at Kafka & Flink High level overview of Apache Iceberg Lakehouse to the rescue 02 01 Challenges with Data Warehouse & Data Lake 06 Take-home Demo followed by Q&A
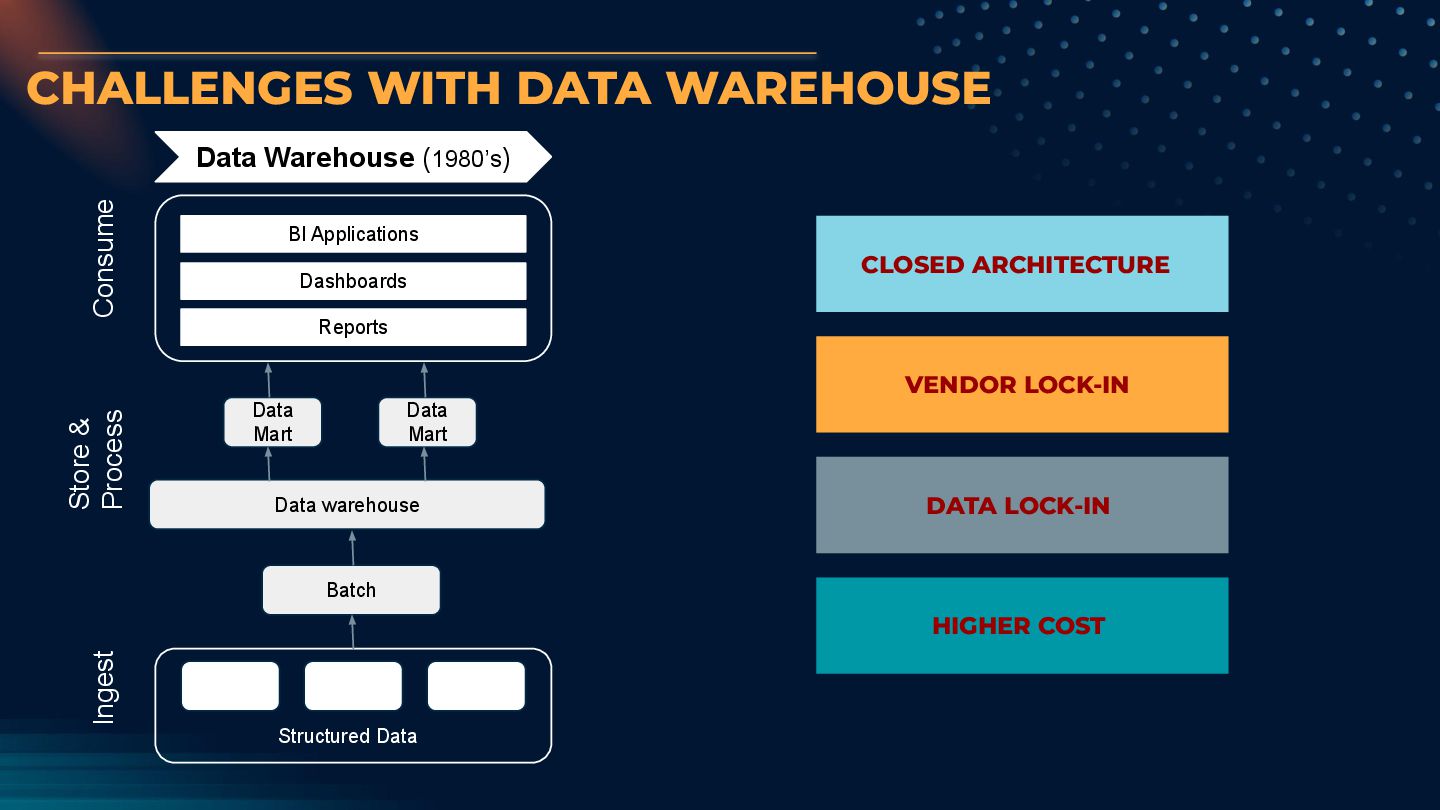
Reports Data Mart Data Mart Data warehouse Batch Structured Data Ingest Store & Process Consume CLOSED ARCHITECTURE VENDOR LOCK-IN DATA LOCK-IN HIGHER COST
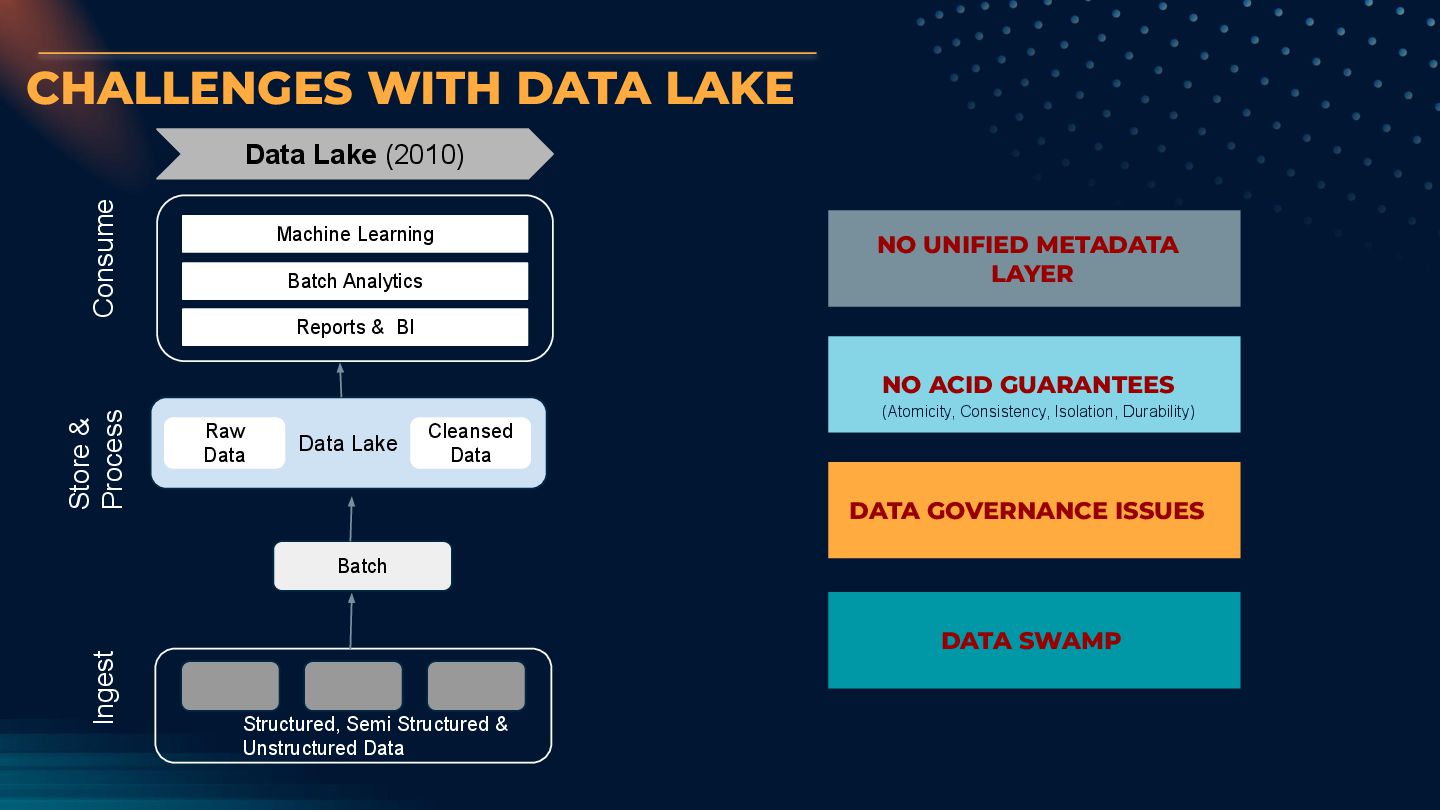
Process Consume Machine Learning Batch Analytics Reports & BI Data Lake Raw Data Cleansed Data Batch Structured, Semi Structured & Unstructured Data DATA GOVERNANCE ISSUES NO UNIFIED METADATA LAYER DATA SWAMP NO ACID GUARANTEES (Atomicity, Consistency, Isolation, Durability)
different platforms without interoperability DATA DUPLICATION Data copied across to process with different engines or platforms DATA SYNCH ISSUES Data copies are not in synch always EXPENSIVE Drives costs higher
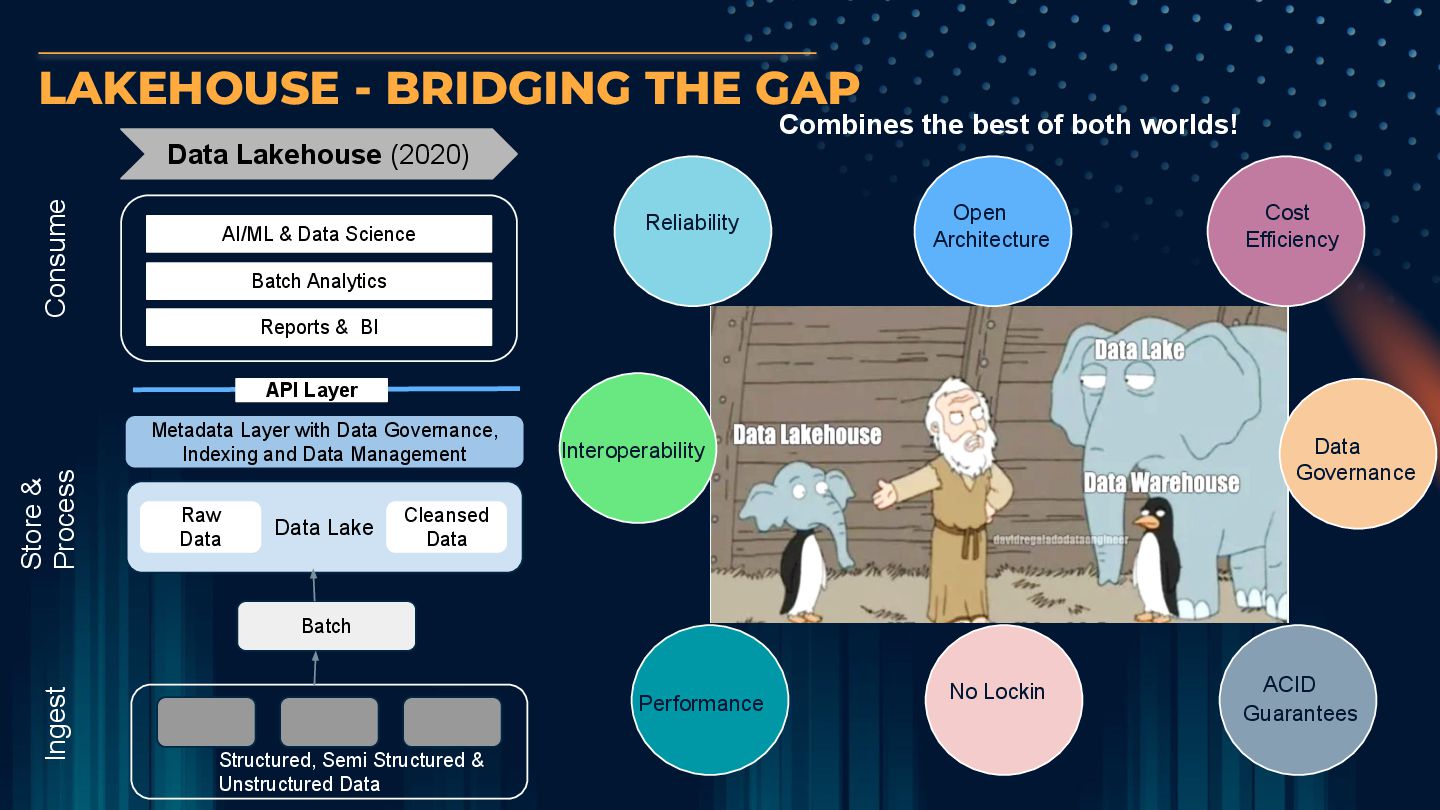
Data Science Batch Analytics Reports & BI Data Lake Raw Data Cleansed Data Batch Structured, Semi Structured & Unstructured Data LAKEHOUSE - BRIDGING THE GAP Metadata Layer with Data Governance, Indexing and Data Management Combines the best of both worlds! Reliability Performance ACID Guarantees Open Architecture Cost Efficiency No Lockin Interoperability Data Governance API Layer
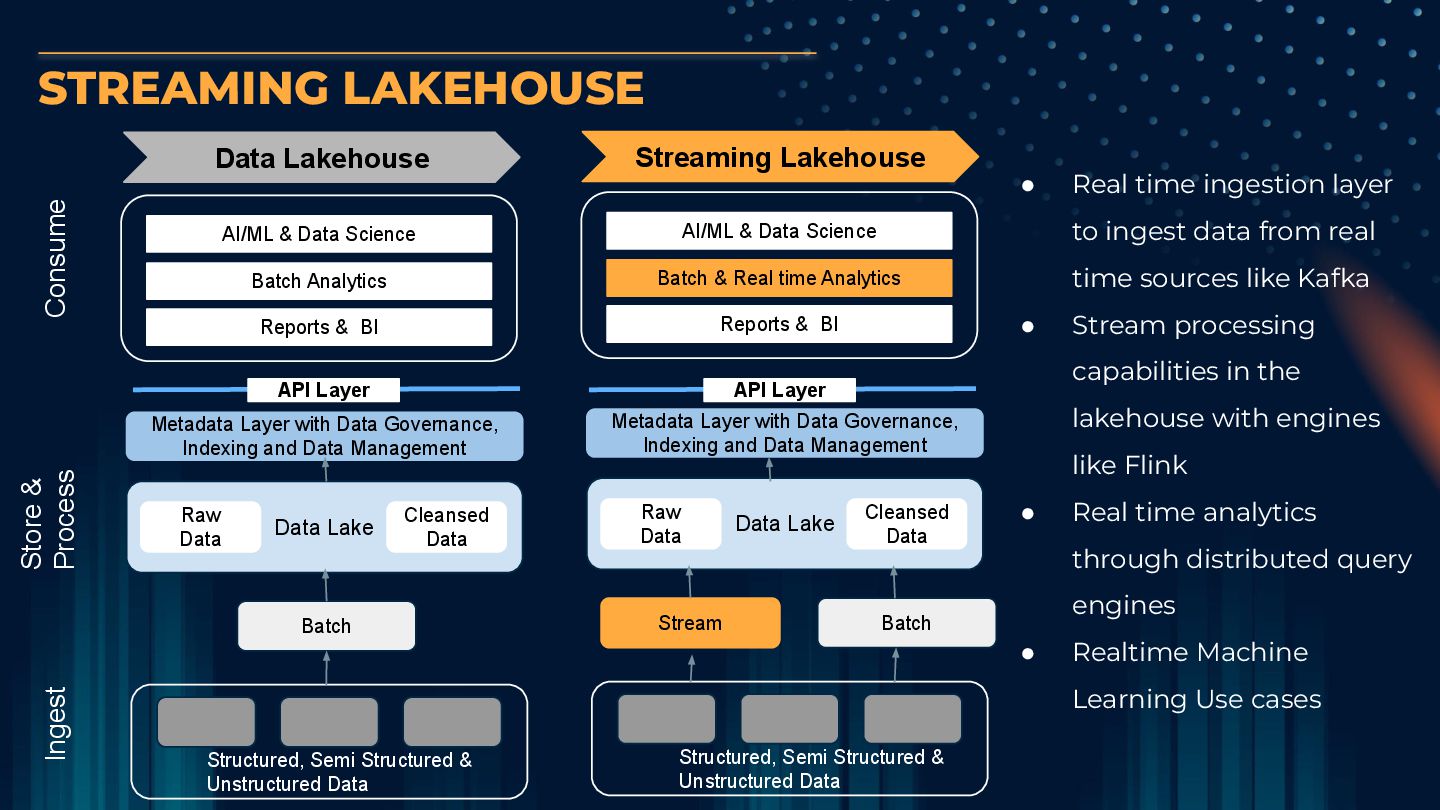
Analytics Reports & BI Data Lake Raw Data Cleansed Data Batch Structured, Semi Structured & Unstructured Data STREAMING LAKEHOUSE Metadata Layer with Data Governance, Indexing and Data Management AI/ML & Data Science Batch & Real time Analytics Reports & BI Data Lake Raw Data Cleansed Data Stream Batch Structured, Semi Structured & Unstructured Data Metadata Layer with Data Governance, Indexing and Data Management • Real time ingestion layer to ingest data from real time sources like Kafka • Stream processing capabilities in the lakehouse with engines like Flink • Real time analytics through distributed query engines • Realtime Machine Learning Use cases Data Lakehouse Streaming Lakehouse API Layer API Layer
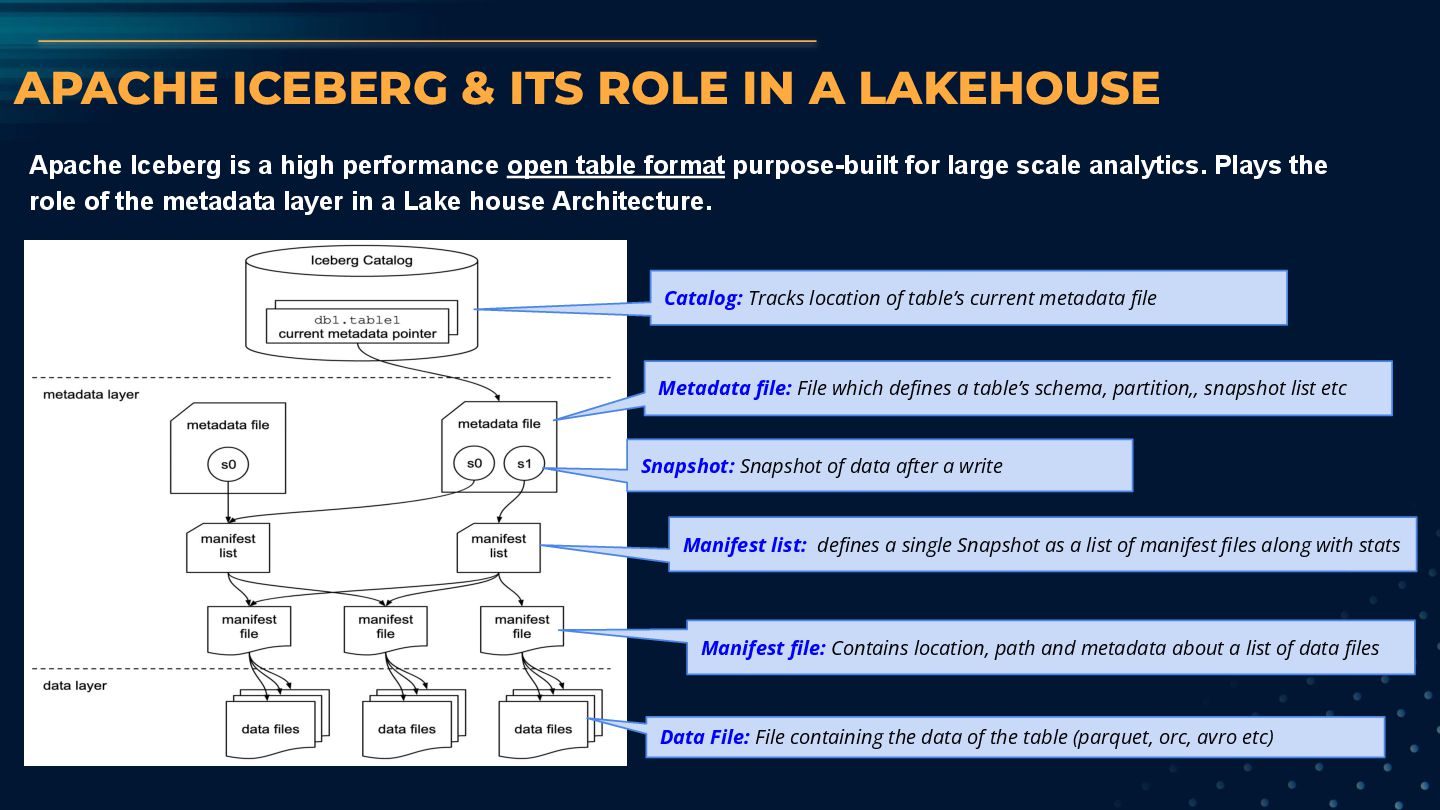
is a high performance open table format purpose-built for large scale analytics. Plays the role of the metadata layer in a Lake house Architecture. Catalog: Tracks location of table’s current metadata file Metadata file: File which defines a table’s schema, partition,, snapshot list etc Snapshot: Snapshot of data after a write Manifest file: Contains location, path and metadata about a list of data files Manifest list: defines a single Snapshot as a list of manifest files along with stats Data File: File containing the data of the table (parquet, orc, avro etc)
Catalog - Databricks acquired Tabular, a company founded by the original creators of Iceberg. Also open sourced Unity Catalog - All major cloud & data platform providers supports Iceberg (Confluent Table Flow, AWS S3 Tables, GCP BigQuery Tables etc) - Cloudflare has announced R2 Data Catalog (Iceberg REST Catalog) just last week And the Winner is Iceberg
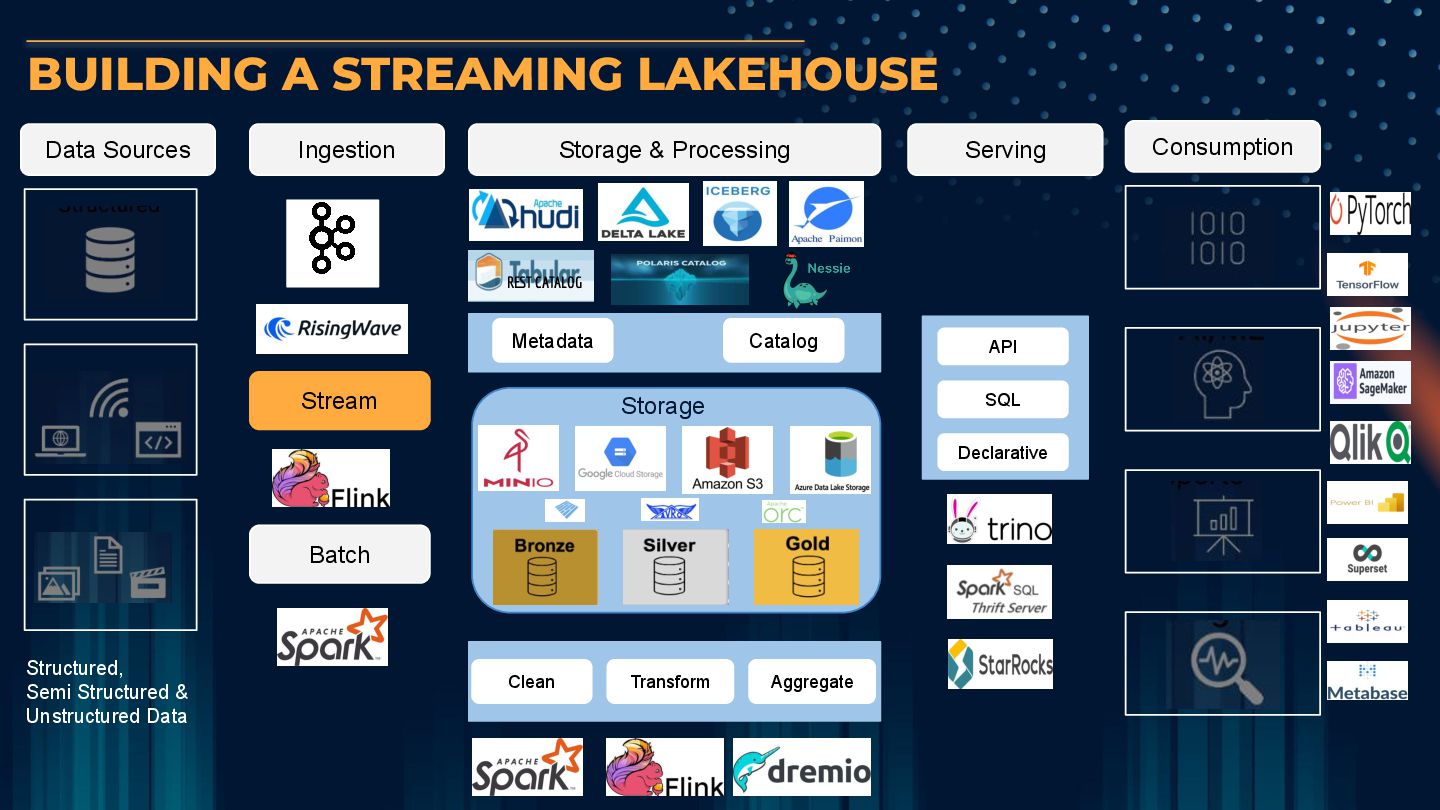
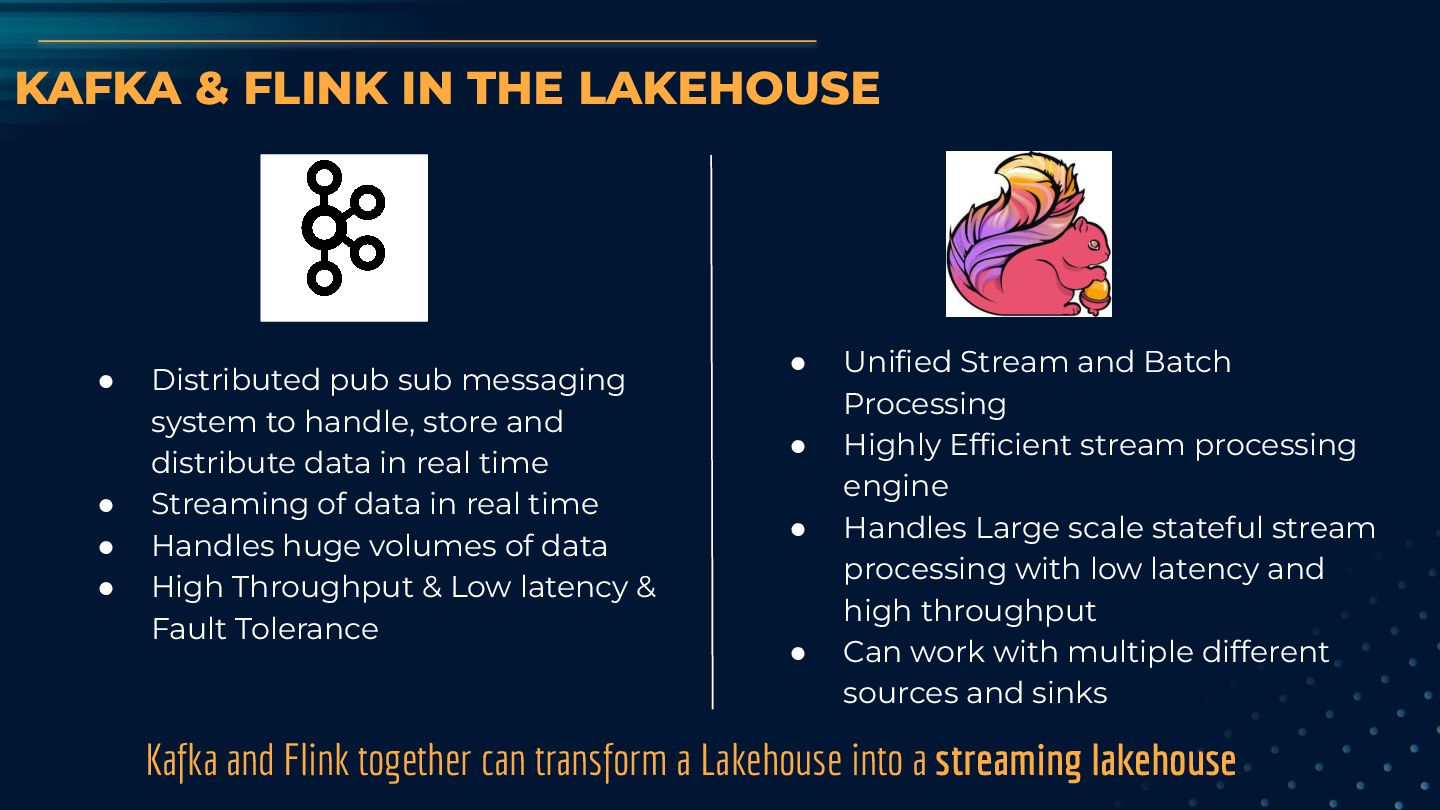
messaging system to handle, store and distribute data in real time • Streaming of data in real time • Handles huge volumes of data • High Throughput & Low latency & Fault Tolerance • Unified Stream and Batch Processing • Highly Efficient stream processing engine • Handles Large scale stateful stream processing with low latency and high throughput • Can work with multiple different sources and sinks Kafka and Flink together can transform a Lakehouse into a streaming lakehouse
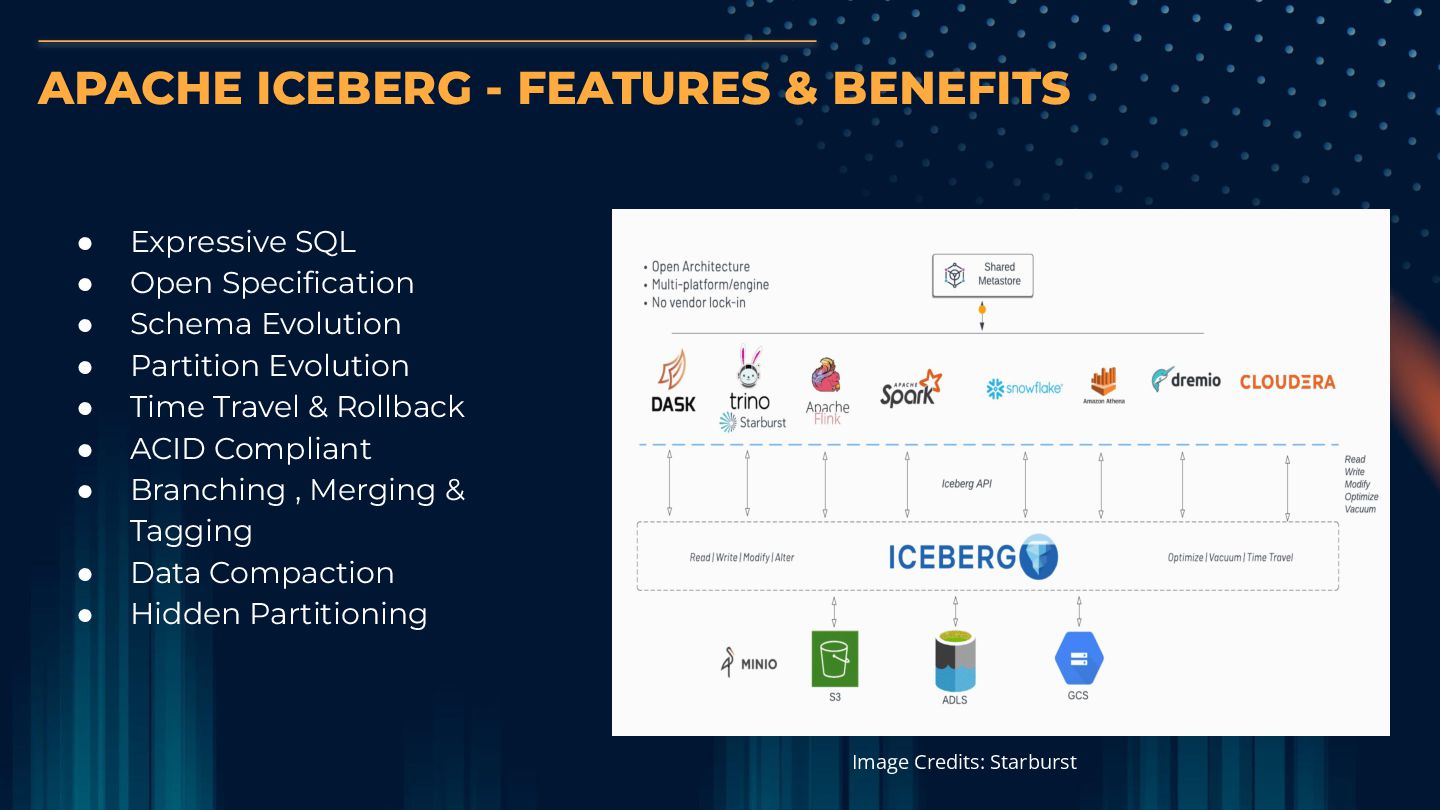
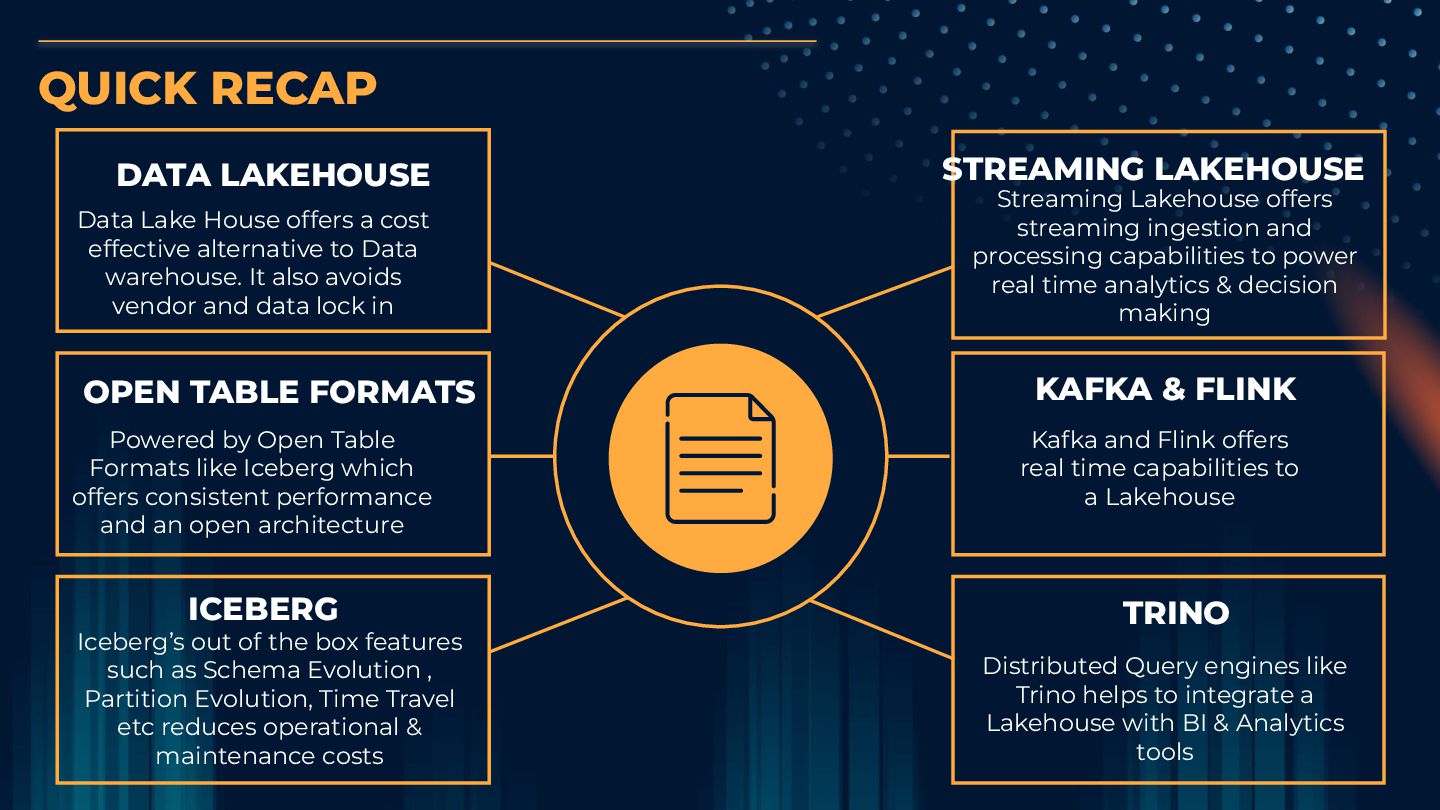
effective alternative to Data warehouse. It also avoids vendor and data lock in ICEBERG Iceberg’s out of the box features such as Schema Evolution , Partition Evolution, Time Travel etc reduces operational & maintenance costs OPEN TABLE FORMATS Powered by Open Table Formats like Iceberg which offers consistent performance and an open architecture STREAMING LAKEHOUSE Streaming Lakehouse offers streaming ingestion and processing capabilities to power real time analytics & decision making TRINO Distributed Query engines like Trino helps to integrate a Lakehouse with BI & Analytics tools KAFKA & FLINK Kafka and Flink offers real time capabilities to a Lakehouse
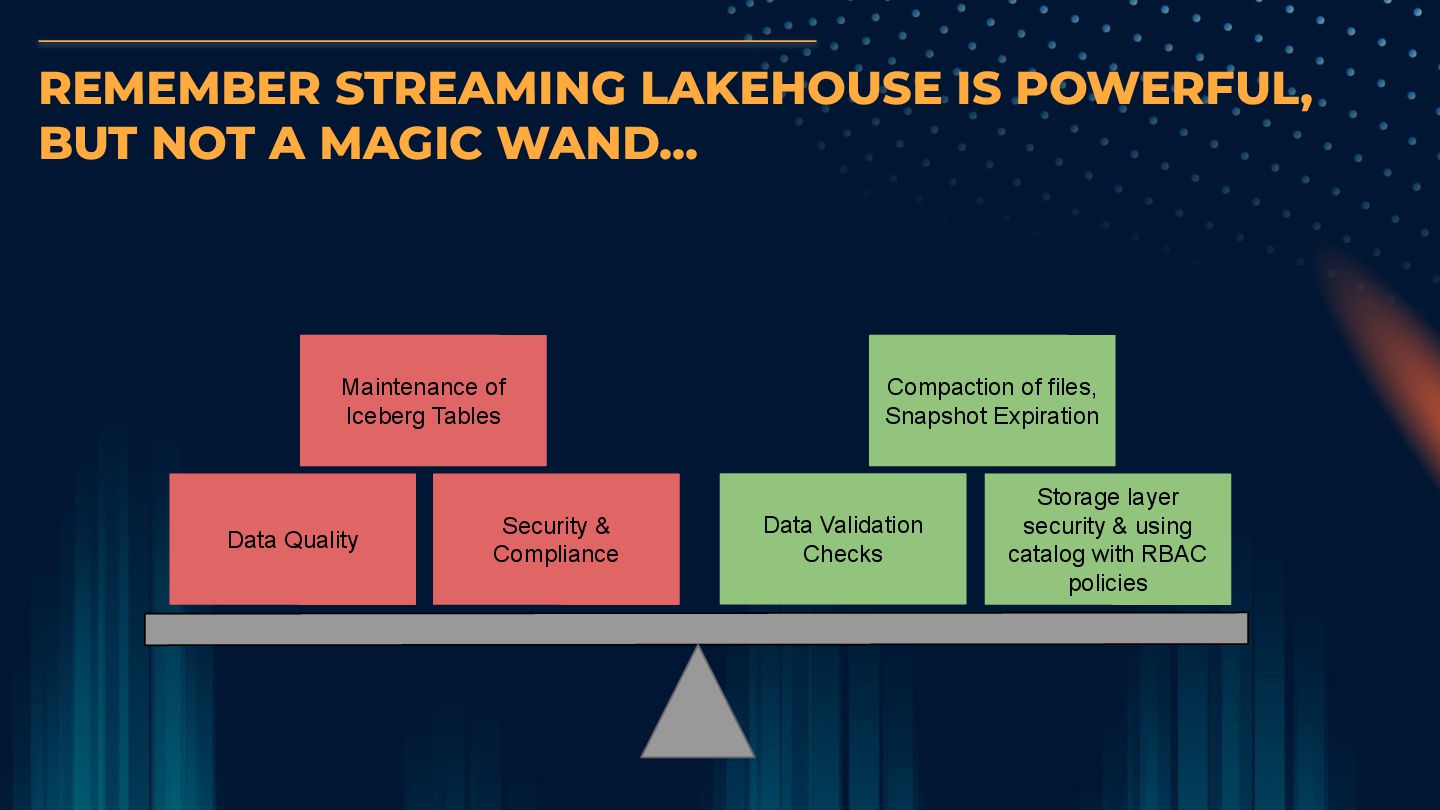
Data Quality Security & Compliance Maintenance of Iceberg Tables Storage layer security & using catalog with RBAC policies Data Validation Checks Compaction of files, Snapshot Expiration
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}