(Presented at KubeCon + CloudNativeCon Europe 2025 https://kccnceu2025.sched.com/event/1txGQ)
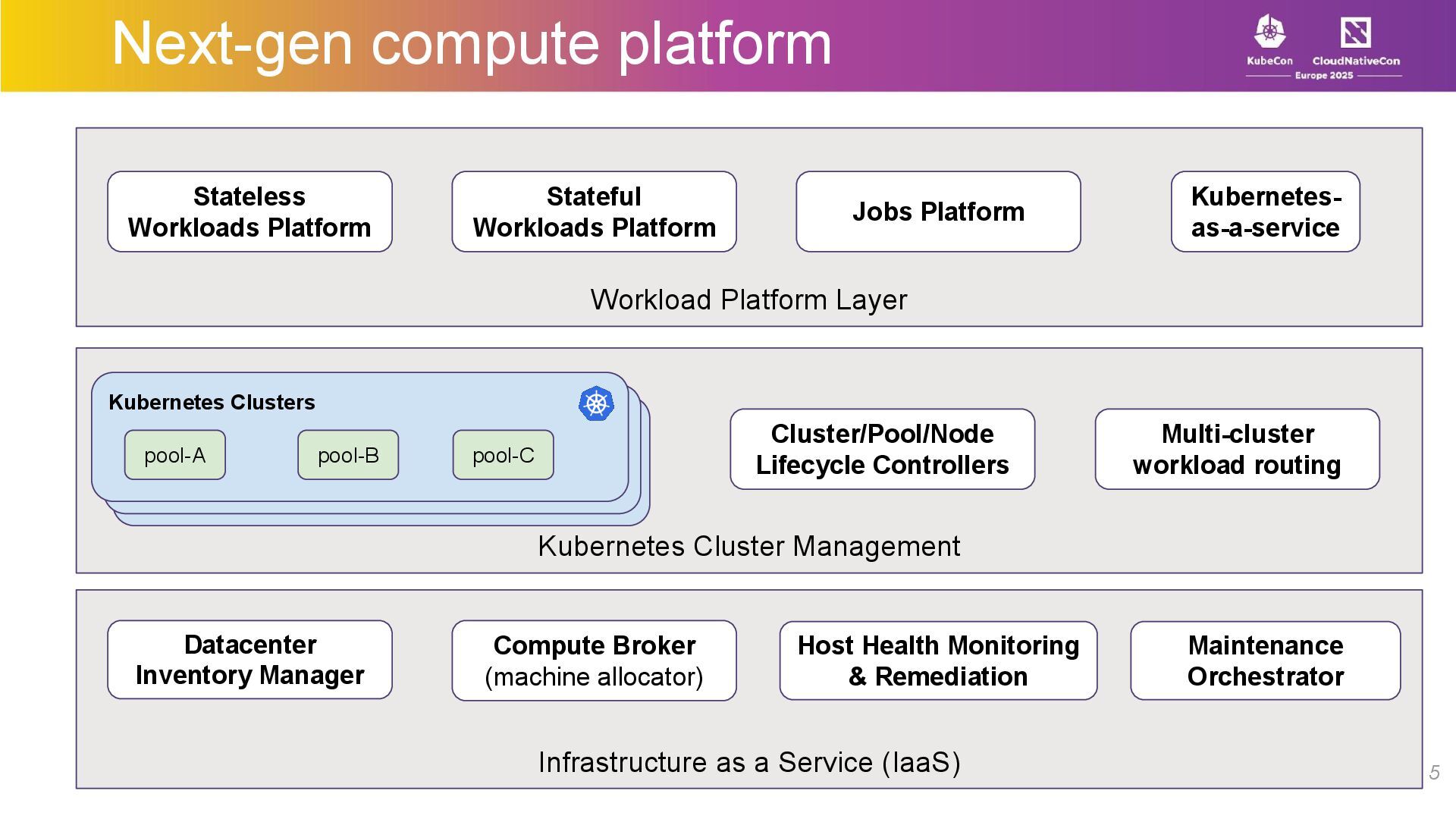
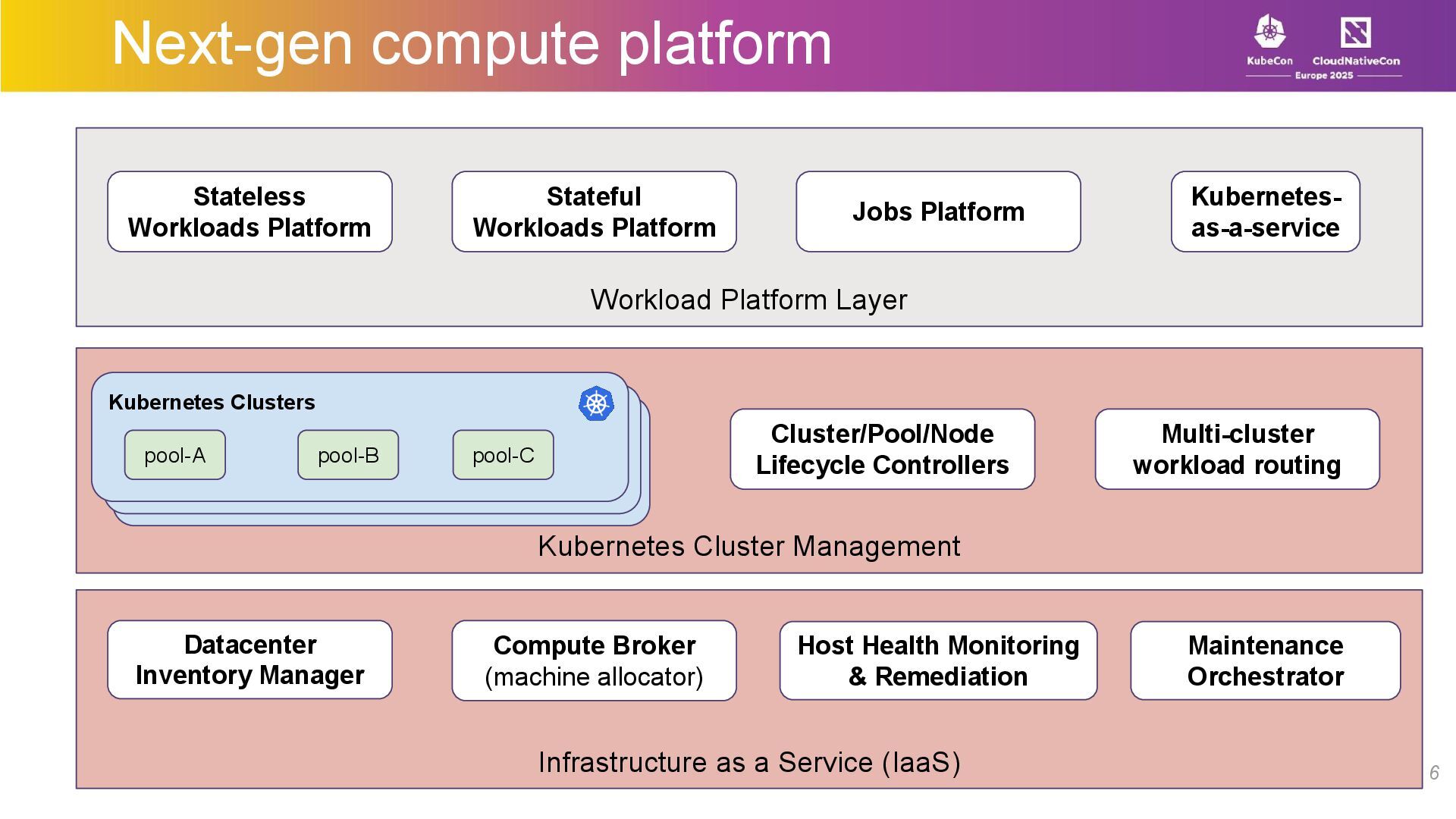
What does it take to design a Kubernetes-based fleet management stack that bridges the gap between bare-metal servers in data centers and a platform capable of hosting thousands of microservices, large-scale stateful applications, and a GPU fleet running AI workloads?
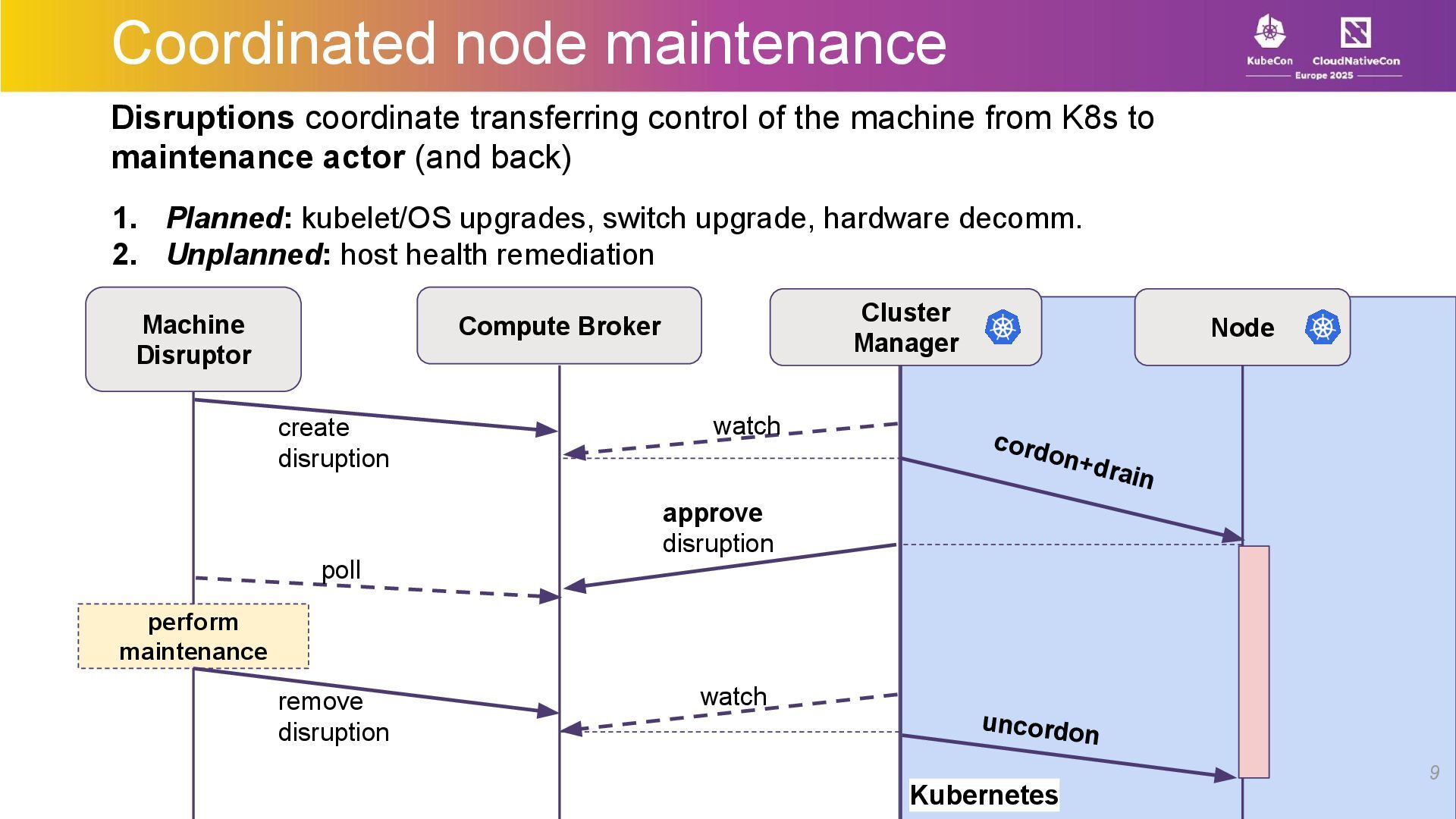
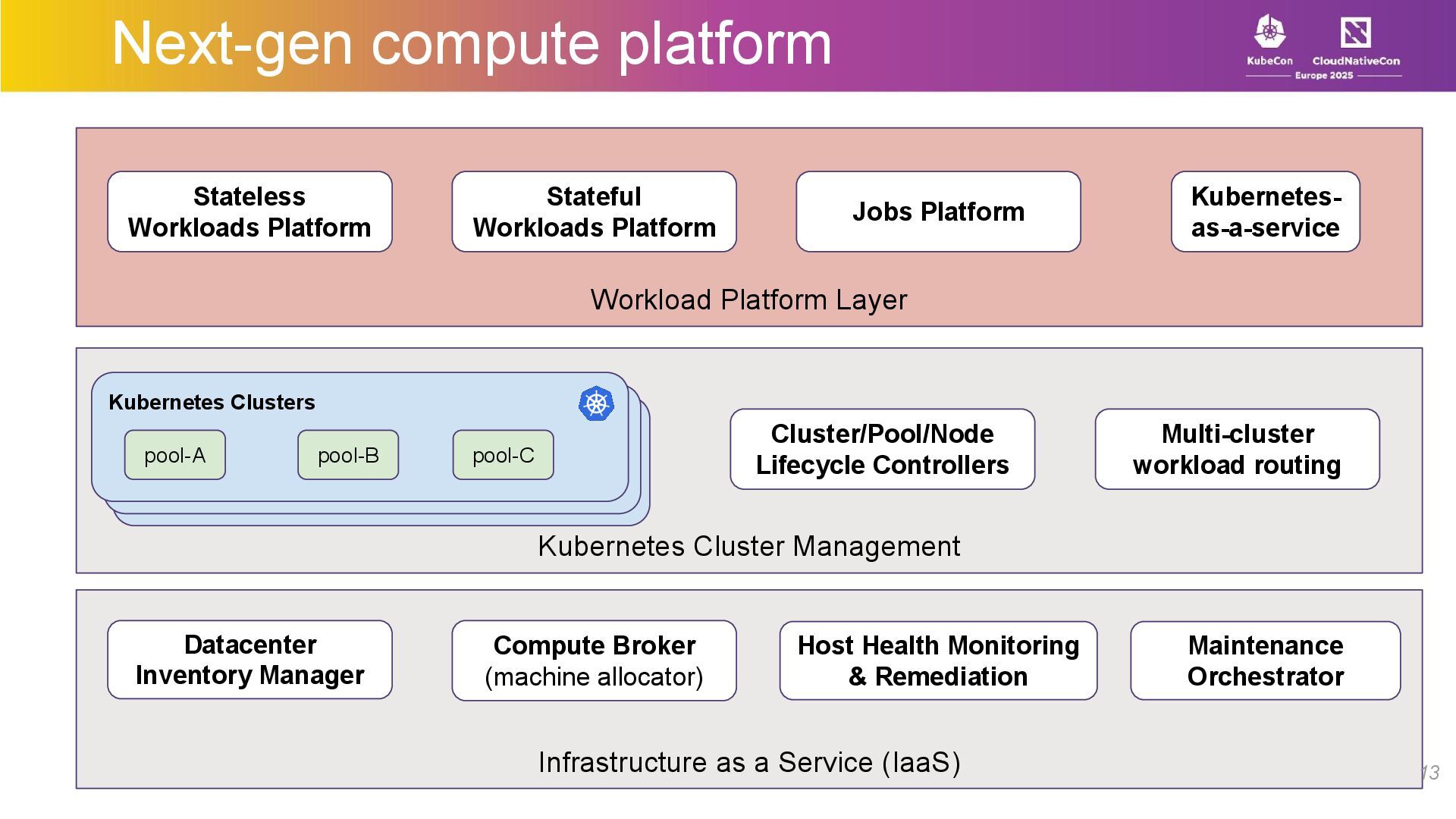
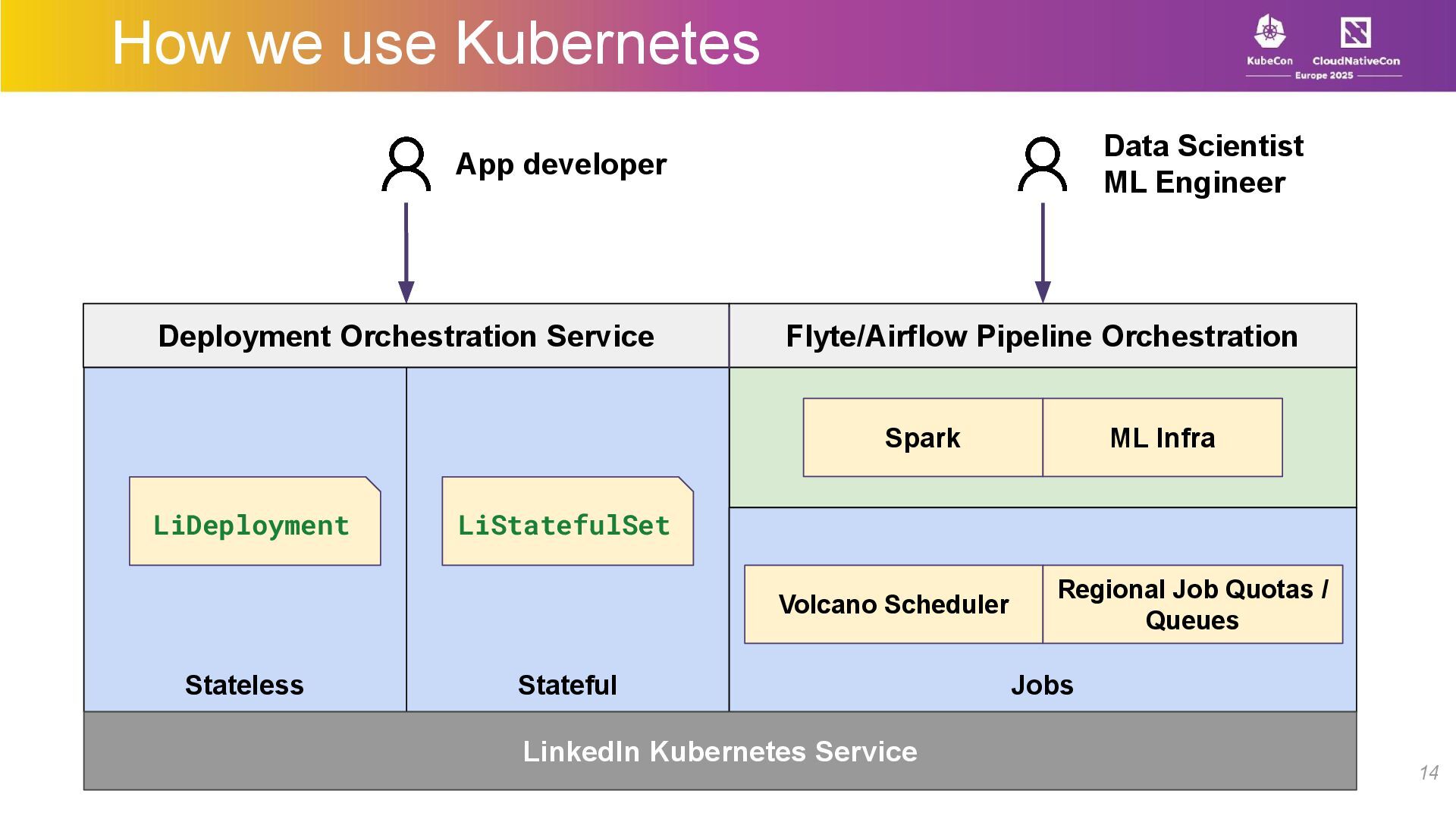
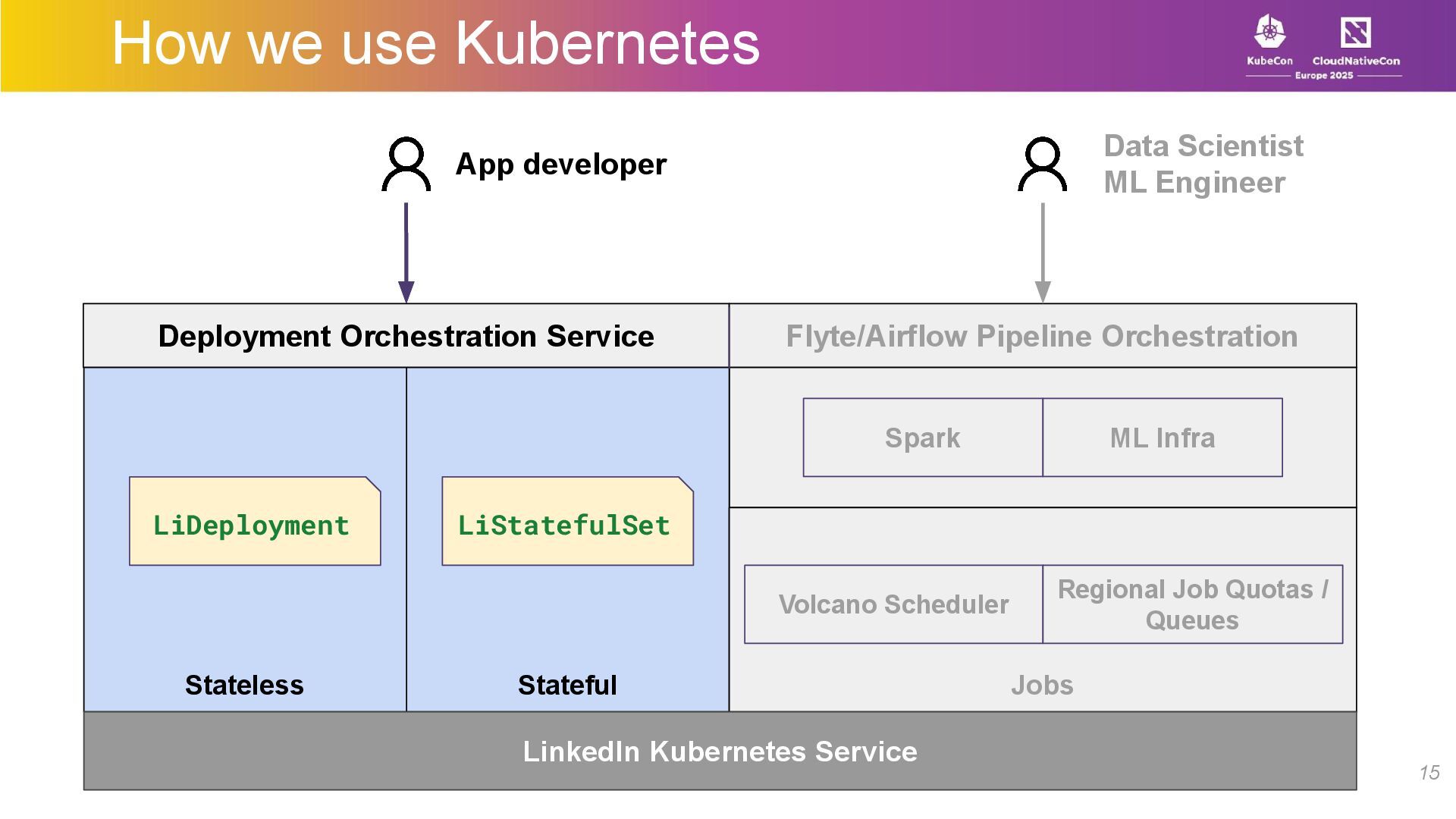
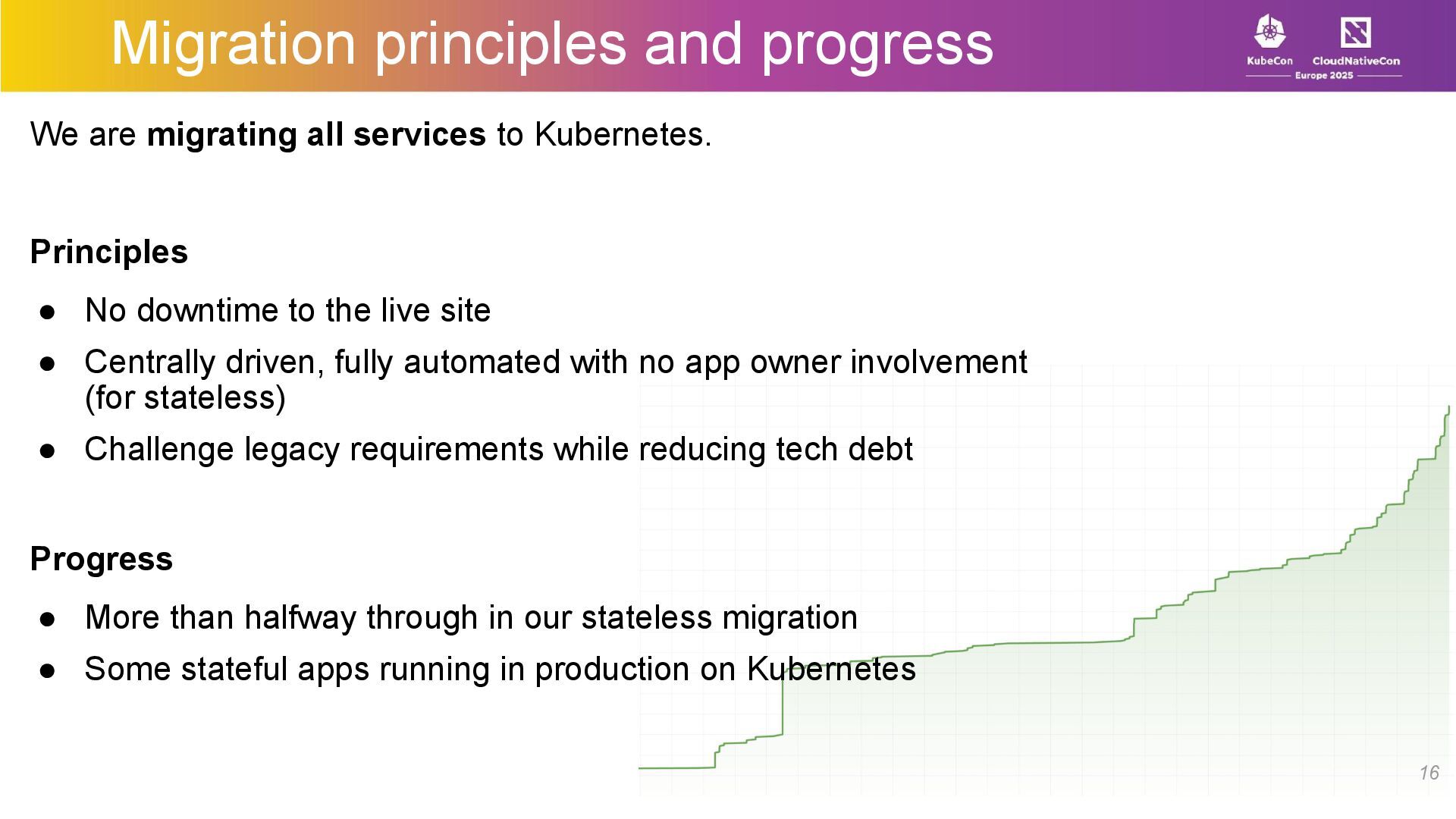
At LinkedIn, we use Kubernetes as a foundational primitive in our compute platform. We run thousands of microservices, manage large stateful applications with our custom scheduler, manage a large fleet of GPUs –all while performing regular maintenance on the bare metal hosts with no downtime or manual intervention.
In this talk, we’ll talk about how we architected and built an API-driven, Kubernetes-based compute stack with a large-scale microservices platform, a workload-agnostic stateful scheduler, and a multi-tenant ML/batch jobs platform. We’ll share insights on scaling Kubernetes for diverse workloads while maintaining tenant isolation, resilience, flexibility, and ease of use for developers.
Speakers:
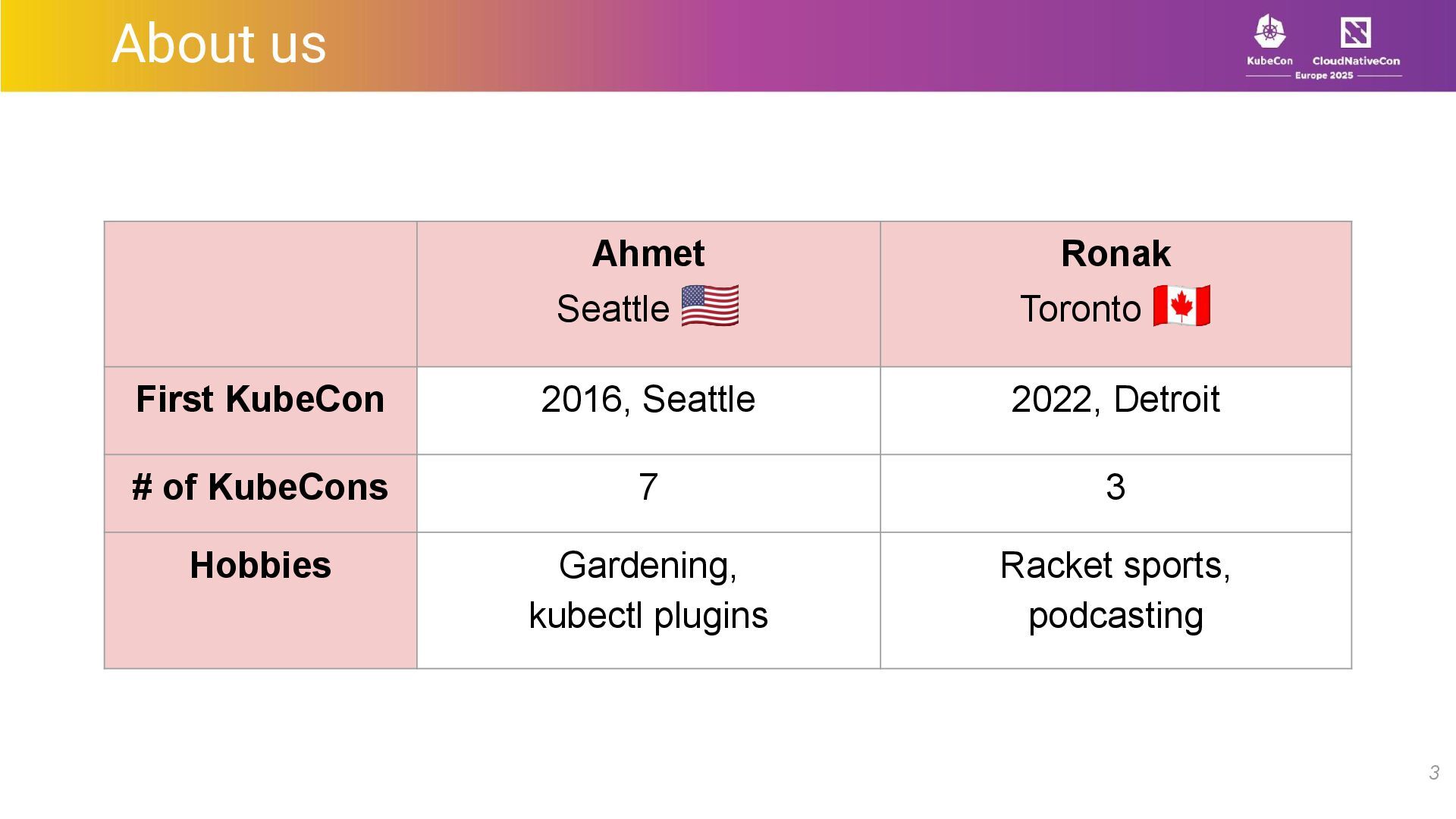
Ahmet Alp Balkan, Sr. Staff Software Engineer, LinkedIn
Ronak Nathani, Sr. Staff Software Engineer, LinkedIn
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
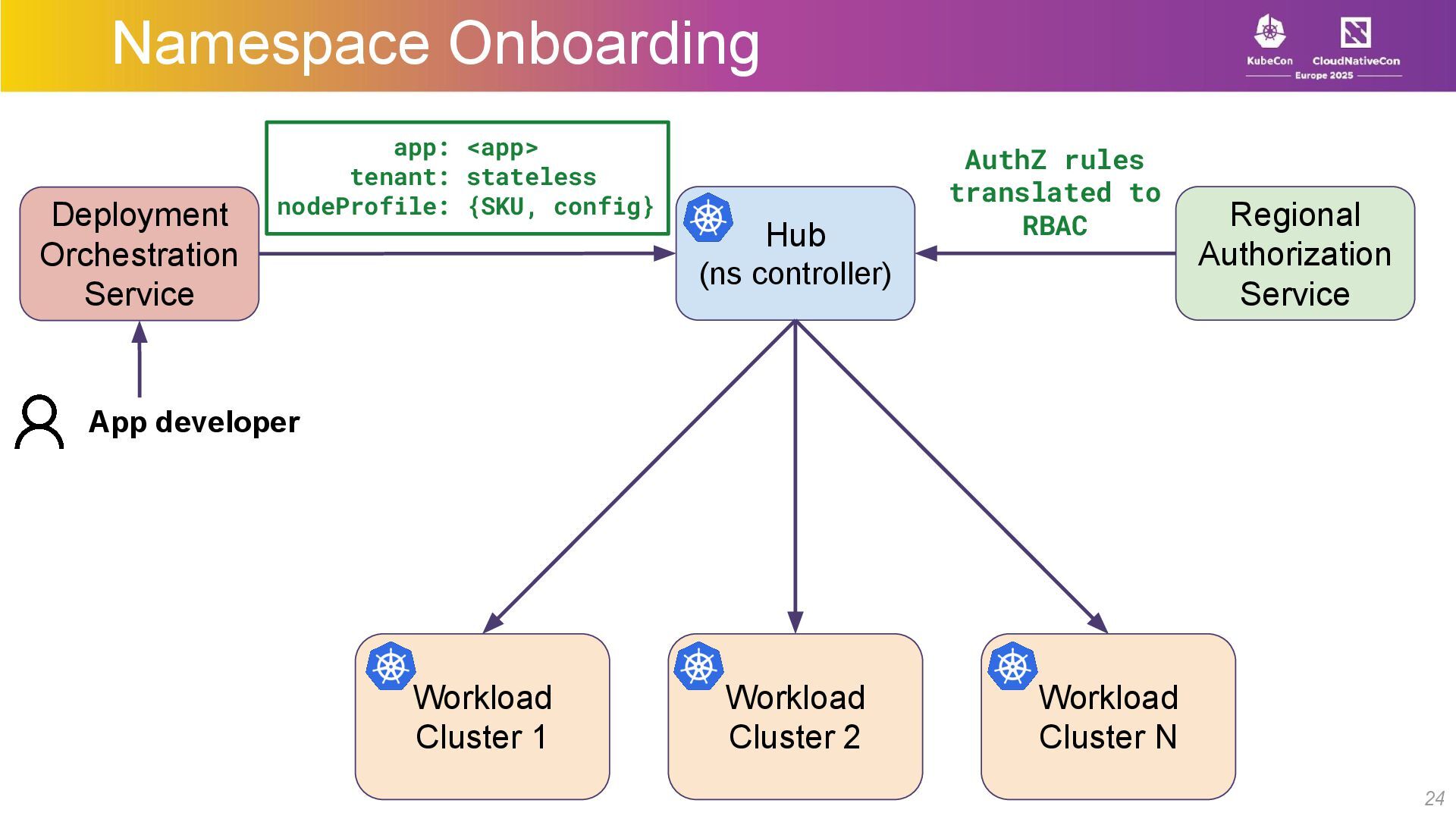{kind=link}
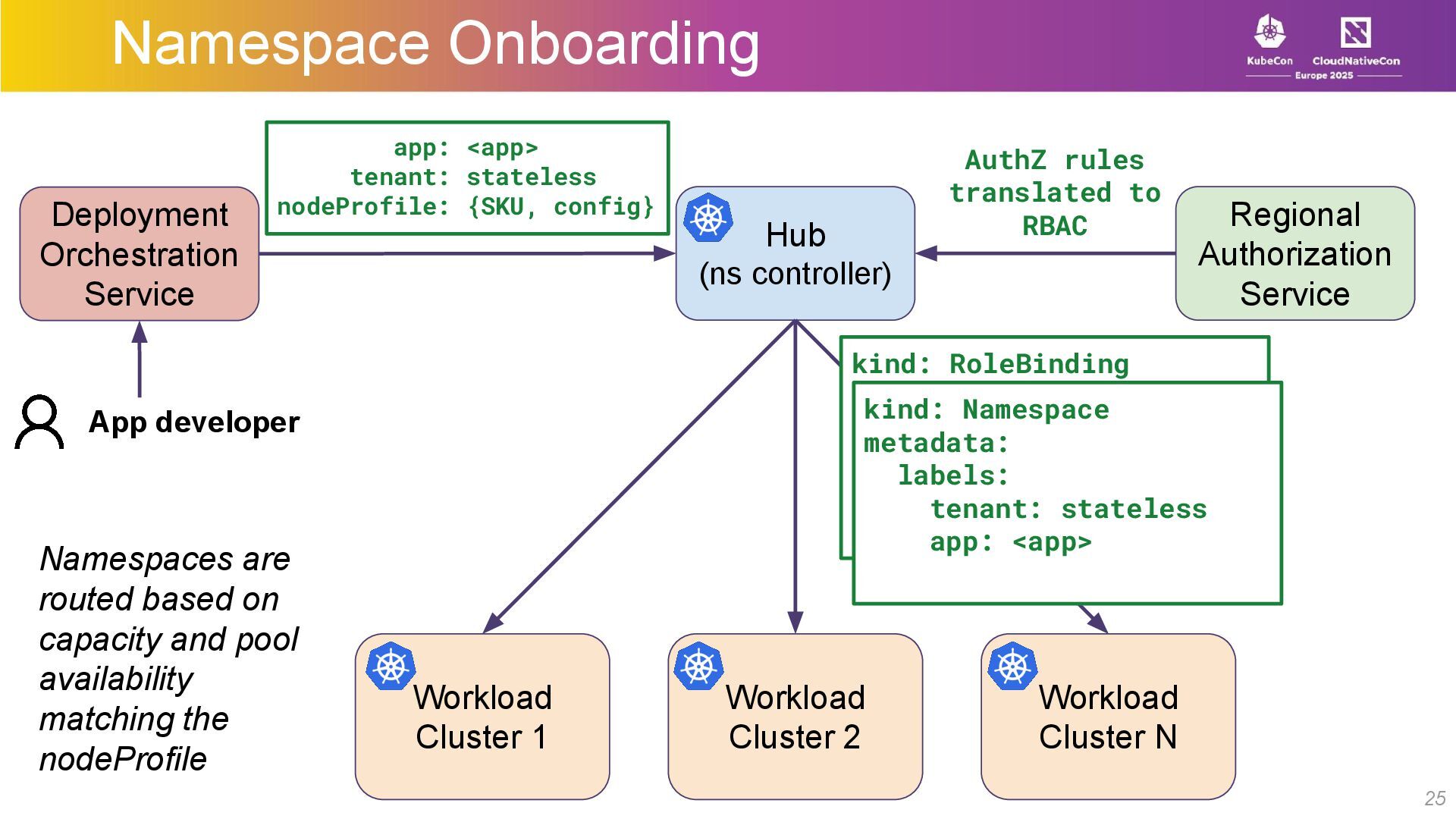{kind=link}
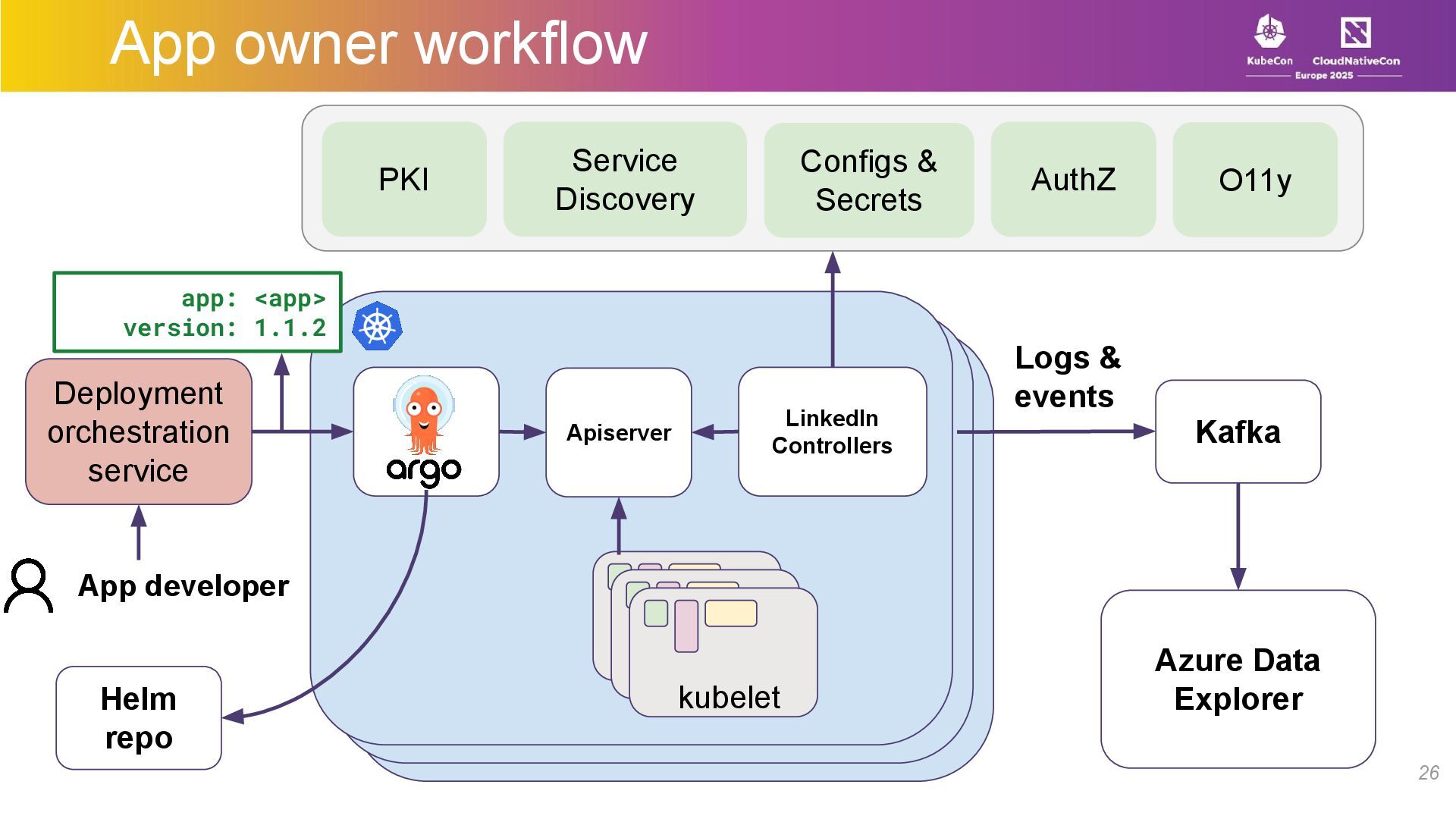{kind=link}
{kind=link}
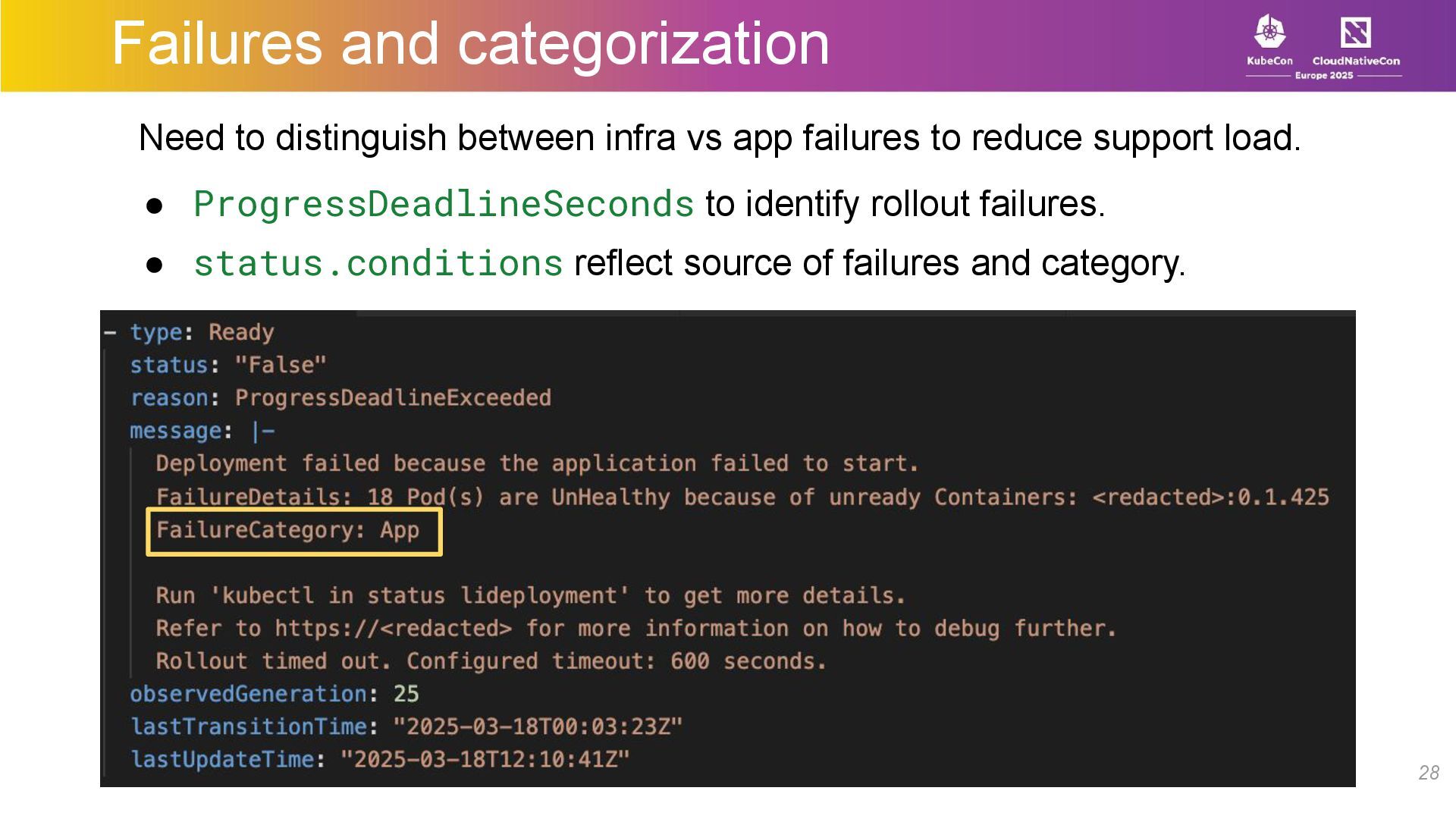{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}