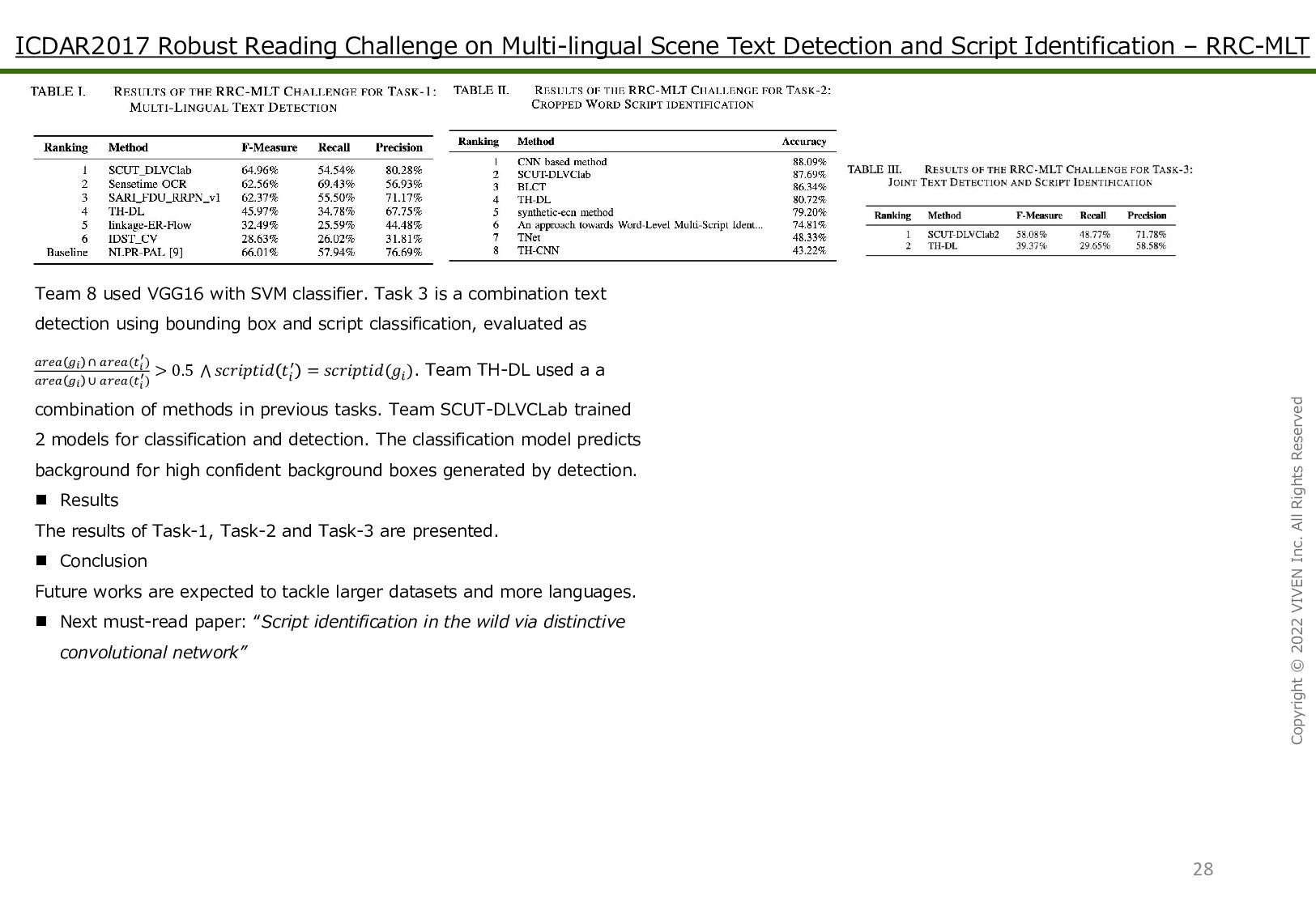
and Script Identification – RRC-MLT Copyright © 2022 VIVEN Inc. All Rights Reserved Summary RRC-MLT challenge has tasks like text detection, script classification and all tasks for necessary for multilingual text recognition. The dataset contains 18K images having text from 9 different languages. Proposed Methodology The dataset contains natural images with embedded text such as street signs, advertisement boards, shop names, passing vehicles, images from internet search. The dataset contains at least 2K images from Arabic, Bangla, Chinese, English, French, German, Italian, Japanese and Korean. Text containing special character also from multiple languages are available. Task 1 is text detection for which 9K images were for training and remaining 9K for testing. For a set of don’t care regions D = {d1, d2, …dk }, ground truth regions G = {g1, g2,…gm} and predictions T = {t1,t 2, …tn}. The predictions are matched as area(dk ) = 0 area(dk) area(tk ) area(dk) > 0.5 against don’t care regions to discard noise. The filtered predictions T’ are considered positive if area(gi ) area(t’ j ) area(gi ) ∪ area(t’ j ) > 0.5 . The set of positive matches(M) are used to calculate F-score for𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 = |𝑀| |𝑇′| and 𝑟𝑒𝑐𝑎𝑙𝑙 = |𝑀| |𝐺| thus 𝐹 − 𝑠𝑐𝑜𝑟𝑒 = 2 ∗𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 ∗𝑟𝑒𝑐𝑎𝑙𝑙 𝑝𝑟𝑒𝑐𝑖𝑠𝑖𝑜𝑛 +𝑟𝑒𝑐𝑎𝑙𝑙 . Team SCUT-DLVC lab used one model for rough detection followed by another for finely adjusting bounding box and postprocessing. CAS and Fudan university designed rotation region proposal network for inclined region proposals with angle information which is used for bounding box regression. This is followed by text region classifier. Sensetime group proposed an FCN based model with with deformable convolution which predicts whether a pixel is a text or not along with location if it is in a text box. TH-DL group used an FCN with residual connection to predict whether a pixel belongs to text, followed by binarizing at multiple thresholds. The connected components thus extracted along with their bounding boxes are used as region proposals. The features of region proposals after Rotation ROI pooling are fed to Fast R-CNN and non-max suppression for results. Linkage group extracted external regions from each channel followed by calculating linkage between components and pruning to get non-overlapping components, candidate lines are extracted and merged. Alibaba group used a CNN to detect text regions and predict their relation which are then grouped and used by a CNN+RNN to divide into words. For script identification 84K and 97K images were used for training andtesting respectively, with text Arabic, Bangla, Chinese, Japanese, Korean, Latin and Symbols. SCUT-DLVC labs used CNN with random crop for training and sliding windows for test images. Team CNN-based method used VGG16 initialized with ImageNet weights and cross-entropy loss with training images resized to fixed height and variable width for training. TNet enhanced the features of dataset followed by deep network for training and majority vote for classification. Team BLCT extracted patches of variable sizes to train a 6-layer CNN model. Features from penultimate layer are randomly combined, these are used to create bag-of-visual words of 1024 codewords which are used as image representations which are aggregated to form histogram which in turn is used by a 2 dense and 1 dropout layer for classification. Team Th-DL, TH-CNN used GoogLeNet like structure, while Synthetic-ECN used an ECN based structure.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}