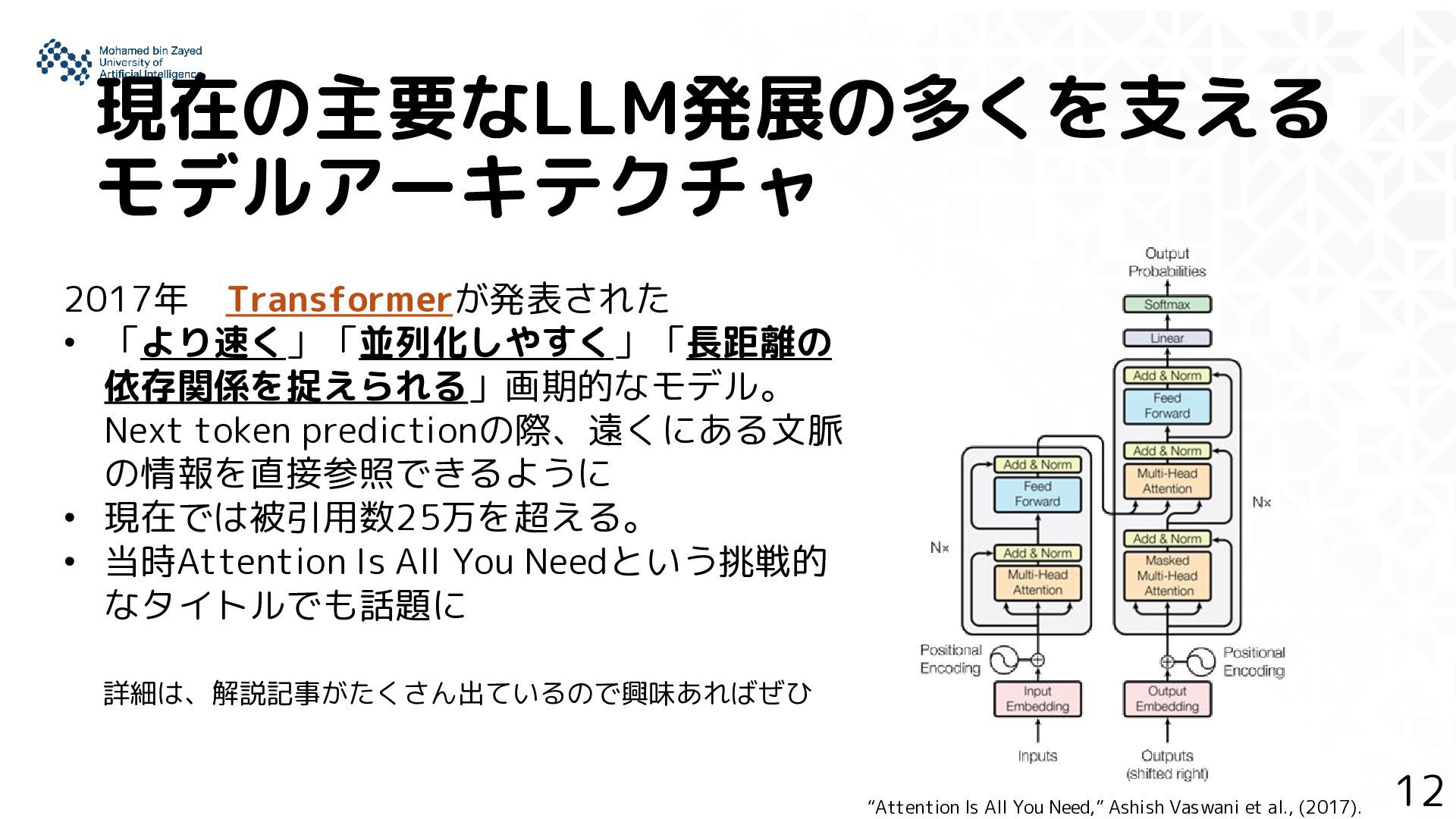
predictionの際、遠くにある文脈 の情報を直接参照できるように • 現在では被引用数25万を超える。 • 当時Attention Is All You Needという挑戦的 なタイトルでも話題に “Attention Is All You Need,” Ashish Vaswani et al., (2017). 詳細は、解説記事がたくさん出ているので興味あればぜひ
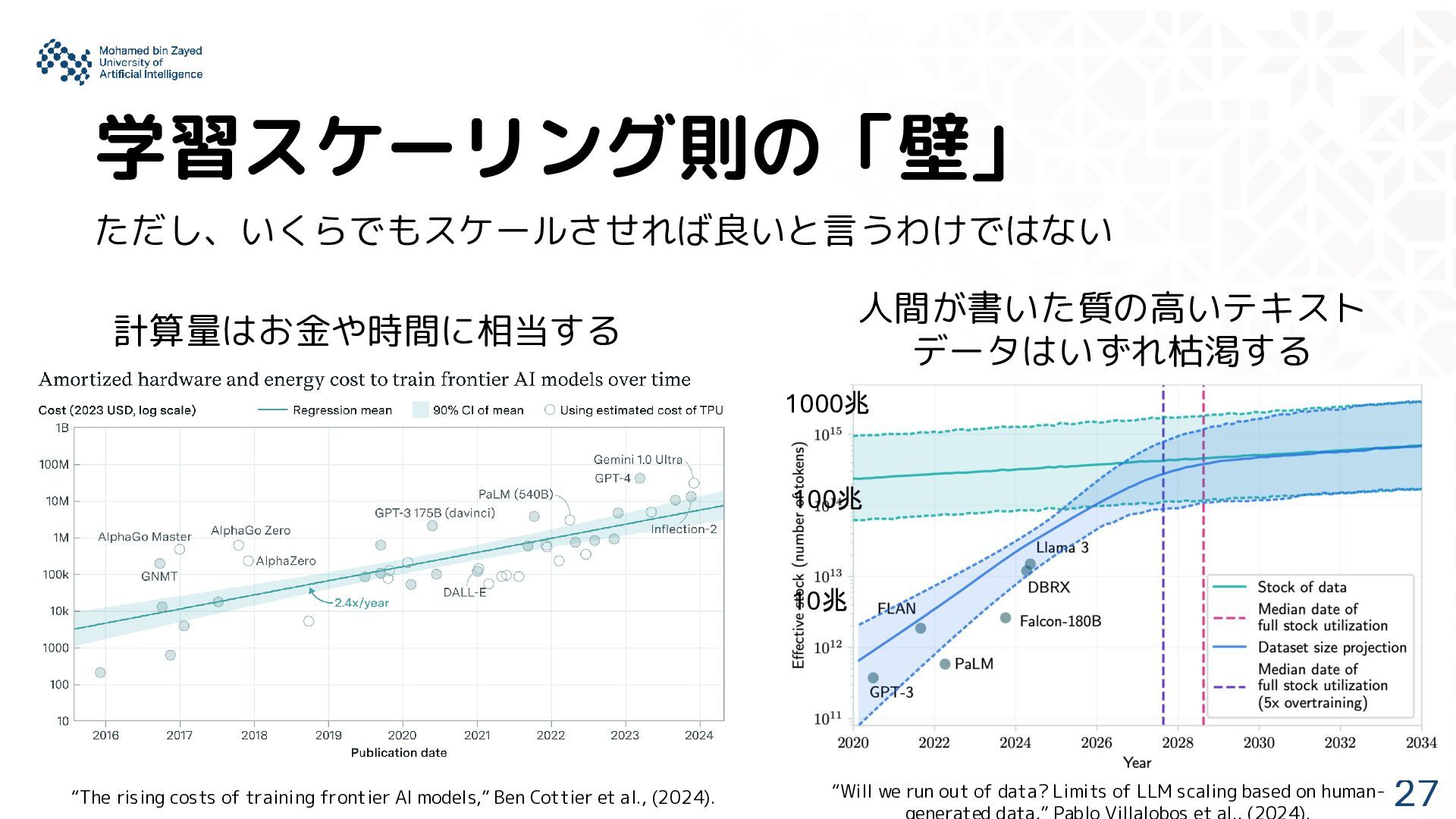
Limits of LLM scaling based on human- 人間が書いた質の高いテキスト データはいずれ枯渇する 1000兆 100兆 10兆 “The rising costs of training frontier AI models,” Ben Cottier et al., (2024).
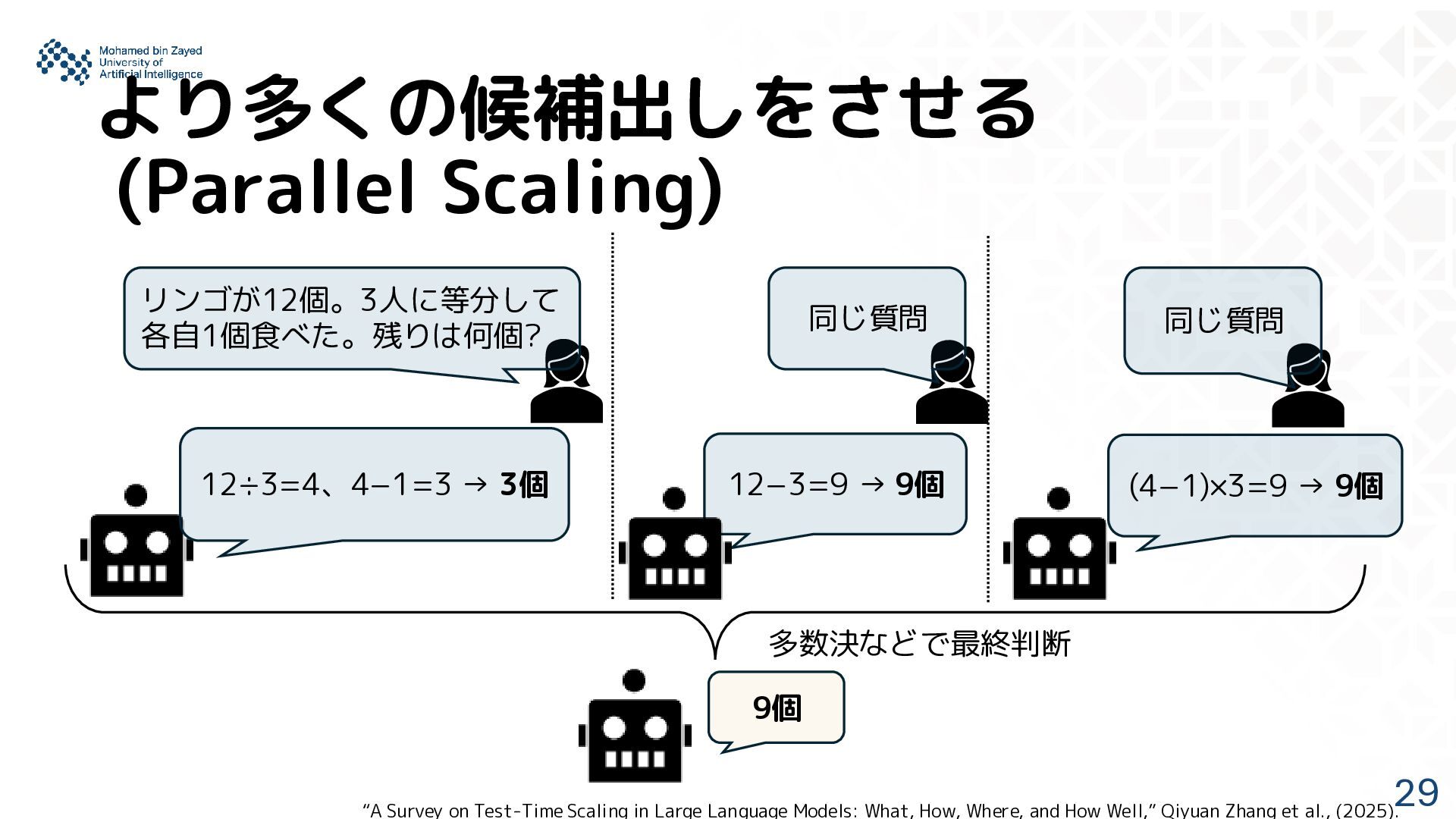
深く考えさせる(Sequential Scaling) リンゴが12個。3人に等分して各自1個食 べた。残りは何個? 3個です。 スケーリング前の通常の会話 “A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well,” Qiyuan Zhang et al., (2025).
12−3=9 → 9個 (4−1)×3=9 → 9個 9個 同じ質問 同じ質問 “A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well,” Qiyuan Zhang et al., (2025).
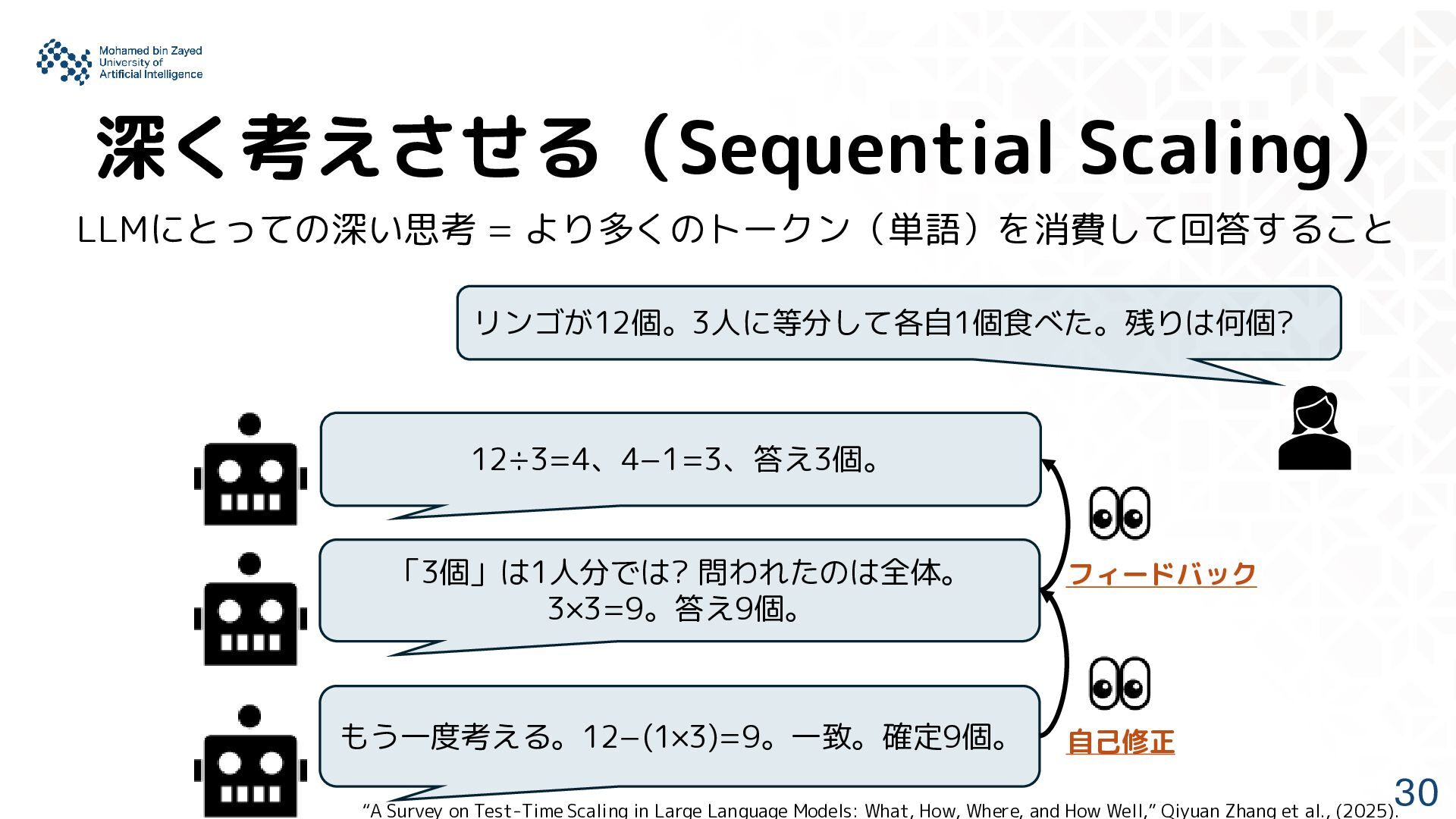
= より多くのトークン(単語)を消費して回答すること フィードバック 自己修正 “A Survey on Test-Time Scaling in Large Language Models: What, How, Where, and How Well,” Qiyuan Zhang et al., (2025).
Krakauer らの議論 • NLP研究者の間でも「LLMは言語を理解しているか」について意見は割れている。 • Mitchell & Krakauerは、LLMの「理解」を人間の理解と同一視するのではなく、別種の理解と して捉える可能性を議論している。 “The Debate Over Understanding in AI’s Large Language Models,” (2023).
Large Language Models,” Yanzhu Guo et al., (2024). “The Homogenizing Effect of Large Language Models on Human Expression and Thought,” Zhivar Sourati et al., (2025).
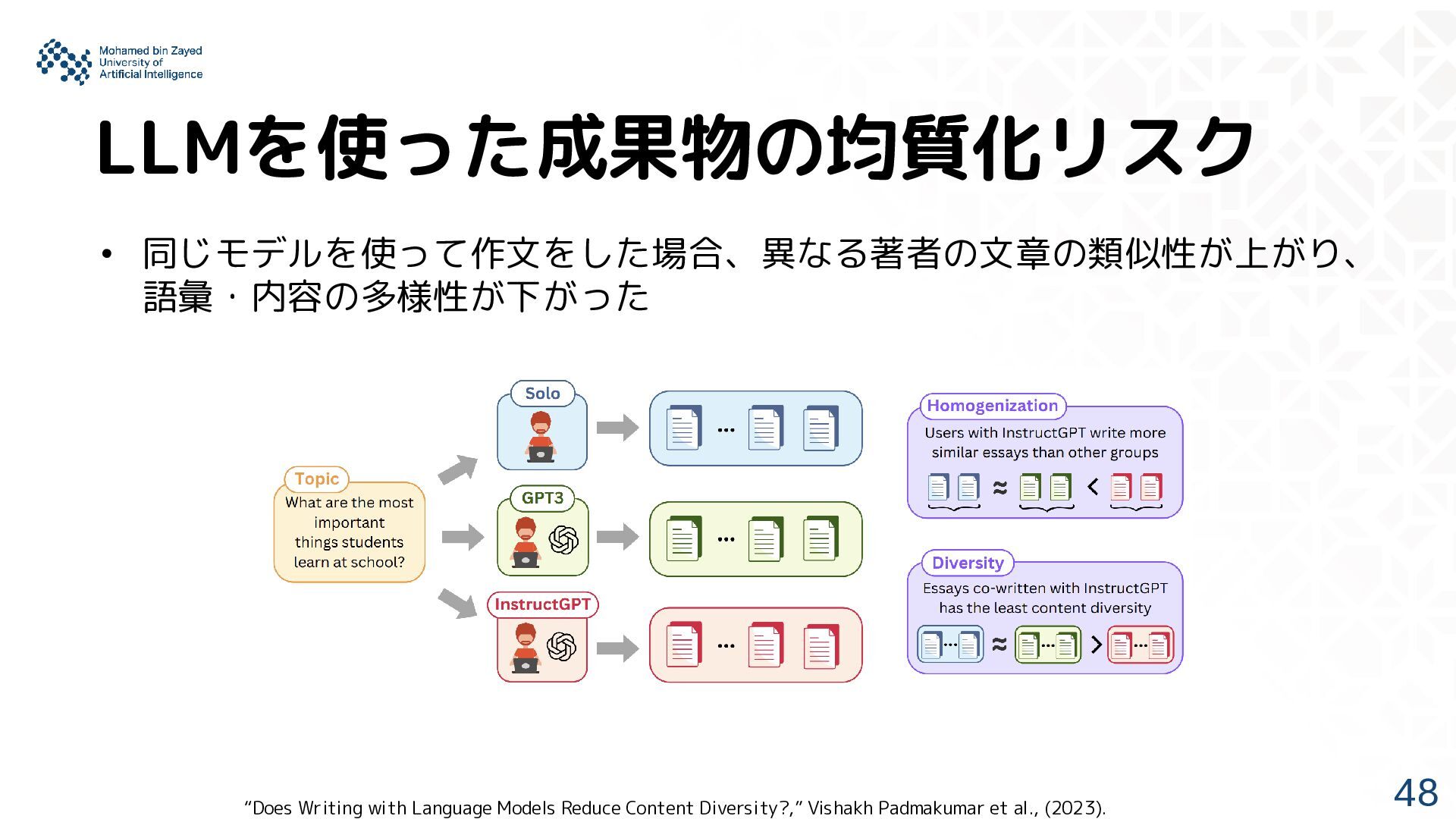
ChatGPTを創造支援ツールとして使った参加者同士のアイデアが、別の創造支援 ツールを使った場合より意味的に似てしまうリスク “Picking on the Same Person: Does Algorithmic Monoculture lead to Outcome Homogenization?,” Rishi Bommasani et al., (2022). “The Silent Curriculum: How Does LLM Monoculture Shape Educational Content and Its Accessibility?,” Aman Priyanshu et al., (2024).
が溜まって行く。その結果、さらに均質化が進む “Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task,” Nataliya Kosmyna et al., (2025). “Co-Writing with Opinionated Language Models Affects Users' Views,” Maurice Jakesch et a., (2023).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}