in my free time over a course of time! ◈ If you think a problem can be approached in a better manner, let us share the knowledge over coffee beer. ◈ Have some more ideas, please write it down so we can discuss. ◈ There are multiple ways of approaching a problem. ◈ I also share my failures so that you know what not to do. *All Images to original owners
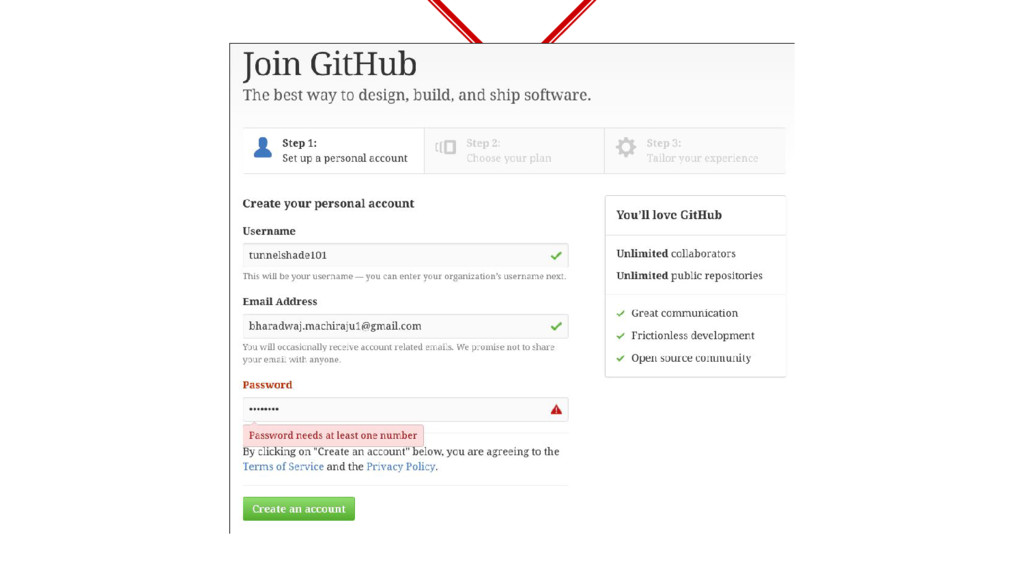
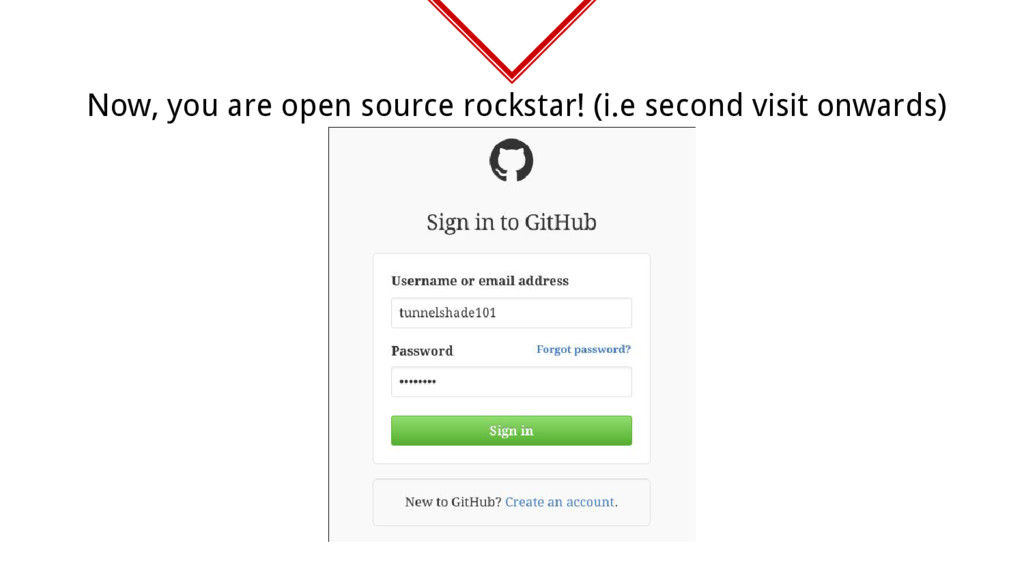
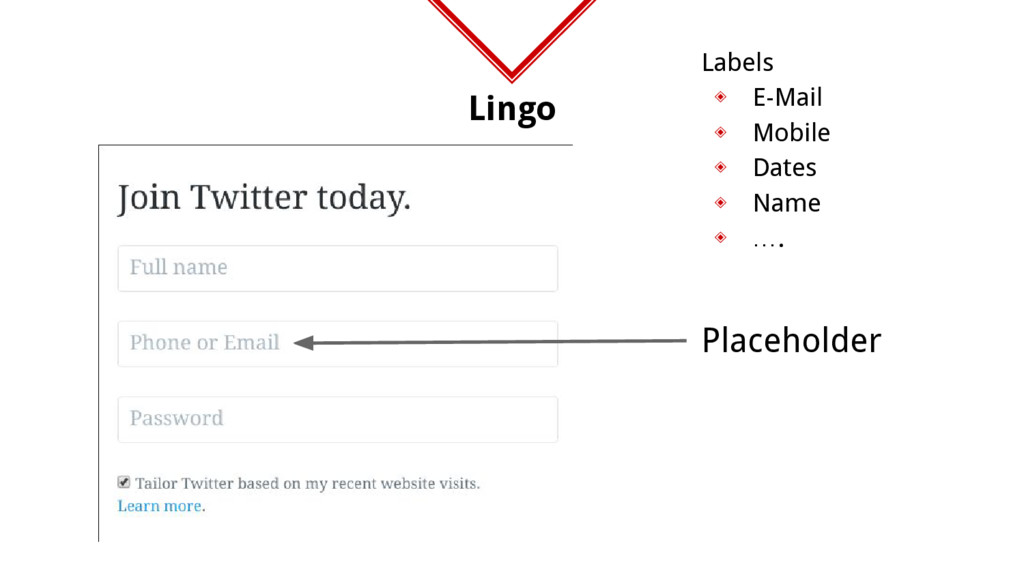
did in the story. Recognize Sequences From your previous experiences you recognize that you need to login but signup before that to access more functionality. Identify Inputs You understood that an email input field expects an email address while a credit card number expects a well, credit card number. Understand Feedback Feedback of application in this case incorrect format of password was understood by you and correspondingly the input was changed. Recall Input Values For logging in you recollected that these values are same as the ones provided during the sign-up hence used them. Categorize Pages While browsing the pages found were partially remembered for their functionality to be recalled later. Avoid Redundancy If a page similar to a previously browsed one turned up, it was ignored to prevent redundancy and save time.
the format that is expected plays a vital role in understanding or navigating an application Understand Feedback Understanding the feedback given by the application makes the system self improving hence enhancing it’s performance overtime. Perform Sequences Being able to learn and perform simple sequence of steps like registering and logging in or adding a new address and editing it allows for better targeted navigation.
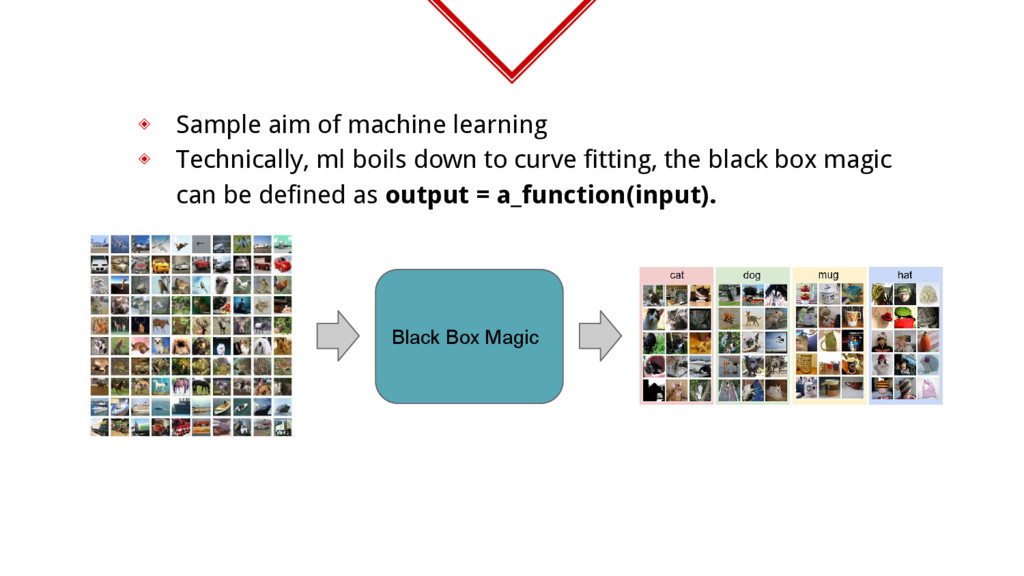
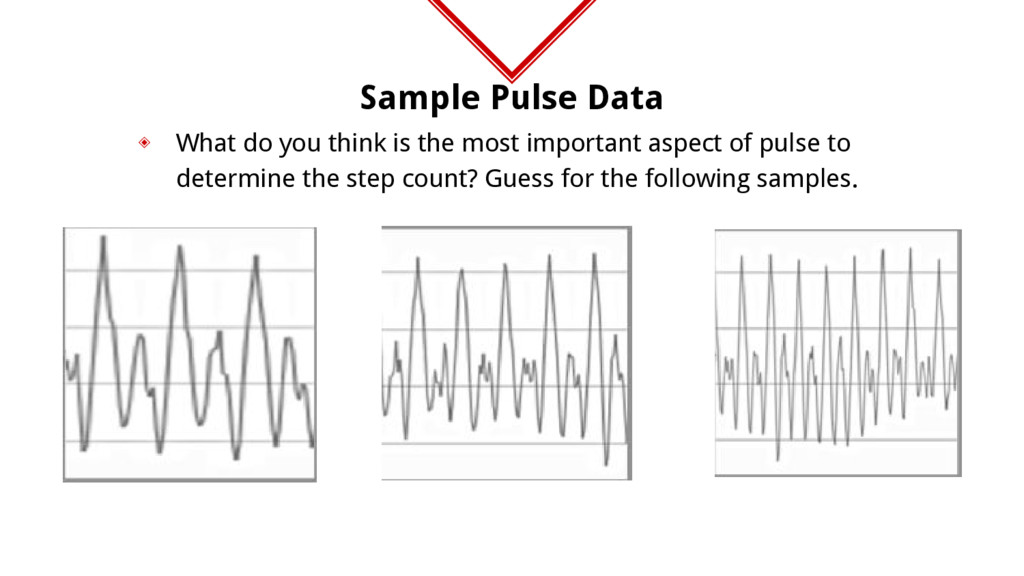
like manufacturer, trying to find step count using your gadget, the data that you have is pulse rate. ◈ Now, you need to tell if user took 1,2 or 3 steps depending on his pulse rate. ◈ You need a function that is like steps = f(pulse_data)
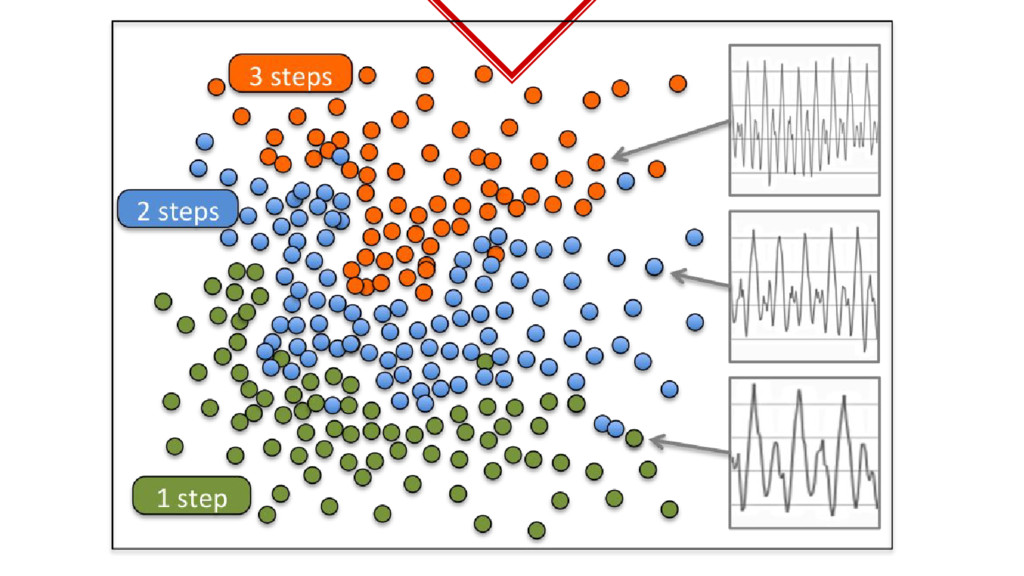
pulses. ◈ Simplified function steps = f(average_pulse_height, average_time_between_pulses) ◈ What we did above is called feature engineering. ◈ If you plot the pulse data samples and known step counts on a 2-d plot
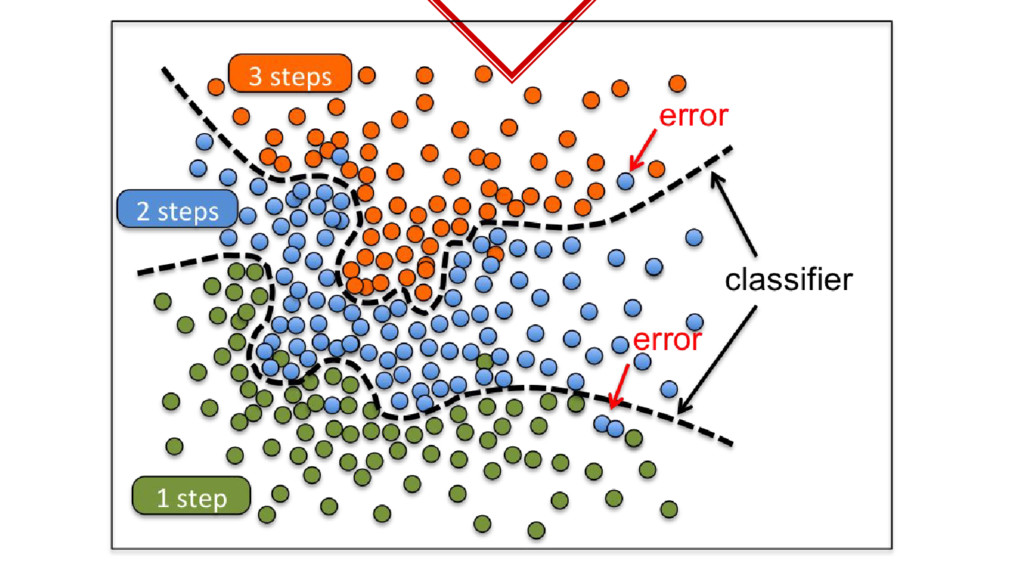
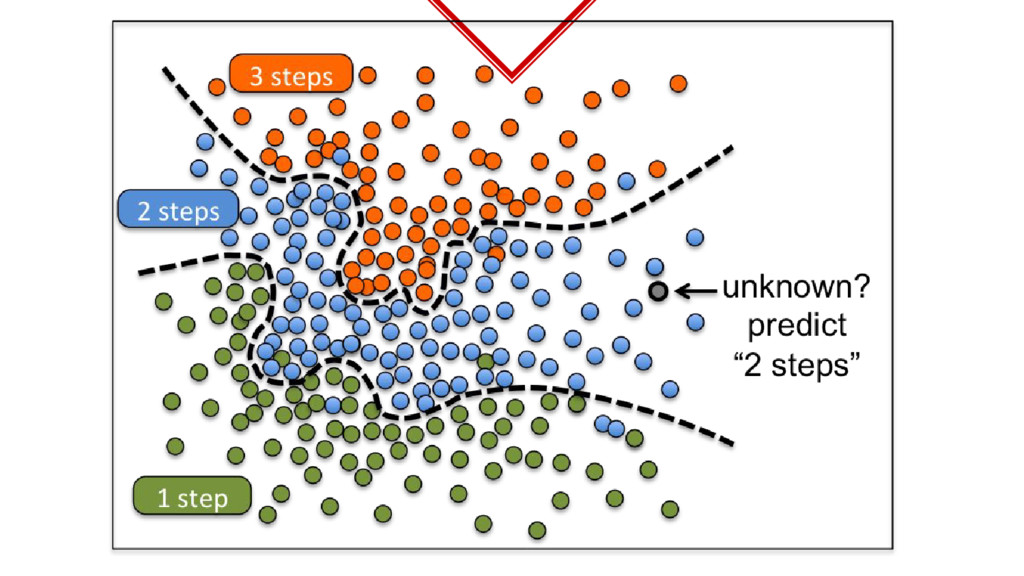
◈ Collected lots of samples. ◈ Train the samples. ◈ What we just did is called Supervised Learning. ◈ Obviously because we had to label the training data ourselves.
saw this! ◈ Unsupervised Learning ◈ Semi-Supervised learning is a class of supervised where small amount of labelled data is used along with large amount of unlabelled data.
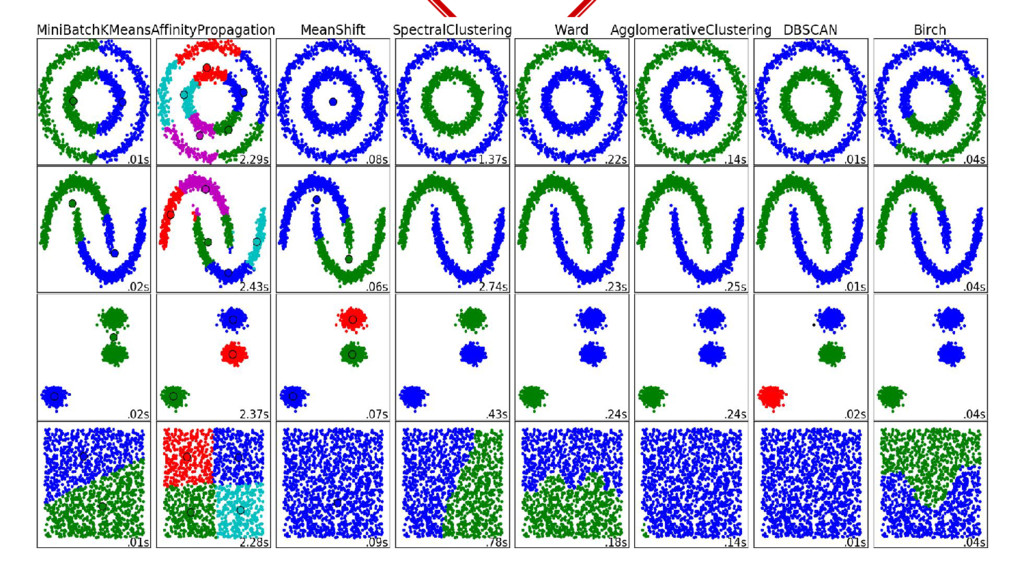
hand labelling all the training data, you just tell how many clusters need to be formed in the data. ◈ Depending on the algorithm and hyperparameters you get your function. ◈ Downside of this is the difficulty in visualizing the clusters especially in high dimensional data.
is heavily dependent on the textual content. ◈ Does that mean we should used it as our features? Not necessarily. ◈ But it is consistent across applications and general feedback from apps is textual again!
that we don't consciously understand language ourselves. The second major difficulty is ambiguity. ◈ Representation of text in numbers is another story. Imagine the following line ⬥ What do you understand by “Pressing a suit”? ⬥ Now think like a Lawyer and then like a dry cleaner.
the format that is expected plays a vital role in understanding or navigating an application Understand Feedback Understanding the feedback given by the application makes the system self improving hence enhancing it’s performance overtime. Perform Sequences Being able to learn and perform simple sequence of steps like registering and logging in or adding a new address and editing it allows for better targeted navigation.
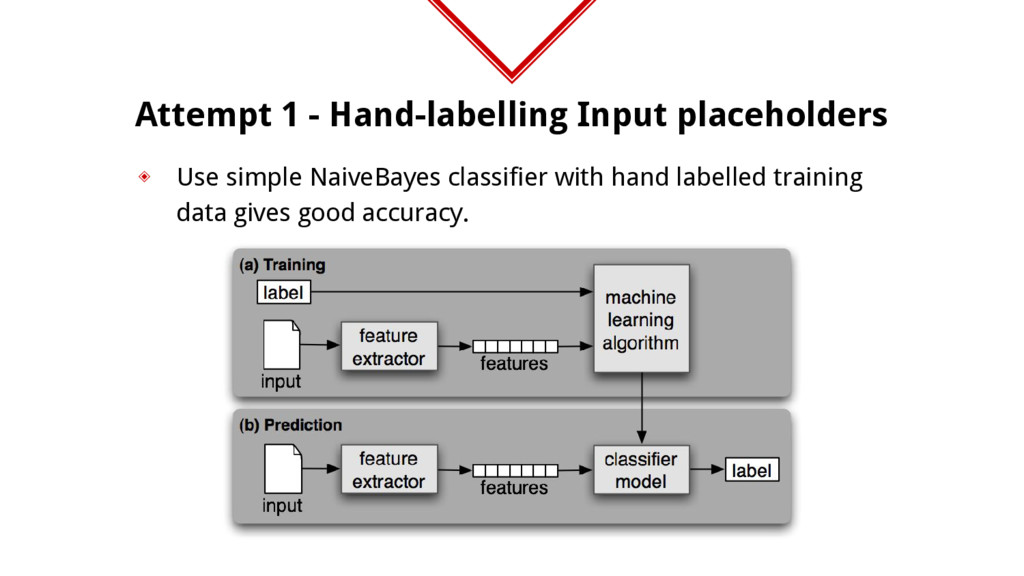
solution ◈ Cons ⬥ Hand labelling takes manual effort. This is a big NO NO for me. ⬥ Unknown placeholders or a different language support is a whole new story.
of data, I cannot label them manually or automatically. ◈ Manually is too much effort. ◈ Automatically not possible because input formats cannot be categorized without complex rules, so drop classification. ◈ Clustering is a daunting task as the data is high dimensional.
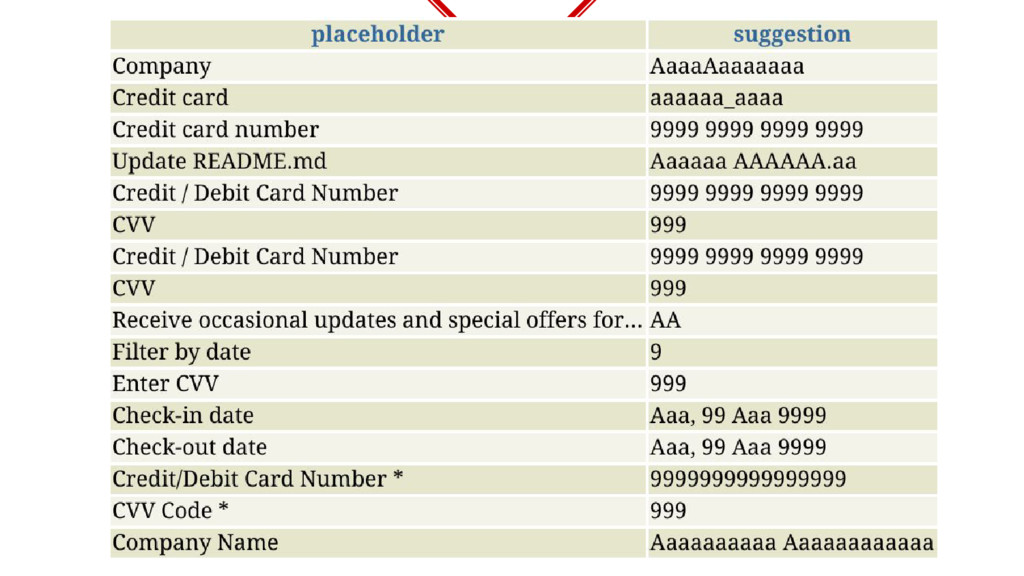
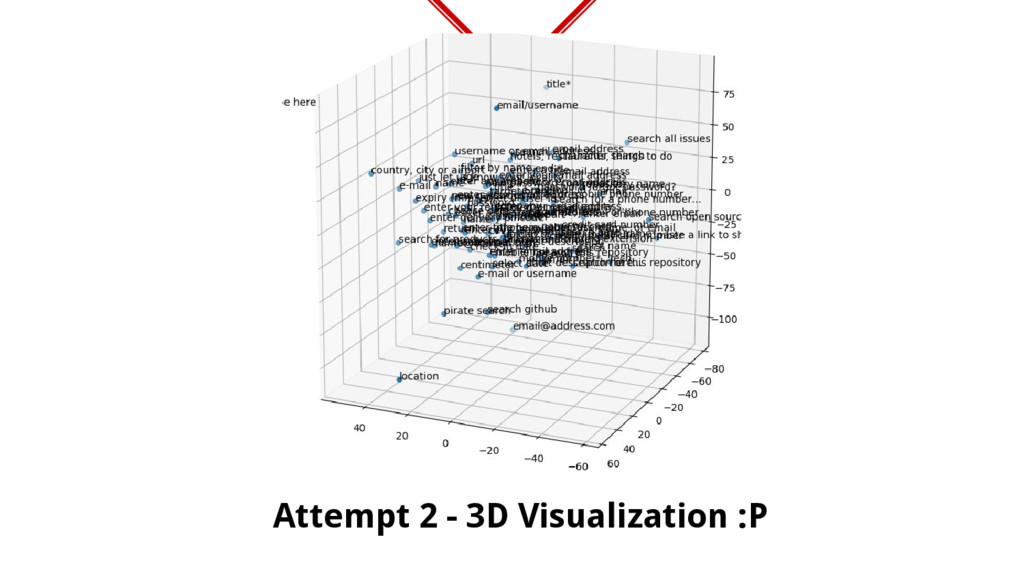
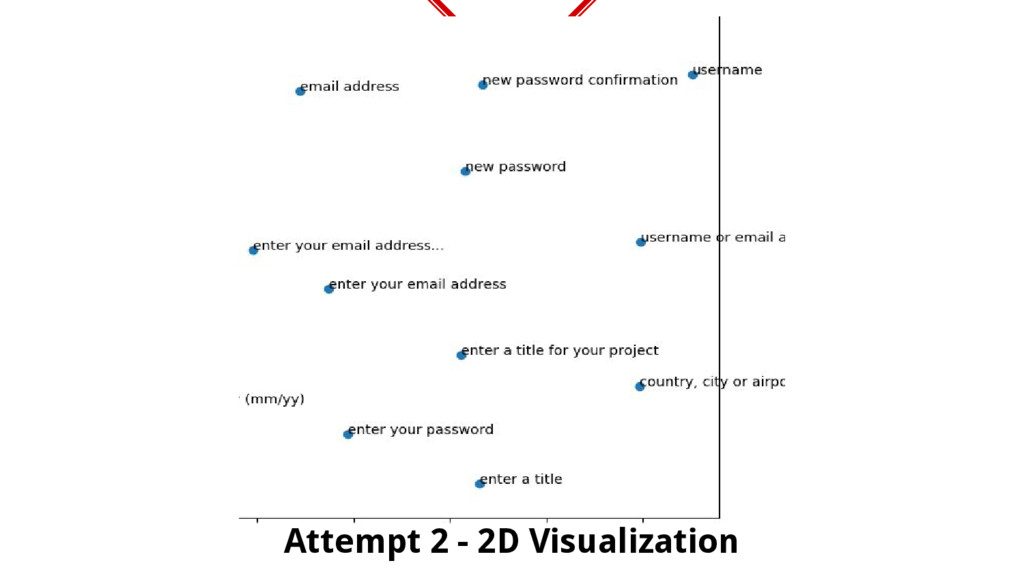
placeholders into a multi-dimensional vector space so that similar placeholders are nearby. Used Term Frequency-Inverse Document Frequency. ◈ Imagine a 3d space, our vectorization should be such that f(“Enter your email address”) ≅ f(“E-mail address..”) ◈ So, if you get a new placeholder, you can check the spatial cosine distance between the placeholder with all known data to get most similar matches. Let us visualize
a new placeholder is encountered similarity is checked with other placeholders to determine the input and if input is successful, the new placeholder is added into training data….
the format that is expected plays a vital role in understanding or navigating an application Understand Feedback Understanding the feedback given by the application makes the system self improving hence enhancing it’s performance overtime. Perform Sequences Being able to learn and perform simple sequence of steps like registering and logging in or adding a new address and editing it allows for better targeted navigation.
of Speech ◈ One way to understand feedback like these is to breakdown the sentence into phrases and extract information. ◈ Pros ⬥ It works!! ← Yes, it is a pro ◈ Cons ⬥ Complex logic to get it right. ⬥ Different languages might need different logic. ⬥ Illformed english is a NO NO.
help text to a particular input field? ⬥ Noun reference - When the help text directly refers to the input placeholder like “Your password should be …” ⬥ Visual Correlation - When the help texts are placed in such a way that they are visually related to the input.
Short Term Memory network (a class of Recurrent Neural Networks) ◈ Using seq2seq to translate these help texts into suggestions like previously seen. ◈ Seq2seq is a popular model which are extremely successful in translation tasks.
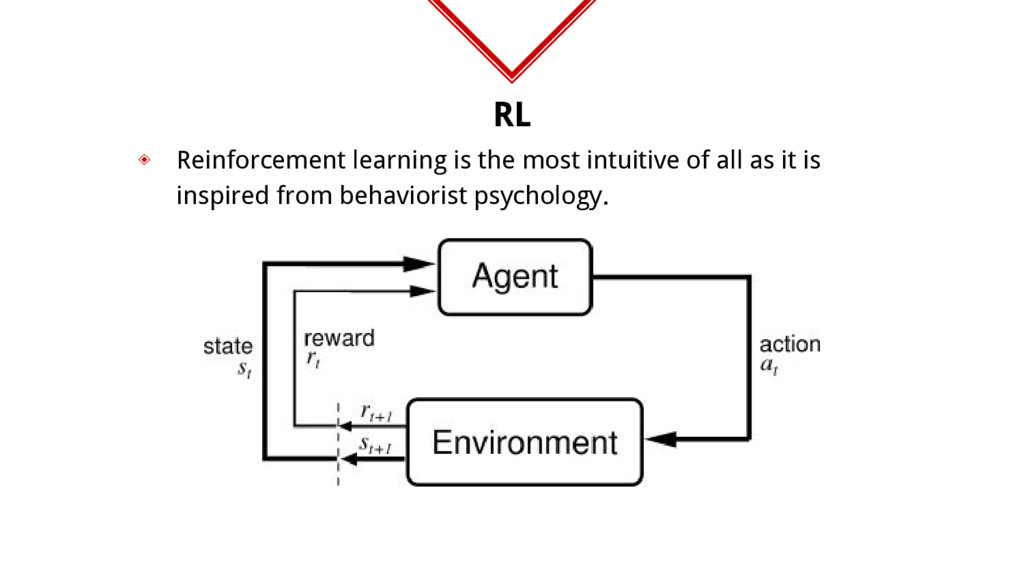
which lead to cumulative positive reward while avoiding actions that lead to a cumulative negative reward. ◈ So, generally an agent can be rewarded based on the states it arrives in which in long term make the agent biased towards the actions that lead to these states. ◈ Any problem that can be expressed as a Markov Decision Process can be an application for RL.
Right, Up, Down ◈ State: ??? ◈ Reward: +10 for “+1” box, -1 for every step and -10 for “-1” box [left_box_type, right_box_type, up_box_type, down_box_type, direction_of_nearest_+1]
is to perform certain action in certain state Q(state_vector, action_num). ◈ Higher the Q value more profitable the action will be. ◈ Value functions are generally stored in different ways of function approximators like RBF, Neural Networks etc... ◈ So, when you say experience is stored, it means that this value function was updated according to latest occurances.
the format that is expected plays a vital role in understanding or navigating an application Understand Feedback Understanding the feedback given by the application makes the system self improving hence enhancing it’s performance overtime. Perform Sequences Being able to learn and perform simple sequence of steps like registering and logging in or adding a new address and editing it allows for better targeted navigation.
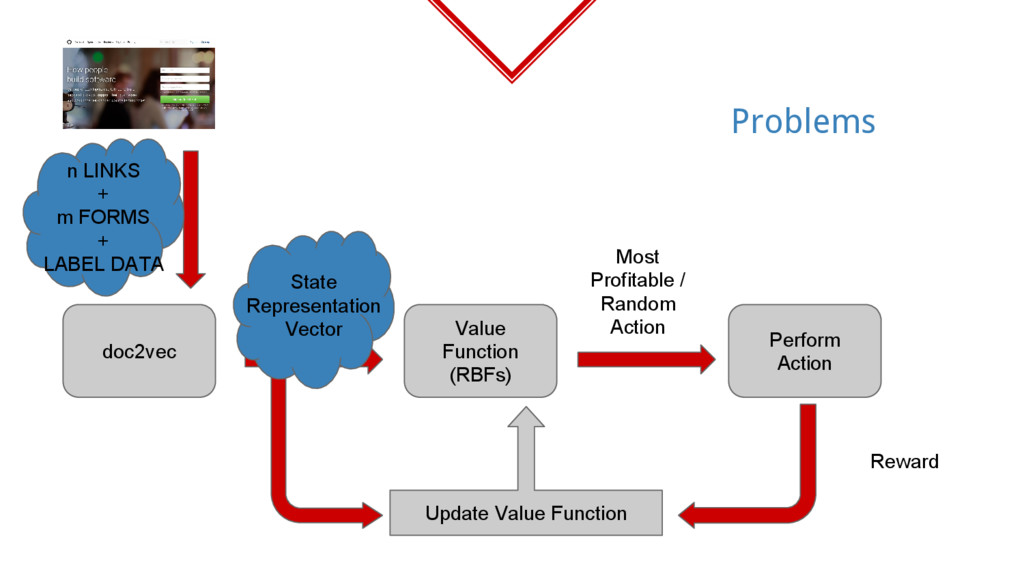
sequence of link clicks and form fills! So, these two types generally constitute our actions. ◈ Reward based on the end result requirements. ◈ What is state made up of then?
a text “SignUp” generally leads to a form where you can register. ◈ You didn’t click on other links on the page like Open Source etc.. because the reward that you were pursuing is to login.
need to be numbers. So again we have to represent the text in a numerical form so that similar states are closer in their vector form. ◈ What might be a good way?
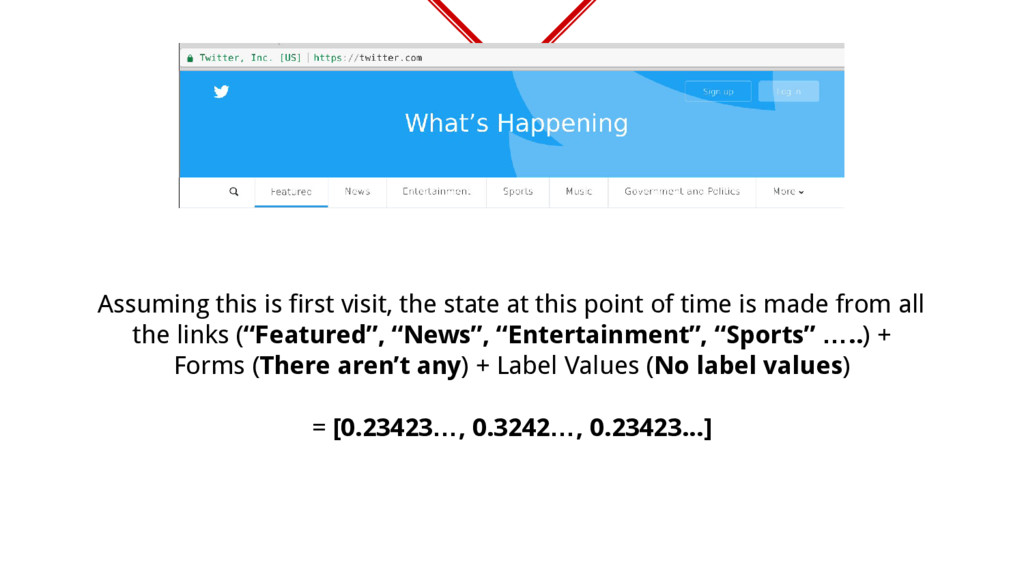
all the link texts, form placeholders and label input data as a string and vectorize it? ◈ Doc2Vec/Paragraph2Vec was used for this. ◈ The idea still remains same, you have a bunch of state strings which when mapped have the similarities between them. ◈ For example
of time is made from all the links (“Featured”, “News”, “Entertainment”, “Sports” …..) + Forms (There aren’t any) + Label Values (No label values) = [0.23423…, 0.3242…, 0.23423...]
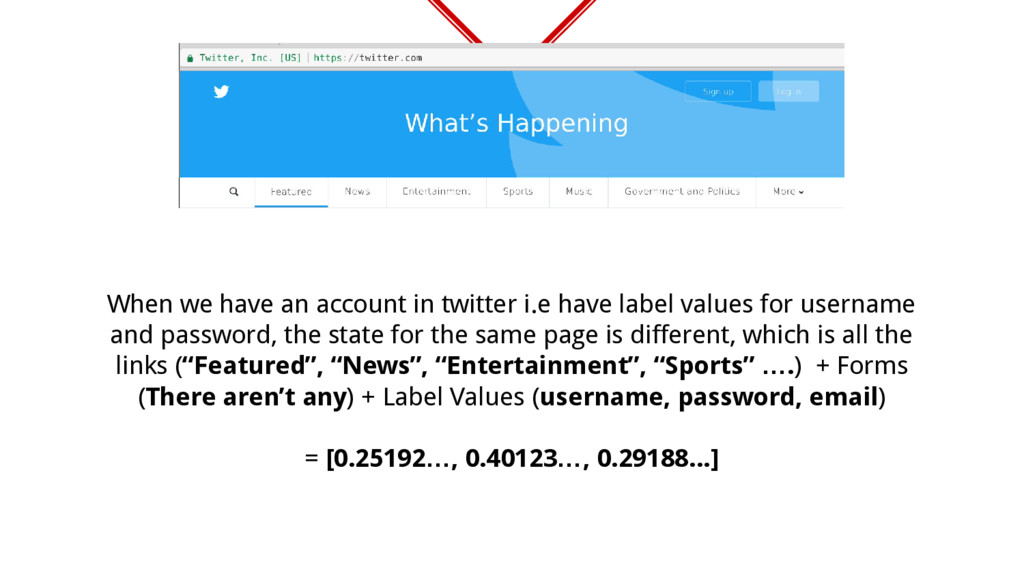
values for username and password, the state for the same page is different, which is all the links (“Featured”, “News”, “Entertainment”, “Sports” ….) + Forms (There aren’t any) + Label Values (username, password, email) = [0.25192…, 0.40123…, 0.29188...]
each state were ⬥ Clicking a link (which was part of state info) ⬥ Filling a form (which was part of state info) ◈ Reward ⬥ Each step: -1 ⬥ Successfully Logged In: +20 ◈ LSPI SARSA agent was used with RBF for storing the value function. ◈ Let us quickly look at it step by step
Representation Vector Value Function (RBFs) Most Profitable / Random Action Perform Action Reward Update Value Function New State and same cycle repeats
did, but only for simple applications. ◈ Huge applications like E-Commerce sites have lots of links of which most of them lead to a product page. ◈ The state representation being continuous poses convergence challenges to the policy. I.e even though the state vector is only 3 dimensional, those three dimensions can take any value between -1 to +1 which makes the state space extremely complex for quickly learning a policy.
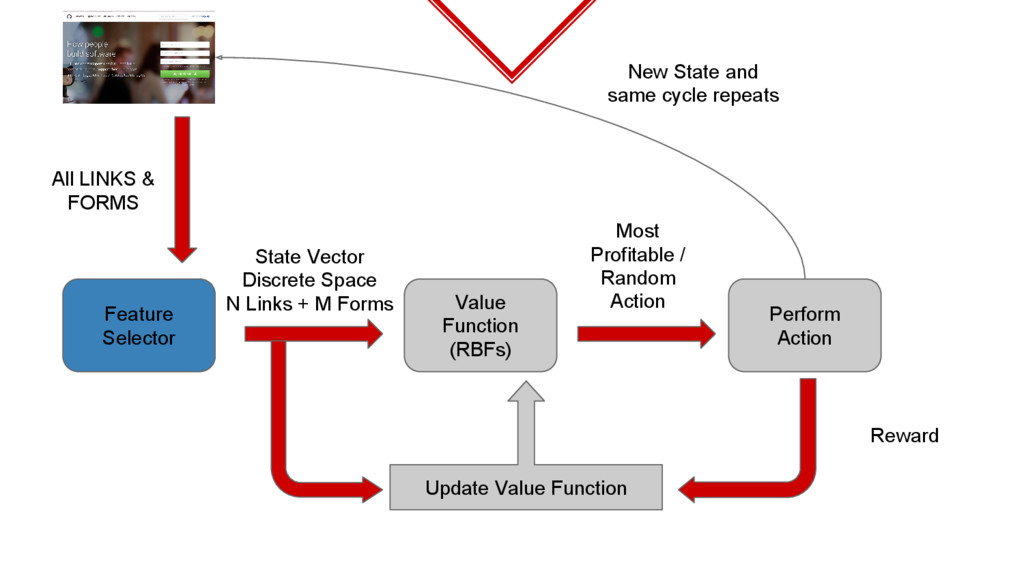
solve the problems in the previous model ⬥ Limited set of links & forms for consideration. ⬥ Huge state space. ◈ One good way is to use an unsupervised feature selector and then converting those selected features into a state vector.
allow us to consider huge number of links and forms at the same time giving a discrete state space. ◈ The added complexity is to train the feature selector along with the value function.
subset of features and try episodic learning with the RL agent. ◈ If an episode ends with a positive reward, try to store the elements (i.e links and forms) if they are not already present. ◈ For the next episode, label the required number of forms or links as per the stored elements. ◈ These labels constitute the state vector. ◈ Damn!! This is difficult to explain, let us look at an example
1.0, 0.0] Login Module Trained to pick only login & signup links and forms. 2 links and 2 forms are labelled [1, 2, 4, 0] = [link1, link2, form1, form2] Link Labels 1. SignUp type link 2. Login type link Form Labels (0 indicates no match) 1. Login Type Form 2. Signup Type Form
a subset of features, manually perform new sequences for once. ◈ This greatly reduces the training time as you assist the feature selector in picking the right features. ◈ So feature selector is trained in a semi-supervised approach. ◈ Using only one module per sequence makes it more efficient and simple state and action space.
to execute js you come out of the class attribute context and put a payload. ◈ A simple vector in the above scenario is "><img src=x onerror=alert()>. ◈ This is very trivial because of your exposure to HTML markup. ◈ If we can somehow impart the knowledge of html to an RL agent, it should be able to provide some simple XSS payloads.
just alphabets I gave all the html tags, attributes as actions. ◈ Based on the html parsing, html tags are made available only when the context is a tag name etc.. ◈ Similarly based on the html parsing attributes and their values are made available only when the context needs one of those.
its types. ◈ Ways to make machine identify inputs, understand application feedback. ◈ Reinforcement learning and its use cases. ◈ Ways to perform sequences using rl. ◈ Vulnerability detection with the help of reinforcement learning.
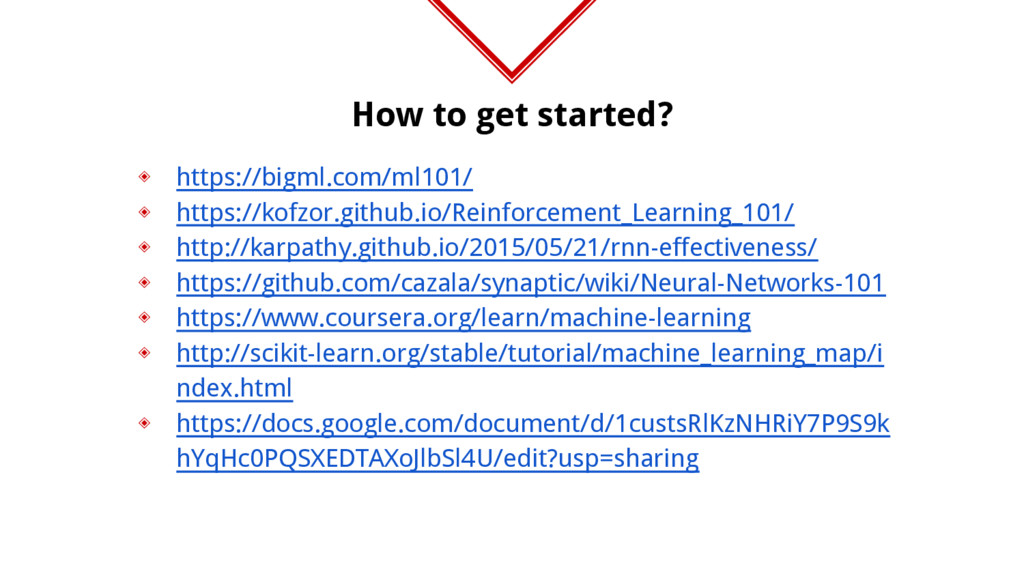
am aware of ◈ https://www.cloudsek.com/announcements/blog/cloud-ai-an-a rtificial-intelligence-on-the-cloud/ ◈ https://www.slideshare.net/babaroa/code-blue-2016-method- of-detecting-vulnerability-in-web-apps
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! And Questions? Email: [email protected] Twitter: @tunnelshade_ Blog: blog.tunneshade.in Github:](https://files.speakerdeck.com/presentations/8d5daf4a21b94c12b26a4ffa2c3bfc56/slide_95.jpg){kind=link}