Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【CNDT2020】Amebaアフィリエイト基盤の GKEアーキテクチャと マイクロサービス
Search
youta ogino
September 08, 2020
Technology
1.3k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【CNDT2020】Amebaアフィリエイト基盤の GKEアーキテクチャと マイクロサービス
Cloud Native Days 2020での登壇資料
https://event.cloudnativedays.jp/cndt2020/talks/59
youta ogino
September 08, 2020
More Decks by youta ogino
See All by youta ogino
Amplify Console のビルド通知をSlackで受け取るためにやったこと
youta1119
1
5.4k
KotlinFest2019
youta1119
4
12k
Other Decks in Technology
See All in Technology
起点・思考・出力で分解する 〜PM業務の自動化設計〜
kazu_kichi_67
2
1.2k
感情と身体を置き去りにしない、エンジニアの生きのこり方 ──いまから、ここから「自分の状態」を扱うという選択
saorimurooka
0
440
AIに障害切り分けを全部やってもらった。 。 。 。
estie
0
320
背中から、背中へ /paying forward to community
naitosatoshi
0
200
Why is RC4 still being used?
tamaiyutaro
0
270
データレイクの「見えない問題」を可視化する
sansantech
PRO
1
260
グローバルチームと挑むプロダクト開発
sansantech
PRO
1
120
攻撃者がいなくてもAIエージェントはインシデントを起こす
nomizone
0
180
Multi-Agent並列開発を 安全に回すための技術 / Technology for Safely Multi-Agent Parallel Development
tooppoo
0
240
『AIに負けない』より『AIと遊ぶ』」〜ワクワクが最強のテスト・QA学習戦略_公開用
odan611
1
310
フロントエンドイチゲキ実装 ― Figmaデザインと画面設計書からAIに実装・テストを書かせるための”下ごしらえ” / 20260627 Yusuke Mazuka
shift_evolve
PRO
0
120
打造你的 AI 工作流:Agent Skill + MCP 實戰工作坊
appleboy
0
310
Featured
See All Featured
What's in a price? How to price your products and services
michaelherold
247
13k
The Curse of the Amulet
leimatthew05
2
13k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
220
The World Runs on Bad Software
bkeepers
PRO
72
12k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Done Done
chrislema
186
16k
Unlocking the hidden potential of vector embeddings in international SEO
frankvandijk
0
860
KATA
mclloyd
PRO
35
15k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.5k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Typedesign – Prime Four
hannesfritz
42
3.1k
Transcript
Amebaアフィリエイト基盤の GKEアーキテクチャと マイクロサービス
小沢周平 CyberAgent, Inc. 技術本部サービスリライアビリティグループ インフラエンジニア 現在はAmebaの新認証基盤のEKS周りの運用を主に しています。今後はコスト可視化/負債可視化業を やっていき。
1. アーキテクチャの紹介 2. GKEのオートプロビジョニングとスケールアップ 3. gRPCのバランシングのEnvoyの設定 4. リクエストを取りこぼさないためにやったこと 5. DatadogAPMとOpenCensusでのモニタリング
後半:アプリやマイクロサービスについて
None
1. アーキテクチャの紹介 2. GKEのオートプロビジョニングとスケールアップ 3. gRPCのバランシングのEnvoyの設定 4. リクエストを取りこぼさないためにやったこと 5. DatadogAPMとOpencensusでのモニタリング
後半:アプリやマイクロサービスについて
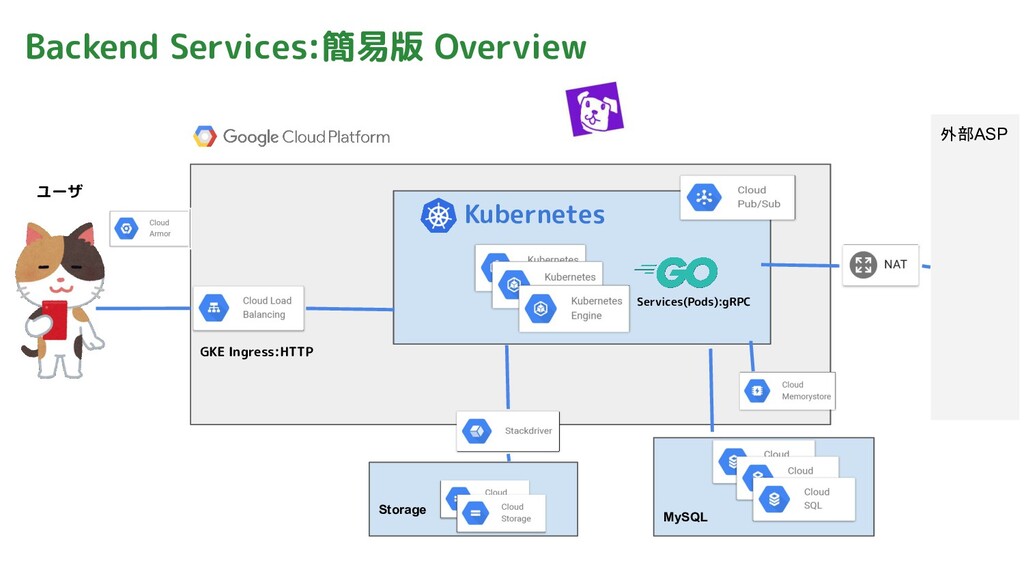
Backend Services:簡易版 Overview Services(Pods):gRPC GKE Ingress:HTTP MySQL Storage 外部ASP ユーザ
Kubernetes
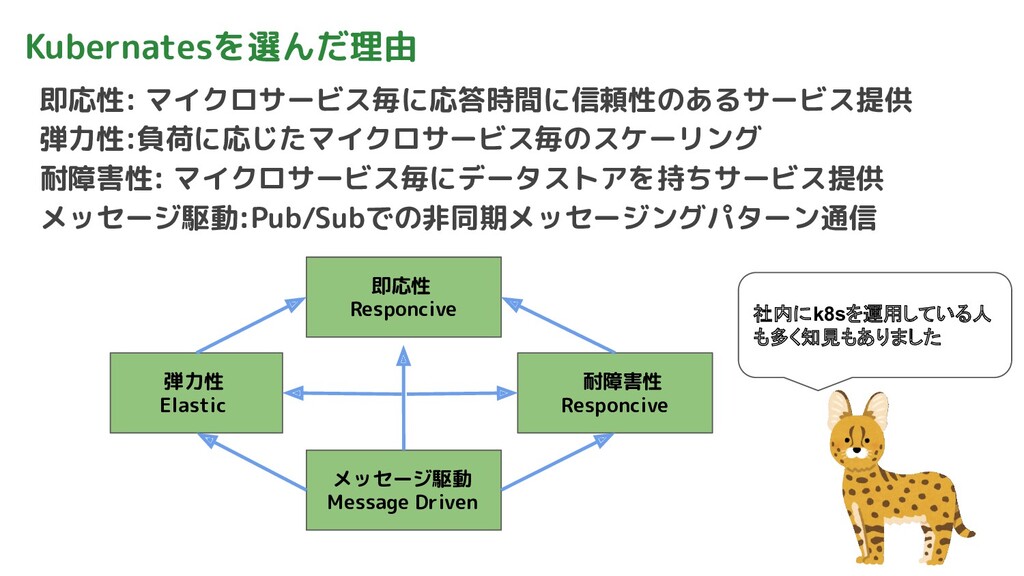
Kubernatesを選んだ理由 即応性: マイクロサービス毎に応答時間に信頼性のあるサービス提供 弾力性:負荷に応じたマイクロサービス毎のスケーリング 耐障害性: マイクロサービス毎にデータストアを持ちサービス提供 メッセージ駆動:Pub/Subでの非同期メッセージングパターン通信 即応性 Responcive メッセージ駆動
Message Driven 弾力性 Elastic 耐障害性 Responcive 社内にk8sを運用している人 も多く知見もありました
GKEを選んだ理由 Kubernatesの運用が初めてだったので、一番運用がしやすいGKEを選択 KubernatesクラスターはGoogleが管理 node groupもマネージド管理 クラスタアップグレードが容易 Podをdrainしてサージアップグレードをしてくれる ノードの自動プロビジョニング ノードプールのスペックを最適なものにしてくれる ノードの自動修復
修復対象のノードが検出されるとdrainして、再作成をしてくれる その他にもKubernatesの運用を楽にする機能の有効化が簡単 EKSを構築した時にGKE がいい感じにしてくれて いた事に気が付きました
1. アーキテクチャの紹介 2. GKEのオートプロビジョニングとスケールアップ 3. gRPCのバランシングのEnvoyの設定 4. リクエストを取りこぼさないためにやったこと 5. DatadogAPMとOpencensusでのモニタリング
後半:アプリやマイクロサービスについて
Ⅰ GKEのオートプロビジョニングとスケールアップ 負荷に応じてノードとPodのオートスケールをさせています ノードの自動プロビジョニング 必要なリソースに合わせてノードプール単位でスケーリングしてくれます HPA 人気ブログなどでアクセスのスパ イクが予想されるときは予めス ケールさせます spec:
scaleTargetRef: apiVersion: apps/v1 kind: Deployment name: grpcserver minReplicas: 3 maxReplicas: 40 metrics: - type: Resource resource: name: cpu targetAverageUtilization: 80 ここではCPU使用率が閾値を 超えたらPodがスケールする ように設定しています。
Ⅰ HPAでスケールしたPodにリクエストが送られない 負荷試験時にIngress→NodePort→Podだと負荷が偏ってしまった NEGsを有効にしてIngressから直接Podを見れるようにすることでHPAで スケールしたPodに対しても偏りなく負荷分散させることができた。 annotations: cloud.google.com/neg: '{ "ingress": true
}' 有効化もannotationを追加するだけ
1. アーキテクチャの紹介 2. GKEのオートプロビジョニングとスケールアップ 3. gRPCのバランシングのEnvoyの設定 4. リクエストを取りこぼさないためにやったこと 5. DatadogAPMとOpencensusでのモニタリング
後半:アプリやマイクロサービスについて
gRPCのバランシングのEnvoyの設定 gRPCのバランシングのためにEnvoyをSidecarで導入しました。 サービスディスカバリはHeadless Services 名前解決のレイテンシを改善する為にNodeLocalDNSCacheを有効化 control planeを導 入してCanary Releaseなど出来る ようにしたいお気持
ちはあります Envoy アプリA Envoy アプリB Inbound Inbound Outbound Outbound
可用性を高めるEnvoyの機能 Circuit Breaking 過剰なリクエストが来た時に応答不可を防ぐ Outlier Detection Podへの500系や200系の回数をみてクラスタから取り除くか制御 Health Check アプリ側でHTTPのエンドポイントをはやしてLiveness/Readiness
Prove gRPCのHealthCheckはSidecarのEnvoyからのみ叩くようにした
アクセスログの設定 access_log: - name: envoy.access_loggers.file typed_config: "@type": type.googleapis.com/envoy.extensions.access_loggers.file.v3.FileAccessLog path: "/dev/stdout"
typed_json_format: start_time: "%START_TIME%" method: "%REQ(:METHOD)%" path: "%REQ(X-ENVOY-ORIGINAL-PATH?:PATH)%" protocol: "%PROTOCOL%" response_code: "%RESPONSE_CODE%" response_flags: "%RESPONSE_FLAGS%" bytes_rcvd: "%BYTES_RECEIVED%" bytes_snt: "%BYTES_SENT%" duration: "%DURATION%" x-envoy-upstream-svc-time: "%RESP(X-ENVOY-UPSTREAM-SERVICE-TIME)%" x-forwarded-for: "%REQ(X-FORWARDED-FOR)%" useragent: "%REQ(USER-AGENT)%" x-request-id: "%REQ(X-REQUEST-ID)%" backend_address: "%UPSTREAM_HOST%" client: "%DOWNSTREAM_REMOTE_ADDRESS%" referer: "%REQ(REFERER)%" response_duration: "%RESPONSE_DURATION%" upstream_transport_failure_reason: "%UPSTREAM_TRANSPORT_FAILURE_REASON%" アプリのログの他にも、 Envoyでアクセスログを取得 しています %RESPONSE_FRAGS%で RESPONSEの情報をみるぐ らいに使っています
Envoyのメトリクス EnvoyのメトリクスでgRPC等 のstatusなどもとれます。 実際はDatadogAPMで取得し たメトリクスを主に使用して いますが、Envoyでのメトリ クスで監視設定している部分 もあるので、取得していま す。 template:
metadata: annotations: ad.datadoghq.com/envoy.check_names: '["envoy"]' ad.datadoghq.com/envoy.init_configs: '[{}]' ad.datadoghq.com/envoy.instances: | [ { "stats_url": "http://%%host%%:8001/stats" } ]
共通のEnvoyイメージの用意 共通で使える設定ファイルを内包したEnvoyイメージを使用 YAMLのアンカーとエイリアスで記述量を減らすようにしています。 ゆくゆくはサービス の規模感や体制に合 わせたcontrol planeを導入したい です type: STRICT_DNS
lb_policy: ROUND_ROBIN connect_timeout: 0.25s ignore_health_on_host_removal: true http2_protocol_options: {} health_checks: *egress_health_checks outlier_detection: *outlier_detection circuit_breakers: *circuit_breakers マイクロサービスが増え た際はclustersに書き足 していく運用です。 Envoyをv1.15.0にアッ プグレードして、data plane apiの設定をv3に 対応してあります。
実際に運用して困ったこと Pod数が増えるとヘルスチェックのgRPCアクセスが劇的に増えて、 API監視でUNKNOWNのアラートを発報してしまった。 http_filters: - name: envoy.filters.http.health_check typed_config: "@type": type.googleapis.com/envoy.extensions.filters.http.health_che
ck.v3.HealthCheck pass_through_mode: false cluster_min_healthy_percentages: self-grpc: value: 100 headers: - name: ":path" exact_match: /healthz pass_through_mode: falseにし てヘルスチェックの状態を保持 し返すようにしました。 no_traffic_intervalを60sにし大 量のヘルスチェックを飛ばさな いようにしています。
1. アーキテクチャの紹介 2. GKEクラスタを本番運用にするためにやった工夫 3. GKEのオートプロビジョニングとスケールアップ 4. gRPCのバランシングのEnvoyの設定 5. リクエストを取りこぼさないためにやったこと
後半:DatadogAPMとOpencensusでのモニタリング
Ⅰ リクエストを取りこぼさないためにやったこと① アプリのGraceful Shutdown // Stop datadog exporter cleanly defer
a.datadog.Stop() go func() { _ = a.server.Serve(listenPort) }() // Wait for signal sigCh := make(chan os.Signal, 1) signal.Notify( sigCh, syscall.SIGHUP, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT) log.Printf("SIGNAL %d received, then shutting down...\n", <-sigCh) a.server.GracefulStop() gRPCのGraceful Shutdownを実 装しました。 GracefulStop()を使っています。 またDatadog Exporterにメトリ クスを投げているためdeferで止 めています。 terminationGracePeriodSecon dsも指定しています。
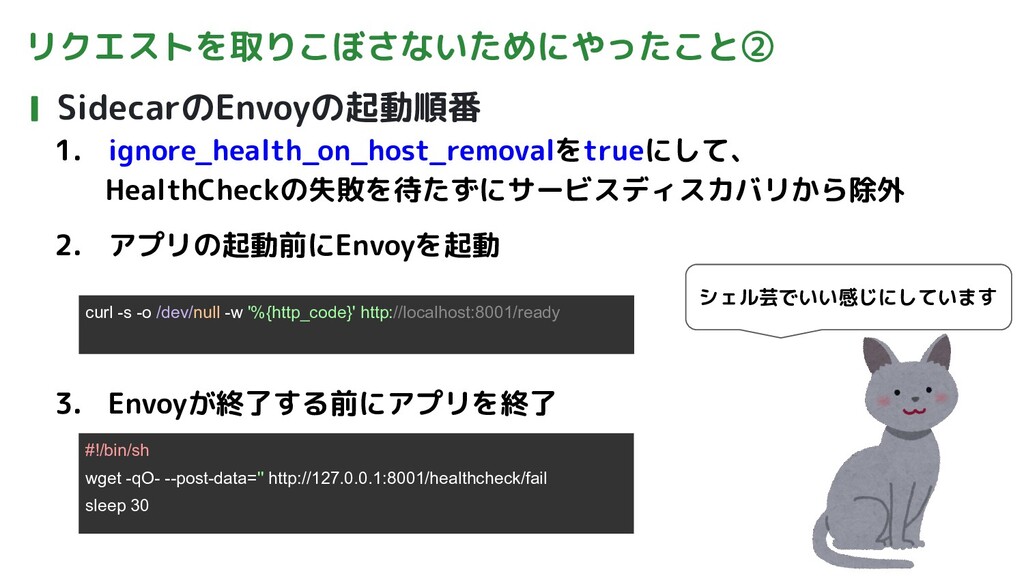
リクエストを取りこぼさないためにやったこと② SidecarのEnvoyの起動順番 1. ignore_health_on_host_removalをtrueにして、 HealthCheckの失敗を待たずにサービスディスカバリから除外 2. アプリの起動前にEnvoyを起動 3. Envoyが終了する前にアプリを終了 #!/bin/sh
wget -qO- --post-data='' http://127.0.0.1:8001/healthcheck/fail sleep 30 curl -s -o /dev/null -w '%{http_code}' http://localhost:8001/ready シェル芸でいい感じにしています
定期的なクラスタアップグレードや機能追加 定期的・継続的にアップグレードや機能追加をすることで システムの価値を維持・向上し続けることができます。 そのためのリクエストを取りこぼさない工夫でした。 GKEは3つのマイナーバージョンをサポート EnvoyのDataplane APIのLifecycleは最大3つのメジャーバージョン 開発スピードが早い
アーキテクチャの紹介 GKEのオートプロビジョニングとスケールアップ gRPCのバランシングのEnvoyの設定 リクエストを取りこぼさないためにやったこと DatadogAPMとOpencensusでのモニタリング 後半:アプリやマイクロサービスについて
Kubernatesの監視体制 外形監視: Datadog Synthetic 内形監視: Datadog DeploymentのDesired/Available, PodのRestart回数 GSLBと各APIのレイテンシやStatusの監視, NodeのStatus,ノードのDisk使用量etc
ログ監視: Stackdriver Logging トレース/APM: DatadogAPM/OpenCensus 通知先: Slack/メーリングリスト ドキュメント管理: esa Datadogでの監視の知見が多いの で使用していますDashboardを なるべく統一したいのもあります
DatadogAPMとOpenCensusでのモニタリング APM(Application Performance Monitoring)でアプリの稼働状況を監視 - DatadogのDashboardに出力したいので設定はAPMの有効化ぐらい - エンドポイント毎にLATENCYとERROR RATEが表示できる #
Enable APM and Distributed Tracing apmEnabled: true ◆Datadogはhelmfileで管理しています エンドポイント名
DatadogAPMとOpenCensusでのモニタリング OpenCensusでTrace,Stats情報を取得 Datadog Exporterへ送信 - StatsはPrometheus Exporterへ変更を対応中 - Agentのリソース負担を減らすため -
DogStatsD経由でメトリクスを送らないため - OpenTelemetryに移行させたい 当初DatadogAPMを有効化するか、自前 でJaegerをたてるか悩み、DatadogAPM のライブラリを使わずにOpencensusで取 得している背景があります
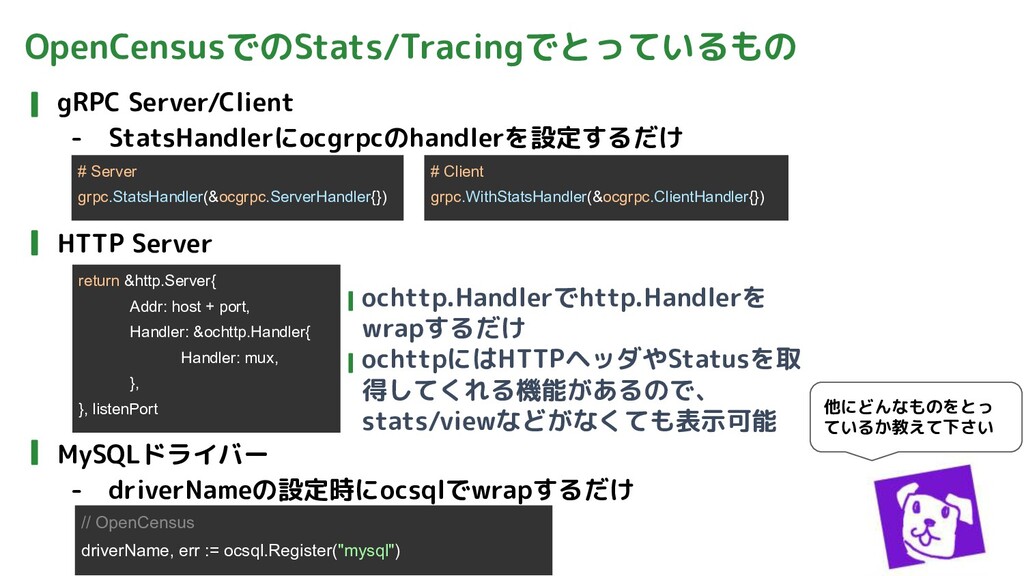
OpenCensusでのStats/Tracingでとっているもの gRPC Server/Client - StatsHandlerにocgrpcのhandlerを設定するだけ HTTP Server MySQLドライバー - driverNameの設定時にocsqlでwrapするだけ
他にどんなものをとっ ているか教えて下さい # Server grpc.StatsHandler(&ocgrpc.ServerHandler{}) # Client grpc.WithStatsHandler(&ocgrpc.ClientHandler{}) return &http.Server{ Addr: host + port, Handler: &ochttp.Handler{ Handler: mux, }, }, listenPort ochttp.Handlerでhttp.Handlerを wrapするだけ ochttpにはHTTPヘッダやStatusを取 得してくれる機能があるので、 stats/viewなどがなくても表示可能 // OpenCensus driverName, err := ocsql.Register("mysql")
次はアプリ側 のおはなし
荻野陽太 CyberAgent, Inc. Ameba事業本部 AmebaPickDiv サーバサイドエンジニア 新卒2年目 Ameba Pickの開発をしています
1. マイクロサービスを採用した理由 2. マイクロサービスの設計 3. システム構成について 4. マイクロサービス間でのエラーハンドリング 5. マイクロサービスのデプロイ
1. マイクロサービスを採用した理由 2. マイクロサービスの設計 3. システム構成について 4. マイクロサービス間でのエラーハンドリング 5. マイクロサービスのデプロイ
Ⅰ 開発初期のチーム状況 サーバーチームのメンバー: 8人 クラウドネイティブを使った開発経験があった人:2人 ほとんどのメンバーがクラウドネイティブを使った開発経験がなかった! 手探りで開発を進めて いきました
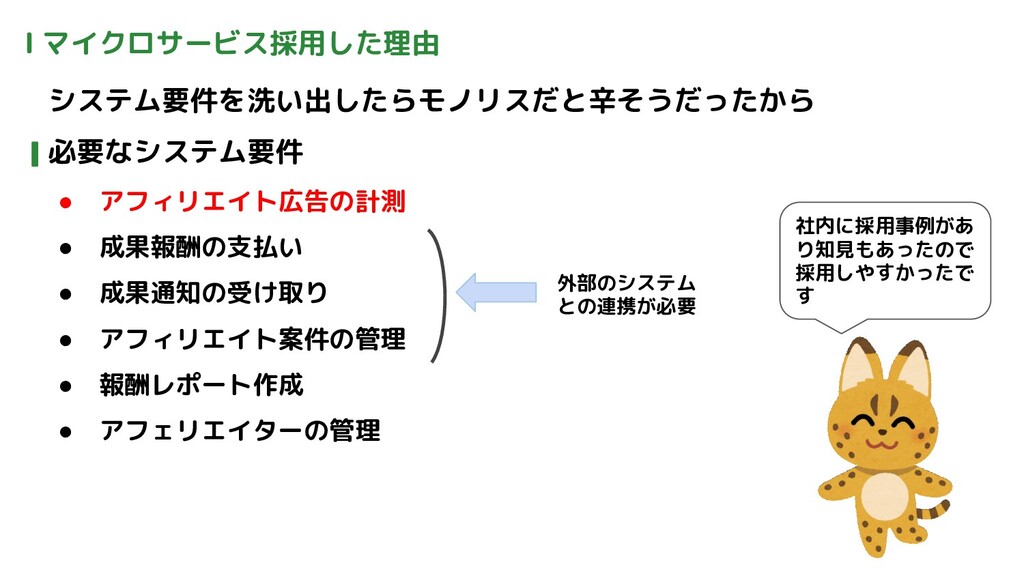
Ⅰ マイクロサービス採用した理由 システム要件を洗い出したらモノリスだと辛そうだったから 必要なシステム要件 • アフィリエイト広告の計測 • 成果報酬の支払い • 成果通知の受け取り
• アフィリエイト案件の管理 • 報酬レポート作成 • アフェリエイターの管理 社内に採用事例があ り知見もあったので 採用しやすかったで す 外部のシステム との連携が必要
1. マイクロサービスを採用した理由 2. マイクロサービスの設計 3. システム構成について 4. マイクロサービス間でのエラーハンドリング 5. マイクロサービスのデプロイ
マイクロサービスの設計 ① コンテナオーケストレーションにはKubernatesを採用 • デファクトスタンダードなので採用しない理由がなかった マイクロサービス 間の通信にはgRPCを採用 • HTTP/2を使うので低レイテンシでマイクロサービス間の通信が行える •
Protoocol Buffersを使ったIDLでクライアント・サーバー間でスキーマを共有 できる • IDLからクライアント・サーバーコードの自動生成ができる • エコシステムが充実している
マイクロサービスの設計 ② アーキテクチャにはレイヤードアーキテクチャを採用 開発手法にはDDDを採用(しようとした) • 人員追加や要件追加があり途中からおざなりになった DDDの境界付けられたコンテキストによってマイクロサービスを分割 開発言語にはGolangを採用 • Kotlinという案もあったが、社内での導入事例や人員採用のしやすさを踏まえ
て採用 • Golangを採用したことで結果的にかなりインフラコストを削減できた
1. マイクロサービスを採用した理由 2. マイクロサービスの設計 3. システム構成について 4. マイクロサービス間でのエラーハンドリング 5. マイクロサービスのデプロイ
Ⅰ バックエンドアーキテクチャ ユーザ Private Cloud ブログシステム Services(Pods):gRPC GKE Ingress:HTTP MySQL
Storage 外部 ASP NAT Rest API gRPC喋れない
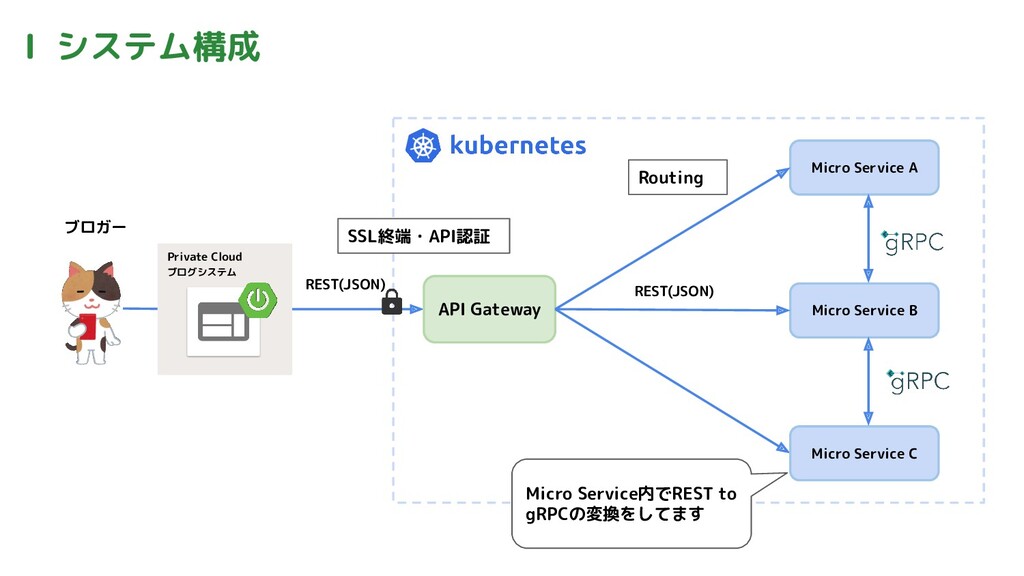
Ⅰ システム構成 ブロガー Private Cloud ブログシステム API Gateway Micro Service
A Micro Service B Micro Service C Routing SSL終端・API認証 Micro Service内でREST to gRPCの変換をしてます REST(JSON) REST(JSON)
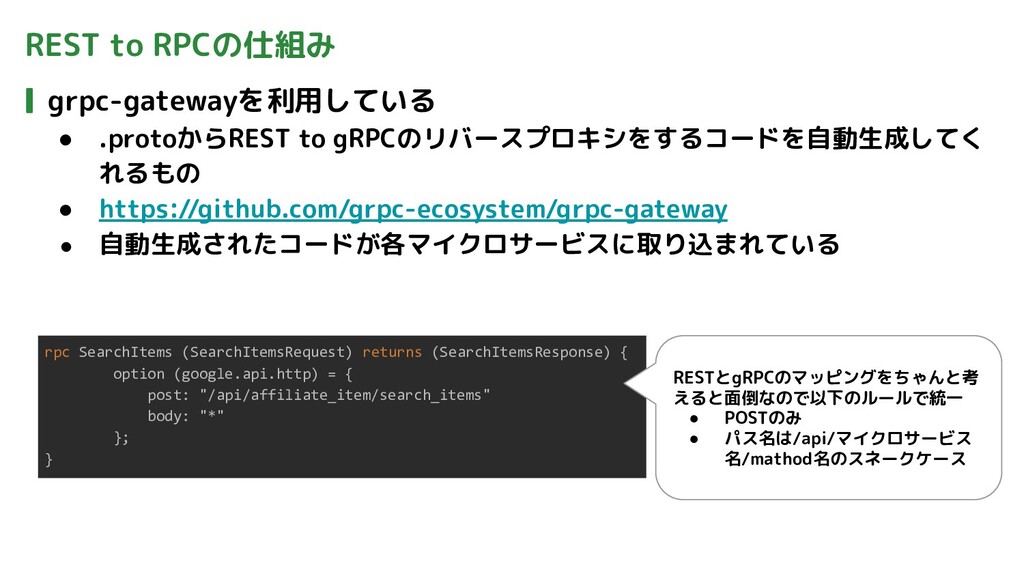
REST to RPCの仕組み grpc-gatewayを利用している • .protoからREST to gRPCのリバースプロキシをするコードを自動生成してく れるもの •
https://github.com/grpc-ecosystem/grpc-gateway • 自動生成されたコードが各マイクロサービスに取り込まれている rpc SearchItems (SearchItemsRequest) returns (SearchItemsResponse) { option (google.api.http) = { post: "/api/affiliate_item/search_items" body: "*" }; } RESTとgRPCのマッピングをちゃんと考 えると面倒なので以下のルールで統一 • POSTのみ • パス名は/api/マイクロサービス 名/mathod名のスネークケース
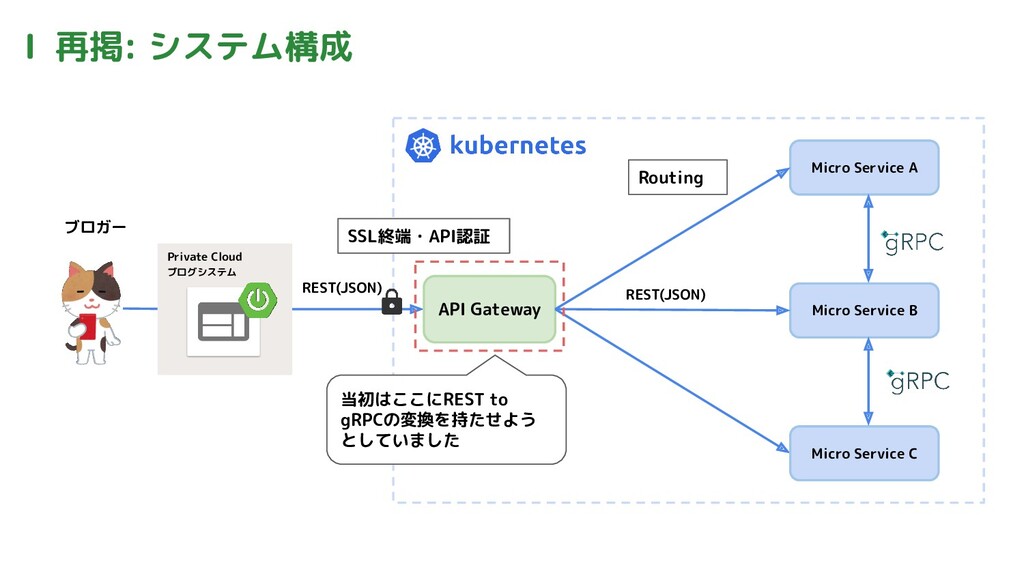
Ⅰ 再掲: システム構成 ブロガー Private Cloud ブログシステム REST(JSON) API Gateway
Micro Service A Micro Service B Micro Service C Routing SSL終端・API認証 当初はここにREST to gRPCの変換を持たせよう としていました REST(JSON)
REST to RPCの仕組み 当初はAPI-GatewayにREST to gRPCの変換機能を持たせようとしていた この方法だとマイクロサービスのデプロイの度にAPI-Gatewayのデプロイ が必要になり辛いのでやめた
1. マイクロサービスを採用した理由 2. マイクロサービスの設計 3. システム構成について 4. マイクロサービス間でのエラーハンドリング 5. マイクロサービスのデプロイ
Ⅰ マイクロサービス間でのエラーハンドリング 共通のエラーコードを定義して、エラーコードを使ってエラーハンドリン グをしている type ApplicationError struct { code string
message string gRPCStatusCode codes.Code } var ( UnknownError = newApplicationError("CM500003", "unknown error", codes.Internal) UnavailableError = newApplicationError("CM503001", "unavailable", codes.Unavailable) ) 共通のエラーコードの定義
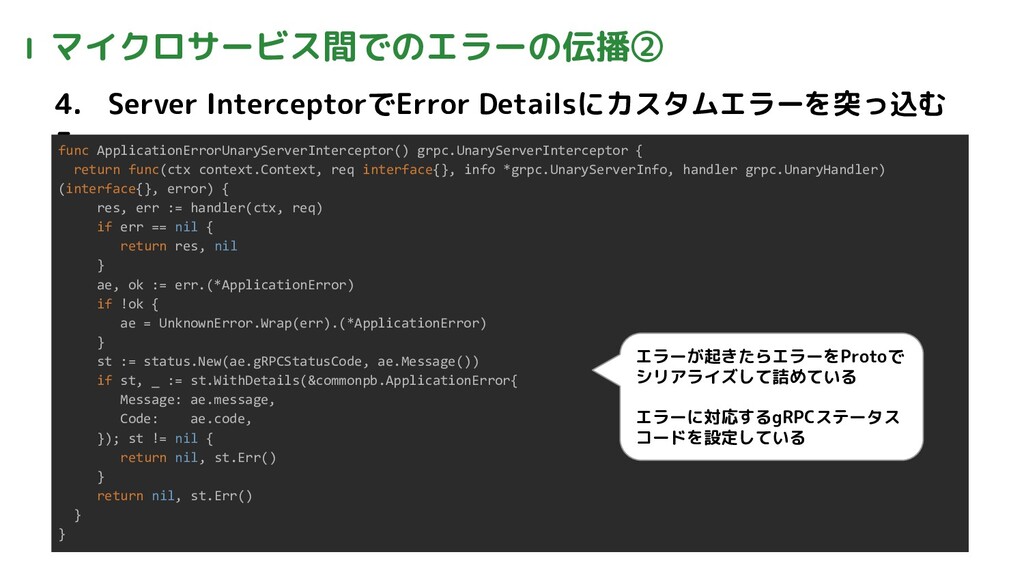
Ⅰ マイクロサービス間でのエラーの伝播① 1. カスタムエラーを定義 2. カスタムエラーをProtocol Buffersで定義 3. エラー時アプリでカスタムエラーを返す message
ApplicationError { string code = 1; string message = 2; } type ApplicationError struct { code string message string gRPCStatusCode codes.Code } var ( UnknownError = newApplicationError("CM500003", "unknown error", codes.Internal) UnavailableError = newApplicationError("CM503001", "unavailable", codes.Unavailable) ) - エラーメッセージ - 共通のエラーコード - エラーに対応するgRPC のステータスコード を定義
Ⅰ マイクロサービス間でのエラーの伝播② 4. Server InterceptorでError Detailsにカスタムエラーを突っ込む 5. func ApplicationErrorUnaryServerInterceptor() grpc.UnaryServerInterceptor
{ return func(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (interface{}, error) { res, err := handler(ctx, req) if err == nil { return res, nil } ae, ok := err.(*ApplicationError) if !ok { ae = UnknownError.Wrap(err).(*ApplicationError) } st := status.New(ae.gRPCStatusCode, ae.Message()) if st, _ := st.WithDetails(&commonpb.ApplicationError{ Message: ae.message, Code: ae.code, }); st != nil { return nil, st.Err() } return nil, st.Err() } } エラーが起きたらエラーをProtoで シリアライズして詰めている エラーに対応するgRPCステータス コードを設定している
Ⅰ マイクロサービス間でのエラーの伝播③ 5. Client InterceptorでError Detailsからカスタムエラーを取り出す func ApplicationErrorUnaryClientInterceptor() grpc.UnaryClientInterceptor {
return func(ctx context.Context, method string, req, reply interface{}, cc *grpc.ClientConn, invoker grpc.UnaryInvoker, opts ...grpc.CallOption) error { err := invoker(ctx, method, req, reply, cc, opts...) if err == nil { return nil } st := status.Convert(err) for _, d := range st.Details() { switch t := d.(type) { case *commonpb.ApplicationError: return newApplicationError(t.GetCode(), t.GetMessage(), st.Code()) } } //不明なエラー return UnknownError.Wrap(err) } } Error DetailからProtoでシリアラ イズされたエラーを取り出してデシ リアライズしている
1. マイクロサービスを採用した理由 2. マイクロサービスの設計 3. システム構成について 4. マイクロサービス間でのエラーハンドリング 5. マイクロサービスのデプロイ
マイクロサービスのデプロイ ブランチモデルにはGithub-Flowを採用 CIOpsを採用 • CI/CDに時間をかけたくなかった • Manifestとアプリケーションコードを同一リポジトリで管理している • CIにK8sの強い権限を渡たす必要があったり、Manifestの軽微な変更でもイ メージのビルドが走るなどの課題もある...
将来的にはGitOps に移行していきたい と考えています
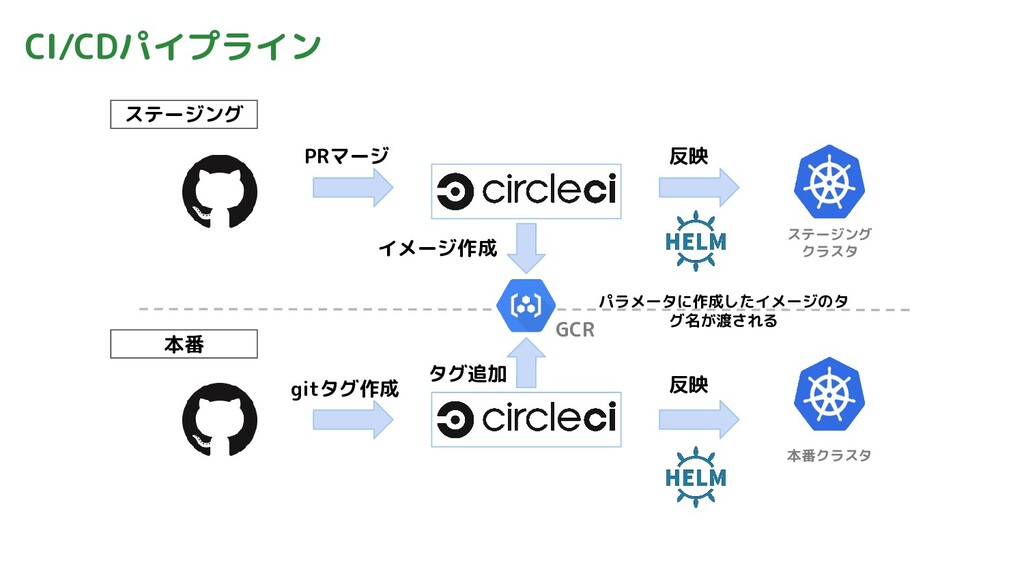
CI/CDパイプライン GCR 本番クラスタ ステージング クラスタ ステージング 本番 PRマージ 反映 反映
イメージ作成 タグ追加 gitタグ作成 パラメータに作成したイメージのタ グ名が渡される
Manifestの管理 最初はKustomizeを使っていた... • yaml差分を書くのが面倒臭い • 使い回しがしづらい • Command Lineからパラメータを渡せないのが辛い 結局Helmを採用した
• Kustomizeに比べて学習コストが高いが一度Chartを作れば使いまわせる! • Command Lineからパラメータを渡せる!
Secretsの管理 最初はkubesecを利用 • Secret の構造を保ったまま値だけ暗号化してくれるもの • https://github.com/shyiko/kubesec 現在はhelm-secretsを採用 • HelmのPlugin
• HelmのValuesファイルを暗号化してくれるもの • デプロイも簡単! helm install が helm secrets installになるだけ • https://github.com/zendesk/helm-secrets External Secretsを採用するのもアリだったかも...
ご清聴ありがとう ございました
CAではSRE・ バックエンドエンジニ アを募集しています https://www.cyberagent.co.jp/careers/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}