geometries Euclidean distance d2 (p, q) = i (pi − qi )2 (Pythagoras’ theorem circa 500 BC) Minkowski distance (Lk -norm) dk (p, q) = k i |pi − qi |k (H. Minkowski 1864-1909) Manhattan distance d1 (p, q) = i |pi − qi | (city block-taxi cab) Mahalanobis metric (1936) dΣ = (p − q)T Σ−1(p − q) Quadratic distance dQ = (p − q)T Q(p − q) Riemannian metric tensor gij dxi ds dxj ds ds (B. Riemann 1826-1866,) Physics entropy JK−1 −k p log pdµ (Boltzmann-Gibbs 1878) Information entropy H(p) = − p log pdµ (C. Shannon 1948) Fisher information (local entropy) I(θ) = E[ ∂ ∂θ ln p(X|θ) 2 ] (R. A. Fisher 1890-1962) Kullback-Leibler divergence KL(p||q) = p log p q dµ = Ep [log P Q ] (relative entropy, 1951) R´ enyi divergence (1961) Hα = 1 α(1−α) log fαdµ Rα (p|q) = 1 α(α−1) ln pαq1−αdµ (additive entropy) Tsallis entropy (1998) (Non-additive entropy) Tα (p) = 1 1−α ( pαdµ − 1) Tα (p||q) = 1 1−α (1 − pα qα−1 dµ) Bregman divergences (1967): BF (θ1 ||θ2 ) = F(θ1 ) − F(θ2 ) − (θ1 − θ2 )⊤∇F(θ2 ) Bregman-Csisz´ ar divergence (1991) Fα(x) = x − log x − 1 α = 0 x log x − x + 1 α = 1 1 α(1−α) (−xα + αx − α + 1) 0 < α < 1 Csisz´ ar’ f-divergence Df (p||q) = pf(q p )dµ (Ali& Silvey 1966, Csisz´ ar 1967) Amari α-divergence (1985) fα(x) = x log x α = 1 − log x α = −1 4 1−α2 (1 − x 1+α 2 ) −1 < α < 1 Quantum entropy S(ρ) = −kTr(ρ log ρ) (Von Neumann 1927) Kolmogorov K(p||q) = |q − p|dµ (Kolmogorov-Smirnoff max |p − q|) Hellinger H(p||q) = ( √ p − √ q)2 = 2(1 − √ fg Chernoff divergence (1952) Cα (p||q) = − ln pαq1−αdµ C(p, q) = maxα∈(0,1) Cα (p||q) χ2 test χ2(p||q) = (q−p)2 p dµ (K. Pearson, 1857-1936 ) Matsushita distance (1956) Mα (p, q) = α |q 1 α − p 1 α |dµ Bhattacharya distance (1967) d(p, q) = − log √ p √ qdµ Non-additive entropy cross-entropy conditional entropy mutual information (chain rules) Additive entropy Non-Euclidean geometries Statistical geometry Jeffrey divergence (Jensen-Shannon) H(p) = KL(p||u) Earth mover distance (EMD 1998) ×α(1 − α) α = −1 α = 0 Generalized Pythagoras’ theorem (Generalized projection) I-projection Quantum & matrix geometry Log Det divergence D(P||Q) =< P, Q−1 > − log det PQ−1 − dimP Von Neumann divergence D(P||Q) = Tr(P(log P − log Q) − P + Q) Itakura-Saito divergence IS(p|q) = i (pi qi − log pi qi − 1) (Burg entropy) Kullback-Leibler ∇∗ Hamming distance (|{i : pi ̸= qi }|) Neyman Dual div. (Legendre) DF ∗ (∇F(θ1 )||∇F(θ2 )) = DF (θ2 ||θ1 ) Generalized f-means duality... Dual div.∗-conjugate (f∗(y) = yf(1/y)) Df∗ (p||q) = Df (q||p) Burbea-Rao or Jensen (incl. Jensen-Shannon) JF (p; q) = f(p)+f(q) 2 − f p+q 2 Integral probability metrics IPMs Wasserstein distances Wα,ρ (p, q) = (infγ∈Γ(p,q) ρ(p, q)αdγ(x, y)) 1 α ρ = L1 L´ evy-Prokhorov distance LPρ (p, q) = infϵ>0 {p(A) ≤ q(Aϵ) + ϵ∀A ∈ B(X)} Aϵ = {y ∈ X, ∃x ∈ A : ρ(x, y) < ϵ} Finsler metric tensor gij = 1 2 ∂2 F 2(x,y) ∂yi∂yj Sharma-Mittal entropies hα,β (p) = 1 1−β pαdµ 1−β 1−α − 1 β = 1 β → α Fisher-Rao distance: ds2 = gij dθidθj = dθ⊤I(θ)dθ ρF R (p, q) = minγ 1 0 ˙ γ(t)I(θ) ˙ γ(t)dt Haussdorf set distance dH (X, Y ) = max{supx ρ(x, Y ), supy ρ(X, y)} Gromov-Haussdorf distance Sinkhorn divergence (h-regularized OT) (between compact metric spaces) dGH (X, Y ) = infϕX :X→Z,ϕY :Y →Z {ρZ H (ϕX (X), ϕY (Y ))} ϕX , ϕY : isometric embeddings MMD Maximum Mean Discrepancy Stein discrepancies ©2023 Frank Nielsen Optimal transport geometry Logarithmic divergence LG,α (θ1 : θ2 ) = 1 α log 1 + α∇G(θ2 )⊤(θ1 − θ2 ) +G(θ2 )−G(θ1 ) α → 0, F = −G Affine differential geometry Riemannian geometry Hyperbolic/spherical geometry Bolyai (1802-1860) Lobachevsky (1792-1856) Aitchison distance Probability simplex Hilbert log-ratio metric Quantum f-divergences (D´ enes Petz) Fr¨ obenius & Hilbert-Schmidt norm J. Jensen F. Itakura B. De Finetti G. Monge L. Kantorovich M. Nagumo Pearson K. Nomizu L. LeCam Vajda M. Fr´ echet J.M. Souriau J.L. Koszul Symplectic geometry Cone geometry E. Vinberg Bhat. Conformal geometry Conformal divergence Dρ (p : q) = ρ(p)D(p : q) conformal Riemannian metric gp hi = eϕg Dually flat space Constant sectional curvature Hessian manifolds H. Shima ∇ Lev M. Bregman C. R. Rao B. Riemann Euclid Pythagoras Pal & Wong 2016 4
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
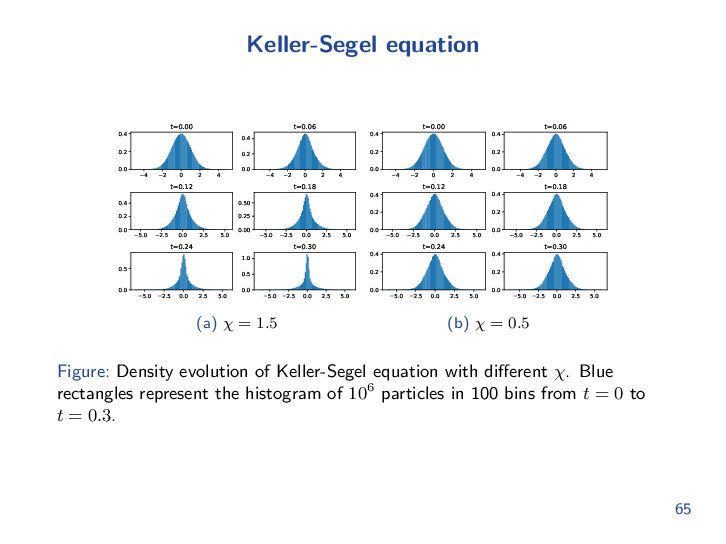{kind=link}
{kind=link}
{kind=link}