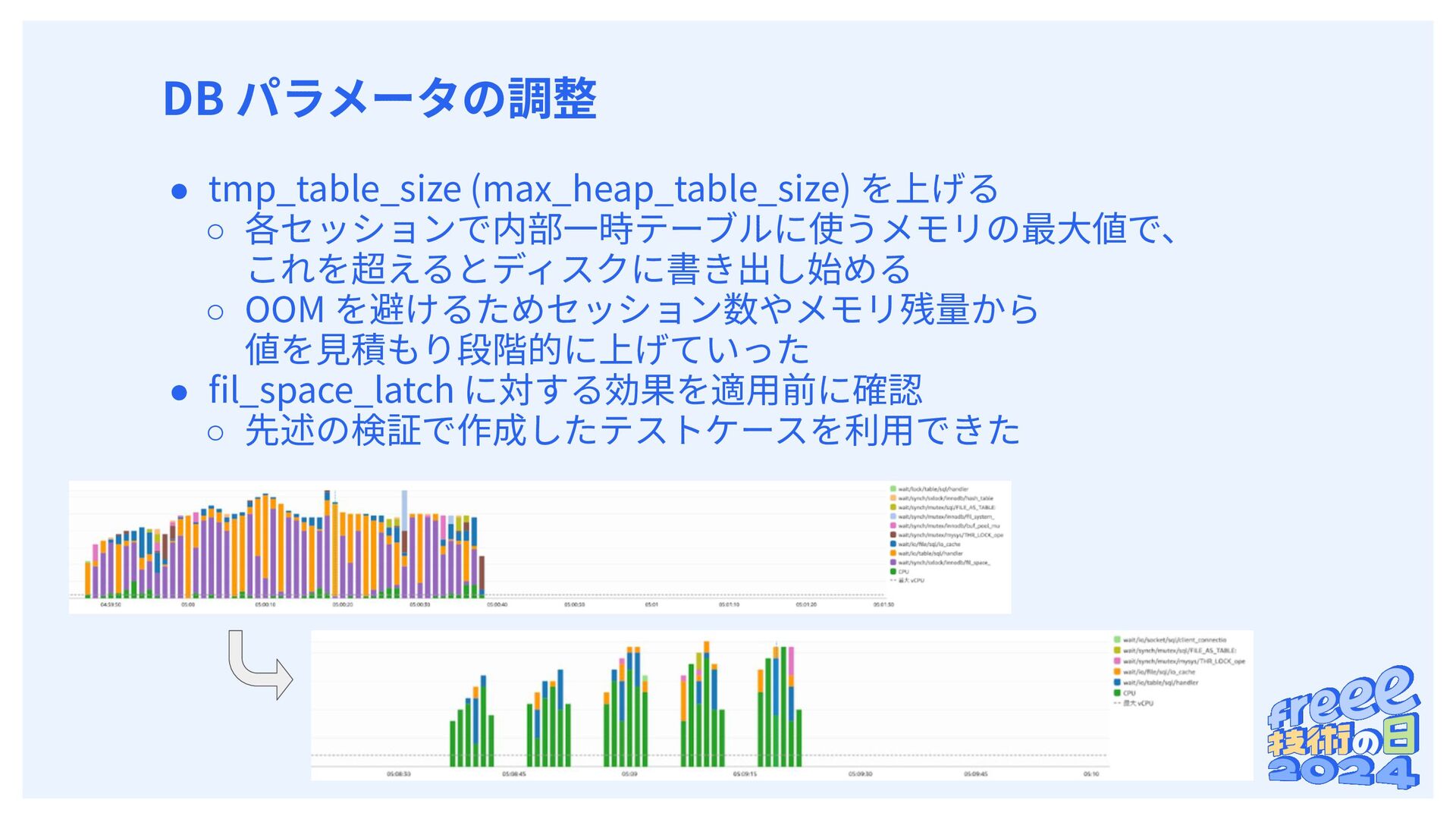
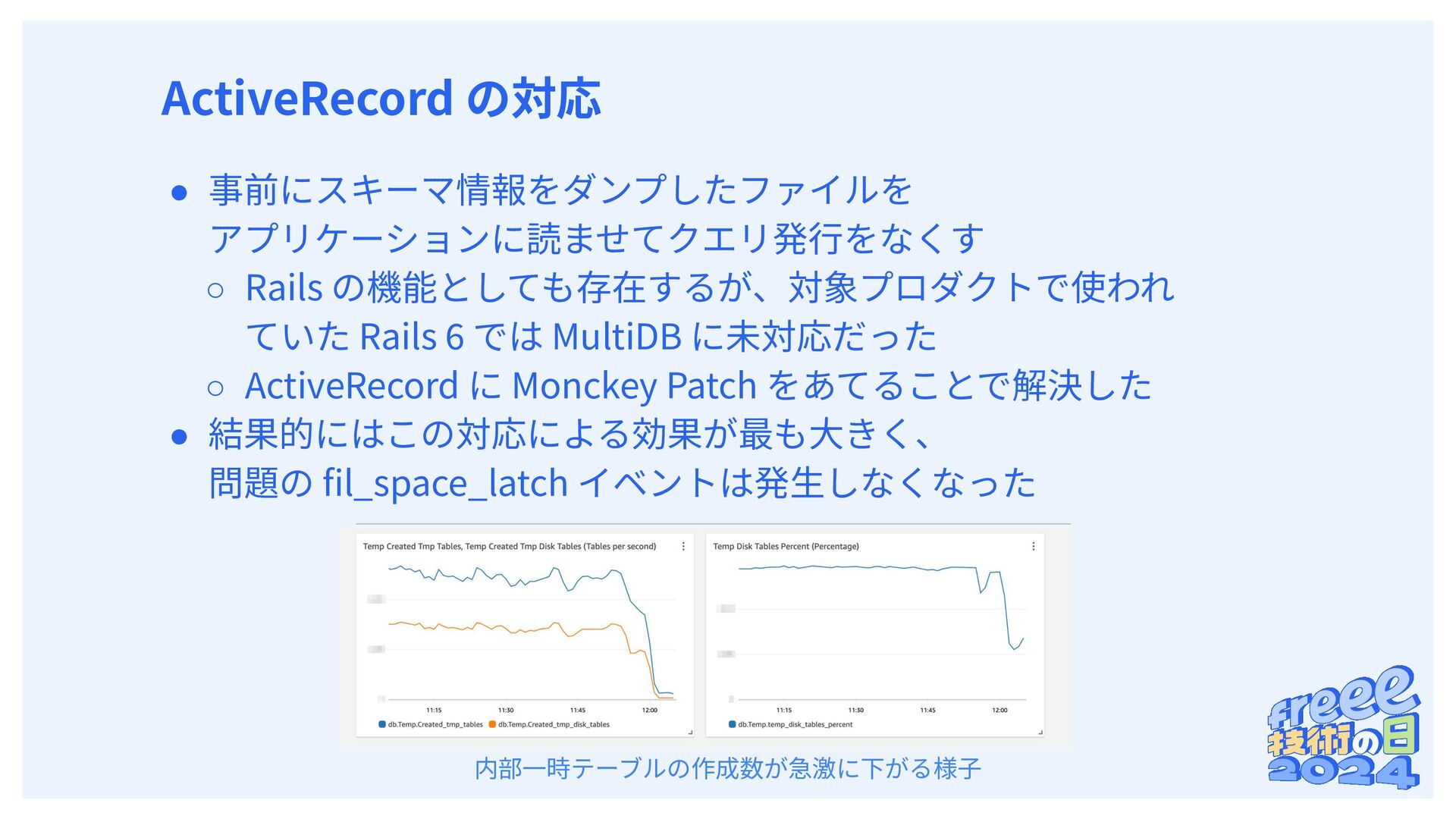
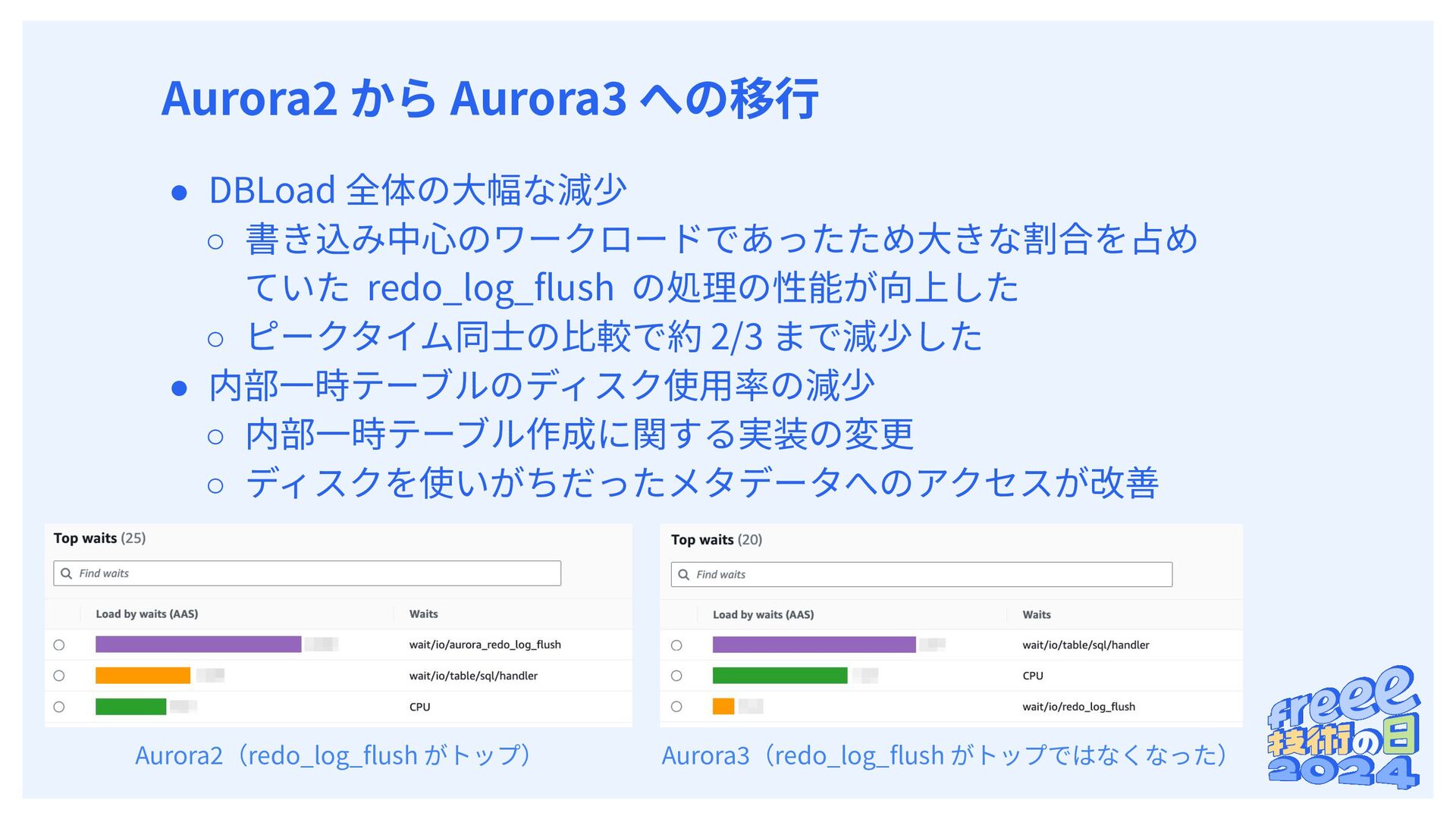
内部⼀時テーブル作成でディスク使⽤時にアクセスされる • スペースへのアクセス時にラッチが獲得される ◦ 獲得待ちで記録されるイベントが fil_space_latch 内部⼀時テーブル作成時の動作 Thread (Session) Thread (Session) shared temporary tablespace ‧‧‧ SELECT * FROM t1 JOIN t2 ON t1.id = t2.t1_id ... ORDER BY t2.id SELECT * FROM t3 JOIN t4 ON t3.id = t4.t1_id ... ORDER BY t4.id
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
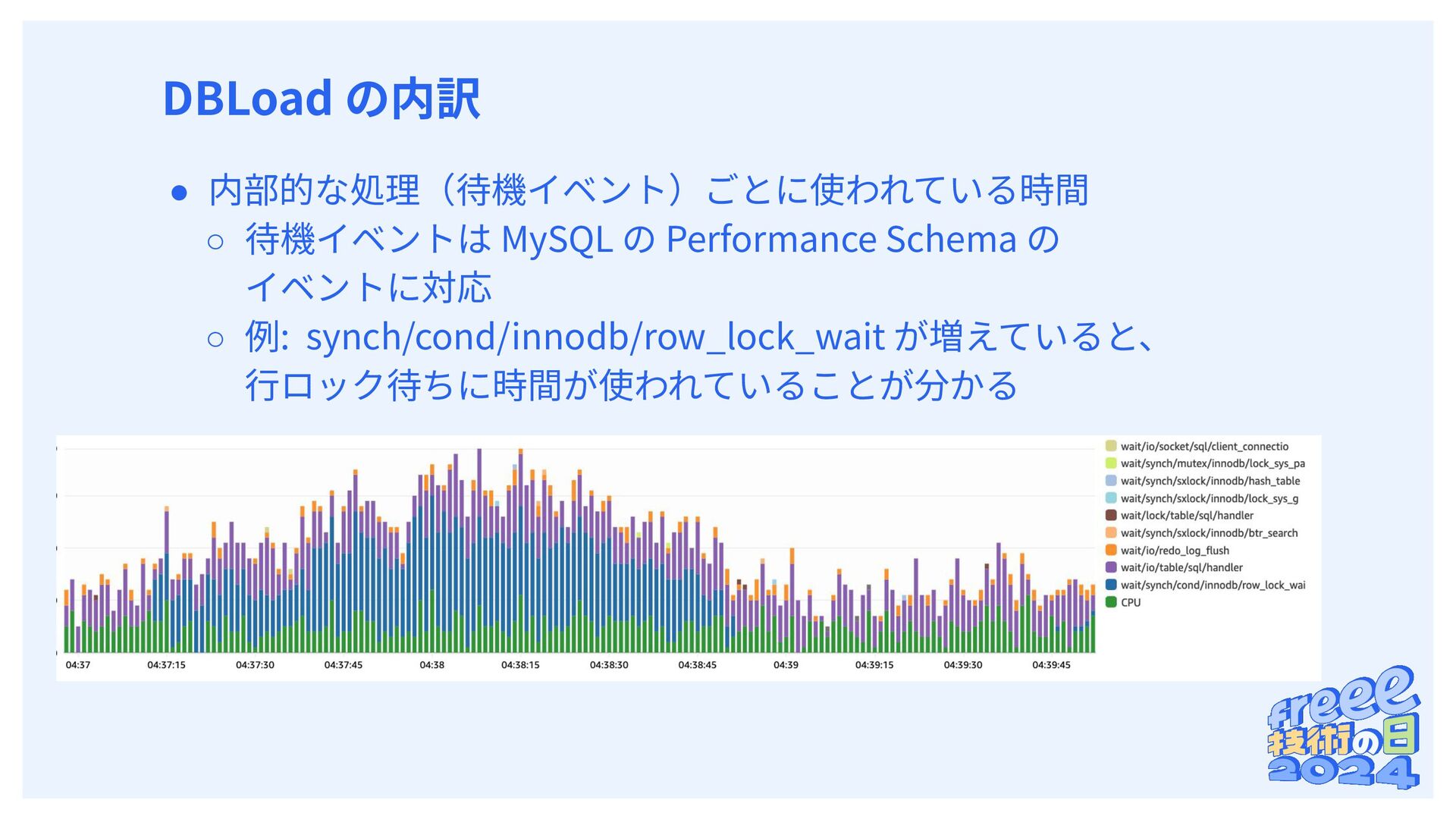{kind=link}
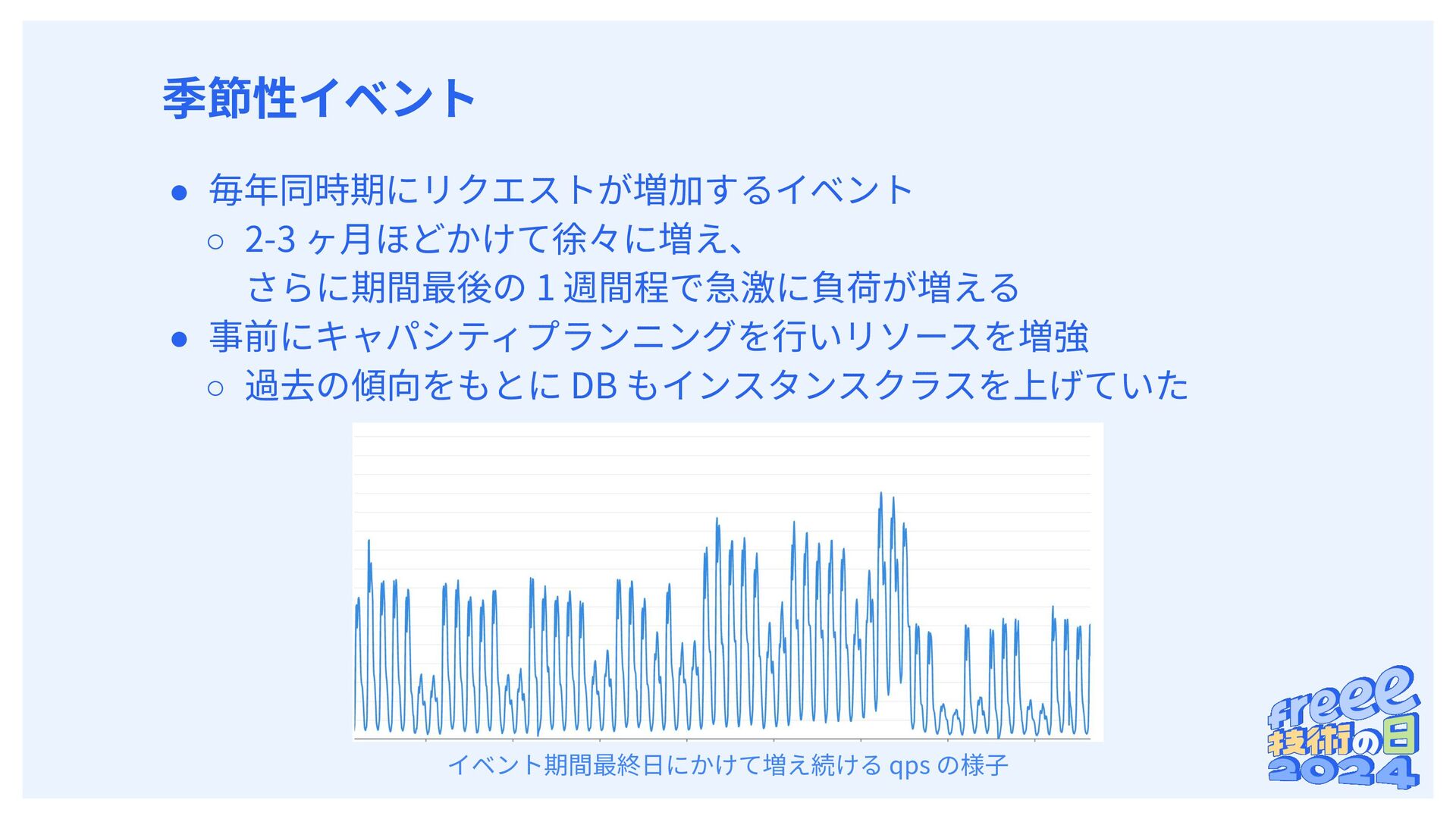{kind=link}
{kind=link}
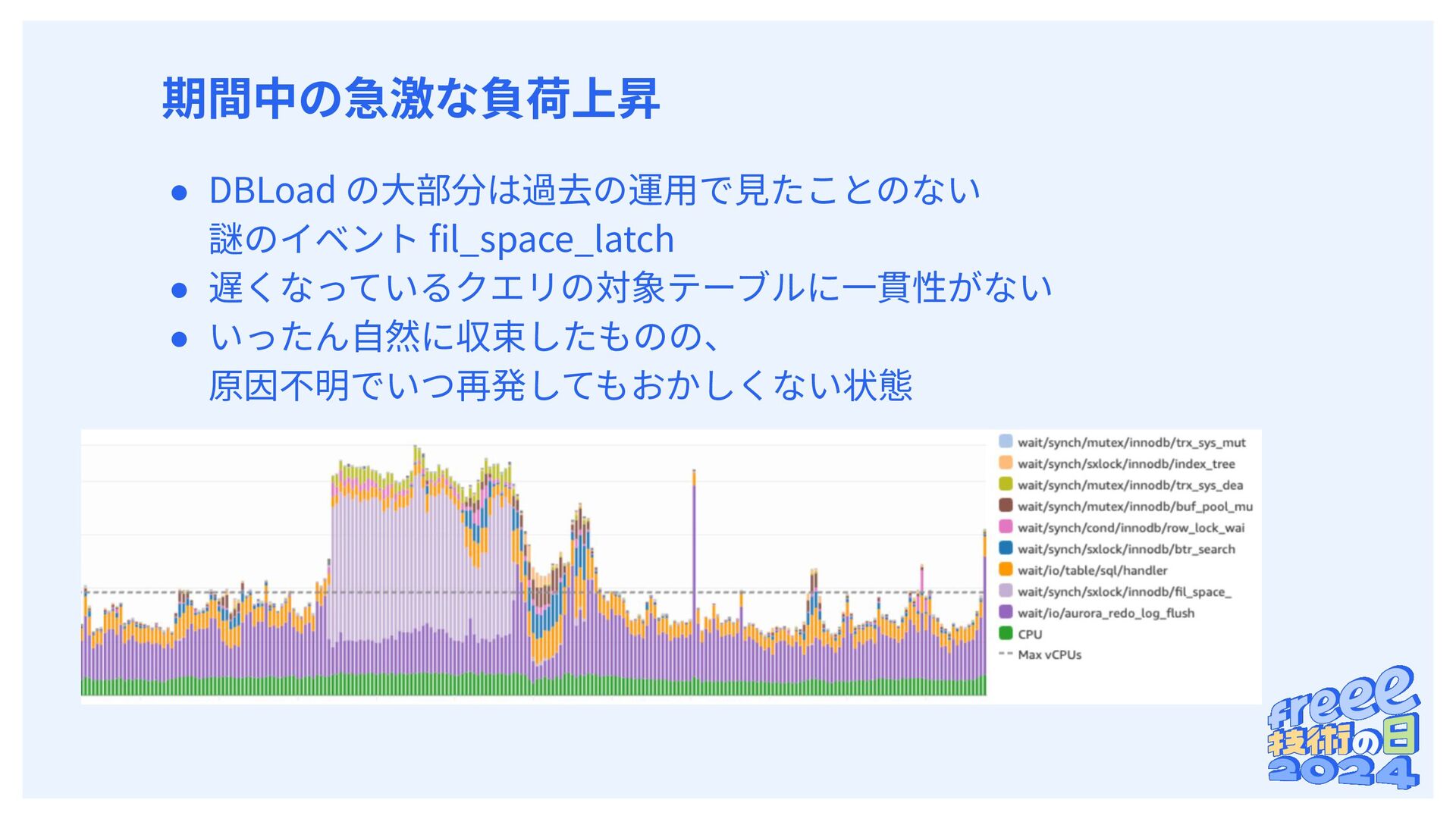{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
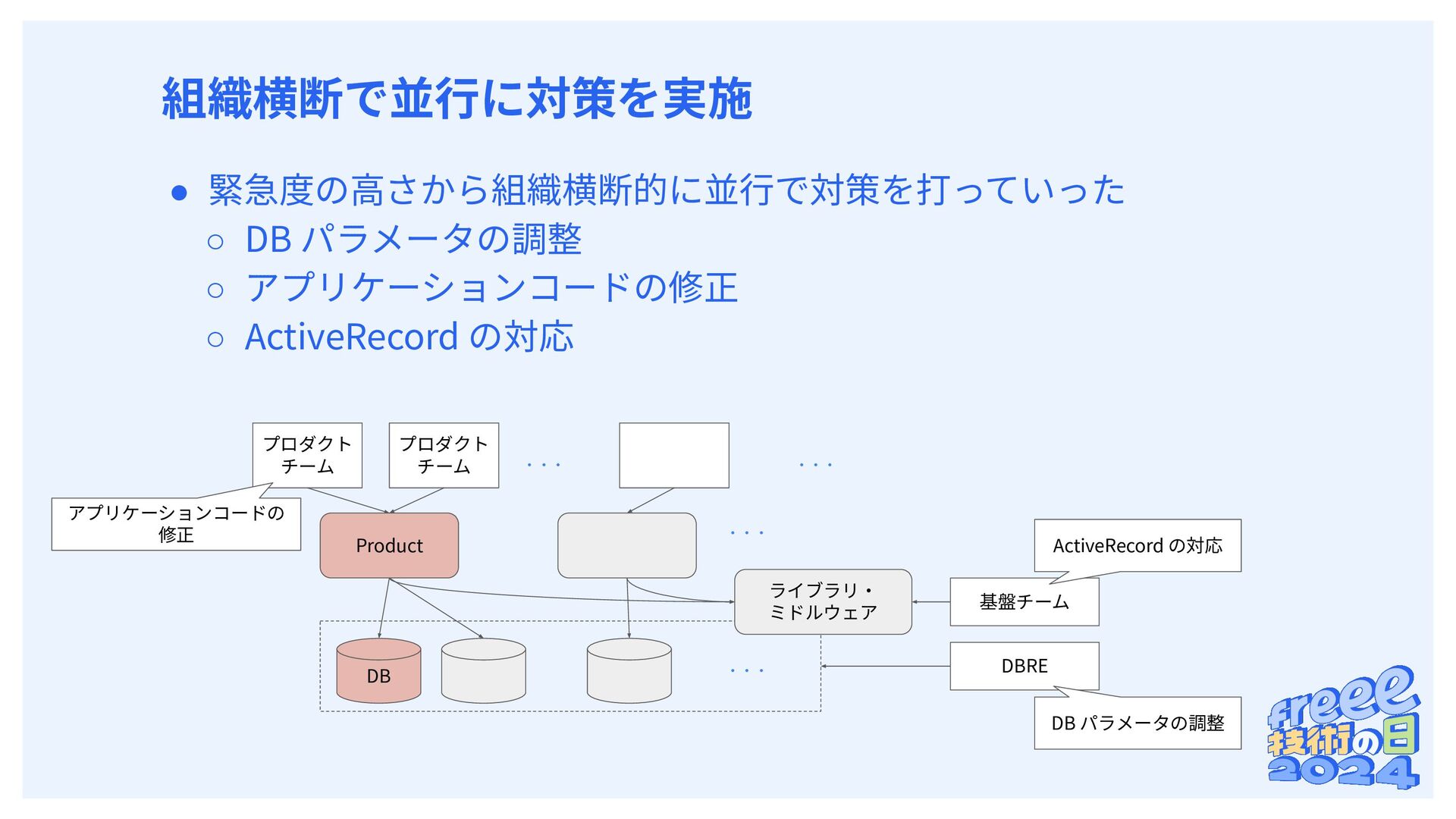{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}