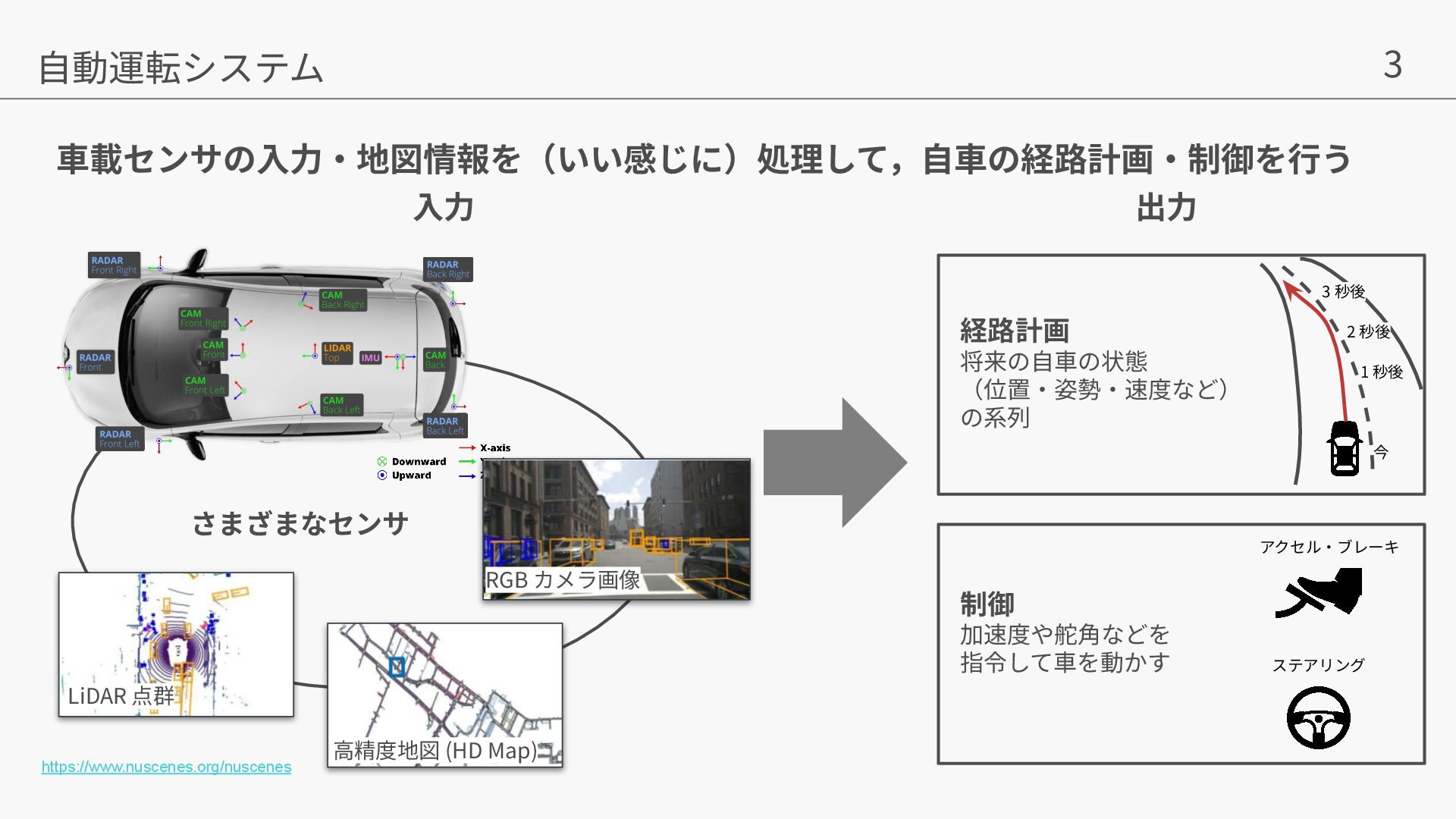
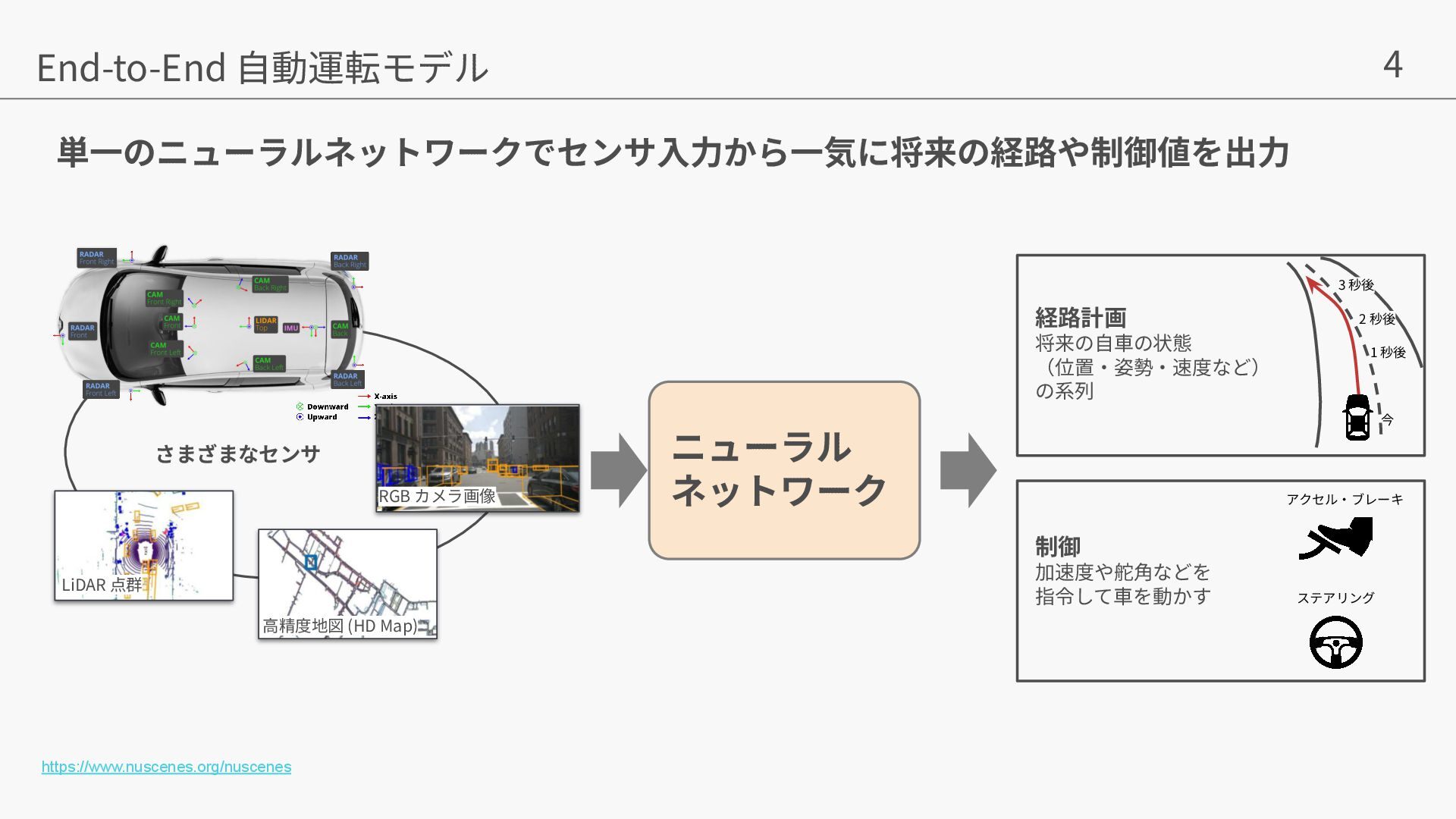
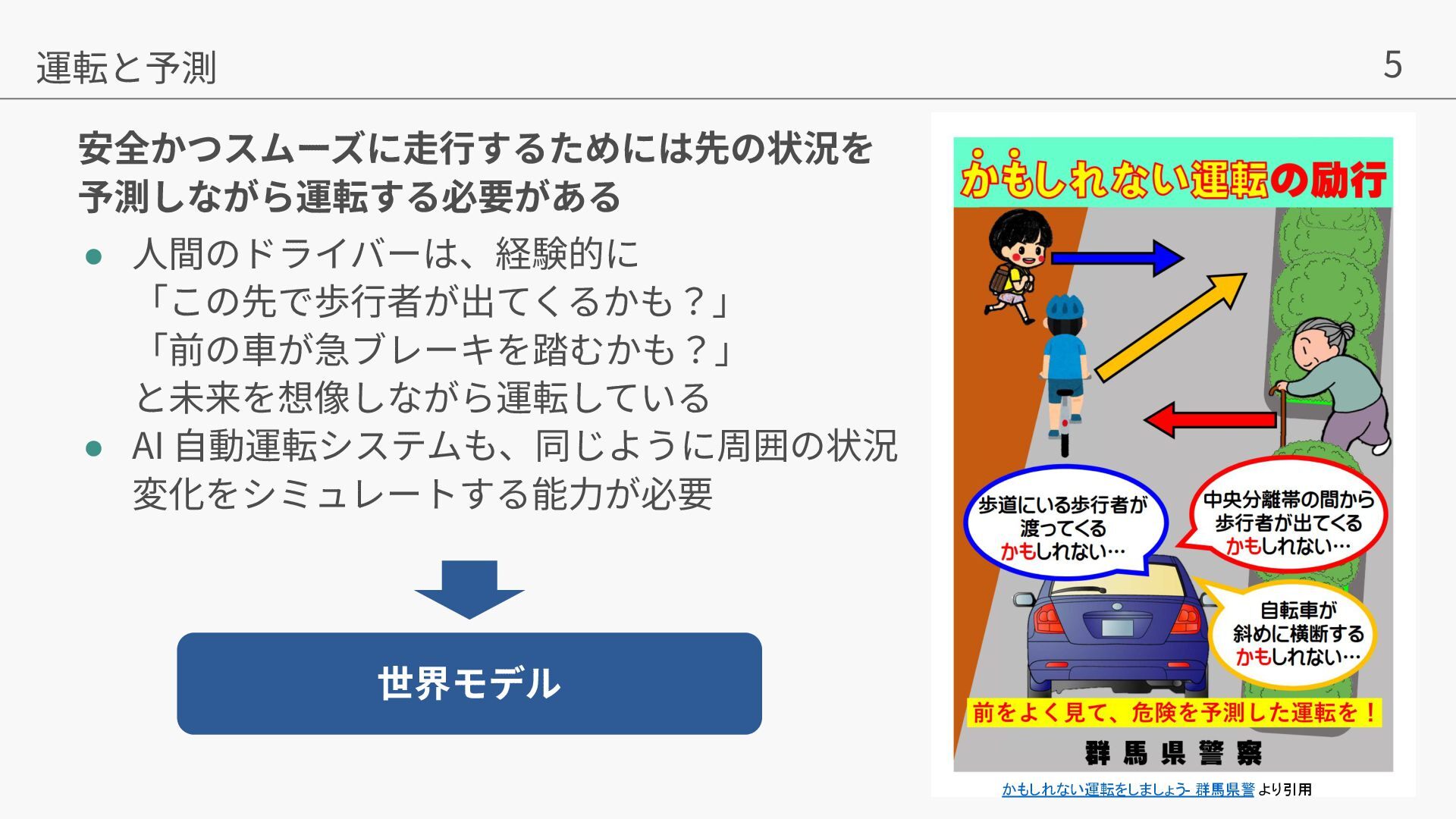
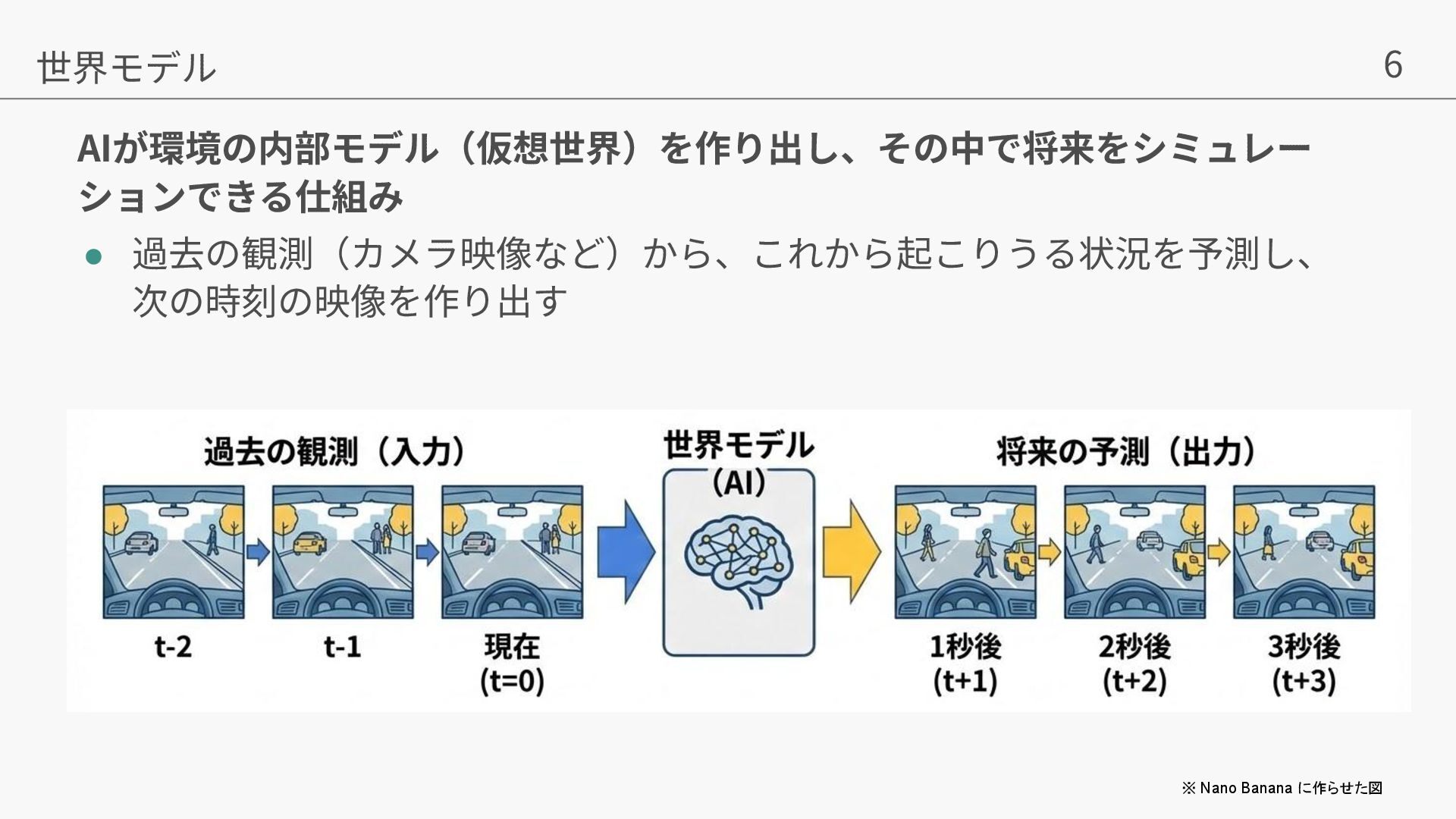
Liu, William T. Freeman. MaskGIT: Masked Generative Image Transformer. In CVPR, 2022. • [Flow Matching] Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le.Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022. • [GEM] Mariam Hassan, Sebastian Stapf, Ahmad Rahimi, Pedro Rezende, Yasaman Haghighi, David Brüggemann, Isinsu Katircioglu, Lin Zhang, Xiaoran Chen, Suman Saha, et al. Gem: A generalizable ego-vision multimodal world model for fine-grained ego-motion, object dynamics, and scene composition control. In CVPR, 2025. • [Vista] Shenyuan Gao, Jiazhi Yang, Li Chen, Kashyap Chitta, Yihang Qiu, Andreas Geiger, Jun Zhang, and Hongyang Li. Vista: A generalizable driving world model with high fidelity and versatile controllability. In Advances in Neural Information Processing Systems (NeurIPS), 2024. • [Cosmos] Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575, 2025. • [DrivingWorld] Xiaotao Hu, Wei Yin, Mingkai Jia, Junyuan Deng, Xiaoyang Guo, Qian Zhang, Xiaoxiao Long, and Ping Tan.Drivingworld: Constructingworld model for autonomous driving via video gpt.arXiv preprint arXiv:2412.19505, 2024. • [GAIA-1] Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado.Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080, 2023. • arXiv preprint: https://arxiv.org/pdf/2507.13162v1 • 著者の発表スライド:https://neurips.cc/media/neurips-2025/Slides/118316.pdf • プロジェクトページ: https://lmb-freiburg.github.io/orbis.github.io/ • code: https://github.com/lmb-freiburg/orbis 参考⽂献
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![26 • [MaskGIT] Huiwen Chang, Han Zhang, Lu Jiang, Ce](https://files.speakerdeck.com/presentations/cb4f1807cb574c11a94e0521634f549e/slide_22.jpg){kind=link}
{kind=link}