本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
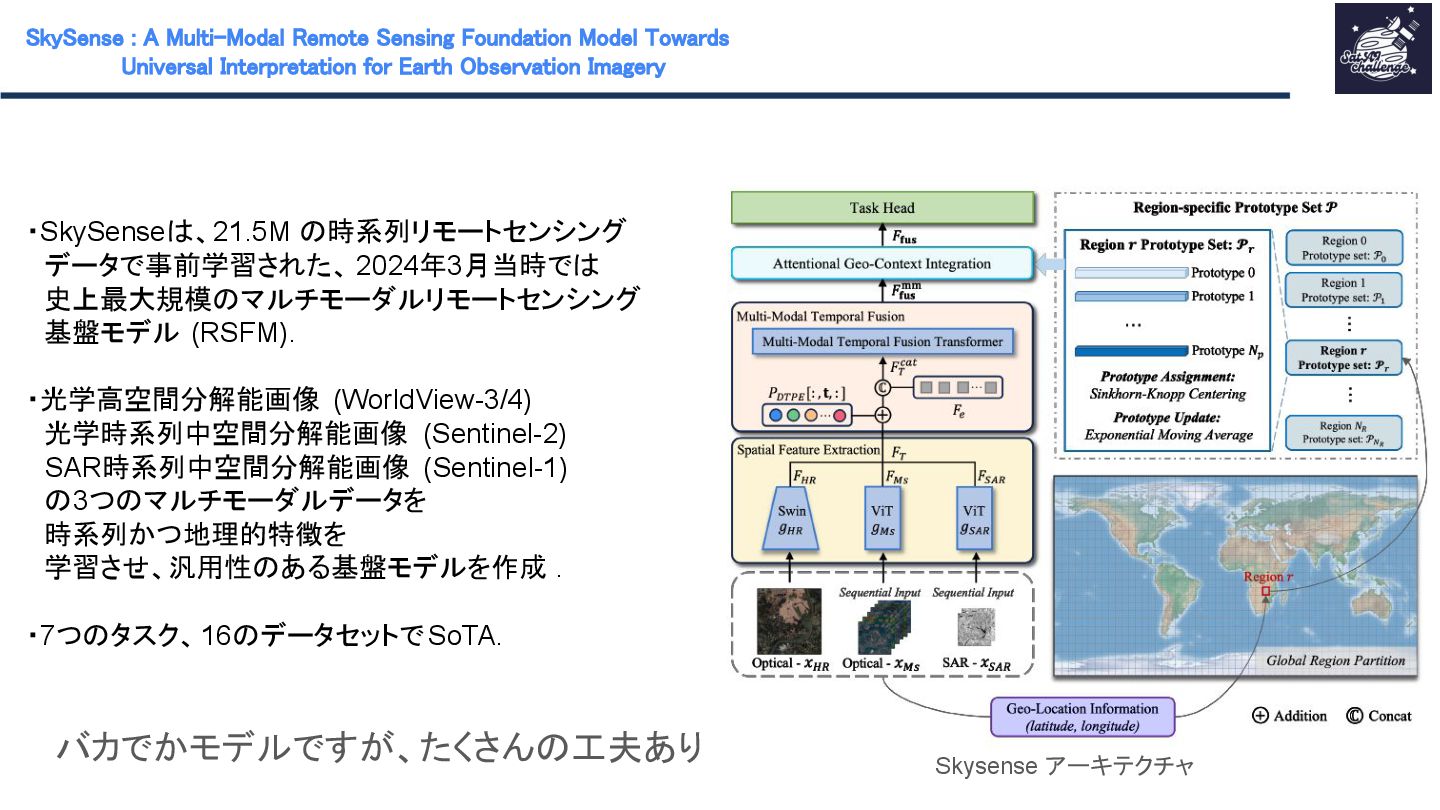
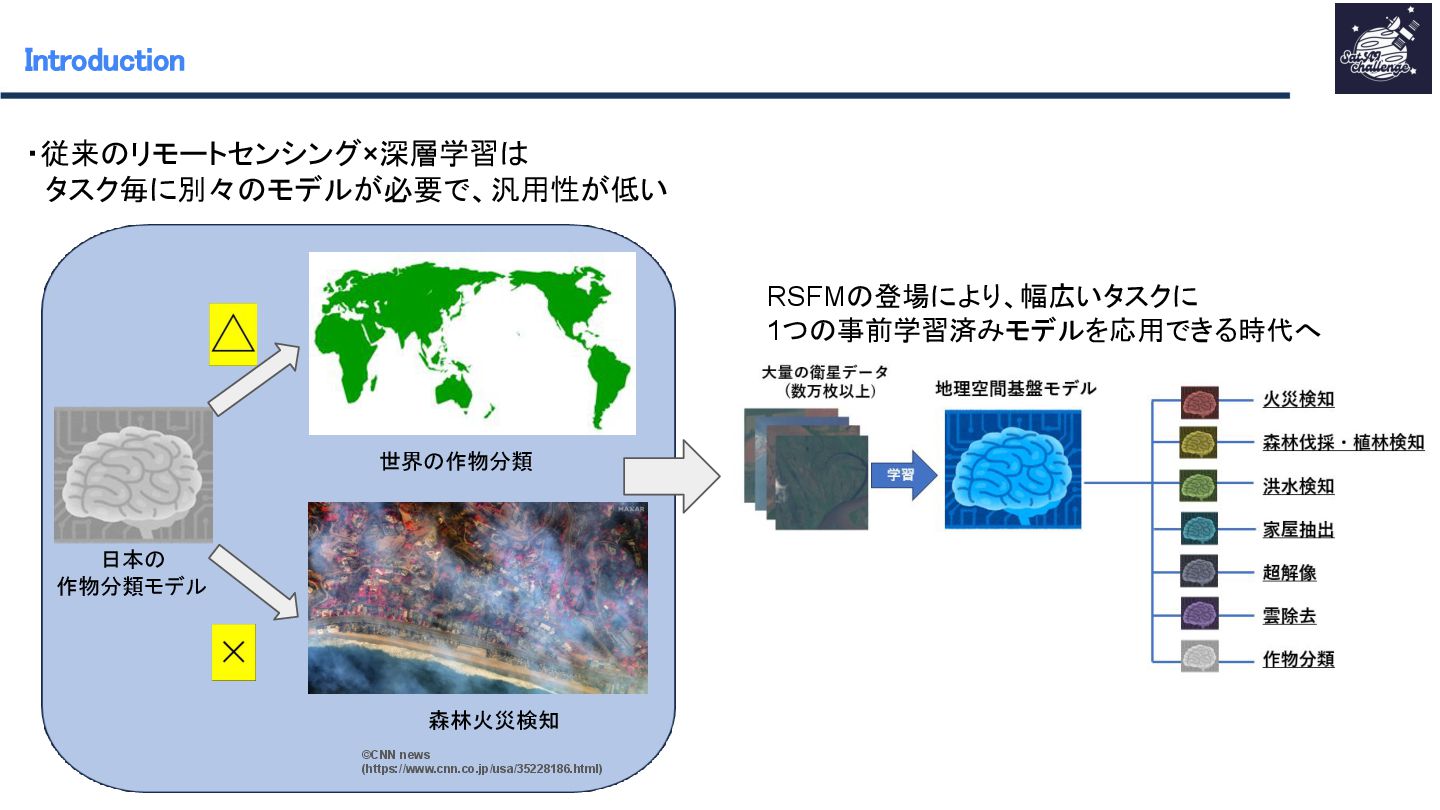
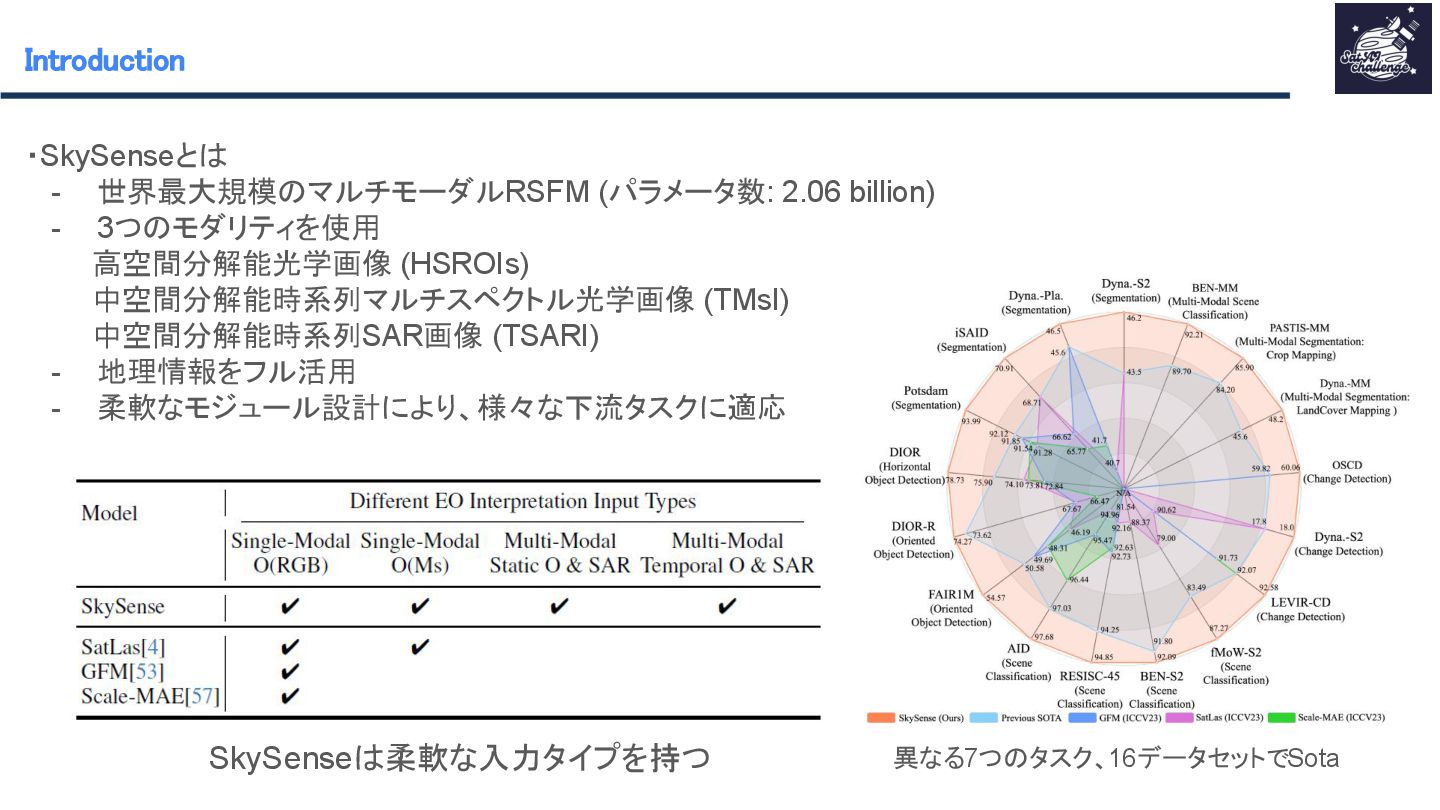
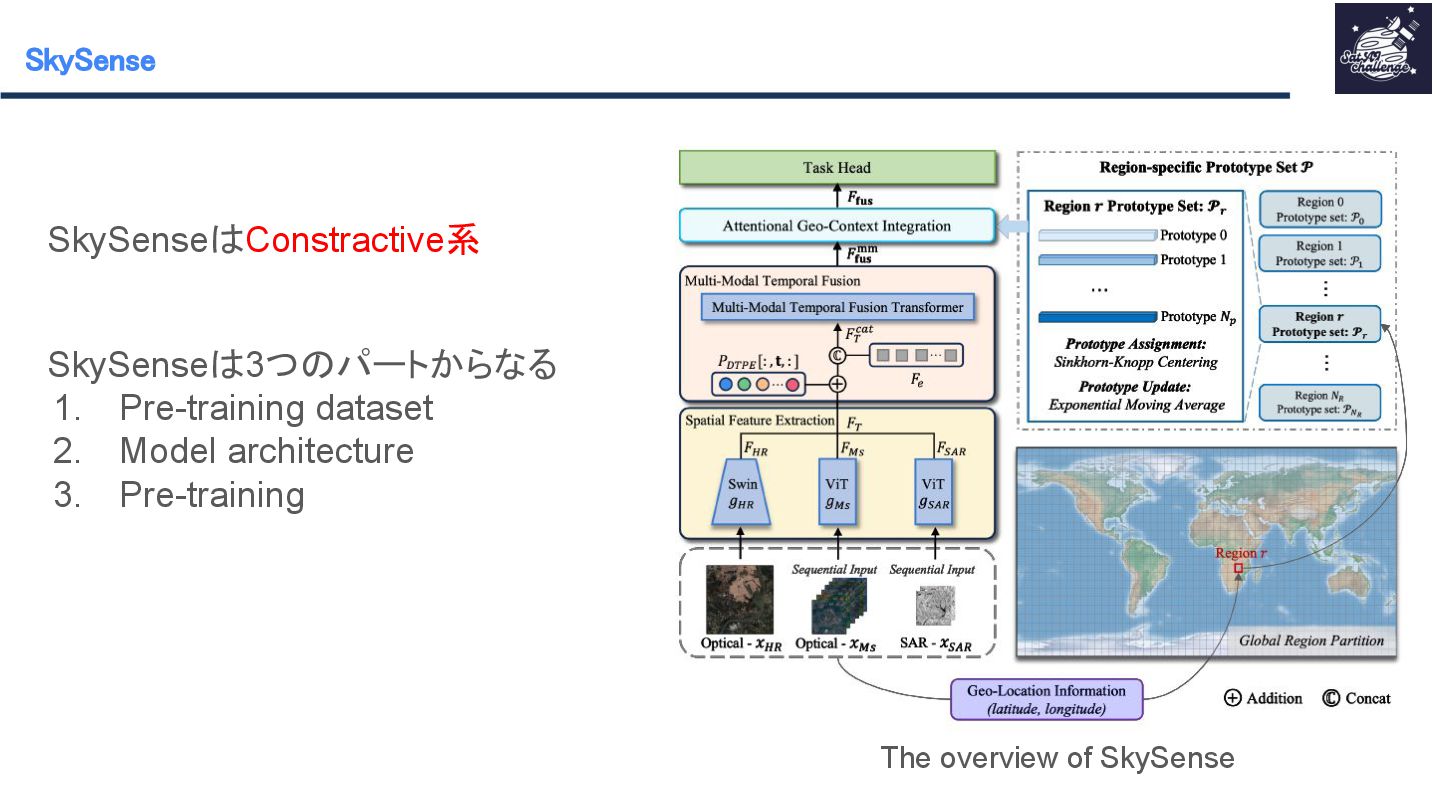
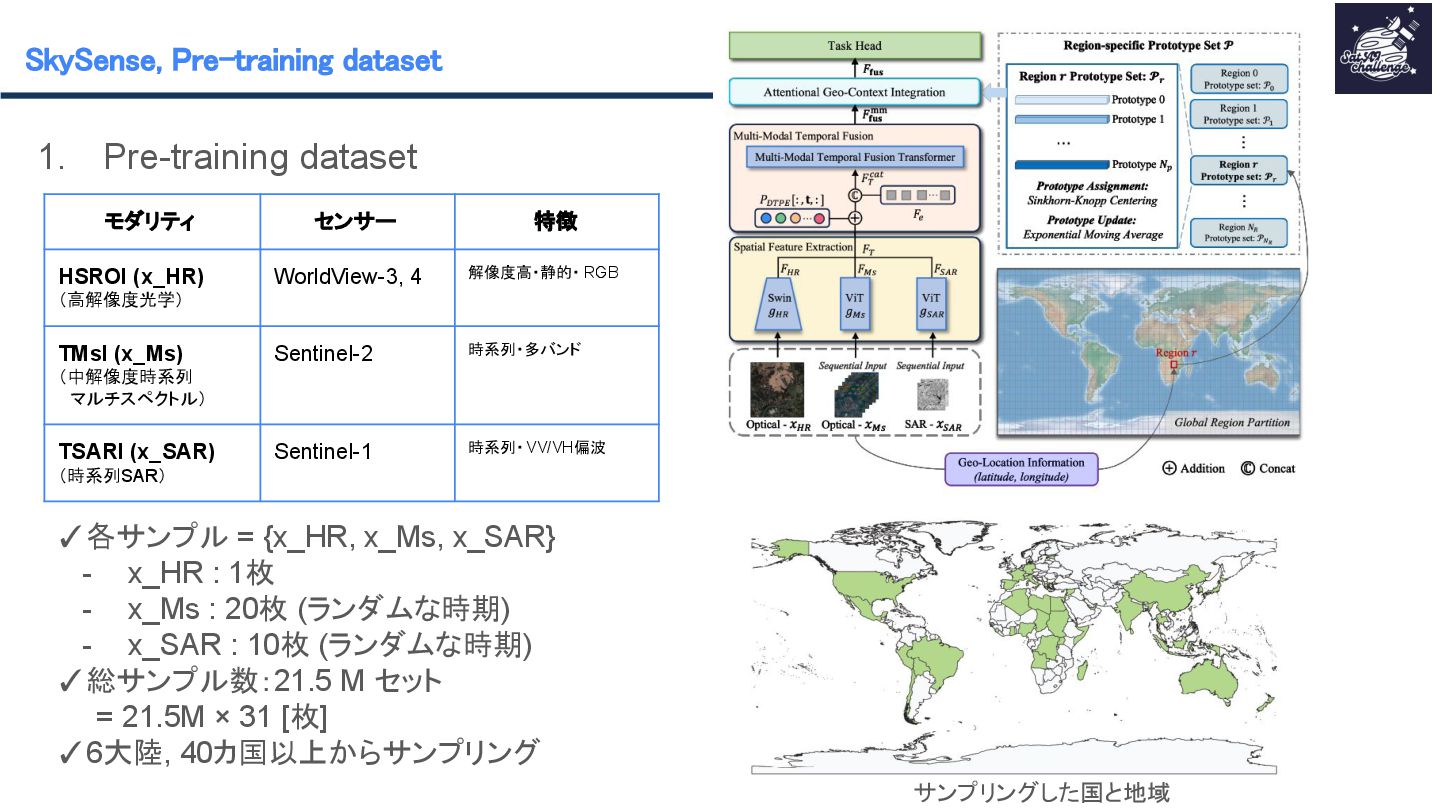
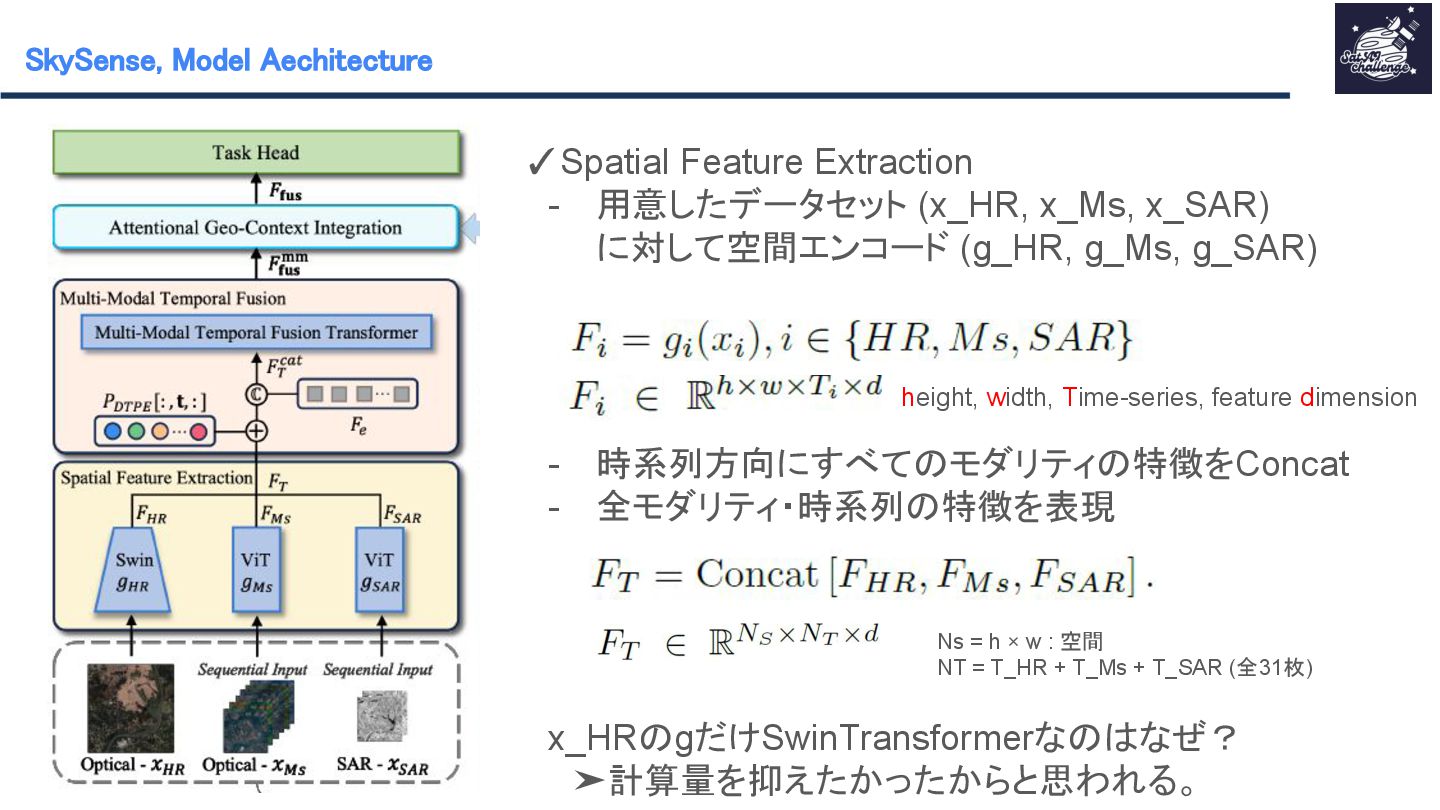
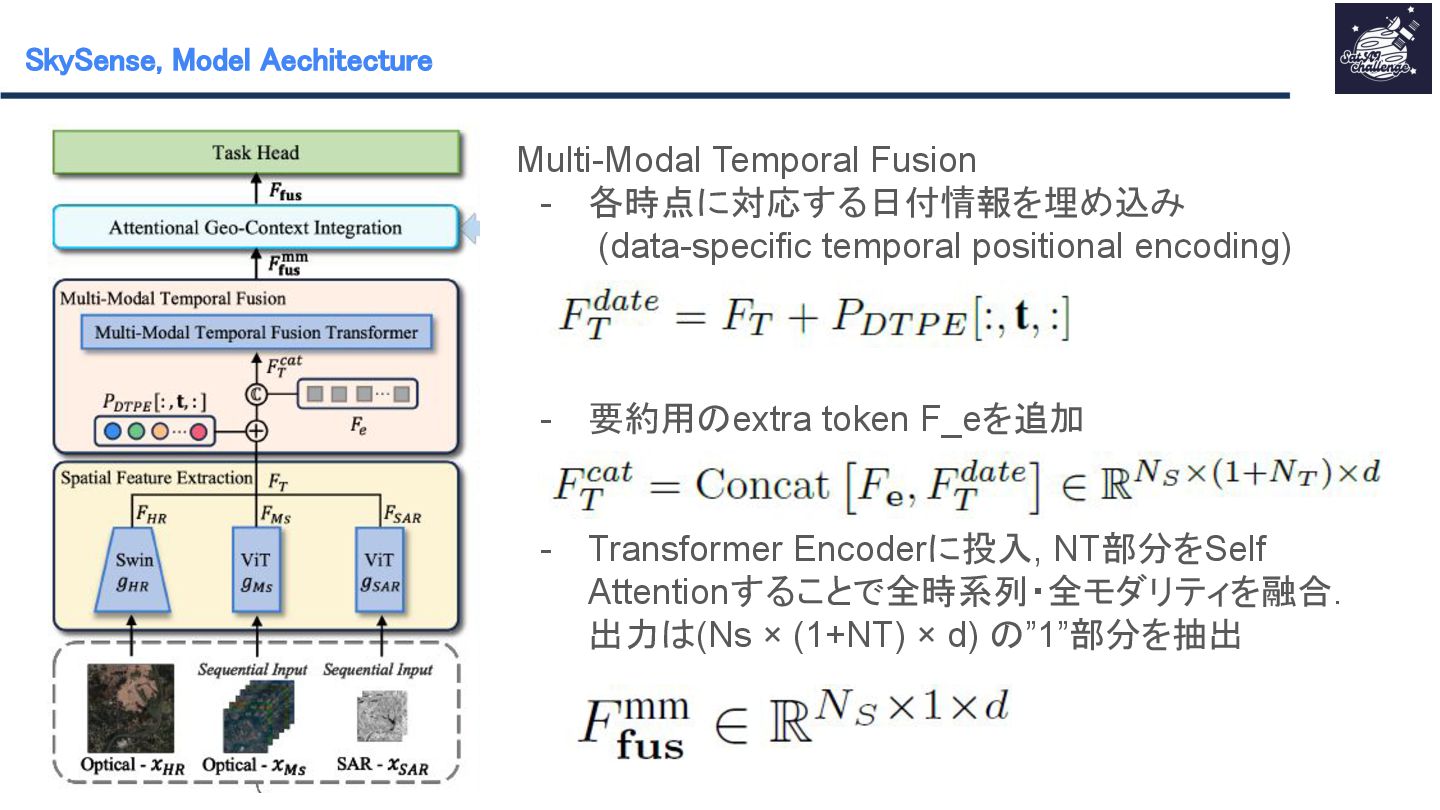
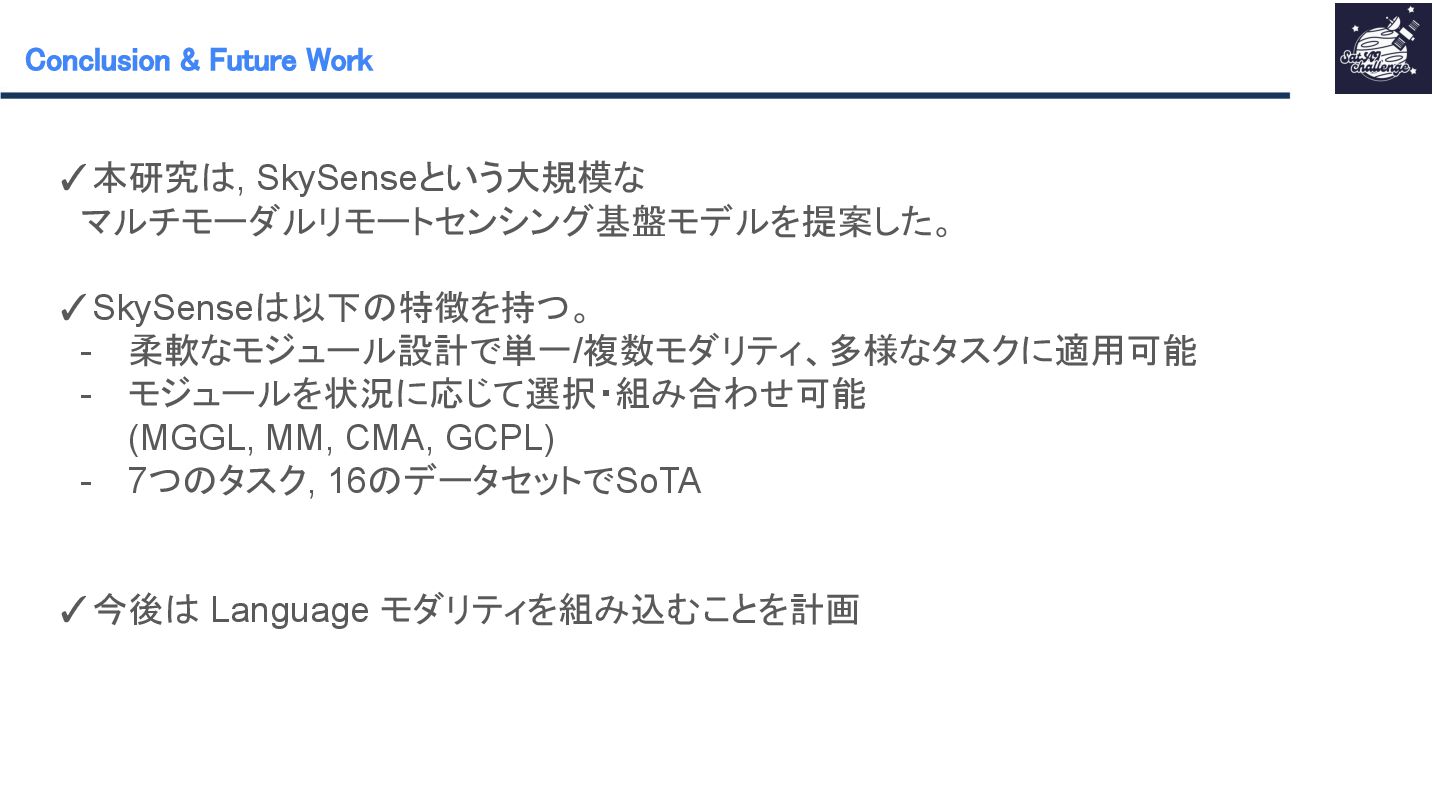
紹介する論文は 「SkySense : A Multi-Modal Remote Sensing Foundation Model Towards Universal Interpretation for Earth Observation Imagery」です。SkySenseはWorldView-3/4の高空間分解能光学衛星データ、Sentinel-2の時系列中空間分解能光学衛星データ、Sentinel-1の時系列中空間分解能SAR衛星データという3つのモダリティを統合し、マルチモーダルな特徴学習を実現する自己教師ありの大規模リモートセンシング地理空間基盤モデルです。時系列データ、複数スケール、モダリティ間、地理的特徴を学習させることで汎用性のあるモデルの作成が可能となりました。SkySenseを用いて、ベンチマークを比較した結果、7つのタスク/16のデータセットでSoTAを達成しました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
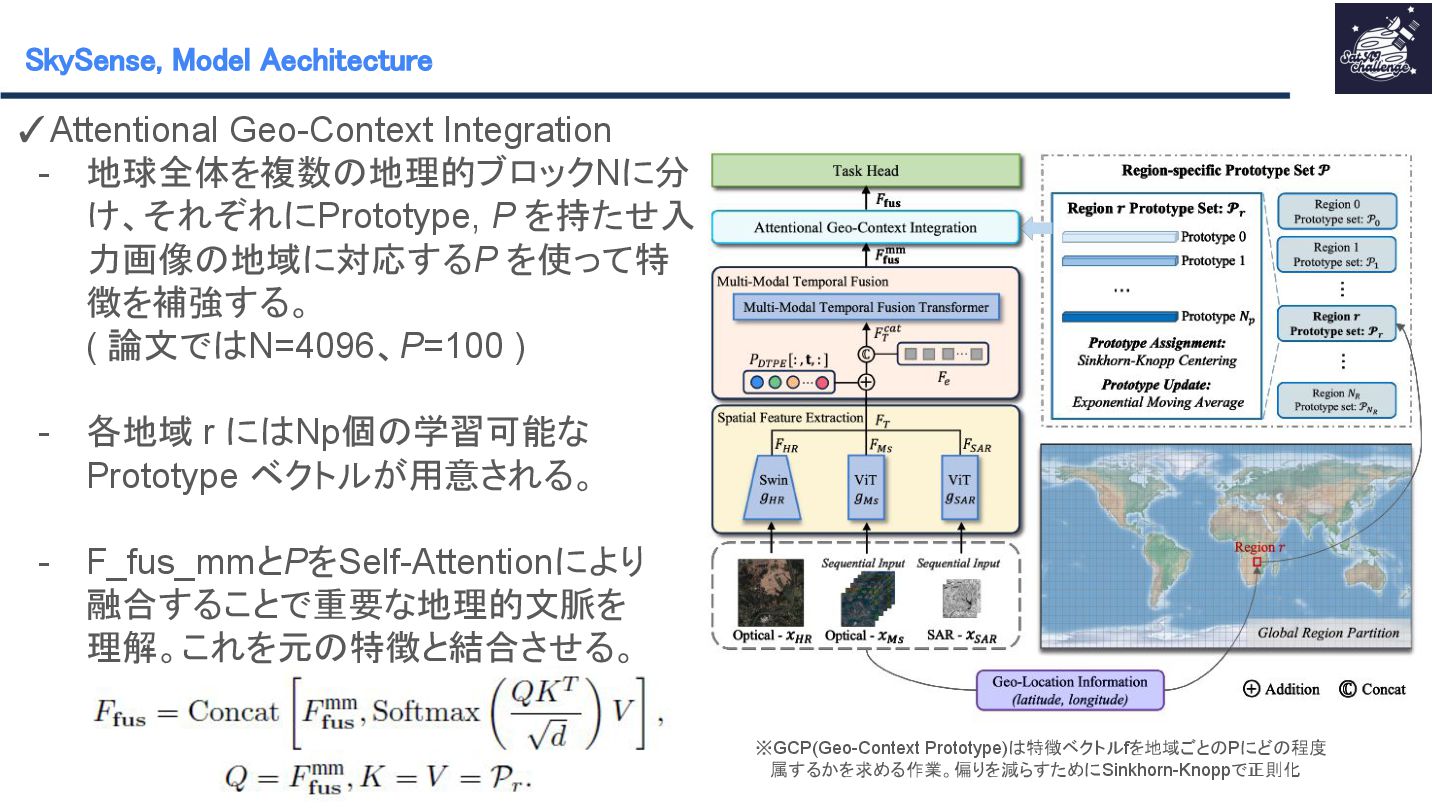{kind=link}
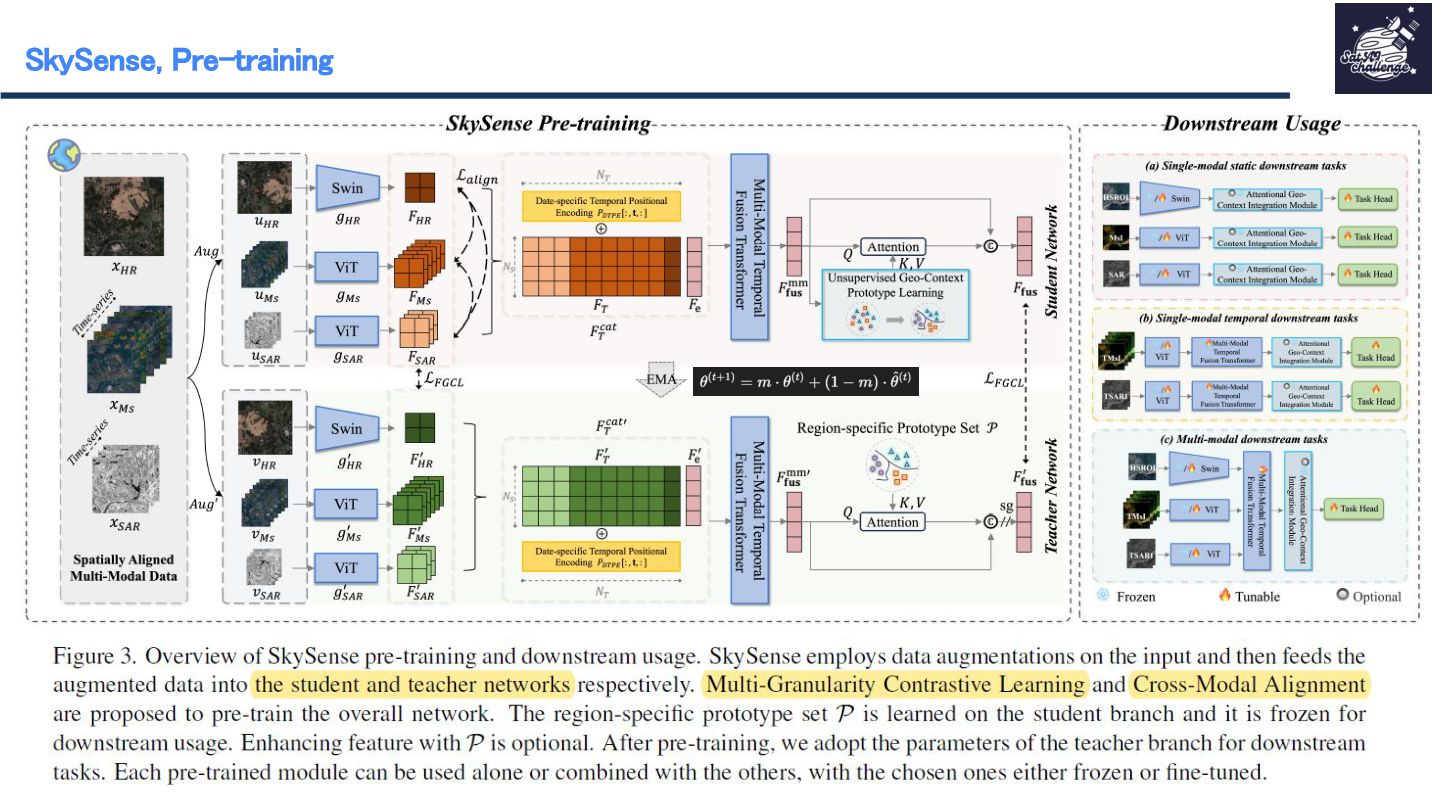{kind=link}
{kind=link}
{kind=link}
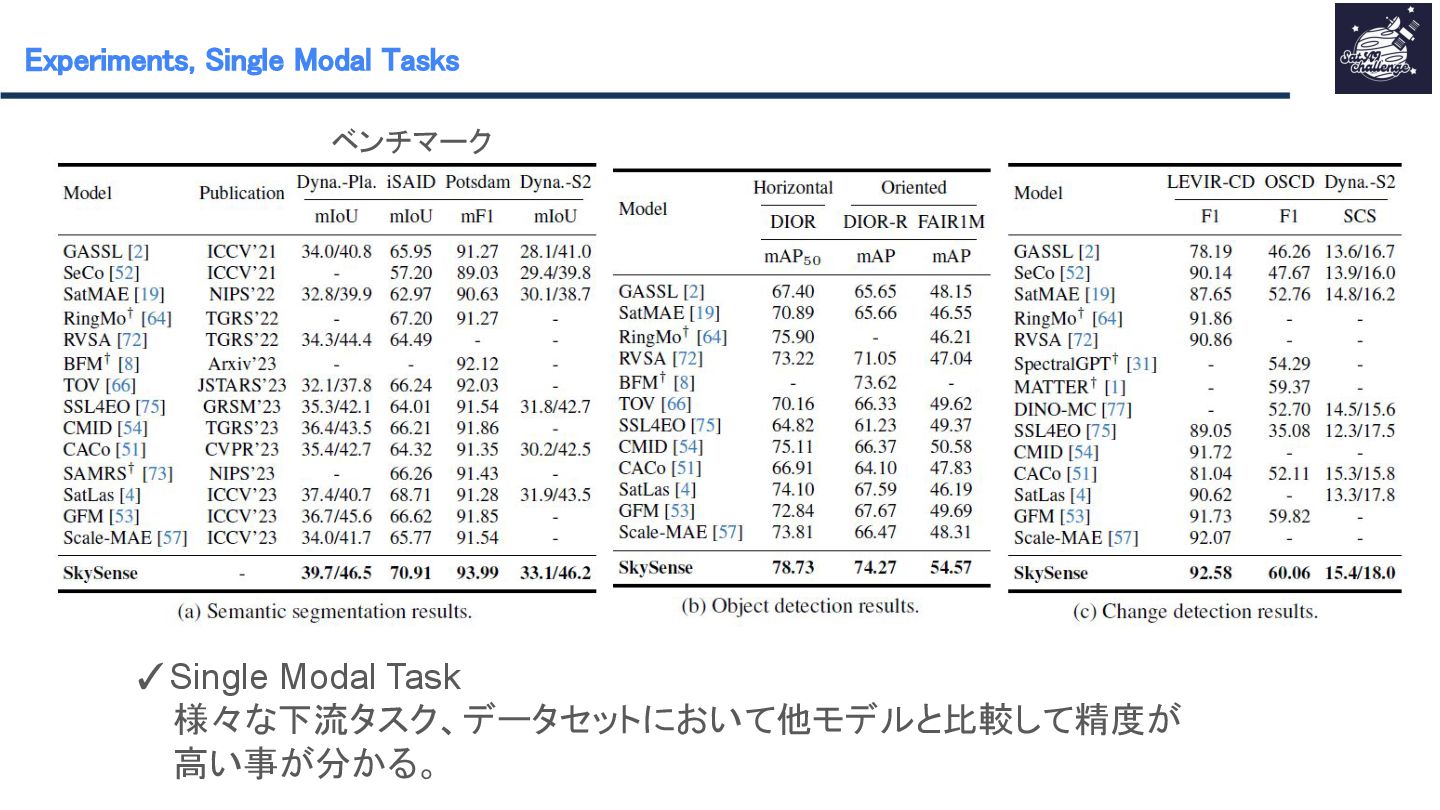{kind=link}
{kind=link}
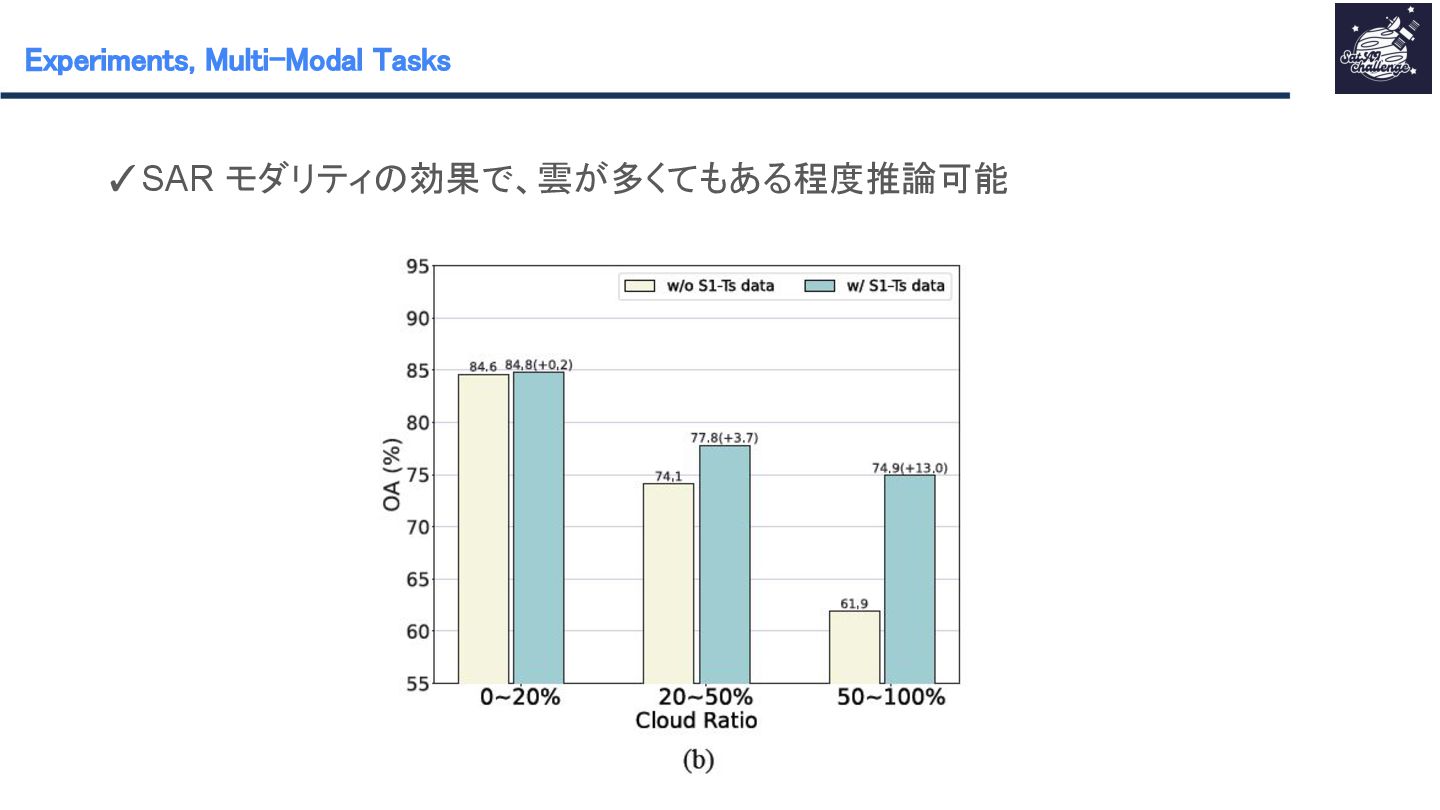{kind=link}
{kind=link}
{kind=link}