0/209 100/204 36/123 16/94 9/29 16/81 9/112 6/109 0/3 48/359 26/337 19/110 18/109 0/1 7/227 0/22 spam spam spam spam spam spam spam spam spam email email email email email email email email email email email email email email ch$<0.0555 remove<0.06 ch!<0.191 george<0.005 hp<0.03 CAPMAX<10.5 CAPAVE<2.7505 free<0.065 business<0.145 george<0.15 hp<0.405 CAPAVE<2.907 1999<0.58 ch$>0.0555 remove>0.06 ch!>0.191 george>0.005 hp>0.03 CAPMAX>10.5 CAPAVE>2.7505 free>0.065 business>0.145 george>0.15 hp>0.405 CAPAVE>2.907 1999>0.58 画像出典: T. Hastie et al. (2009): “The Elements of Statistical Learning”, Springer.
![決定木からはじめる機械学習 ⼭本 祐輔 名古屋市⽴⼤学 データサイエンス研究科 [email protected] 第3回 機械学習発展 (導入編)](https://files.speakerdeck.com/presentations/5e94d8d0e65b47589f075f85a271ff9e/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
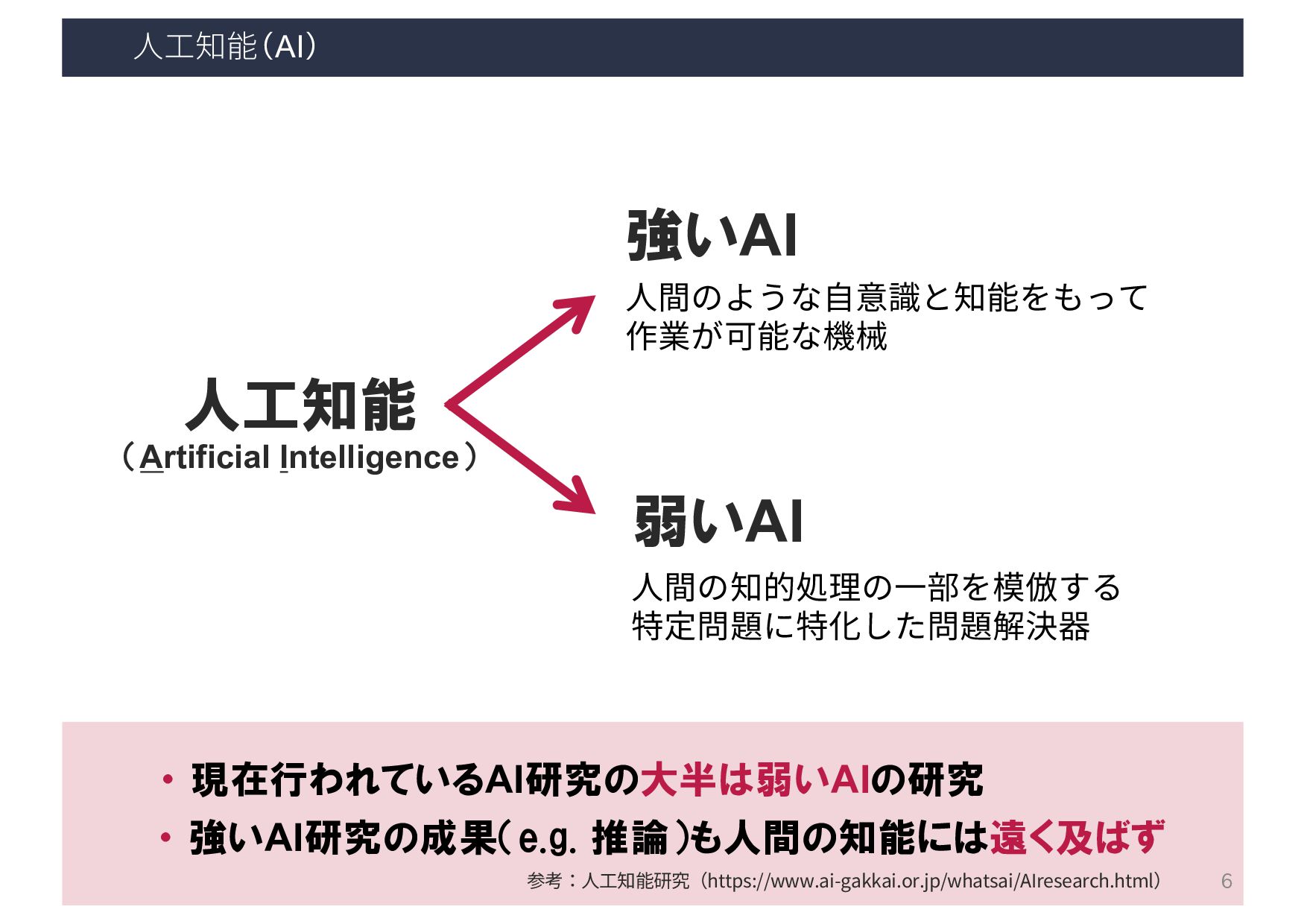{kind=link}
{kind=link}
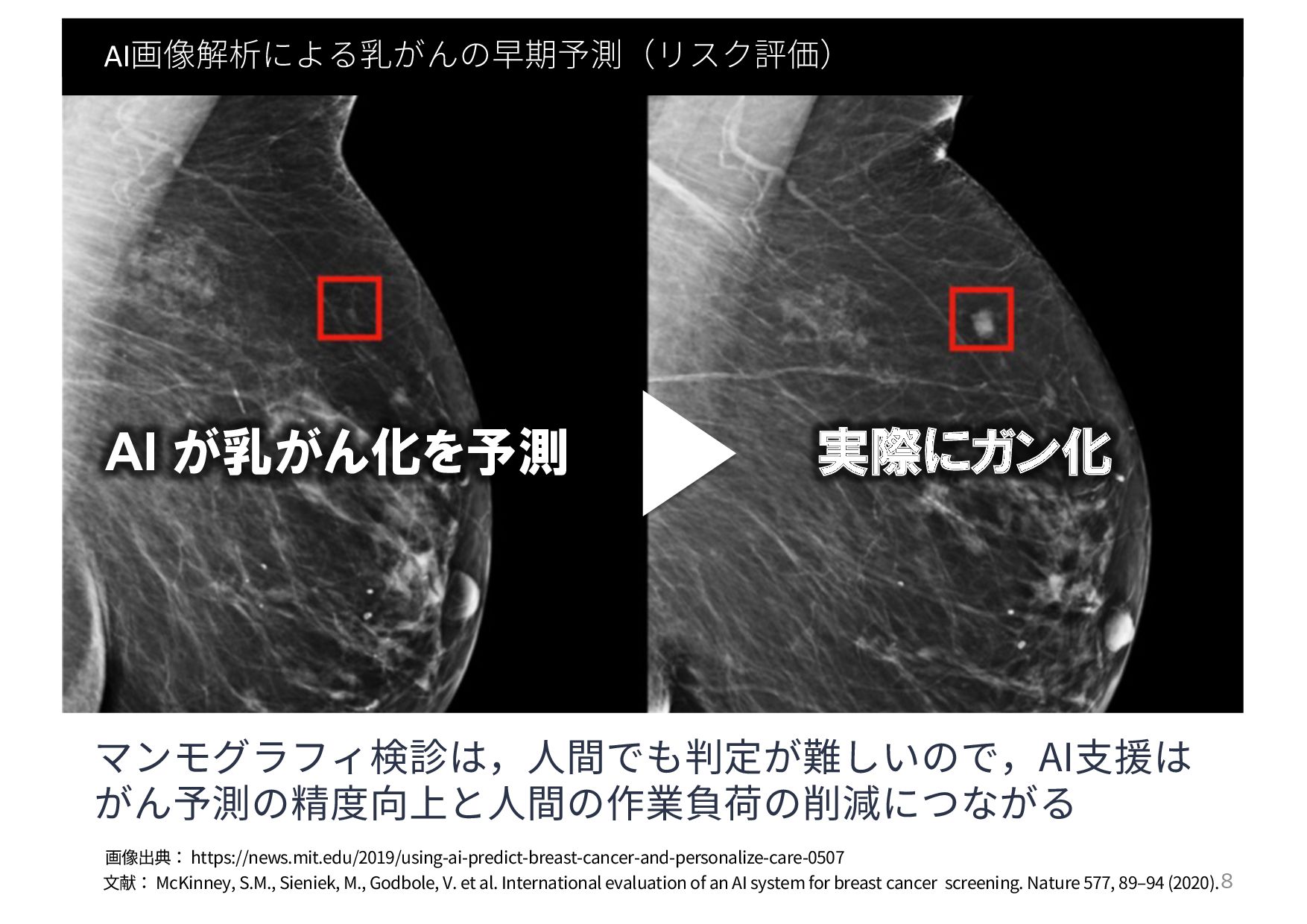{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
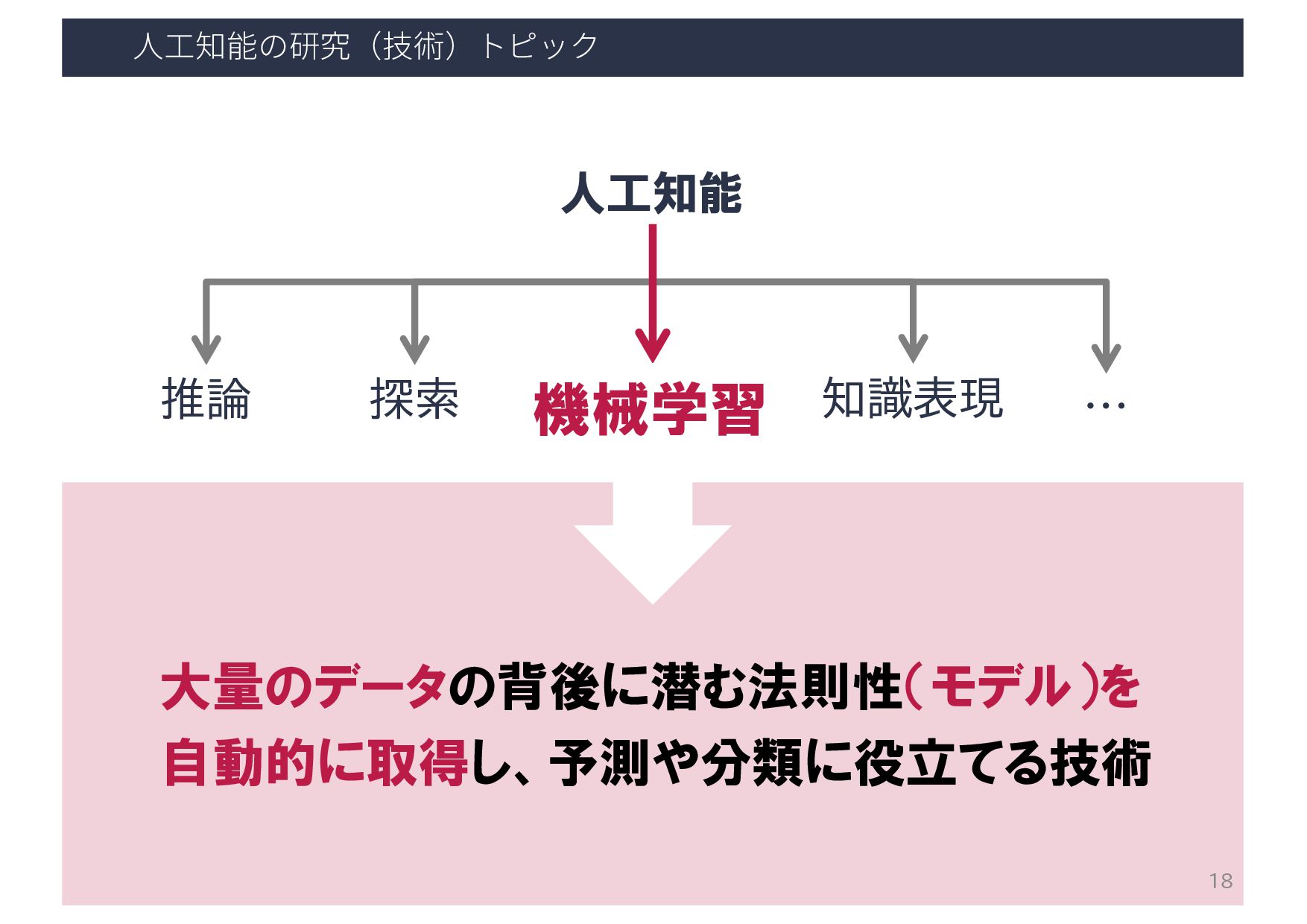{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
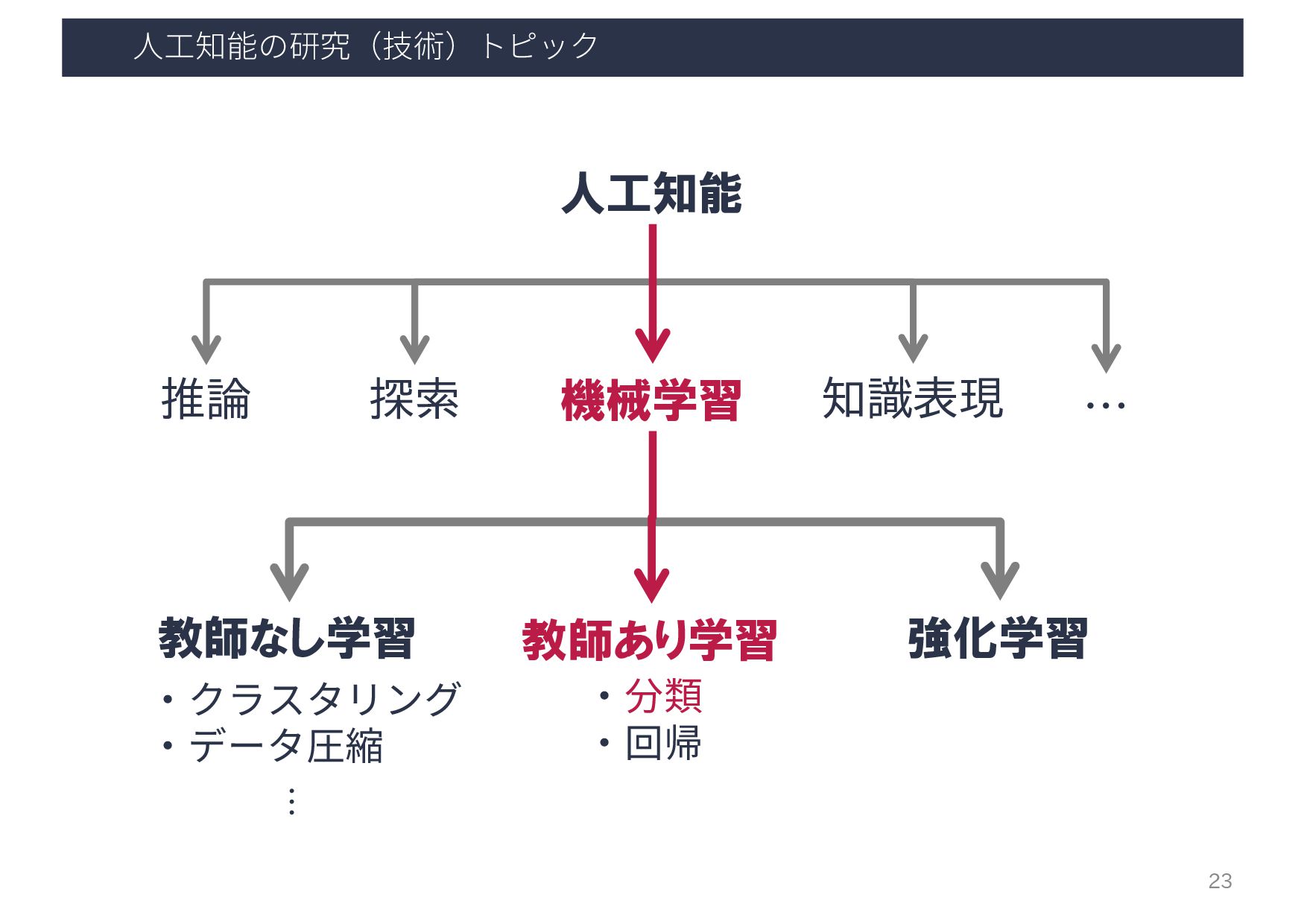{kind=link}
{kind=link}
{kind=link}
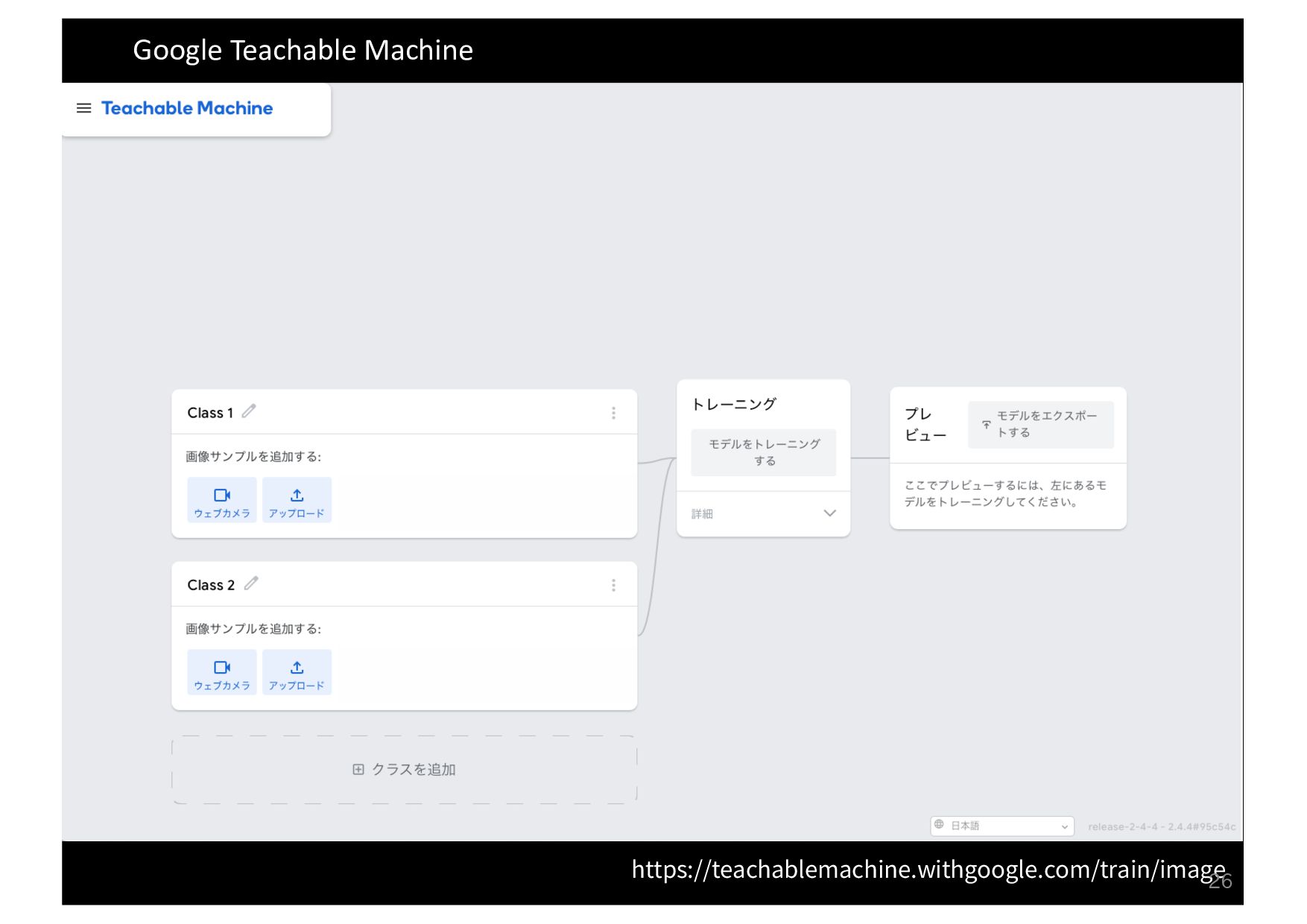{kind=link}
{kind=link}
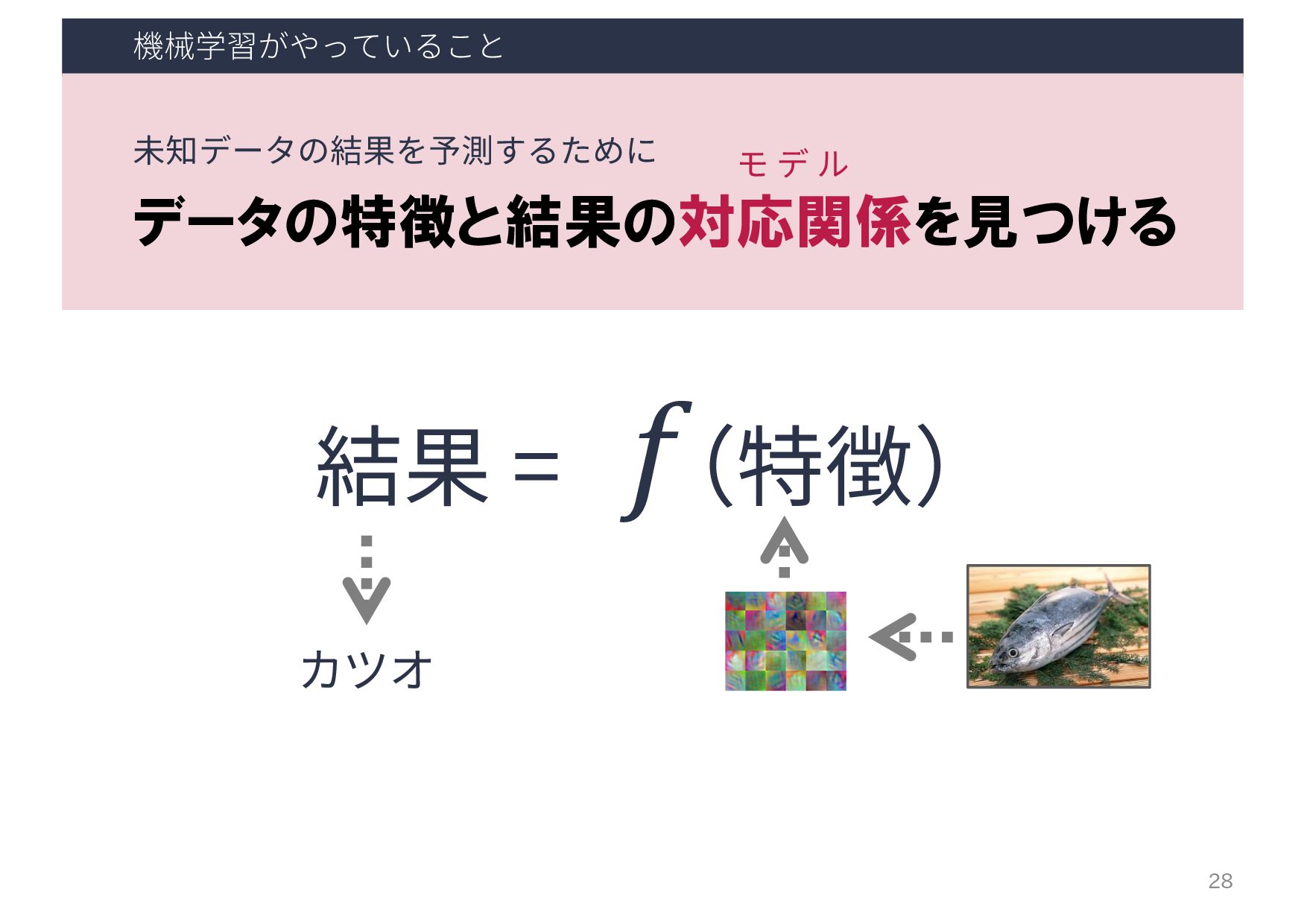{kind=link}
{kind=link}
{kind=link}