Littwin, E., and Webb, R. (2025). Distillation scaling laws. arXiv preprint arXiv:2502.08606. Feng, G., Zhang, B., Gu, Y., Ye, H., He, D., and Wang, L. (2023). Towards revealing the mystery behind chain of thought: a theoretical perspective. In Advances in Neural Information Processing Systems. Goyal, K., Dyer, C., and Berg-Kirkpatrick, T. (2017). Differentiable scheduled sampling for credit assignment. In Association for Computational Linguistics. Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. (2025). DeepSeek-R1: incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948. Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Carney, A., et al. (2024). OpenAI o1 system card. arXiv preprint arXiv:2412.16720. Kimi, T., Du, A., Gao, B., Xing, B., Jiang, C., Chen, C., Li, C., Xiao, C., Du, C., Liao, C., et al. (2025). Kimi k1.5: scaling reinforcement learning with LLMs. arXiv preprint arXiv:2501.12599. Li, H., Wang, M., Lu, S., Cui, X., and Chen, P.-Y. (2024a). How do nonlinear transformers acquire generalization-guaranteed CoT ability? In High-dimensional Learning Dynamics 2024: The Emergence of Structure and Reasoning. Li, Y., Sreenivasan, K., Giannou, A., Papailiopoulos, D., and Oymak, S. (2023). Dissecting chain-of-thought: compositionality through in-context filtering and learning. In Advances in Neural Information Processing Systems. Li, Z., Liu, H., Zhou, D., and Ma, T. (2024b). Chain of thought empowers transformers to solve inherently serial problems. In International Conference on Learning Representations. 26
{kind=link}
{kind=link}
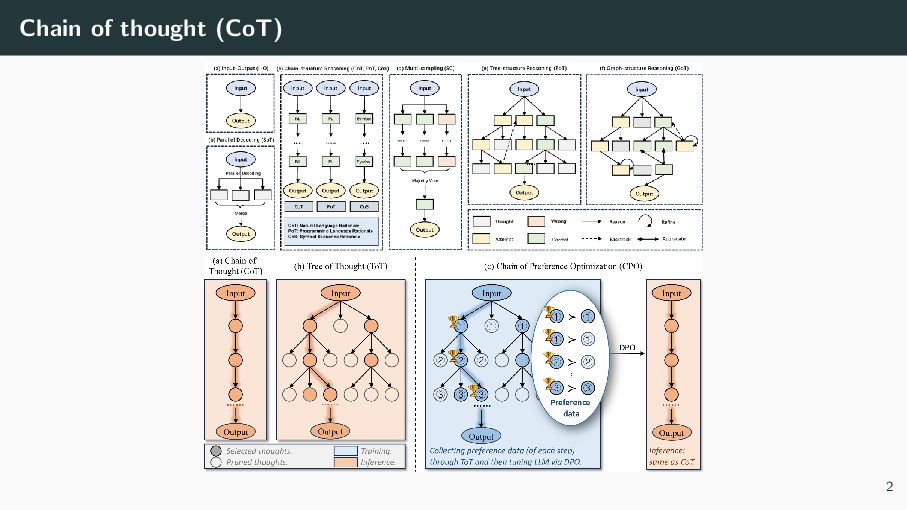{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
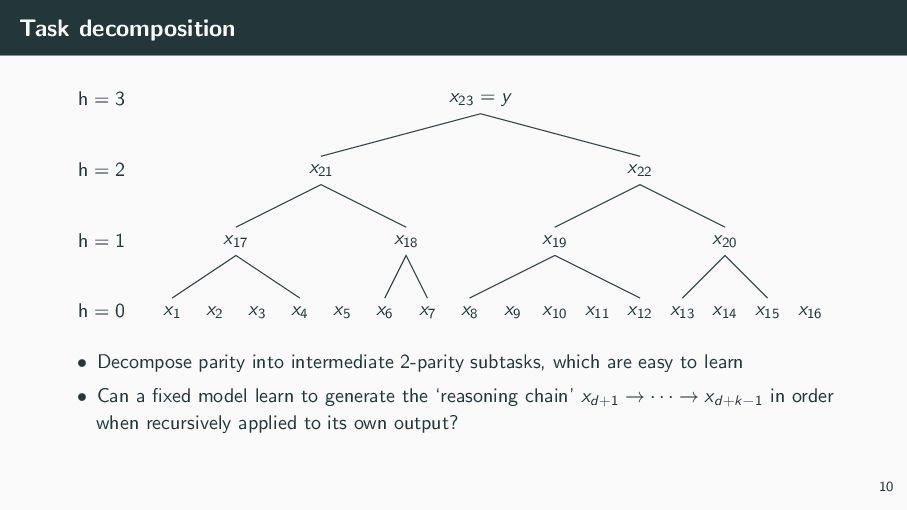{kind=link}
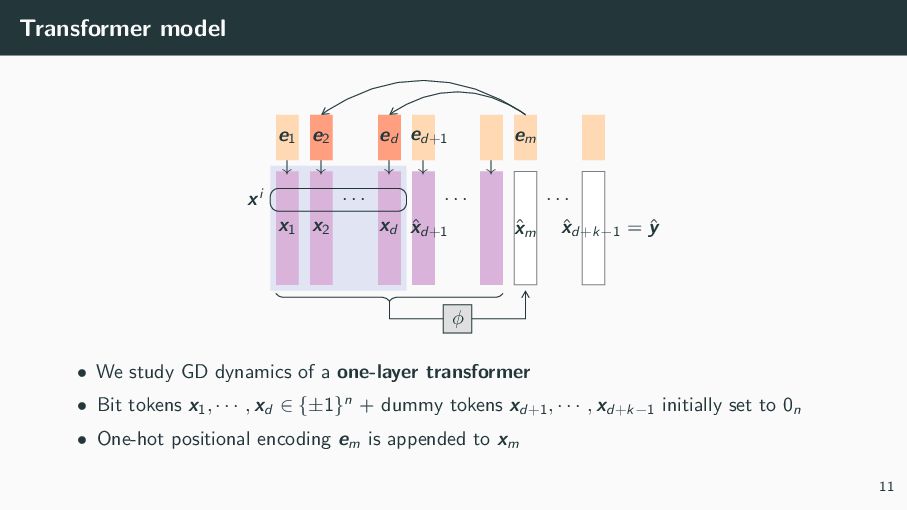{kind=link}
{kind=link}
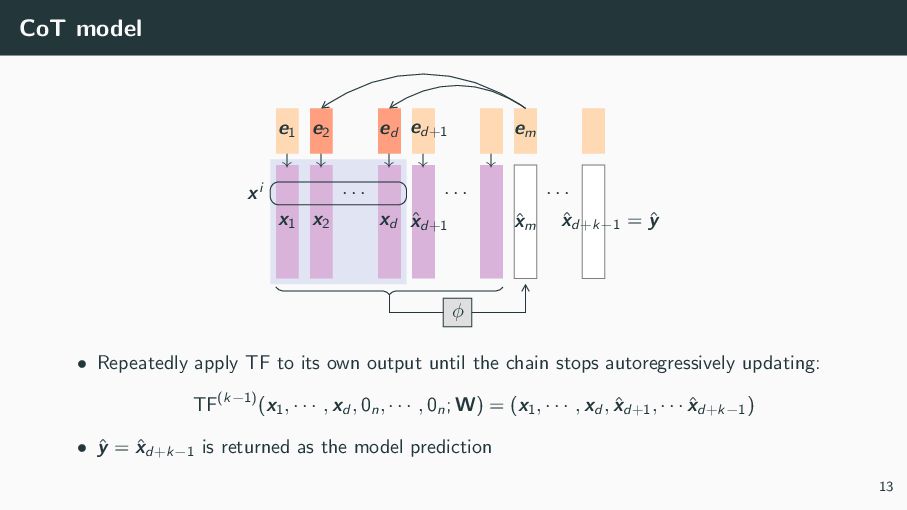{kind=link}
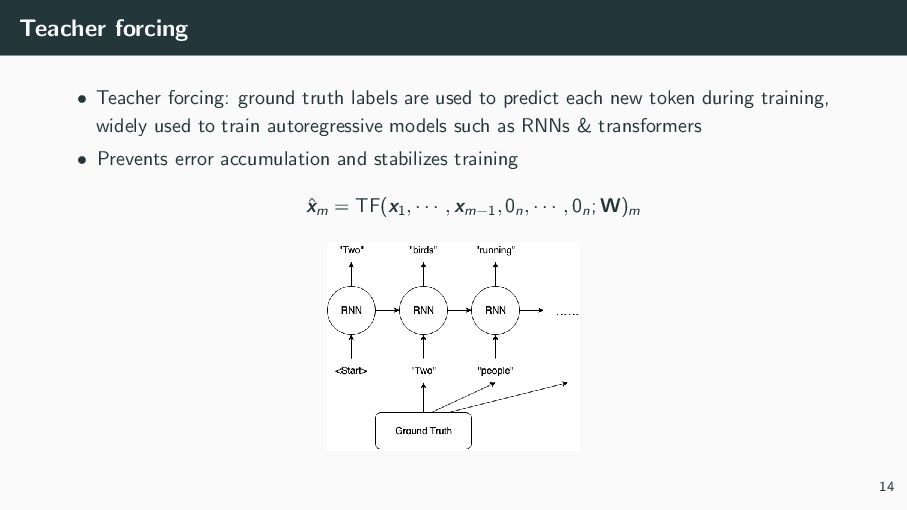{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
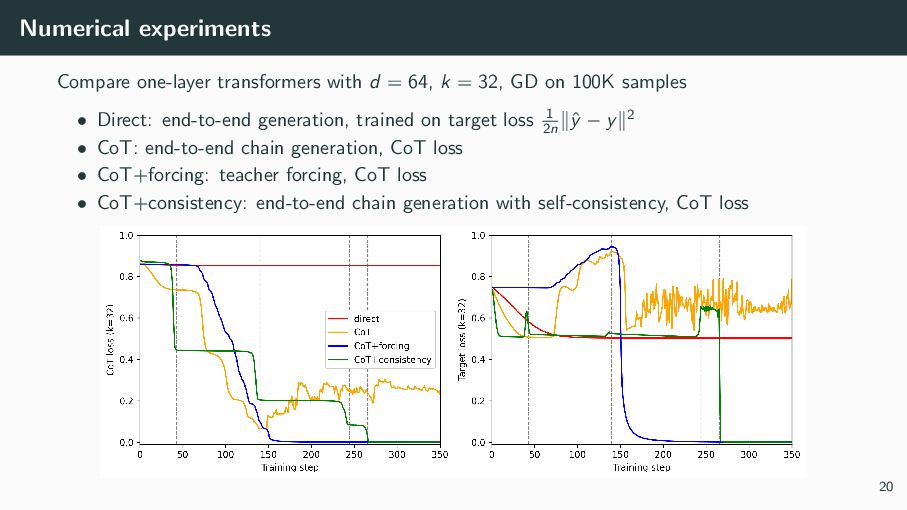{kind=link}
{kind=link}
{kind=link}
{kind=link}
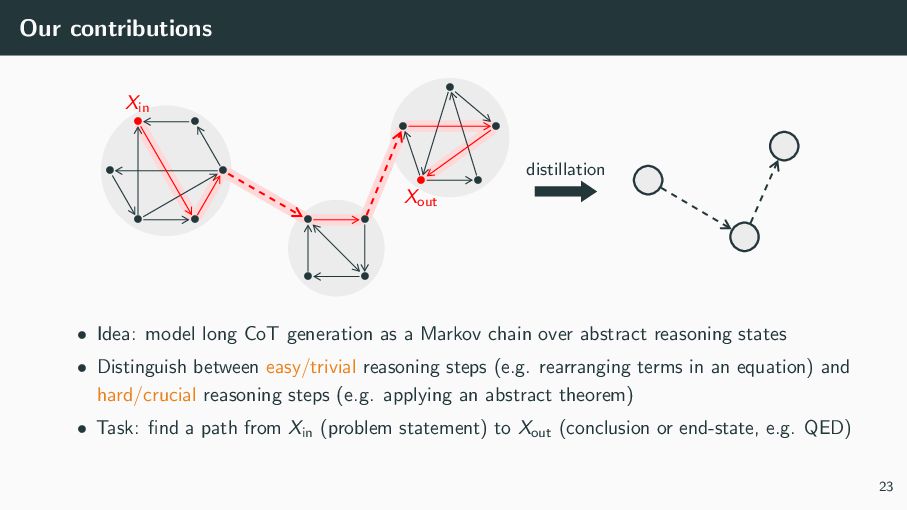{kind=link}
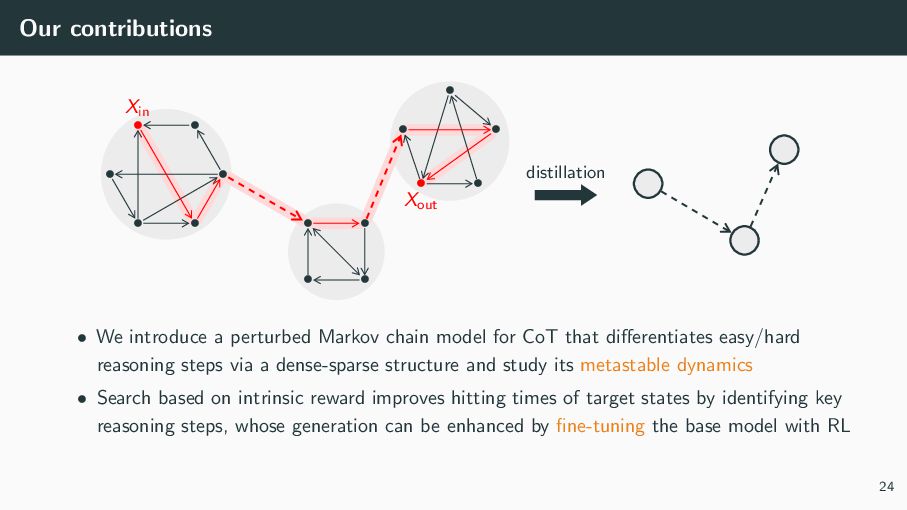{kind=link}
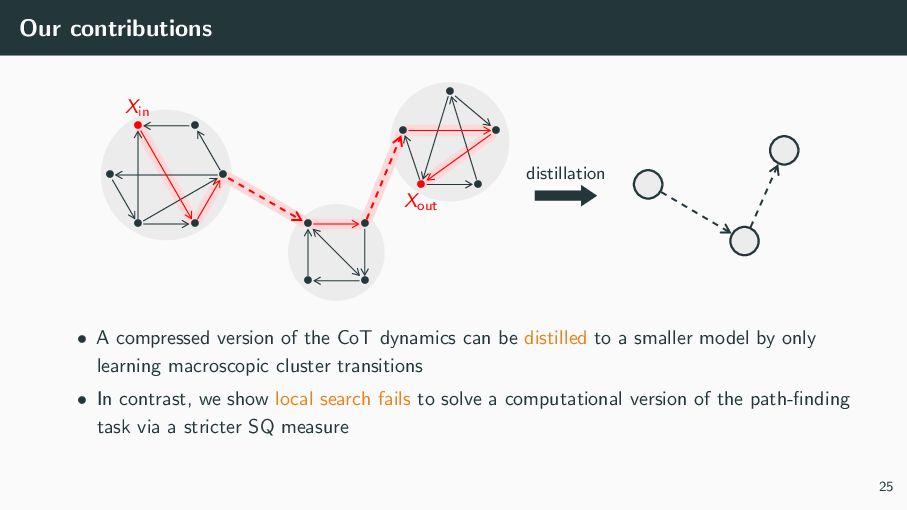{kind=link}
{kind=link}
{kind=link}
{kind=link}