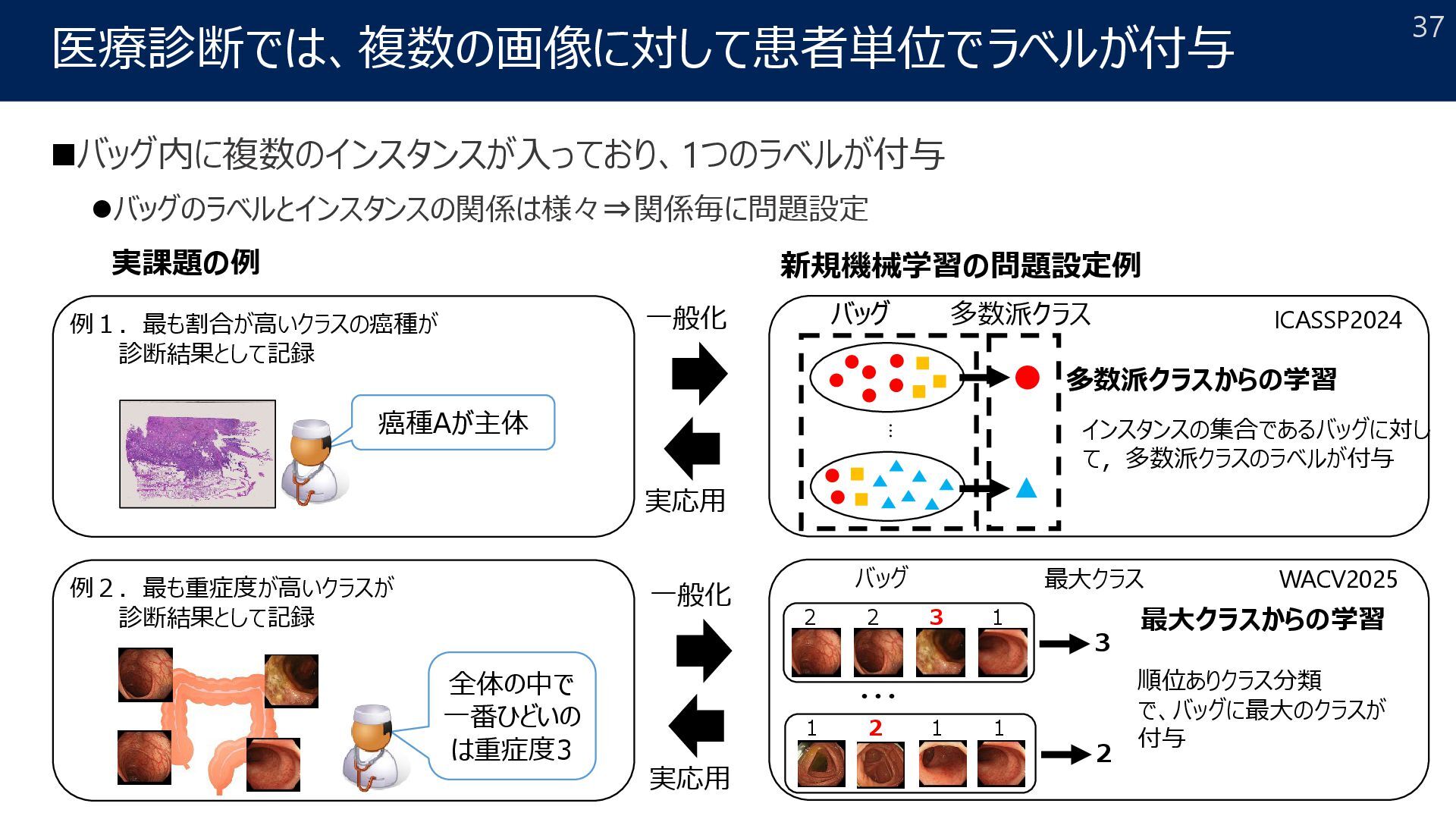
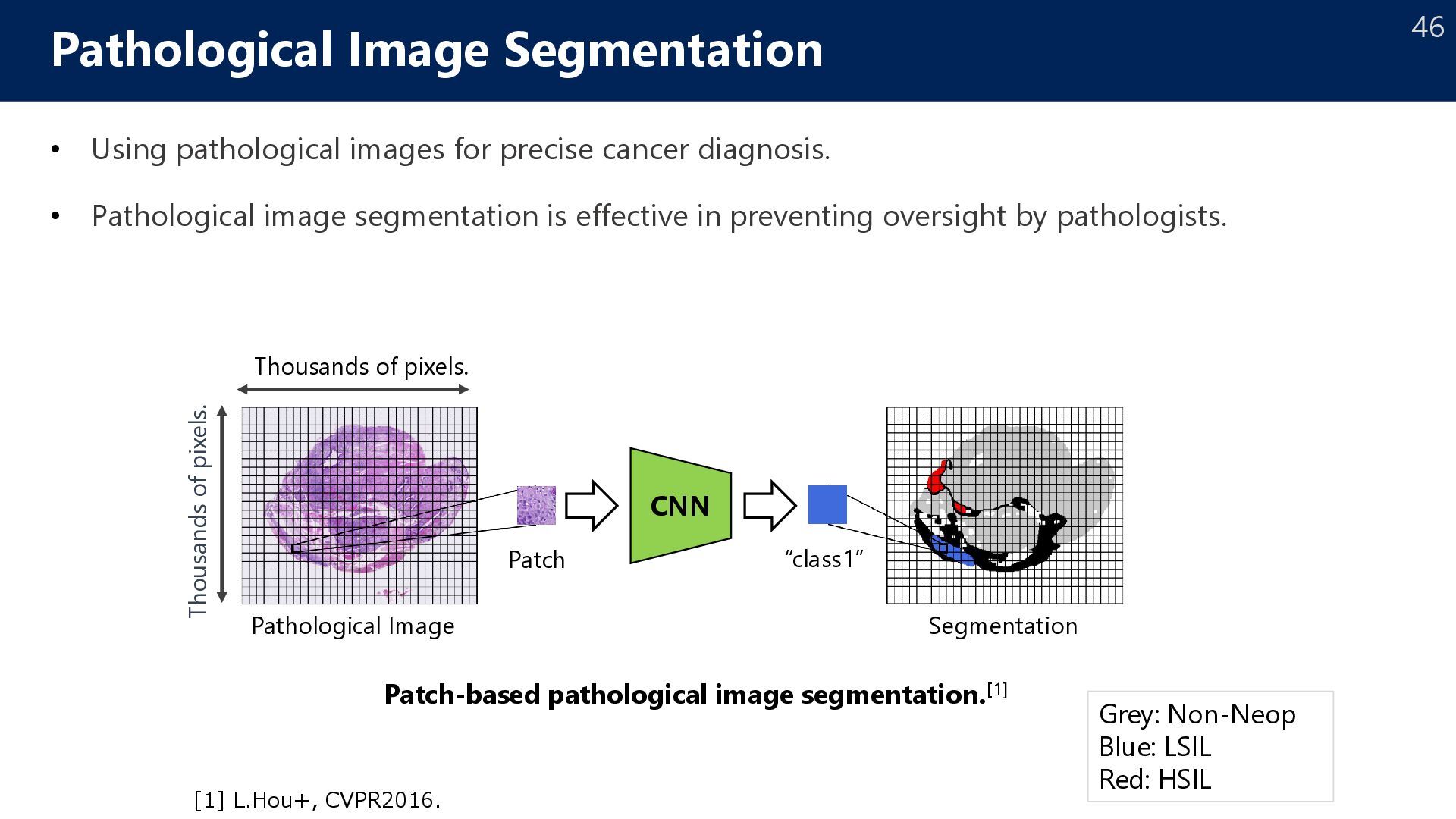
Pathologist 2017年~ Lepidic Acinar Micropap Solid Normal Tumor Papillary [*] A. Yoshizawa et al.,, “Validation of the IASLC/ATS/ERS lung adenocarcinoma classification for prognosis and association with EGFR and KRAS gene mutations: analysis of 440 Japanese patients.,” Journal of Thoracic Oncology, 2013. Lepidic Micropap Solid Acinar Papillary time Survival rate Lung Cancer Analysis PDL1 Chemotherapy Collaborative papers: CVPR2019 ECCV2020 MICCAI2024 Modern Pathology ×3(IF:7.2) 13 papers 研究開始当初の依頼: 肺癌の手術検体の癌腫毎にセグメンテーションして欲しい (癌腫比率を推定して欲しい) → 予後(例:5年生存率)との関係性を解析したい! 8
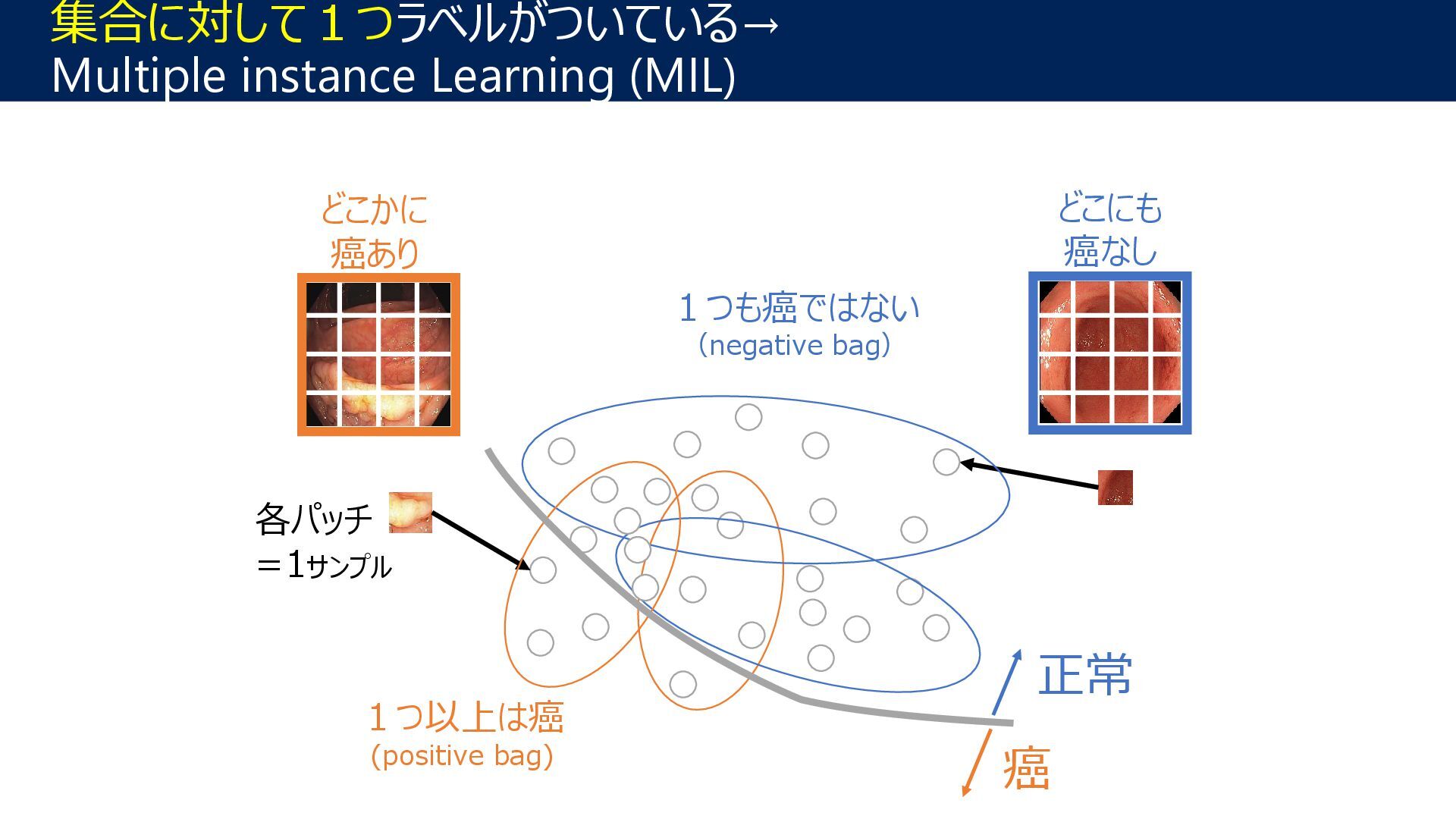
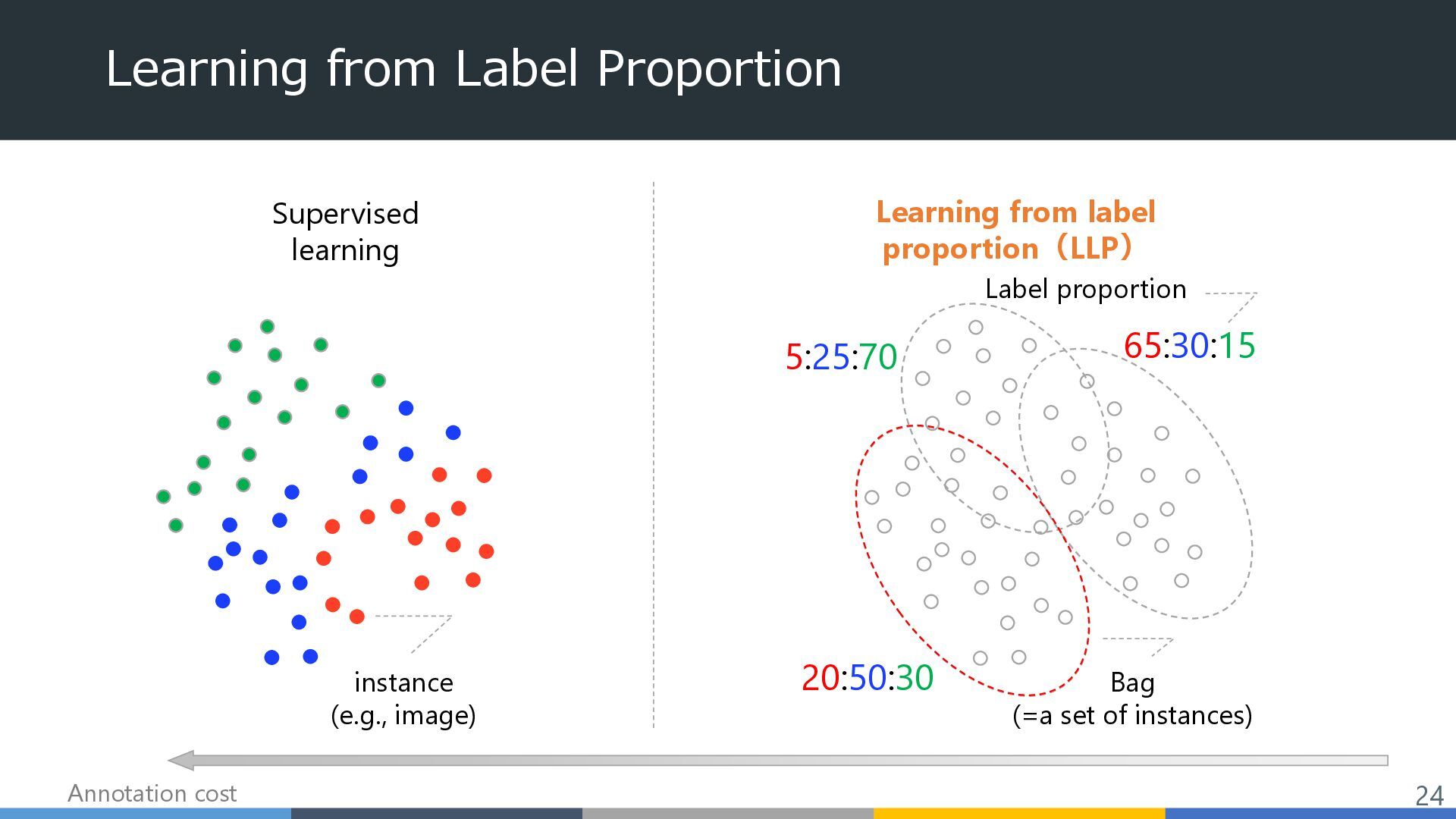
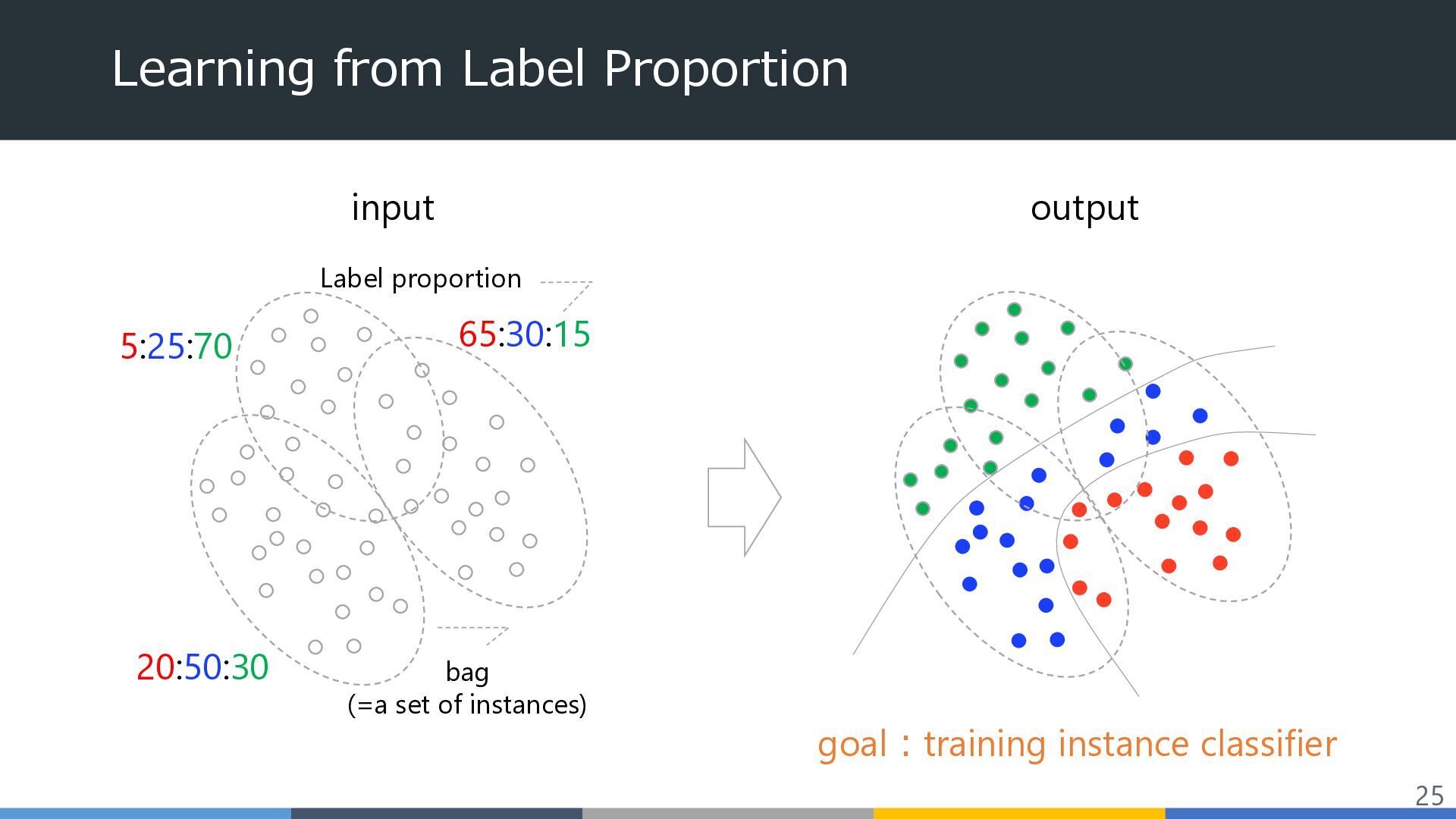
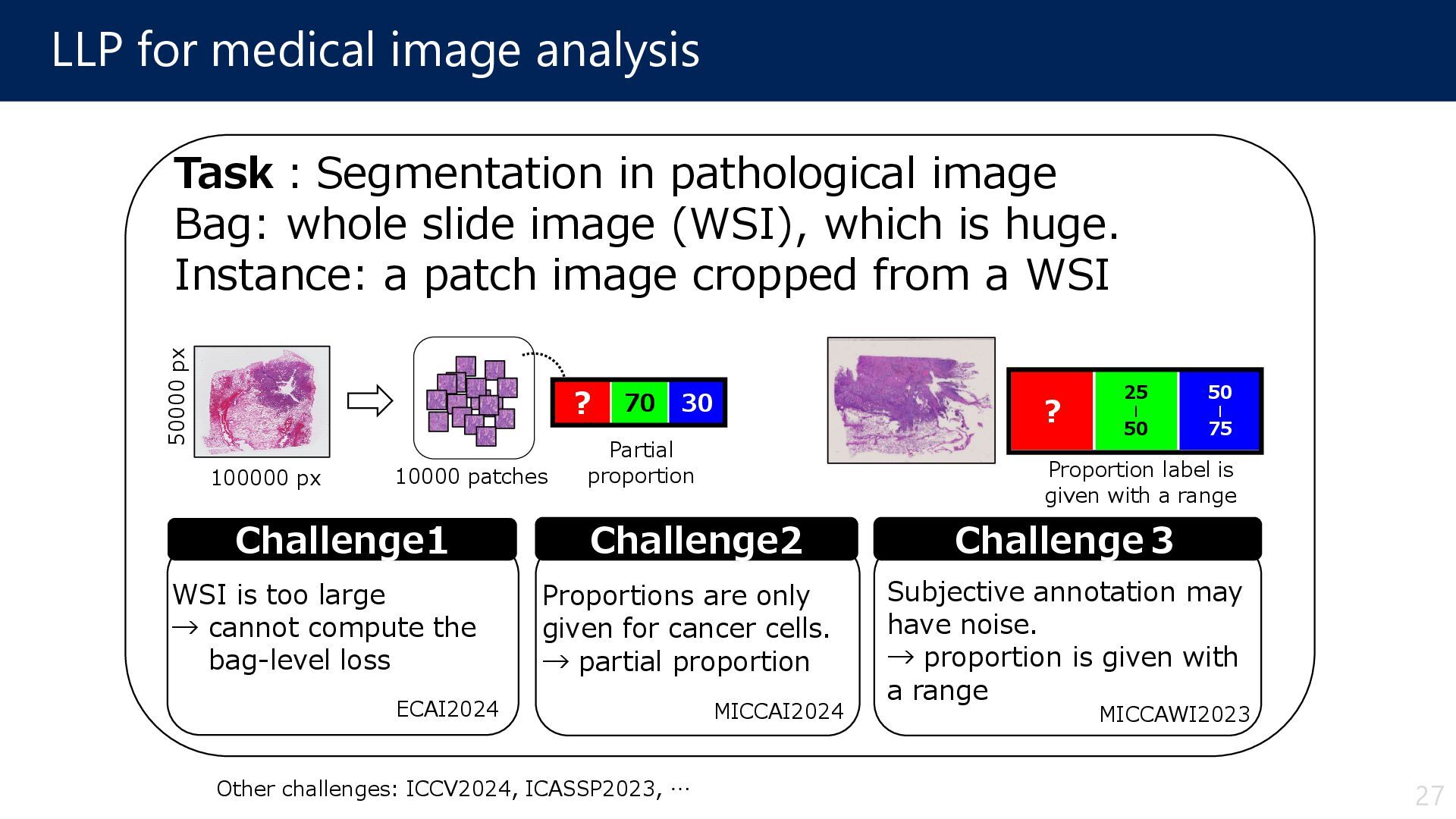
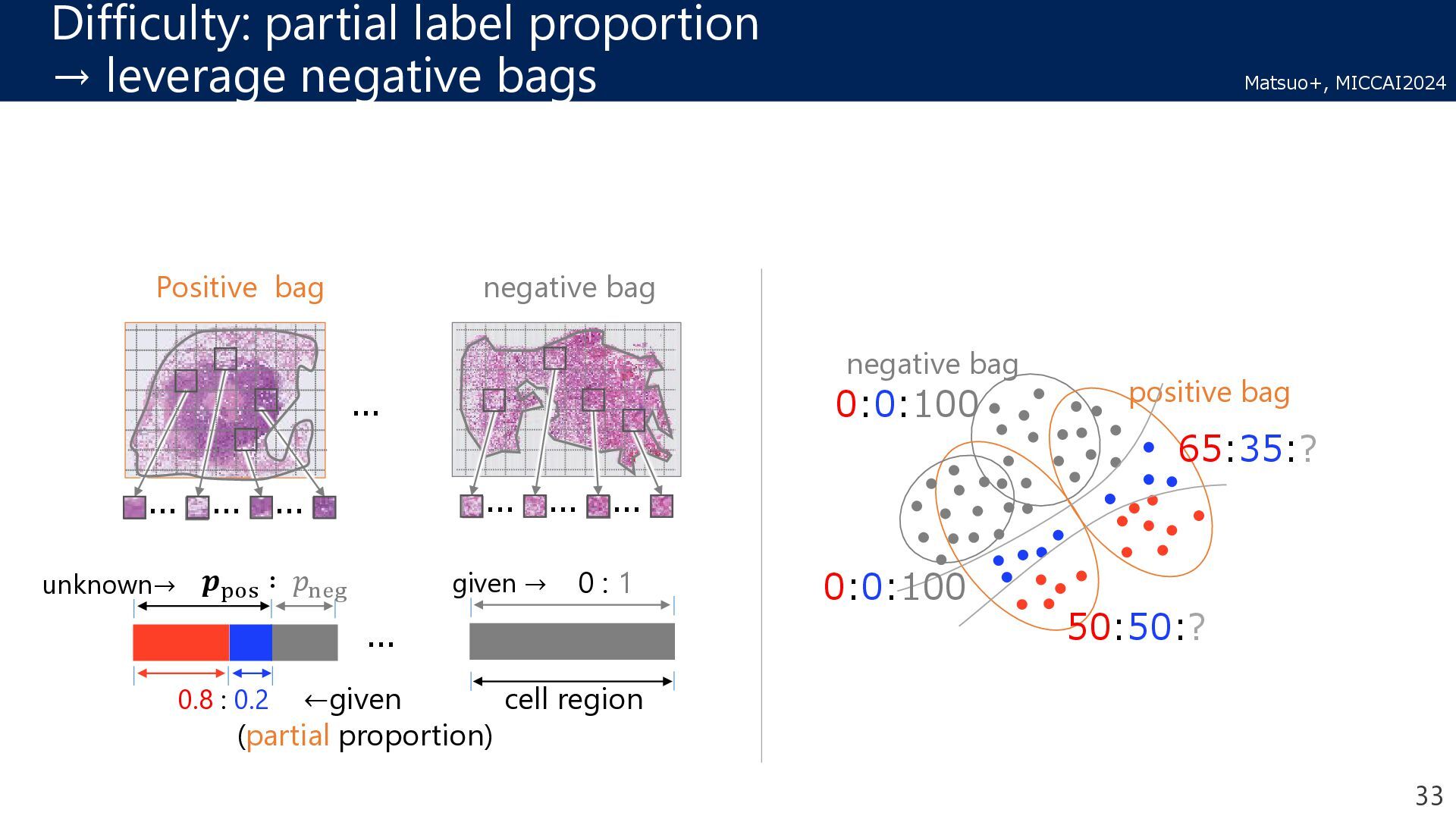
pathological image Bag: whole slide image (WSI), which is huge. Instance: a patch image cropped from a WSI Challenge2 Proportions are only given for cancer cells. → partial proportion Challenge1 WSI is too large → cannot compute the bag-level loss 100000 px 50000 px 10000 patches Partial proportion Challenge3 Subjective annotation may have noise. → proportion is given with a range 25 | 50 ? 50 | 75 Proportion label is given with a range 27 ECAI2024 MICCAI2024 MICCAWI2023 Other challenges: ICCV2024, ICASSP2023, …
pathological image Bag: whole slide image (WSI), which is huge. Instance: a patch image cropped from a WSI Challenge2 Proportions are only given for cancer cells. → partial proportion Challenge1 WSI is too large → cannot compute the bag-level loss 100000 px 50000 px 10000 patches Partial proportion Challenge3 Subjective annotation may have noise. → proportion is given with a range 25 | 50 ? 50 | 75 Proportion label is given with a range 28 ECAI2024 MICCAI2024 MICCAWI2023 Other challenges: ICCV2024, ICASSP2023, …
S Matsuo1, D Suehiro1, S Uchida1, H Ito2, K Terada2, A Yoshizawa2, and R Bise1 1Kyushu University, 2Kyoto University Hospital MICCAI2024 (Top Conference on Medical Imaging, Core Rank: A) 29
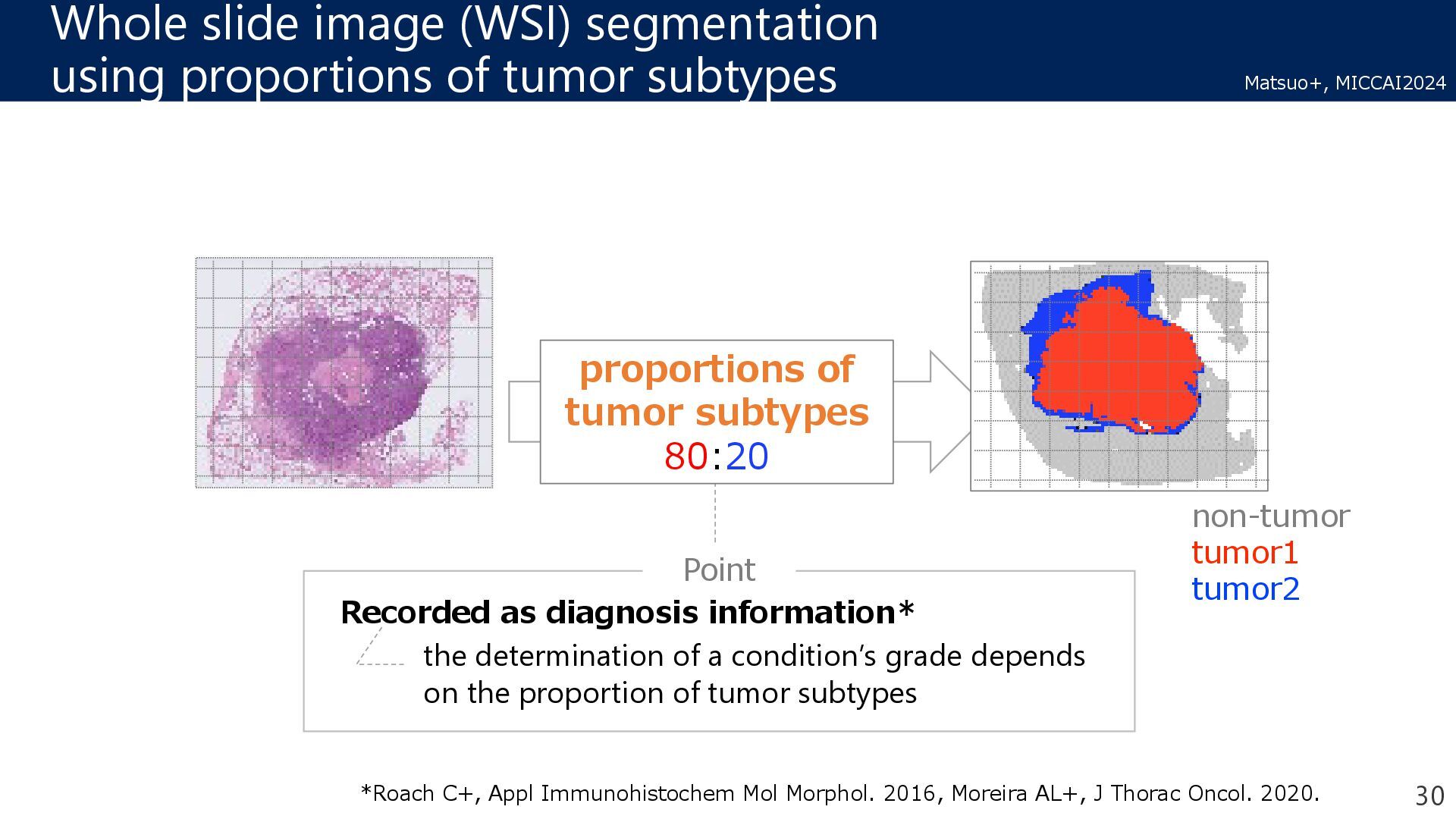
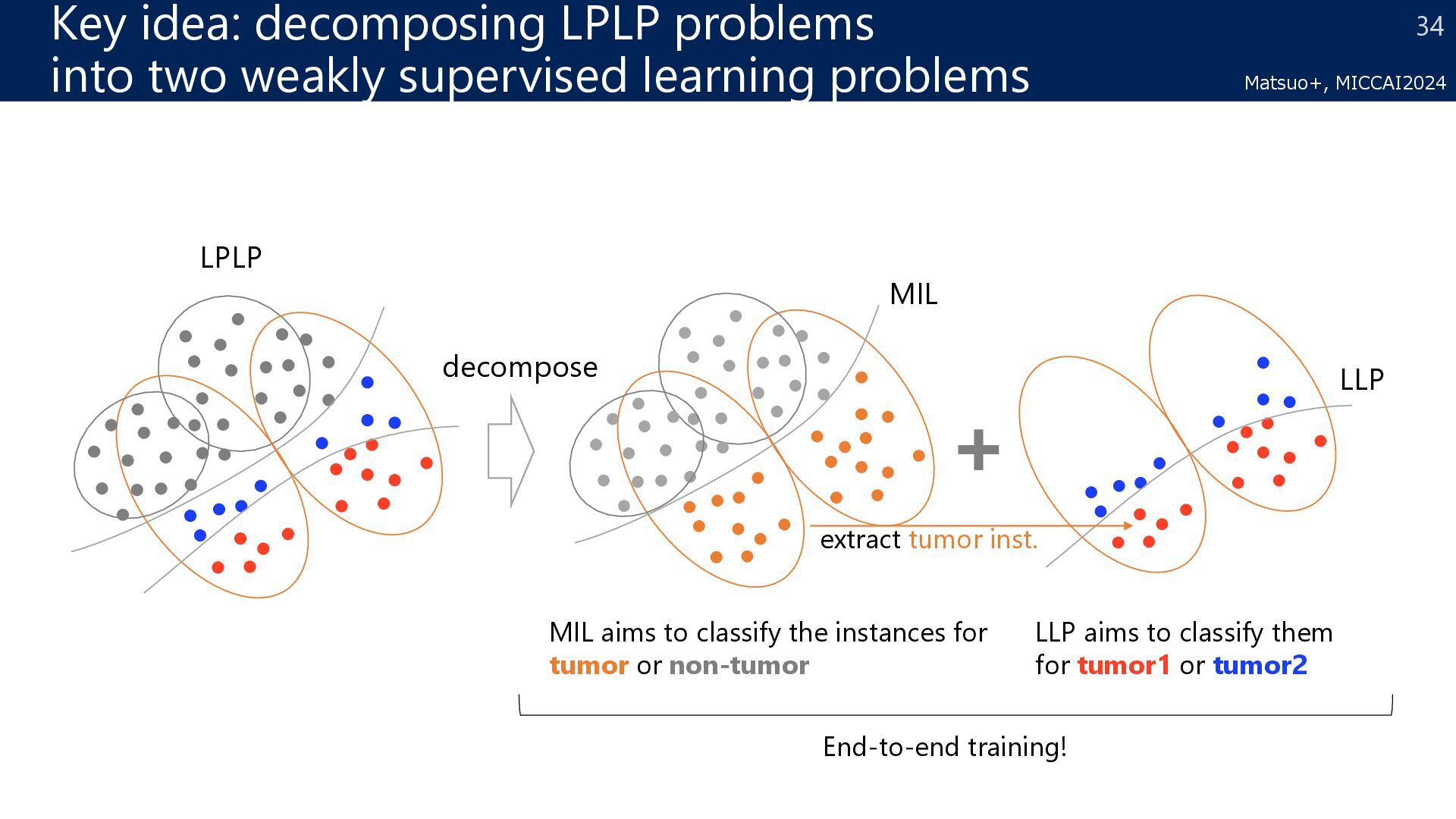
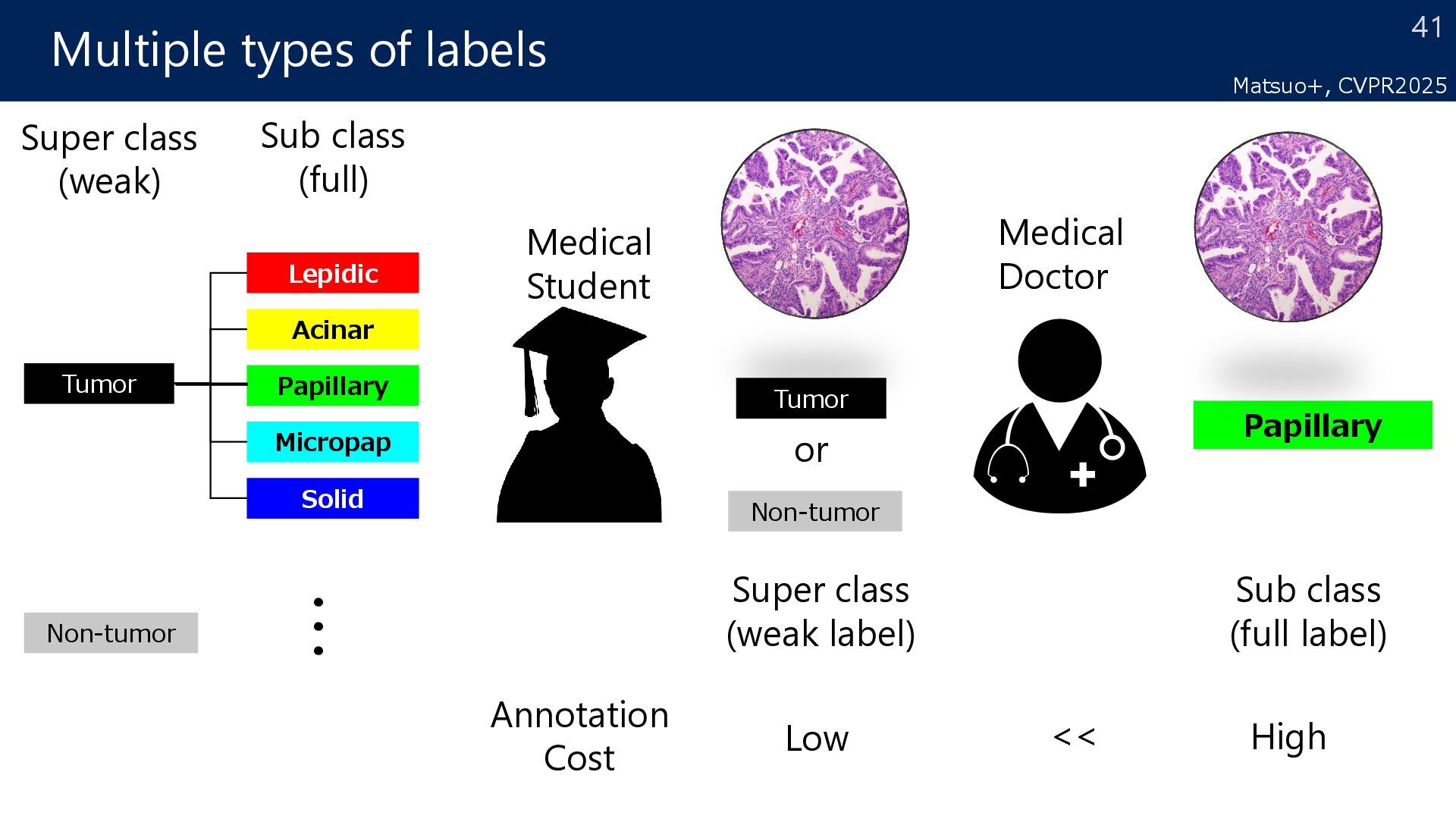
the determination of a condition’s grade depends on the proportion of tumor subtypes Point Recorded as diagnosis information* *Roach C+, Appl Immunohistochem Mol Morphol. 2016, Moreira AL+, J Thorac Oncol. 2020. non-tumor tumor1 tumor2 proportions of tumor subtypes 80:20 30 Matsuo+, MICCAI2024
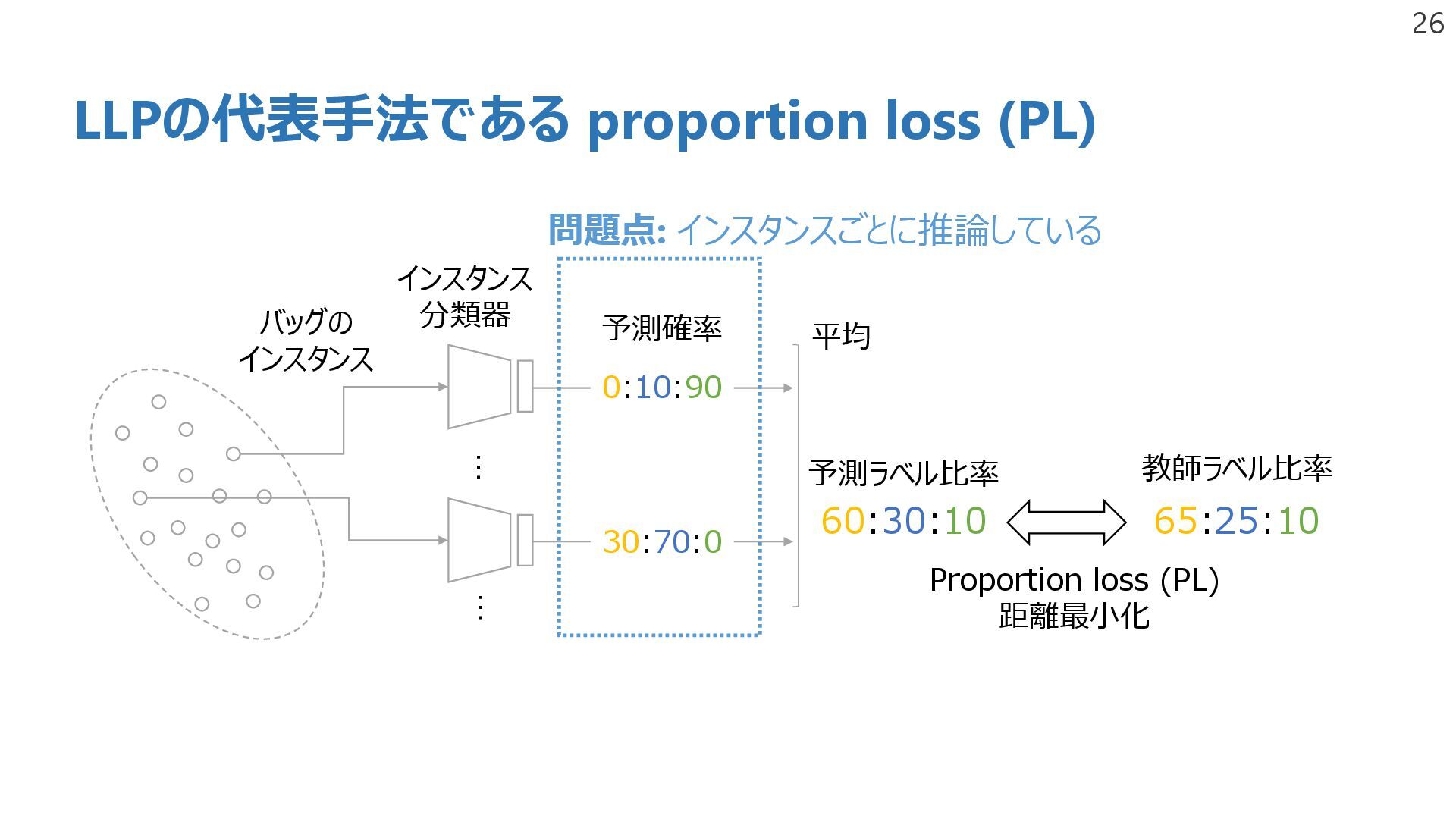
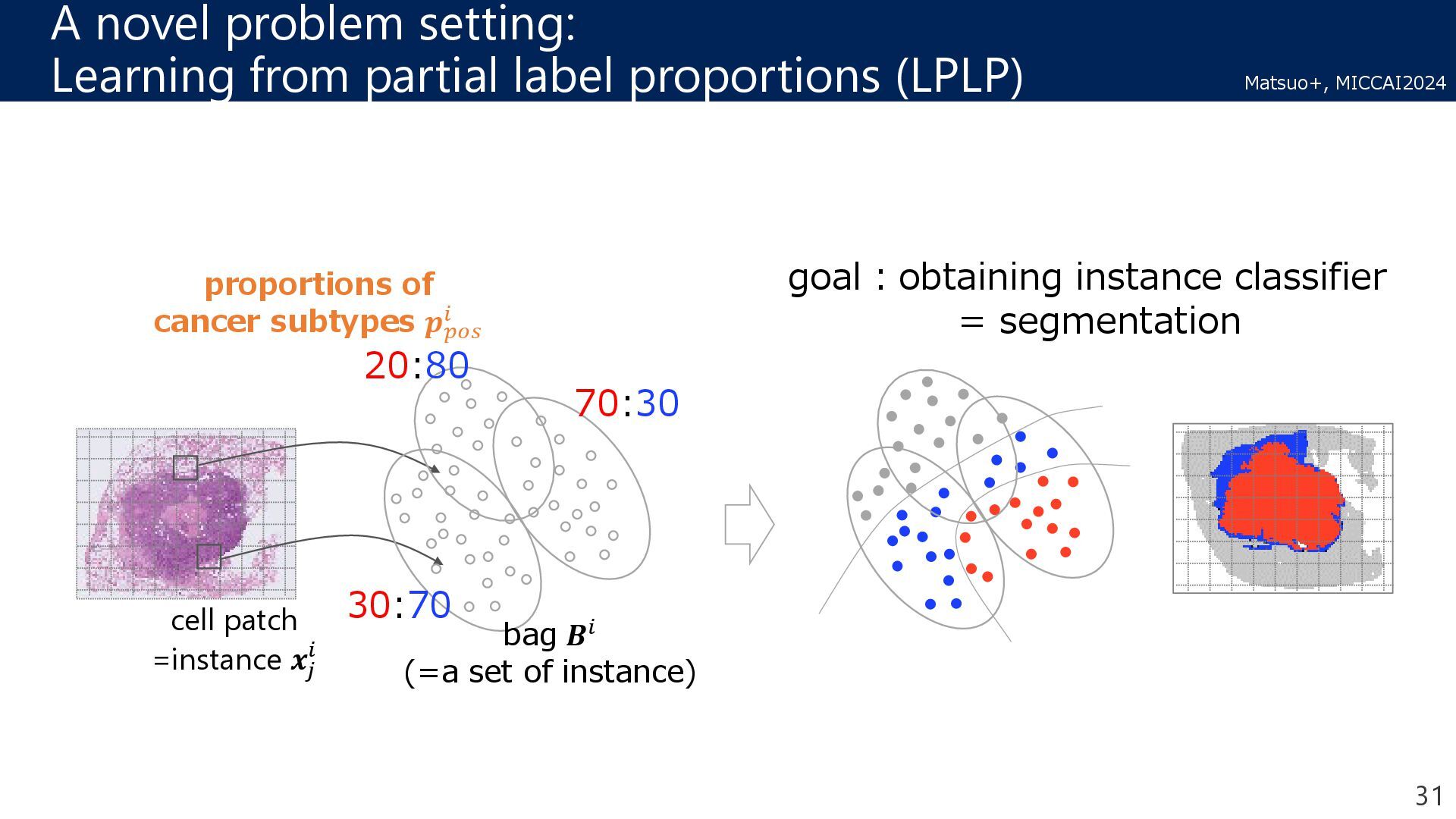
learning problems LLP MIL extract tumor inst. LPLP decompose MIL aims to classify the instances for tumor or non-tumor End-to-end training! LLP aims to classify them for tumor1 or tumor2 Matsuo+, MICCAI2024
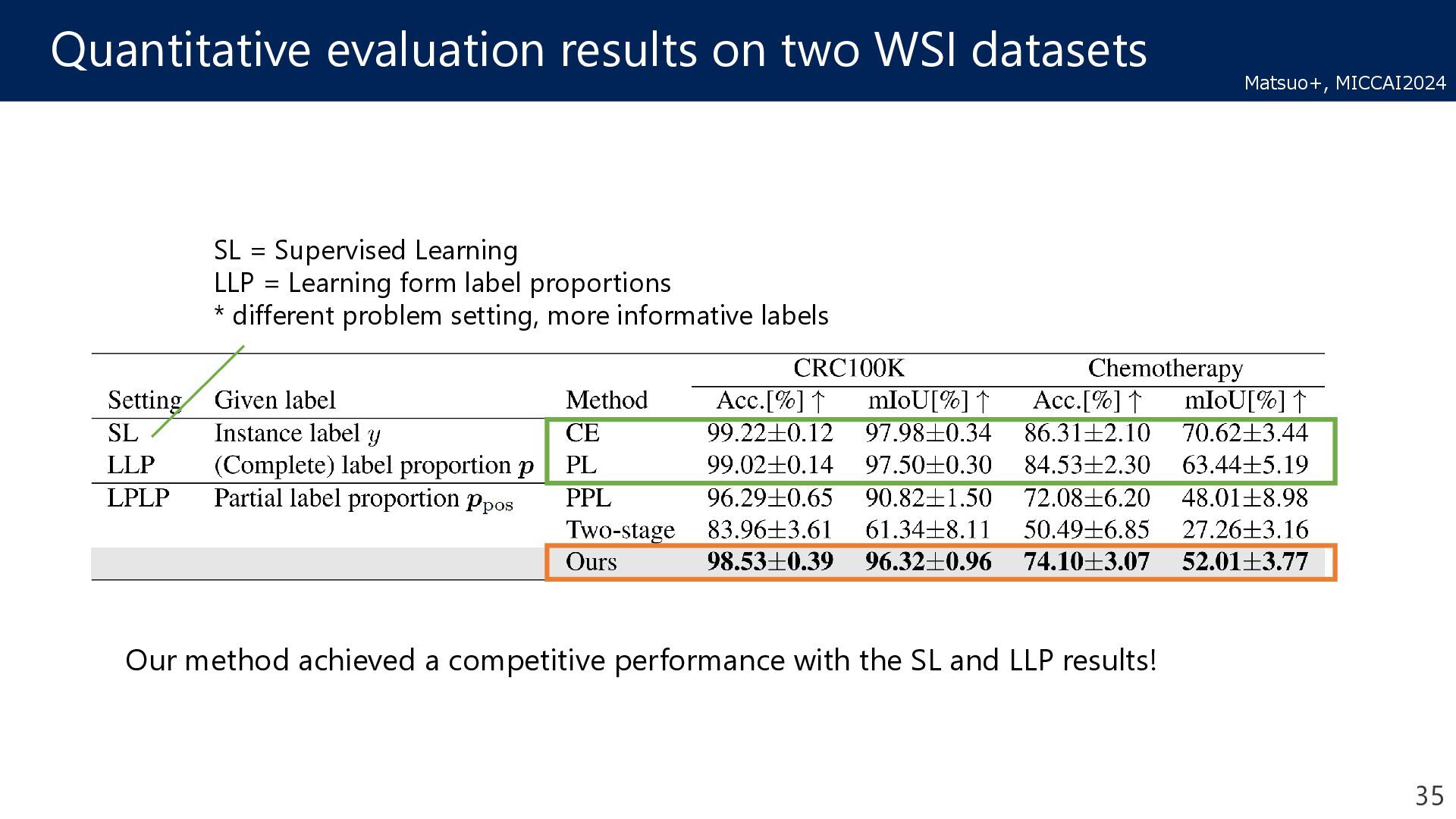
Learning LLP = Learning form label proportions * different problem setting, more informative labels Our method achieved a competitive performance with the SL and LLP results! 35 Matsuo+, MICCAI2024
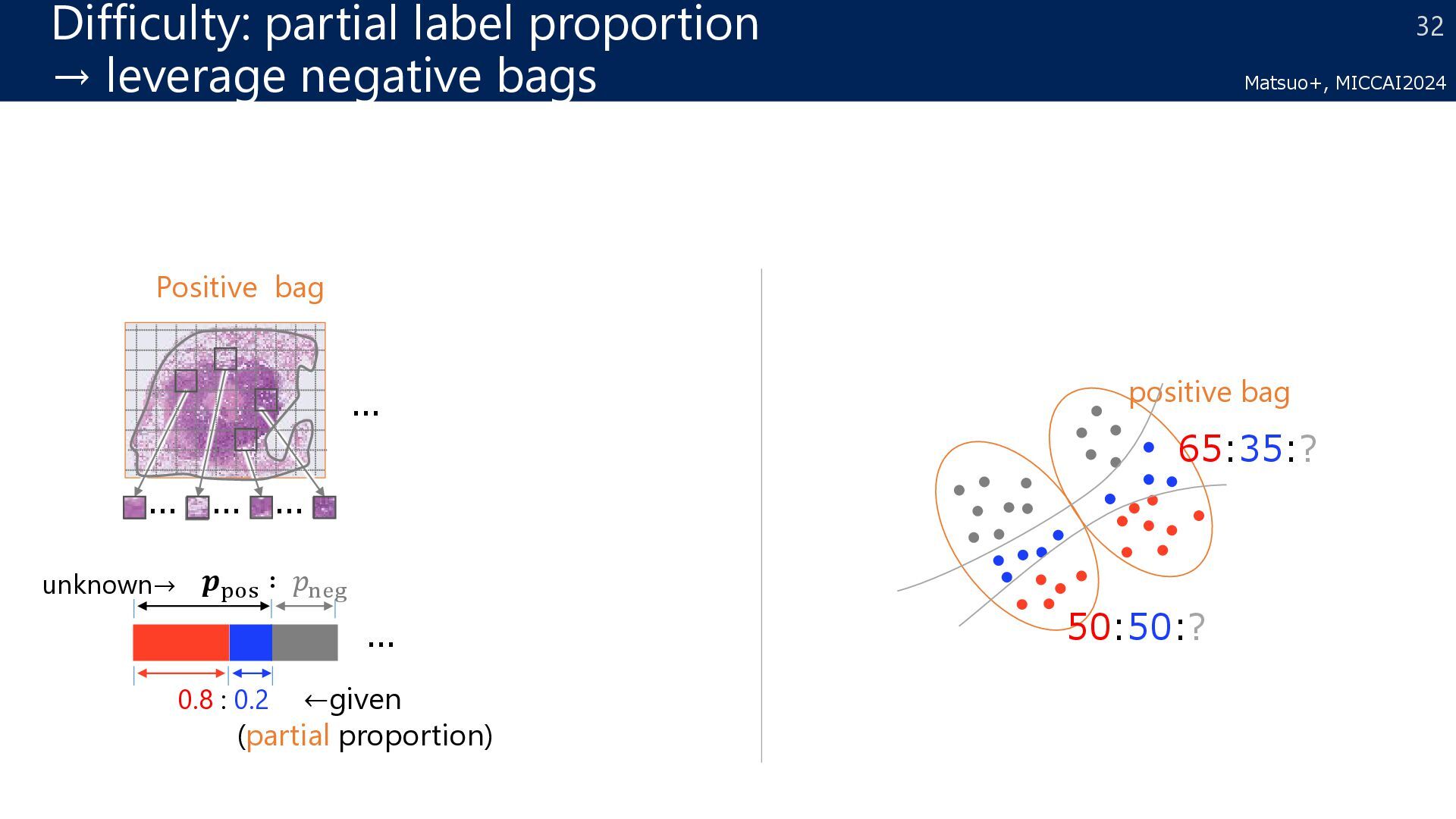
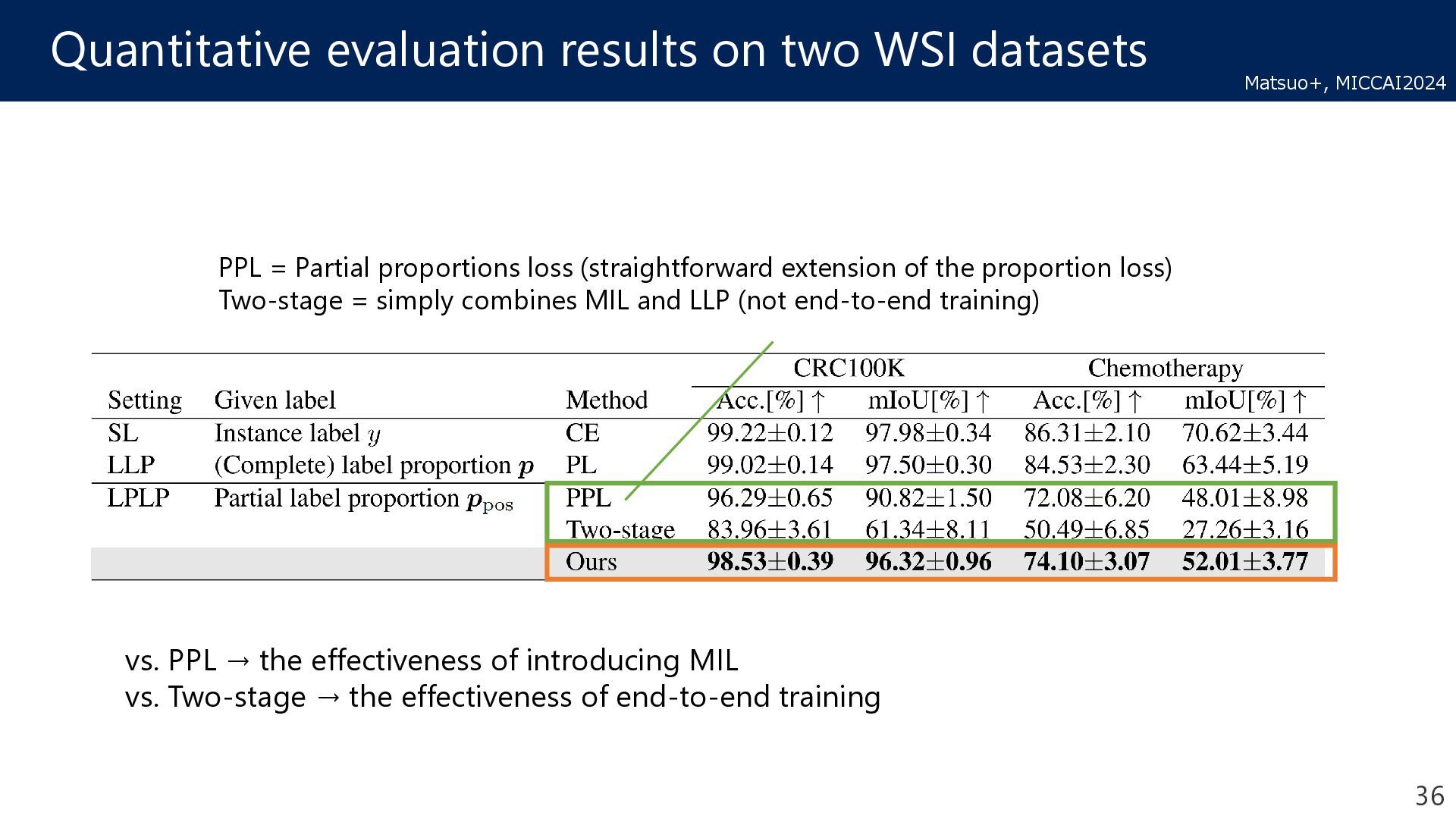
proportions loss (straightforward extension of the proportion loss) Two-stage = simply combines MIL and LLP (not end-to-end training) vs. PPL → the effectiveness of introducing MIL vs. Two-stage → the effectiveness of end-to-end training 36 Matsuo+, MICCAI2024
Solid Non-tumor Tumor Papillary Super class (weak) ・・・ Sub class (full) or Non-tumor Tumor Medical Student Super class (weak label) Papillary Medical Doctor Sub class (full label) Annotation Cost Low High <<
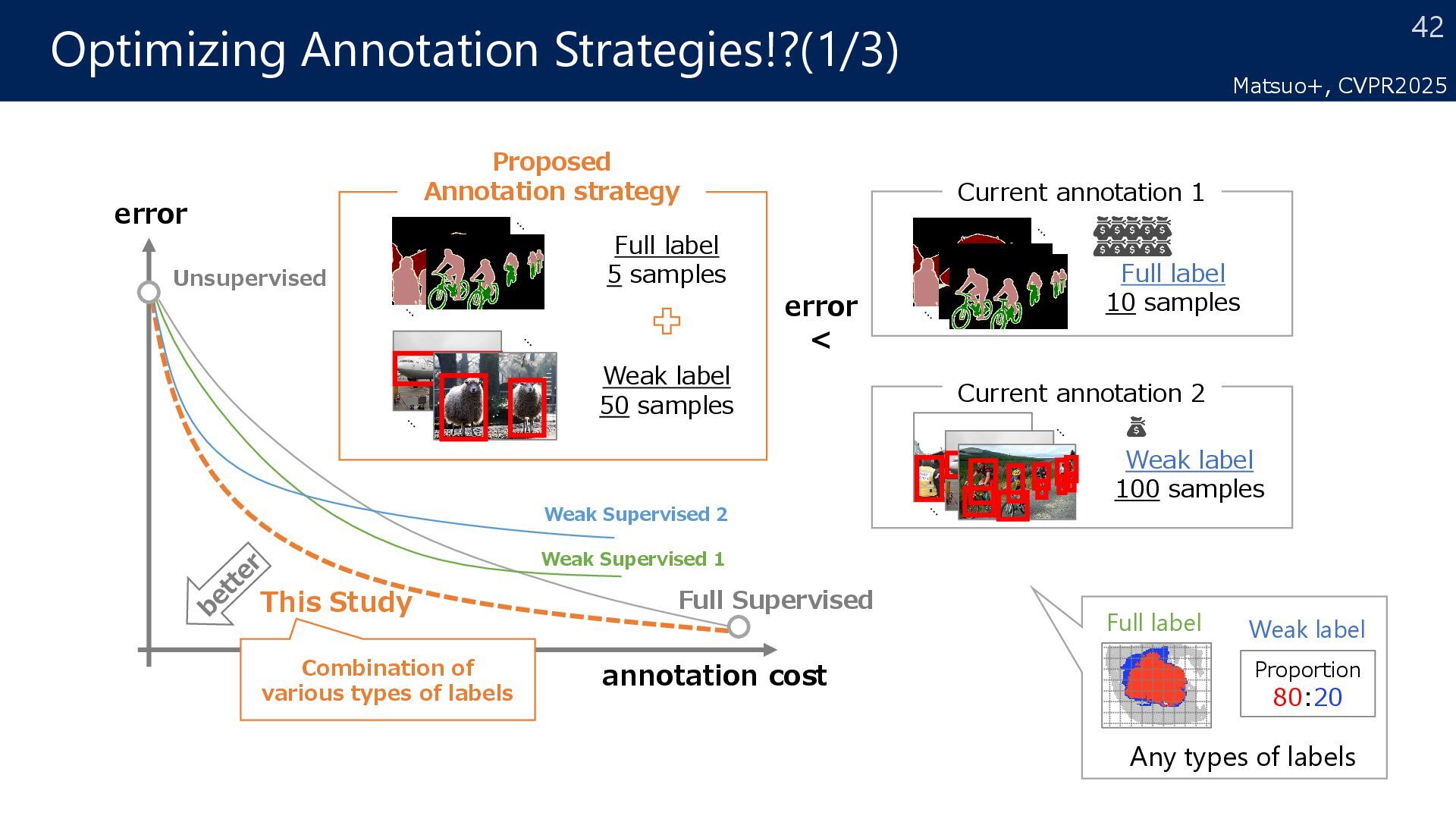
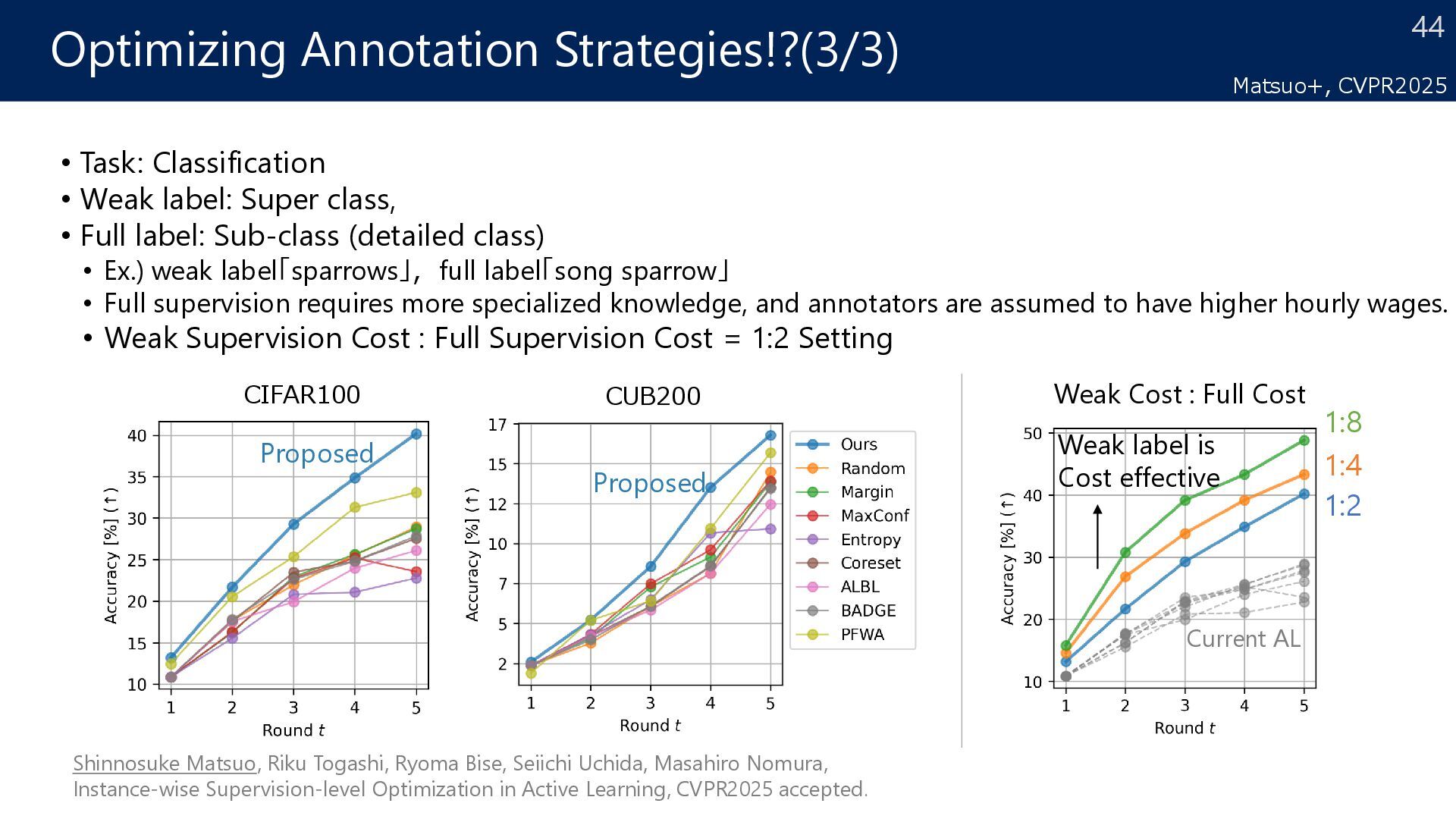
samples Current annotation 1 Full label 10 samples error < Proposed Annotation strategy Full label 5 samples Weak label 50 samples error annotation cost This Study Combination of various types of labels Weak Supervised 1 Weak Supervised 2 Unsupervised Full Supervised Proportion 80:20 Any types of labels Full label Weak label Matsuo+, CVPR2025
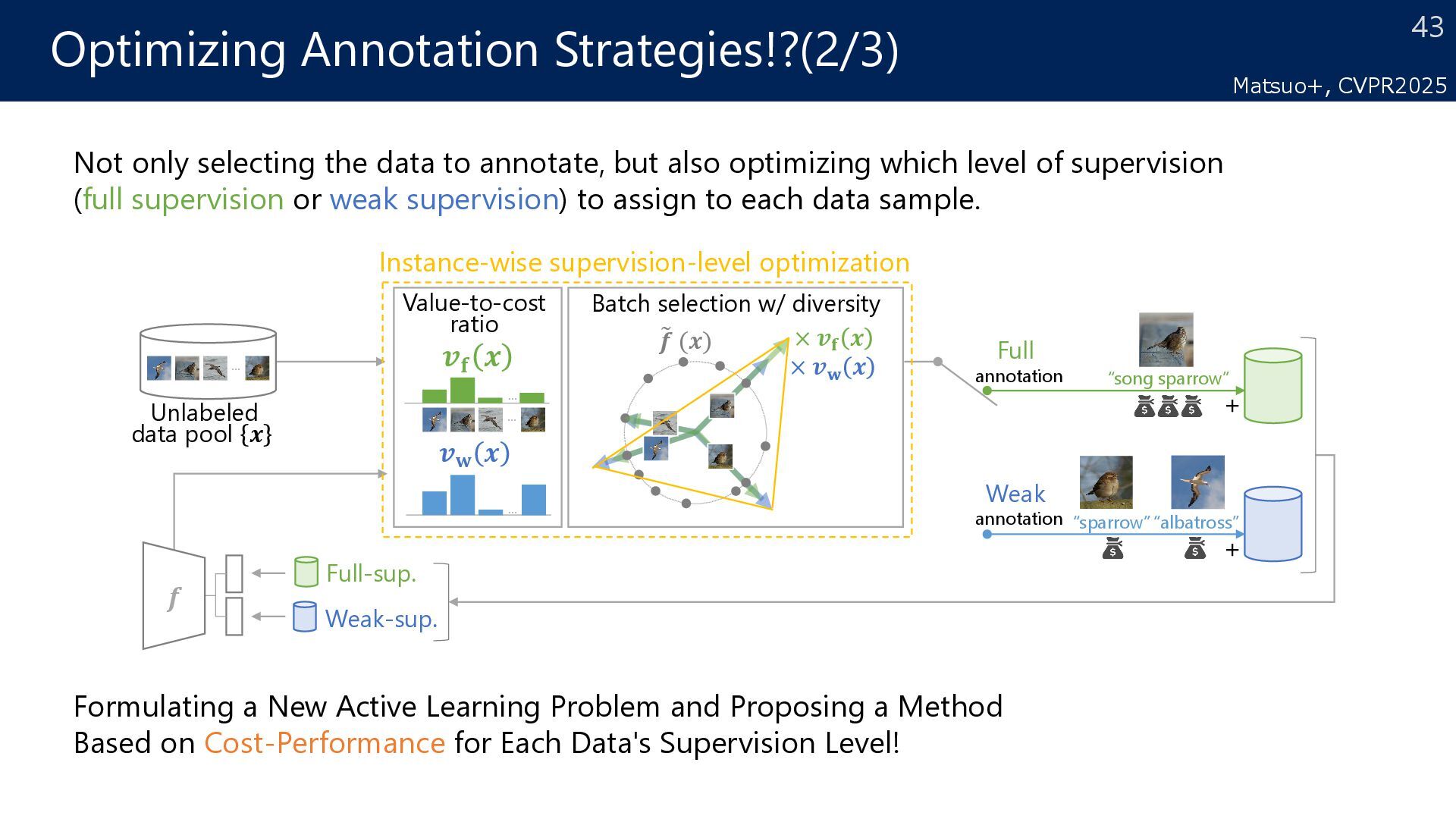
Full annotation Full-sup. Weak-sup. � 𝒇𝒇 (𝒙𝒙) × 𝒗𝒗𝐟𝐟 𝒙𝒙 Value-to-cost ratio 𝒇𝒇 + + “song sparrow” “albatross” “sparrow” Batch selection w/ diversity Instance-wise supervision-level optimization × 𝒗𝒗𝐰𝐰 𝒙𝒙 𝒗𝒗𝐟𝐟 𝒙𝒙 𝒗𝒗𝐰𝐰 𝒙𝒙 ⋯ ⋯ ⋯ ⋯ Formulating a New Active Learning Problem and Proposing a Method Based on Cost-Performance for Each Data's Supervision Level! Not only selecting the data to annotate, but also optimizing which level of supervision (full supervision or weak supervision) to assign to each data sample. Matsuo+, CVPR2025
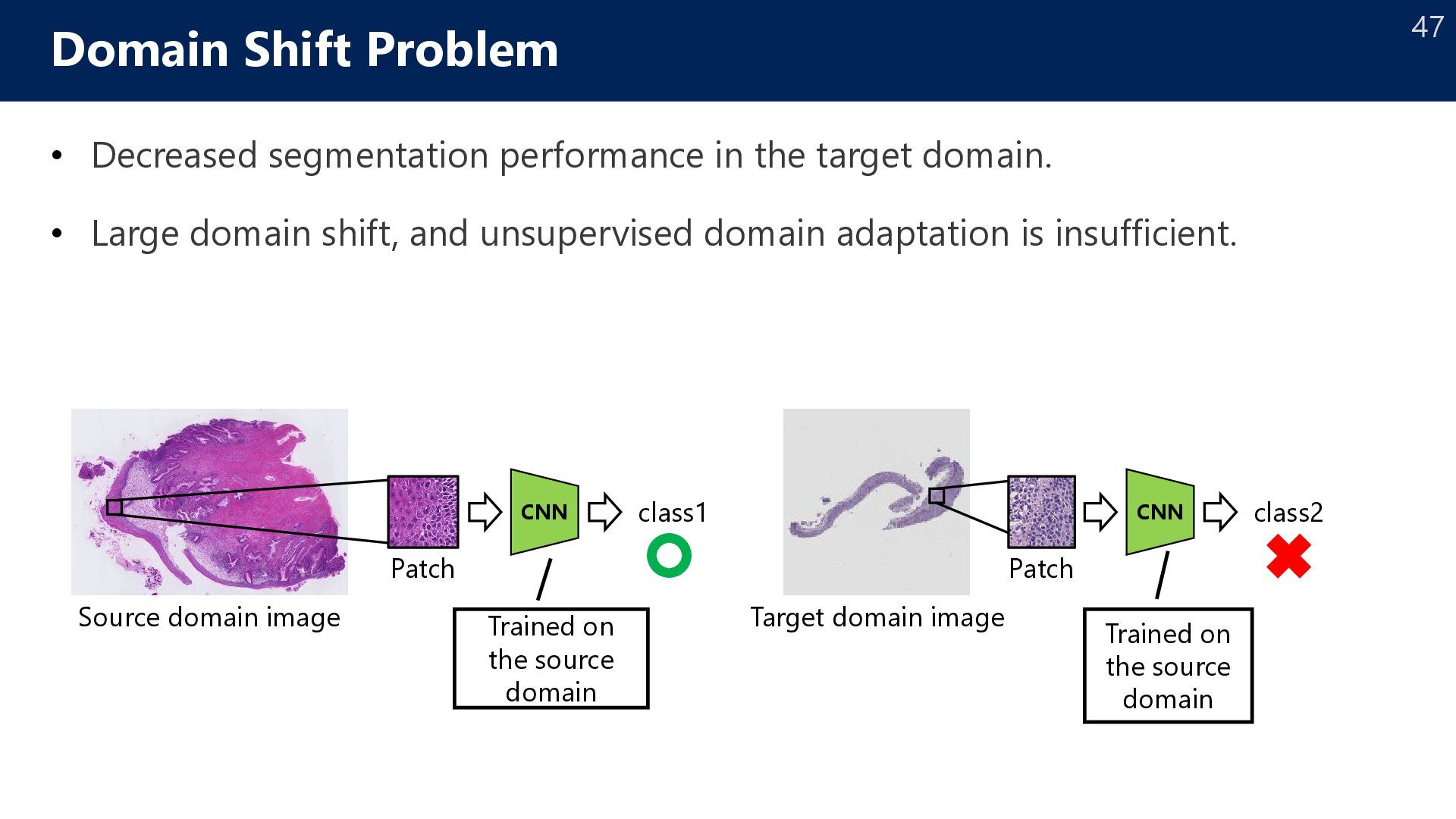
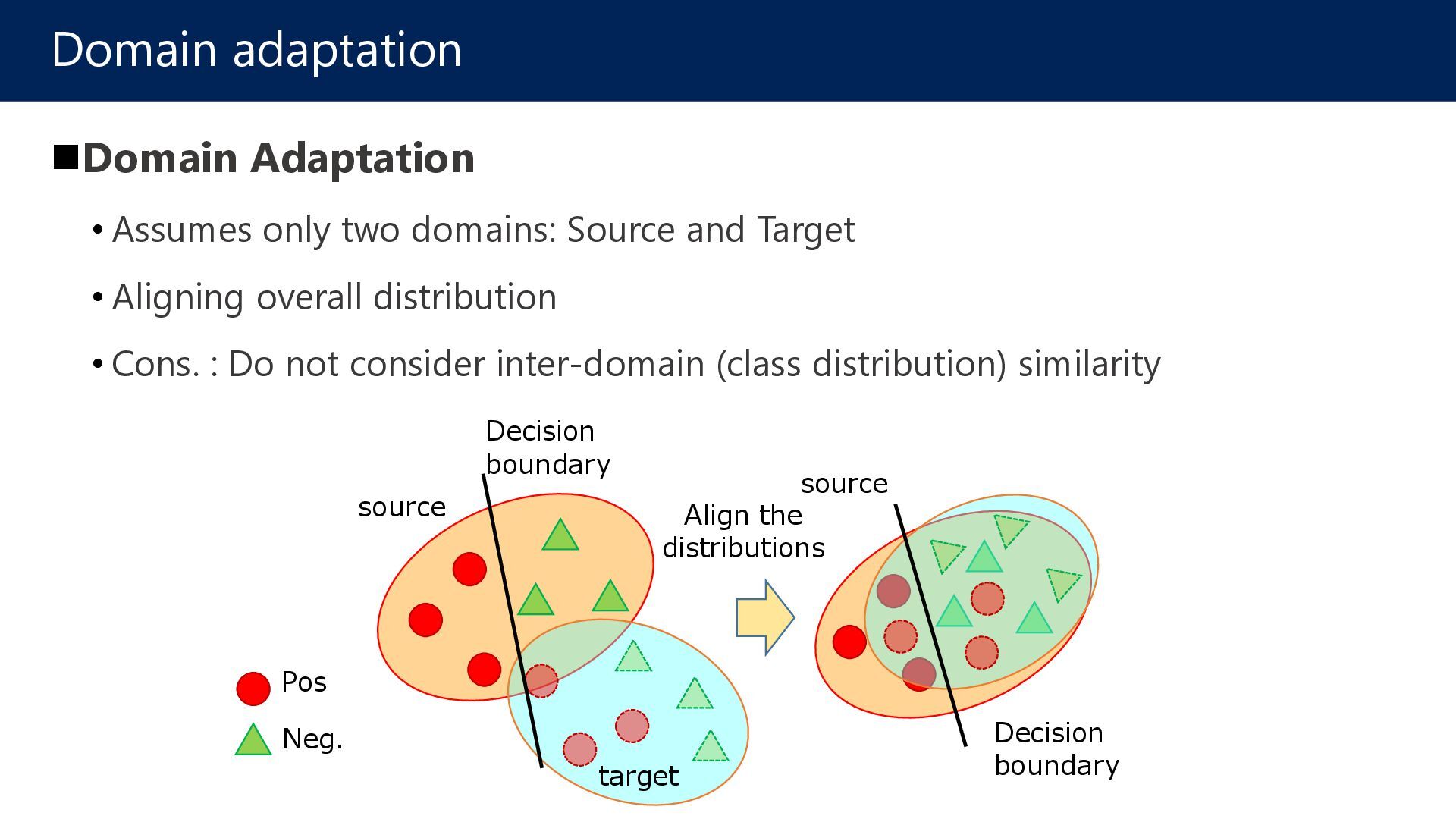
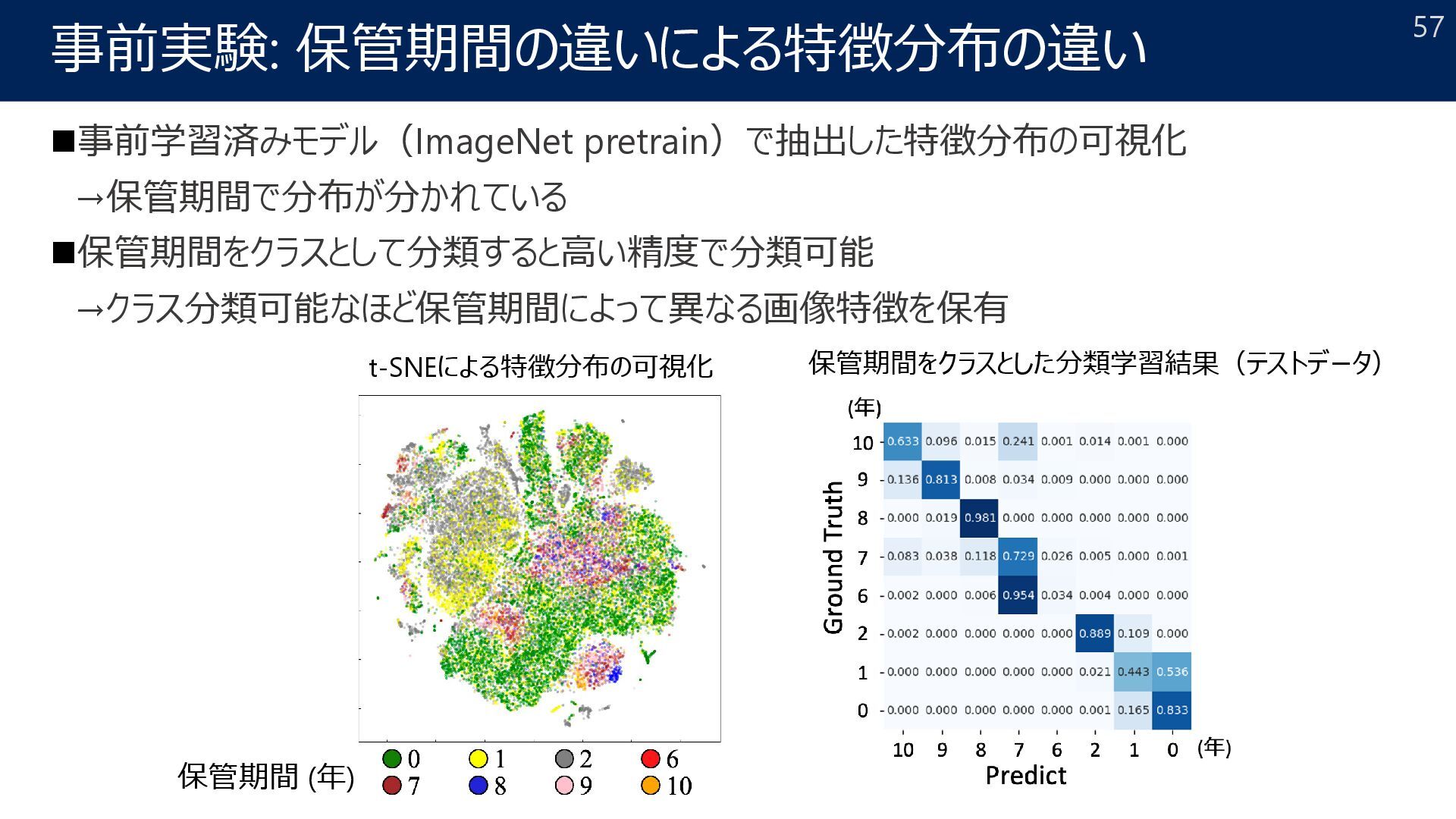
Large domain shift, and unsupervised domain adaptation is insufficient. Domain Shift Problem Source domain image Patch CNN class1 Trained on the source domain Target domain image Patch CNN class2 Trained on the source domain
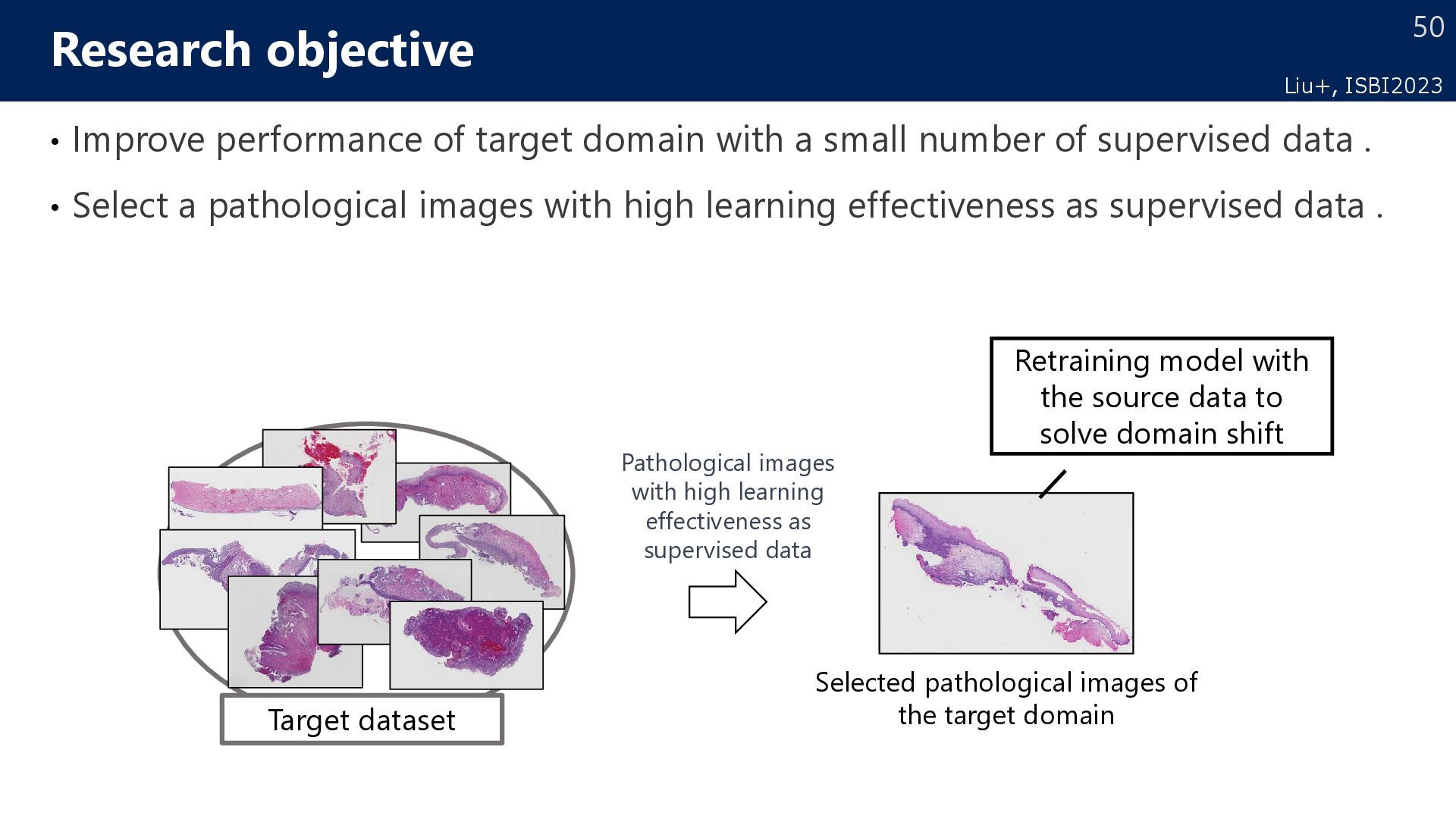
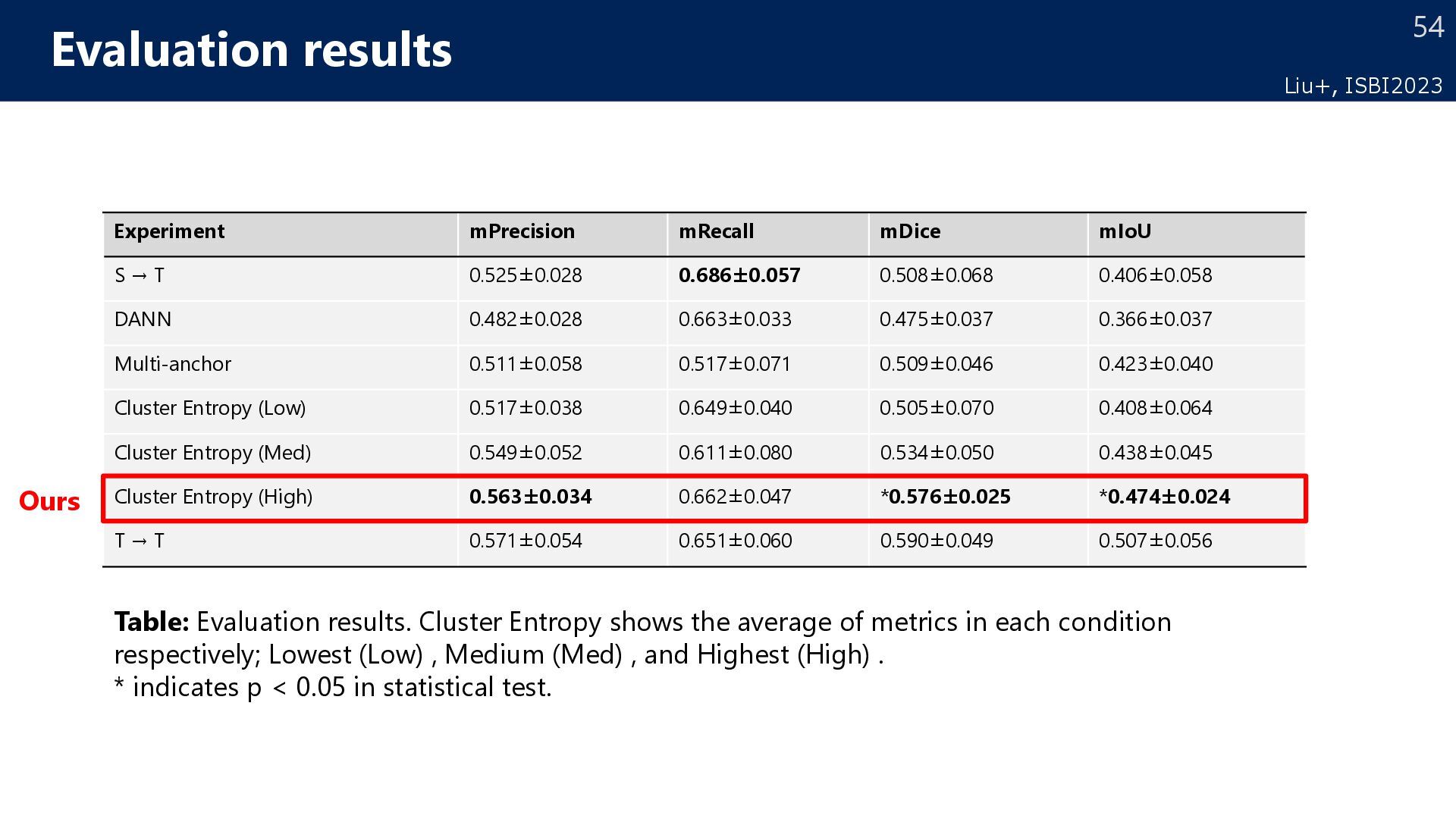
number of supervised data . • Select a pathological images with high learning effectiveness as supervised data . Research objective Target dataset Selected pathological images of the target domain Pathological images with high learning effectiveness as supervised data Retraining model with the source data to solve domain shift Liu+, ISBI2023
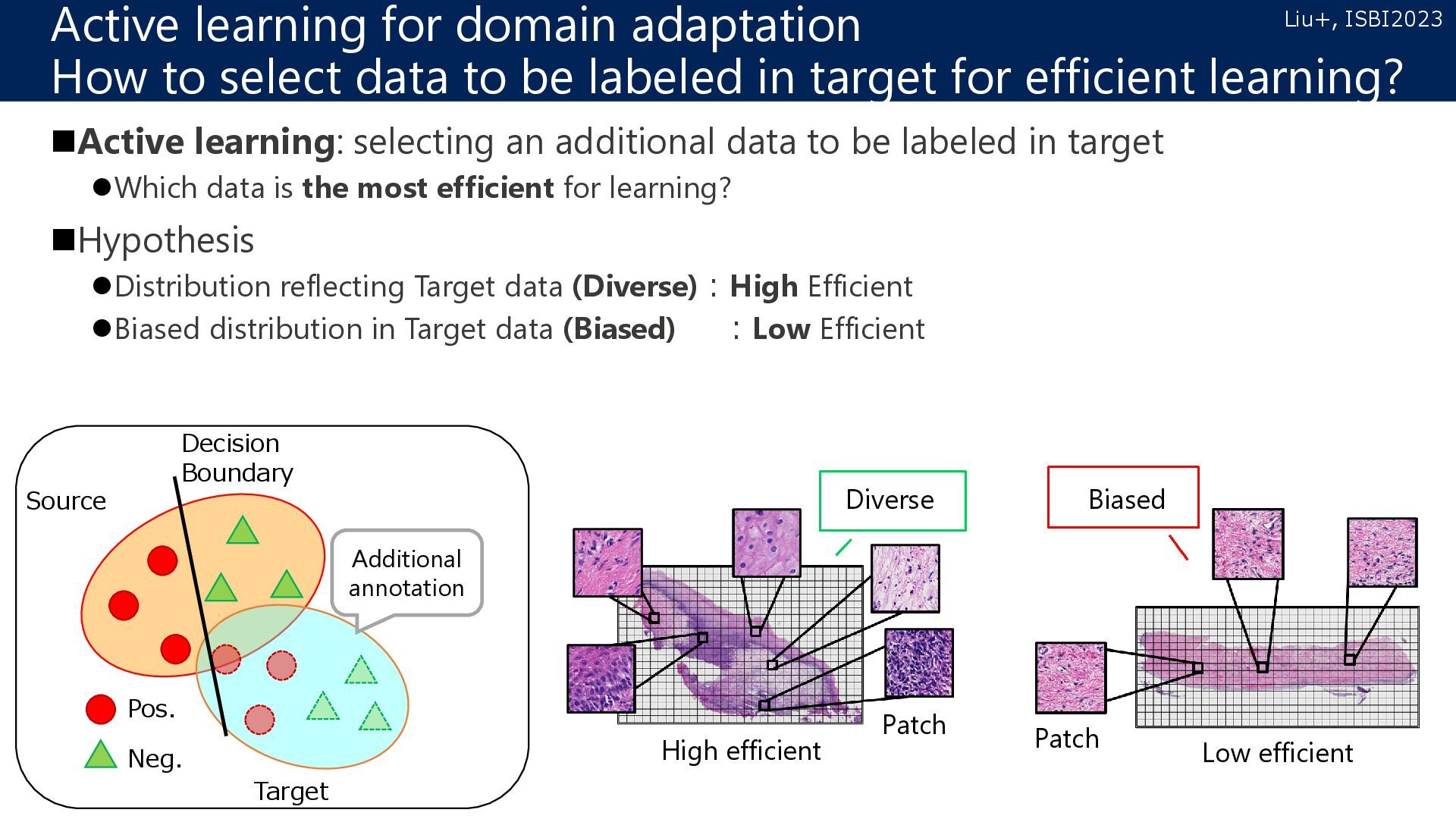
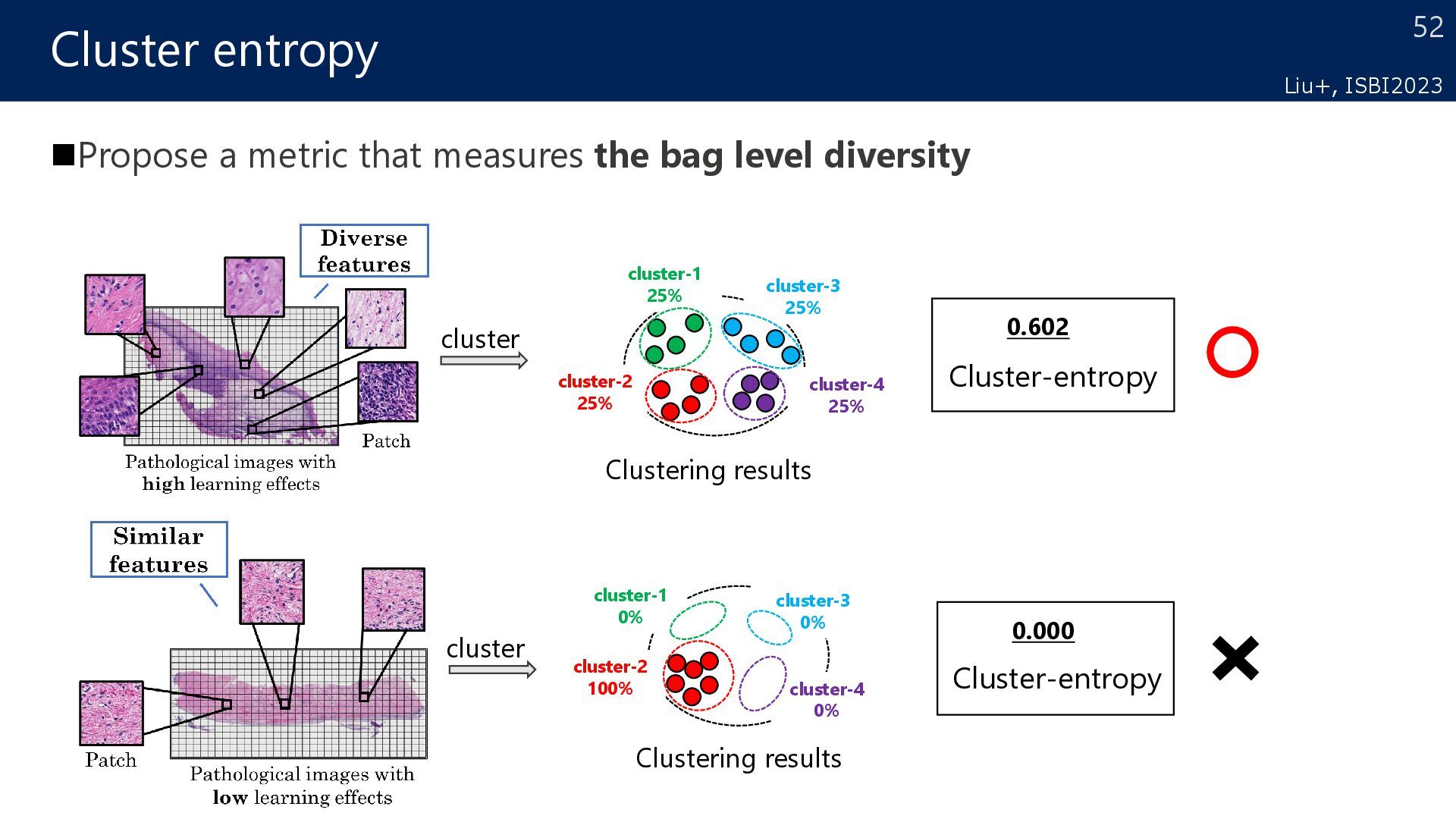
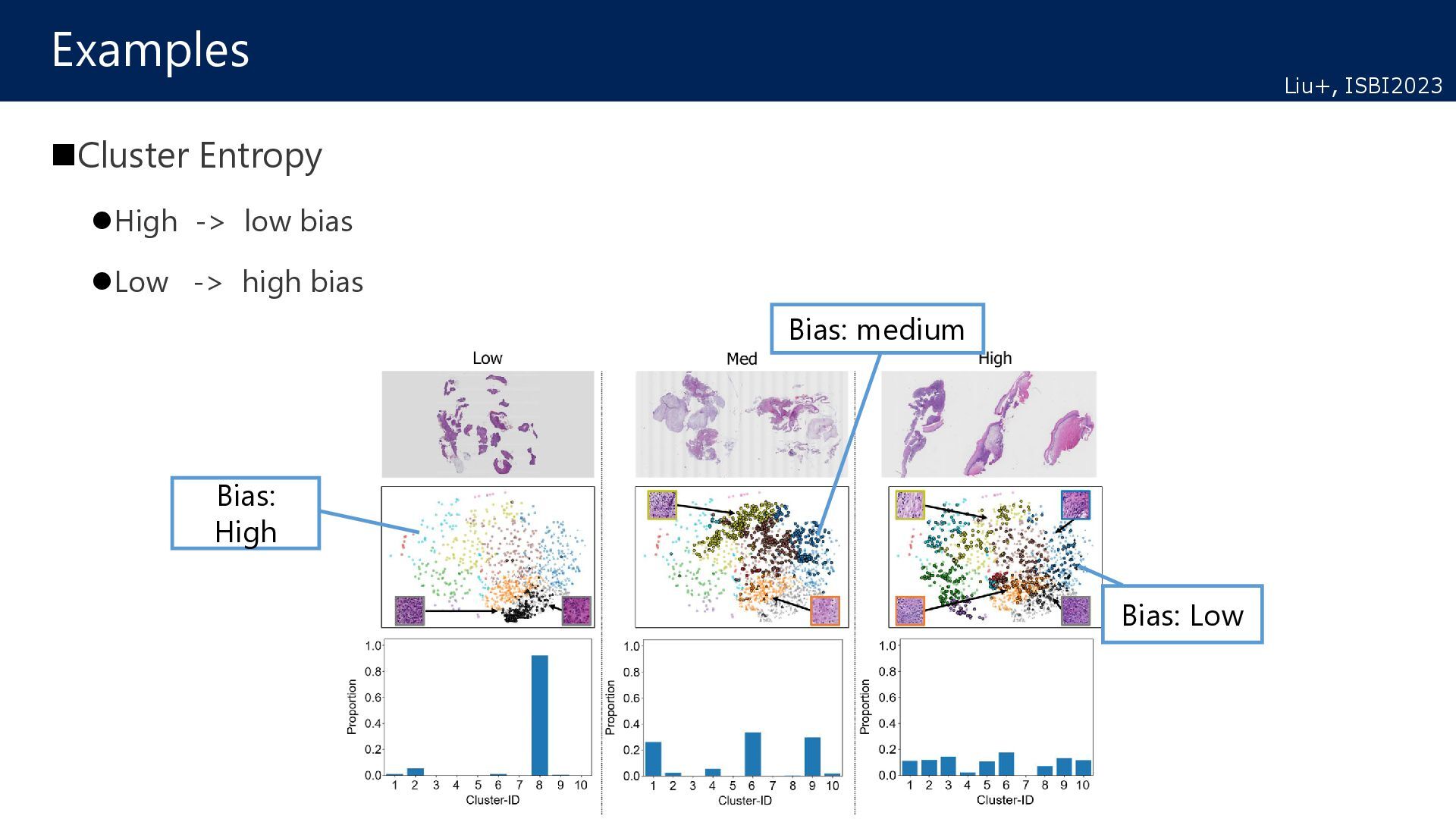
target Which data is the most efficient for learning? Hypothesis Distribution reflecting Target data (Diverse):High Efficient Biased distribution in Target data (Biased) :Low Efficient Active learning for domain adaptation How to select data to be labeled in target for efficient learning? Source Target Decision Boundary Pos. Neg. Additional annotation Diverse Biased Patch Patch High efficient Low efficient Liu+, ISBI2023
Yuki Shigeyasu1, Shota Harada1, Akihiko Yoshizawa3, Kazuhiro Terada2, and Ryoma Bise1 1Kyushu University, 2Kyoto University Hospital, 3Nara Medical University IEEE International Symposium on Biomedical Imaging (ISBI), 2024. 55
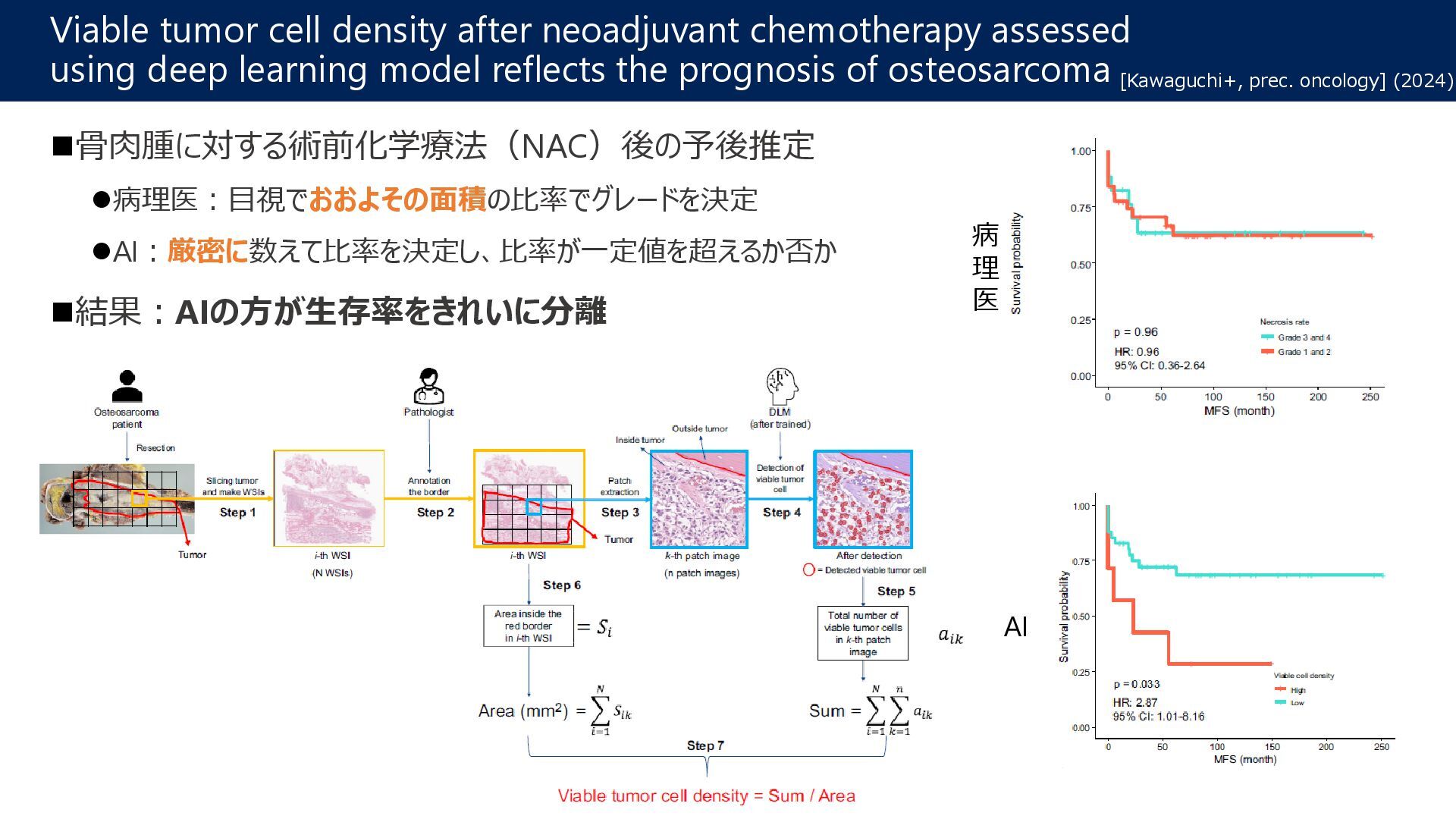
learning model reflects the prognosis of osteosarcoma [Kawaguchi+, prec. oncology] (2024) 骨肉腫に対する術前化学療法(NAC)後の予後推定 病理医:目視でおおよその面積の比率でグレードを決定 AI:厳密に数えて比率を決定し、比率が一定値を超えるか否か 結果:AIの方が生存率をきれいに分離 AI 病 理 医
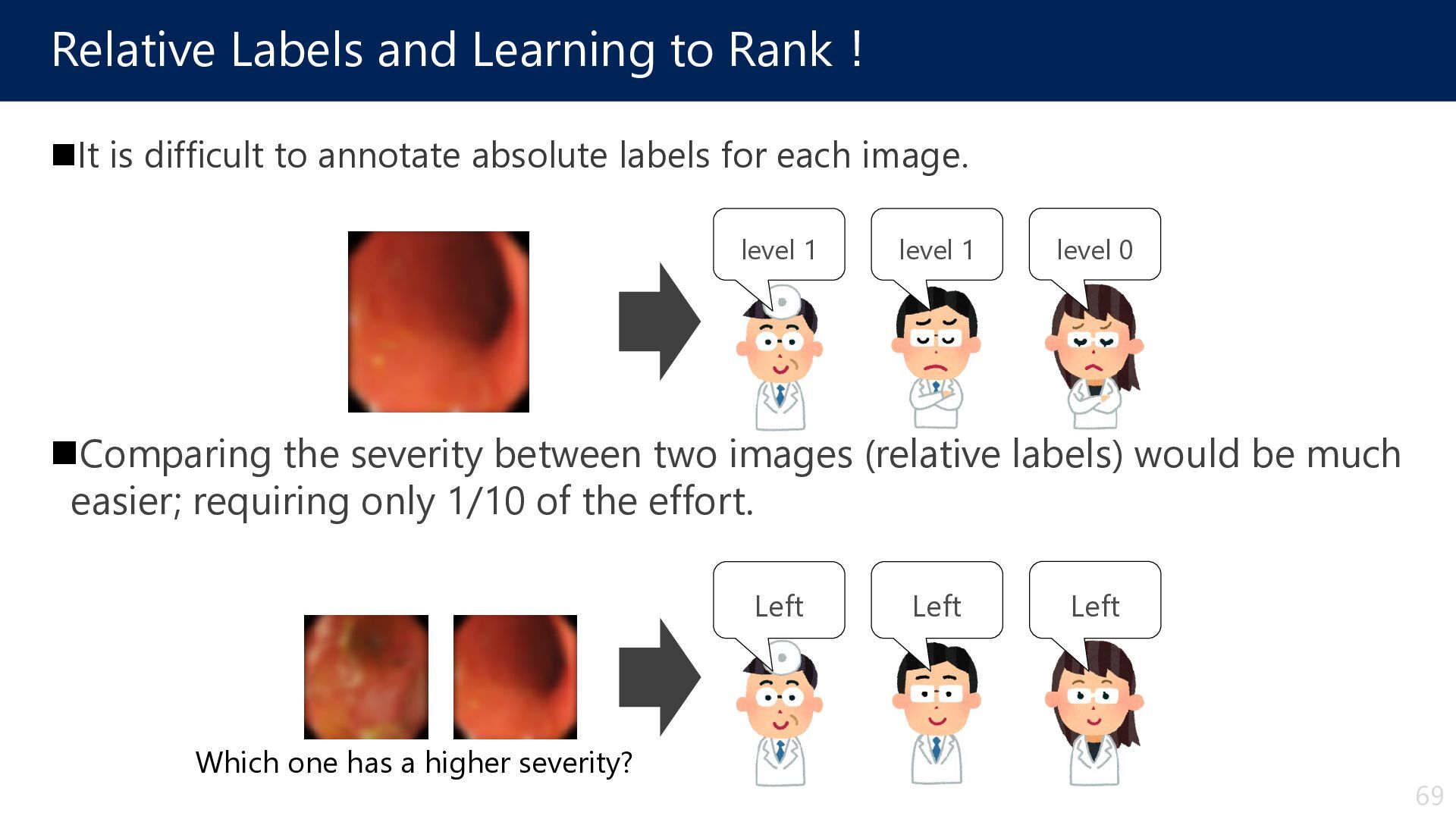
annotate absolute labels for each image. Comparing the severity between two images (relative labels) would be much easier; requiring only 1/10 of the effort. level 1 level 1 level 0 Left Left Left Which one has a higher severity? 69
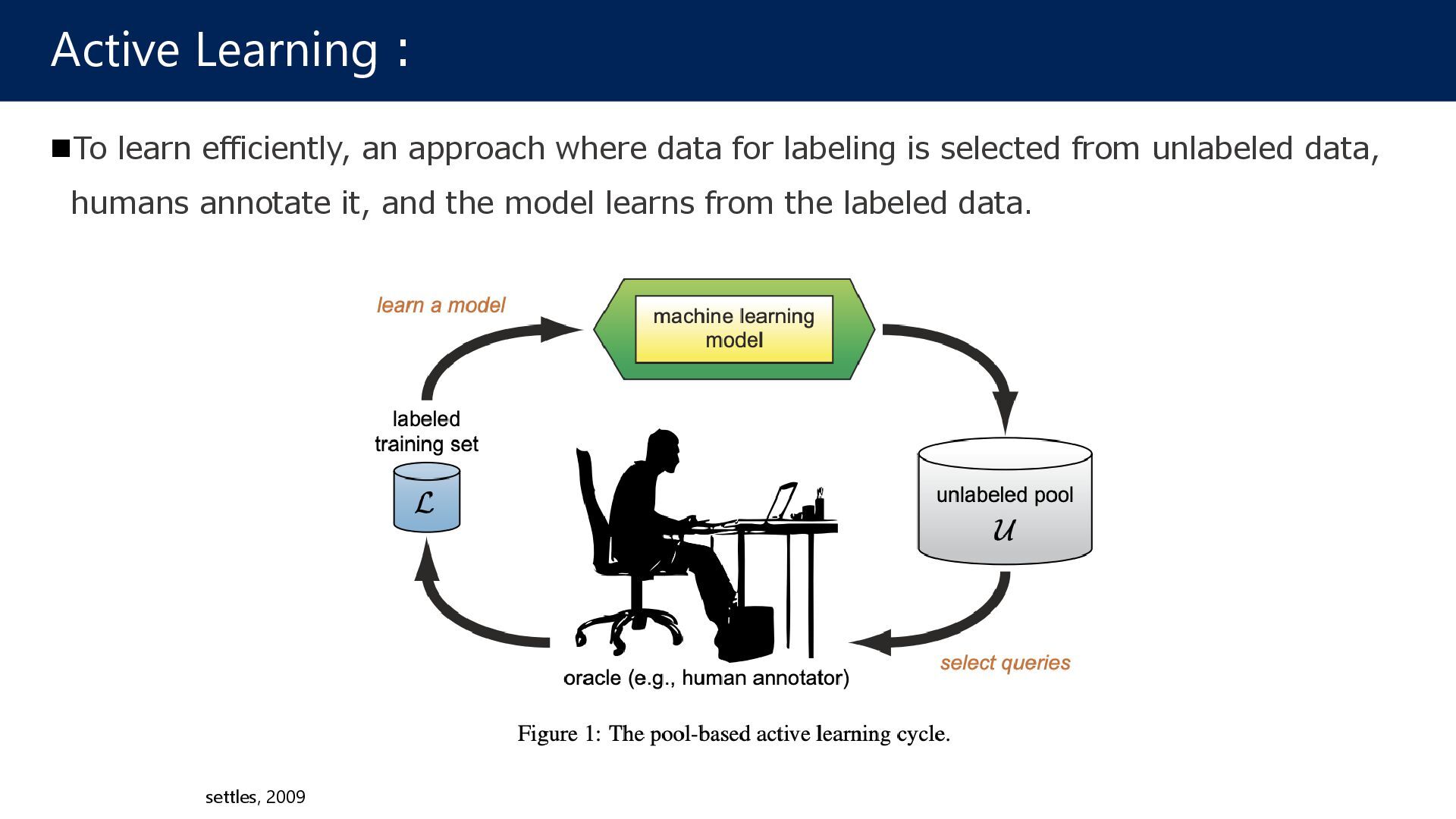
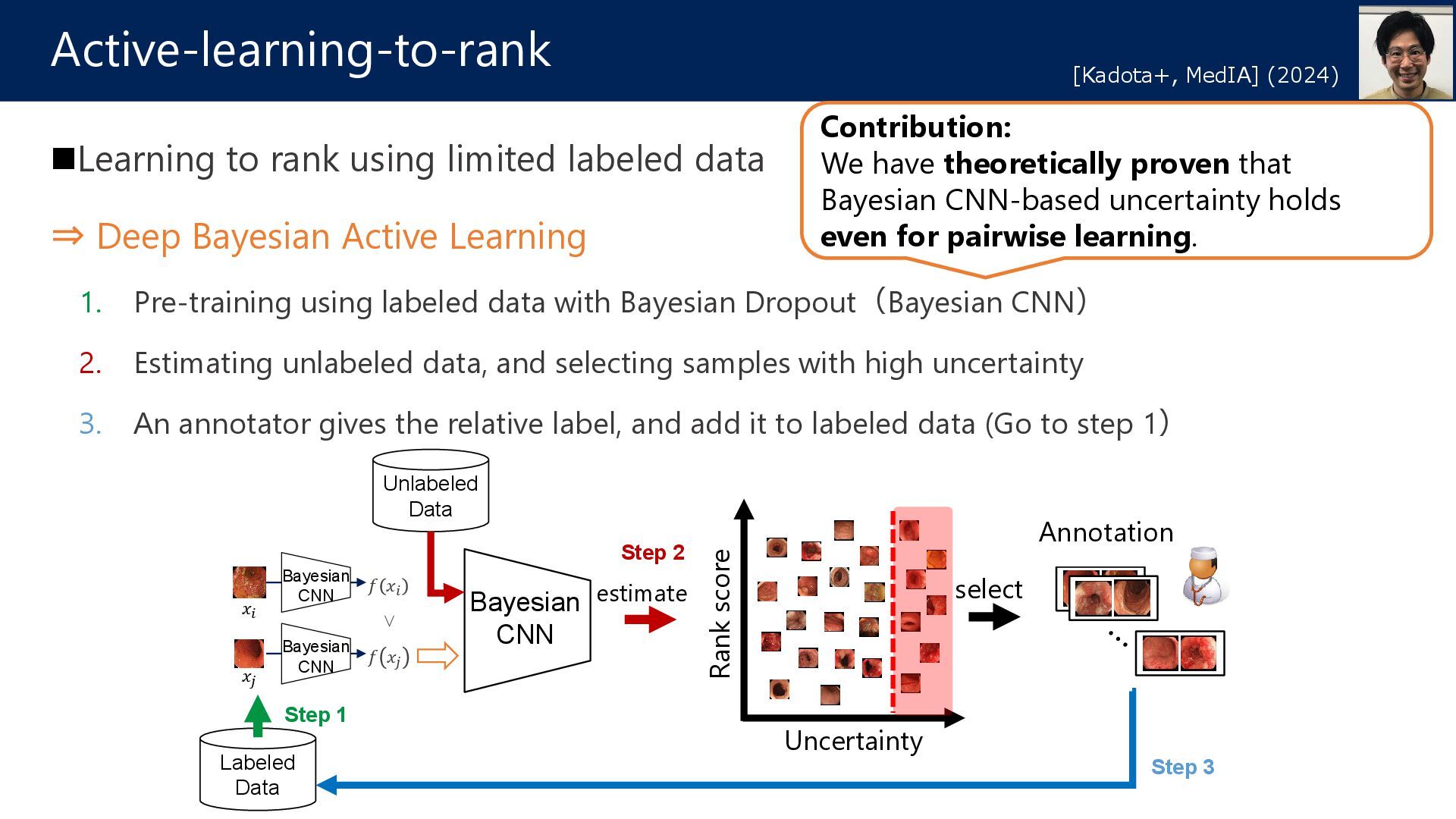
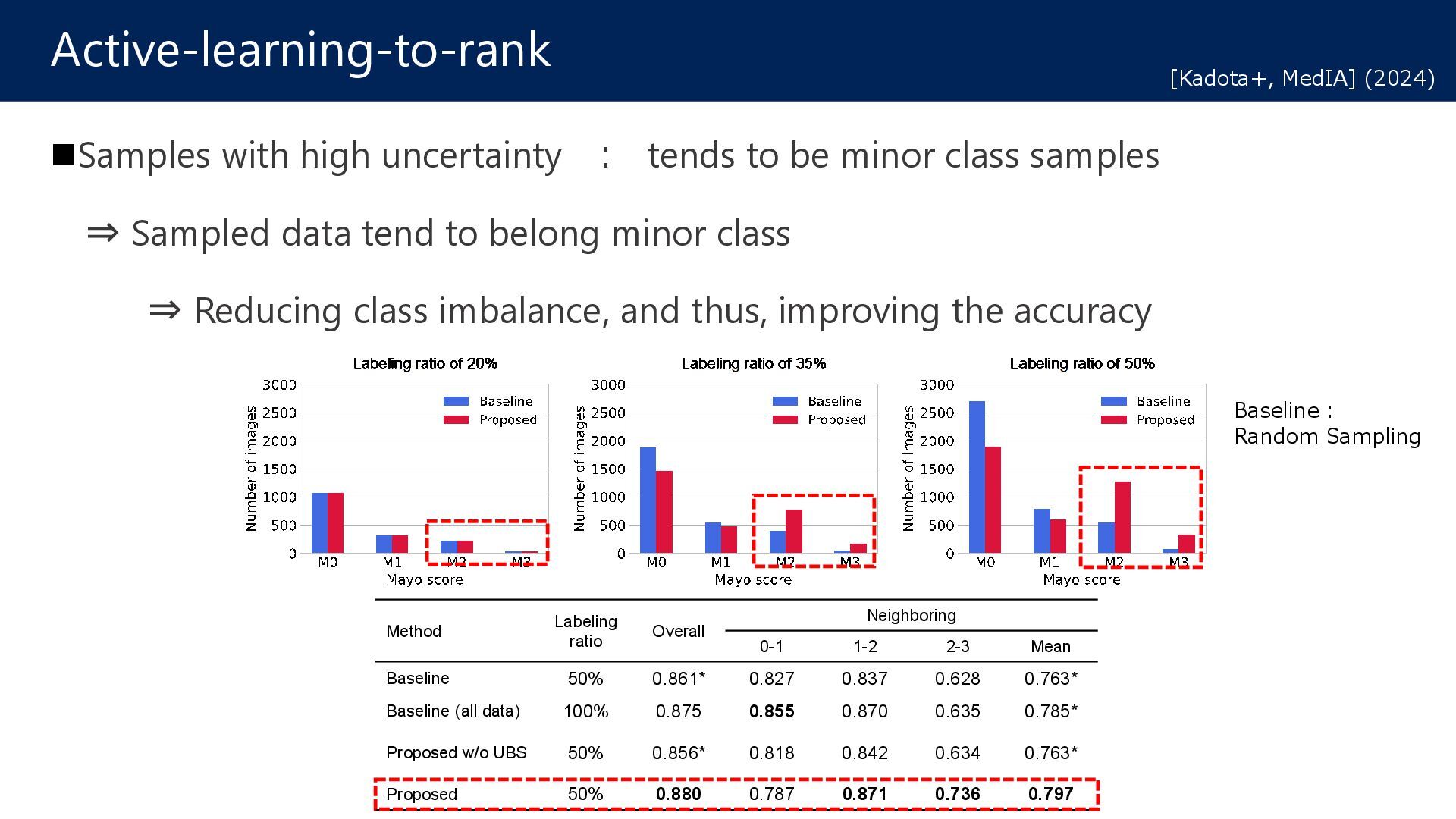
Active Learning 1. Pre-training using labeled data with Bayesian Dropout(Bayesian CNN) 2. Estimating unlabeled data, and selecting samples with high uncertainty 3. An annotator gives the relative label, and add it to labeled data (Go to step 1) Active-learning-to-rank [Kadota+, MedIA] (2024) Uncertainty Bayesian CNN 𝑥𝑥𝑖𝑖 𝑥𝑥𝑗𝑗 𝑓𝑓 𝑥𝑥𝑖𝑖 𝑓𝑓 𝑥𝑥𝑗𝑗 Bayesian CNN Bayesian CNN < select estimate Rank score Unlabeled Data Labeled Data Step 1 Step 2 Step 3 Annotation Contribution: We have theoretically proven that Bayesian CNN-based uncertainty holds even for pairwise learning.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![「できるかぎり」ヒントを信じる(時には無視してもOK) ソフト制約付きクラスタリング cannot (hard) must (soft) 精度(purity) 改善 [九大×田中先生の共著] 一種の最適化](https://files.speakerdeck.com/presentations/17da6198dbae456692edf6527e2133a2/slide_67.jpg){kind=link}
{kind=link}
![70 大量の相対ラベルと少量の絶対ラベルから, アノテーションコストを削減しながらUC重症度判定を実現 重症度の相対評価の利用:ランキングによるUC重症度判定 [Kadota+, IEEE Access, 2022] 順序 付け](https://files.speakerdeck.com/presentations/17da6198dbae456692edf6527e2133a2/slide_69.jpg){kind=link}
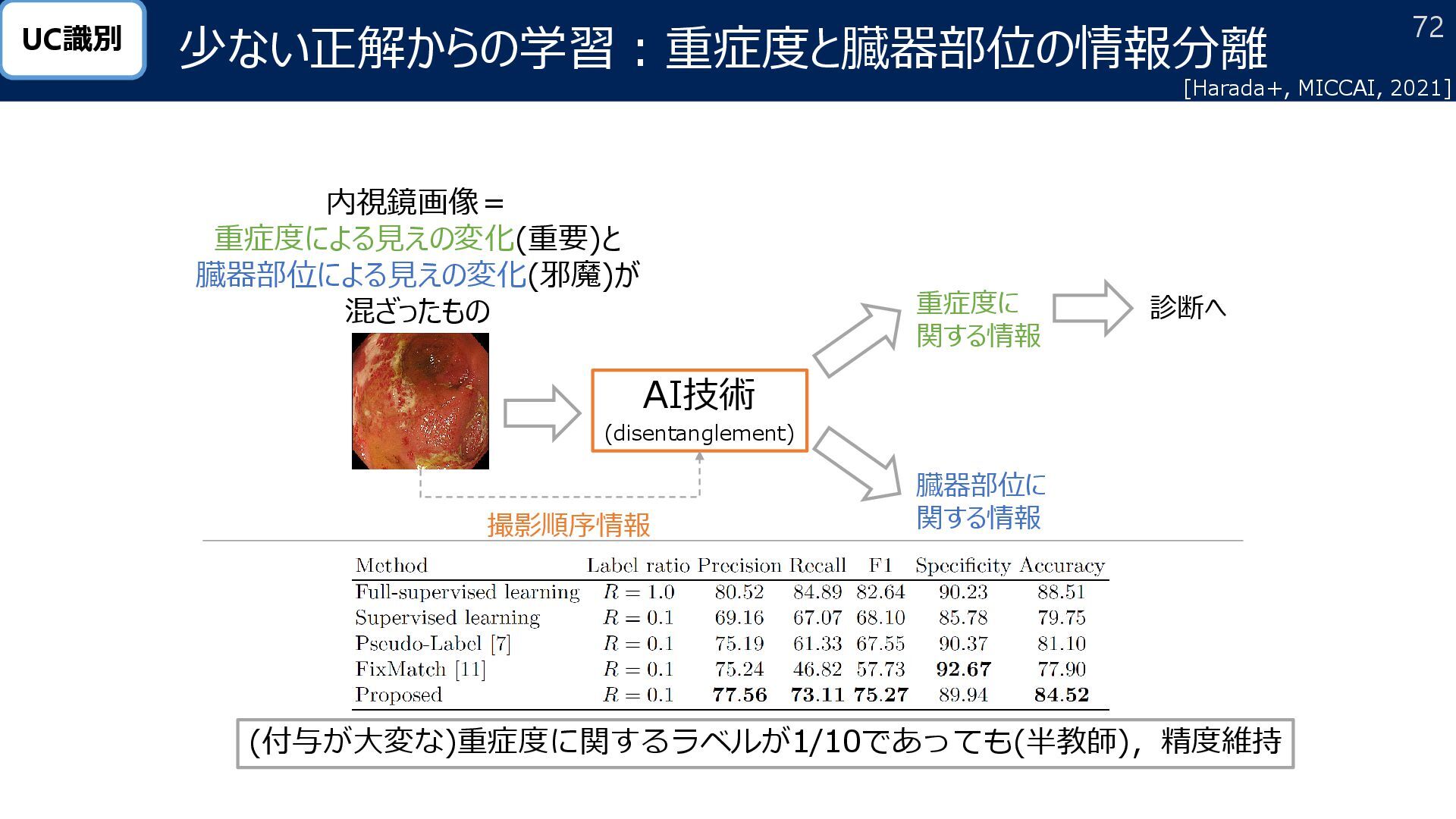
![71 今までは絶対ラベル用AIと相対ラベル用AIを組み合わせていた 1つのAIで絶対ラベルと相対ラベルを取り扱えるように →別々のAIを利用するよりも精度向上 重症度の相対評価の利用: 絶対ラベルと相対ラベルを同時に学習できるAIの開発 [宝満+, MIRU, 2024] UC識別](https://files.speakerdeck.com/presentations/17da6198dbae456692edf6527e2133a2/slide_70.jpg){kind=link}
{kind=link}
{kind=link}
![74 Theoretical proof [Kadota+, MedIA] (2024)](https://files.speakerdeck.com/presentations/17da6198dbae456692edf6527e2133a2/slide_73.jpg){kind=link}
{kind=link}
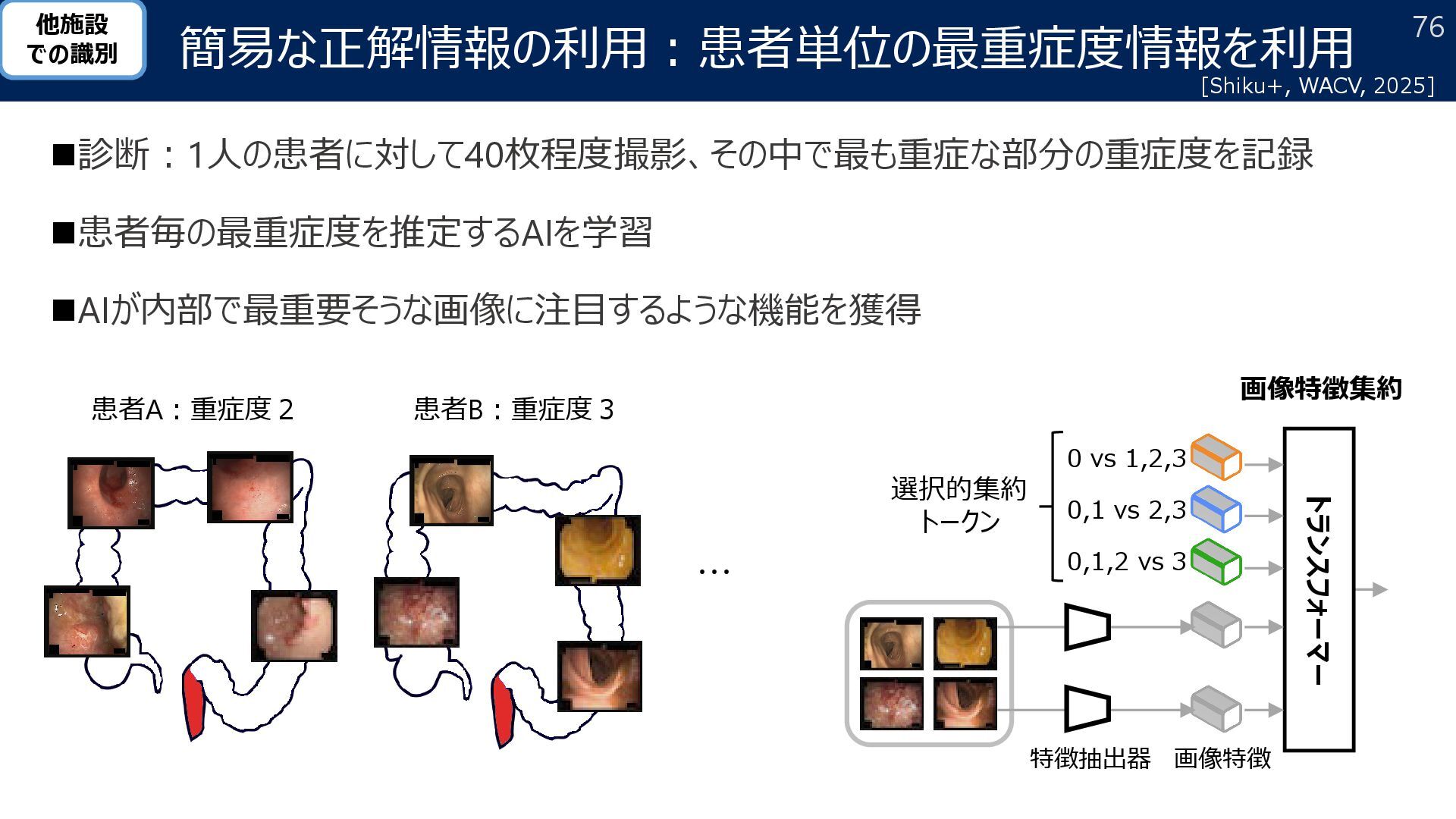{kind=link}
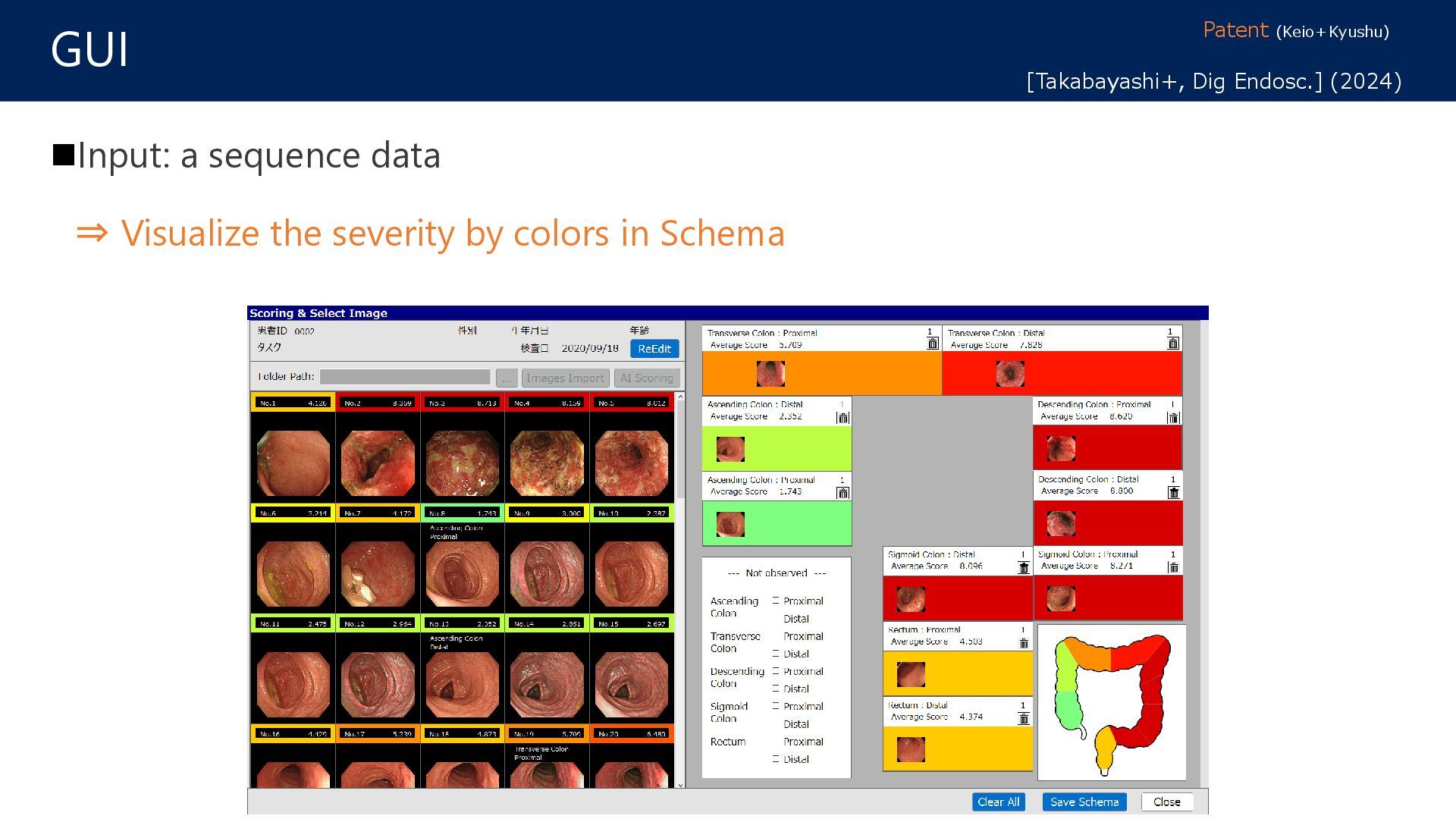{kind=link}
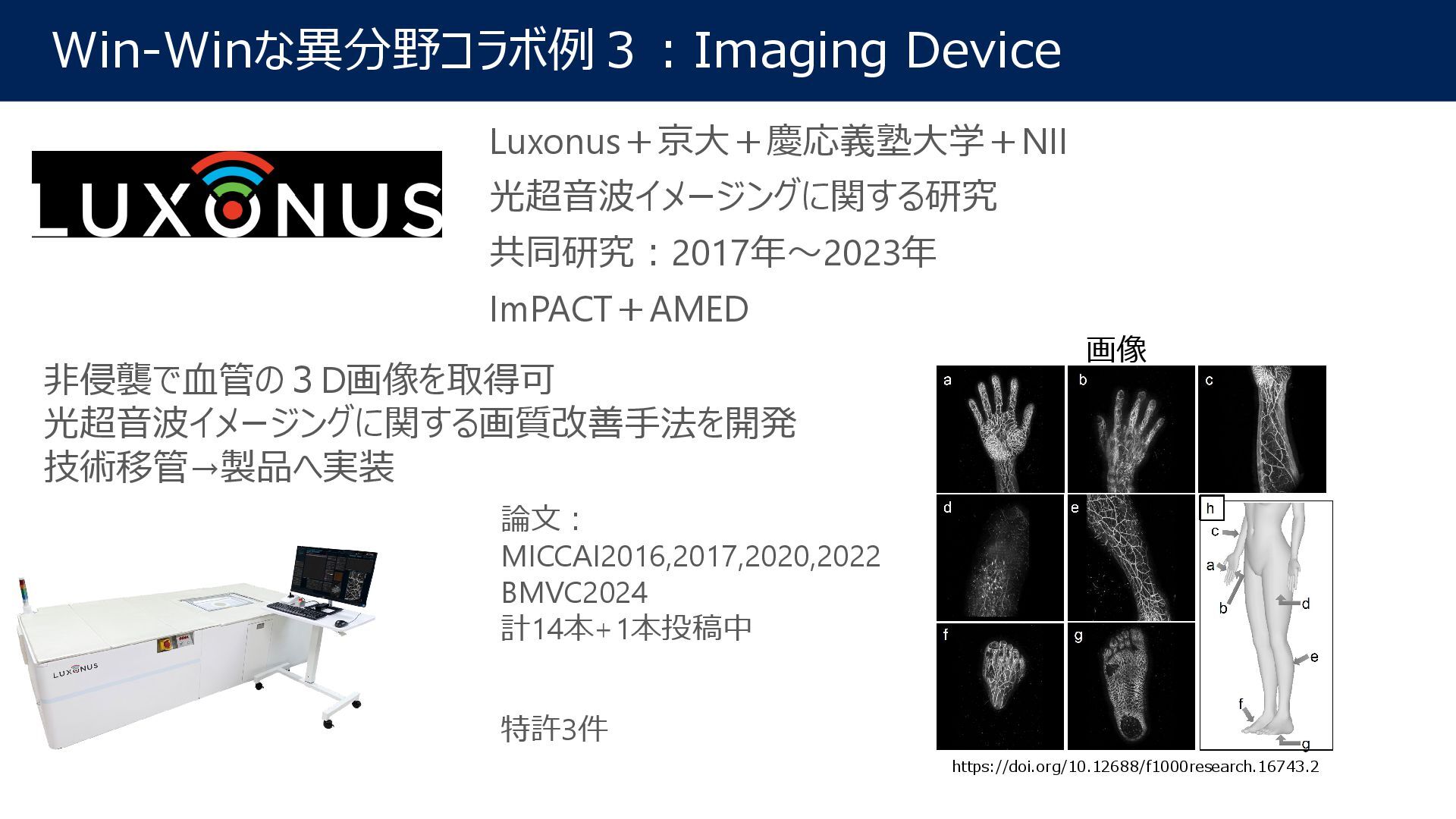{kind=link}
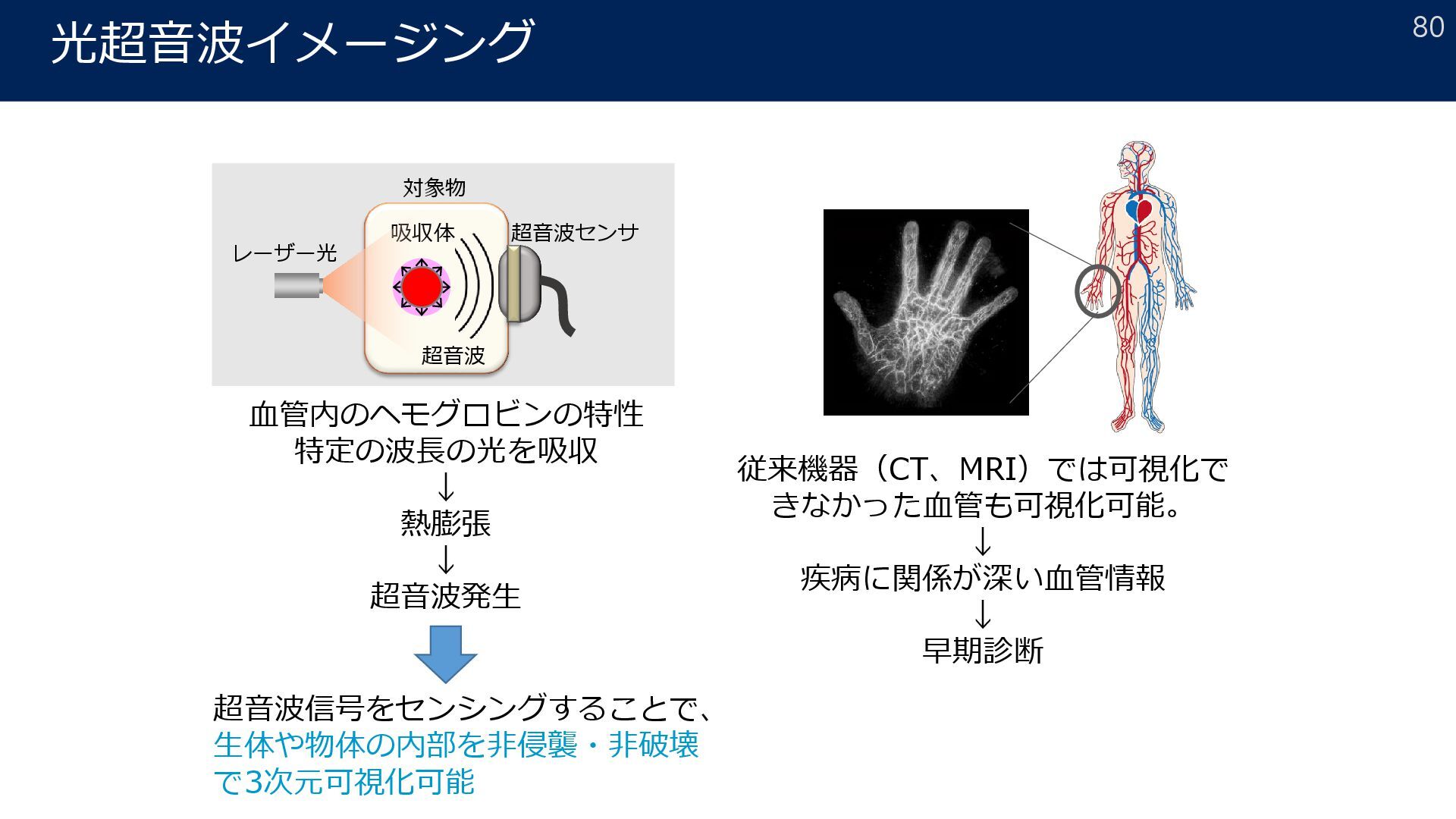{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}