Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Agentic AI in 30min
Search
ymicky06
December 25, 2025
380
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Agentic AI in 30min
ymicky06
December 25, 2025
More Decks by ymicky06
See All by ymicky06
LMDX / 論文紹介 LMDX:Language Model-based Document Information Extraction and Localization
ymicky06
0
87
freeeのOCR開発における Amazon SageMaker Ground Truthの活用 / SageMaker Ground Truth for OCR at freee
ymicky06
0
170
Kaggleのたんぱく質コンペで銅メダルとった話 / Get Bronze medal on Kaggle Competition
ymicky06
0
470
Kaggle鳥コンペ反省会 / Retrospective Birt Competition on Kaggle
ymicky06
0
290
Featured
See All Featured
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Mozcon NYC 2025: Stop Losing SEO Traffic
samtorres
1
390
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.8k
Mobile First: as difficult as doing things right
swwweet
225
10k
Being A Developer After 40
akosma
91
590k
ラッコキーワード サービス紹介資料
rakko
1
3.9M
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Bridging the Design Gap: How Collaborative Modelling removes blockers to flow between stakeholders and teams @FastFlow conf
baasie
0
610
Transcript
30分でわかる Agentic AI micky@AI Lab
30分でわかるAgentic AI • 対象 ◦ LLMを使ったアプリケーション開発に関わるエンジニア / PdM • 今日のゴール
◦ Agentic AI の全体像をつかむ ◦ 4つのエージェント設計パターンを理解する ◦ 評価(Evals)とエラー分析のプロセスを、実務で使えるレベルで持ち帰る • アジェンダ ◦ Agentic AI とは? ◦ 4つのデザインパターン ◦ 評価・エラー分析の進め方(メイン) ◦ 実務への応用とまとめ
元ネタ • Andrew Ng先生のAgentic AIコース(link) ◦ Ng先生はAI教育の第一人者 (linkedin) ◦ Agentic
AIの実践的な作り方、評価方法を学ぶ ◦ 自分がコースを一通りみて重要だと思ったところ、とくに評価部分を厚めに紹介します ◦ 無料なのでAI Agent作ろうとしているエンジニアは見ることをおすすめします ◦ 図、画像は特に断りがない限りすべてコースからの引用です
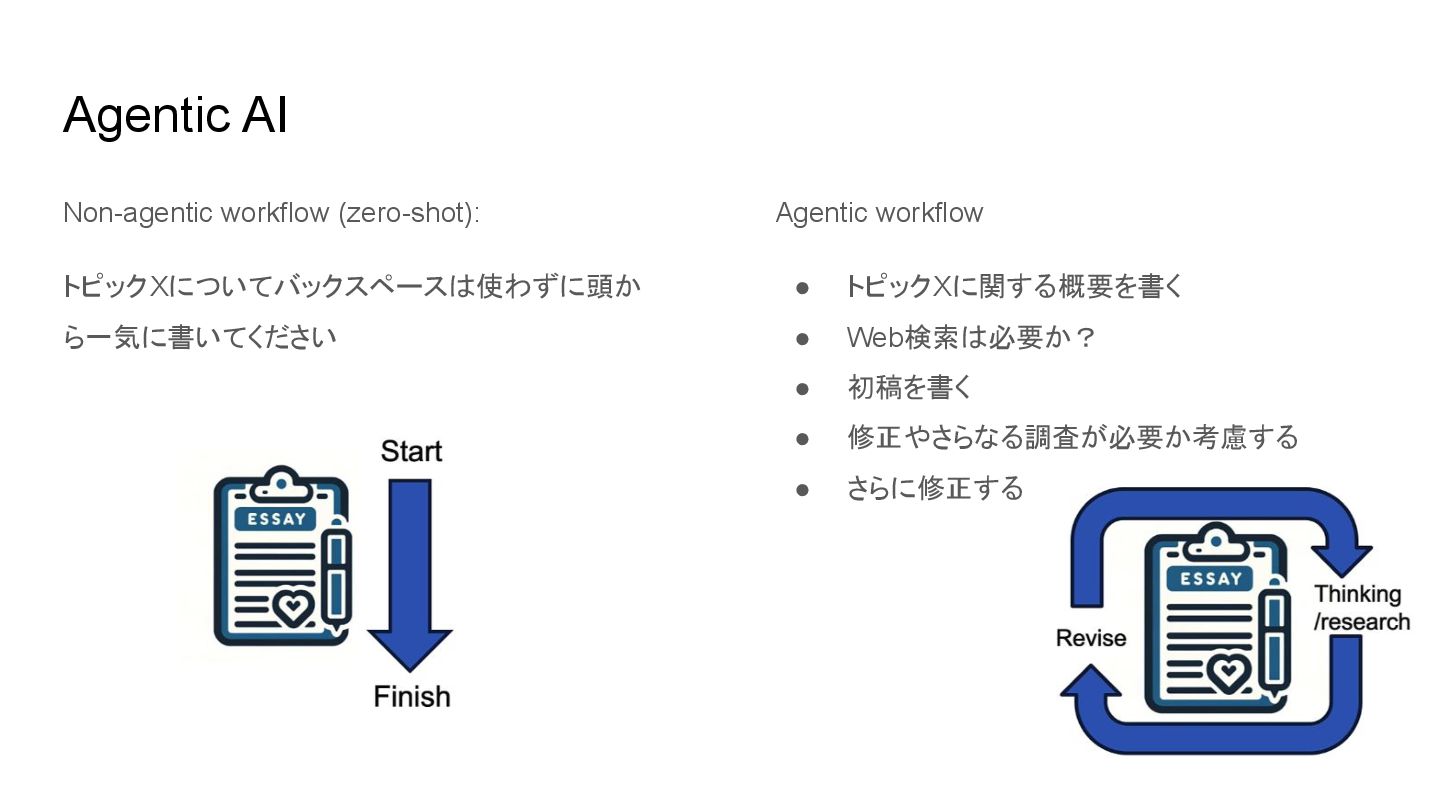
Agentic AI Non-agentic workflow (zero-shot): トピックXについてバックスペースは使わずに頭か ら一気に書いてください Agentic workflow •
トピックXに関する概要を書く • Web検索は必要か? • 初稿を書く • 修正やさらなる調査が必要か考慮する • さらに修正する
なぜAgenticなアプローチが必要か? • 従来の使い方 ◦ 「プロンプトを投げる → 1 回の回答を受け取る」単発チャット • 実際の仕事の流れ
◦ 調査 → 情報整理 → アウトライン作成 → ドラフト → 推敲 → 仕上げ ◦ 現実のタスクはマルチステップで反復的 • 課題 ◦ 「1 回きりの回答」では、 ◦ 情報が足りない ◦ 間違いを修正しきれない ◦ 外部ツールとの連携が弱い • Agentic AI の狙い ◦ LLM に行動(Action)と自己改善(Self-improvement)をさせる ◦ ユーザの代わりに、タスクを計画・実行・見直しする
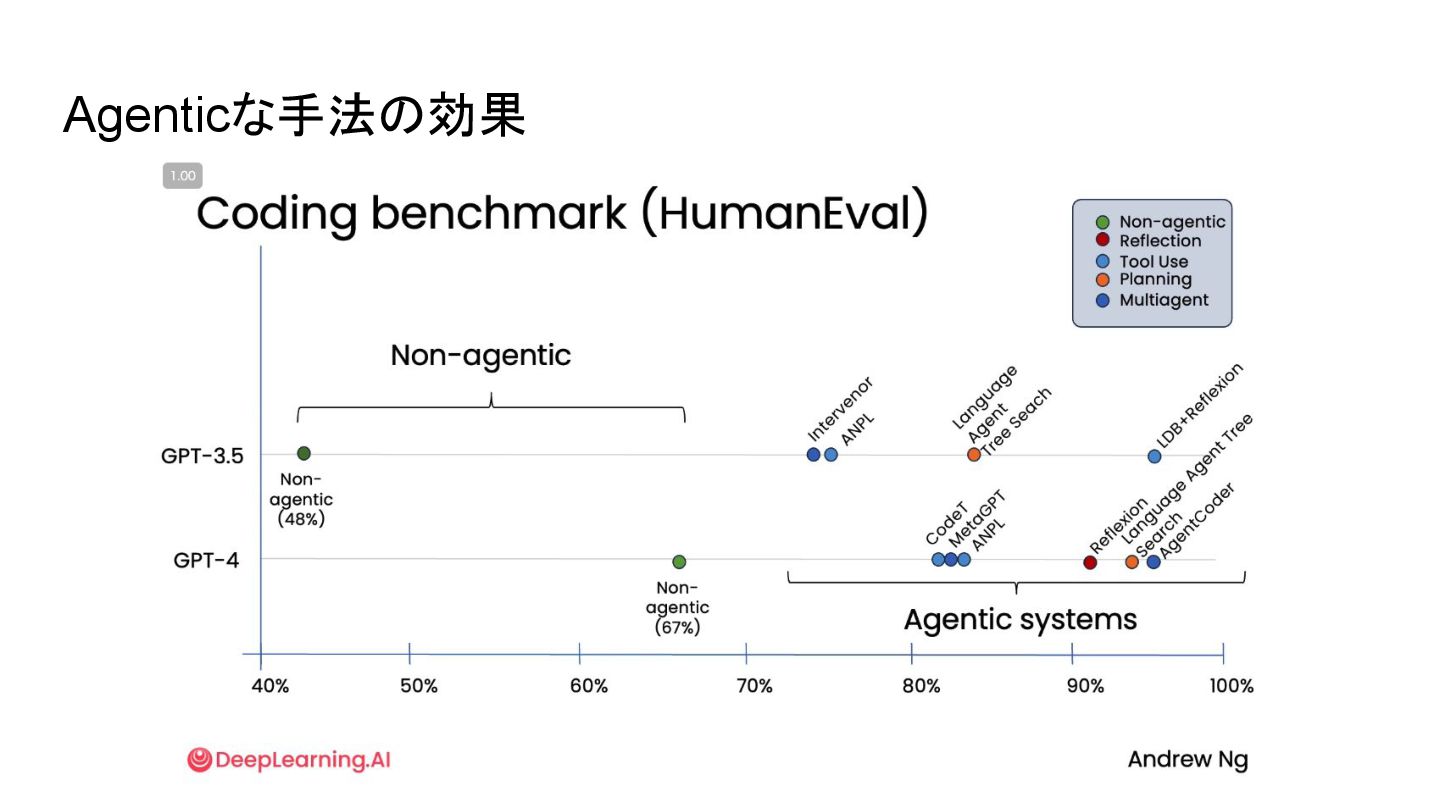
Agenticな手法の効果
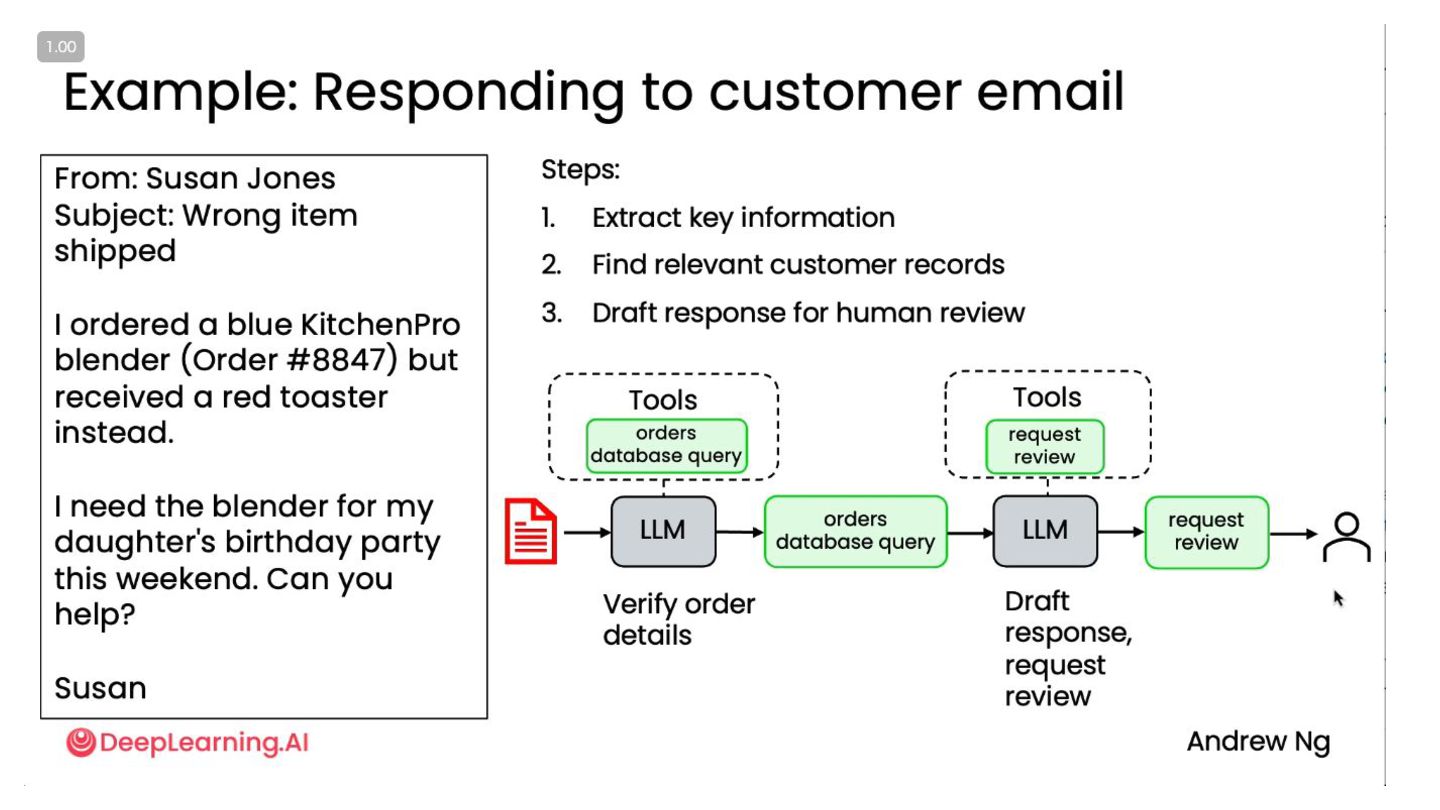
None
None
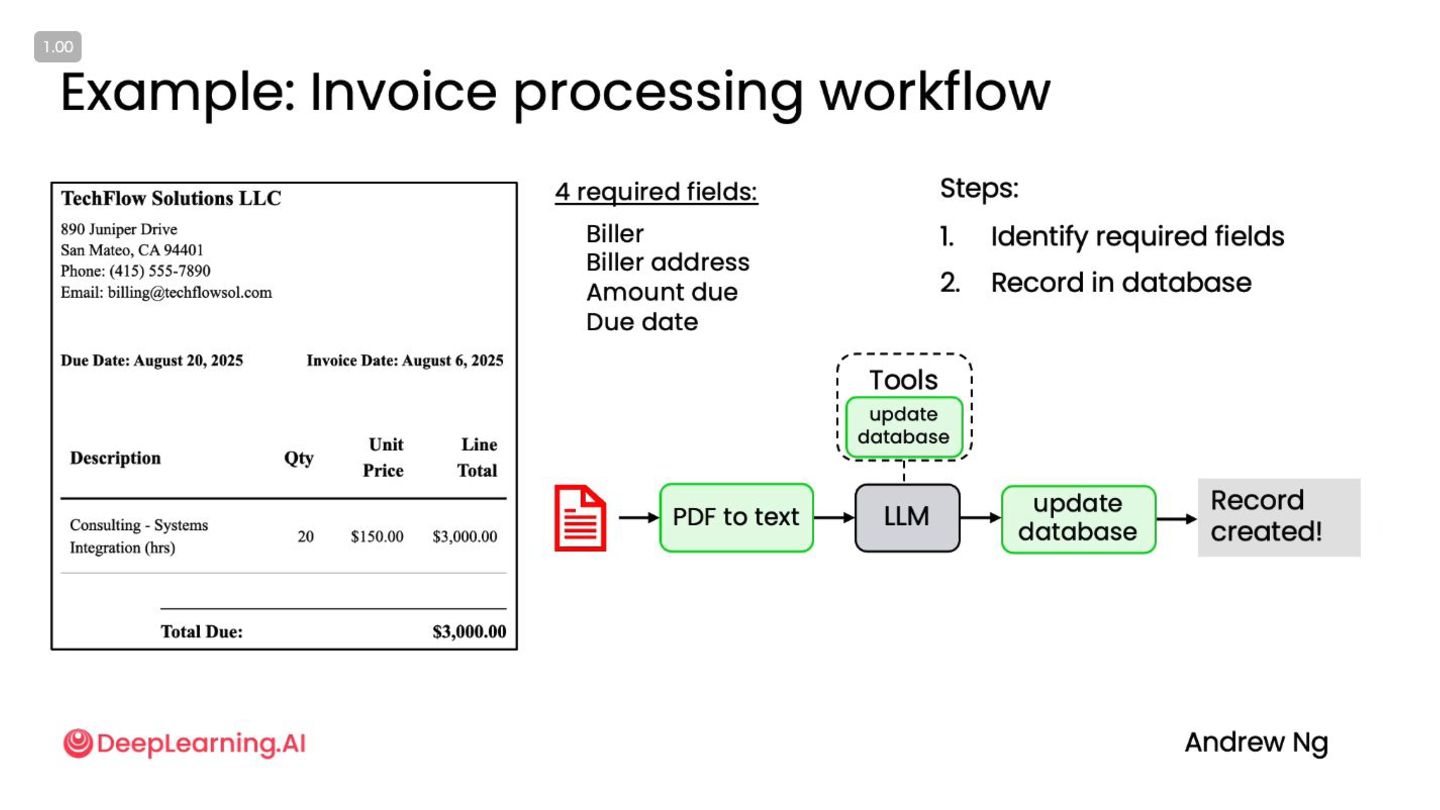
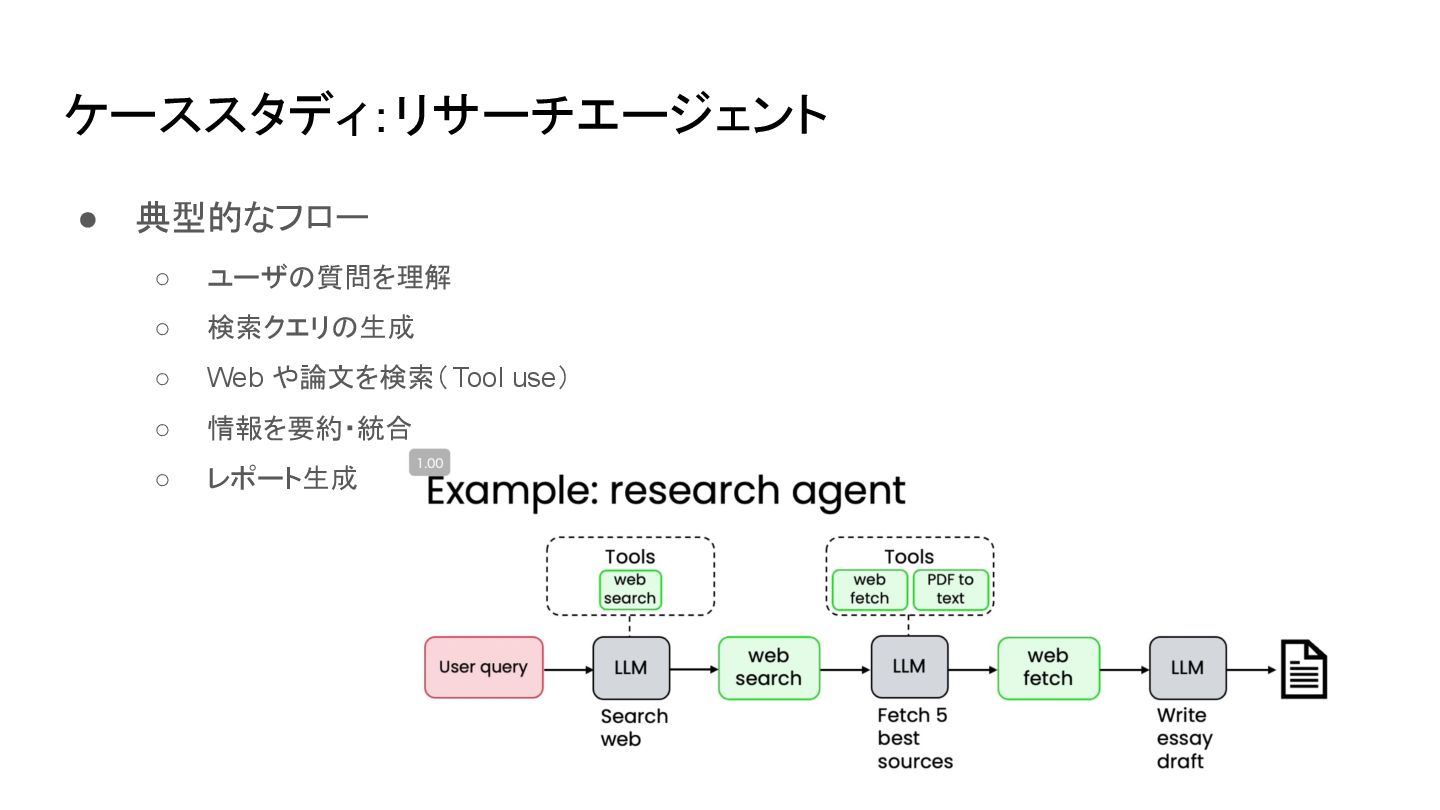
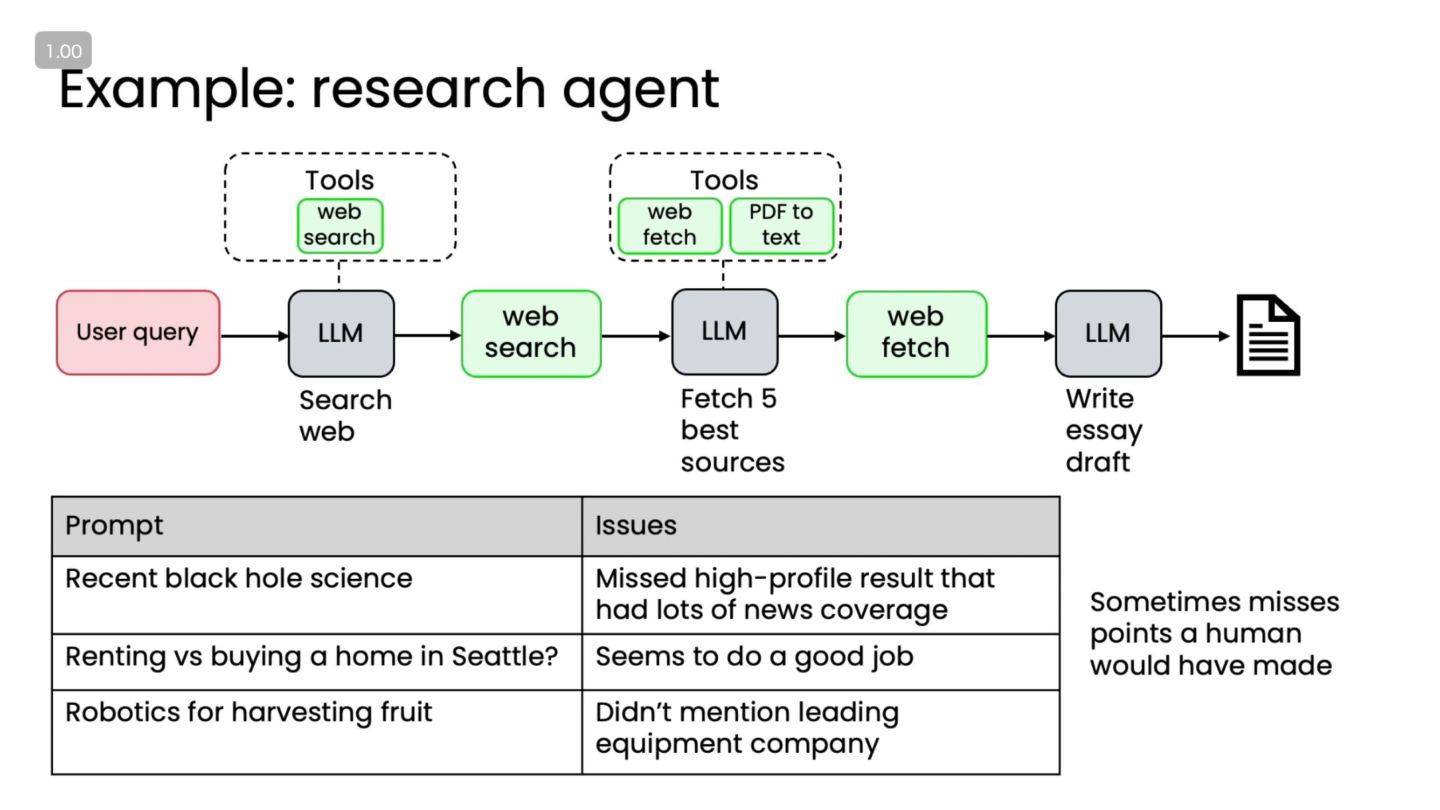
ケーススタディ:リサーチエージェント • 典型的なフロー ◦ ユーザの質問を理解 ◦ 検索クエリの生成 ◦ Web や論文を検索(Tool
use) ◦ 情報を要約・統合 ◦ レポート生成
4つの Agentic デザインパターン • Reflection ◦ 自分の出力を振り返り、自己修正する • Tool use
◦ 検索・DB・カレンダー・コード実行などのツールを呼び出す • Planning ◦ タスクをサブタスクに分解し、順序立てて実行する • Multi-agent collaboration ◦ 複数のエージェントが協調してタスクを遂行する
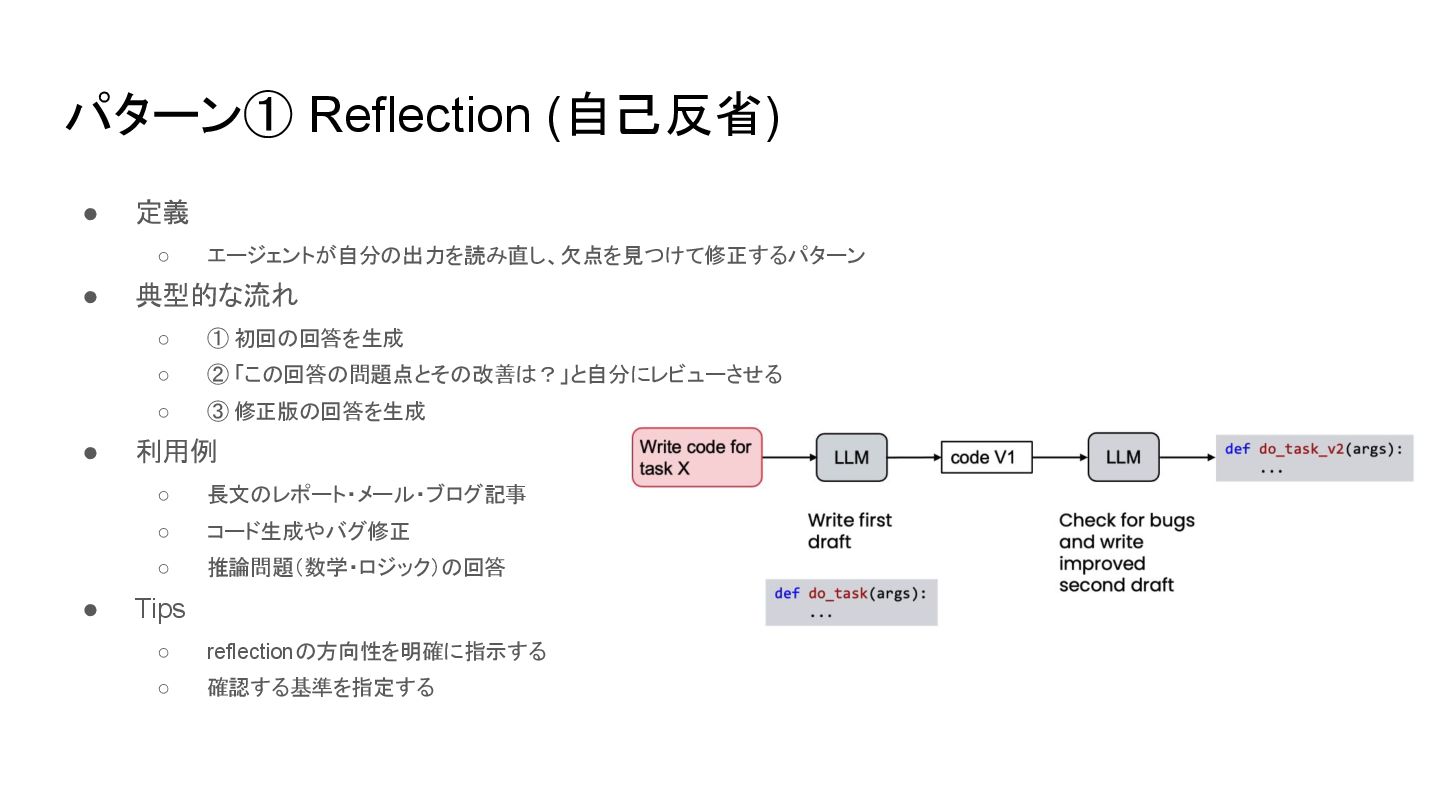
パターン① Reflection (自己反省) • 定義 ◦ エージェントが自分の出力を読み直し、欠点を見つけて修正するパターン • 典型的な流れ ◦
① 初回の回答を生成 ◦ ② 「この回答の問題点とその改善は?」と自分にレビューさせる ◦ ③ 修正版の回答を生成 • 利用例 ◦ 長文のレポート・メール・ブログ記事 ◦ コード生成やバグ修正 ◦ 推論問題(数学・ロジック)の回答 • Tips ◦ reflectionの方向性を明確に指示する ◦ 確認する基準を指定する
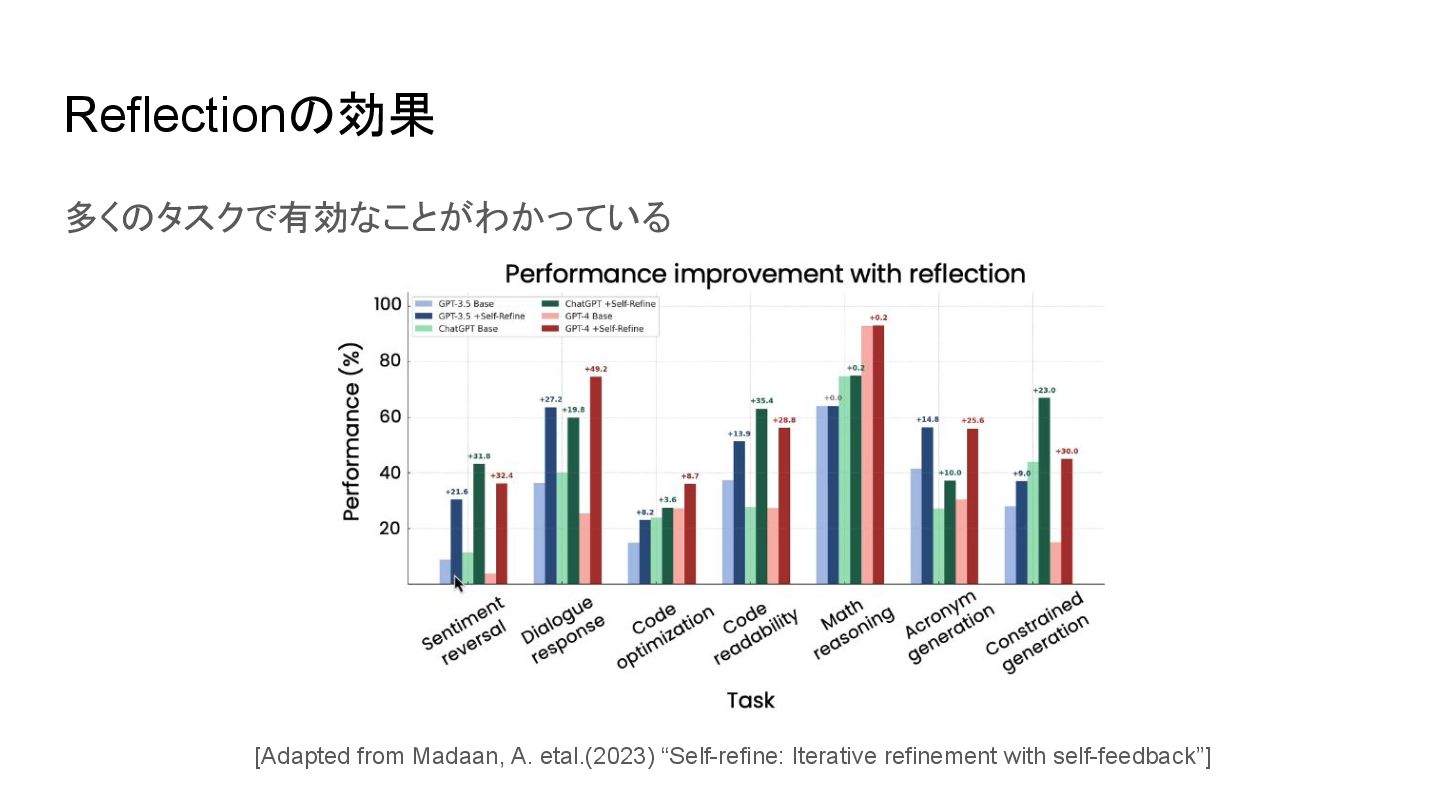
Reflectionの効果 多くのタスクで有効なことがわかっている [Adapted from Madaan, A. etal.(2023) “Self-refine: Iterative refinement
with self-feedback”]
パターン② Tool use(ツール利用) • 定義 ◦ LLM が外部ツールの呼び出しを自分で決めるパターン • ツールの例
◦ Web 検索、社内検索 ◦ データベース問い合わせ ◦ カレンダー・メール・タスク管理 ◦ コード実行(Python REPL など) • ポイント ◦ ツールのインターフェース設計 ◦ (入力パラメータ・返り値のフォーマット) ◦ 失敗時の扱い ◦ (ネットワークエラー・空の結果など) • Tips ◦ 「どのツールをいつ使うか」をプロンプトで明示す
パターン③ Planning(計画) • 定義 ◦ タスクをサブタスクに分解し、実行順序を決めるパターン • 例:リサーチレポート作成 ◦ ①
重要な観点の洗い出し ◦ ② 調査対象の絞り込み ◦ ③ 情報収集 ◦ ④ 構成案作成 ◦ ⑤ 下書き → 推敲 • いつ使うか? ◦ あらかじめワークフローを定義できないとき ◦ どんなクエリが来るか不明なとき
パターン④ Multi-agent collaboration • 定義 ◦ 複数の専門エージェントに役割分担させるパターン • 例:レポート生成エージェント ◦
リサーチ担当 ◦ 要約・構造化担当 ◦ スタイル・トーン調整担当 • メリット ◦ 専門性を分けることで、設計・評価がしやすい ◦ 後から「この役割だけ差し替える」が可能 • 課題 ◦ エージェント間のインターフェース設計 ◦ どの段階で評価・フィードバックを入れるか? ◦ → このあと話す「評価・エラー分析」で非常に重要になる
なぜ「評価とエラー分析」が最重要なのか? • Andrew Ng のメッセージ ◦ 「エージェント構築が上手くいくかどうかの最大の差は、評価とエラー分析のプロセスを回せるかど うか」 • 直感だけで改良すると…
◦ 改善ポイントが当てずっぽうになる ◦ 変えた結果が良くなったのか悪くなったのか分からない • 評価の目的 ◦ どのコンポーネントを優先的に改善すべきかを決める ◦ 変更前後をデータで比較できるようにする • 評価 を回すチームが、結局一番早く前に進む
Agentic AI 評価の難しさ • 普通の「1ショット LLM」と違う点 ◦ ステップ数が多い(計画 → 検索
→ 要約 → 出力…) ◦ 外部ツール・API が絡む ◦ ランダム性が高く、毎回挙動が少しずつ違う • その結果 ◦ 単に「最終出力が良いか」で見るだけでは不十分 ◦ どのステップが失敗したかが分かりにくい • 必要になる評価の視点 ◦ ワークフロー全体の評価 ◦ 各ステップの評価 • まとめ ◦ 「ブラックボックスとして評価」ではなく、「分解して評価」が Agentic AI には必須
評価の3つのレイヤー • レイヤー①:出力レベル ◦ 例:最終レポートの正確性・読みやすさ ◦ モデルの文章品質・事実性など • レイヤー②:ステップレベル ◦
例:検索ステップで、十分な情報が取れているか? ◦ 例:計画ステップで、重要な観点を落としていないか? • レイヤー③:ワークフローレベル ◦ 例:ユーザの本来の目的が達成されているか? ◦ 例:タスク全体の時間・コストは妥当か? • ポイント ◦ どのレイヤーに問題があるか特定できることがエラー分析 → 改善の近道
評価方法①:自動評価 • 向いているケース ◦ 正解ラベルがはっきりあるタスク ▪ コード生成(テストが通るか) ▪ 事実 Q&A
▪ 構造化データ抽出( OCRとか) • 代表的な指標 ◦ 正答率 / F1 スコア / ルールベースチェック ◦ テストケースの通過率 • メリット ◦ 再現性が高い ◦ 自動で大量に回せる • Tips ◦ できるところはできるだけ自動化してしまう
評価方法②:主観タスクの評価 • 向いているケース ◦ 要約・文章生成・レポート・企画案など「正解が 1つでない」タスク • 人手評価 ◦ 例:5段階評価
◦ 例:A/B テスト(旧版 vs 新版の比較) • LLM-as-a-judge ◦ LLM に「採点者」として評価させる ◦ 一貫した評価基準(プロンプト)が重要 • 注意点 ◦ モデルのバイアス ◦ 同じ出力でも評価が揺れる可能性 • 現実的な落としどころ ◦ 人手評価 + LLM-as-a-judge を組み合わせてコスト/精度のバランスを取る
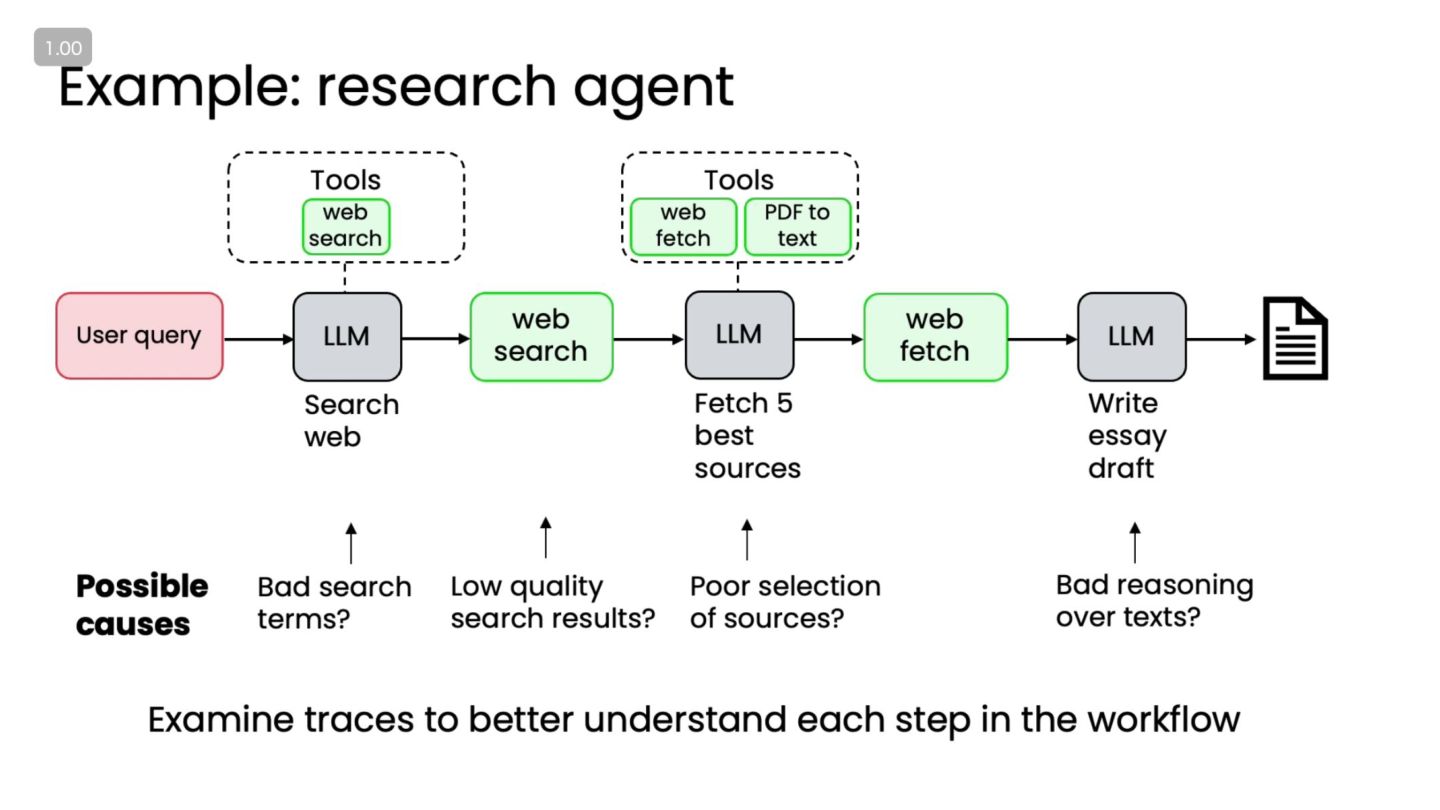
ログとトレース:失敗箇所を特定する • なぜログが重要か? ◦ 「最終出力が悪い」だけでは、どこを直すべきか分からない • 残しておきたい情報 ◦ 各ステップのプロンプト ◦
LLM の中間出力(計画、思考メモ、レビュー結果など) ◦ ツール呼び出しの引数と返り値 • トレースを見ることで分かること ◦ 不適切な検索クエリ ◦ 間違った中間推論 ◦ 反省(Reflection)が機能していないポイント • Tips ◦ まずはシンプルに、JSON ログ / DB に記録するところから始める
None
None
None
None
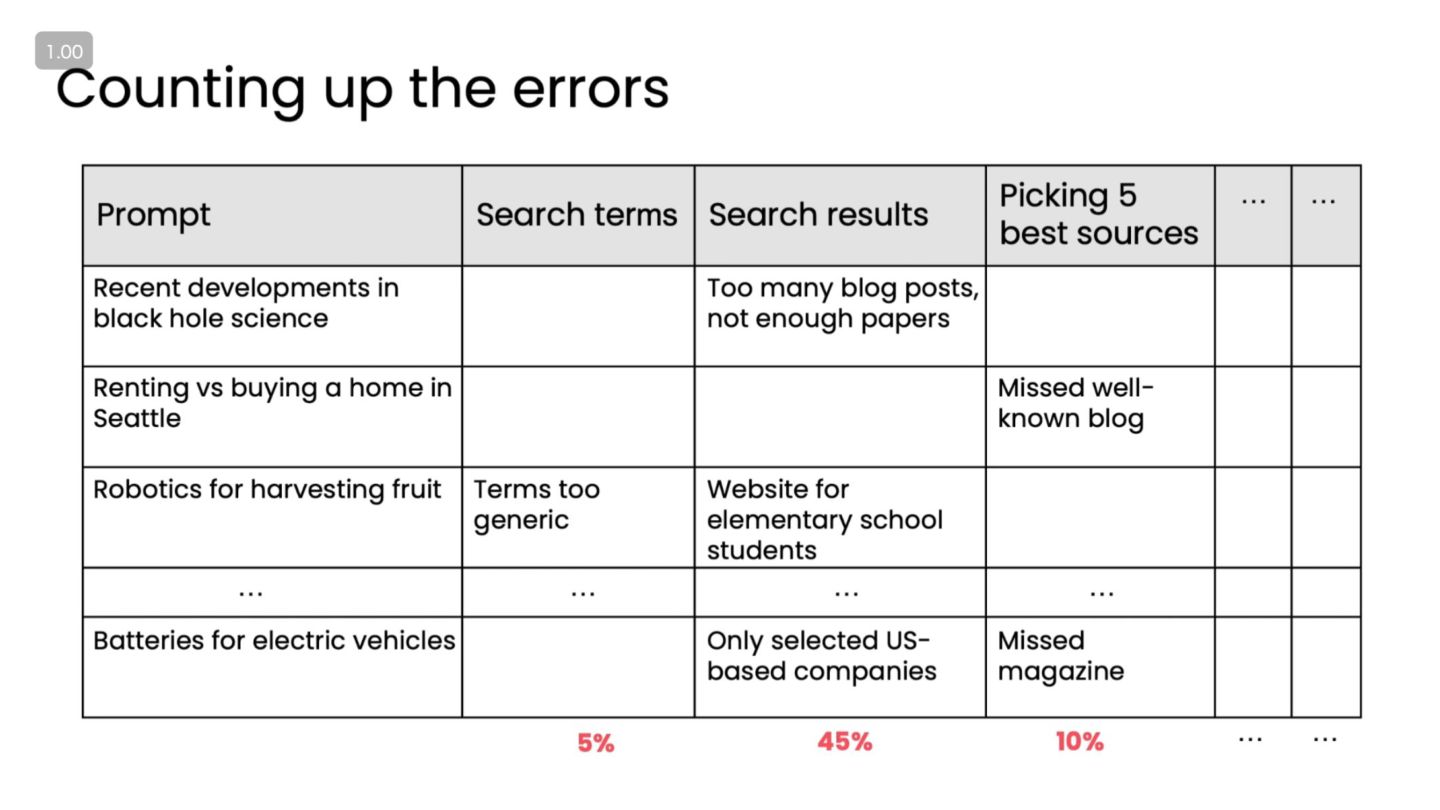
エラー分析①:エラーの分類 • エラー例 ◦ リサーチ不足(重要な情報を取りこぼしている) ◦ 要約の誤り・幻覚(存在しない事実) ◦ スタイル不一致(トーン・フォーマットが要件と違う) ◦
ツール呼び出しの失敗(API エラー、間違った関数選択) • 分析の基本 ◦ 失敗ケースをいくつかピックアップ ◦ 各ケースに「エラーラベル」を付与 ▪ 例:"planning_error", "tool_query_error", "hallucination", … • メリット ◦ どのタイプのエラーが多いかが一目で分かる ◦ 改善の優先順位をつけやすい
エラー分析②:改善ポイントの優先順位付け • 優先度の考え方 ◦ 「頻度 × 影響度」で重み付け • 例 ◦
多くの失敗が「計画に重要な観点が抜けている」 ◦ → Planning ステップのプロンプト改善が最優先 ◦ 特定分野の事実誤りが多い ◦ → 検索クエリの改善 / 信頼できるソースの制限 ◦ スタイルのブレが多い ◦ → 出力フォーマットのガイドライン・テンプレート強化 • ポイント ◦ 「何となく気になるところ」ではなく、データから決めた優先度に従って直す
評価用データセットの作り方 • 最初に決めること ◦ タスク定義(入力と、望まれる出力のイメージ) ◦ 評価の観点(正確性 / 網羅性 /
読みやすさ / スタイル など) • データセットの作り方 ◦ 代表的なユースケースからサンプルを集める ◦ エッジケース(ややこしい指示、あいまいな要求)も入れる • 継続的な更新 ◦ 実運用中に出た失敗例を評価セットに追加していく • 最終的な目標イメージ ◦ 「何か変更したら、とりあえずこの評価セットを流す」という回帰テストのような仕組みにする
評価ループの自動化 • 基本的な方針 ◦ 評価できるならやり方はなんでも OK ◦ 評価ロジックを生の Python で書く,
langfuse使う, etc • 典型的な評価ループ ◦ ① エージェントの新バージョンを実装 ◦ ② 評価データセットに対して一括実行 ◦ ③ 自動評価 / LLM-as-a-judge でスコアリング ◦ ④ 旧バージョンとスコアを比較 • 将来像 ◦ CI/CD パイプラインに組み込み ▪ コードが変更されたら自動で 評価実行 ▪ スコアが一定以下ならリリースをブロック • 実務での最初の一歩 ◦ ローカルスクリプトでもよいので、「ワンコマンドで評価が回る」状態を作る
まとめ:明日から何を始めるか? • スモールスタートのアイデア ◦ 既存の LLM ワークフローに「ログ取得」を追加 ◦ 代表的な 10〜20
件の評価データセットを作る ◦ 簡単な評価スクリプト( Python)を用意する • 少し進んだステップ ◦ Reflection を追加して、出力品質の底上げを図る ◦ Tool use を導入し、検索や社内データとつなぐ • 中長期的な方向性 ◦ 重要なユースケースに対して、 ◦ Planning / Multi-agent を導入 ◦ 評価ループを CI に組み込む • メッセージ ◦ 「高機能なフレームワークを使うこと」より「 evals とエラー分析を回せること」が差になる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}