A sharing session in Hello-World Dev Conference 2025.
https://hwdc.ithome.com.tw/2025/session-page/4042
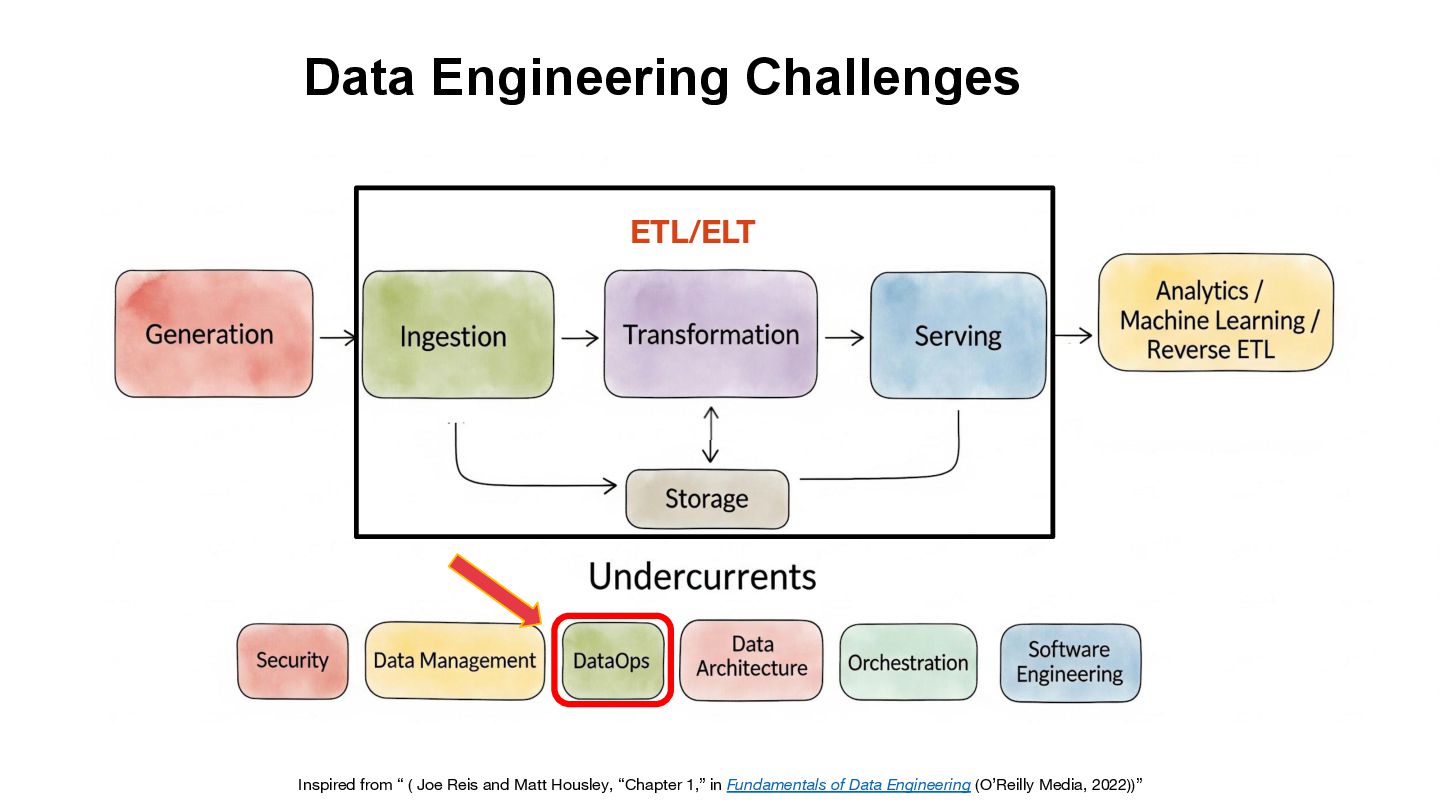
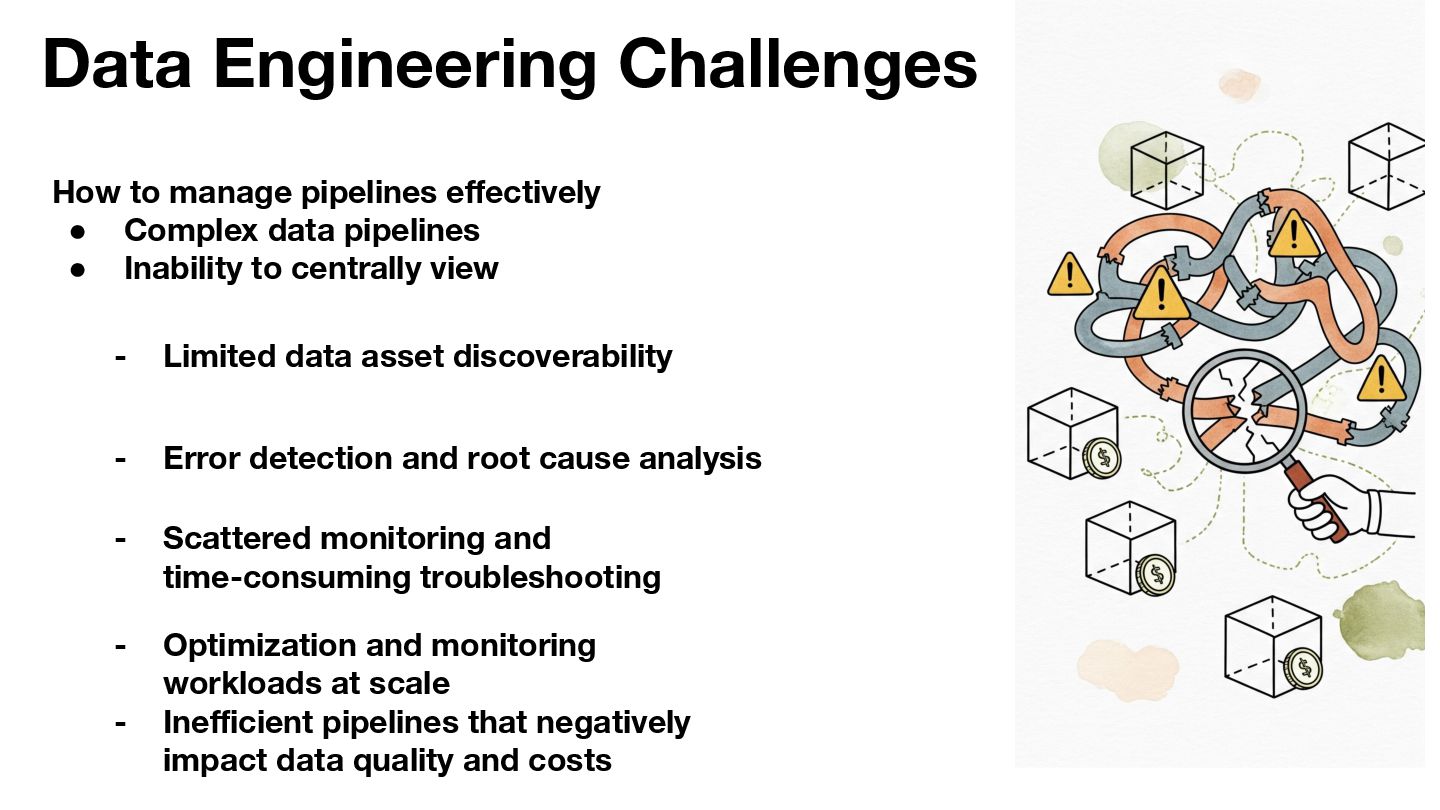
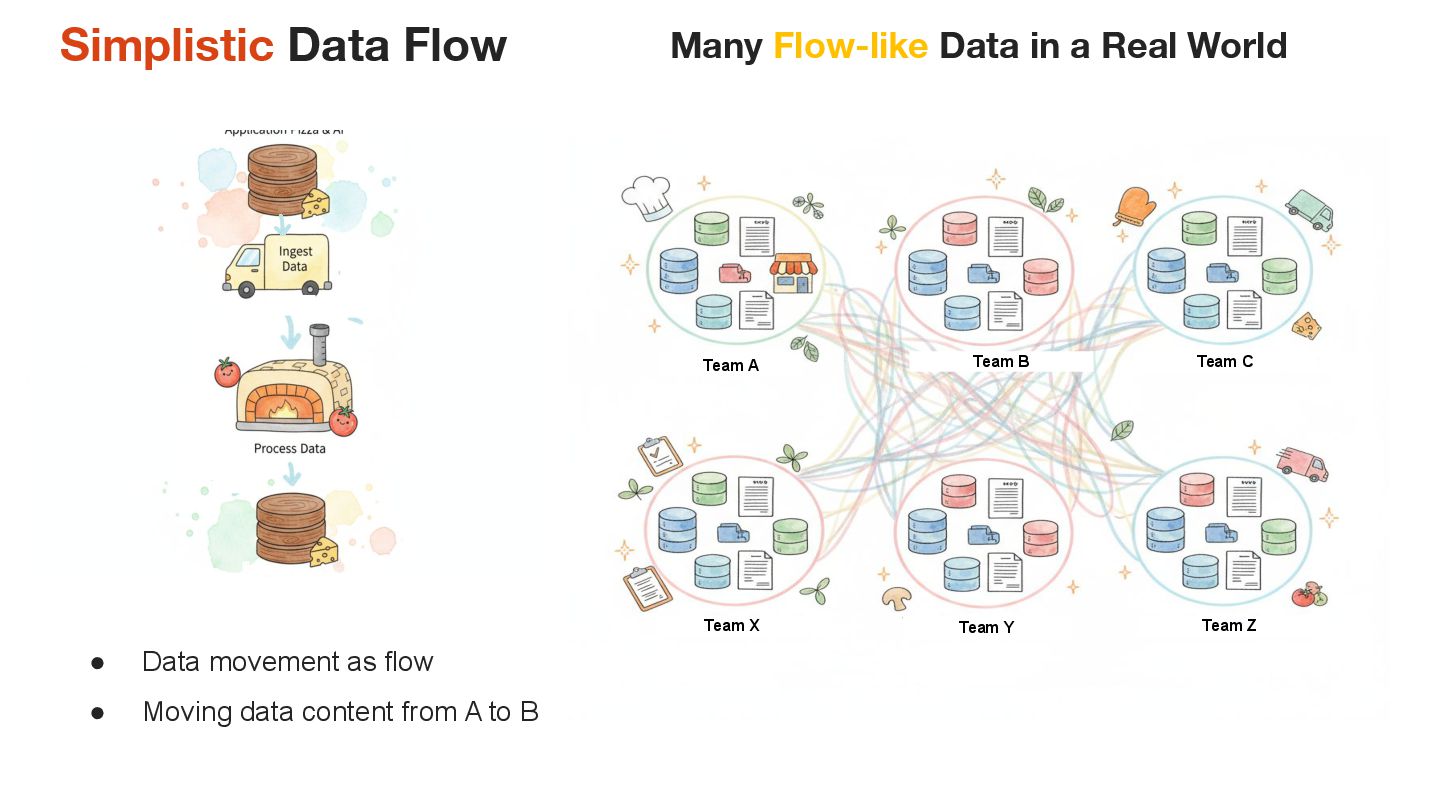
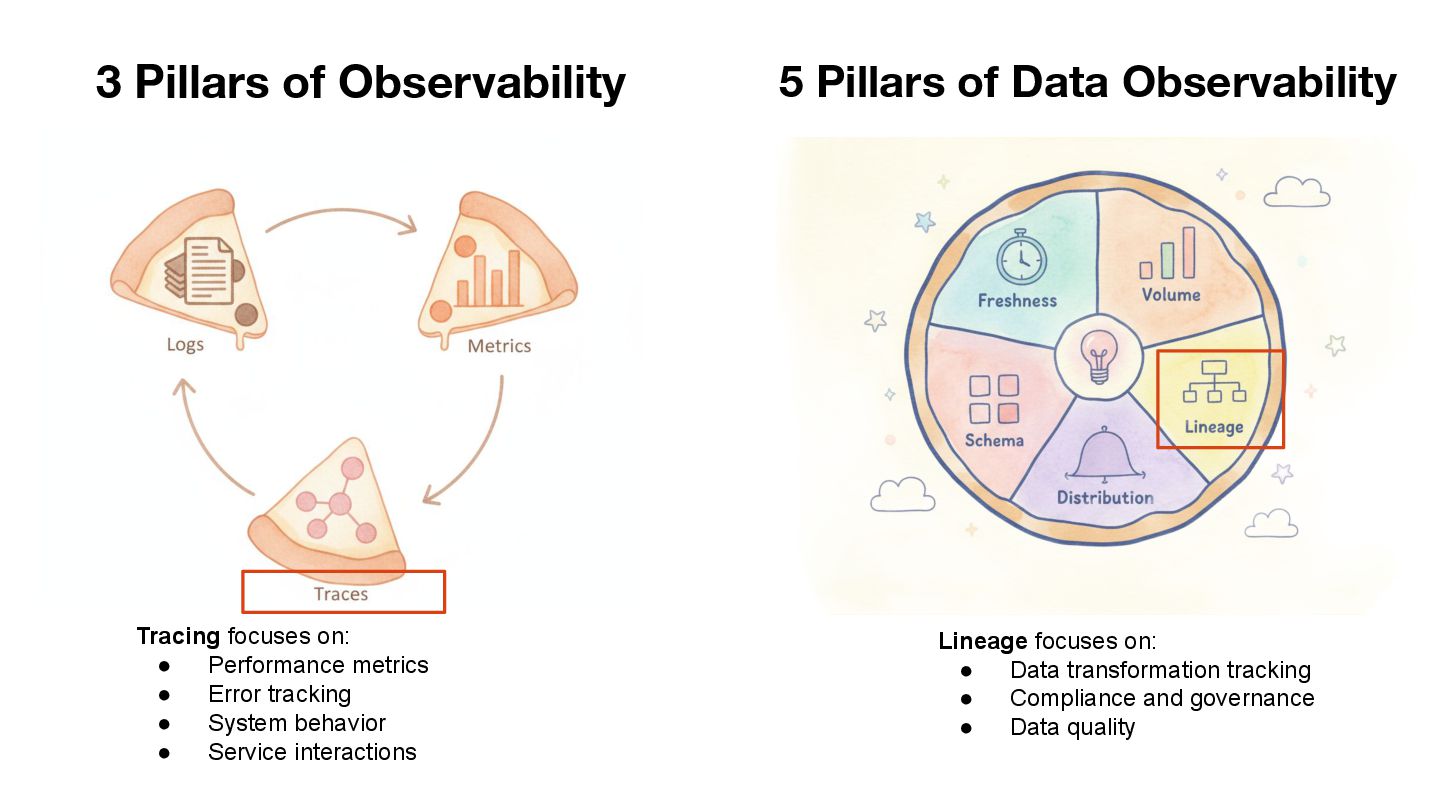
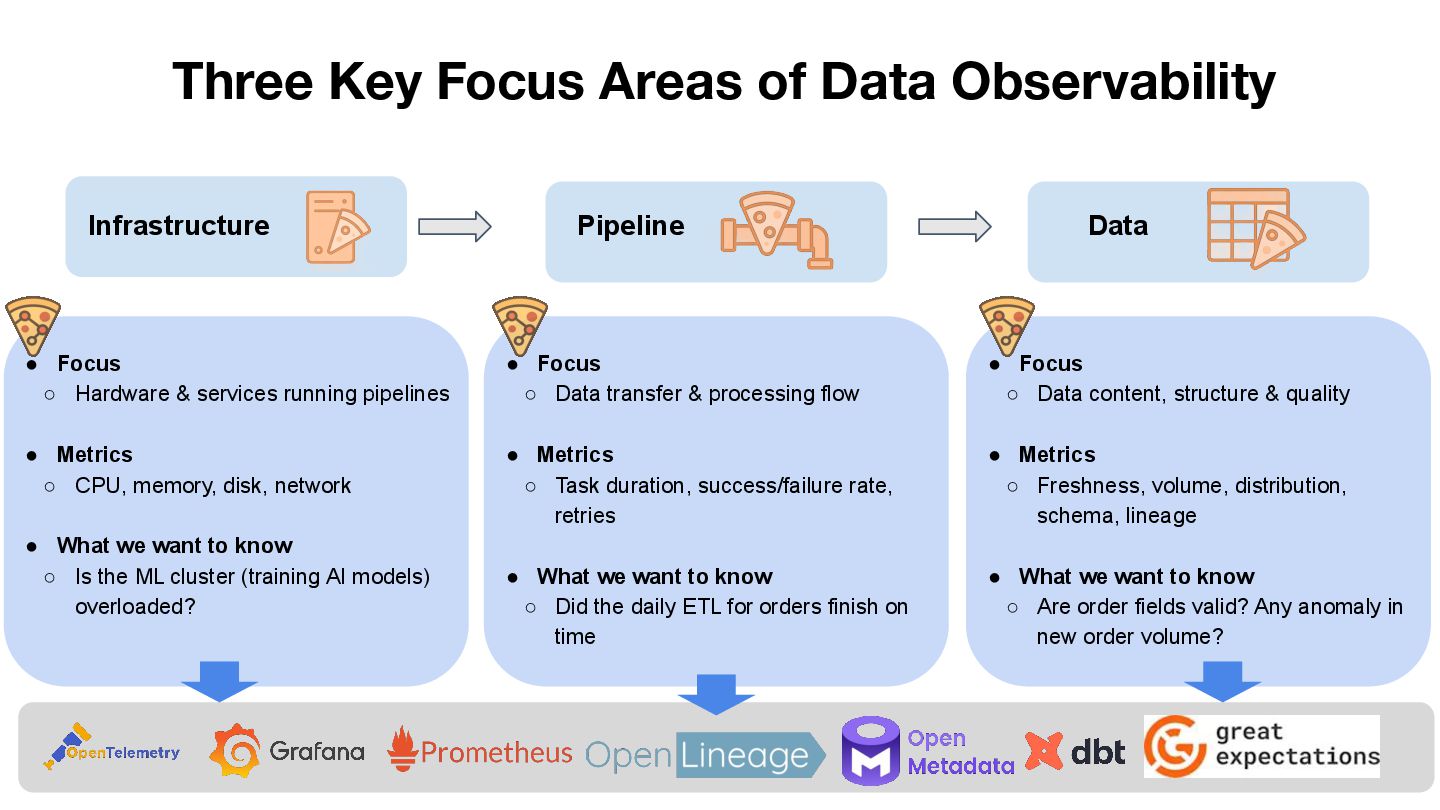
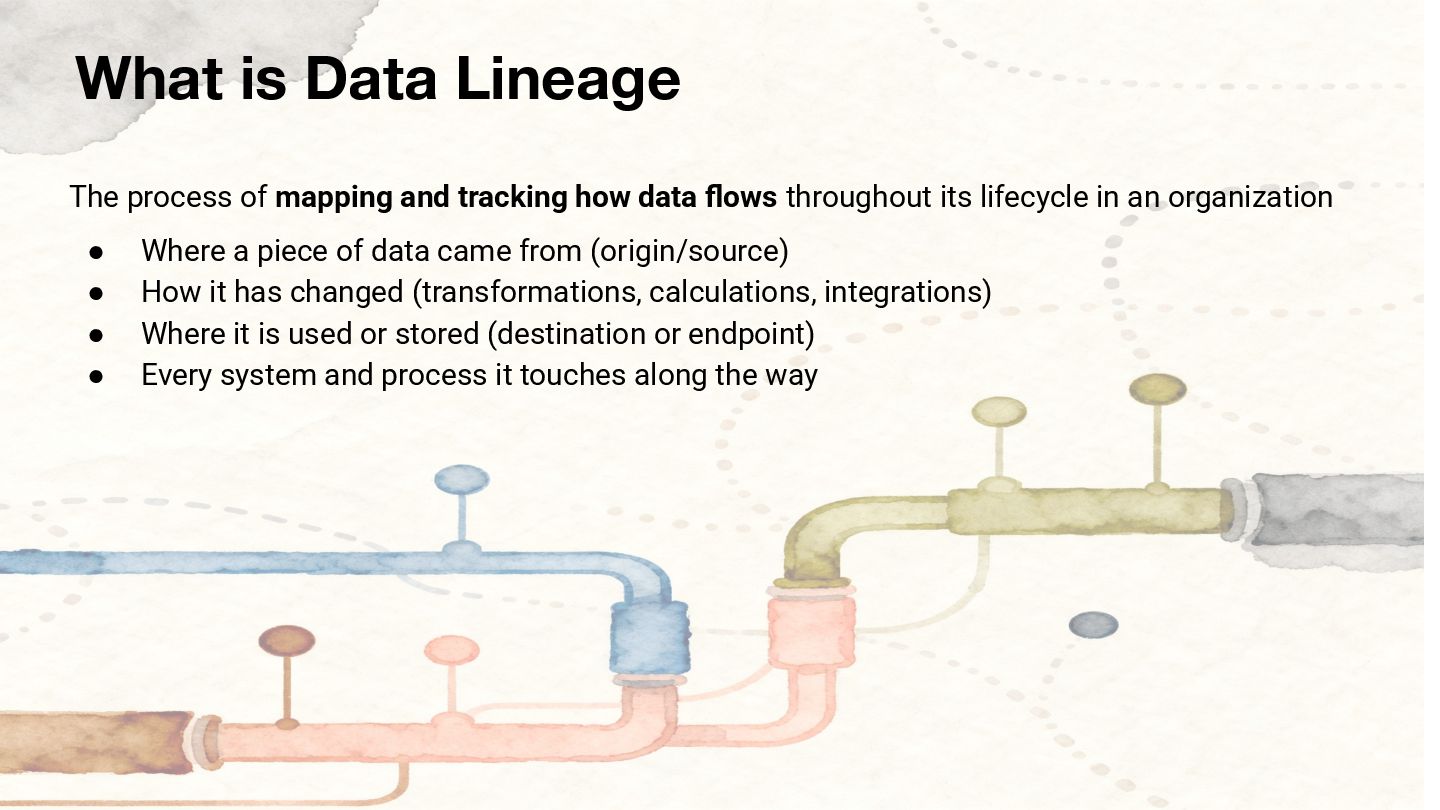
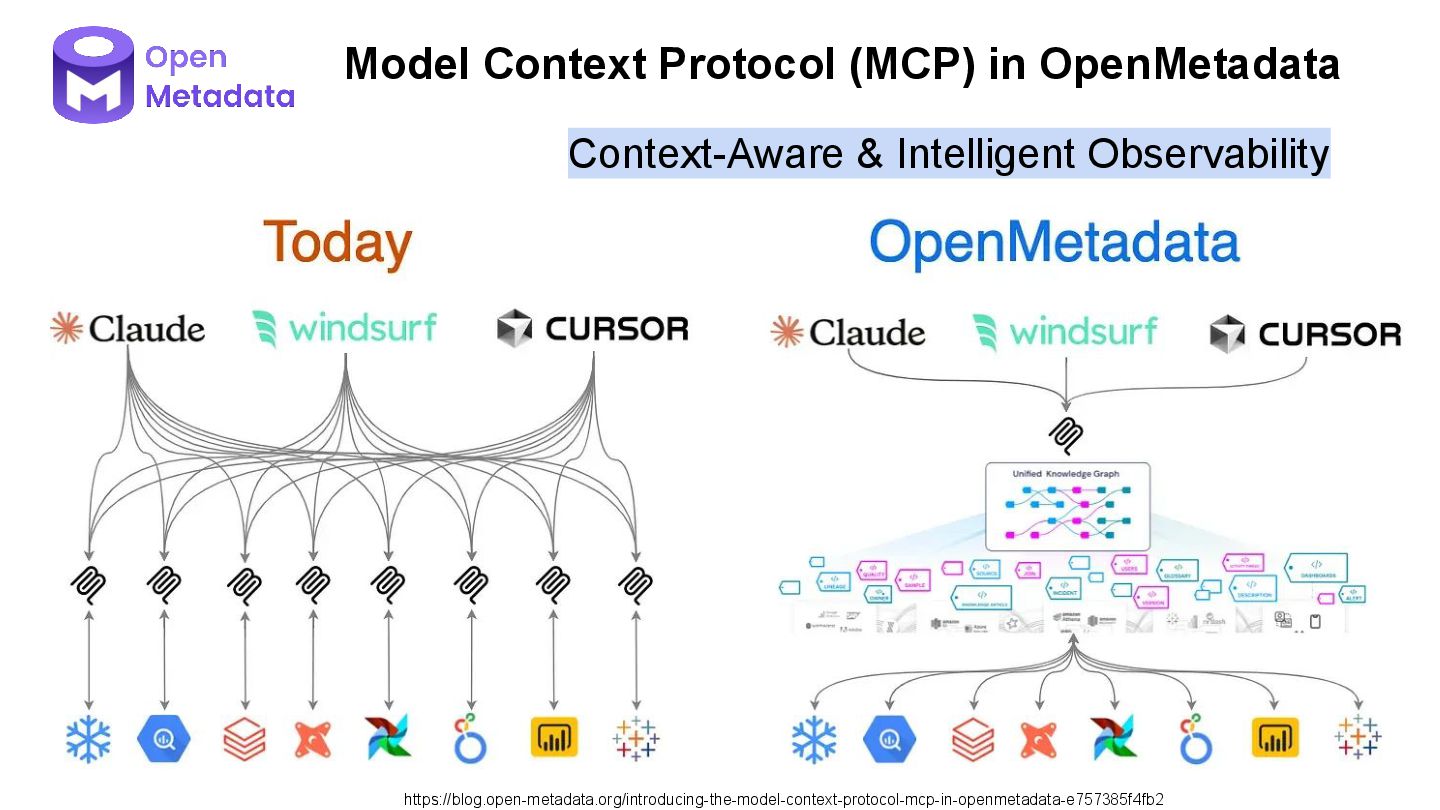
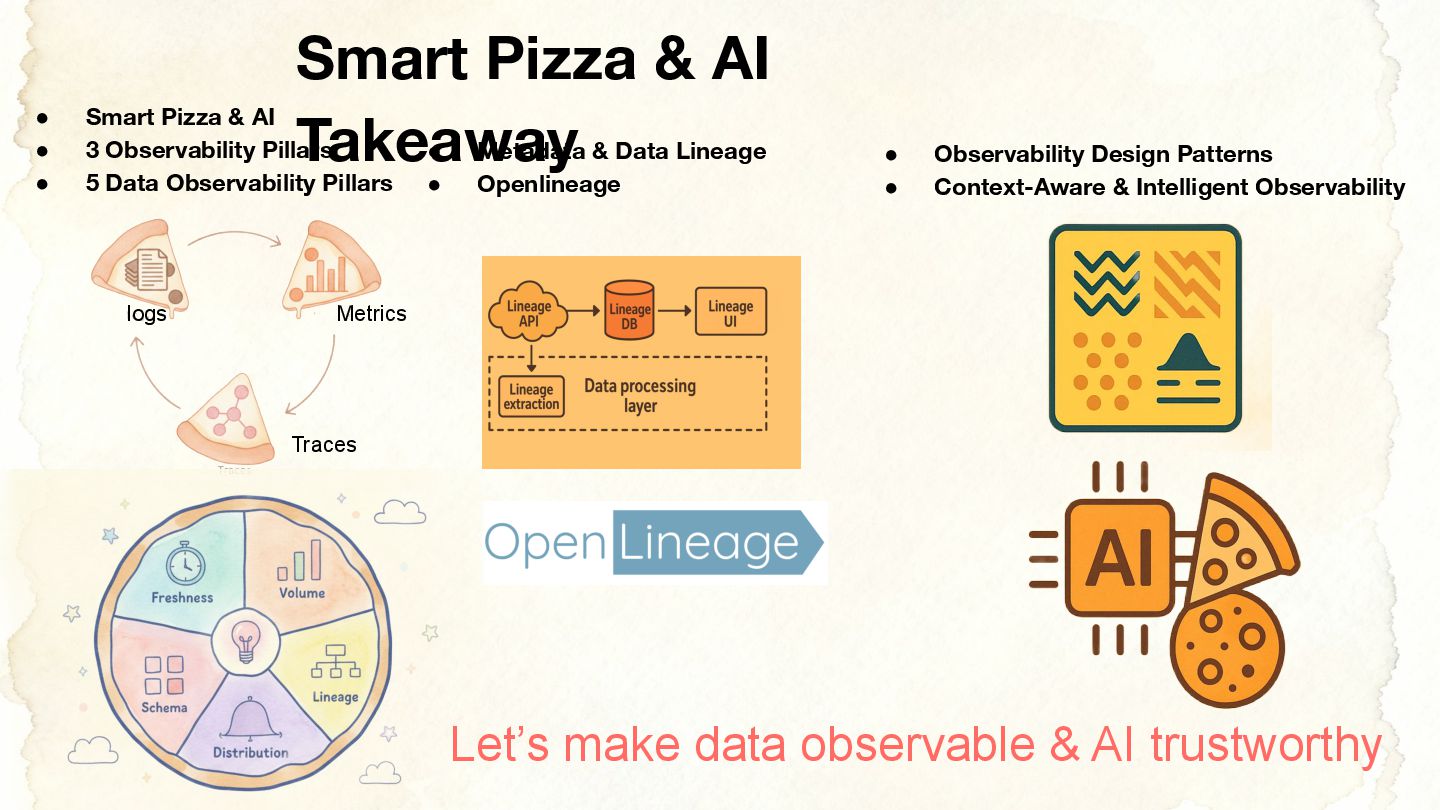
As data processing and AI workloads become increasingly complex, data observability is crucial for platform stability and trustworthiness. OpenLineage, an open-source standard, offers a new way to track data flow and lineage relationships, helping teams understand data movement, quickly pinpoint issues, and enhance transparency.
This session will share our practical experience in exploring and adopting OpenLineage, covering its integration strategies in cloud-native environments, the challenges encountered and how they were addressed, and its actual impact on observability, data quality, and cross-team collaboration. We will also discuss its potential applications in AI or data platforms.
Whether you are focused on observability, data governance, or the stability of AI/ML pipelines, this presentation will provide practical insights and directions for consideration.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
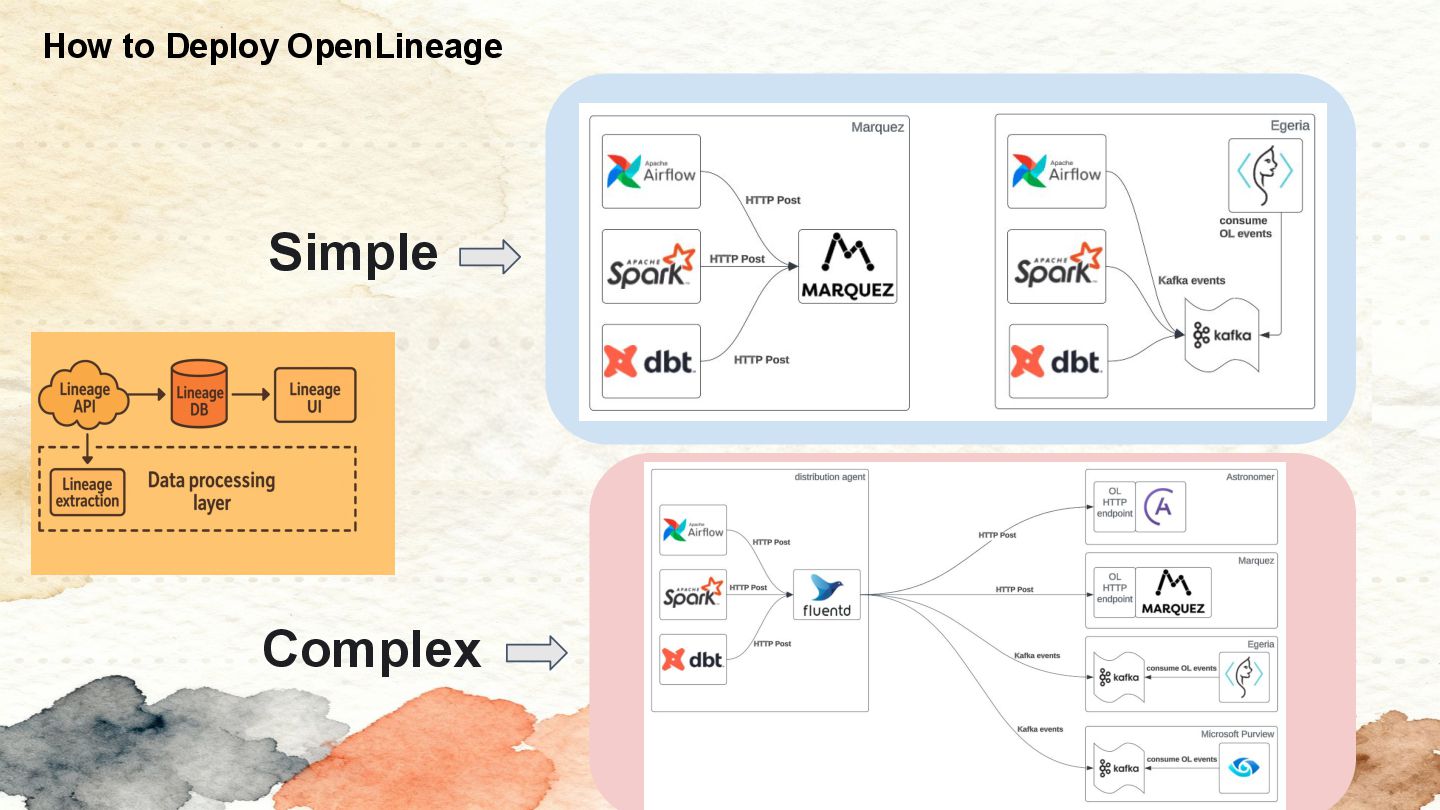{kind=link}
{kind=link}
{kind=link}
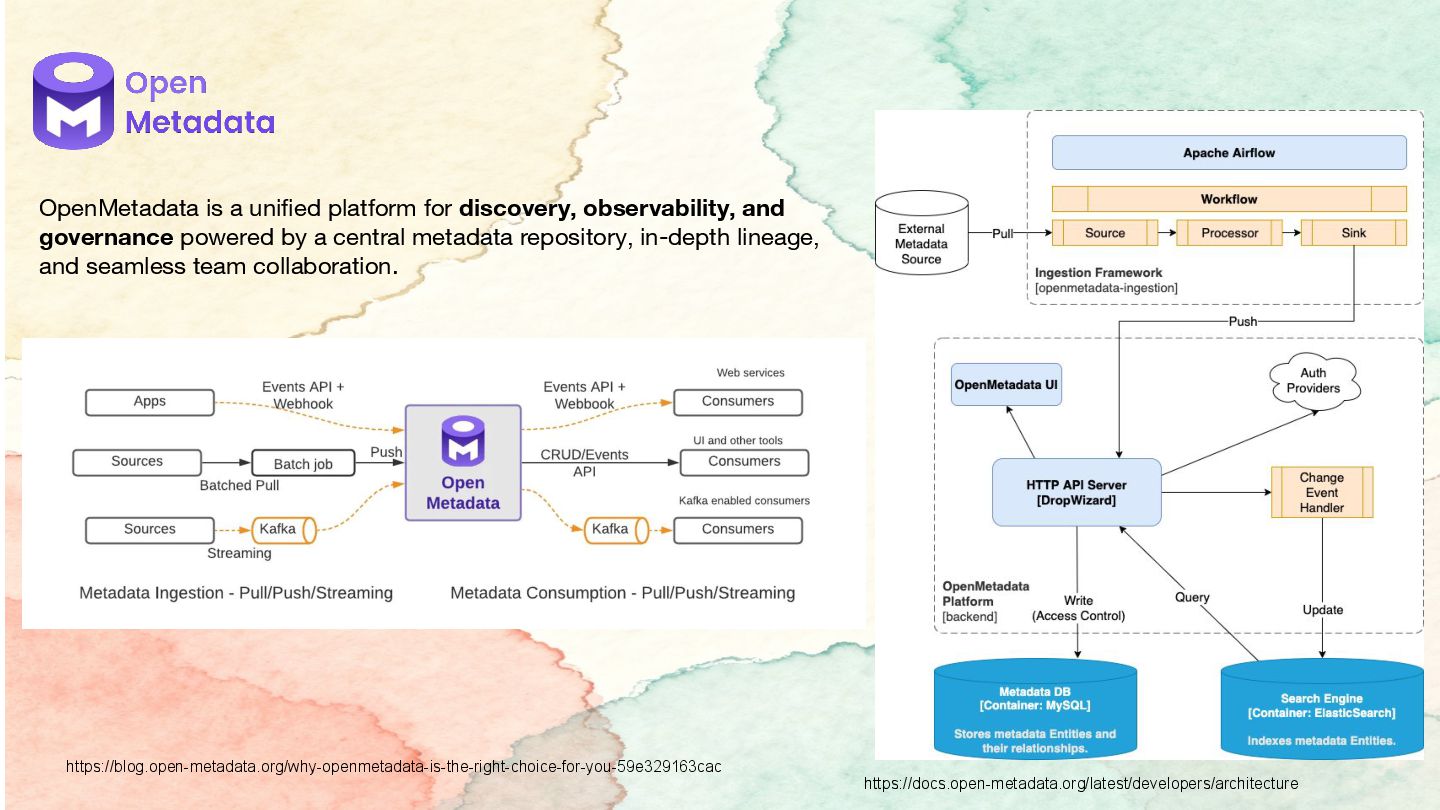{kind=link}
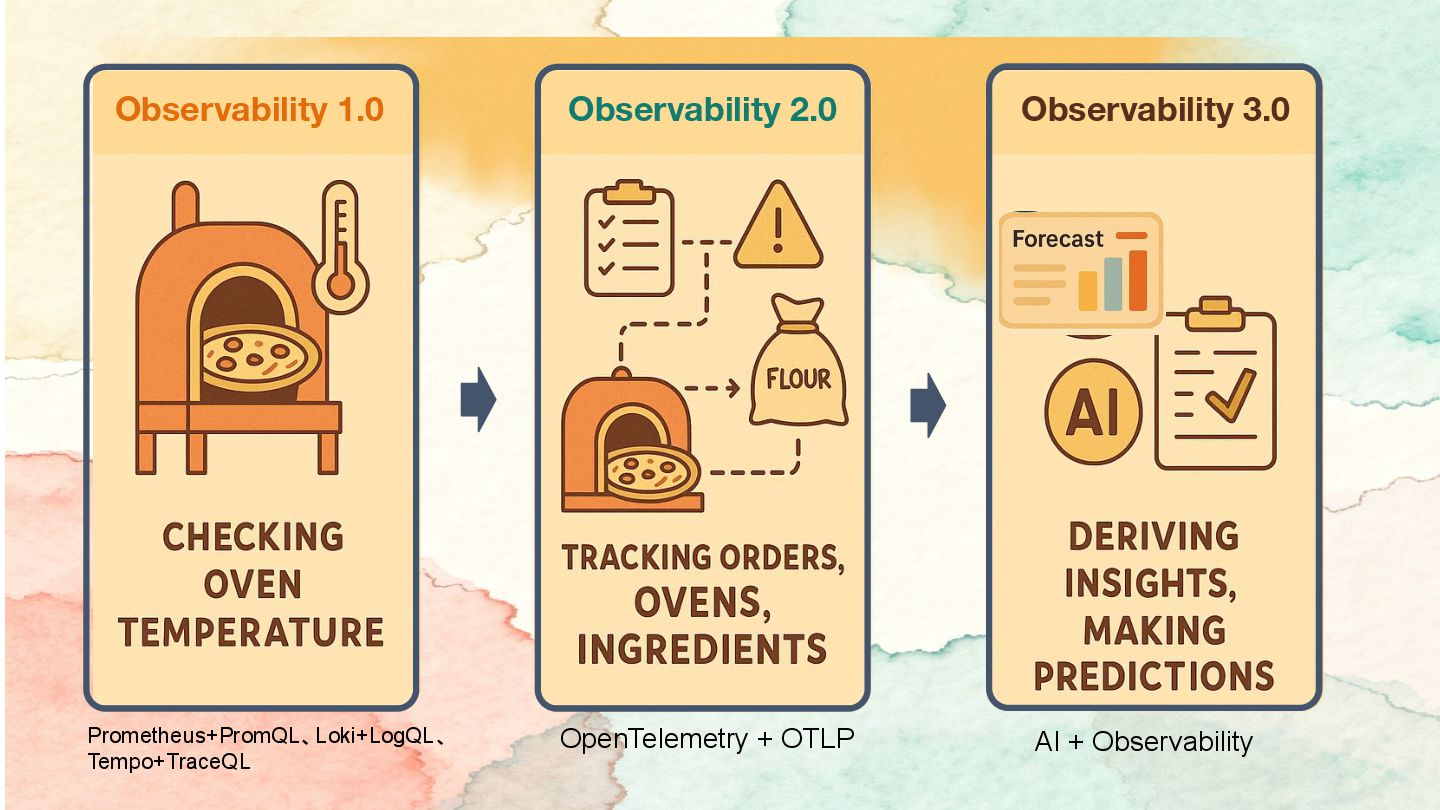{kind=link}
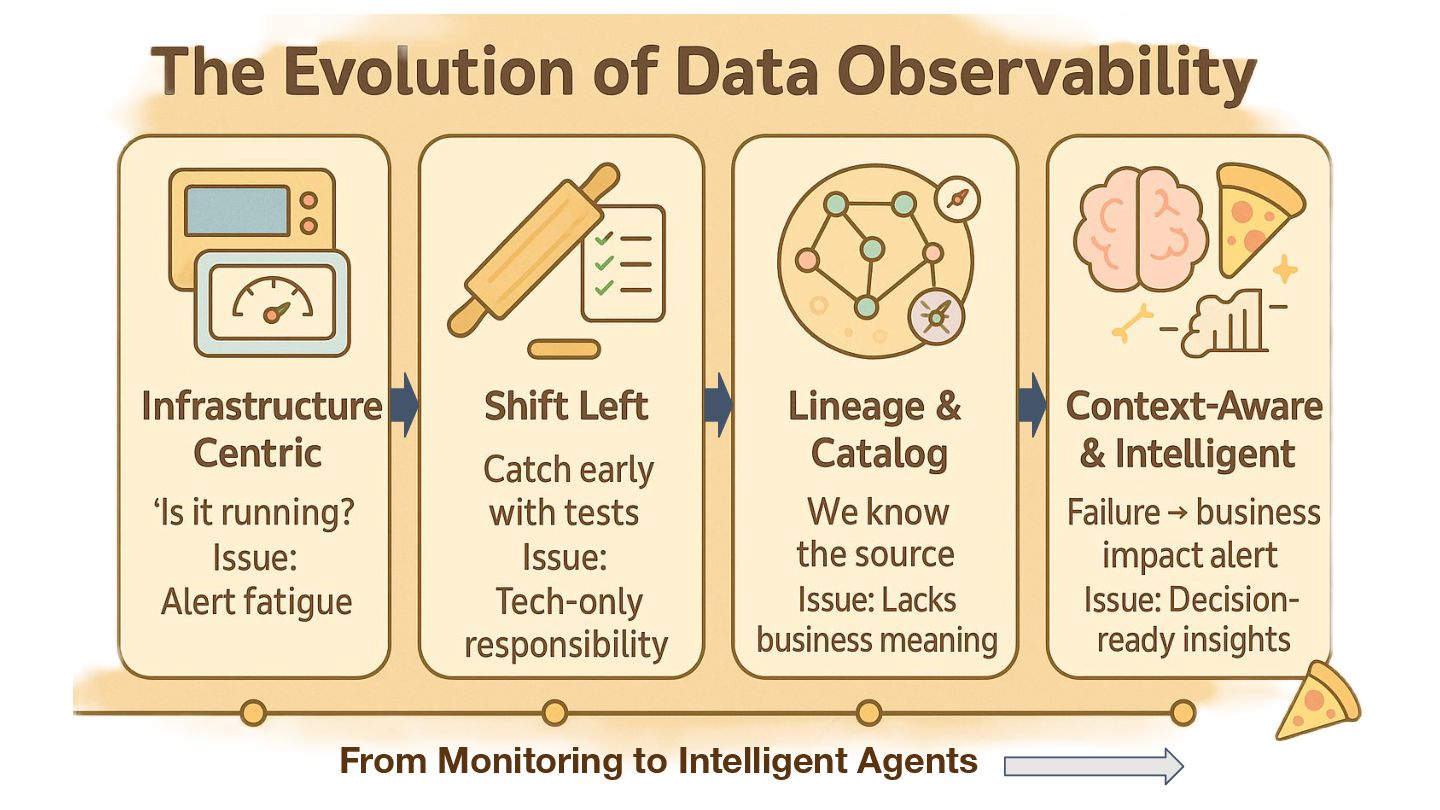{kind=link}
{kind=link}
{kind=link}
{kind=link}