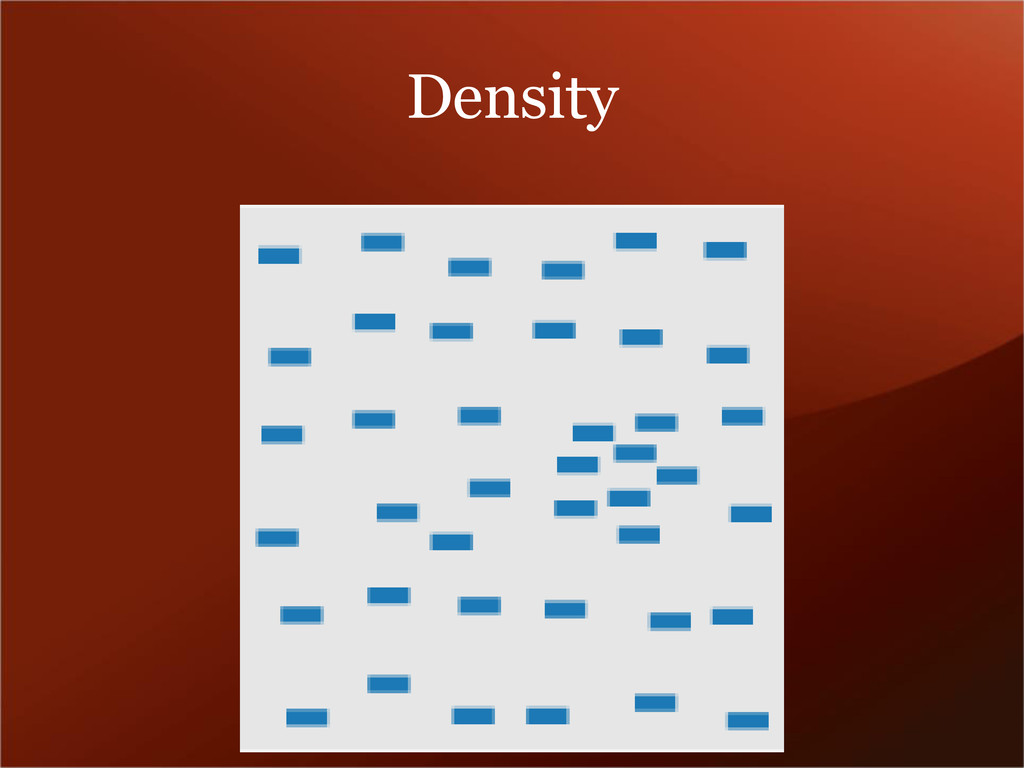
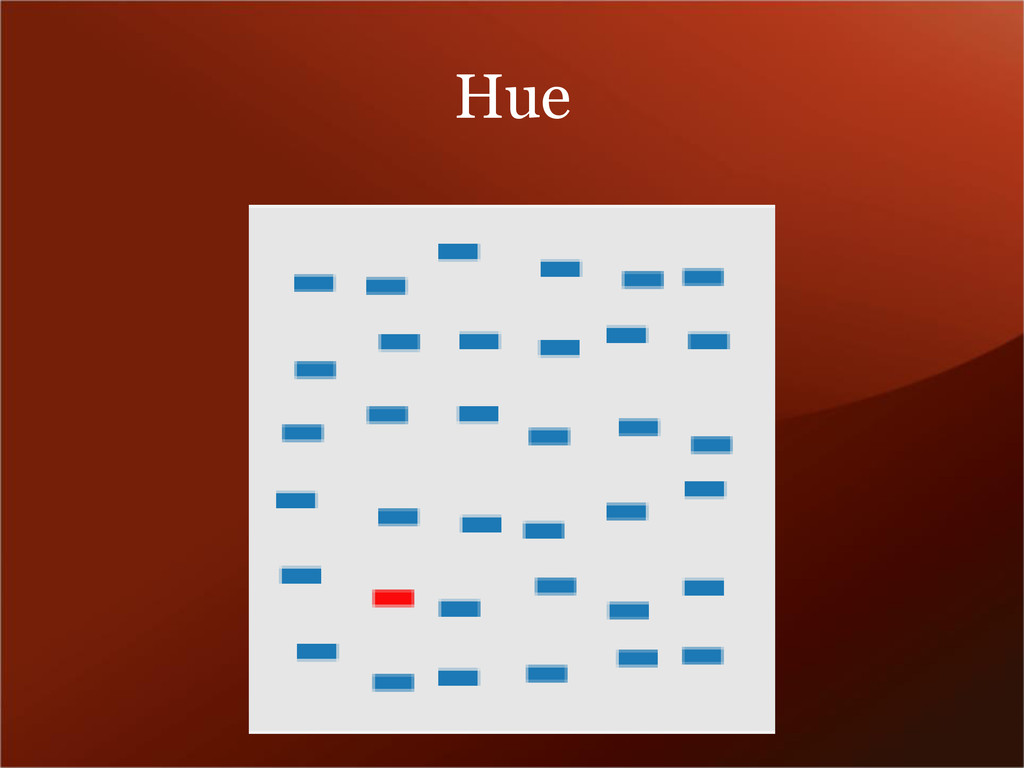
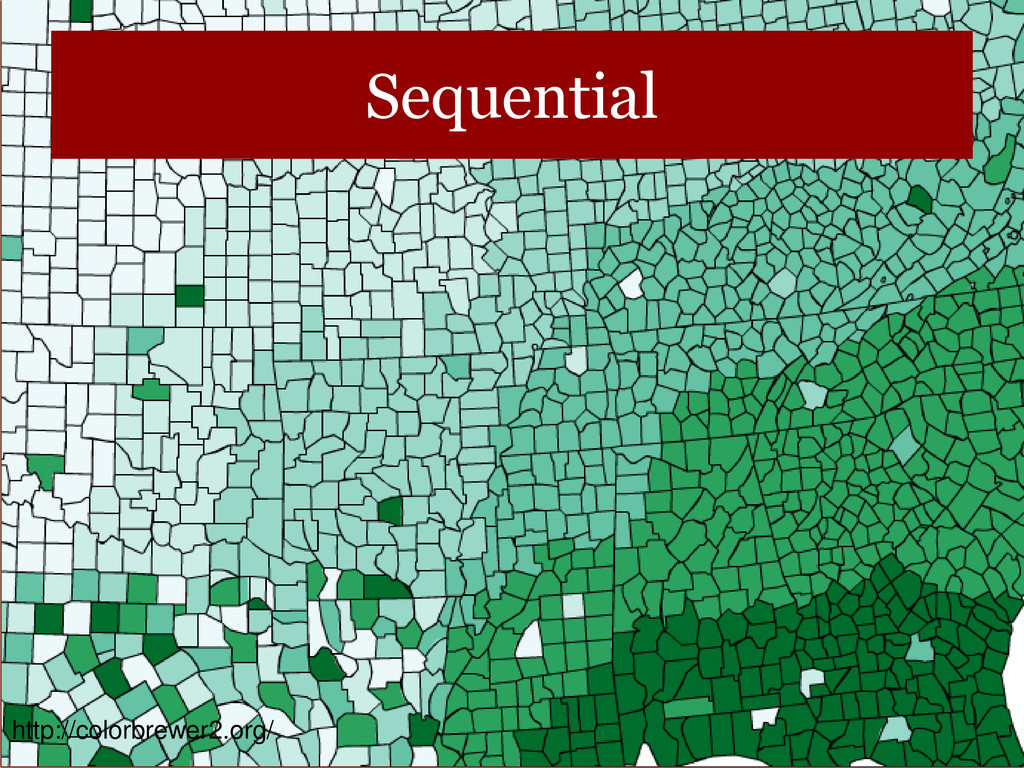
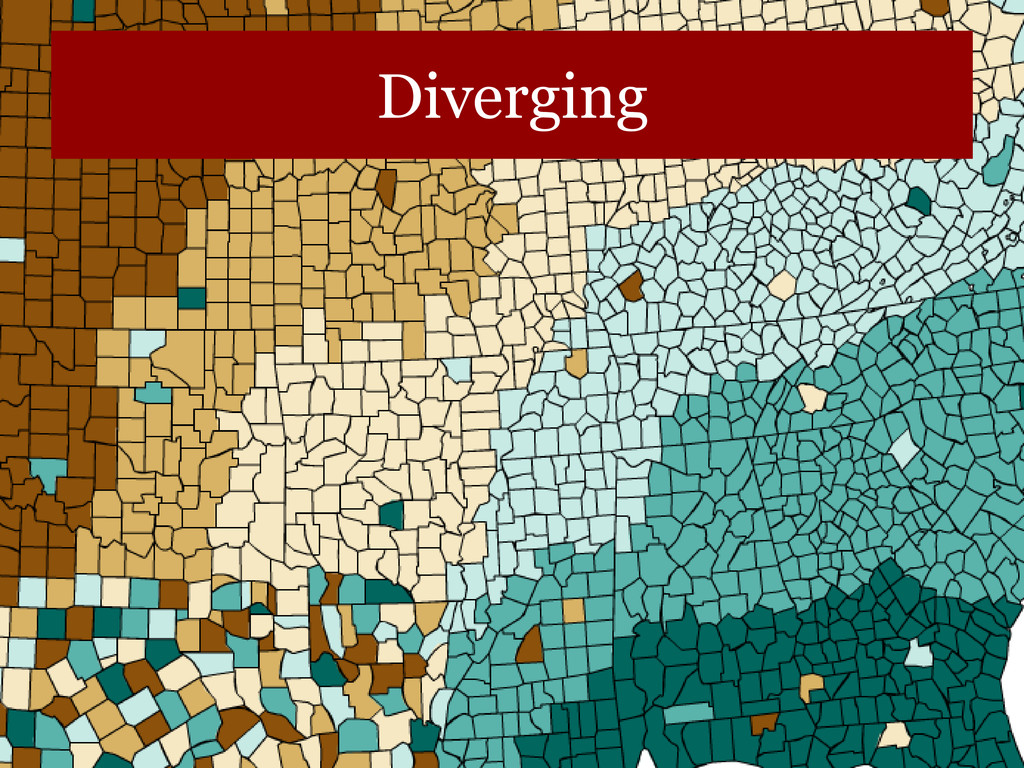
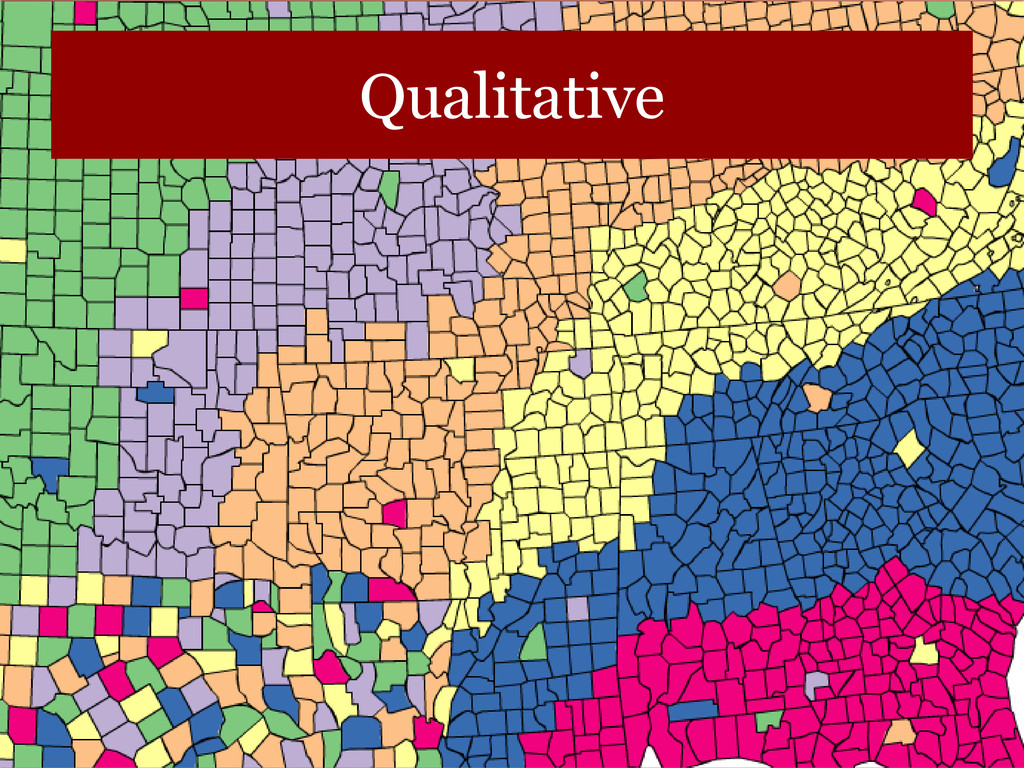
data that progress from low to high. Use light colors for low values and dark colors for higher. • Diverging – uses hue to show the breakpoint and intensity to show divergent extremes. • Qualitative – uses different colors to represent different categories. Beware of using hue/saturation to highlight unimportant categories.
• ~8% of men are red-green colorblind • Diverging schemes don’t do well when printed or photocopied • Colors will often render differently on different screens, especially low-end LCD screens • http://colorbrewer2.org
packages for any kind of analysis • Saves time repeating data processing steps • Allows working with more diverse types of data and much larger datasets than Excel • Processing is much faster than Excel • Scripts are easily shareable, promoting reproducible work
ways • vectors (1,2,3,4) but not (1,2,3,x,y,z) • lists – can hold heterogeneous data – 1 – 2 – a • x • arrays – multi-dimensional • dataframes – lists of vectors - like spreadsheets
graphics” in R • a set of graph types and a way of mapping variables to graph features • graph types are called “geoms” • mappings are “aesthetics” • graphs are built up by layering geoms
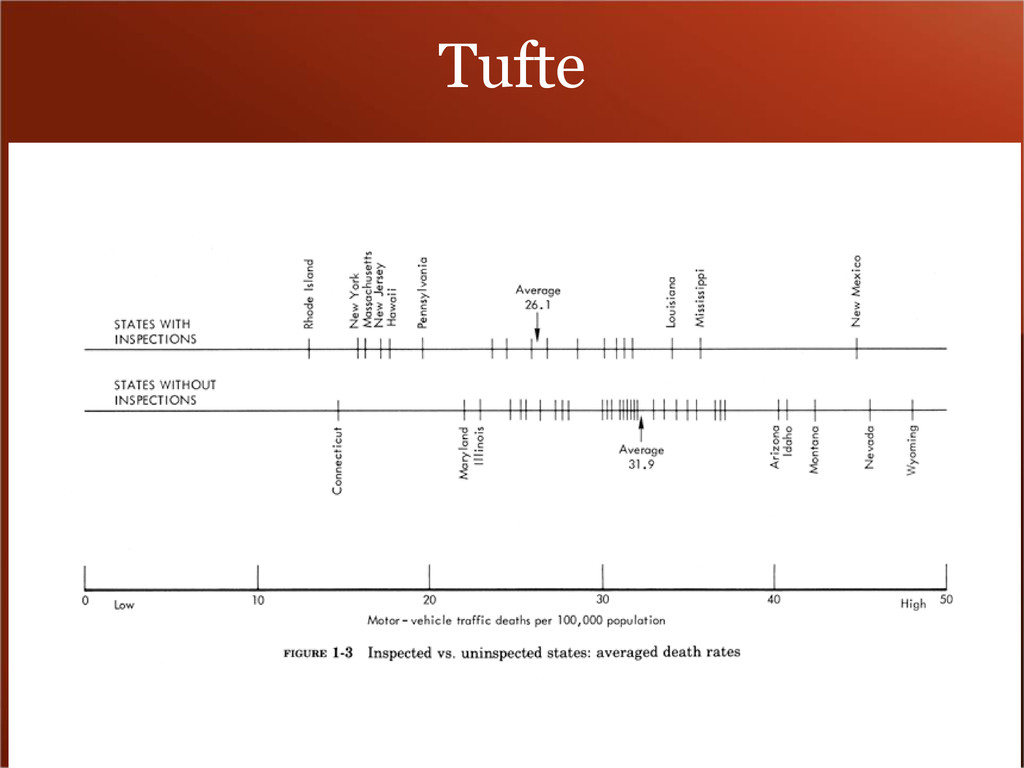
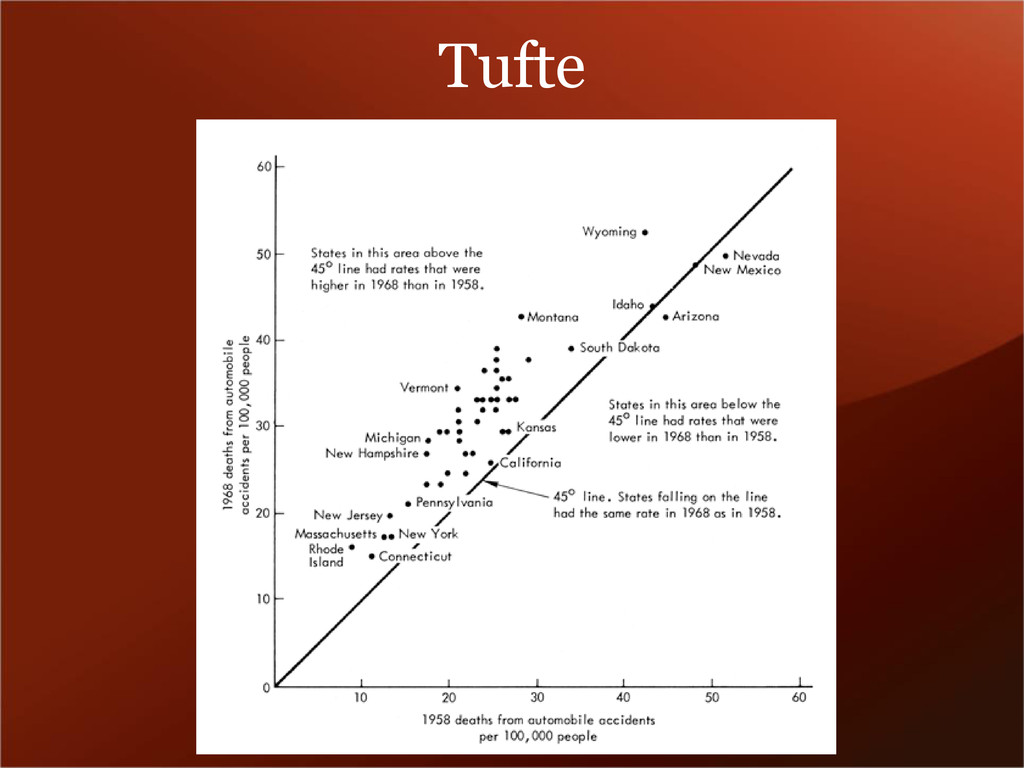
coords of points • abline – line layer – takes slope, intercept • line – connect points with a line • smooth – fit a curve • bar – aka histogram – takes vector of data • boxplot – box and whiskers • density – to show relative distributions • errorbar – what it says on the tin
{kind=link}
{kind=link}
{kind=link}
{kind=link}
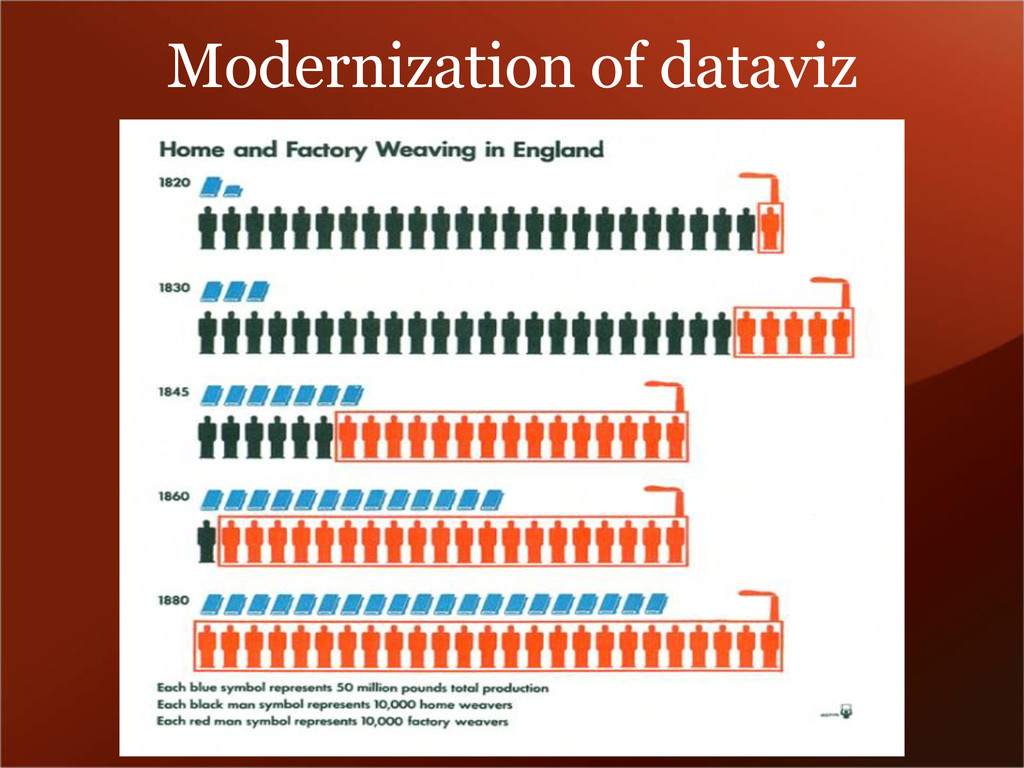{kind=link}
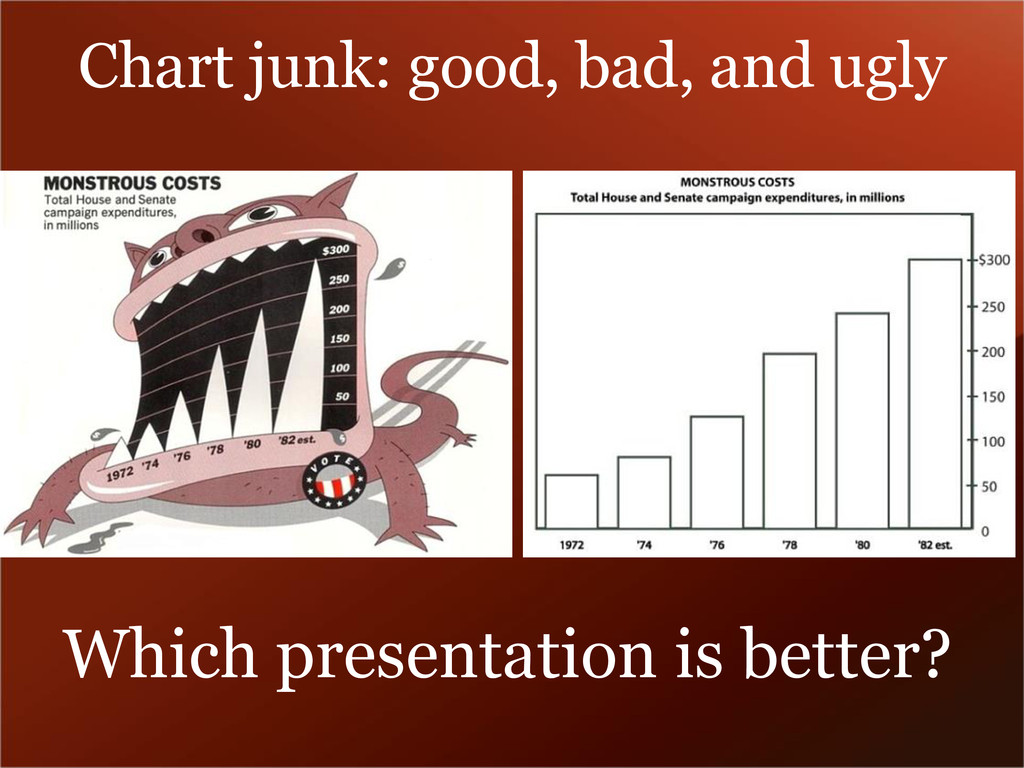{kind=link}
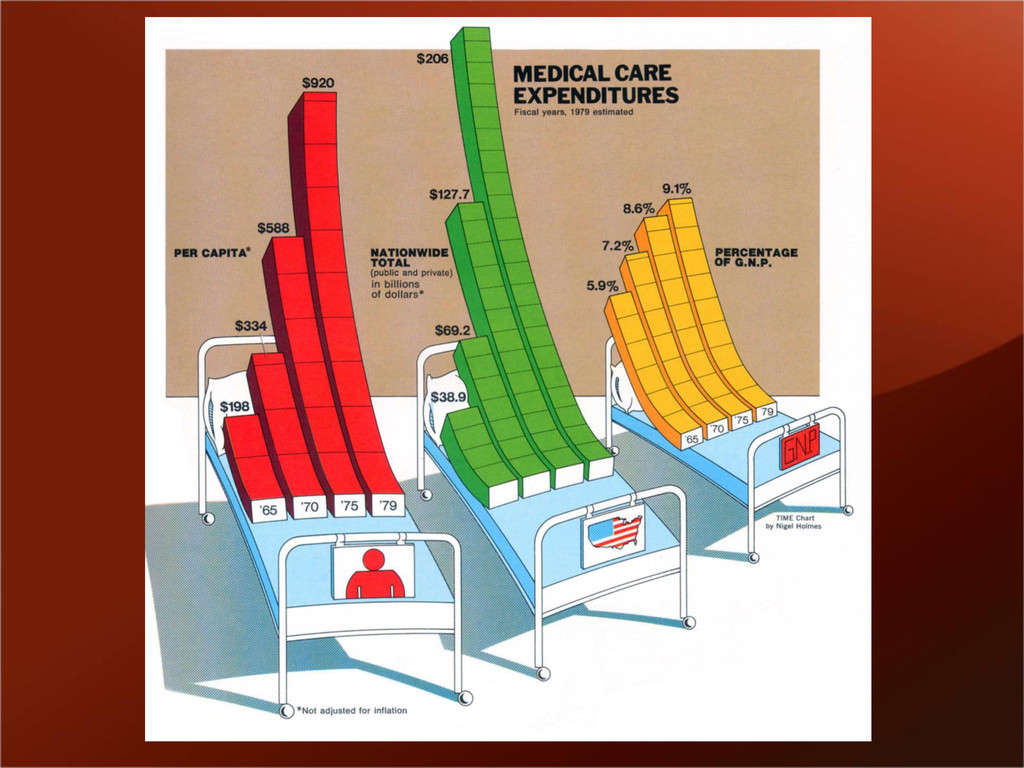{kind=link}
{kind=link}
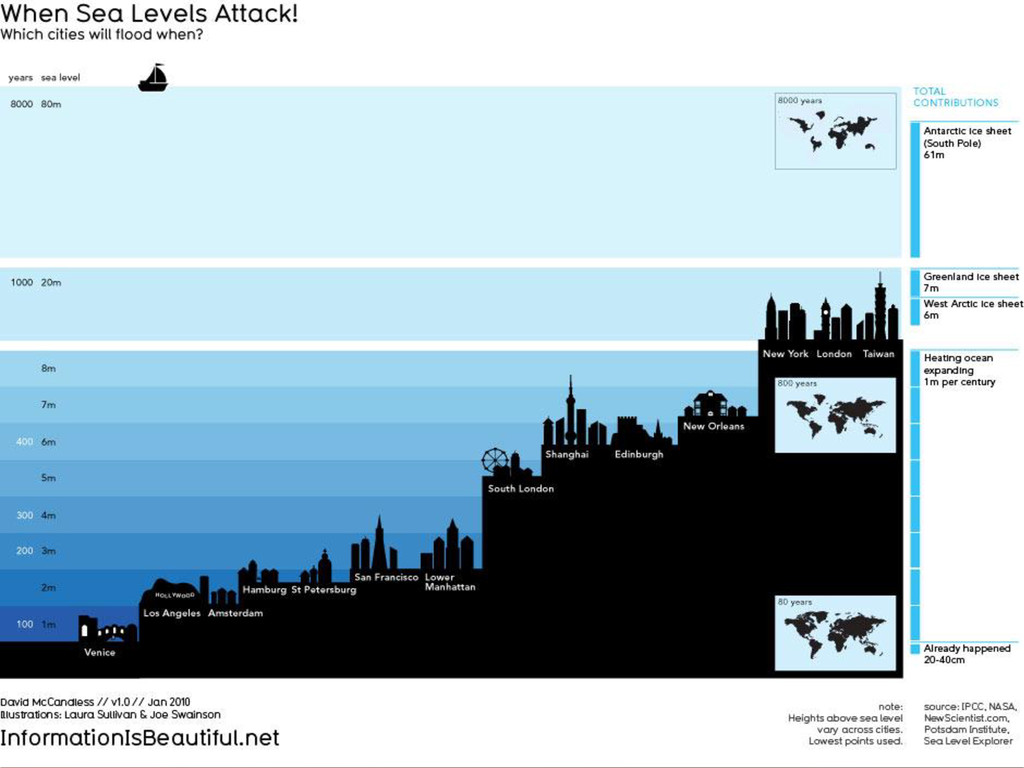{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
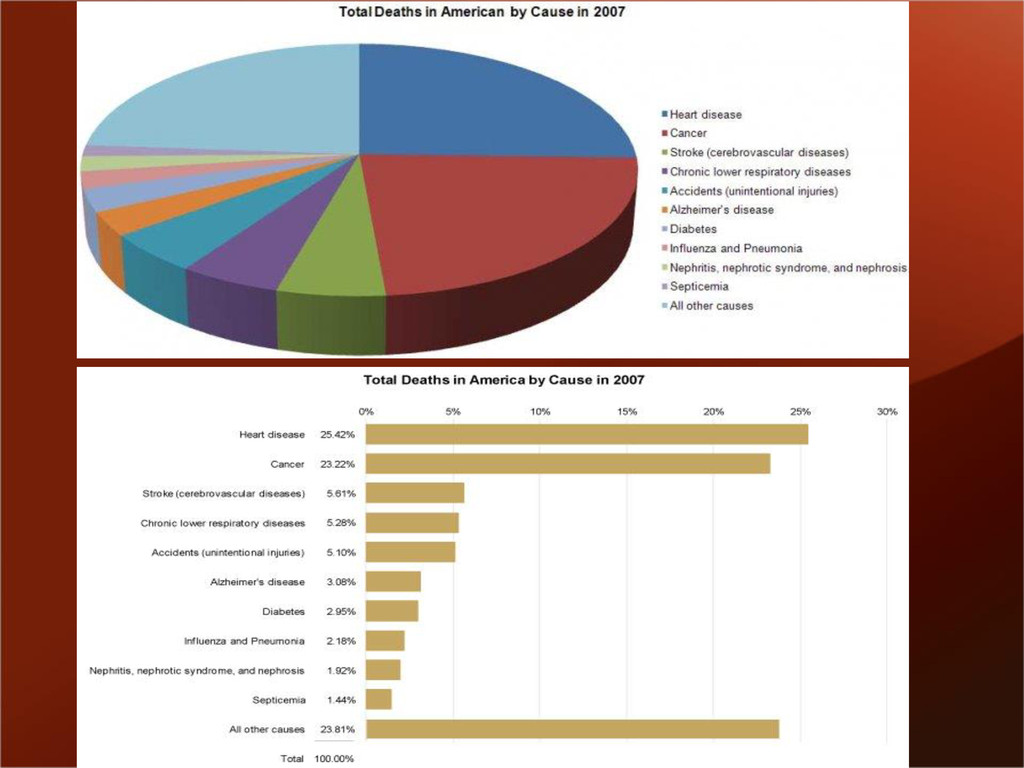{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![data structures • x<-c(1,2,3,4,5,6,7,8,9,10) • x • length(x) • x[1]](https://files.speakerdeck.com/presentations/e5a281b0e0370130ec7c72aeeb5d2bba/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}