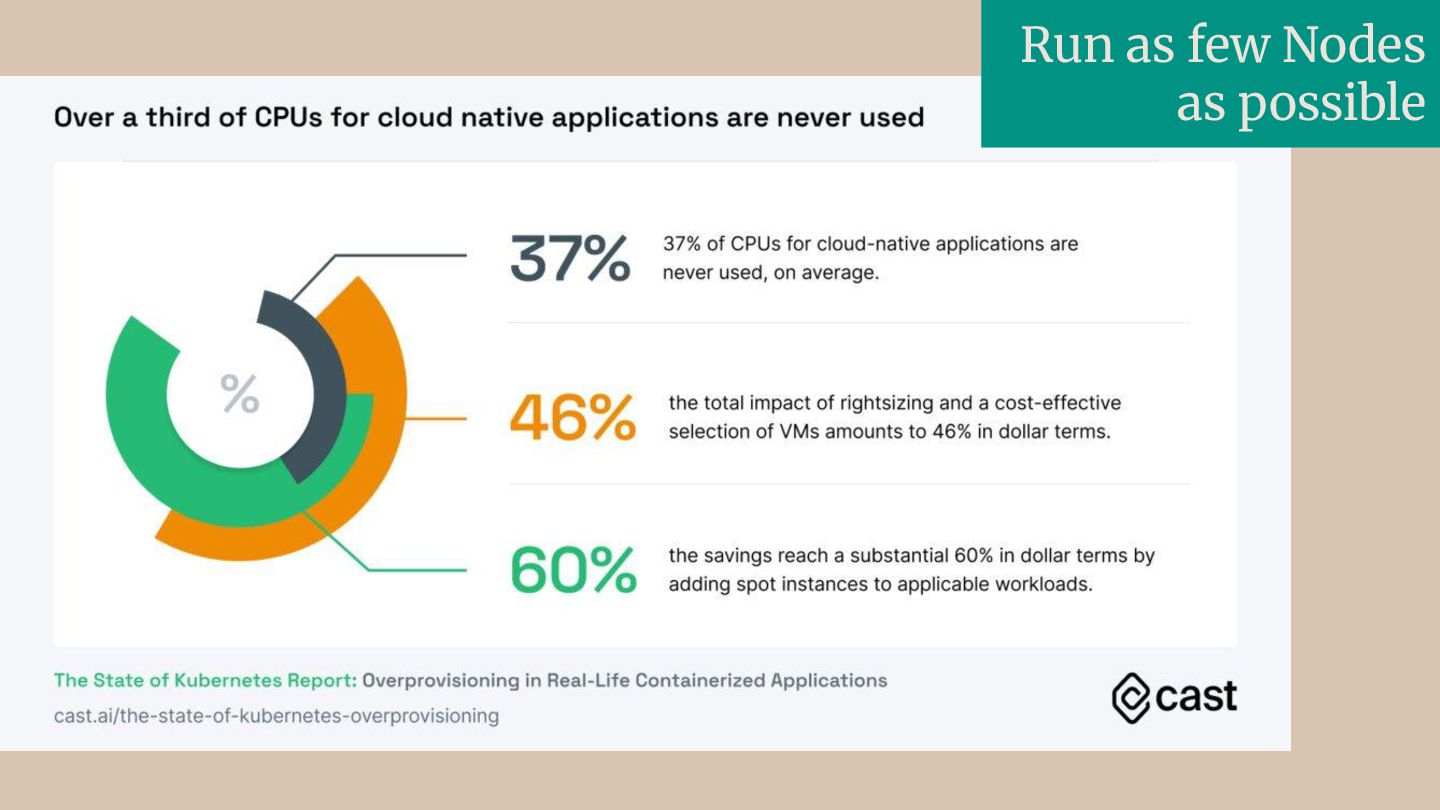
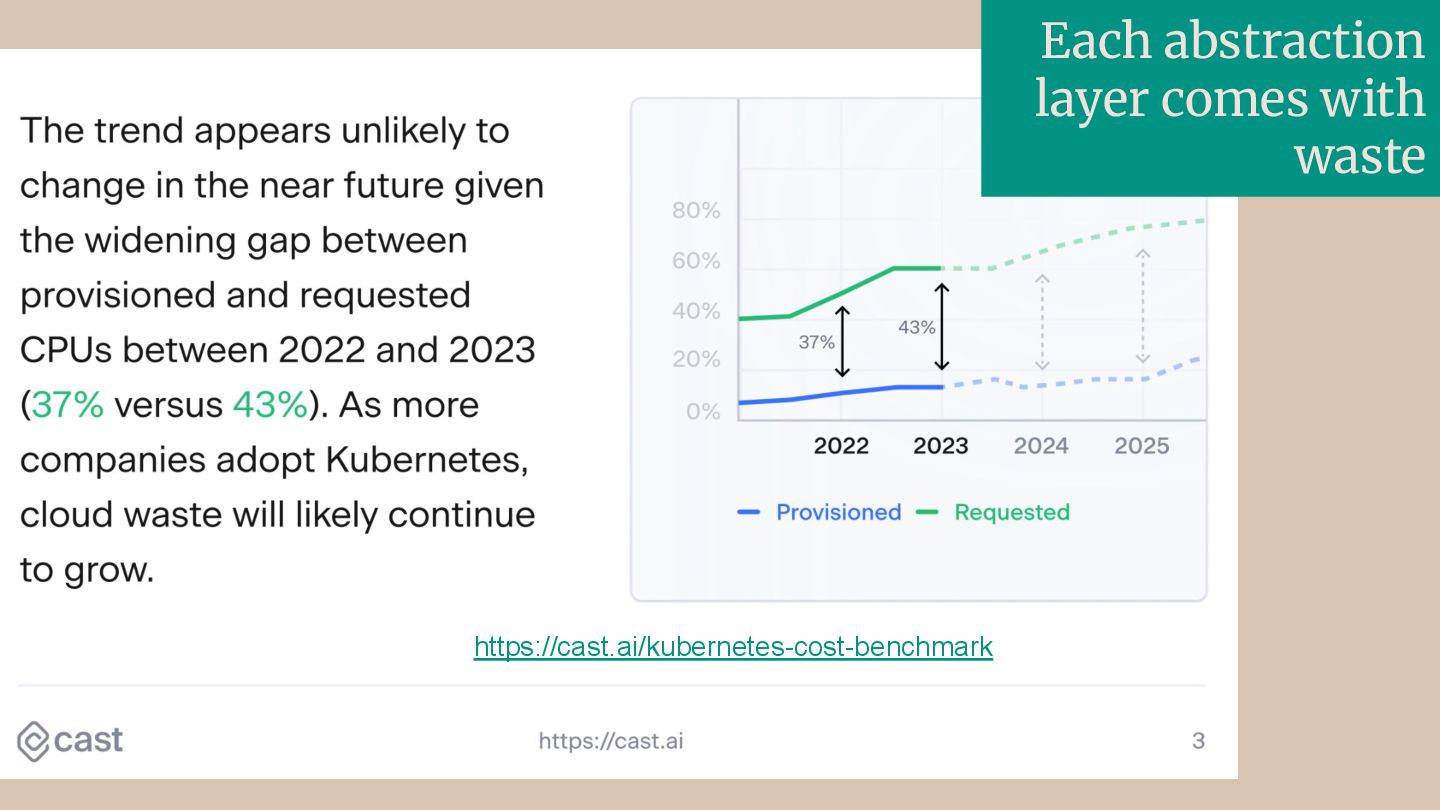
Did you know that, on average, 37% of CPUs provisioned for cloud-native applications are never used, and the gap between resources allocated and resources used is widening? This inefficiency is causing cloud waste, and is negatively impacting the environment.
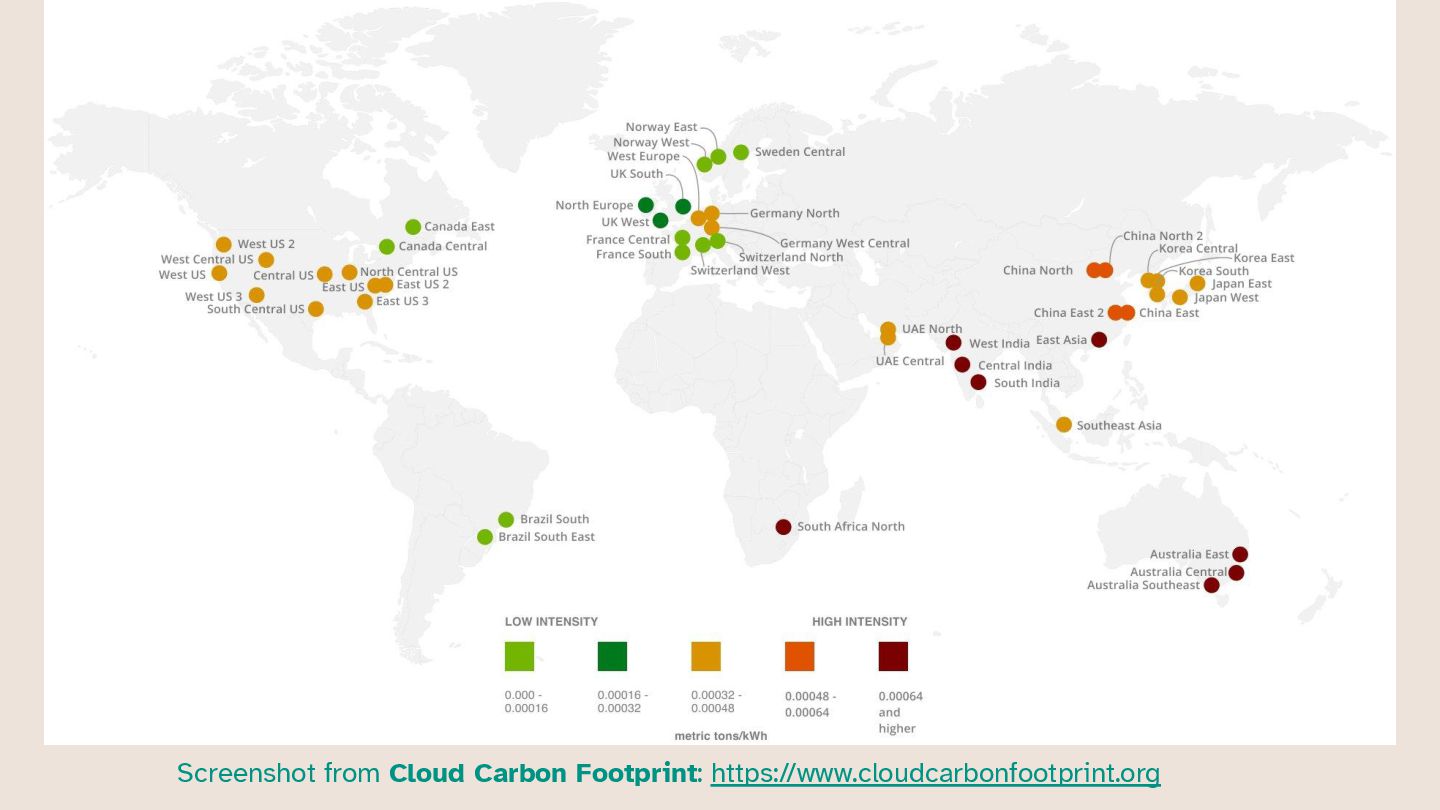
Sustainability of cloud infrastructure is a growing concern, not just for people inside the IT sector. Knowledge around what is environmentally sustainable within IT is still somehow limited, with persisting misconceptions, such as the belief that running cheap automatically equals running green. With factors like committed spend discounts and cloud regions running on cheap but dirty energy, that is often not correct.
Kubernetes has become the orchestration platform of choice. While its capabilities have been increasing with each passing year, a system can only be as efficient as its users let it, and Kubernetes on its own is not a silver bullet for solving environmental sustainability challenges.
In this talk, I want to highlight areas of running workloads on Kubernetes that organizations can improve on. We'll take a starting point in the "reuse, reduce, recycle" principle of environmental protection, and see how we can apply it to our applications running on Kubernetes.
Attendees will leave with actionable insights on how to directly improve the sustainability and efficiency of the Kubernetes clusters they manage. Join me to learn how to employ Kubernetes for a greener cloud future.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}