Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
画像コンペでのベースラインモデルの育て方
Search
tattaka
August 07, 2025
Programming
3.9k
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
画像コンペでのベースラインモデルの育て方
イベント「上位Kagglerに学ぶ~画像コンペの戦い方~」で発表したLTの資料です。
tattaka
August 07, 2025
More Decks by tattaka
See All by tattaka
ドメイン特化なCLIPモデルとデータセットの紹介
tattaka
3
1.3k
論文紹介:LLMDet (CVPR2025 Highlight)
tattaka
0
2.5k
実は強い 非ViTな画像認識モデル
tattaka
5
2.7k
CZII - CryoET Object Identification 参加振り返り・解法共有
tattaka
1
1.7k
Distributed and Parallel Training for PyTorch
tattaka
3
1.2k
論文紹介 DSRNet: Single Image Reflection Separation via Component Synergy (ICCV 2023)
tattaka
0
570
最近のVisual Odometry with Deep Learning
tattaka
1
3.1k
Fuzzy Metaballs: Approximate Differentiable Rendering with Algebraic Surfaces
tattaka
0
710
Other Decks in Programming
See All in Programming
Haskell/Servantを通してWebミドルウェアを捉え直す
pizzacat83
0
410
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
symfony/aiとlaravel/boost
77web
0
120
霧の中の代数的エフェクト
funnyycat
1
280
「なぜそう決めたのか」を残し続ける仕組み ― Notion AI カスタムエージェント × Slack連携による設計判断の自動記録 - NIKKEI Tech Talk #47
niftycorp
PRO
0
250
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
140
気圧・高度・GPSを記録&可視化するアプリ「Koudo」を作った話
hjmkth
1
340
自作OSでスライド発表する
uyuki234
1
3.7k
鹿野さんに聞く!『TypeScriptコードレシピ集』で磨く実践力
tonkotsuboy_com
4
1k
AIを活用したE2Eテスト実装効率化のあゆみ / ebisu-mobile-14-kotetu
kotetuco
0
160
LLMによるContent Moderationの本番運用の裏側と品質担保への挑戦
suikabar
3
830
スマートグラスで並列バイブコーディング
hyshu
0
280
Featured
See All Featured
エンジニアに許された特別な時間の終わり
watany
107
250k
Scaling GitHub
holman
464
140k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
630
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
610
JavaScript: Past, Present, and Future - NDC Porto 2020
reverentgeek
52
6k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
960
Fireside Chat
paigeccino
42
4k
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
180
We Have a Design System, Now What?
morganepeng
55
8.2k
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
260
The World Runs on Bad Software
bkeepers
PRO
72
12k
Transcript
画像コンペでの ベースラインモデルの育て方 GOドライブ株式会社 福井 尚卿 (@tattaka_sun)
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 2 自己紹介 名前:tattaka - kaggle: https://www.kaggle.com/tattaka -
Twitter: https://x.com/tattaka_sun 趣味: • 熱帯魚飼育 ◦ 南米の中型肉食魚 • ランニング ◦ 暑いのでサボりがち Kaggleはほぼ画像系のみ・仕事でも画像認識をやっています
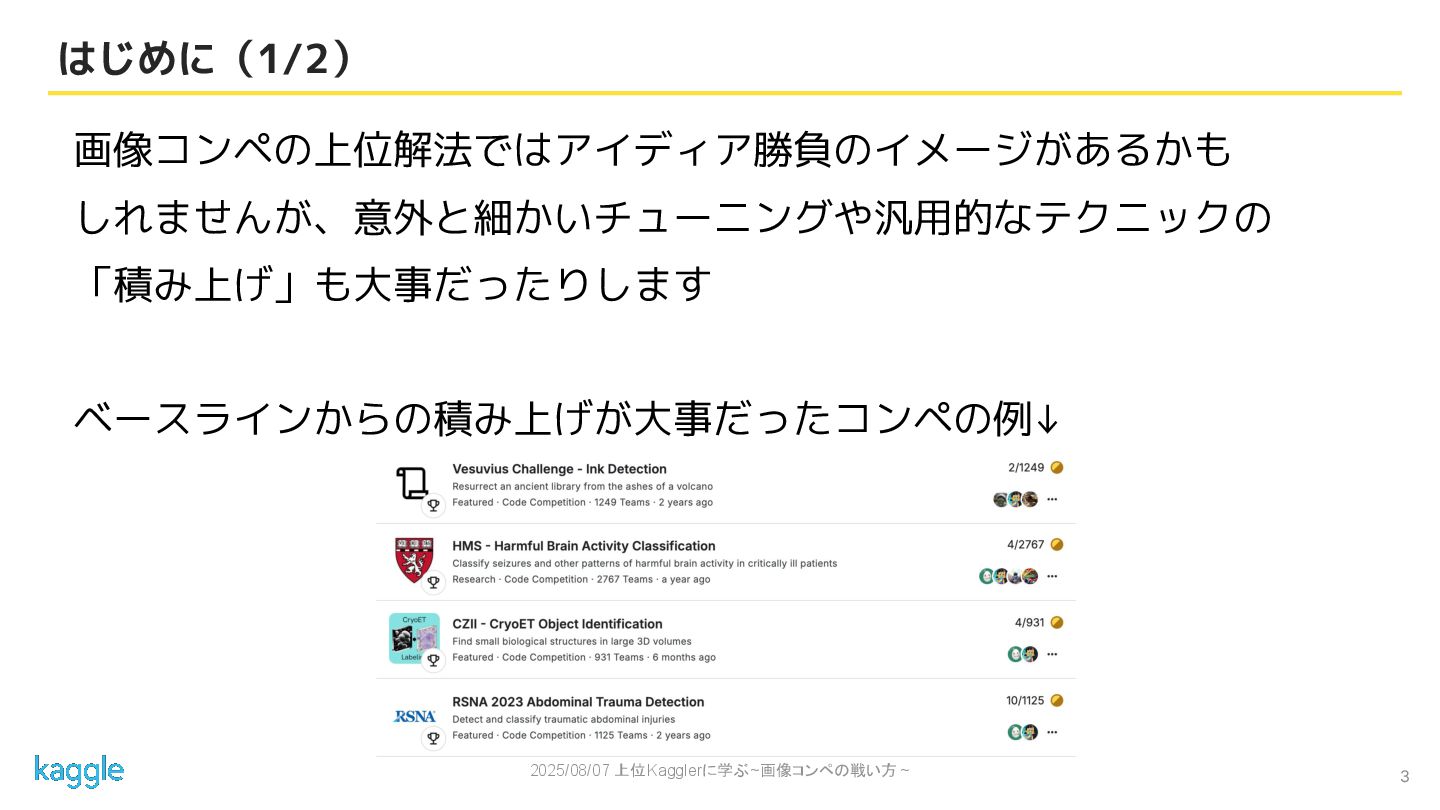
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 3 はじめに(1/2) 画像コンペの上位解法ではアイディア勝負のイメージがあるかも しれませんが、意外と細かいチューニングや汎用的なテクニックの 「積み上げ」も大事だったりします ベースラインからの積み上げが大事だったコンペの例↓
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 4 はじめに(2/2) 本LTでは、公開Notebookなどのシンプルなベースラインモデルを を作った後の「どうベースラインモデルを育てていくか」に焦点を 当てて普段使っているテクニックや気をつけていることなど事例ととも に紹介します
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 5 このLTで話すこと - 「良い」ベースラインモデルとは - I/O・CPU処理を高速化して実験回数を増やそう -
ハイパラチューニングの勘所 - すぐに使える色々なテクニック - アイディアを出すために
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 6 良いベースラインモデルとは 前提として、実験を重ねる前に良いベースラインモデルを 作ることが大事 - 実装について把握できている -
リークしていない - Trust CVかTrust LBかの方針を定めた上で、 適切に評価ができている - など - 参考: 競技としてのKaggle、役に立つKaggle
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 7 I/O・CPU処理を高速化する(1/2) 細かい試行を重ねるためには実験の高速化が必須 意外とモデルの学習部分よりI/OやCPU処理がボトルネックに なっていることも多い - jpg・pngをnumpy形式で保存する
- 精度低下しないならfloat16・uint8で保存する - tfrecord・hdf5・np.memmapなど部分的にデータを読み込める 形式を使う - DataLoaderクラスのnum_workers・prefetch_factor の設定を見直す
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 8 I/O・CPU処理を高速化する(2/2) CPUで動いているnumpyなどの処理をTorchを使ってGPUに載せる 例:CZIIコンペでの後処理 np.ndarray torch.Tensor
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 9 ハイパラチューニングの勘所(1/5) モデル設計まわり - 事前学習済みモデル(timm models)の選び方 -
以下から選ぶことが多いです - CNN系統 - ResNet-RS・ResNeSt・ConvNeXt V1/V2・ConvFormer・ EfficientNet V1/V2・RDNet・InceptionNeXt - ViT系統 - SwinT V1/V2・CAFormer・MaxViT・EfficientViT_b*/l* - ResNet系統は学習しやすく、初手で使いがち - 3DタスクだとResNet*-irCSN など
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 1 0 ハイパラチューニングの勘所(2/5) - drop_path_rate - 学習時にモデルのlayerの一部をskipすることで汎化性能を上げる
DropPathの適用割合を決めるパラメータ - 一部のモデルでは使えない(EfficientViT_b*/l*・ResNeStなど) - headの設計 - 何層にするか - Dropout・BatchNormを入れるか - (分類の場合)どのPooling層を使うか - UNet系ならどのAttentionを使うか(CBAM・SCSEなど)
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 11 ハイパラチューニングの勘所(3/5) 学習設定まわり - optimizer - AdamW・AdamWがうまくいかない場合はSGD
- 最近だとMuonも良いらしいですが使ったことがないので試してみたい - 学習率のチューニング - AdamWだと1e-3 ~ 1e-5でいいところを探す - 事前学習済み部分とそれ以外で学習率を変えた方が良いことも - 個人的には事前学習済み部分を小さめに設定することが多い - warmup - 多くの場合入れた方が学習が安定する
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 1 2 ハイパラチューニングの勘所(4/5) - AdamWのパラメータ - weight
decay: 1e-2 ~ 1e-5の間でチューニング - eps: 1e-6 ~1e-8でチューニング - 小さいと性能は良いが安定性が悪くなることが多い印象 - fp32の時は1e-8・fp16の時は1e-6をよく使います - epoch数 - なるべくEarly Stoppingはしないようにチューニングする (のが理想) - last = bestにならない場合も多いので様子を見ながら調整する - batch size - 大きい方が良い場合・小さい方が良い場合どちらもあるので調整する
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 1 3 ハイパラチューニングの勘所(5/5) 入力画像への前処理 - data augmentation
- Flip・Rot90を基本に処理後の画像を目視で確認しながら追加していく - ShiftScaleRotate・RandomBrightnessContrast・CouarseDropout あたりは良く使う - 入力画像の解像度を変える - 計算リソース上の制限(batch size・学習時間)を見比べながら調整 - 入力画像の正規化 - 基本的にはデータセット全体の統計で正規化 - 画像単位・画像系列単位の統計で正規化すると良いことも
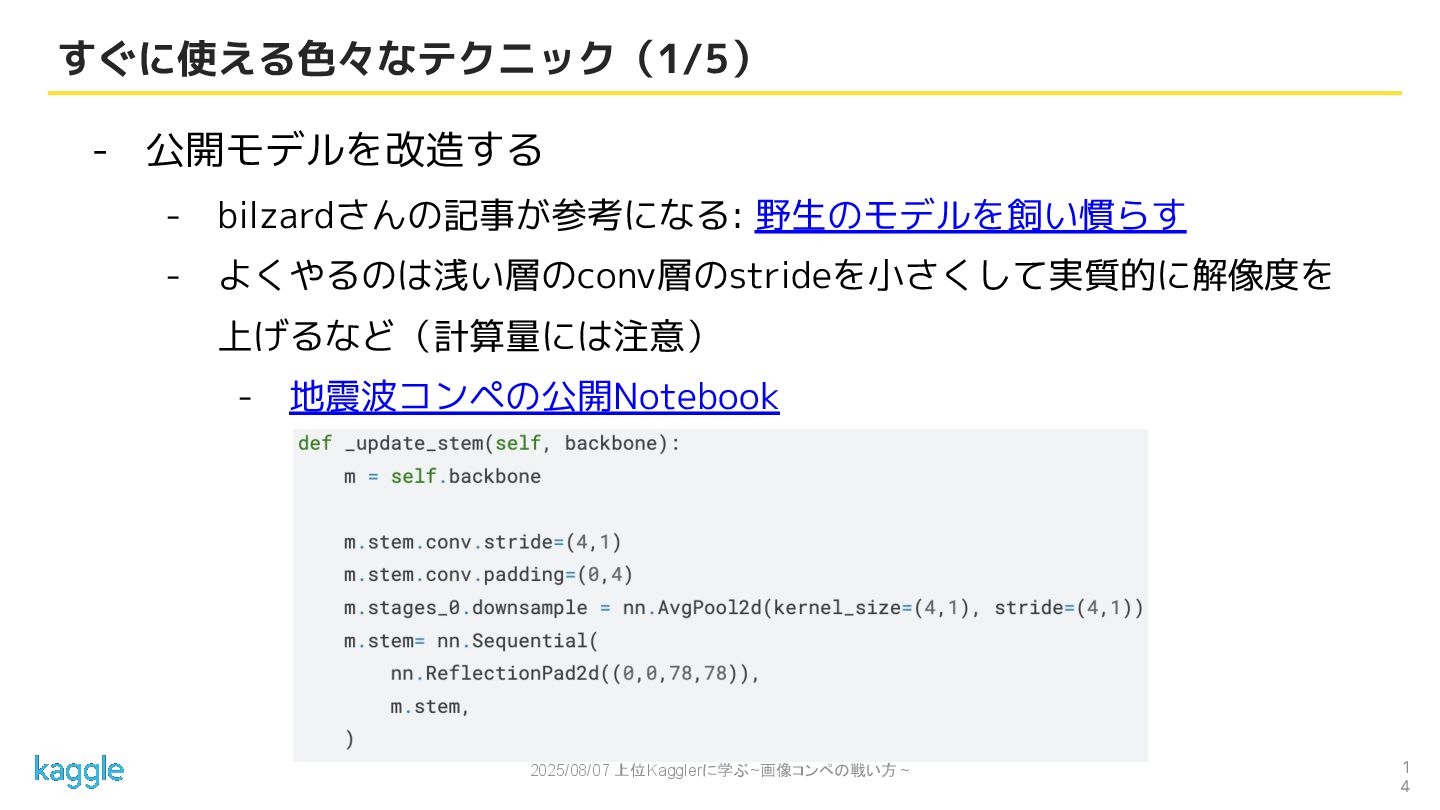
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 1 4 すぐに使える色々なテクニック(1/5) - 公開モデルを改造する - bilzardさんの記事が参考になる:
野生のモデルを飼い慣らす - よくやるのは浅い層のconv層のstrideを小さくして実質的に解像度を 上げるなど(計算量には注意) - 地震波コンペの公開Notebook
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 1 5 すぐに使える色々なテクニック(2/5) - Exponential Moving Average(EMA)
- 学習中にstepごとにモデルウェイトの移動平均を取る手法 - 収束は遅くなるが、val_loss・metricが安定する - epoch数と一緒に調整する - 汎化性能も上がってそう(お気持ち)なので EMA前提でベースライン構築をすることも多い - timm.utils.ModelEmaV3 が便利 - Label Smoothing - 0/1ラベルを0.1/0.9のように変換し、モデルがラベルノイズに対して 敏感にならないようにする
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 1 6 すぐに使える色々なテクニック(3/5) - Mixup・CutMix - 2つの学習データを混合して新しい学習データを作る手法
- 入力画像を混ぜる代わりに中間層の出力を混ぜる Manifold Mixupも有効なことがある - 最終層でMIXUPしたら良さげだった件 - targetを混ぜる・lossを混ぜるのどちらもある - 個人的には後者が好きだが、タスクによって改造しやすいのは前者 - targetを重み付け和ではなく論理和で混ぜる例: SETIコンペ 2nd solution
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 1 7 すぐに使える色々なテクニック(4/5) データ不均衡への対処 - FocalLoss・Online Hard
Example Mining(OHEM) - 少数クラス=学習が難しいサンプルとみなして重みを増やす手法 - BCEWithLogitsLossのpos_weight、CrossEntropyLossのweight を調整して少数クラスの重みを増やす - オーバー・ダウンサンプリング - 少数データを水増しする or 多数データを間引く - 適切なepoch数も変わってくるので適宜修正
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 1 8 すぐに使える色々なテクニック(5/5) - 閾値の最適化 - メトリック計算に閾値が必要な場合、0.5などを決めうちで閾値を切る
よりもscipy.optimize.minimizeを使ってCVに最適化する方が良いこと が多い(オーバーフィットには注意) - パーセンタイルベースの閾値設定 - 固定値で閾値を切るのではなく、出力値のパーセンタイルで 閾値を設定する手法 - モデルごとの出力値の分布のズレに頑健になる - train・val/testのGTの分布が大きく異なる時は 固定値の方が良いことも
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 1 9 アイディアを出すために(1/2) - コンペのOverviewやDataの説明をよく読みましょう - ドメイン知識を深める
- ホストが書いたコンペ設計に関する論文を探して読む - アノテーションルールはどうなっているのか? - 外部データはあるかどうか - etc…
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 2 0 アイディアを出すために(2/2) - 似た過去コンペの解法を参考にする - ベースラインを作る時にも有用
- Discussionは基本全て目を通した方が良い - vote数が少なくても重要な情報が書かれていることもある - EDA Notebookもあれば見ておく・自分でも動かす - エラーケース分析 - FN/FPどちらの間違え方をしているかなどを見る - 可視化して間違え方に特徴がないかを探す
2025/08/07 上位Kagglerに学ぶ~画像コンペの戦い方 ~ 21 最後に - いろいろなテクニックを紹介しましたが、時間・計算リソースは 有限なので仮説を立ててから実験することが大事 - この施策はどういう時に効くからこんな結果になるはずだ
- 思った結果にならないならなんでだろう -> 新しい仮説を立てる の繰り返し
4th Pace Solution by team “yu4u & tattakaˮ 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}