Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第3回AI王YAMALEXソリューション
Search
Takashi Sasaki
December 05, 2022
Programming
1.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第3回AI王YAMALEXソリューション
Takashi Sasaki
December 05, 2022
More Decks by Takashi Sasaki
See All by Takashi Sasaki
FastAPIでのasync defとdefの使い分け
takashi1029
16
7.7k
Semantic KernelでGPTと外部ツールを連携する
takashi1029
2
3.6k
Other Decks in Programming
See All in Programming
AIエージェントで 変わるAndroid開発環境
takahirom
2
680
Claude Opus 4.6以後の受託開発エンジニアの変化(Claude Code開発ノウハウ大公開スペシャルbyクラスメソッド)
iidatakuma
1
810
Laravelで学ぶ Webアプリケーションチューニング入門/web_application_tuning_101
hanhan1978
4
1.1k
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
16
3.5k
なぜ型を書くのか? TSKaigi2026で改めて考える #tskaigi_smarthr
kajitack
0
390
継続モナドとリアクティブプログラミング
yukikurage
3
620
AI時代、エンジニアはどう育つのか -未経験エンジニアの成長を間近で見て考えたこと-
thasu0123
0
140
Laravel Boostに学ぶ、AIにPHPを書かせる技術 〜OSSの実装から蒸留するエージェント制御の王道〜
kentaroutakeda
3
500
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
130
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
150
琵琶湖の水は止められてもNet--HTTPのリトライは止められない / You might be able to stop the water flow of Lake Biwa but you can't stop Net::HTTP retries
luccafort
PRO
0
410
トークンをケチるな、設計しろ:GitHub Copilotを賢く使うコンテキスト戦略
ochtum
0
320
Featured
See All Featured
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Public Speaking Without Barfing On Your Shoes - THAT 2023
reverentgeek
1
460
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
Art, The Web, and Tiny UX
lynnandtonic
304
22k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Are puppies a ranking factor?
jonoalderson
1
3.7k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
For a Future-Friendly Web
brad_frost
183
10k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Transcript
Copyright © Acroquest Technology Co., Ltd. All rights reserved. AI王~クイズAI日本一決定戦~
第3回コンペティション 開発システム紹介 Acroquest Technology株式会社 YAMALEXチーム 佐々木 峻 1
「働きがいのある会社(GPTW)」 ランキング(従業員25~99人部門) 1位 を 3回 受 賞 1位 1位 1位
若手中心のデータサイエンティストチーム “YAMALEX” Copyright © Acroquest Technology Co., Ltd. All rights
reserved. 3 Acroquest社内で発足したKaggleGMの山本率いる データサイエンスチーム“YAMALEX”(ヤマレックス) プロジェクトの高度な問題解決に取り組んでいます。 チームメンバが切磋琢磨して、コンペティションへの 参加や勉強会を開催し、スキルアップに繋げています。 主な活動内容 多種多様な課題をAIで解決するデータサイエンティストチーム ①AL/MLを利用した課題解決 ②データサイエンス コンペティションへの参加 ③自社サービス開発の支援 様々な分野でのお客様が抱える 課題解決に向けて、AI/MLの 導入支援を行っています。 Kaggleをはじめとしたデータ サイエンスコンペティションに 参加し、日々、スキルアップを 図っています。 Acroquestでは、映像解析 ソリューションTorrentioVideoや 日本語検索のENdoSnipeを開発 しています。それらの新機能の 検証・開発を行っています
目次 Copyright © Acroquest Technology Co., Ltd. All rights reserved.
4 1. 参加のモチベーション 2. システム概要 3. システム詳細 4. 試したけど改善しなかったこと 5. やりたかったけどできなかったこと 6. 感想
1. 参加のモチベーション Copyright © Acroquest Technology Co., Ltd. All rights
reserved. 5 ①QAの経験を積みたい ⚫ QAシステム自体は、チームメンバがほぼ扱ったことが無かったので このコンペを知った際に、チャレンジしたくなった(今回、初参加です)。 ②日本のNLPコンペに参加したい ⚫ Kaggleなどには参加したことはあるが、問題のほとんどが英語の文章なので 日本のコンペにチームとして出たかった。 ③チームとしてコンペに参加してみたい ⚫ YAMALEXチームはまだ個人参加はあれど、チームでコンペに取り組んだ ことがなかったので、チームで取り組んでみたかった。
Copyright © Acroquest Technology Co., Ltd. All rights reserved. 6
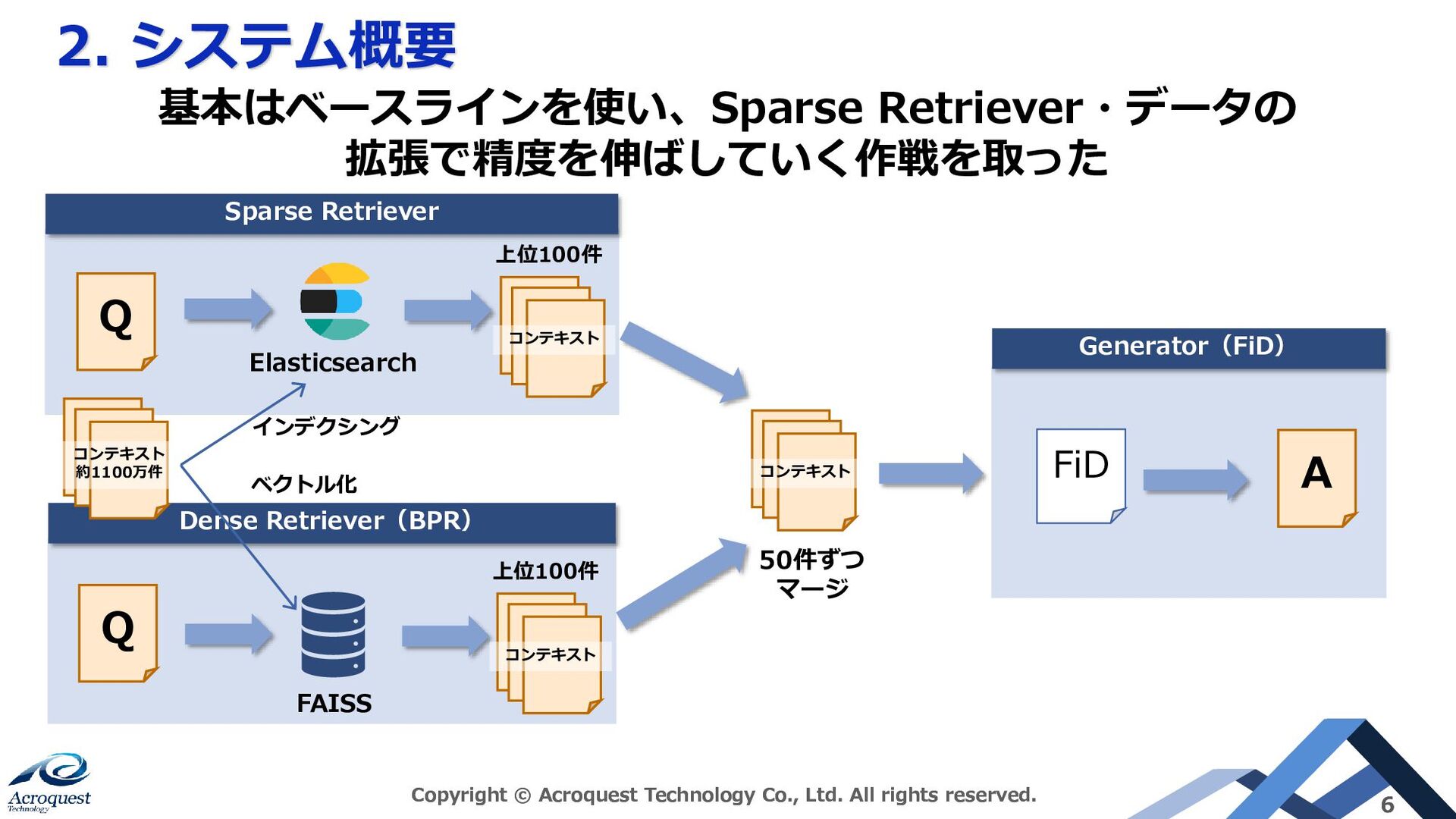
2. システム概要 Copyright © Acroquest Technology Co., Ltd. All rights reserved. 6 Sparse Retriever Elasticsearch Dense Retriever(BPR) FAISS 上位100件 50件ずつ マージ Generator(FiD) FiD ベクトル化 インデクシング 基本はベースラインを使い、Sparse Retriever・データの 拡張で精度を伸ばしていく作戦を取った Q コンテキスト コンテキスト 約1100万件 Q 上位100件 コンテキスト コンテキスト A
3-1. Retriever Copyright © Acroquest Technology Co., Ltd. All rights
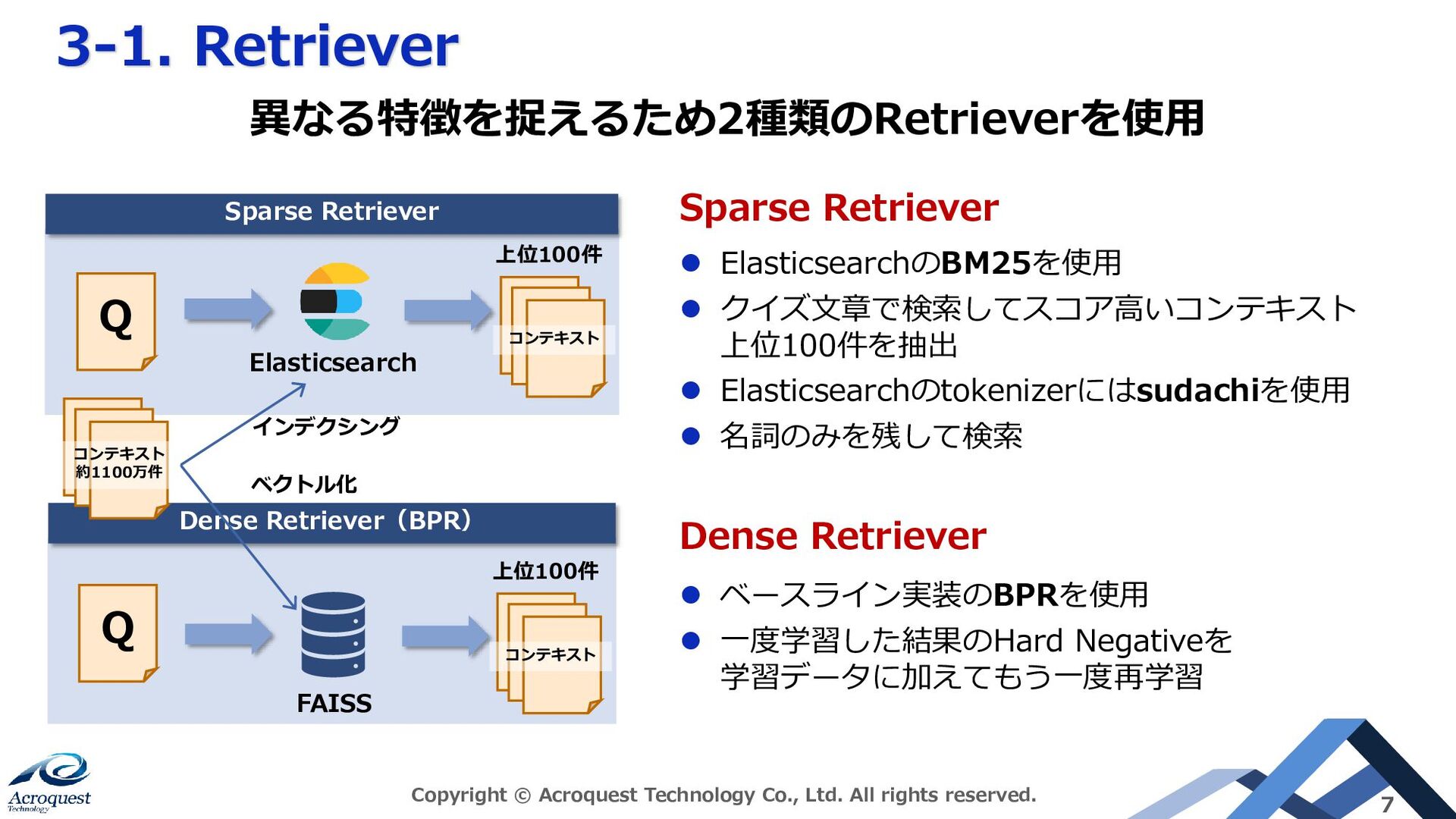
reserved. 7 Sparse Retriever ⚫ ElasticsearchのBM25を使用 ⚫ クイズ文章で検索してスコア高いコンテキスト 上位100件を抽出 ⚫ Elasticsearchのtokenizerにはsudachiを使用 ⚫ 名詞のみを残して検索 Dense Retriever ⚫ ベースライン実装のBPRを使用 ⚫ 一度学習した結果のHard Negativeを 学習データに加えてもう一度再学習 異なる特徴を捉えるため2種類のRetrieverを使用 Sparse Retriever Elasticsearch Dense Retriever(BPR) FAISS 上位100件 ベクトル化 インデクシング Q コンテキスト コンテキスト 約1100万件 Q 上位100件 コンテキスト
Copyright © Acroquest Technology Co., Ltd. All rights reserved. 8
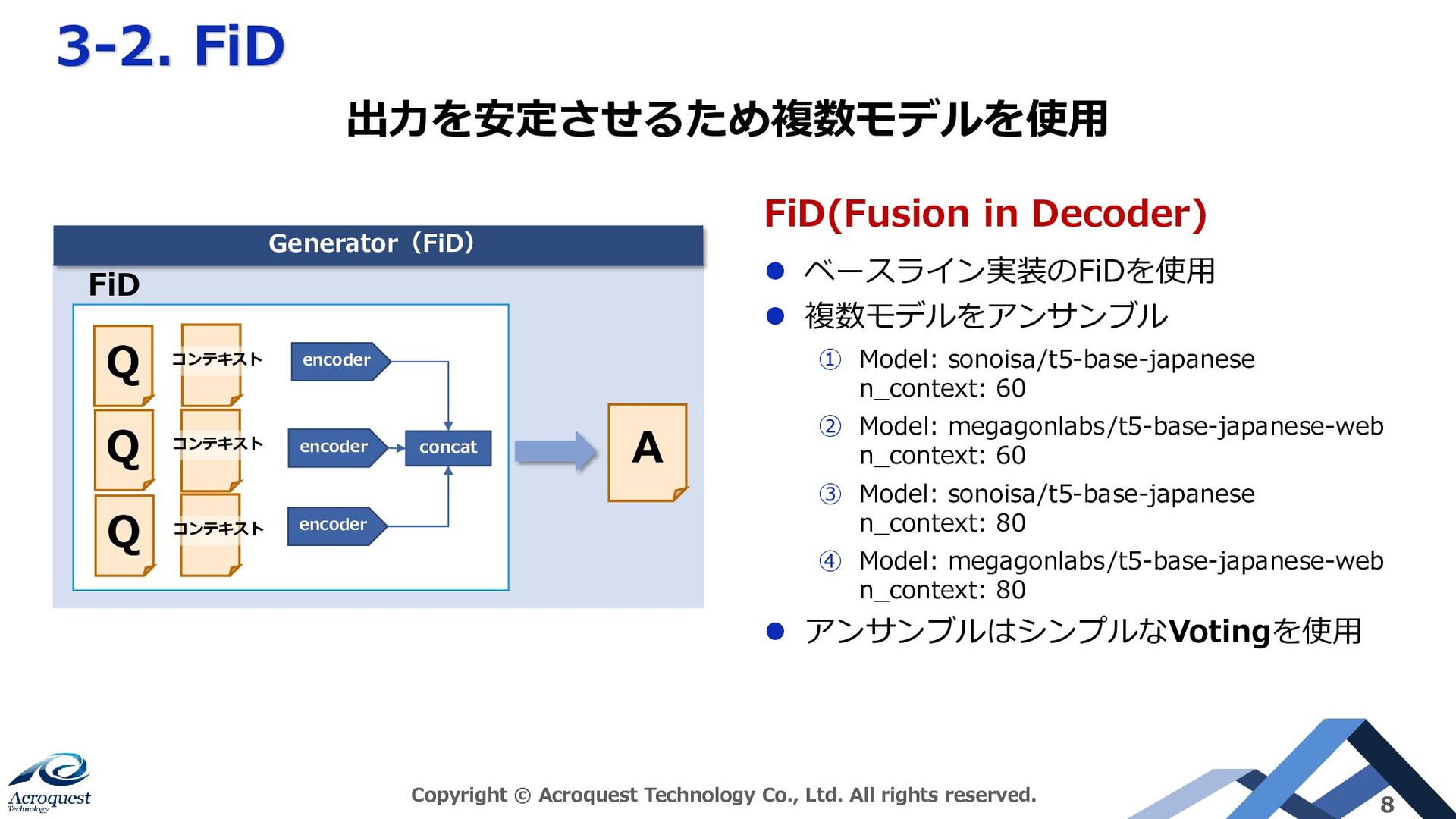
3-2. FiD Copyright © Acroquest Technology Co., Ltd. All rights reserved. 8 Generator(FiD) encoder encoder concat FiD FiD(Fusion in Decoder) ⚫ ベースライン実装のFiDを使用 ⚫ 複数モデルをアンサンブル ① Model: sonoisa/t5-base-japanese n_context: 60 ② Model: megagonlabs/t5-base-japanese-web n_context: 60 ③ Model: sonoisa/t5-base-japanese n_context: 80 ④ Model: megagonlabs/t5-base-japanese-web n_context: 80 ⚫ アンサンブルはシンプルなVotingを使用 出力を安定させるため複数モデルを使用 A Q コンテキスト Q コンテキスト Q コンテキスト encoder
3-3. 取り組みの流れ Copyright © Acroquest Technology Co., Ltd. All rights
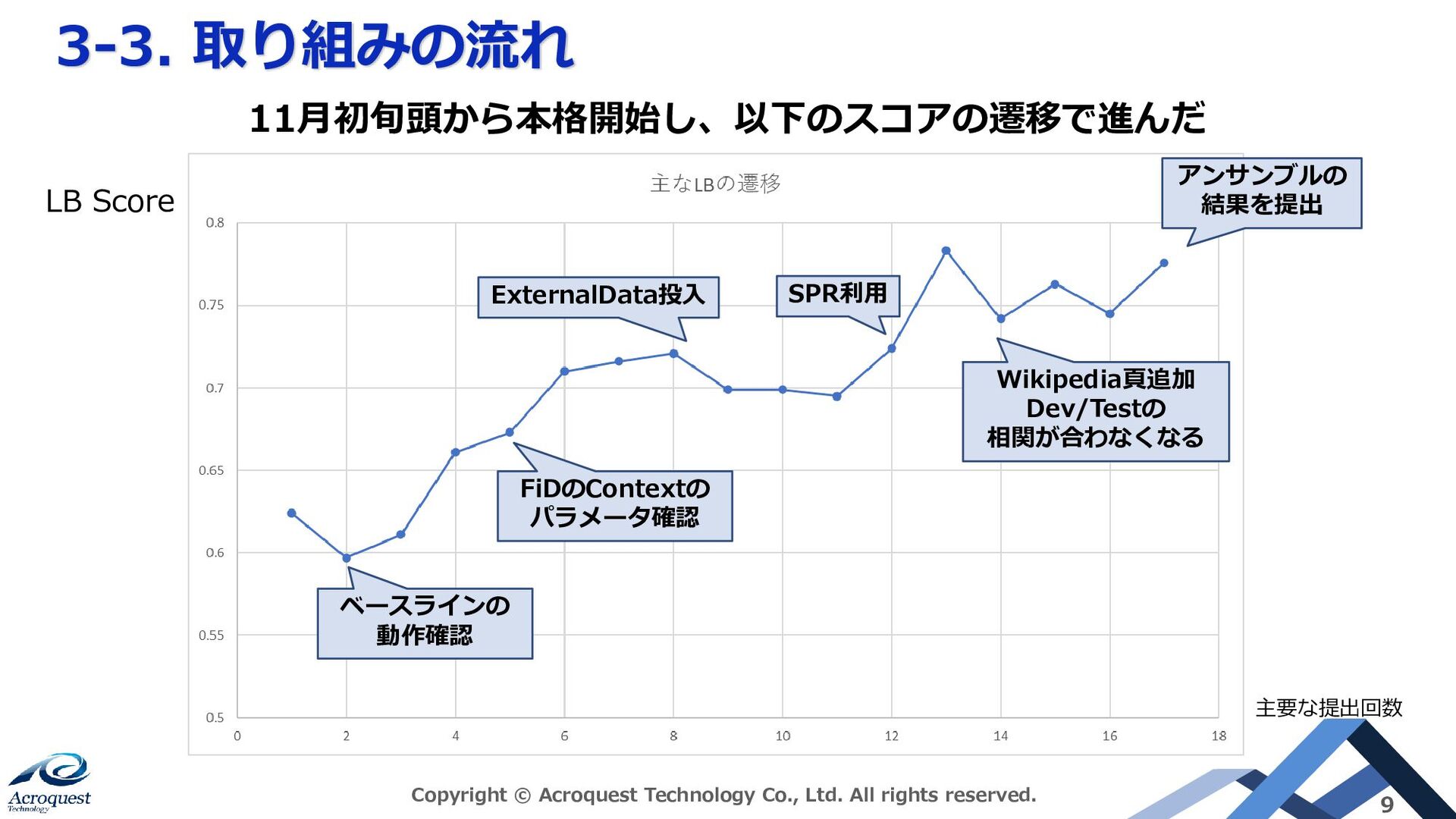
reserved. 9 ベースラインの 動作確認 FiDのContextの パラメータ確認 ExternalData投入 SPR利用 Wikipedia頁追加 Dev/Testの 相関が合わなくなる アンサンブルの 結果を提出 11月初旬頭から本格開始し、以下のスコアの遷移で進んだ LB Score 主要な提出回数
4. 試したけど改善しなかったこと Copyright © Acroquest Technology Co., Ltd. All rights
reserved. 10 ①Wikipediaのコンテキスト追加 ⚫ Wikipediaデータを追加した際に、DevのEMは増加したが、Testに相関しなかったこと。 ⚫ ただし、未知の問題に頑強になる可能性があるので、最終投稿には適用した。 ②BPRの出力をHard Negative ContextとPositive Contextに 複数回追加 ⚫ BPRの出力を学習データのHard Negativeに追加することで精度に改善は見られた。 ⚫ ただし、Positive Contextへの追加と2回目・3回目の追加はDevの精度は改善したが、 Testでの精度はむしろ下がった。 ③Retrieverのモデルを日本語RobertaやSentence BERTに変更 ⚫ bert-japanese-v2を使用したバージョンとほとんど精度が変わらなかった ため、適用を見送った。
5. やりたかったけどできなかったこと Copyright © Acroquest Technology Co., Ltd. All rights
reserved. 11 ①Retrievalの正解データ改善 ⚫ RetrievalのPositiveデータに対するアノテーションの再考。 a. 単語が含まれているからといって正解ではない(例:鳥の「トキ」は単語が含まれやすい) 。 b. そのため、複数のPositiveデータを利用する場合ノイズが含まれるデータも現行の アノテーション方式だと多く存在する。 c. 例えば、BERTとElasticsearchの組み合わせによる再アノテーションも検討できるが、 時間が足りなかった。 ②様々なモデルの検討 ⚫ megagonlabs/t5-base-japanese-webとsonoisa/t5-base-japaneseでのFiDでの 回答生成を実施した。 ⚫ さらに大きなモデルの精度向上を期待できるので他も検討したかったが、時間が足りず、 試せなかった(例: https://huggingface.co/abeja/gpt-neox-japanese-2.7b)。
6. 感想 Copyright © Acroquest Technology Co., Ltd. All rights
reserved. 12 ①日本語を使ったコンペは滅多にないので楽しい ⚫ たいてい世の中のNLPコンペは英語なので、日本語を機械学習をコンペで競えるのは とてもありがたい。 ②QAシステムの奥深さを知れた ⚫ QAモデルを作ったのはこのコンペが初めてだったので、どうすれば精度が上がるかや モデルの論文読んだりなどOpen Domain QAに詳しくなれた。 ③データ・ベースライン・サポートなど運営が充実しており 取り組みやすかった ⚫ ベースラインが充実しているので、参加時期が遅くても一定の精度はすぐに出せるように なった。 ⚫ 提出の際には多大なサポートをありがとうございました。
13 運営委員会の皆様 コンペの開催ありがとうございました。 私たちとしても学びが多く、 非常に面白いものでした! Copyright © Acroquest Technology Co.,
Ltd. All rights reserved.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}