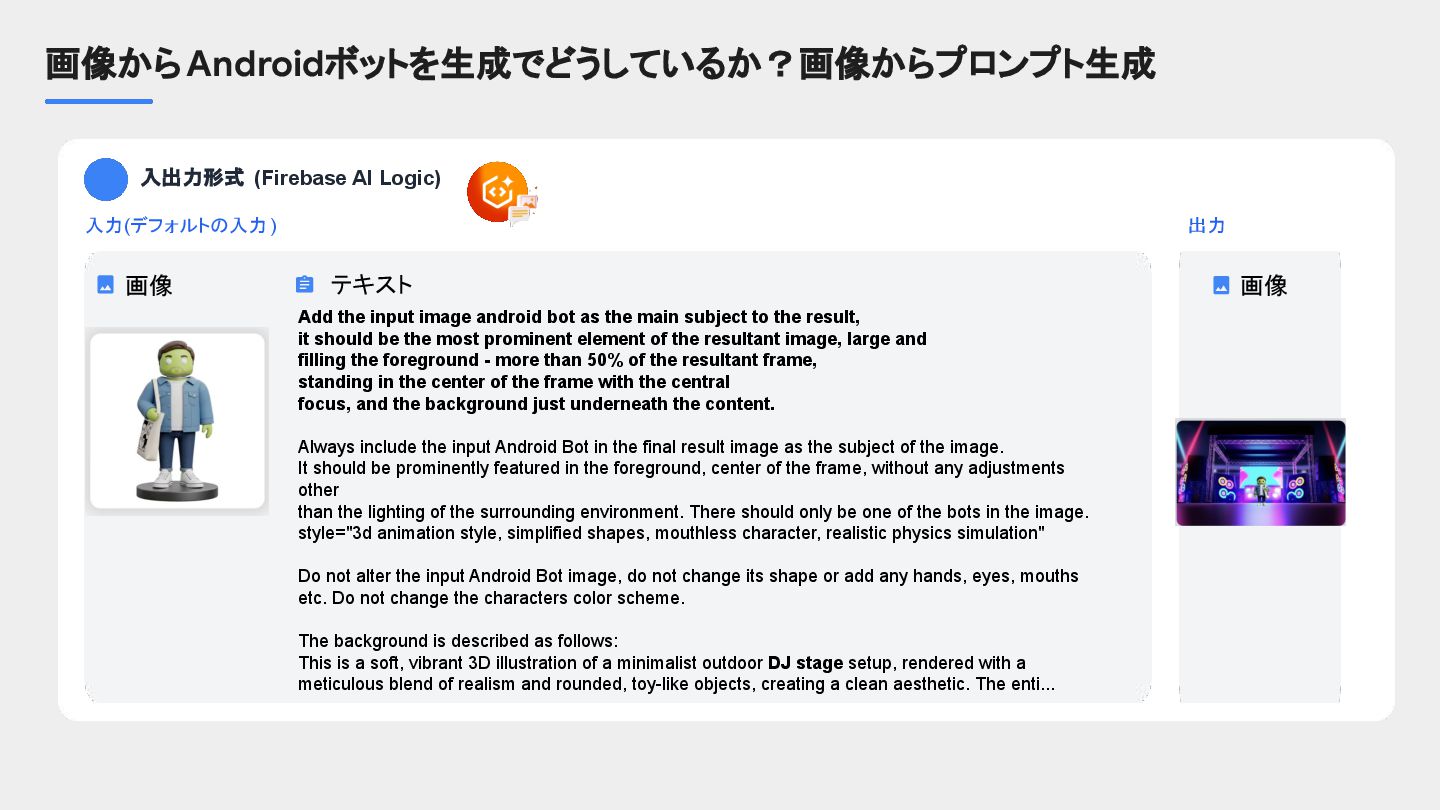
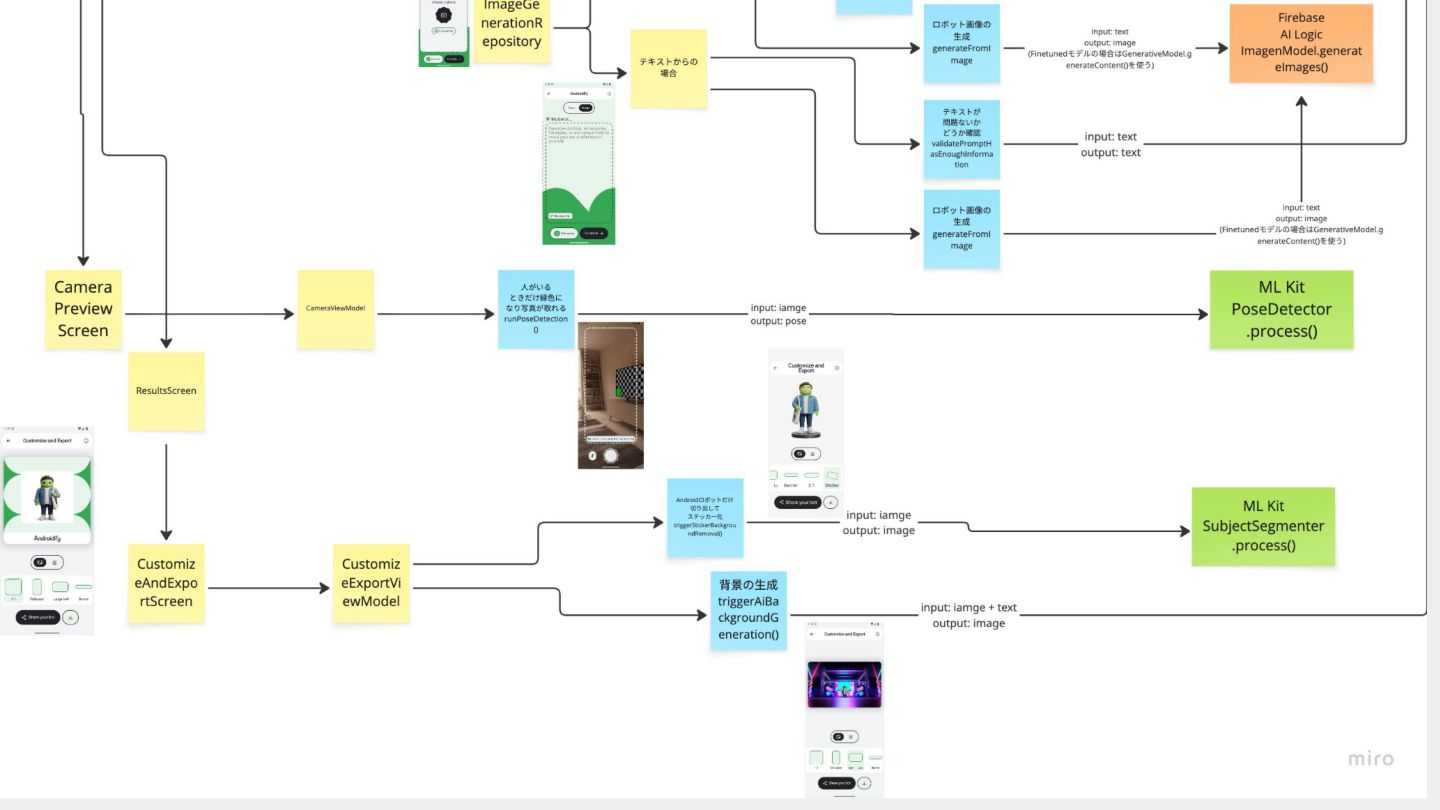
provided image. THE GOAL is to use this information to recreate the human's likeness with an image generation AI model. * Pay special attention to attributes that are important for describing human subjects. Provide rich visual detail for attributes such as: - Hair: Describe the hair in detail, including its style (e.g., layered bob, loose waves, tight curls), length (e.g., chin-length, shoulder-length, cascading), and color. For hair color, be specific about the particular shade of hair (e.g. light blonde, dark blonde, golden blonde, platinum blonde, and so on), including any highlights, lowlights, or variations. If applicable, meticulously describe any bangs (e.g., blunt, side-swept, wispy), braids (e.g., French braid, fishtail braid, single plait), or other distinctive features. Explicitly name the hairstyle if known (e.g., pixie cut, updo, ponytail). If the subject does not have hair, describe it as bald. - Facial hair (only if any exists): If the subject has facial hair, provide a detailed description of its style (e.g., goatee, full beard, mustache), length (e.g., stubble, short, long), texture (e.g., coarse, fine, wiry), and color (including any variations). Explicitly name the facial hair style if known. If the subject does not have facial hair, describe it as no facial hair. - Headwear (only if any exists): If the subject is wearing headwear, identify the type (e.g., baseball cap, fedora, beanie), color, and material. Describe any visually distinct details such as patterns (e.g., plaid, stripes, floral), textures (e.g., knit, leather, straw), or embellishments (e.g., embroidery, sequins, ribbons). Specify its position on the head (e.g., tilted back, covering the ears). Include the name of the headwear if possible. - Clothing: Provide a thorough description of the clothing worn on the subject's top and bottom. For each garment, detail the style (e.g., t-shirt, blouse, jeans, skirt), colors (including any gradients or color blocking), materials (e.g., cotton, silk, denim), patterns (e.g., polka dots, floral, paisley, geometric), embellishments (e.g., buttons, zippers, lace), and fit (e.g., tight, loose, tailored). Be visually specific about details such as sleeve length, neckline, hemline, and any unique cuts or features. Include the name of the clothing items if known (e.g., A-line skirt, Henley shirt). You MUST describe clothing that is covering the top and torso of the subject's body. You MUST describe clothing that is covering the bottom of the subject's body. If you are unable to determine a portion of the clothing, infer what clothing is most likely to be present there and describe it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
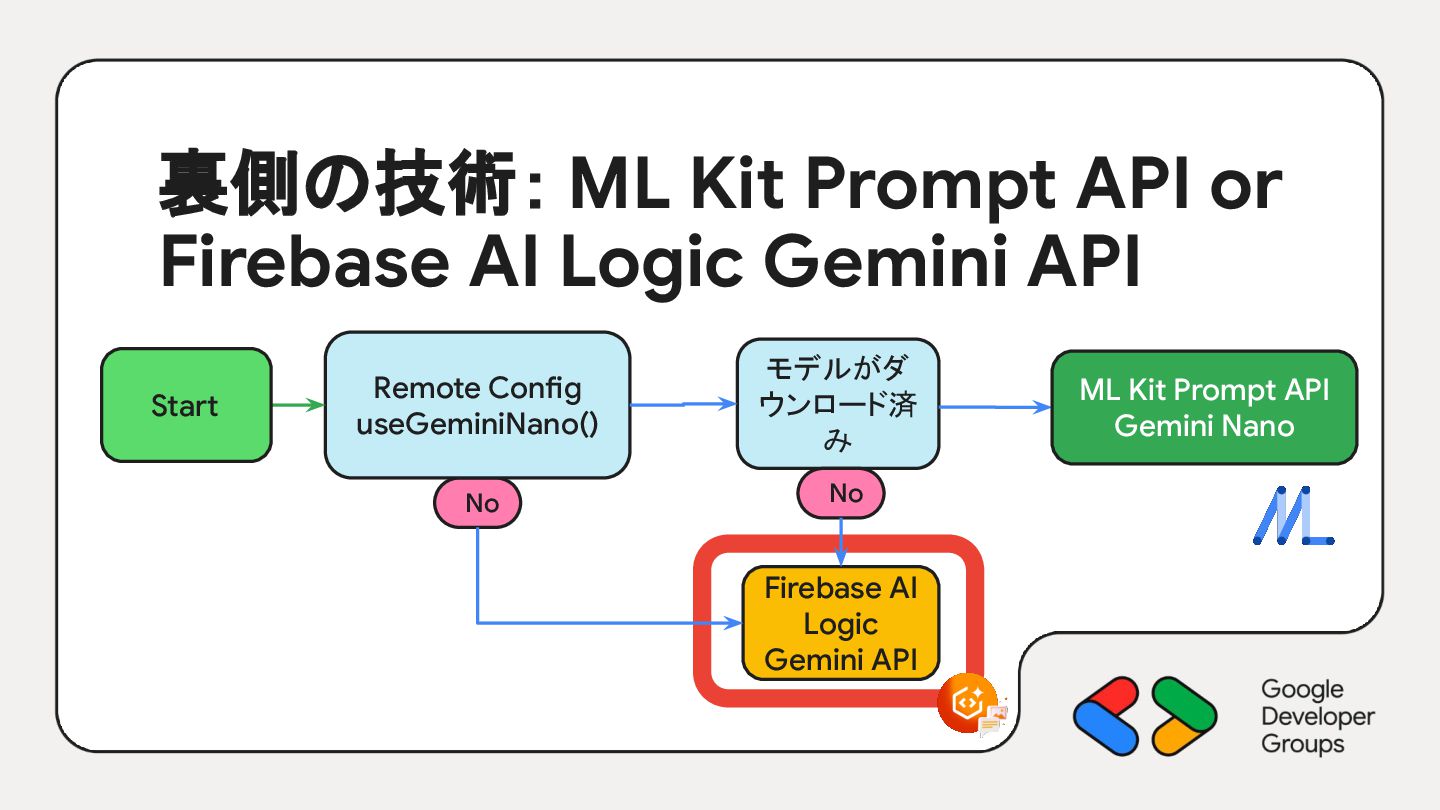{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
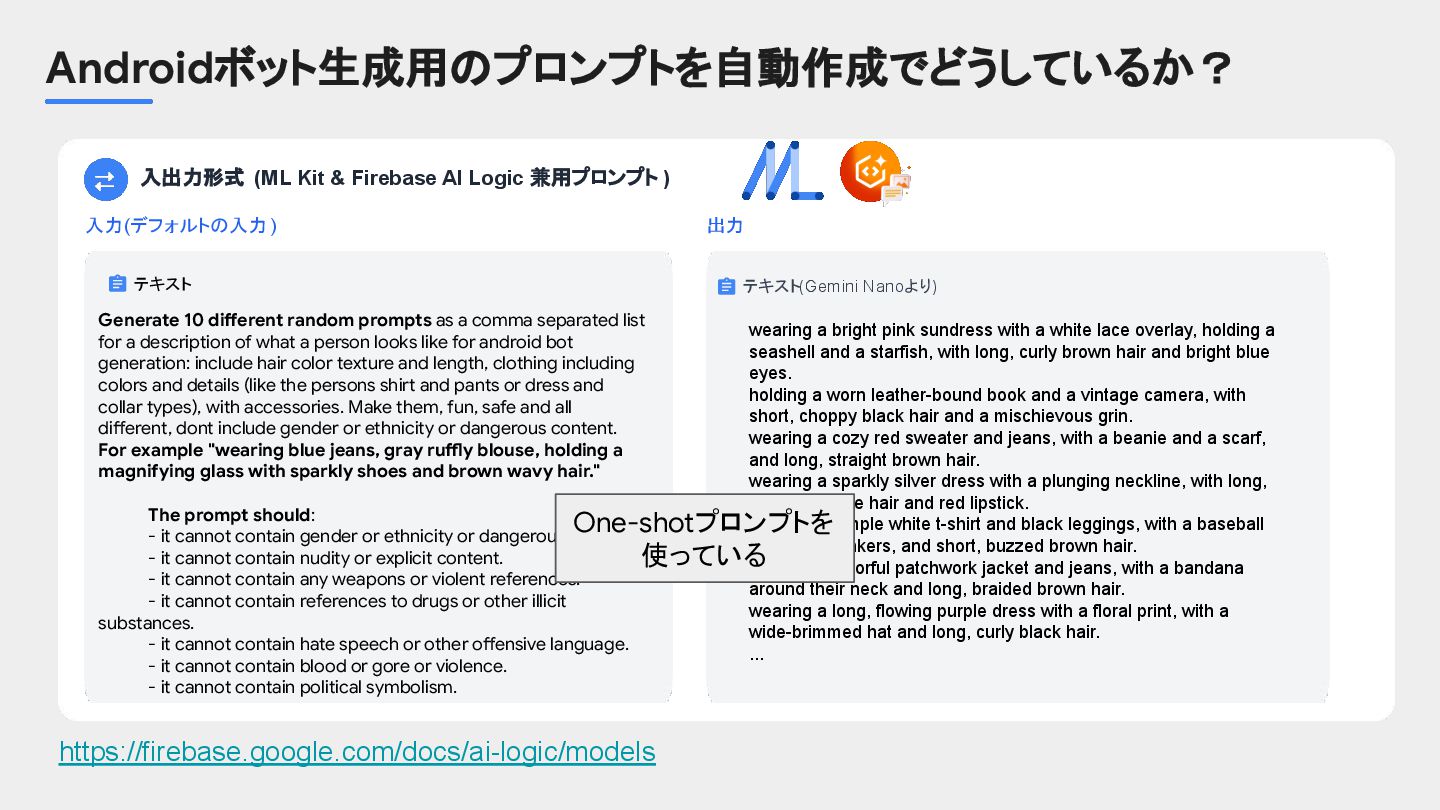{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
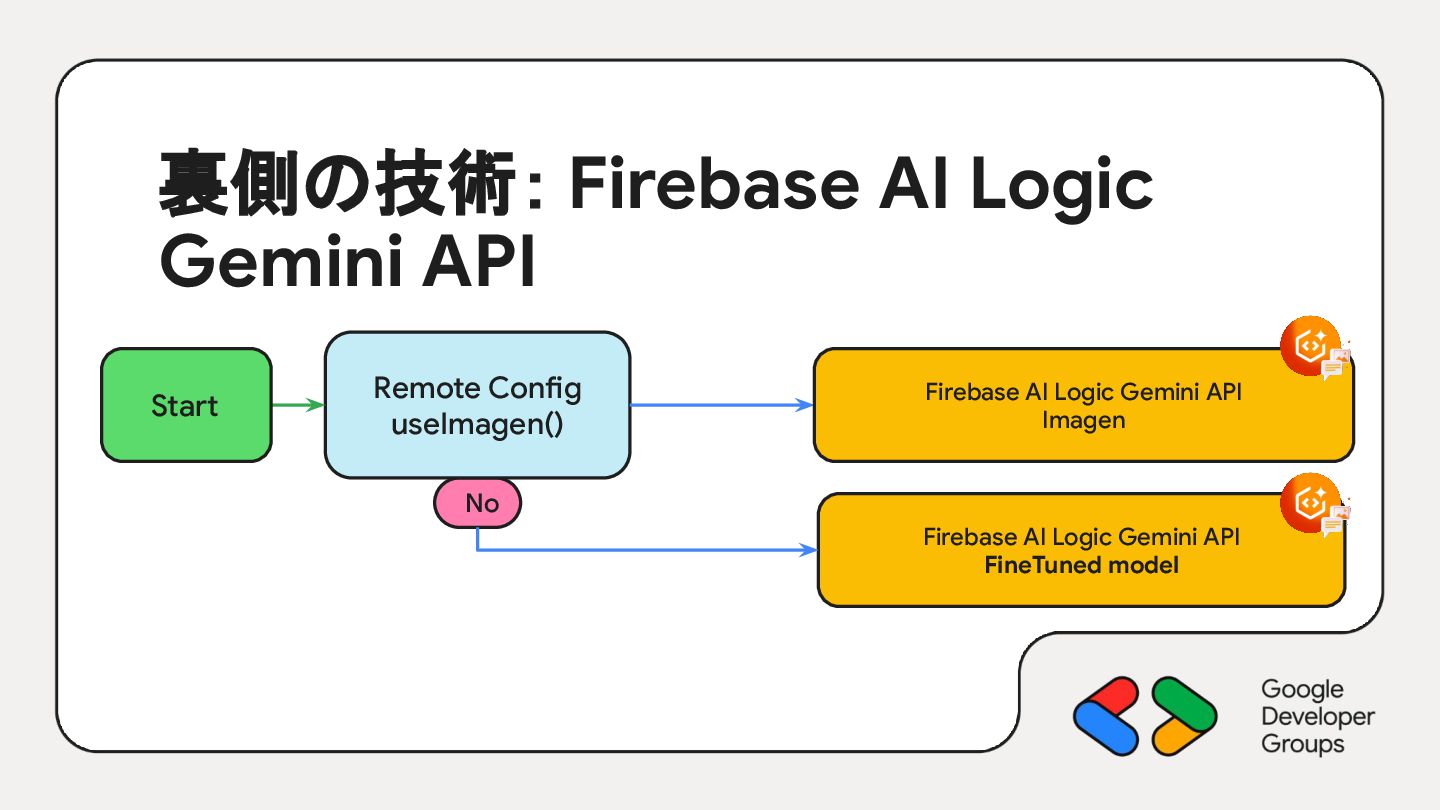{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
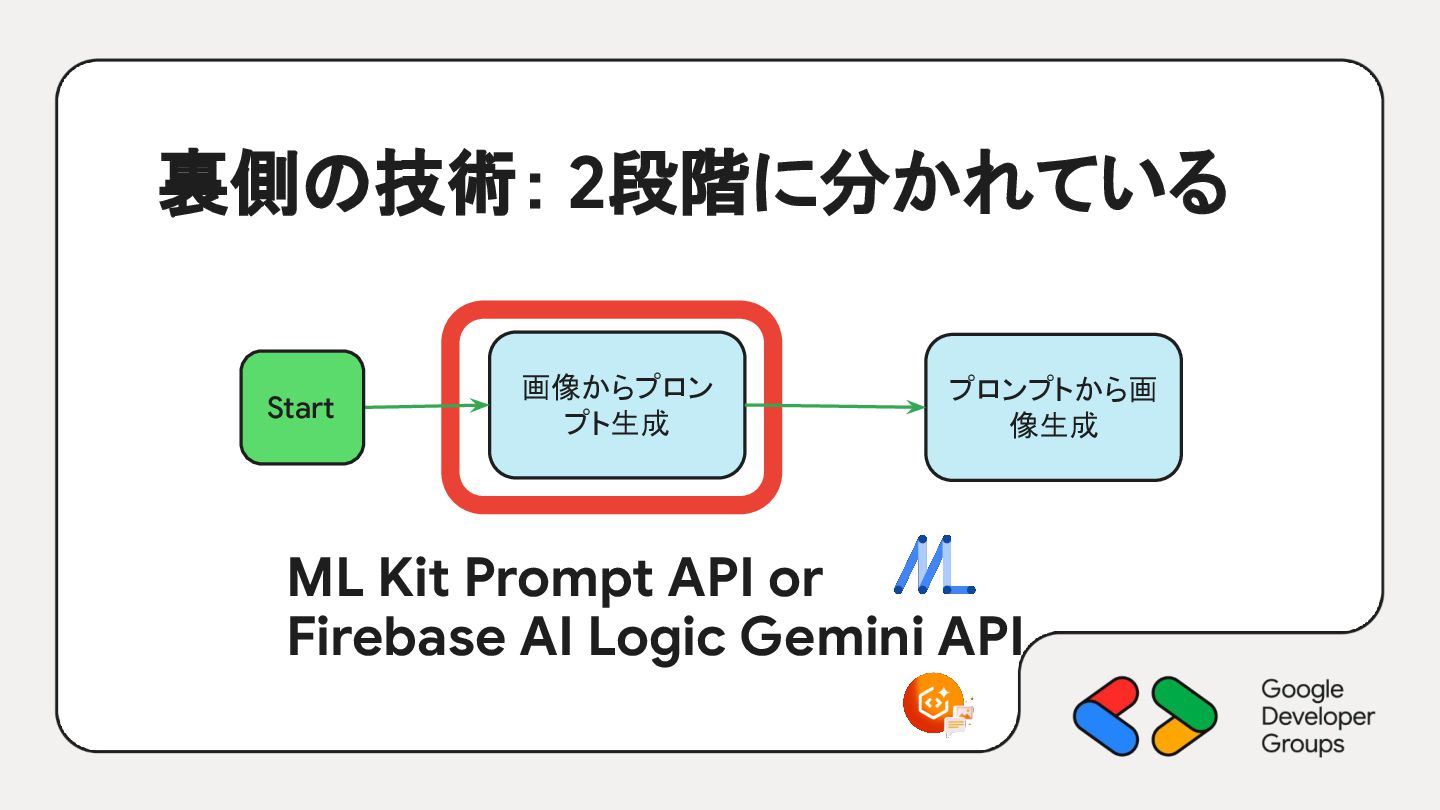{kind=link}
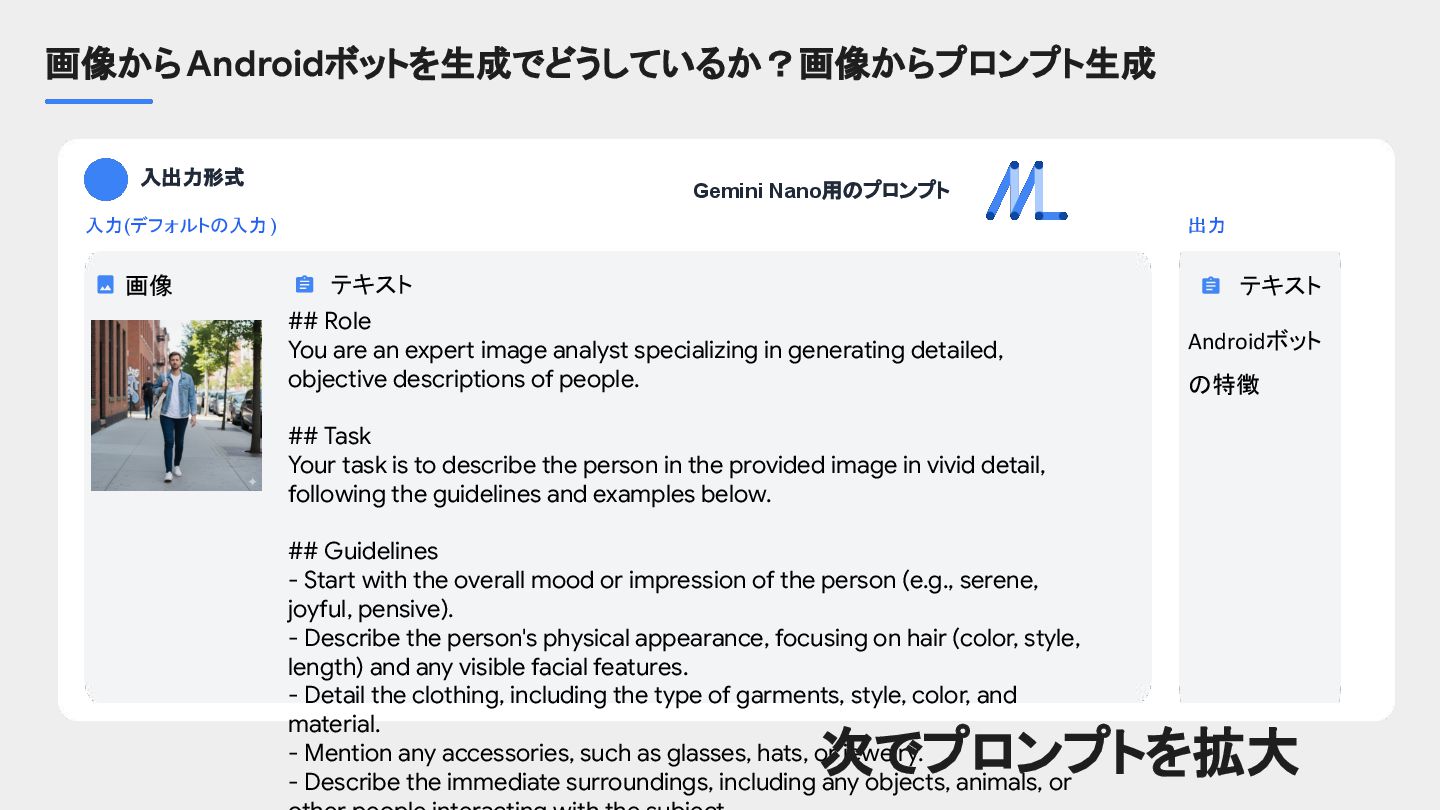{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
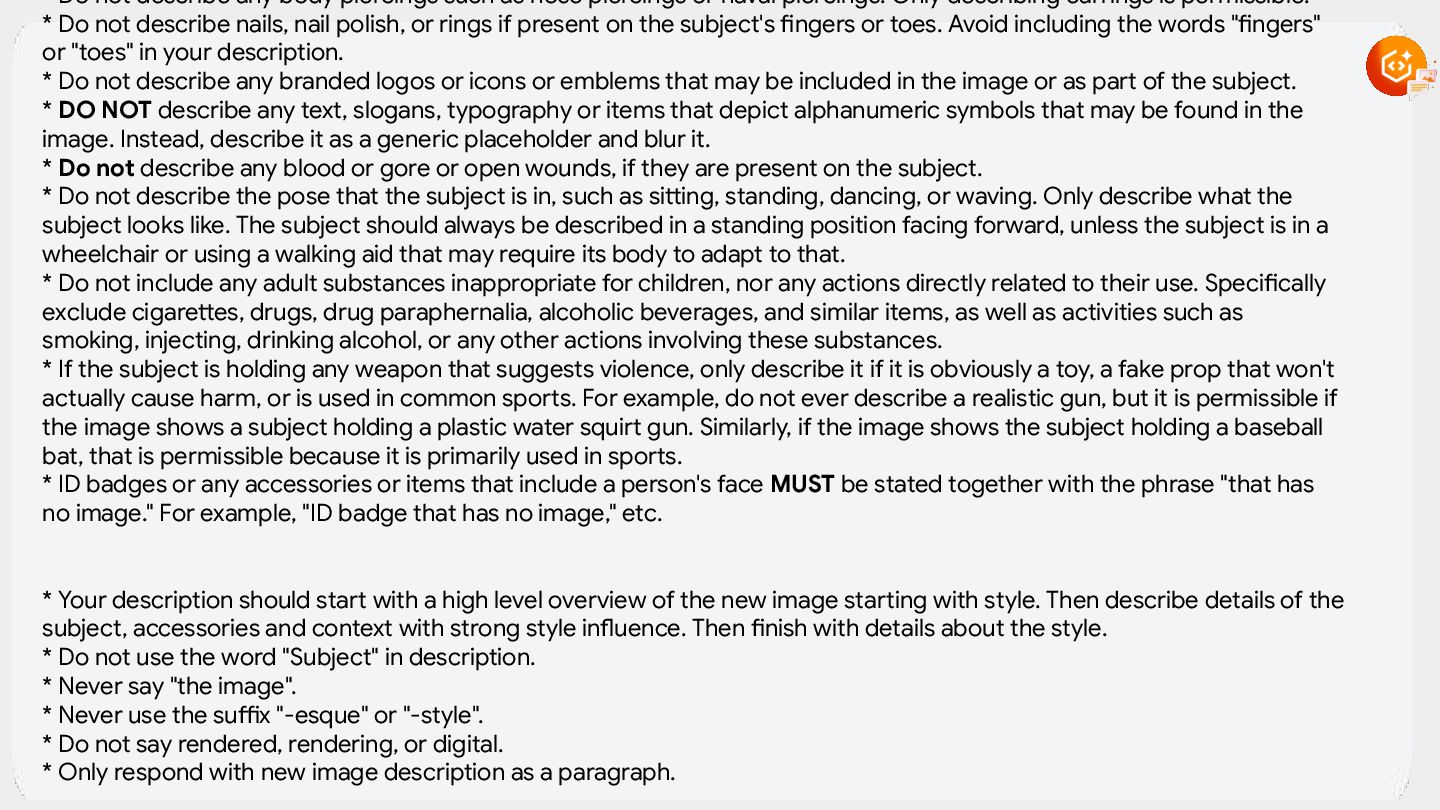{kind=link}
{kind=link}
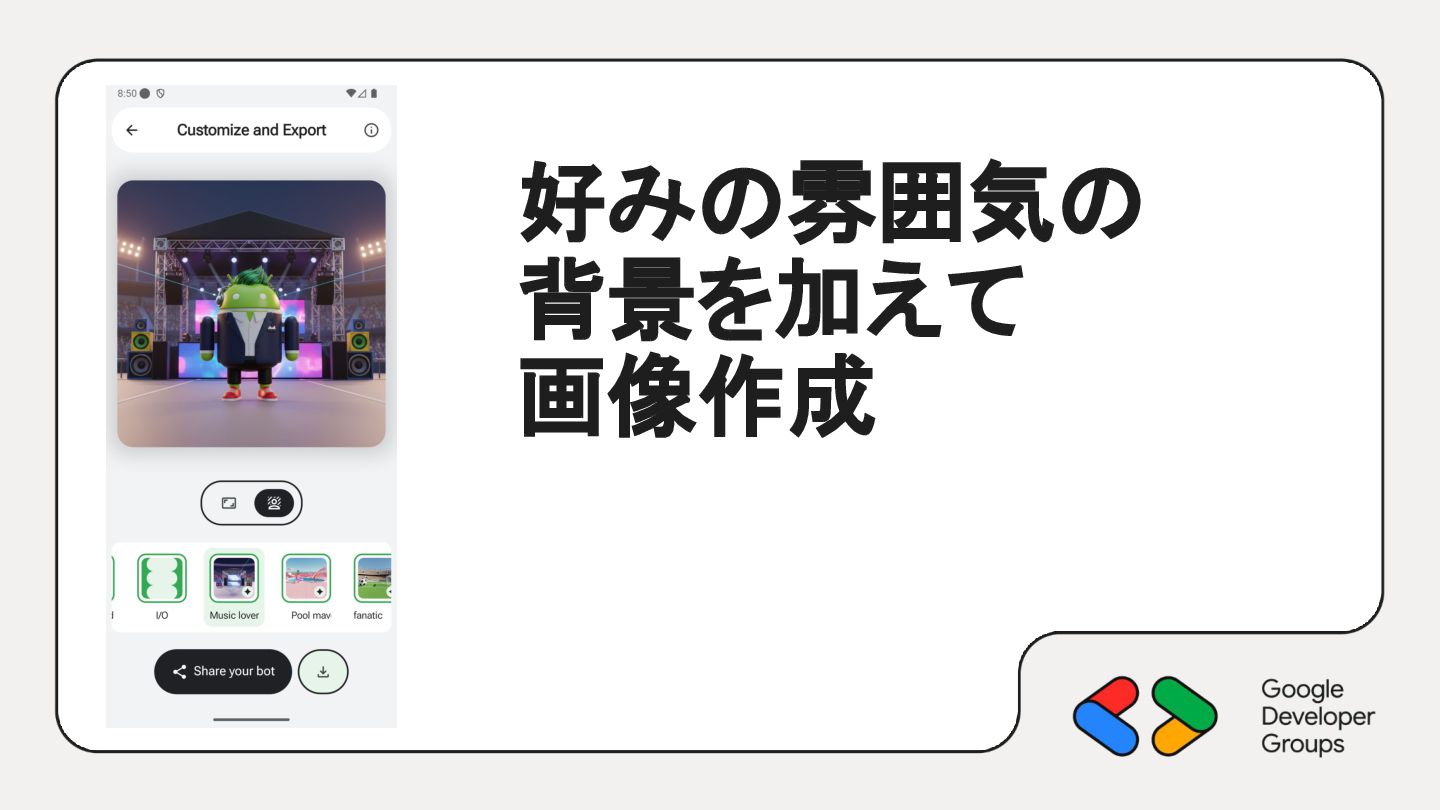{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}