Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
DETR手法の変遷と最新動向(CVPR2025)
Search
TakatoYoshikawa
April 16, 2025
Technology
5.2k
4
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
DETR手法の変遷と最新動向(CVPR2025)
DeNA/Go CV輪講の発表時の資料です。
DETRの発展の大まかな流れとCVPR2025採択手法(Mr. DETR, DEIM)についてまとめました。
TakatoYoshikawa
April 16, 2025
More Decks by TakatoYoshikawa
See All by TakatoYoshikawa
論文紹介:Pixal3D (SIGGRAPH 2026)
tenten0727
0
880
Segment Anything Modelの最新動向:SAM2とその発展系
tenten0727
0
2.7k
YOLOv10~v12
tenten0727
6
1.9k
Segment Anything Model 2 (SAM2)
tenten0727
4
2.8k
Other Decks in Technology
See All in Technology
「最後に責任を取るのはチーム」— 人間のPRレビューを最小化してアップデートしたメンタルモデル
jnishime_dresscode
0
340
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
3.4k
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
110
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
cccccc
moznion
0
1.9k
AICoEでAIネイティブ組織への進化
yukiogawa
0
120
キャリアの中で本を作る / Making a Book During Your Career
ak1210
0
130
AI駆動開発におけるQAエンジニアの役割事例 〜AI駆動開発の現場から〜
kobayashiyorimitsu
0
480
DatabricksにおけるMCPソリューション
taka_aki
1
220
Making sense of Google’s agentic dev tools
glaforge
1
150
AI時代のエンジニアキャリアについて今一度考える
sakamoto_582
2
1.5k
Docker Desktop不要の時代が来る? WSL標準の「wslc」で Linuxコンテナを動かしてみた.
ueponx
0
920
Featured
See All Featured
A Tale of Four Properties
chriscoyier
163
24k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Stewardship and Sustainability of Urban and Community Forests
pwiseman
0
270
From Legacy to Launchpad: Building Startup-Ready Communities
dugsong
0
260
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
330
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Technical Leadership for Architectural Decision Making
baasie
3
440
Typedesign – Prime Four
hannesfritz
42
3.1k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
230
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
760
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Transcript
AI 2025.3.21 Takato Yoshikawa 株式会社ディー・エヌ・エー + GO株式会社 DETR手法の変遷と 最新動向(CVPR2025)
AI 2 ▪ End-to-end Object Detection ▪ End-to-end people detection
in crowded scenes [Stewart+, CVPR2016] ▪ End-to-end object detection with Transformers(DETR) [Carion+, ECCV2020] ▪ アーキテクチャ・学習方法の改良 ▪ Deformable DETR: Deformable Transformers for End-to-End Object Detection [Zhu+, ICLR2021] ▪ DAB-DETR: Dynamic Anchor Boxes are Better Queries for DETR [Liu+, ICLR2022] ▪ DN-DETR: Accelerate DETR Training by Introducing Query DeNoising [Li+, CVPR2022] ▪ DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection [Zhang+, ICLR2023] ▪ Real-time Object Detection ▪ DETRs Beat YOLOs on Real-time Object Detection [Zhao, CVPR2024] ▪ 最新手法 ▪ Mr. DETR: Instructive Multi-Route Training for Detection Transformers [Zhang+, CVPR2025] ▪ DEIM: DETR with Improved Matching for Fast Convergence [Huang+, CVPR2025] 紹介論文
AI 3 01 End-to-end Object Detection
AI 4 ▪ End-to-end Object Detectionの原型 1. CNNで特徴抽出 2. 特徴ベクトルをLSTMに入力し、confidenceが高い順にBBox出力
▪ 64x64の範囲に対するBBoxを出力 ▪ confidenceがしきい値を下回ったらstop 3. すでに予測したBBoxと被っているBBoxは後処理で削除 ▪ (End-to-end?) End-to-end people detection in crowded scenes
AI 5 ▪ Loss Function ▪ 予測BoxとGTを1対1でマッチング ▪ ハンガリアンアルゴリズム ▪
左から順に優先度を高くマッチング ▪ G=マッチしたBBox, C=予測BBoxで以下を計算 →1つのGT Boxに対して1つの予測をするように学習するため 最終的なBoxを絞り込む後処理が必要なくなる!(のでend-to-endの推論が可能) End-to-end people detection in crowded scenes コスト =(候補BBox中心がGT Box内にあるか, 出力順番, 2つのBoxのL1距離) BoxのL1 Loss マッチしたかどうかのcross entropy loss
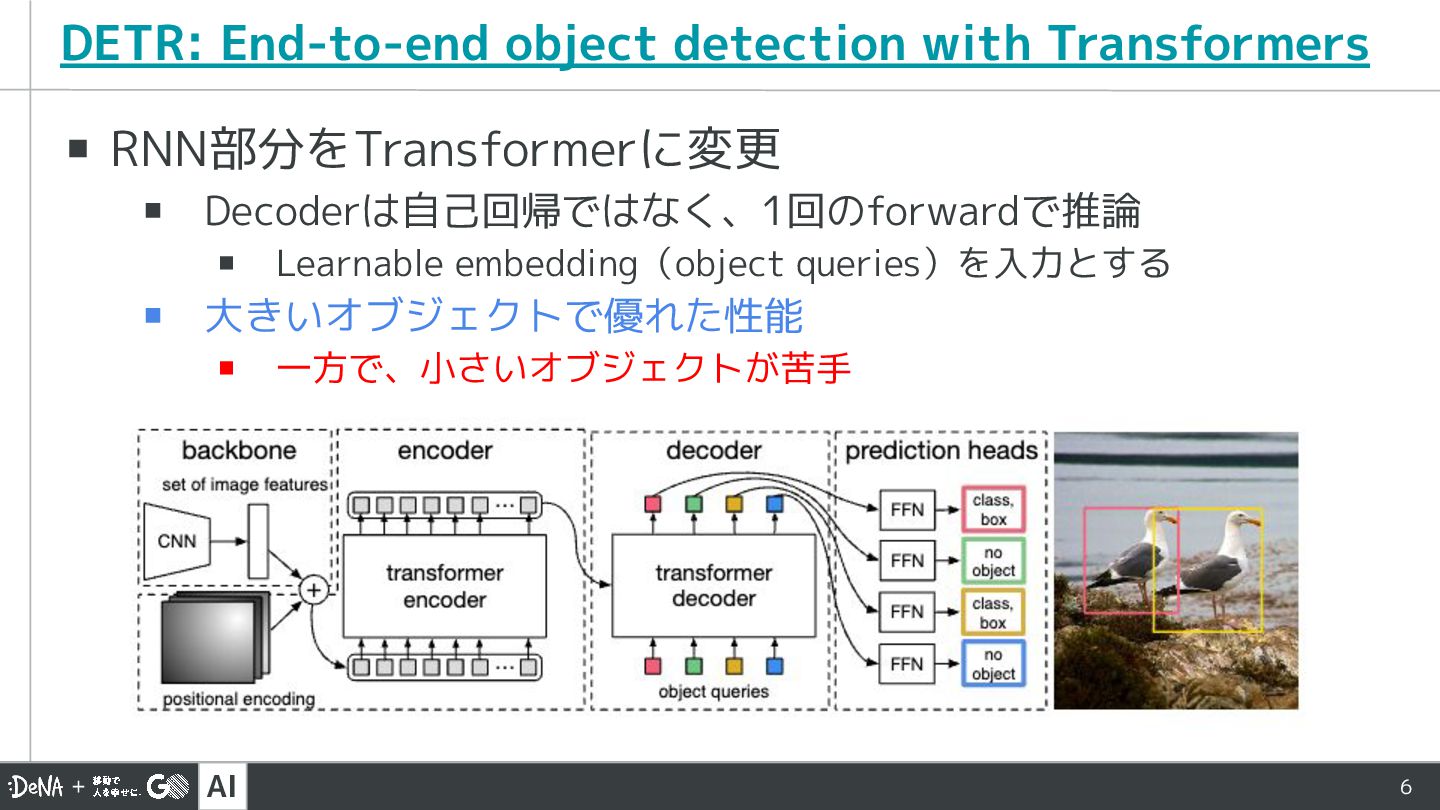
AI 6 ▪ RNN部分をTransformerに変更 ▪ Decoderは自己回帰ではなく、1回のforwardで推論 ▪ Learnable embedding(object queries)を入力とする
▪ 大きいオブジェクトで優れた性能 ▪ 一方で、小さいオブジェクトが苦手 DETR: End-to-end object detection with Transformers
AI 7 ▪ Loss Function ▪ BBox Lossの変更 ▪ L1
LossだとBoxの大きさでスケールが異なる →Generalized IoU Lossに変更 ▪ クラス分類のcross entropy loss + BBox Loss DETR: End-to-end object detection with Transformers より詳しいDETRの日本語解説記事: https://qiita.com/DeepTama/items/937e13f6beda79be17d8
AI 8 02 アーキテクチャ・学習方法の改良
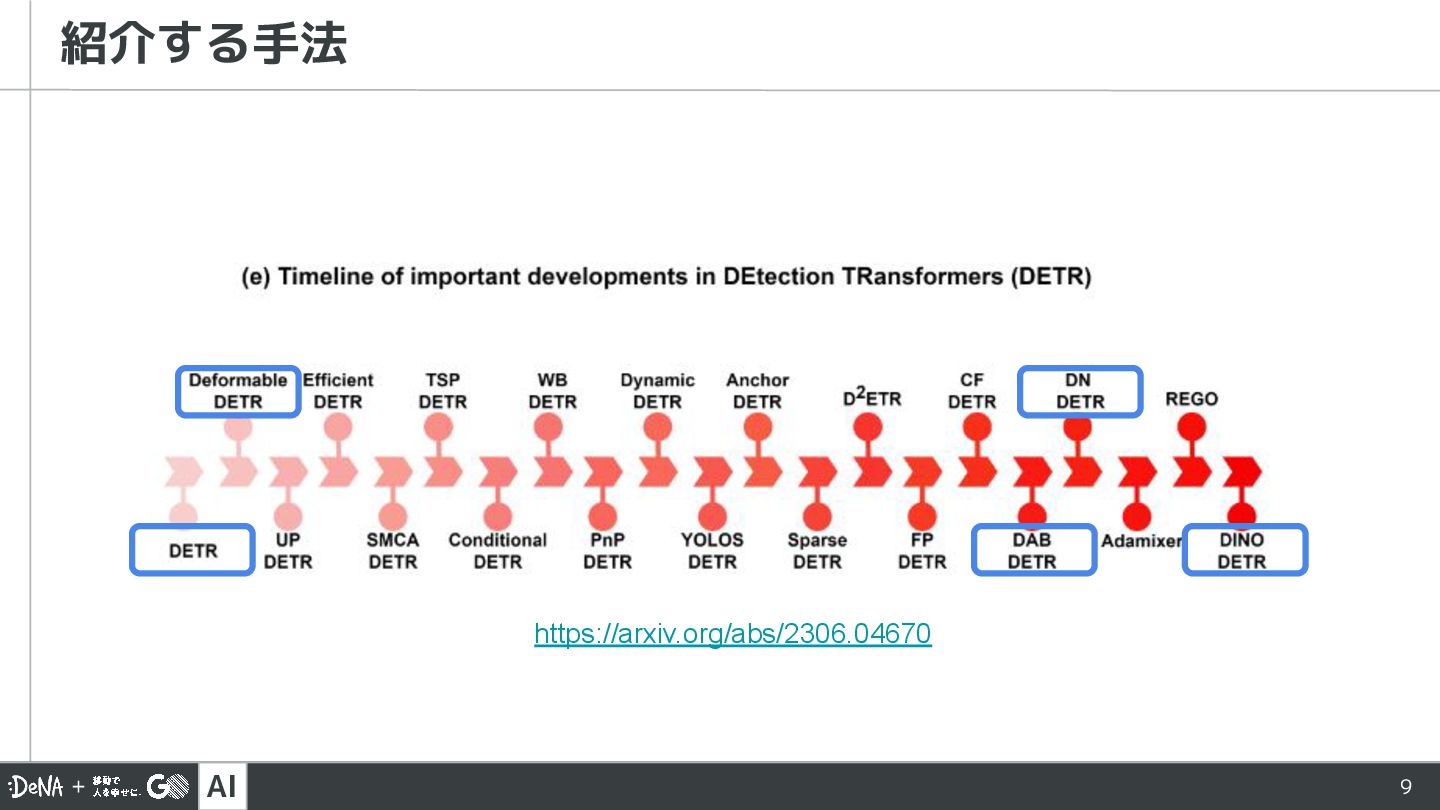
AI 9 紹介する手法 https://arxiv.org/abs/2306.04670
AI 10 ▪ DETRの課題点 1. 小さな物体の検出性能が低い 2. 収束に時間がかかる ▪ Faster
R-CNNの10~20倍 ▪ Update 1. マルチスケール特徴を使用 →高解像度特徴を使用することで小さい物体の検出精度を上げる 2. 計算・メモリ効率の高いDeformable Attentionを提案 ▪ Deformable Convolutionを参考に →マルチスケール特徴を効率的に処理しながら、収束時間を短縮 Deformable DETR
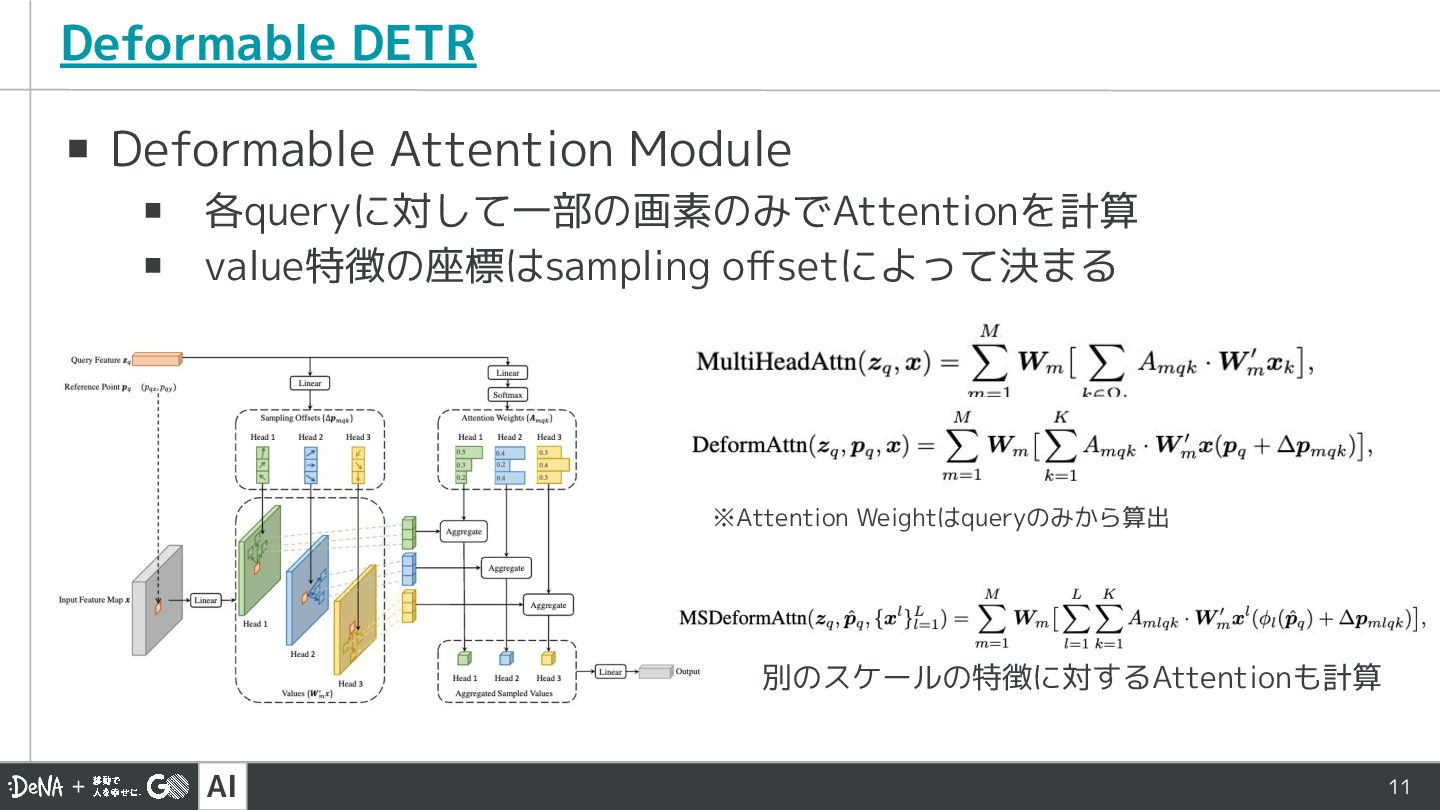
AI 11 ▪ Deformable Attention Module ▪ 各queryに対して一部の画素のみでAttentionを計算 ▪ value特徴の座標はsampling
offsetによって決まる Deformable DETR ※Attention Weightはqueryのみから算出 別のスケールの特徴に対するAttentionも計算
AI 12 ▪ Deformable Attention Module ▪ 近傍の特徴に対するAttentionのみを計算する ▪ Object
Detectionでは近傍の画素が重要になりやすいという前提を モデルに反映し、効率的なAttention計算に Deformable DETR 推論時のサンプリングポイントとAttention weight
AI 13 ▪ その他Update ▪ 反復的に予測BBoxを改善 ▪ 各Decoder layerでxywhの差分を出力 ▪
前の出力に足し合わせて、反復的にrefine ▪ Two-Stage Deformable DETR ▪ Encoderの出力特徴マップそれぞれに対して BBox回帰ヘッドと前景/背景分類ヘッドでBBoxを予測 ▪ 前景スコアが高いBBoxを反復的refineの初期値として 使い、その座標の特徴量+PEをDecoderのInputとする Deformable DETR 図:https://arxiv.org/abs/2010.04159
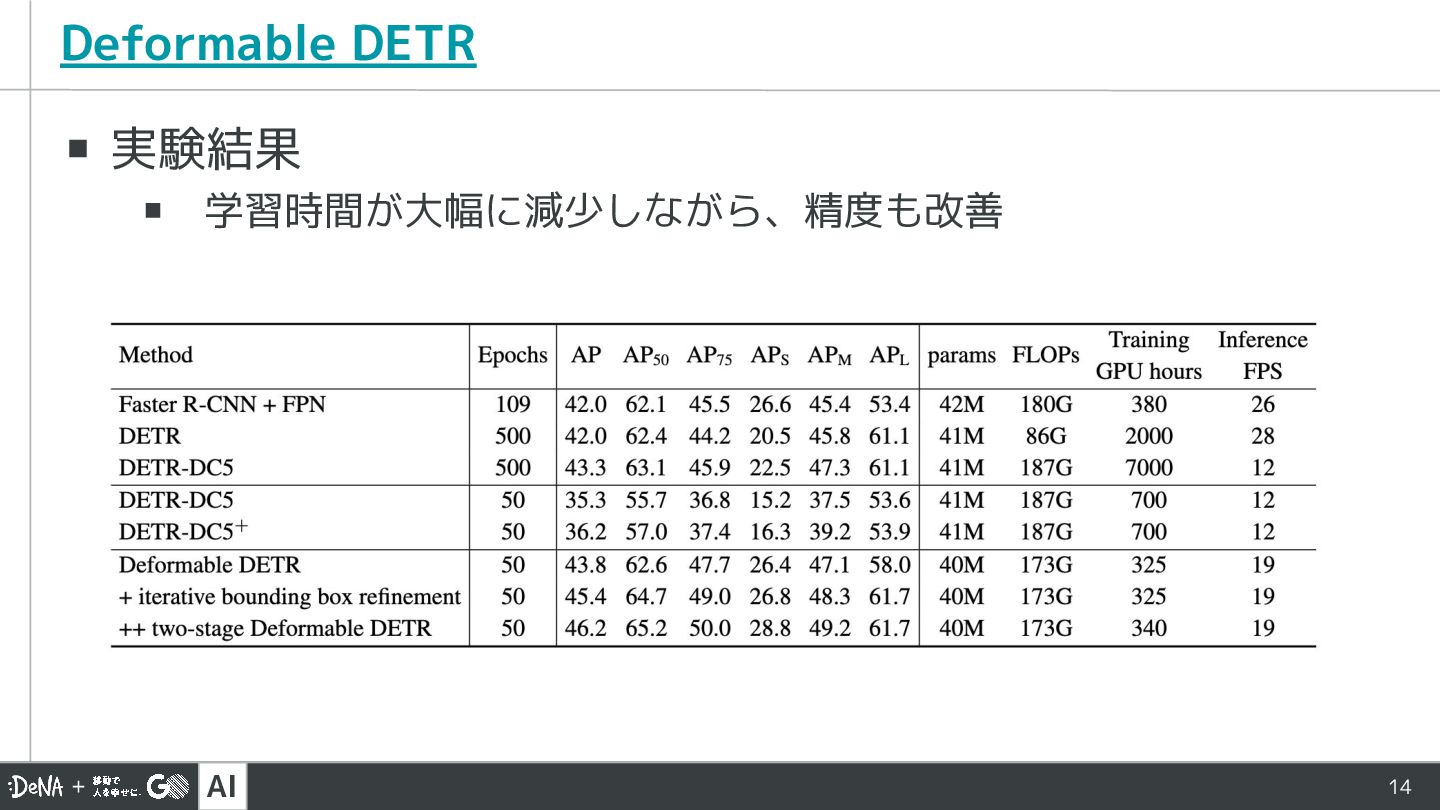
AI 14 ▪ 実験結果 ▪ 学習時間が大幅に減少しながら、精度も改善 Deformable DETR
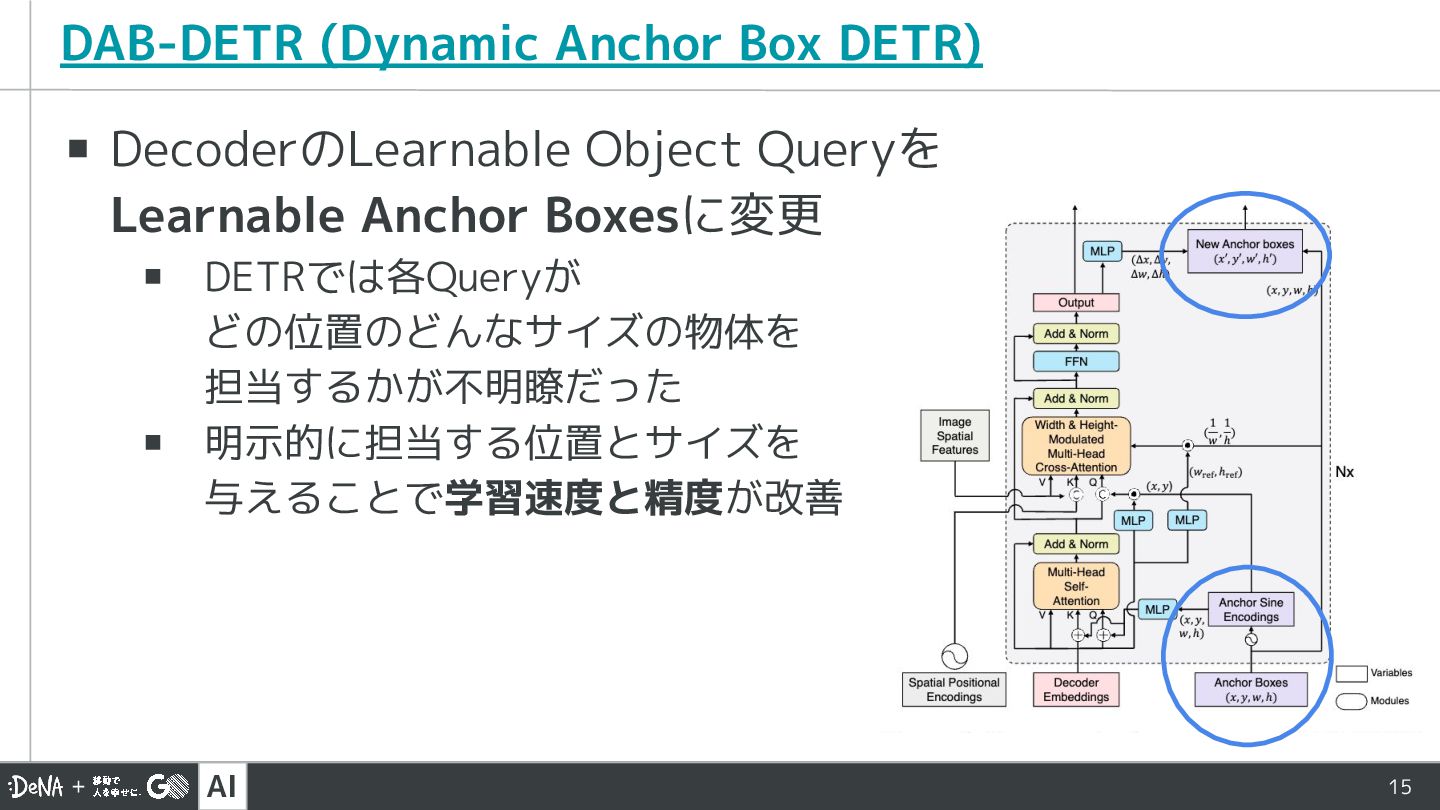
AI 15 DAB-DETR (Dynamic Anchor Box DETR) ▪ DecoderのLearnable Object
Queryを Learnable Anchor Boxesに変更 ▪ DETRでは各Queryが どの位置のどんなサイズの物体を 担当するかが不明瞭だった ▪ 明示的に担当する位置とサイズを 与えることで学習速度と精度が改善
AI 16 DAB-DETR (Dynamic Anchor Box DETR) ▪ Positional embeddingのみの
Attention mapの可視化 ▪ DETRではピークが複数ある ▪ 特定の物体を捉えづらい ▪ DAB-DETRでは物体のサイズ や形状に応じた適応的な Attentionが可能 ▪ DETRに比べて収束が速い
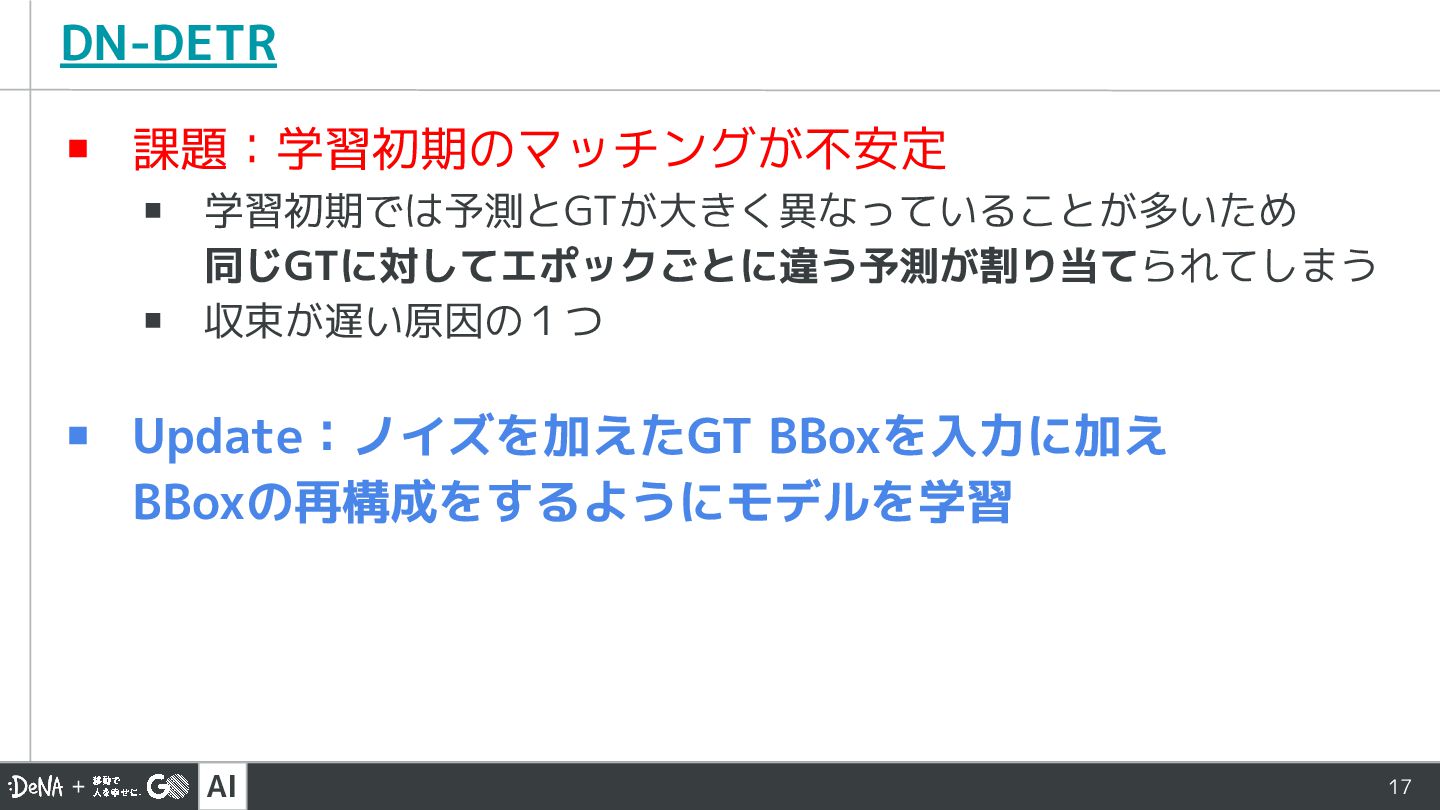
AI 17 DN-DETR ▪ 課題:学習初期のマッチングが不安定 ▪ 学習初期では予測とGTが大きく異なっていることが多いため 同じGTに対してエポックごとに違う予測が割り当てられてしまう ▪ 収束が遅い原因の1つ
▪ Update:ノイズを加えたGT BBoxを入力に加え BBoxの再構成をするようにモデルを学習
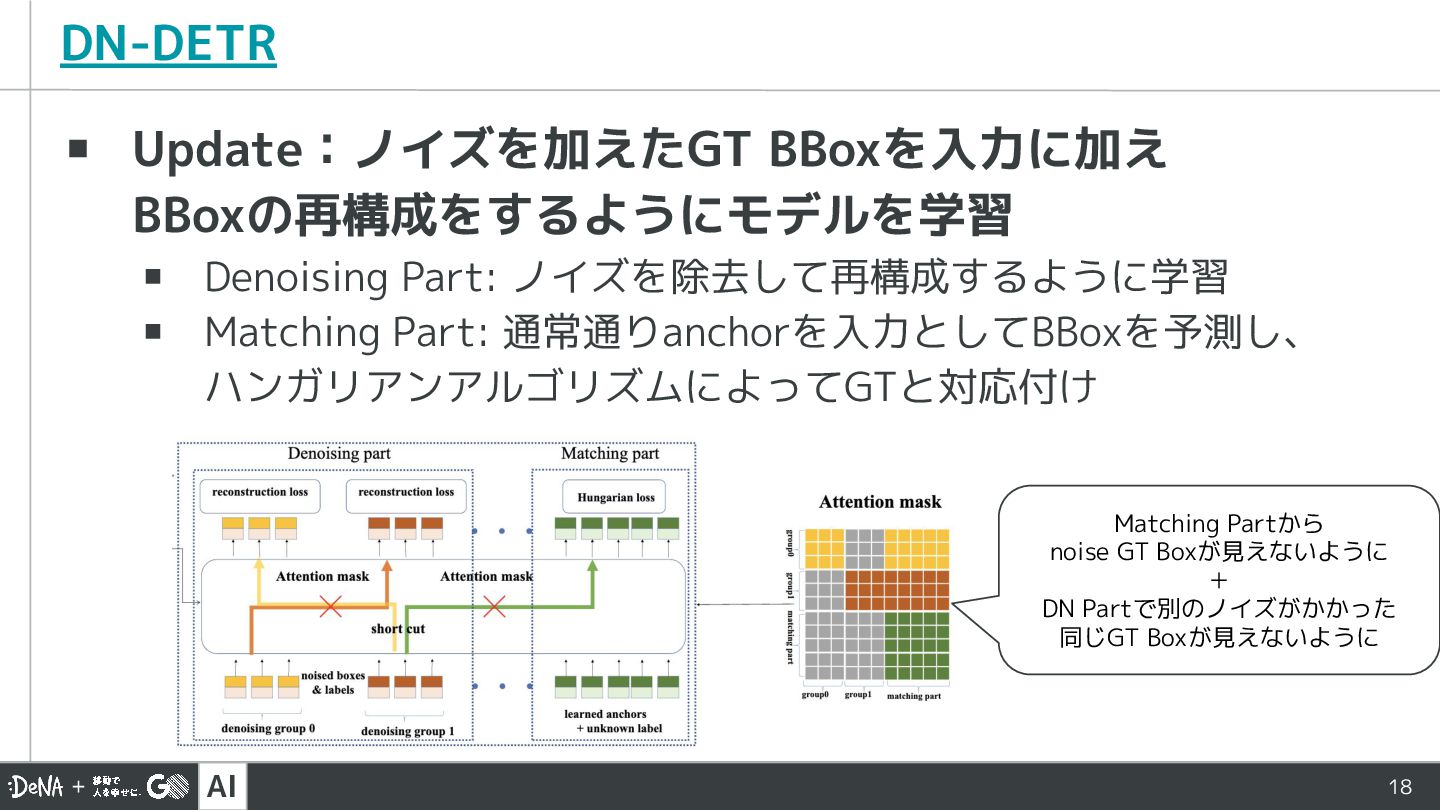
AI 18 DN-DETR ▪ Update:ノイズを加えたGT BBoxを入力に加え BBoxの再構成をするようにモデルを学習 ▪ Denoising Part:
ノイズを除去して再構成するように学習 ▪ Matching Part: 通常通りanchorを入力としてBBoxを予測し、 ハンガリアンアルゴリズムによってGTと対応付け Matching Partから noise GT Boxが見えないように + DN Partで別のノイズがかかった 同じGT Boxが見えないように
AI 19 DN-DETR ▪ Denoising Partが何故収束を早めるのか 1. Matching Partよりも簡単なサブタスクを学習させることで 学習初期の不安定さが解消される
2. Noise GT Box =「良いアンカー」とみなせる ▪ 「良いアンカー」からのオフセット学習が効率的に進む 3. Matching Partの各クエリが近くの領域に焦点を当てるように学 習が進む ▪ Noise GT BoxはGT Boxに近いため ▪ ベースモデルの半分ほどのエポックで より良い精度のモデルが学習できる
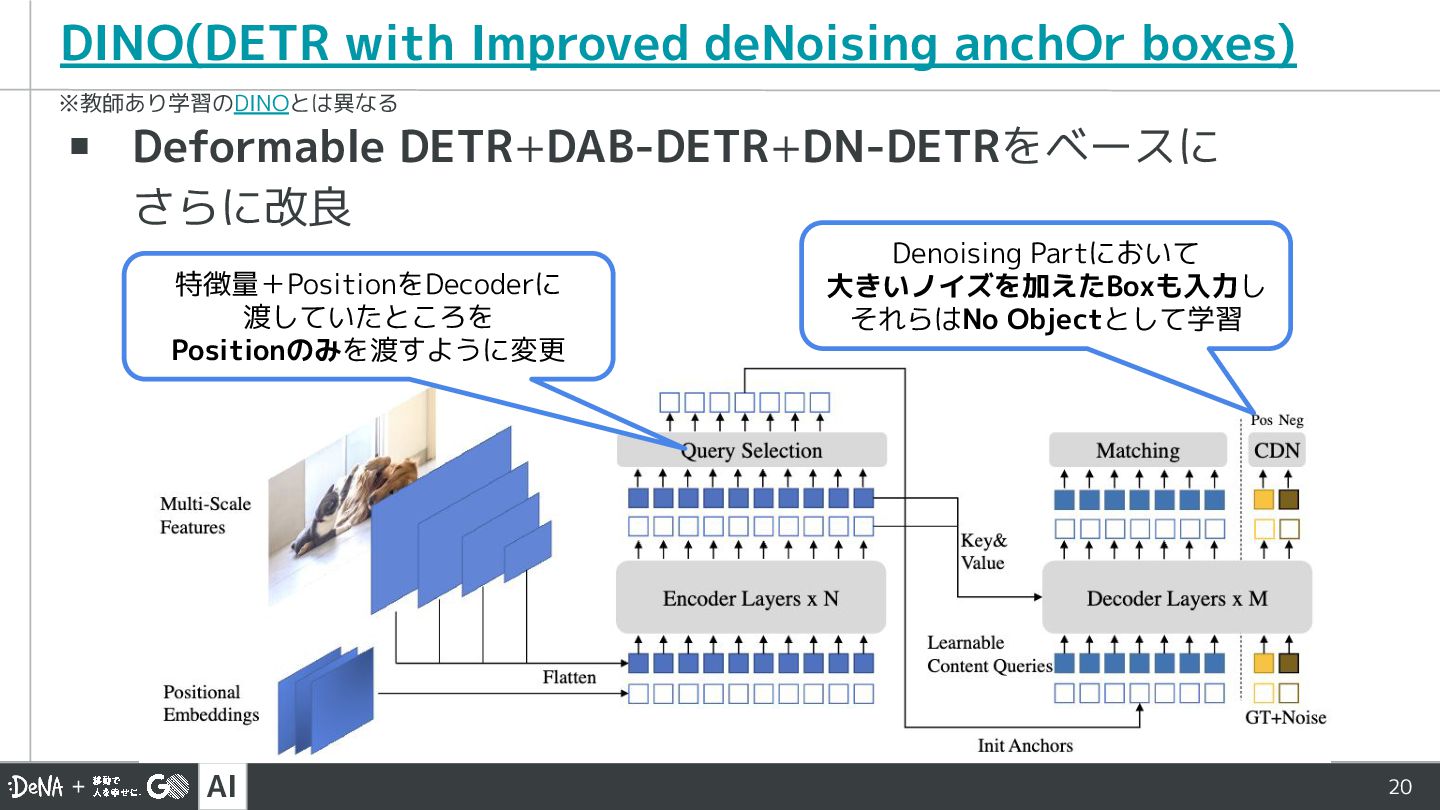
AI 20 DINO(DETR with Improved deNoising anchOr boxes) ▪ Deformable
DETR+DAB-DETR+DN-DETRをベースに さらに改良 ※教師あり学習のDINOとは異なる 特徴量+PositionをDecoderに 渡していたところを Positionのみを渡すように変更 Denoising Partにおいて 大きいノイズを加えたBoxも入力し それらはNo Objectとして学習
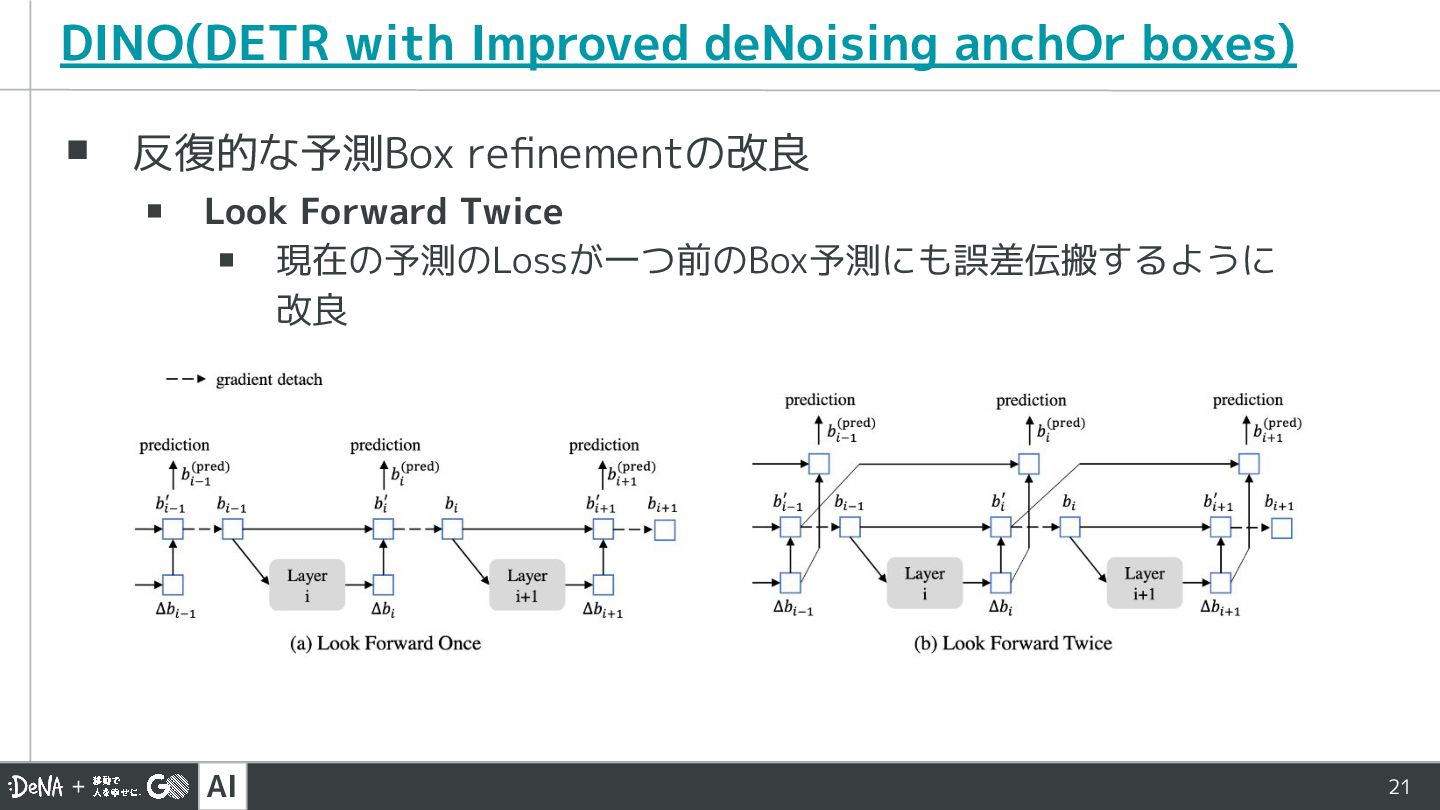
AI 21 DINO(DETR with Improved deNoising anchOr boxes) ▪ 反復的な予測Box
refinementの改良 ▪ Look Forward Twice ▪ 現在の予測のLossが一つ前のBox予測にも誤差伝搬するように 改良
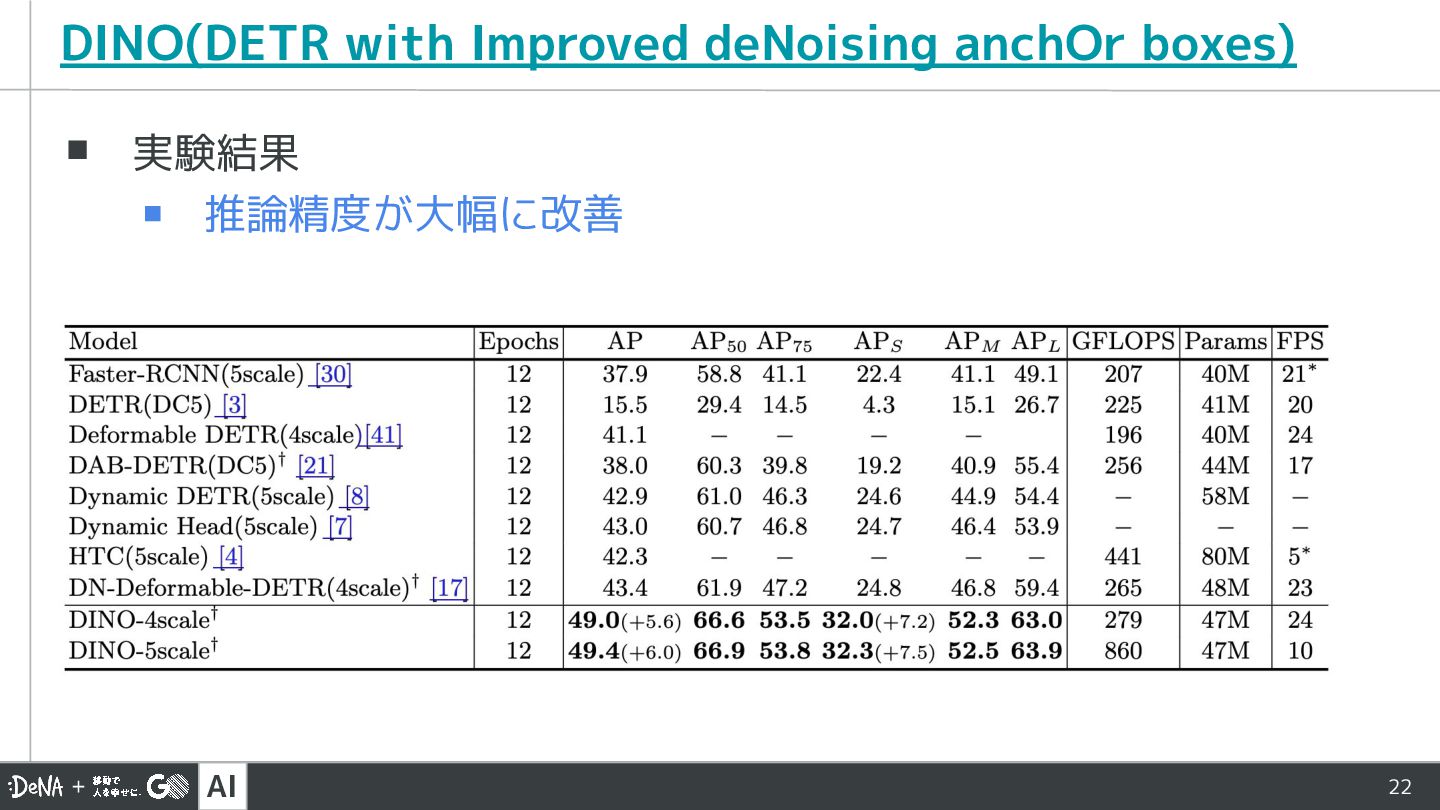
AI 22 DINO(DETR with Improved deNoising anchOr boxes) ▪ 実験結果
▪ 推論精度が大幅に改善
AI 23 03 Real-time DETR
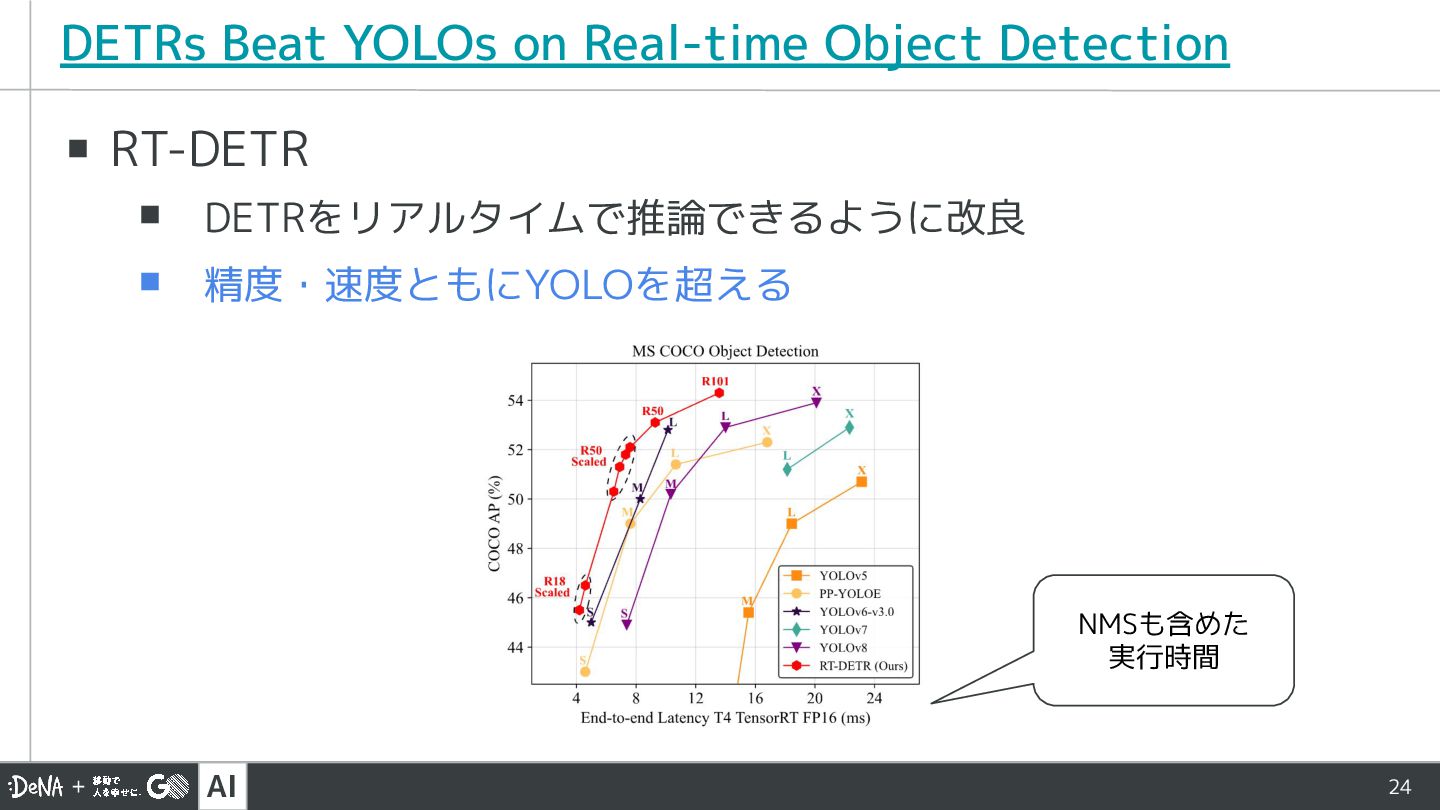
AI 24 ▪ RT-DETR ▪ DETRをリアルタイムで推論できるように改良 ▪ 精度・速度ともにYOLOを超える DETRs Beat
YOLOs on Real-time Object Detection NMSも含めた 実行時間
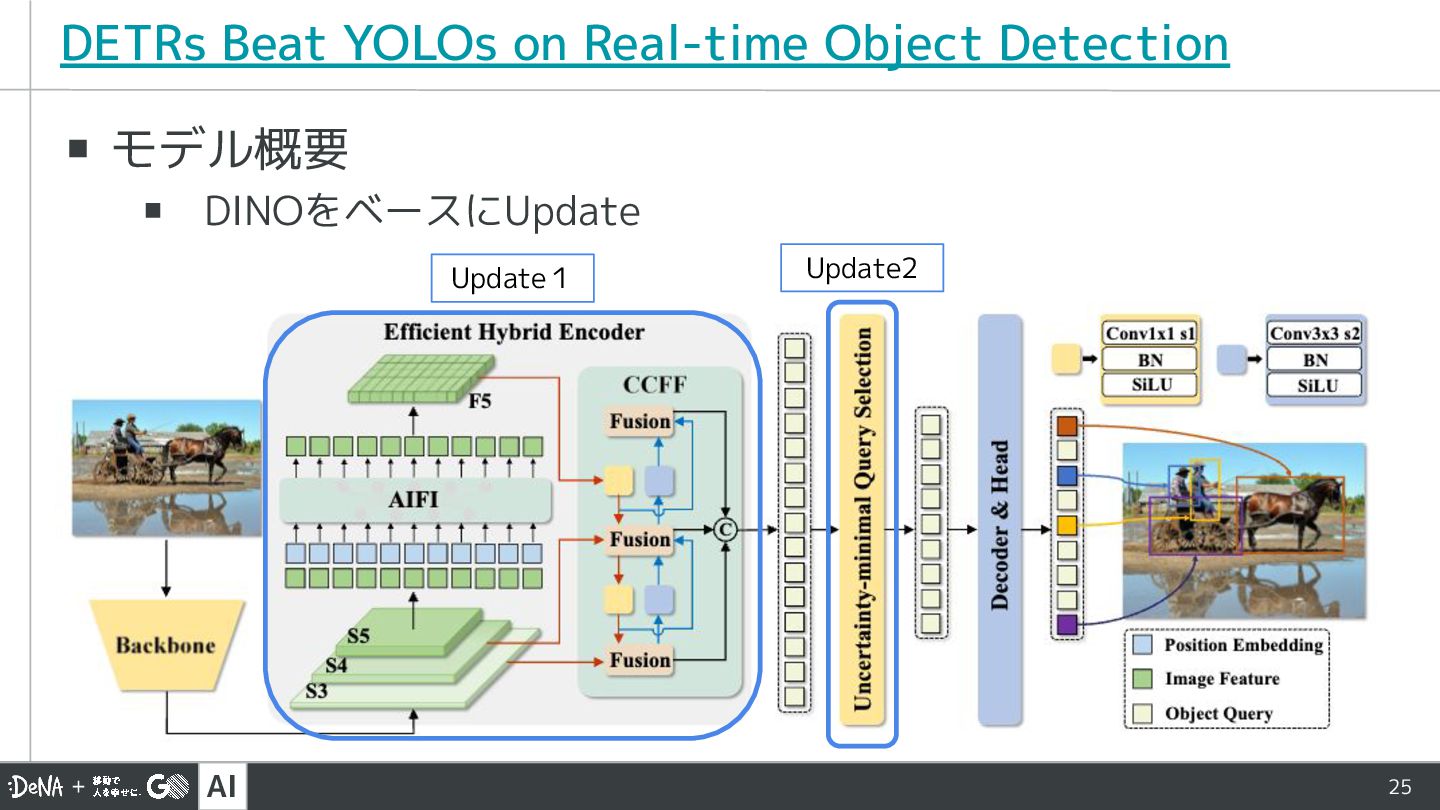
AI 25 ▪ モデル概要 ▪ DINOをベースにUpdate DETRs Beat YOLOs on
Real-time Object Detection Update1 Update2
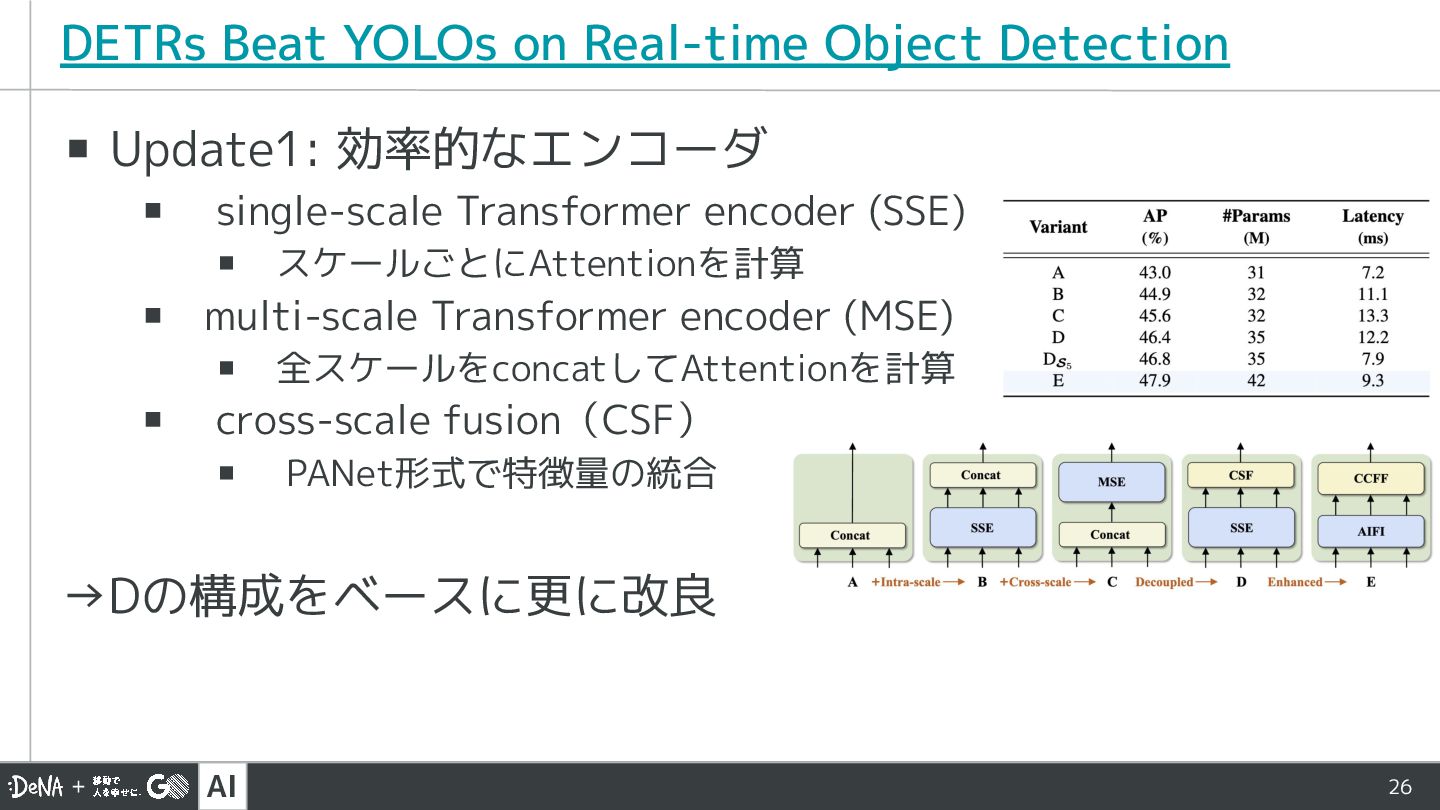
AI 26 ▪ Update1: 効率的なエンコーダ ▪ single-scale Transformer encoder (SSE)
▪ スケールごとにAttentionを計算 ▪ multi-scale Transformer encoder (MSE) ▪ 全スケールをconcatしてAttentionを計算 ▪ cross-scale fusion(CSF) ▪ PANet形式で特徴量の統合 →Dの構成をベースに更に改良 DETRs Beat YOLOs on Real-time Object Detection
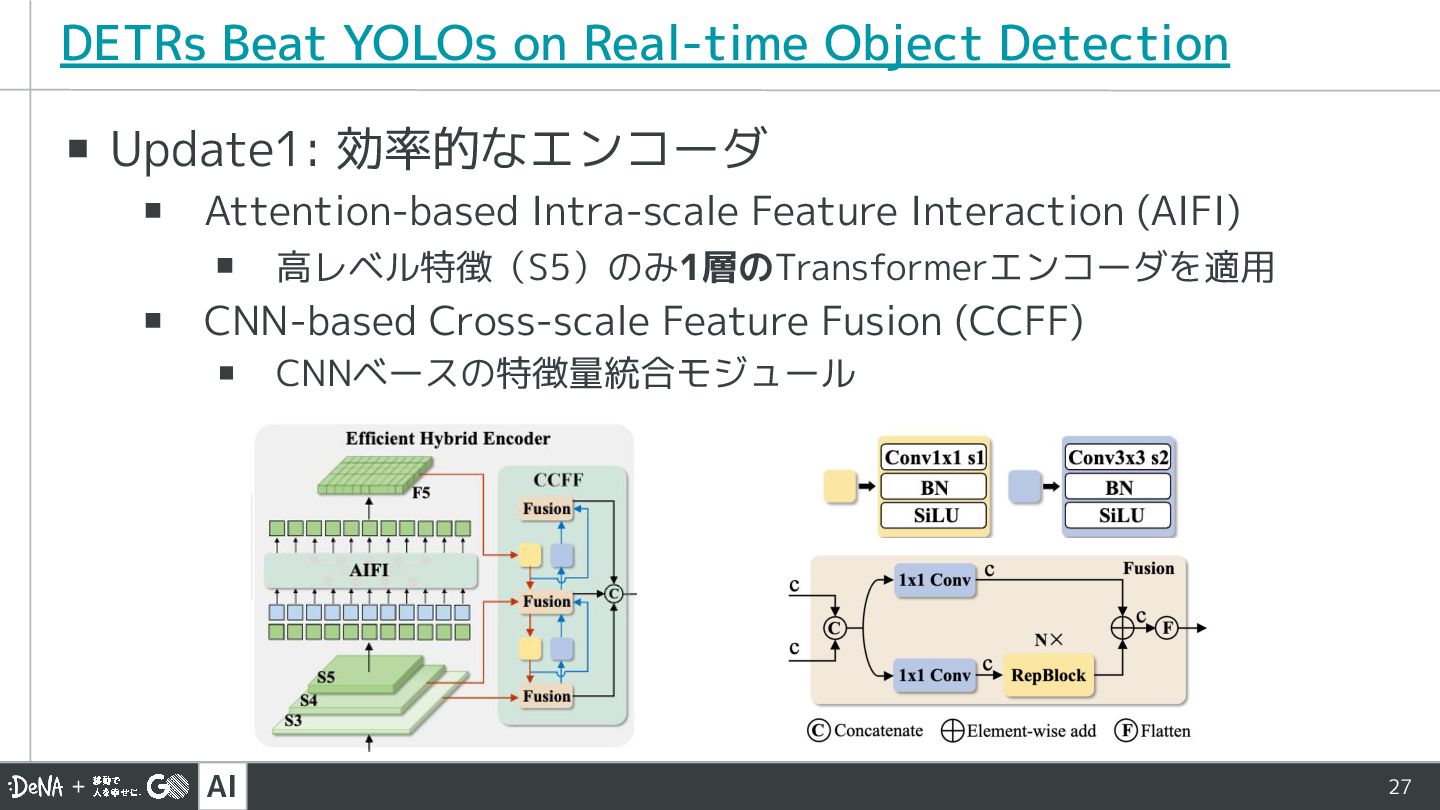
AI 27 ▪ Update1: 効率的なエンコーダ ▪ Attention-based Intra-scale Feature Interaction
(AIFI) ▪ 高レベル特徴(S5)のみ1層のTransformerエンコーダを適用 ▪ CNN-based Cross-scale Feature Fusion (CCFF) ▪ CNNベースの特徴量統合モジュール DETRs Beat YOLOs on Real-time Object Detection
AI 28 ▪ Update2: オブジェクトクエリ選択方法 ▪ 今までは前景かどうかのconfidenceスコア上位をDecoderの 入力クエリとして使用 ▪ 前景かどうかのスコアだけで判断するのは不十分では?
▪ クラスと位置どちらも考慮して選ぶべき! ▪ 分類スコアとBBoxスコアの差分を不確実性として 不確実性が小さいクエリを選択するように改良 ▪ (実装上はVariFocal Loss(VFL)をクラス分類に用いることで実現) ▪ VFLについてはp40を参照 ▪ APが0.8ポイント改善 DETRs Beat YOLOs on Real-time Object Detection
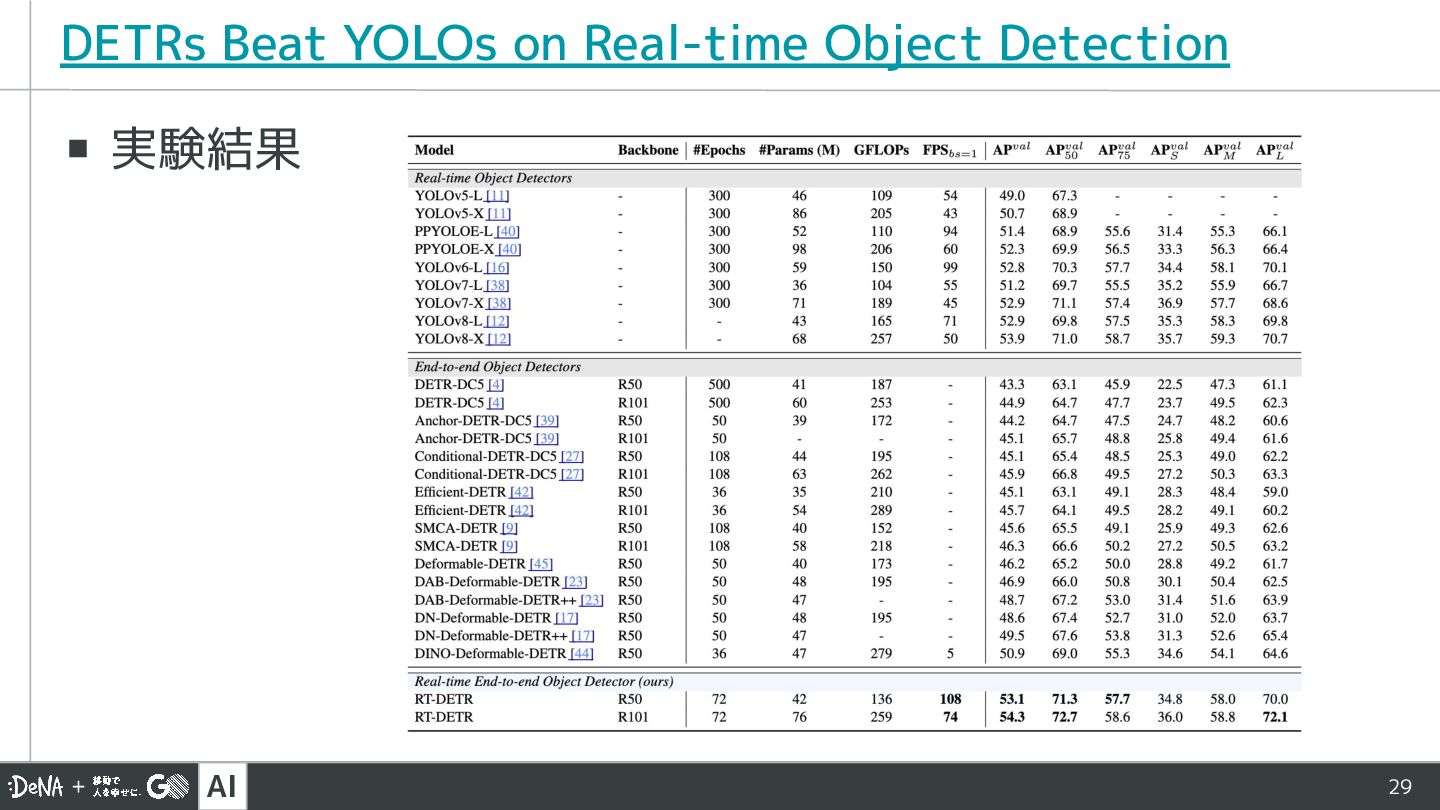
AI 29 ▪ 実験結果 DETRs Beat YOLOs on Real-time Object
Detection
AI 30 04 最新手法 (CVPR2025)
AI 31 Mr. DETR: Instructive Multi-Route Training for Detection Transformers
▪ one-to-one assignment (o2o) ▪ 1つのGTに対して1つの予測を割り当て(通常のDETRの学習) ▪ メリット:後処理が必要なく、end-to-endに推論可能 ▪ デメリット:初期の学習が進みづらい ▪ one-to-many assignment (o2m) ▪ 1つのGTに対して複数の予測を割り当て(YOLOの学習方法) ▪ メリット:GTに対応付ける予測が多いので学習が進みやすい ▪ デメリット:NMS等の後処理が必要
AI 32 Mr. DETR: Instructive Multi-Route Training for Detection Transformers
▪ one-to-manyをマルチタスクで解かせる ▪ 初期の学習が進みやすくなる ▪ 推論時はo2oのみ使用するため end-to-end予測はこれまで通り可能 ▪ DAC-Detr, H-DETR, Ms-detr などいくつかの手法で提案されている →マルチタスク学習の際のDecoderの構造を再考したMr.DETR
AI 33 Mr. DETR: Instructive Multi-Route Training for Detection Transformers
▪ マルチタスク学習のネットワークアーキテクチャの比較 ▪ すべての要素を共有してマルチタスク学習すると精度が低下する ▪ o2mは正の予測として割り当てられるのに、o2oでは負の予測として 割り当てられる場合にそれぞれの学習が干渉し合うため ▪ SAを分離したルート+FFNを分離したルートの構成が 最も精度が良い
AI 34 Mr. DETR: Instructive Multi-Route Training for Detection Transformers
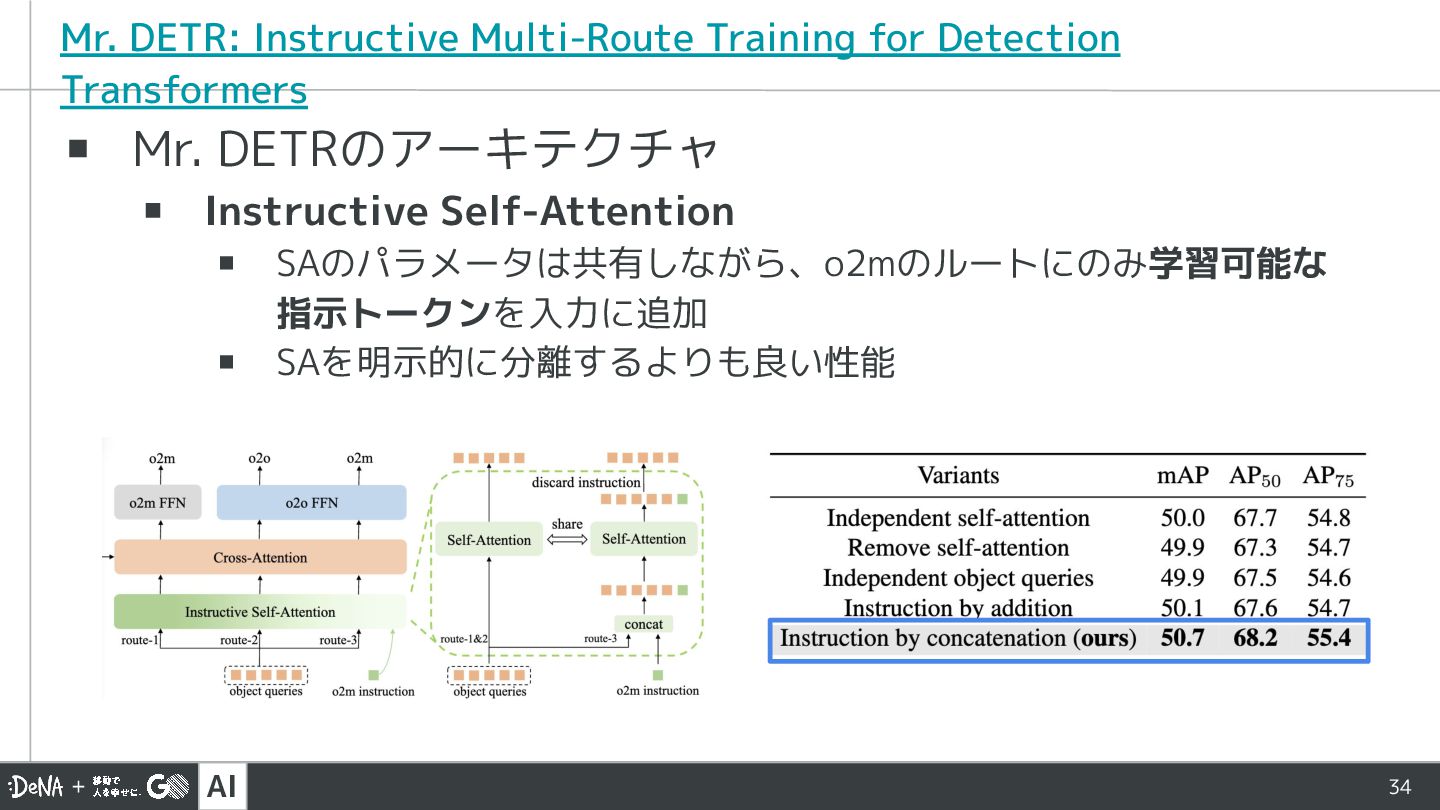
▪ Mr. DETRのアーキテクチャ ▪ Instructive Self-Attention ▪ SAのパラメータは共有しながら、o2mのルートにのみ学習可能な 指示トークンを入力に追加 ▪ SAを明示的に分離するよりも良い性能
AI 35 Mr. DETR: Instructive Multi-Route Training for Detection Transformers
▪ 実験結果 ▪ ベースのo2oモデルは変更する必要がないため 様々なモデルに適用可能 ▪ 様々なベースモデルで性能改善 様々なベースラインモデルで性能改善 ルートに関するablation study マルチタスク学習のインパクトは大きいが 3ルートにするインパクトは小さめ
AI 36 Mr. DETR: Instructive Multi-Route Training for Detection Transformers
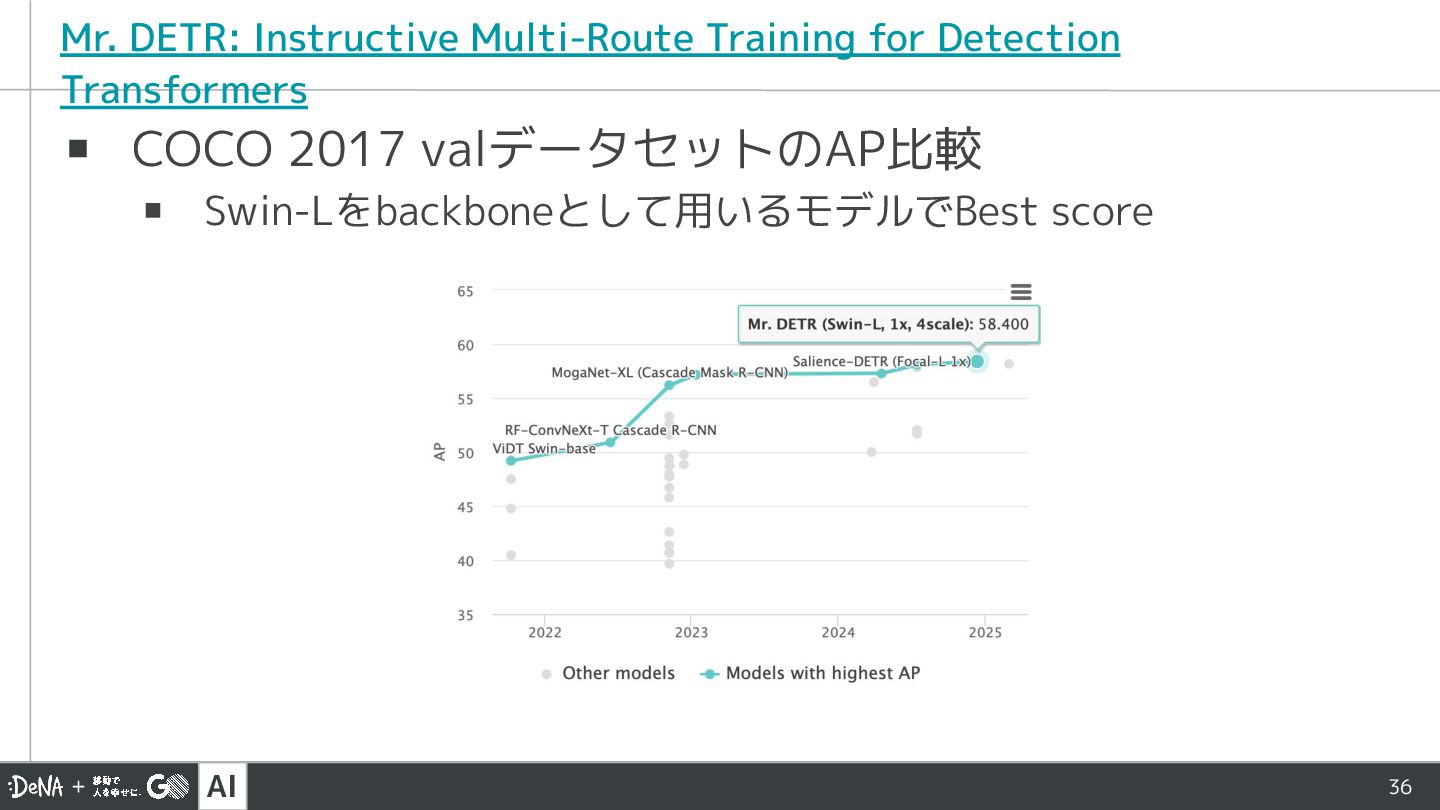
▪ COCO 2017 valデータセットのAP比較 ▪ Swin-Lをbackboneとして用いるモデルでBest score
AI 37 DEIM: DETR with Improved Matching for Fast Convergence
▪ o2mマルチタスク学習の問題点 ▪ 追加のデコーダが必要で計算量が増加 ▪ o2mの学習により、冗長なBoxを生成してしまう可能性 ▪ DEIMでの改良 ▪ Dense o2o matching ▪ VariFocal Loss(VFL)に代わるMatchability-Aware Loss(MAL)
AI 38 DEIM: DETR with Improved Matching for Fast Convergence
▪ Dense o2o matching ▪ 正の予測を増やしたい ▪ 画像内にGTが多く映るようなデータ拡張を適用(シンプル!) ▪ mosaic, mixup ▪ 下図(c)のようにデータ拡張すれば正の予測が4倍になる 黄:GT 赤:positive predictions 緑:negative predictions
AI 39 DEIM: DETR with Improved Matching for Fast Convergence
▪ Dense o2o matching ▪ デコーダーの計算量を増やさずに、学習時間を短縮 ▪ 半分のepochで同等の性能を達成
AI 40 DEIM: DETR with Improved Matching for Fast Convergence
▪ VariFocal Loss(VFL) ▪ 負例(予測BoxとGT BoxのIoUが0)の場合 ▪ Focal Lossと同様 ▪ 正例(予測BoxとGT BoxのIoUが0以上)の場合 ▪ BCE Lossを計算する際に、IoUで重み付け →IoUが高いサンプルを重視して学習
AI 41 DEIM: DETR with Improved Matching for Fast Convergence
▪ VariFocal Loss(VFL) ▪ VFLの欠点 ▪ 下図のような高分類スコア・低IoUの予測BoxはLossが小さいため 改善されづらい ▪ IoU=0のBoxは負の予測扱いなので、正の予測が少なくなり 学習が進みづらい
AI 42 DEIM: DETR with Improved Matching for Fast Convergence
▪ Matchability-Aware Loss(MAL) ▪ 変更点 ▪ 正負のバランスを取るためのハイパラαを削除 ▪ 正例のターゲットラベルをq^γに変更 ▪ IoUが低い場合でもLossが大きくなることで、正例に対する勾配が 強くなり、学習が効果的に進む
AI 43 DEIM: DETR with Improved Matching for Fast Convergence
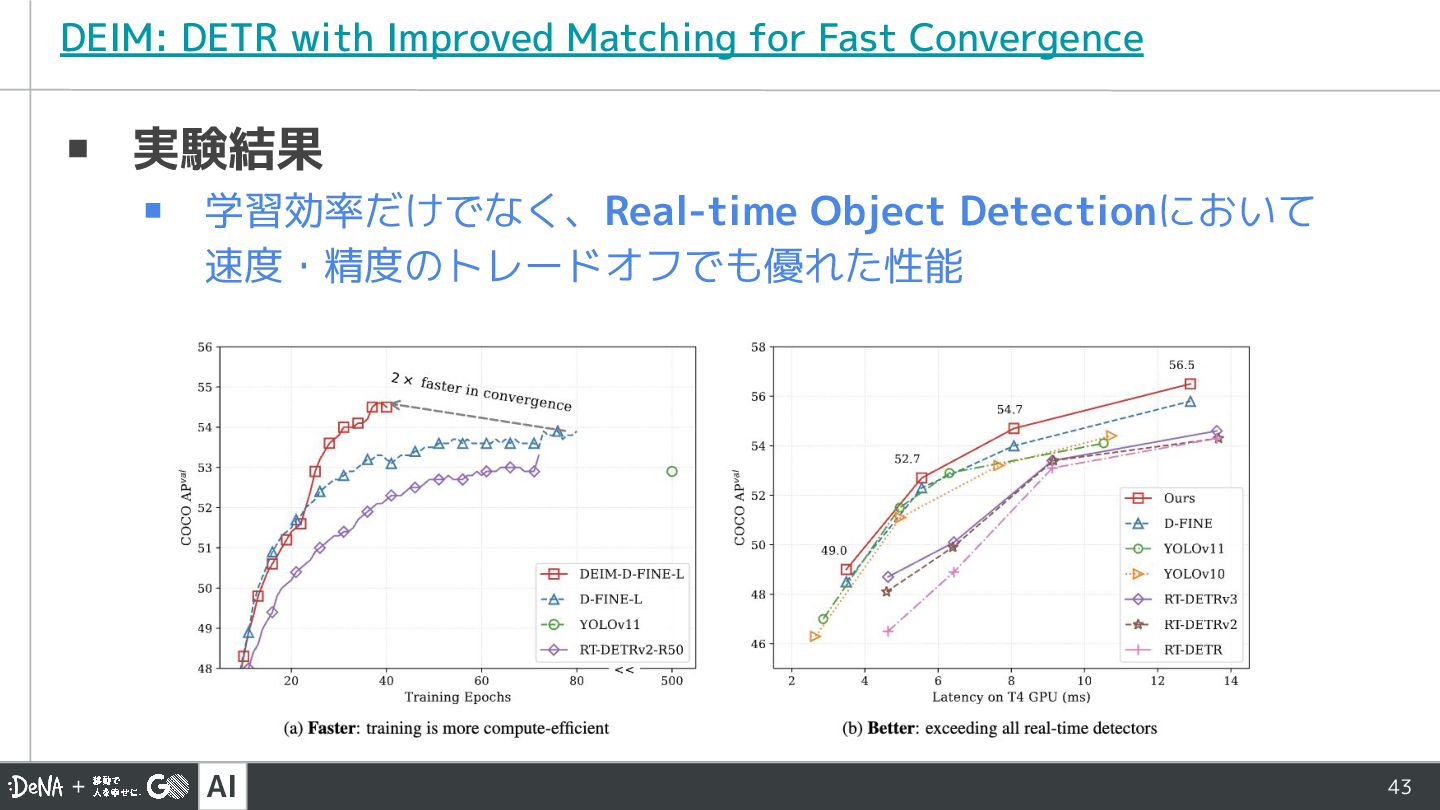
▪ 実験結果 ▪ 学習効率だけでなく、Real-time Object Detectionにおいて 速度・精度のトレードオフでも優れた性能
AI 44 DEIM: DETR with Improved Matching for Fast Convergence
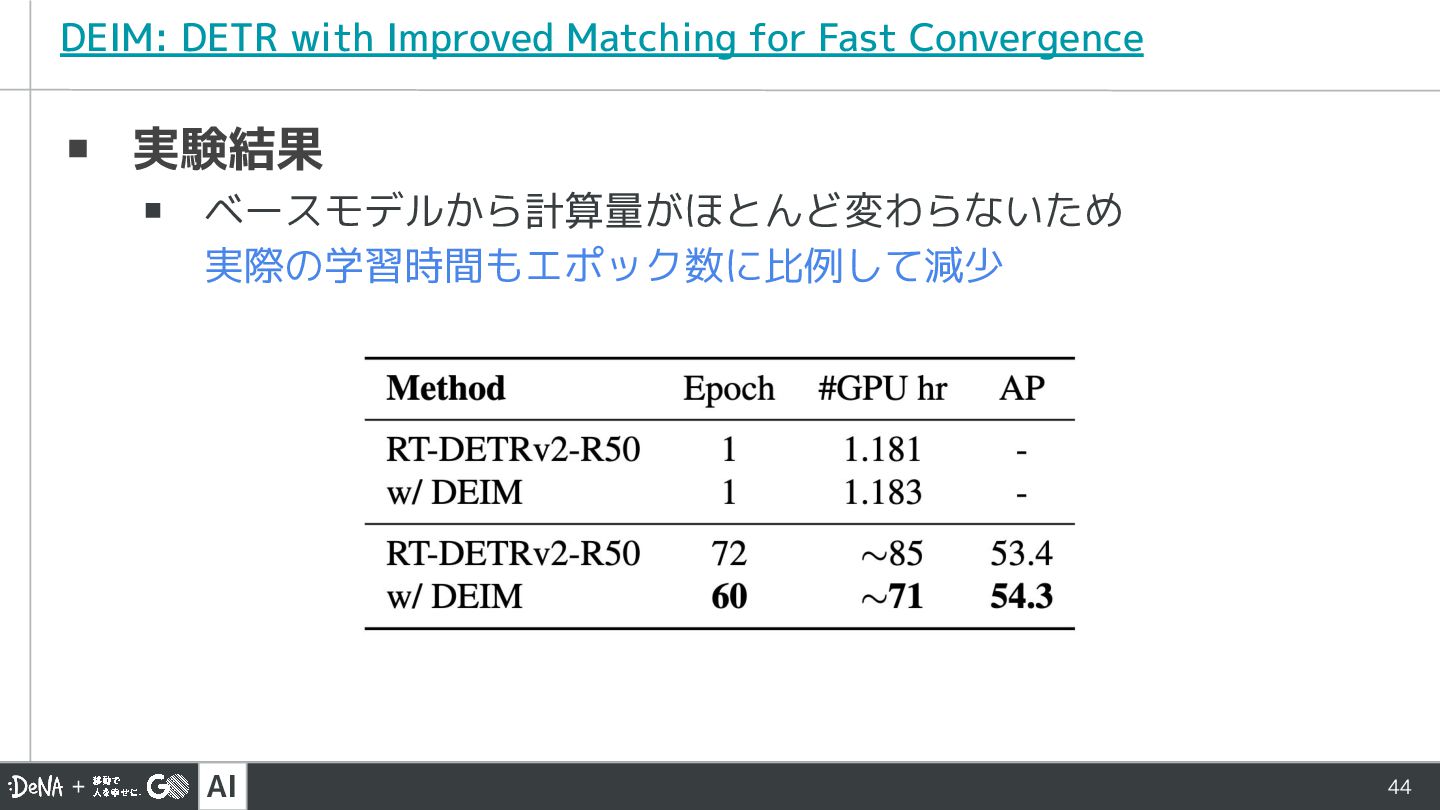
▪ 実験結果 ▪ ベースモデルから計算量がほとんど変わらないため 実際の学習時間もエポック数に比例して減少
AI 45 ▪ DETRの発展 ▪ NMS不要なEnd-to-end物体検出モデルとして発展 ▪ アーキテクチャ・学習設定を改良して、収束速度・精度・ 推論速度を向上 ▪
リアルタイムでの推論も可能に ▪ 最新手法(CVPR2025) ▪ 主な課題点としてはo2o matchingにおける非効率な学習 ▪ Mr. DETR→o2mマルチタスク学習のアーキテクチャを改善 ▪ DEIM→シンプルなデータ拡張+Lossの修正でo2oの問題に対処 まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}