Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
NLTK Intro for PUGS
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Victor Neo
March 27, 2012
Programming
600
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
NLTK Intro for PUGS
Slides for the NLTK talk given on March 2012 for Python User Group SG Meetup.
Victor Neo
March 27, 2012
More Decks by Victor Neo
See All by Victor Neo
Django - The Next Steps
victorneo
5
700
DevOps: Python tools to get started
victorneo
9
13k
Git and Python workshop
victorneo
2
820
Other Decks in Programming
See All in Programming
act1-costs.pdf
sumedhbala
0
230
Apache Hive: Toward a Cloud Native Lakehouse
okumin
0
130
SREは、MCPとSRE Agentをこう使え!
kazumax55
0
150
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
8
4.4k
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
260
アルゴリズムは何を圧縮しているのか ─ Haskell から育った「圧縮代数」というメンタルモデル
naoya
16
3.5k
LaravelLive Japan の裏方のすべて — 第188回 PHP勉強会@東京 (2026-06-24)
suguruooki
2
150
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
100
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.5k
20260623_Loop Engineeringで自分の分身の問い合わせBotを作る
ryugen04
0
220
地域 SRE コミュニティ最前線 - ホンマでっかSRE勉強会
tk3fftk
0
240
Terraform標準の組織で AWS CDKをどう使うか
mu7889yoon
0
280
Featured
See All Featured
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Responsive Adventures: Dirty Tricks From The Dark Corners of Front-End
smashingmag
254
22k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
28
3.6k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Designing Powerful Visuals for Engaging Learning
tmiket
1
450
Art, The Web, and Tiny UX
lynnandtonic
304
22k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
2
1.5k
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Neural Spatial Audio Processing for Sound Field Analysis and Control
skoyamalab
0
370
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
530
Jamie Indigo - Trashchat’s Guide to Black Boxes: Technical SEO Tactics for LLMs
techseoconnect
PRO
0
370
Transcript
Natural Language Toolkit @victorneo
Natural Language Processing
"the process of a computer extracting meaningful information from natural
language input and/or producing natural language output"
None
Getting started with NLTK
Open source Python modules, linguistic data and documentation for research
and development in natural language processing and text analytics, with distributions for Windows, Mac OSX and Linux. NLTK
None
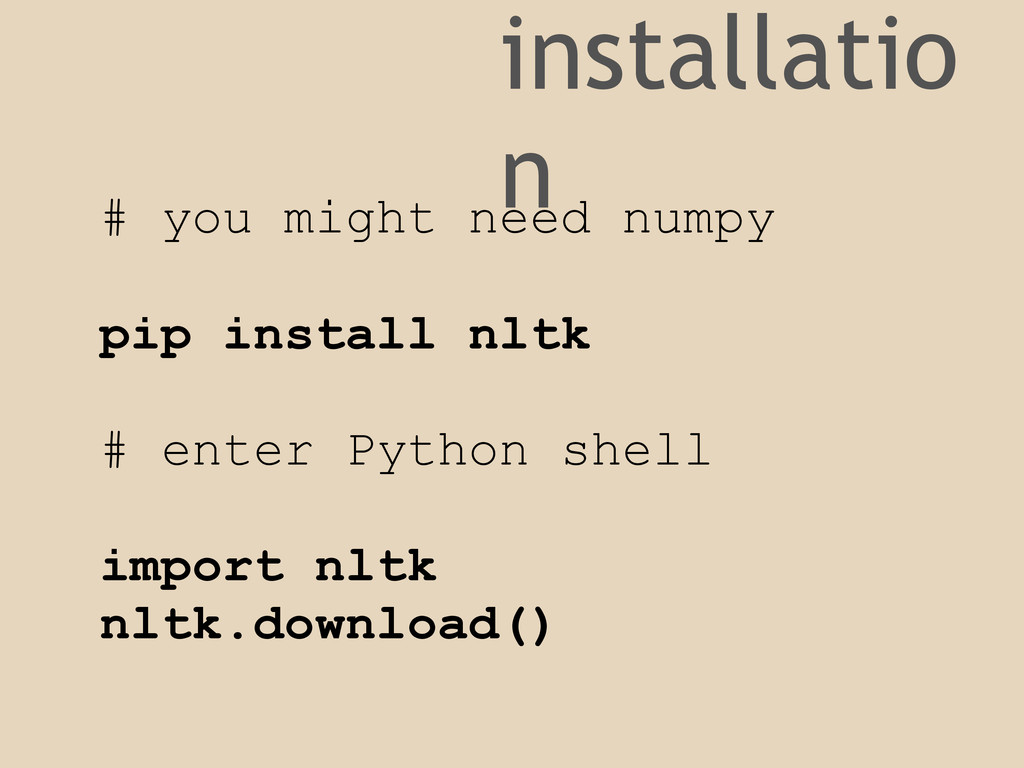
installatio n # you might need numpy pip install nltk
# enter Python shell import nltk nltk.download()
None
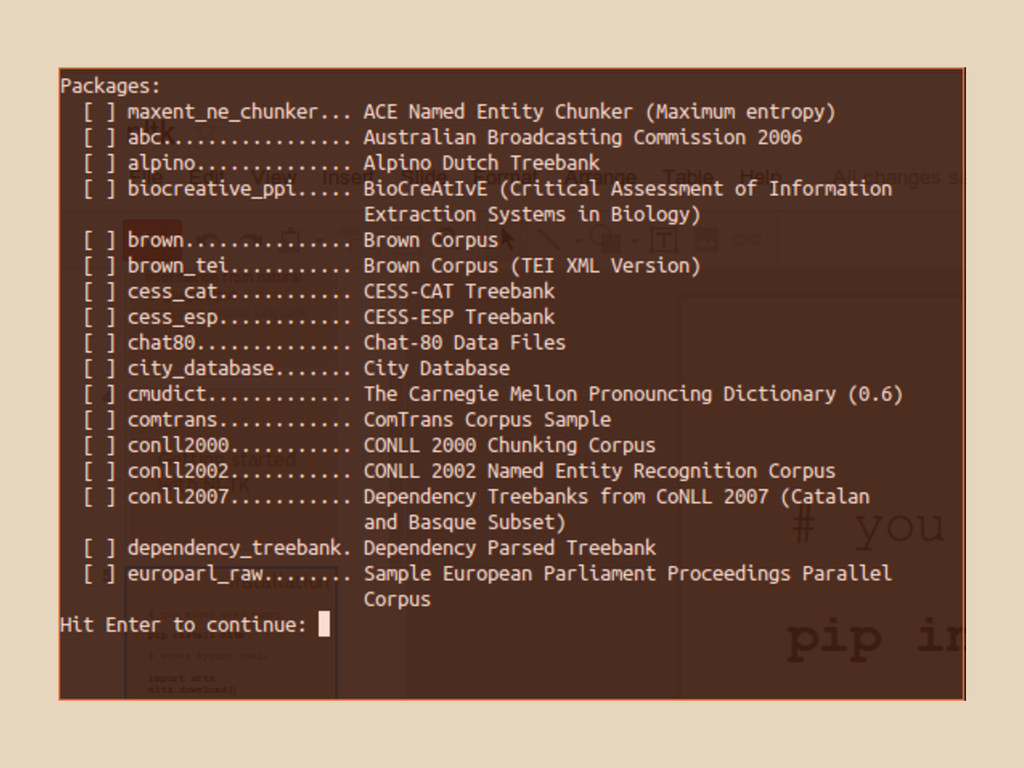
packages # For Part of Speech tagging maxent_treebank_pos_tagger # Get
a list of stopwords stopwords # Brown corpus to play around brown
Preparing data / corpus
tokens NLTK works on Tokens, for example, "Hello World!" will
be tokenized to: ['Hello', 'World', '!'] The built-in tokenizer for most use cases: nltk.word_tokenize("Hello World!")
text processing HTML text: raw = nltk.clean_html(html_text) tokens = nltk.word_tokenize(raw)
text = nltk.Text(tokens) Use BeautifulSoup for preprocessing of the HTML text to discard unnecessary data.
Part-of-speech tagging
pos tagging text = "Run away!" nltk.word_tokenize(text) nltk.pos_tag(tokens) [('Run', 'NNP'),
('away', 'RB'), ('!', '.')]
pos tagging [('Run', 'NNP'), ('away', 'RB'), ('!', '.')] NNP: Proper
Noun, Singular RB : Adverb http://www.ling.upenn.edu/courses/Fall_2003/ling001/penn_treebank_pos. html
pos tagging "The sailor dogs the barmaid." [('The', 'DT'), ('sailor',
'NN'), ('dogs', 'NNS'), ('the', 'DT'), ('barmaid', 'NN'), ('.', '.')]
Sentiment Analysis Code: http://bit.ly/GLu2Q9
Differentiate between "happy" and "sad" tweets. Teach the classifier the
"features" of happy & sad tweets and test how good it is.
Happy: "Looking through old pics and realizing everything happens for
a reason. So happy with where I am right now" Sad: "So sad I have 8 AM class tomorrow"
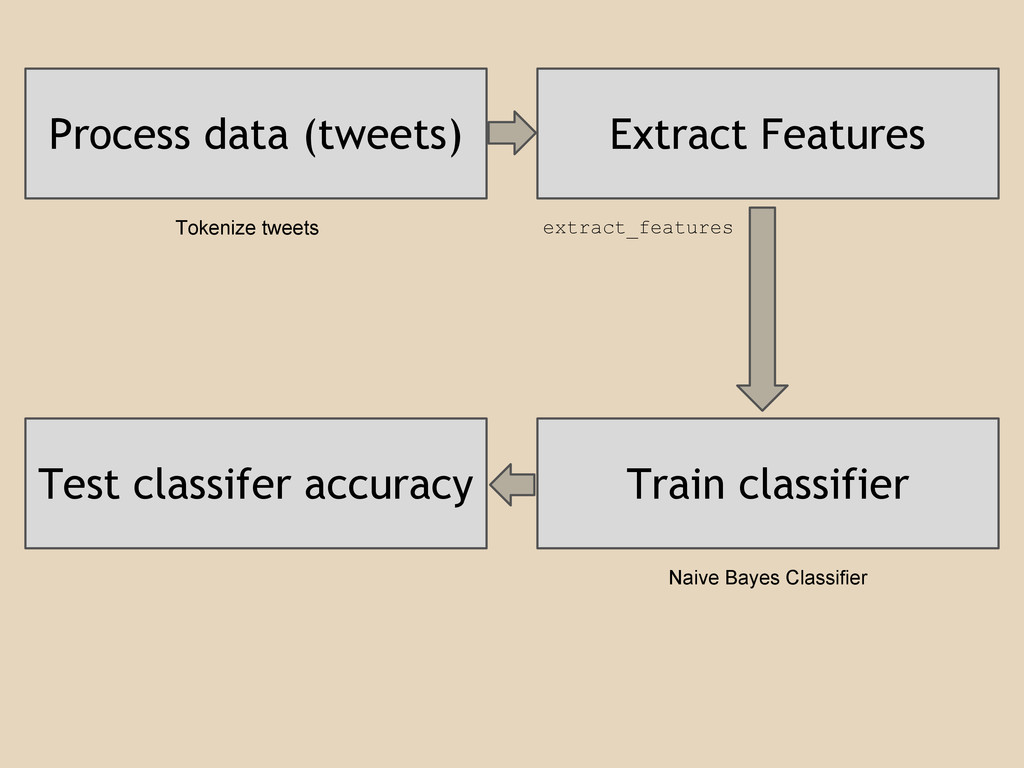
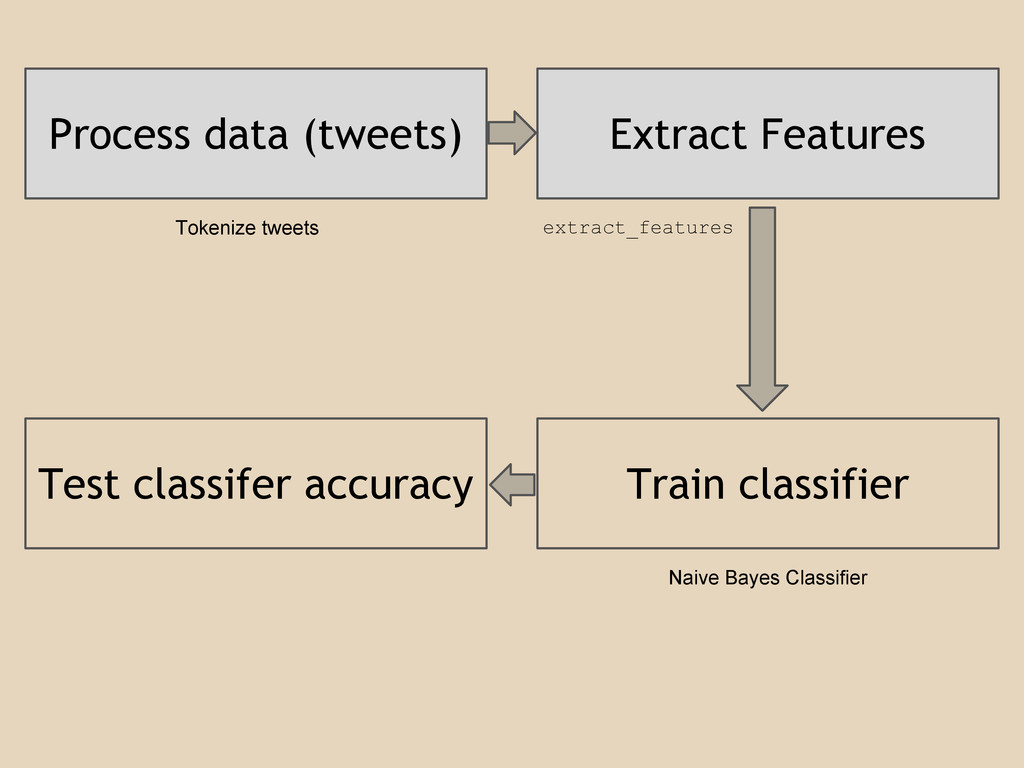
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
happy.txt sad.txt happy_test.txt sad_test.txt } training data } testing data
Tweets obtained from Twitter Search API
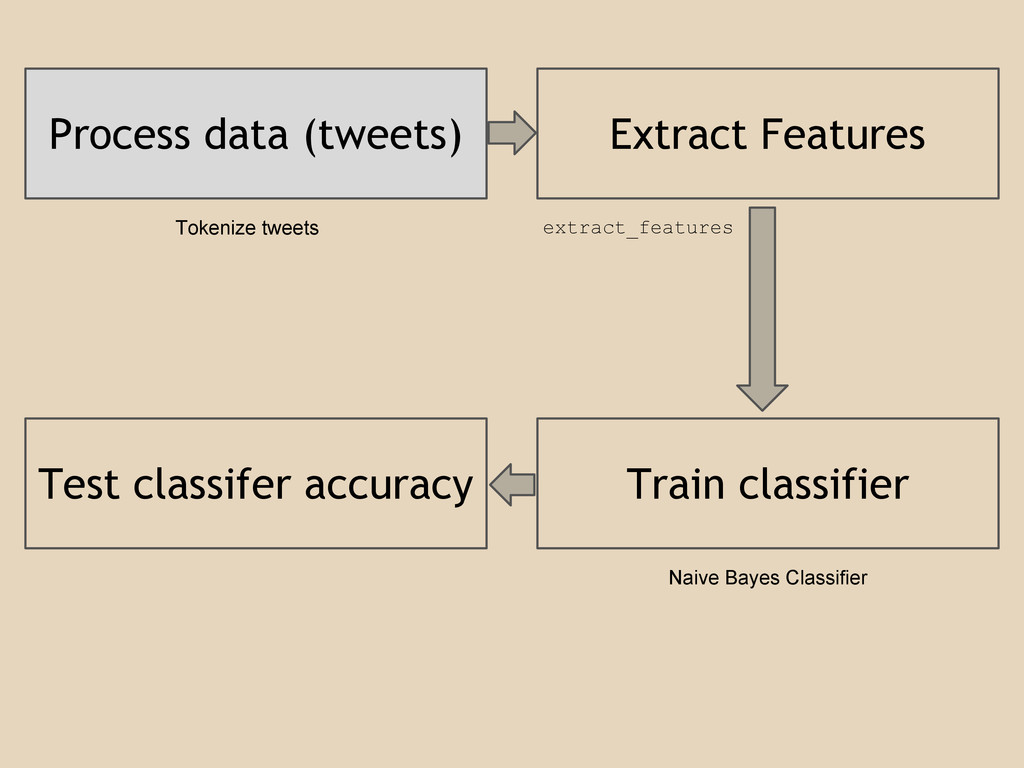
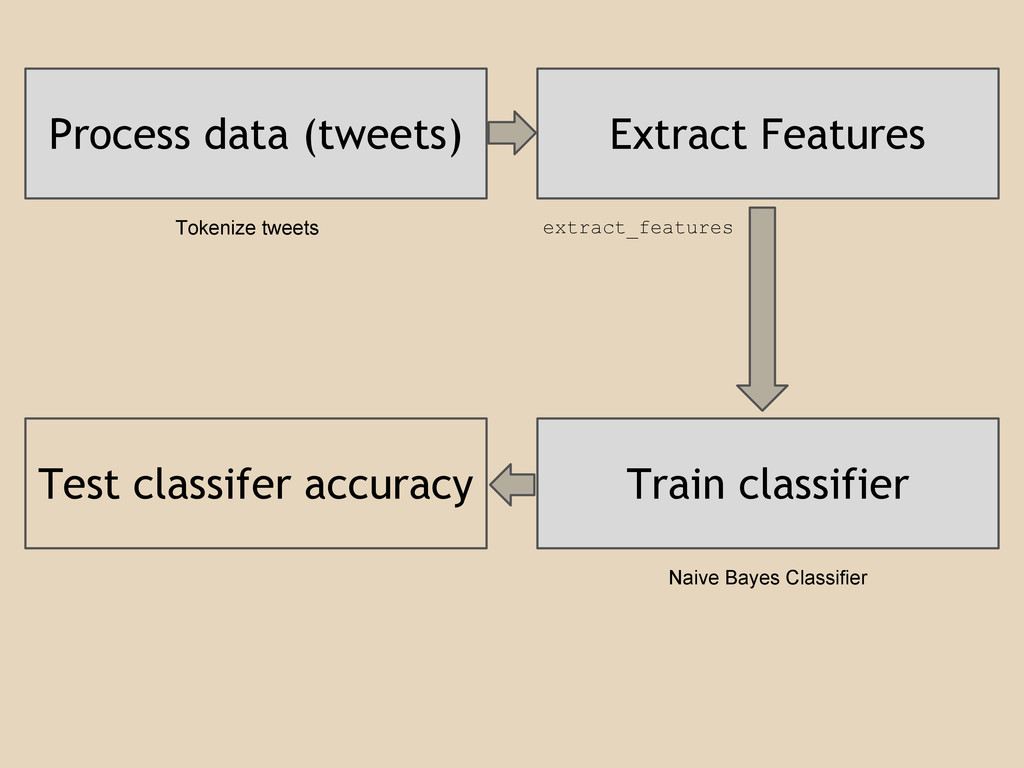
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
Happy tweets usually contain the following words: "am happy", "great
day" etc. Sad tweets usually contain the following: "not happy", "am sad" etc. features
{'contains(not)': False, 'contains(view)': False, 'contains(best)': False, 'contains(excited)': False, 'contains(morning)': False,
'contains(about)': False, 'contains(horrible)': True, 'contains(like)': False, ... } output of extract_features()
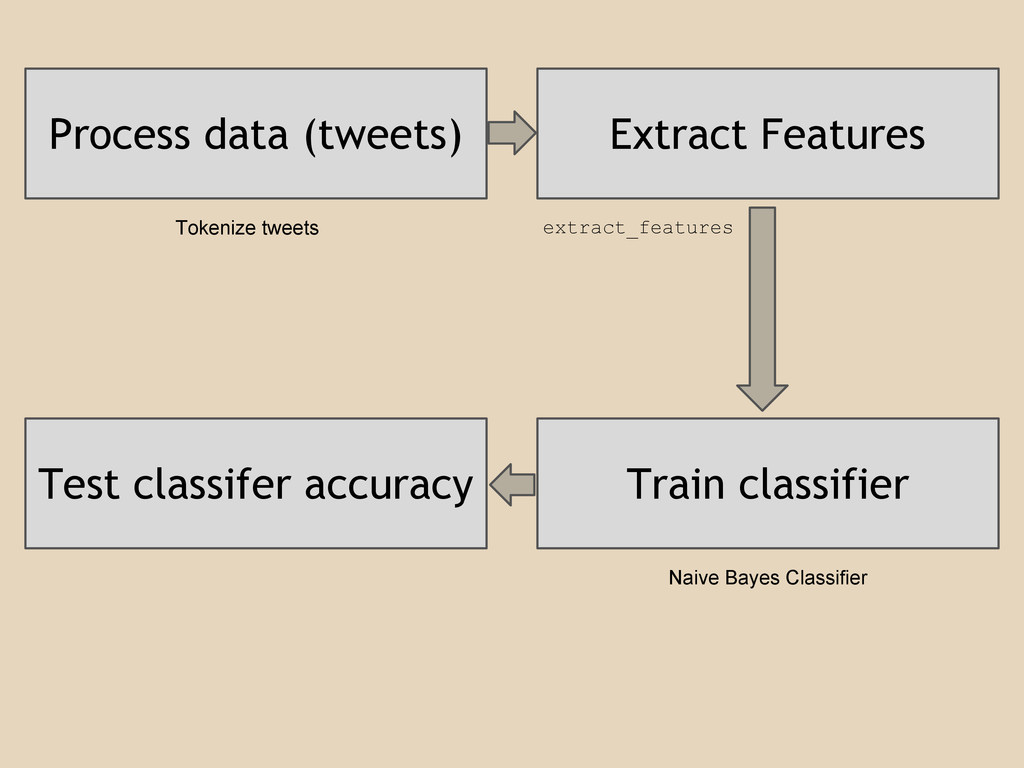
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
training_set = \ nltk.classify.util.\ apply_features(extract_features, tweets) classifier = \ NaiveBayesClassifier.train
(training_set) training the classifer training classifer
Process data (tweets) Extract Features Train classifier Test classifer accuracy
Tokenize tweets extract_features Naive Bayes Classifier
def classify_tweet(tweet): return \ classifier.classify(extract_features (tweet)) testing classifer
$ python classification.py Total accuracy: 90.00% (18/20) 18 tweets got
classified correctly.
Where to go from here.
http://www.nltk.org/book
https://class.coursera.org/nlp/auth/welcome
http://www.slideshare.net/shanbady/nltk-boston-text-analytics
[('Thank', 'NNP'), ('you', 'PRP'), ('.', '.')] @victorneo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![pos tagging [('Run', 'NNP'), ('away', 'RB'), ('!', '.')] NNP: Proper](https://files.speakerdeck.com/presentations/4f71dcc0a1d1bd00220233b1/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[('Thank', 'NNP'), ('you', 'PRP'), ('.', '.')] @victorneo](https://files.speakerdeck.com/presentations/4f71dcc0a1d1bd00220233b1/slide_35.jpg){kind=link}