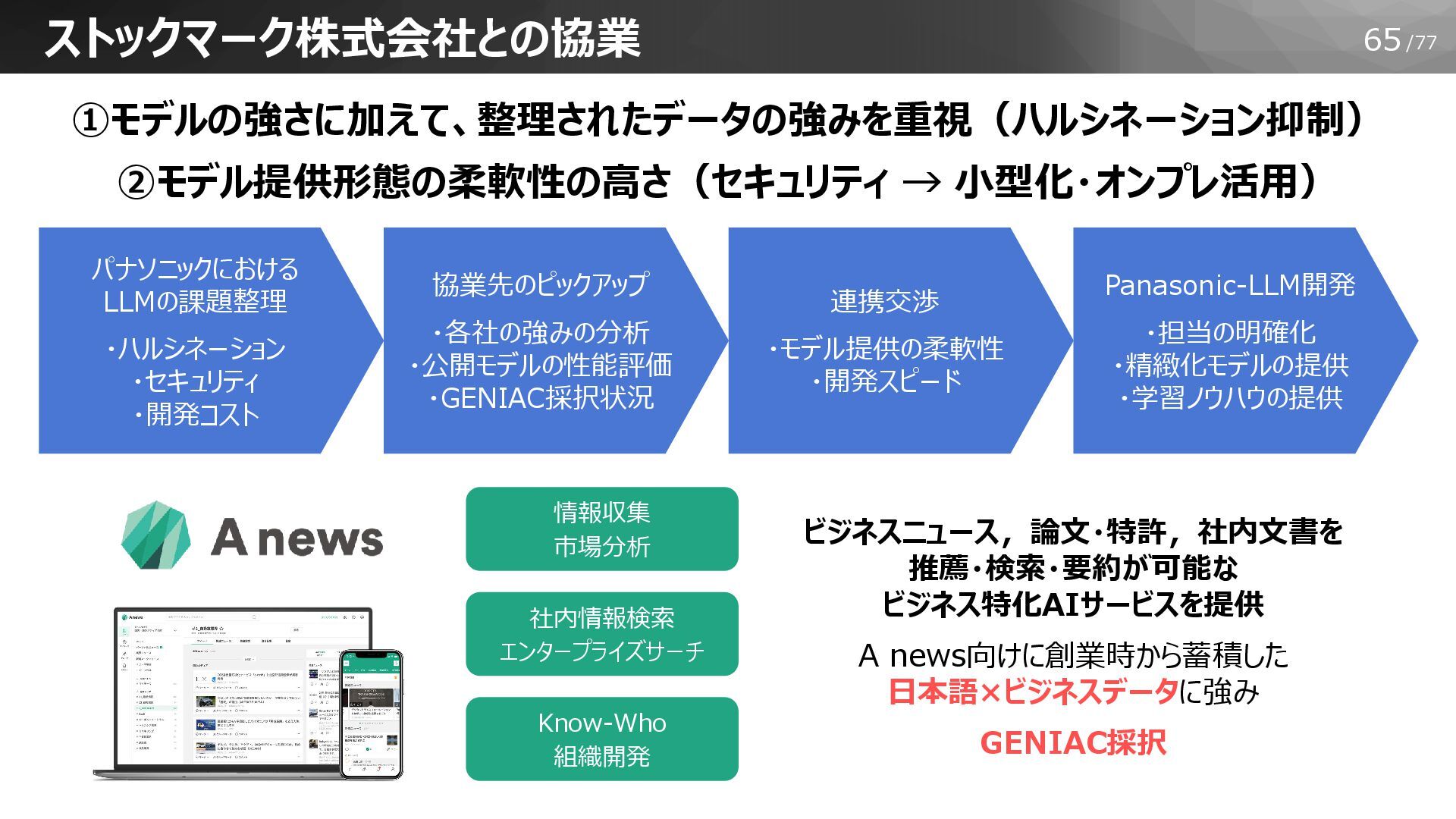
65/77 ストックマーク株式会社との協業 ①モデルの強さに加えて、整理されたデータの強みを重視(ハルシネーション抑制) ②モデル提供形態の柔軟性の高さ(セキュリティ → 小型化・オンプレ活用) パナソニックにおける LLMの課題整理 ・ハルシネーション ・セキュリティ
・開発コスト 協業先のピックアップ ・各社の強みの分析 ・公開モデルの性能評価 ・GENIAC採択状況 連携交渉 ・モデル提供の柔軟性 ・開発スピード Panasonic-LLM開発 ・担当の明確化 ・精緻化モデルの提供 ・学習ノウハウの提供 情報収集 市場分析 社内情報検索 エンタープライズサーチ Know-Who 組織開発 ビジネスニュース,論文・特許,社内文書を 推薦・検索・要約が可能な ビジネス特化AIサービスを提供 A news向けに創業時から蓄積した 日本語×ビジネスデータに強み GENIAC採択
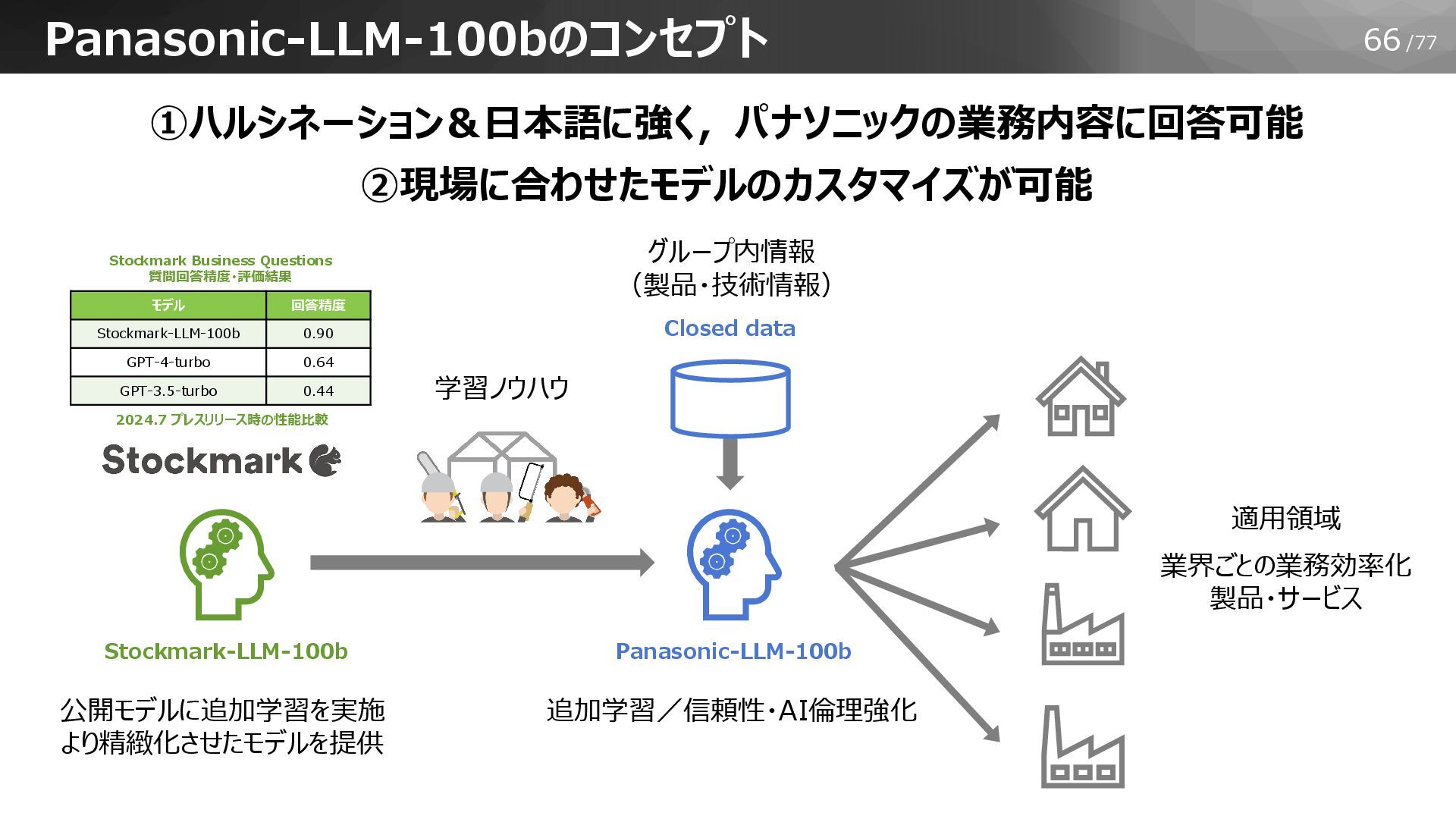
66/77 Panasonic-LLM-100bのコンセプト Stockmark-LLM-100b Panasonic-LLM-100b Closed data ①ハルシネーション&日本語に強く,パナソニックの業務内容に回答可能 ②現場に合わせたモデルのカスタマイズが可能 グループ内情報 (製品・技術情報)
公開モデルに追加学習を実施 より精緻化させたモデルを提供 追加学習/信頼性・AI倫理強化 適用領域 業界ごとの業務効率化 製品・サービス 学習ノウハウ モデル 回答精度 Stockmark-LLM-100b 0.90 GPT-4-turbo 0.64 GPT-3.5-turbo 0.44 Stockmark Business Questions 質問回答精度・評価結果 2024.7 プレスリリース時の性能比較
67/77
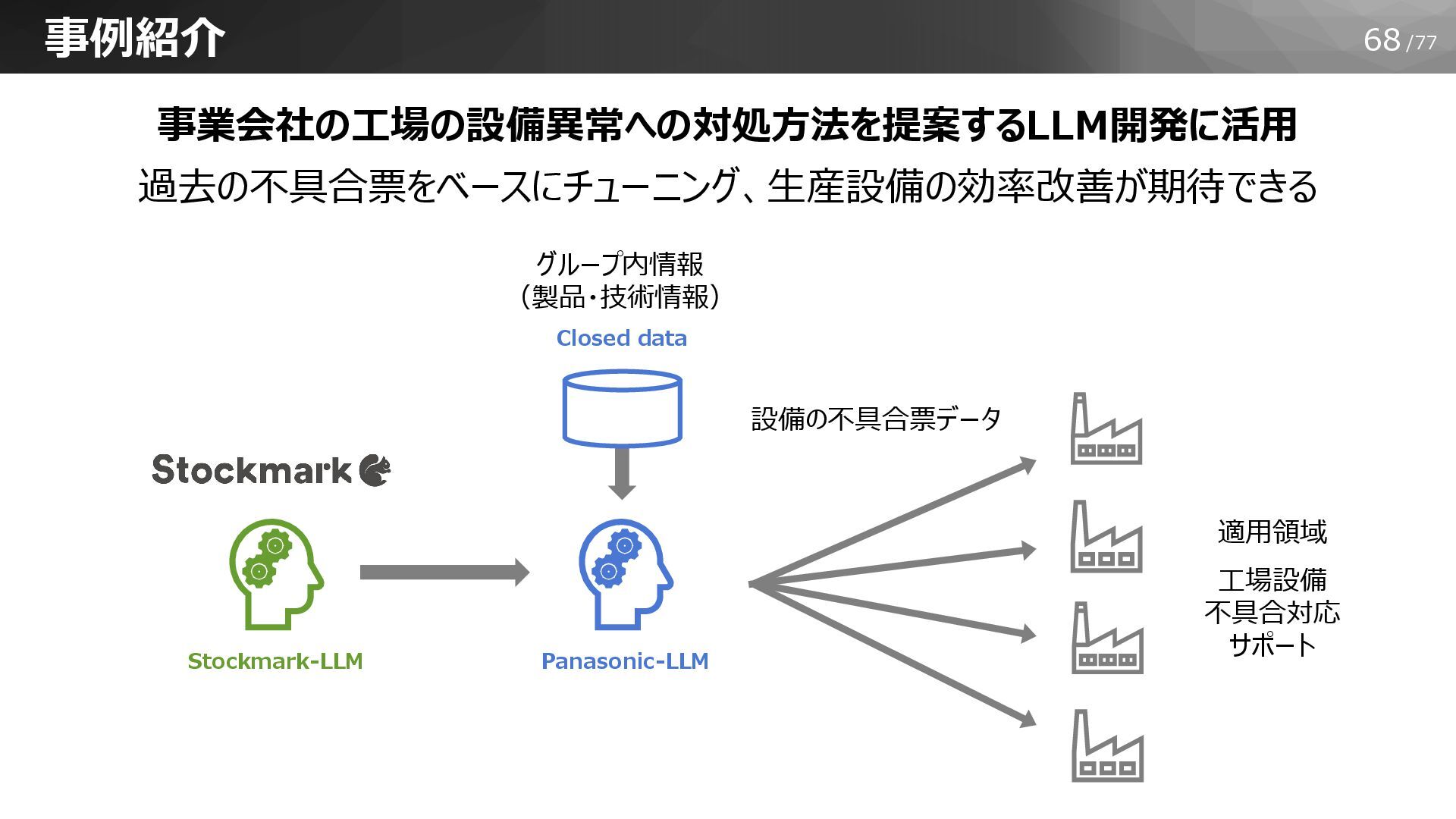
68/77 事業会社の工場の設備異常への対処方法を提案するLLM開発に活用 過去の不具合票をベースにチューニング、生産設備の効率改善が期待できる 事例紹介 Stockmark-LLM Panasonic-LLM Closed data グループ内情報 (製品・技術情報)
適用領域 工場設備 不具合対応 サポート 設備の不具合票データ
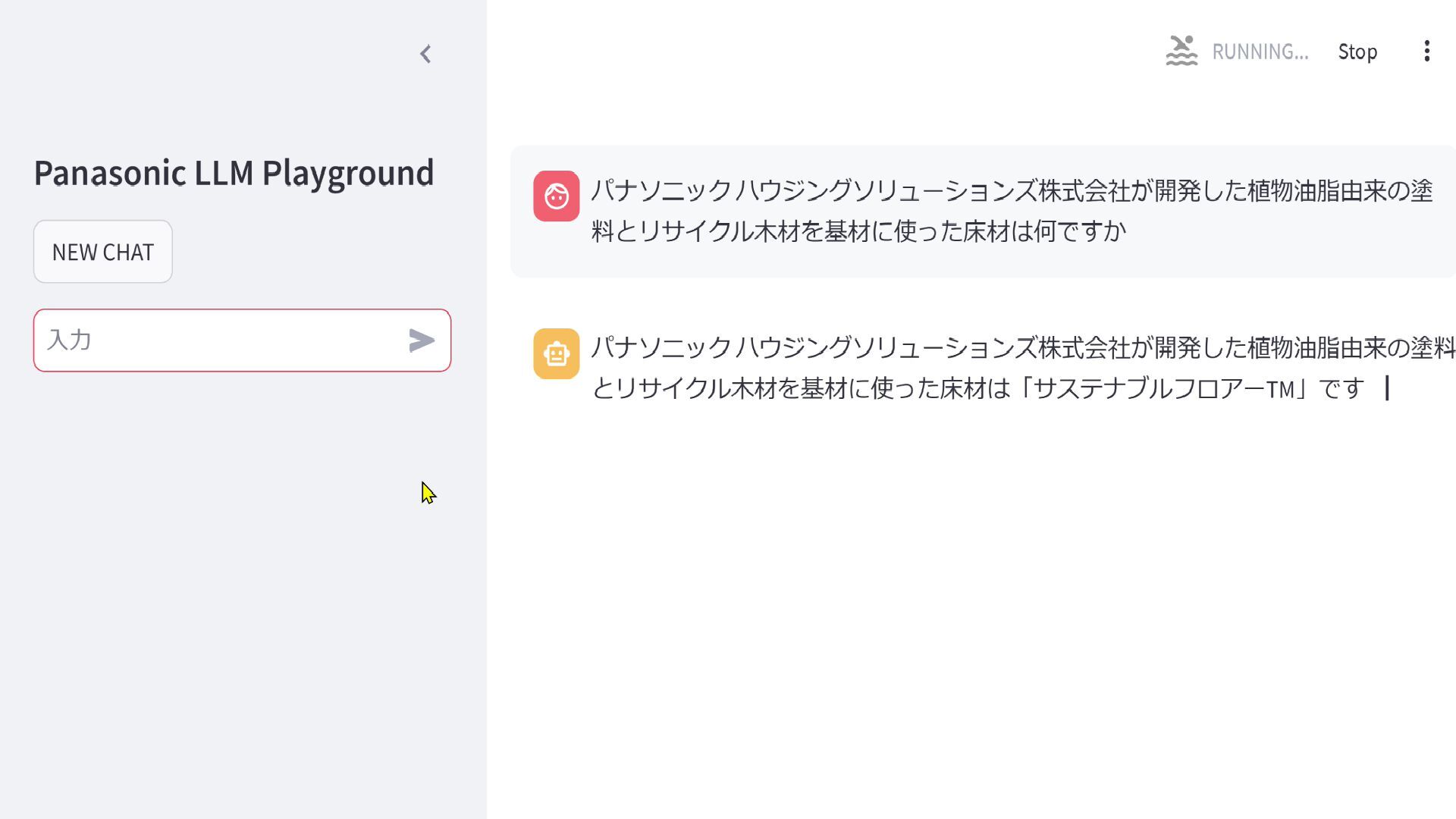
69/77 社内情報に対する回答例 Q.パナソニック ハウジングソリューションズ株式会社が開発した植物油脂由来の塗料とリサイクル木材 を基材に使った床材は何ですか Panasonic-LLM-100b パナソニック ハウジングソリューションズ株式会社が開発 した、植物油脂由来の塗料とリサイクル木材を基材に使 用した床材は「サステナブルフロア―TM」です。
GPT-4o パナソニック ハウジングソリューションズ株式会社が開発 した、植物油脂由来の塗料とリサイクル木材を基材に使 用した床材は「エコシステムフローリング」と呼ばれていま す。この製品は環境に配慮し、持続可能な素材を使用 している点が特徴です。エコシステムフローリングは、自然 素材を活用しながらも高い耐久性と美しい仕上がりを実 現しています。 ※プレスリリース情報を参考情報として提示
FastLabel株式会社との協業による データアノテーション効率化
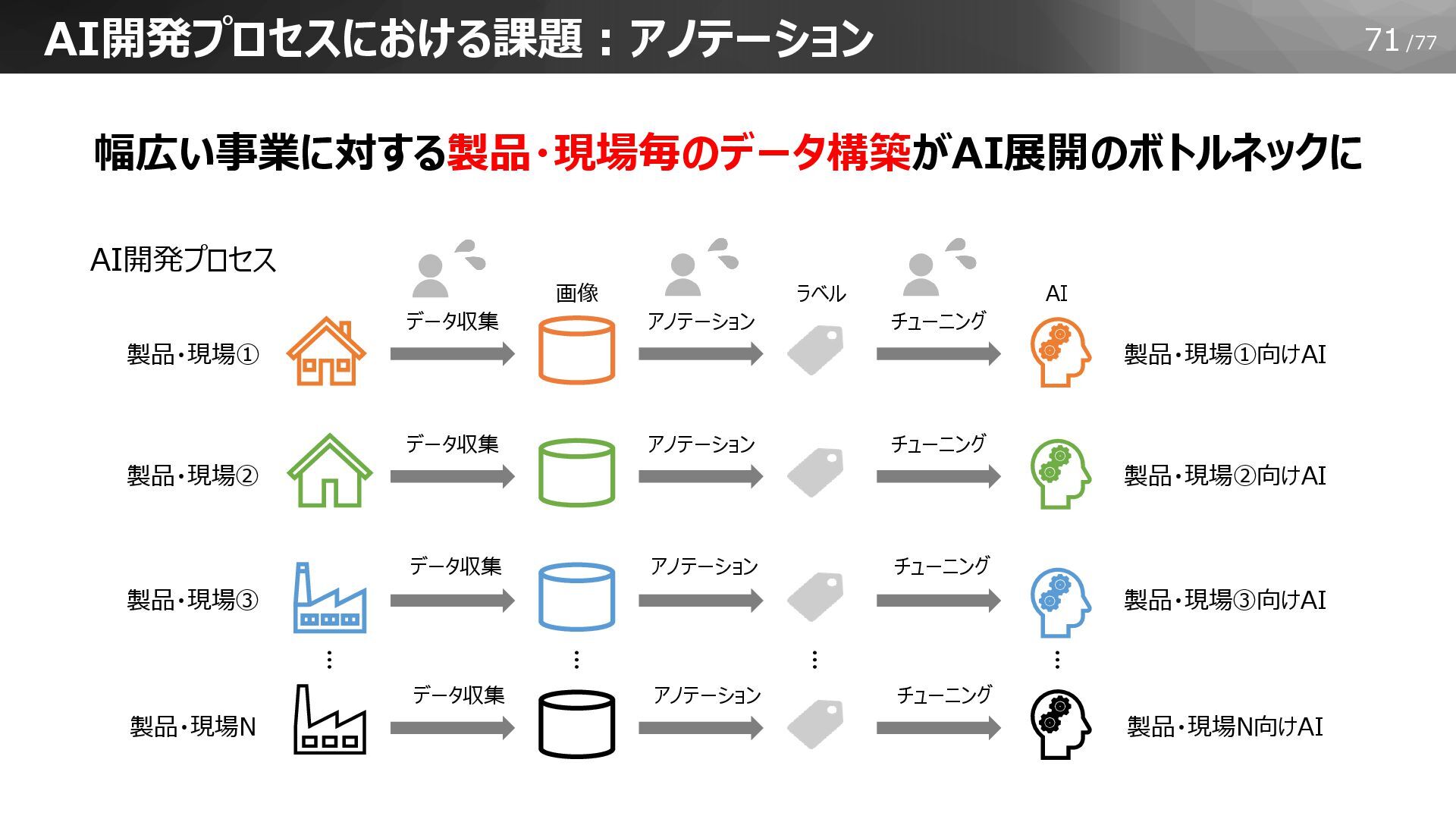
71/77 AI開発プロセスにおける課題:アノテーション … アノテーション チューニング アノテーション チューニング アノテーション チューニング アノテーション
チューニング 製品・現場①向けAI 製品・現場① 製品・現場②向けAI 製品・現場② 製品・現場③向けAI 製品・現場③ 製品・現場N向けAI 製品・現場N 画像 ラベル データ収集 データ収集 データ収集 データ収集 … … … AI 幅広い事業に対する製品・現場毎のデータ構築がAI展開のボトルネックに AI開発プロセス
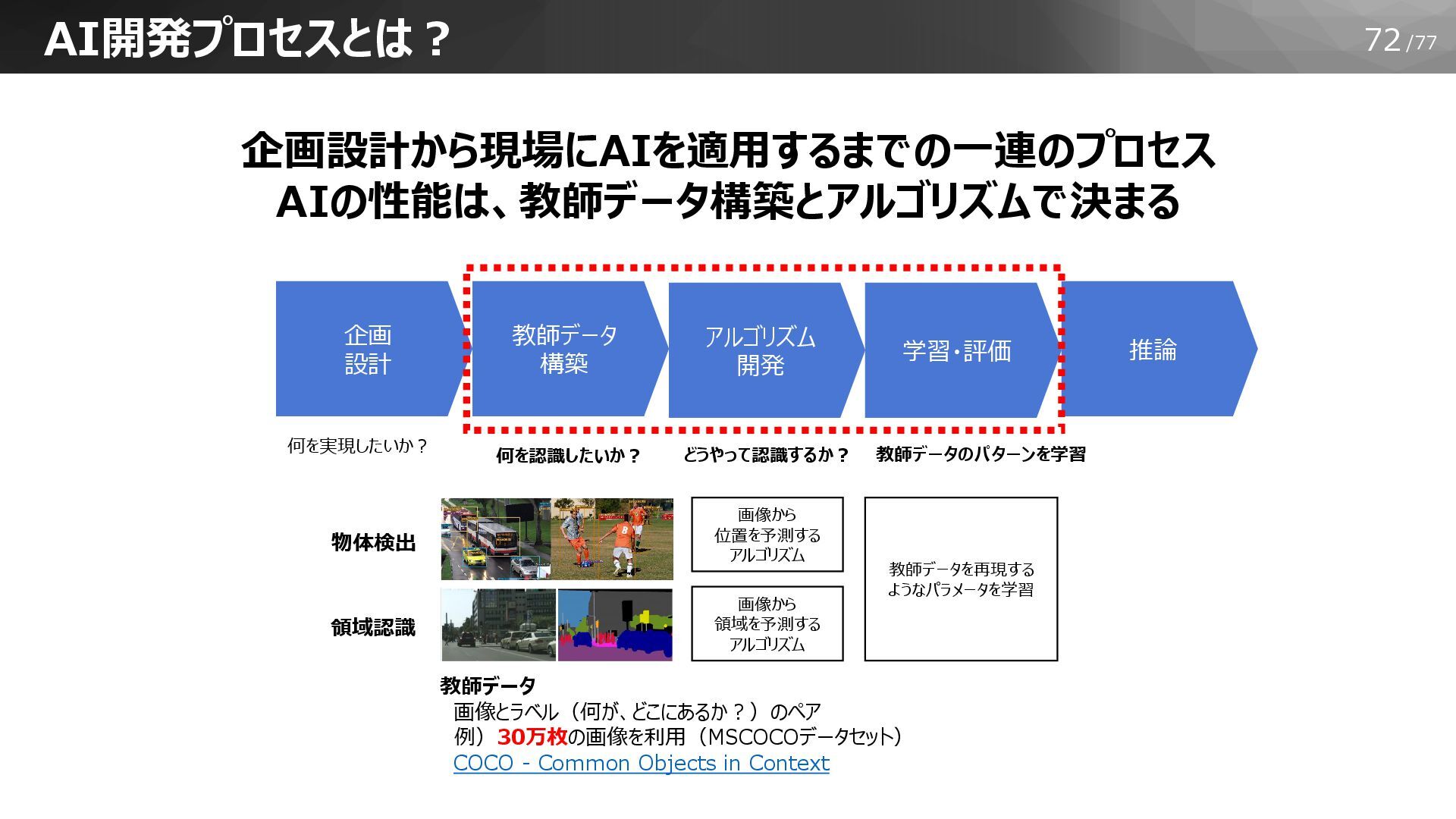
72/77 AI開発プロセスとは? 企画設計から現場にAIを適用するまでの一連のプロセス AIの性能は、教師データ構築とアルゴリズムで決まる アルゴリズム 開発 学習・評価 推論 企画 設計
教師データ 構築 何を実現したいか? 何を認識したいか? どうやって認識するか? 教師データのパターンを学習 教師データ 画像とラベル(何が、どこにあるか?)のペア 例)30万枚の画像を利用(MSCOCOデータセット) COCO - Common Objects in Context 画像から 位置を予測する アルゴリズム 画像から 領域を予測する アルゴリズム 教師データを再現する ようなパラメータを学習 領域認識 物体検出
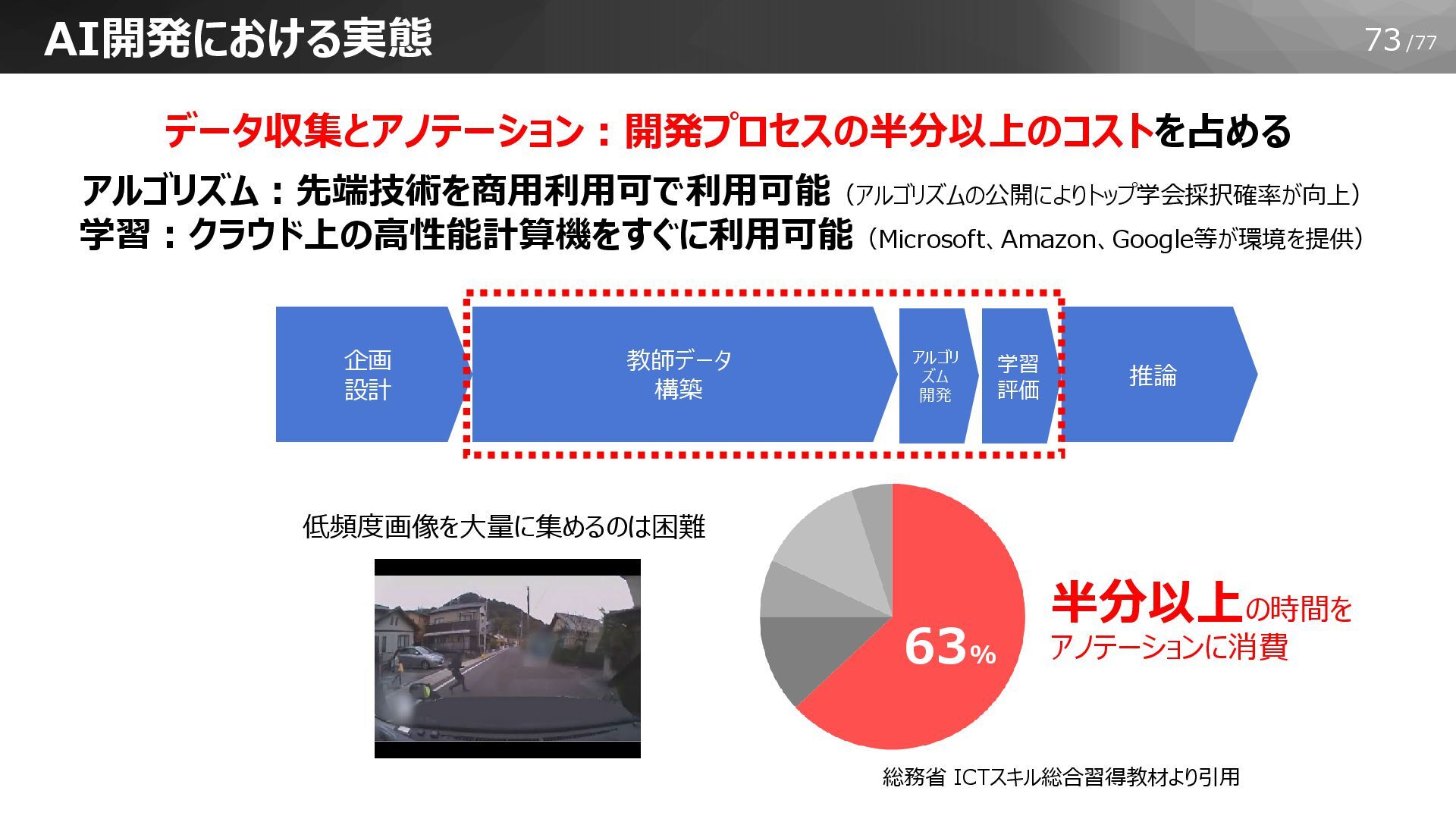
73/77 AI開発における実態 データ収集とアノテーション:開発プロセスの半分以上のコストを占める アルゴリズム:先端技術を商用利用可で利用可能(アルゴリズムの公開によりトップ学会採択確率が向上) 学習:クラウド上の高性能計算機をすぐに利用可能(Microsoft、Amazon、Google等が環境を提供) アルゴリ ズム 開発 学習 評価
推論 企画 設計 教師データ 構築 低頻度画像を大量に集めるのは困難 総務省 ICTスキル総合習得教材より引用 半分以上の時間を アノテーションに消費 63%
74/77 関連リリース AIデータプラットフォームの開発・提供を行うFastLabel様へ パナソニックくらしビジョナリーファンドから出資を決定※ × くらしを支える商品・ソリューションを革新するさらなるAI開発と AIサービスのあり方について追求 ※[プレスリリース] AIデータプラットフォームの開発・提供を行うFastLabelへ パナソニックくらしビジョナリーファンドから出資を決定(2024.9)
https://news.panasonic.com/jp/press/jn240909-5
75/77 FastLabel株式会社との連携:AI開発効率向上に向けた協業 基盤モデル HIPIEとData-centric AIプラットフォームの連携により AI開発効率を向上してパナソニックグループのAI開発を加速 モデルの学習をせずに プロンプトの入力でアノテーション自動化が可能な 基盤モデル HIPIE
企業内AIモデル開発プロジェクトの 一連にわたる支援が可能な Data-centric AIプラットフォーム AI開発プロセスのボトルネックとなるデータアノテーションの手間を大幅に削減 × HIPIE テキスト・プロンプト (データ構築したい対象) 画像認識 banana
76/77 開発技術の活用例:アノテーション自動化 冷蔵庫AIカメラの学習データ構築効率化 テキストで認識対象を入力すると自動でデータ構築(境界入力)をしてくれる 1物体あたりのアノテーション時間(*当社検証事例における概算値) 手作業アノテーション 自動アノテーション(HIPIE) 60秒 5秒 ※
[プレスリリース] パナソニックHDとFastLabel、アノテーションコストの大幅削減と高精度化を両立するAI開発効率向上に向けた協業を開始(2024.9) https://news.panasonic.com/jp/press/jn240927-1
77/77 さいごに AI研究の最前線における外部連携を活用したチームビルディングの事例について紹介 大学との連携事例: 1.スタンフォード人工知能研究所との連携 2.UC Berkeleyとの連携 → ポイント:連携により何を制御したいかを明確化(単純に技術の強化ではない) ・データセットを押さえることにより研究領域の方向性を制御
・柔軟性の高い組織との連携により、チーム規模を制御 スタートアップとの連携事例: 3.ストックマーク株式会社との協業による大規模言語モデルの開発 4.FastLabel株式会社との協業によるデータアノテーション効率化 → ポイント:自身のコアコンピタンスの明確化 社会実装までのパスを繋ぐことができるパートナーとの連携により 実用化までの期間を大幅に短縮できる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![6/77 課題③:チームビルディング体制 CVPRの日本人著者の比率、日本人著者を含む論文比率は低下 → 世界の伸びについていけていない コミュニティやチームが国内に閉じていて、世界で増えている資源をうまく活用できていない? [%] 「ResearchPortトップカンファレンス定点観測 vol.13」から作成](https://files.speakerdeck.com/presentations/5c263d1ea9f64464a565bb29504fc61e/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![74/77 関連リリース AIデータプラットフォームの開発・提供を行うFastLabel様へ パナソニックくらしビジョナリーファンドから出資を決定※ × くらしを支える商品・ソリューションを革新するさらなるAI開発と AIサービスのあり方について追求 ※[プレスリリース] AIデータプラットフォームの開発・提供を行うFastLabelへ パナソニックくらしビジョナリーファンドから出資を決定(2024.9)](https://files.speakerdeck.com/presentations/5c263d1ea9f64464a565bb29504fc61e/slide_74.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}