Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第三回 全日本コンピュータビジョン勉強会(後編)
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
TSUKAMOTO Kenji
July 18, 2020
Technology
1k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第三回 全日本コンピュータビジョン勉強会(後編)
論文:RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
TSUKAMOTO Kenji
July 18, 2020
More Decks by TSUKAMOTO Kenji
See All by TSUKAMOTO Kenji
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
130
第65回コンピュータビジョン勉強会
tsukamotokenji
0
250
第64回コンピュータビジョン勉強会@関東(後編)
tsukamotokenji
0
340
DynIBaR (第60回CV勉強会@関東)
tsukamotokenji
0
270
DeepSFM: Structure from Motion Via Deep Bundle Adjustment
tsukamotokenji
2
650
Other Decks in Technology
See All in Technology
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
430
インフラ寄りSREでも 開発に踏み出せる〜境界を越えてユーザー体験に向き合いたい〜
sansantech
PRO
2
3.9k
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
240
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
740
AICoEでAIネイティブ組織への進化
yukiogawa
0
170
AIと共生する開発者プラットフォーム:バクラクのモノレポ×マイクロサービス基盤
sakajunquality
2
3.6k
穢れた技術選定について
watany
13
3.3k
【Claude Code】鹿野さんに聞く 私の推しの並行開発環境 大公開 / claude-code-parallel-2026-07-15
tonkotsuboy_com
11
7.9k
型は壁、Rustでもバグを直すな、表現できなくせよ
nwiizo
13
2.1k
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
1.3k
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
290
AI時代の開発生産性は、個人技からチーム設計へ
moongift
PRO
3
2k
Featured
See All Featured
We Have a Design System, Now What?
morganepeng
55
8.2k
How STYLIGHT went responsive
nonsquared
100
6.2k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
The Limits of Empathy - UXLibs8
cassininazir
1
470
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
190
Practical Tips for Bootstrapping Information Extraction Pipelines
honnibal
25
2k
Being A Developer After 40
akosma
91
590k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
ラッコキーワード サービス紹介資料
rakko
1
3.9M
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Building an army of robots
kneath
306
46k
Transcript
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds 2020/07/18 第三回
全日本コンピュータビジョン勉強会(後編)
RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds ◼CVPR 2020
(Oral) ◼3次元点群のセグメンテーション ◼Local Feature Aggregationを提案 ◦ 従来手法より早く、大規模点群(~106)が扱えるようになった ◼https://arxiv.org/abs/1911.11236
点群セグメンテーション ◼既存手法の制約 ◦ PointNetなどは小規模な点群(~104)しか扱うことができない ◦ SPG、FCPN、TangentConvでは前処理やVoxel化などの高負荷な処理が必要
目的 ◼大規模な点群を直接処理する ◦ ブロック分割やブロック統合といった前処理を行わない ◦ 出来る限り本来の幾何構造を保持 ◼計算・メモリ効率性 ◦ 高負荷な前処理やメモリ容量が必要なVoxel化は行わない ◦
大規模点群をsingle passで推論する ◼正確性&可用性 ◦ 複雑な幾何学的構造物から顕著な特徴を保持する ◦ 空間サイズや点数の異なる入力点群を処理できる
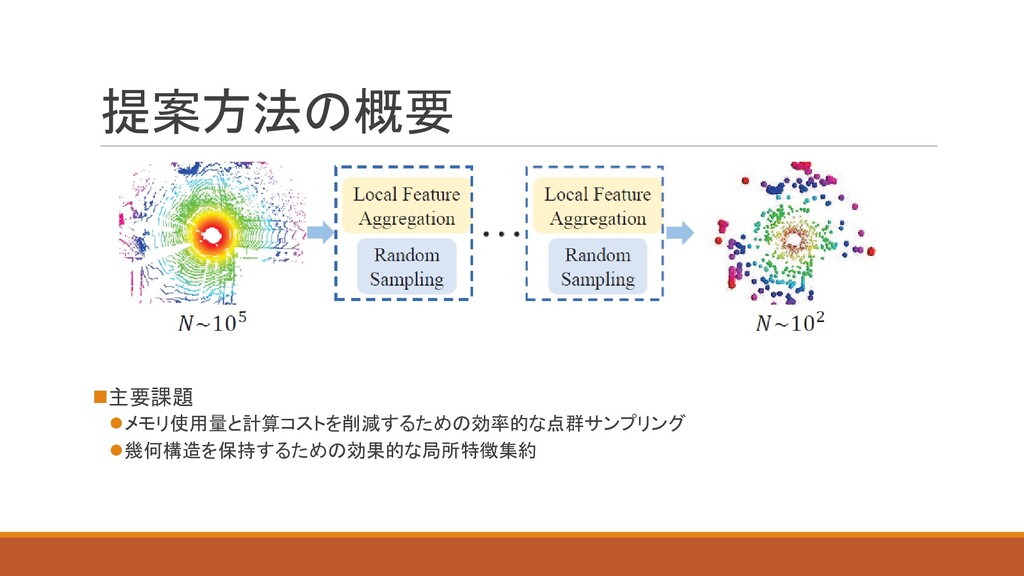
提案方法の概要 ◼主要課題 ⚫メモリ使用量と計算コストを削減するための効率的な点群サンプリング ⚫幾何構造を保持するための効果的な局所特徴集約
従来のサンプリング手法 Heuristic Sampling ◼Farthest Point Sampling (FPS) ⚫互いに最も離れた点パターンを選択する反復法で、広く使われている ⚫ Pros:点群の構造を保持する
⚫ Cons:計算負荷O(N2) ◼Inverse Density Importance Sampling (IDIS) ⚫各点の密度に応じて点群を並べ替え、上位M個の点を選択する ⚫ Pros:密度制御 ⚫ Cons:計算負荷O(N)、ノイズに敏感 ◼Random Sampling (RS) ⚫N個の点群から一様にM個の点を選択。各点は同確率で扱う ⚫ Pros:計算負荷O(1)、メモリ使用量少ない ⚫ Cons:有用な特徴を捨てる可能性がある
従来のサンプリング手法 Learning-based Sampling ◼Generator-based Smapling (GS) ⚫元の大きな点集合を近似的に表現するために、小さな点集合を生成することを学習 ⚫推論時は点の元の集合と部分集合をFPSでマッチング ⚫ Pros:データに基づくサンプリングができる
⚫ Cons:マッチングにFPSを使うため計算負荷が高い ◼Continuous Relaxation based Sampling (CRS) ⚫重み付きサンプリング手法で、重み行列を学習 ⚫ Pros: End-to-Endで学習できる ⚫ Cons: 重み行列のメモリ使用量が膨大 ◼Policy Gradient based Sampling (PGS) ⚫マルコフ決定過程に基づいて、各サンプル点の確率を学習 ⚫ Pros:効果的にサンプリングポリシーを学習 ⚫ Cons:大規模点群の学習では収束しにくい
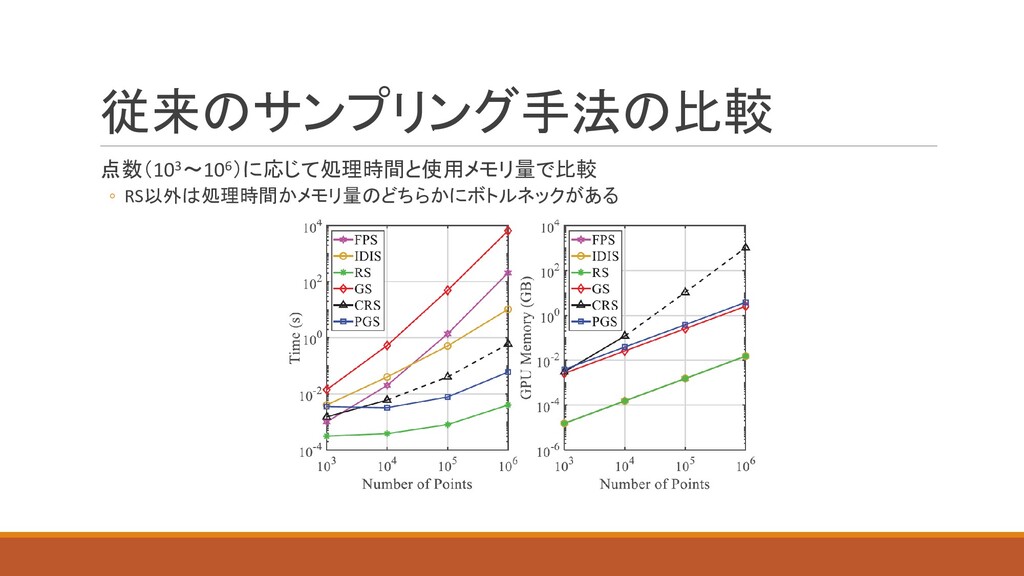
従来のサンプリング手法の比較 点数(103~106)に応じて処理時間と使用メモリ量で比較 ◦ RS以外は処理時間かメモリ量のどちらかにボトルネックがある
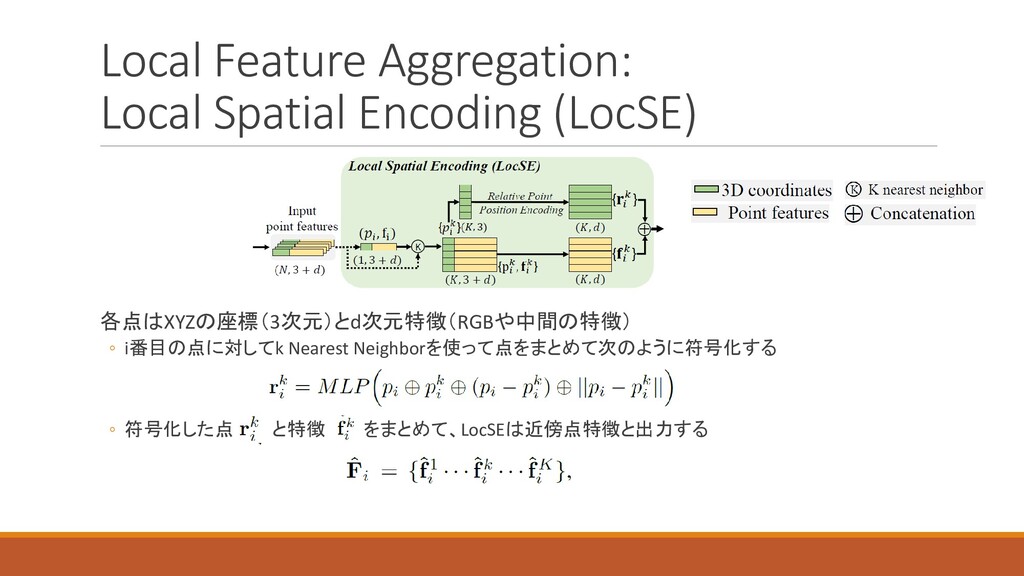
各点はXYZの座標(3次元)とd次元特徴(RGBや中間の特徴) ◦ i番目の点に対してk Nearest Neighborを使って点をまとめて次のように符号化する ◦ 符号化した点 と特徴 をまとめて、LocSEは近傍点特徴と出力する Local
Feature Aggregation: Local Spatial Encoding (LocSE)
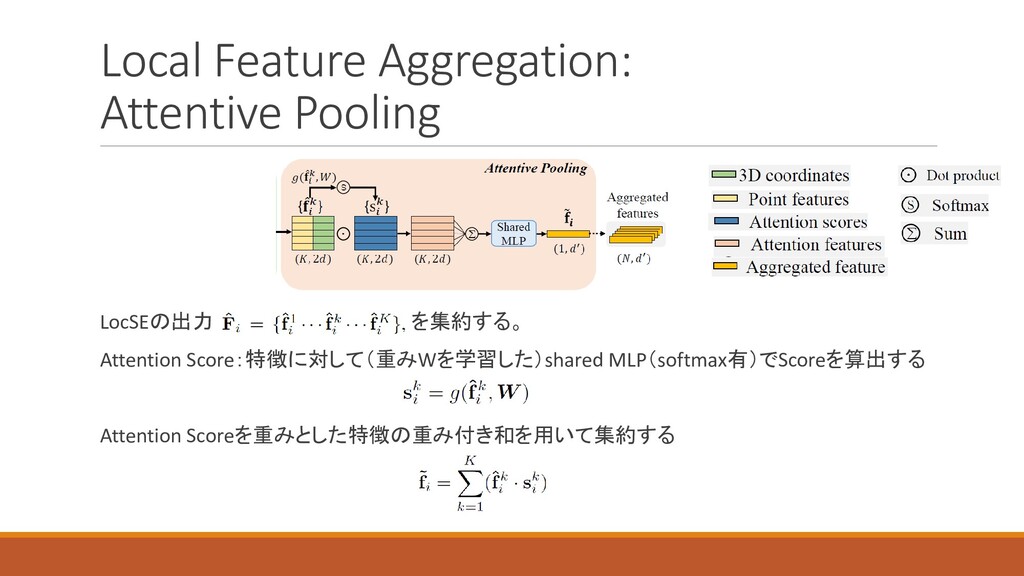
Local Feature Aggregation: Attentive Pooling LocSEの出力 を集約する。 Attention Score:特徴に対して(重みWを学習した)shared MLP(softmax有)でScoreを算出する
Attention Scoreを重みとした特徴の重み付き和を用いて集約する
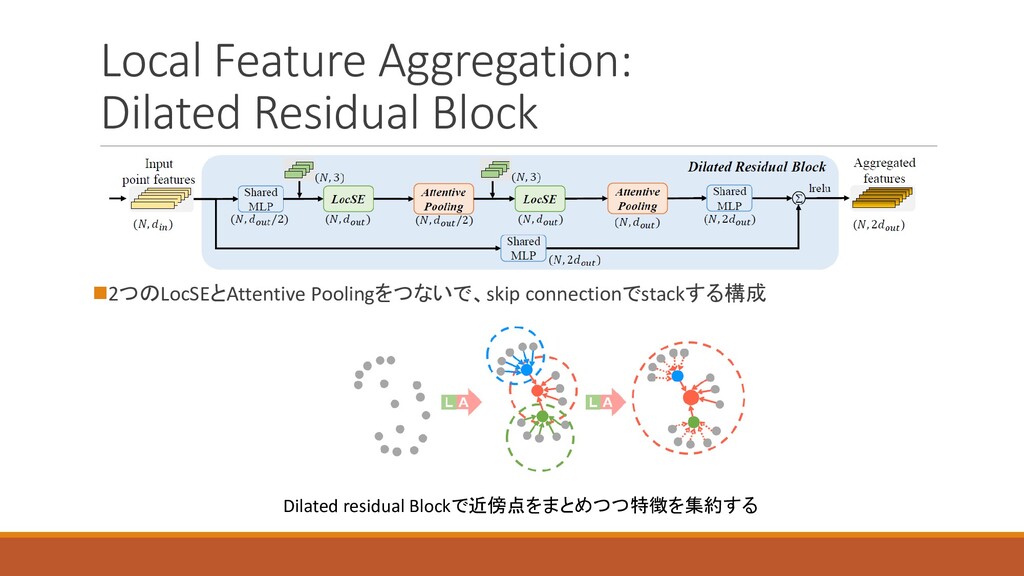
Local Feature Aggregation: Dilated Residual Block ◼2つのLocSEとAttentive Poolingをつないで、skip connectionでstackする構成 Dilated
residual Blockで近傍点をまとめつつ特徴を集約する
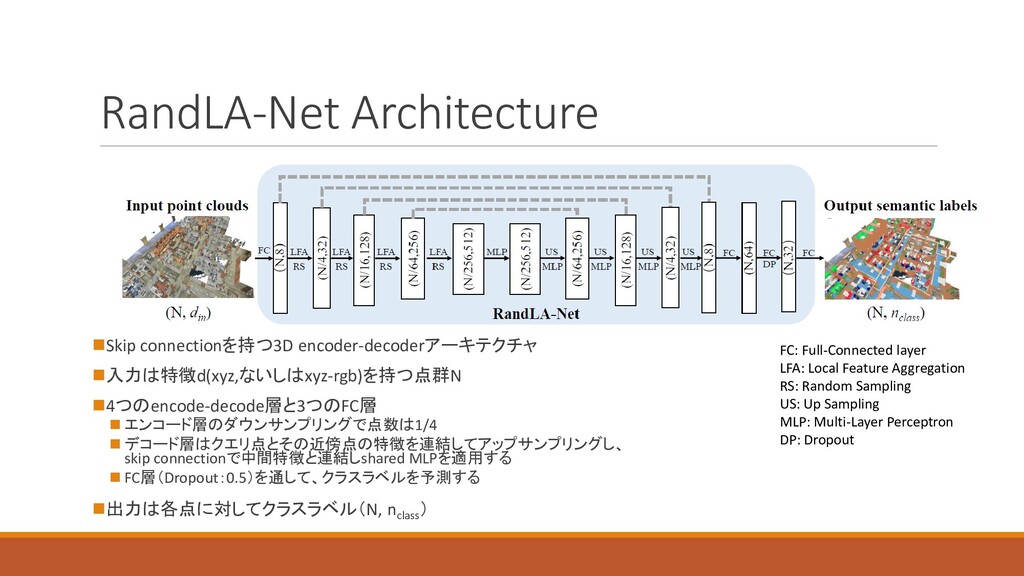
RandLA-Net Architecture ◼Skip connectionを持つ3D encoder-decoderアーキテクチャ ◼入力は特徴d(xyz,ないしはxyz-rgb)を持つ点群N ◼4つのencode-decode層と3つのFC層 ◼ エンコード層のダウンサンプリングで点数は1/4 ◼
デコード層はクエリ点とその近傍点の特徴を連結してアップサンプリングし、 skip connectionで中間特徴と連結しshared MLPを適用する ◼ FC層(Dropout:0.5)を通して、クラスラベルを予測する ◼出力は各点に対してクラスラベル(N, nclass ) FC: Full-Connected layer LFA: Local Feature Aggregation RS: Random Sampling US: Up Sampling MLP: Multi-Layer Perceptron DP: Dropout
実験 ◼実験 ◦ CPU:AMD 3700X @3.6GHz ◦ GPU:RTX2080Ti ◼データセット ◦
SemanticKITTI ◦ Semantic3D ◦ S3DIS ◼評価 ◦ 効率性:処理時間、メモリ使用量 ◦ セグメンテーション精度 ◼コード ◦ https://github.com/QingyongHu/RandLA-Net
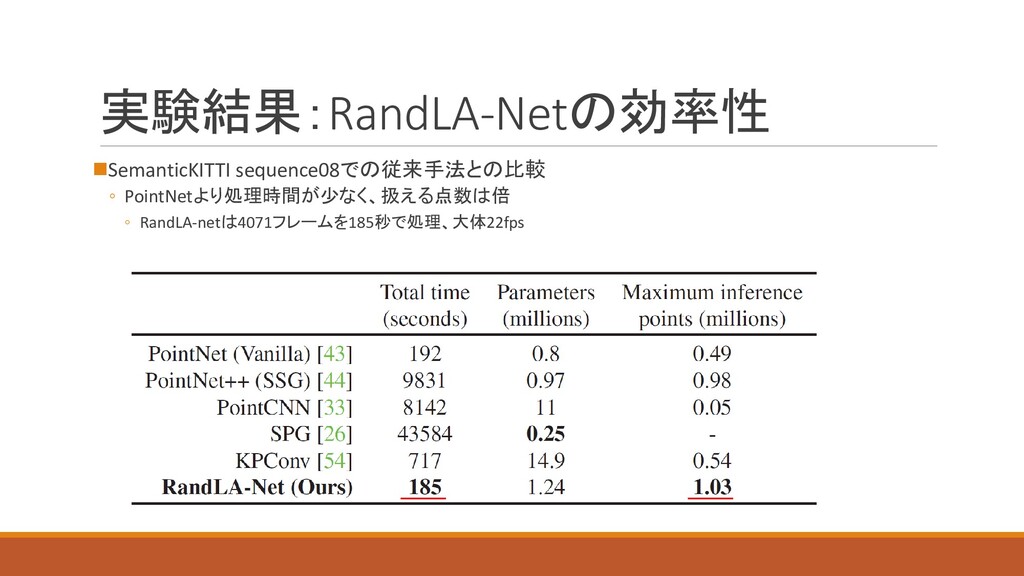
実験結果:RandLA-Netの効率性 ◼SemanticKITTI sequence08での従来手法との比較 ◦ PointNetより処理時間が少なく、扱える点数は倍 ◦ RandLA-netは4071フレームを185秒で処理、大体22fps
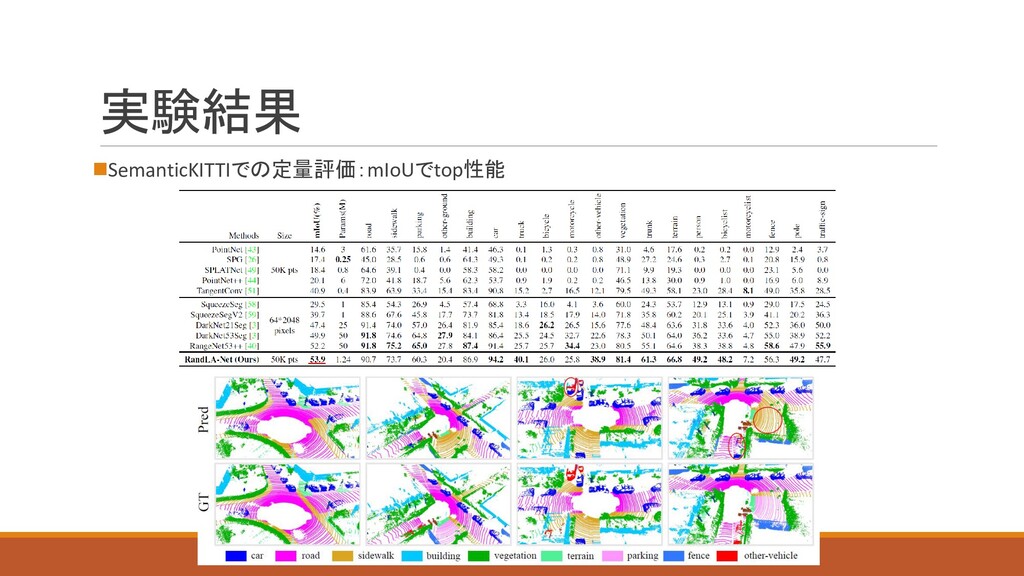
実験結果 ◼SemanticKITTIでの定量評価:mIoUでtop性能
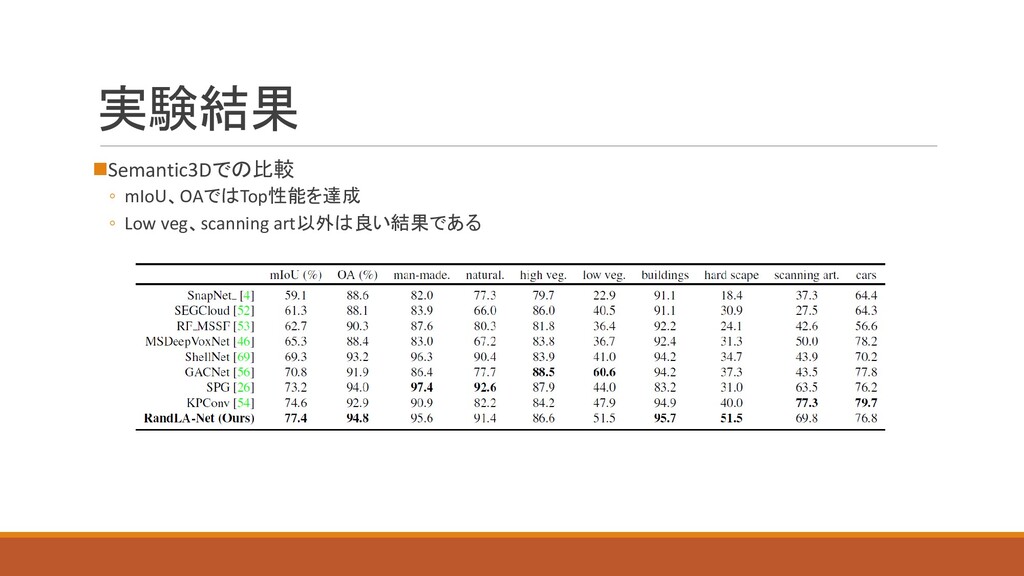
実験結果 ◼Semantic3Dでの比較 ◦ mIoU、OAではTop性能を達成 ◦ Low veg、scanning art以外は良い結果である
実験結果 ◼S3DISでの評価:全13クラスの平均IoU(mIoU)、平均クラス精度(mAcc)、総合精度(OA)を比較 ◦ 全体的に最先端手法と同等の性能を確認 ◦ 最先端手法は点群を分割して(個別の部屋単位)処理していることが精度では有利 ◦ RandLA-Netは点群全体をsingle pathで全体をセグメンテーションしている
セグメンテーション結果 https://www.youtube.com/watch?v=Ar3eY_lwzMk
Ablation Study ◼LFAのablation styudyをSemanticKITTIで確認 ◦ LocSEの除去 (1) ◦ Attentive Poolingの置き換え(max/mean/sum
pooling) (2)~(4) ◦ Dilated residual blockを1つにする (5) ◼実験結果 ◦ Dilated residual blockを1つにするとより広い空間情報を保持できない ◦ LocSEを除去すると、幾何構造を効果的に学習できていないと推測 ◦ Attentive poolingは有用特徴を保持している
まとめ ◼提案手法 ◦ 前処理なしの点群セグメンテーション ◦ 大規模点群を扱うことが出来る ◦ 局所空間で点群の特徴を集約する手法を提案 ◦ Random
samplingを活用 ◼結果 ◦ 最先端手法と同等性能 ◦ 大規模点群(~106 )をsingle pathで高速に処理可能
None
点群処理の資料 PointNet ◦ https://www.slideshare.net/FujimotoKeisuke/point-net LiDARで取得した道路上点群に対するsemantic segmentation ◦ https://www.slideshare.net/takmin/20181228-lidarsemantic-segmentation 点群深層学習の研究動向 ◦
https://www.slideshare.net/SSII_Slides/ssii2019ps2 点群CNN、3D CNN入門 ◦ https://qiita.com/arutema47/items/cda262c61baa953a97e9
Appendix Additional Ablation Studies on LocSE ◼LocSEにおける近傍点をまとめる符号化式を変更時のsemanticKITTIのmIoU評価 1. のみ符号化 2.
のみ符号化 3. と を符号化 4. と と を符号化 5. と と を符号化 LocSE符号化を変更した結果
Appendix Additional Ablation Studies on Dilated Residual Block ◼Dilated Residual
Blocの数を変更した場合 ◦ 1層のLocSEとAttentive Pooling unit ◦ 3層のLocSEとAttentive Pooling unit ◦ 2層のLocSEとAttentive Pooling unit ◼1層のaggregation unitだと性能が低下(点がうまく集約されていない) ◼3層のaggregation unitだとパラメータがoverfitしている Dilated Residual Blockの数を変更
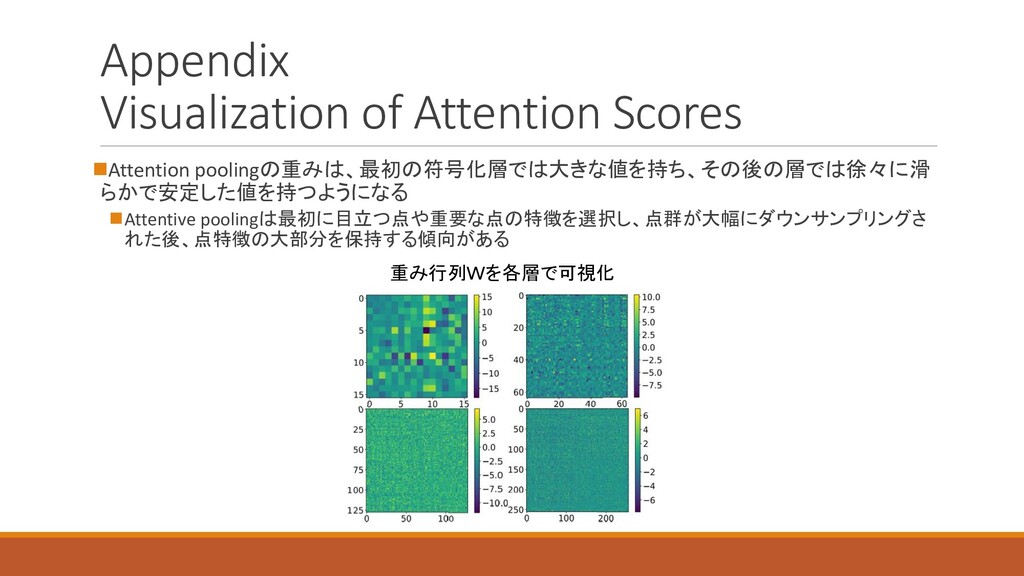
Appendix Visualization of Attention Scores ◼Attention poolingの重みは、最初の符号化層では大きな値を持ち、その後の層では徐々に滑 らかで安定した値を持つようになる ◼Attentive poolingは最初に目立つ点や重要な点の特徴を選択し、点群が大幅にダウンサンプリングさ
れた後、点特徴の大部分を保持する傾向がある 重み行列Wを各層で可視化
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}