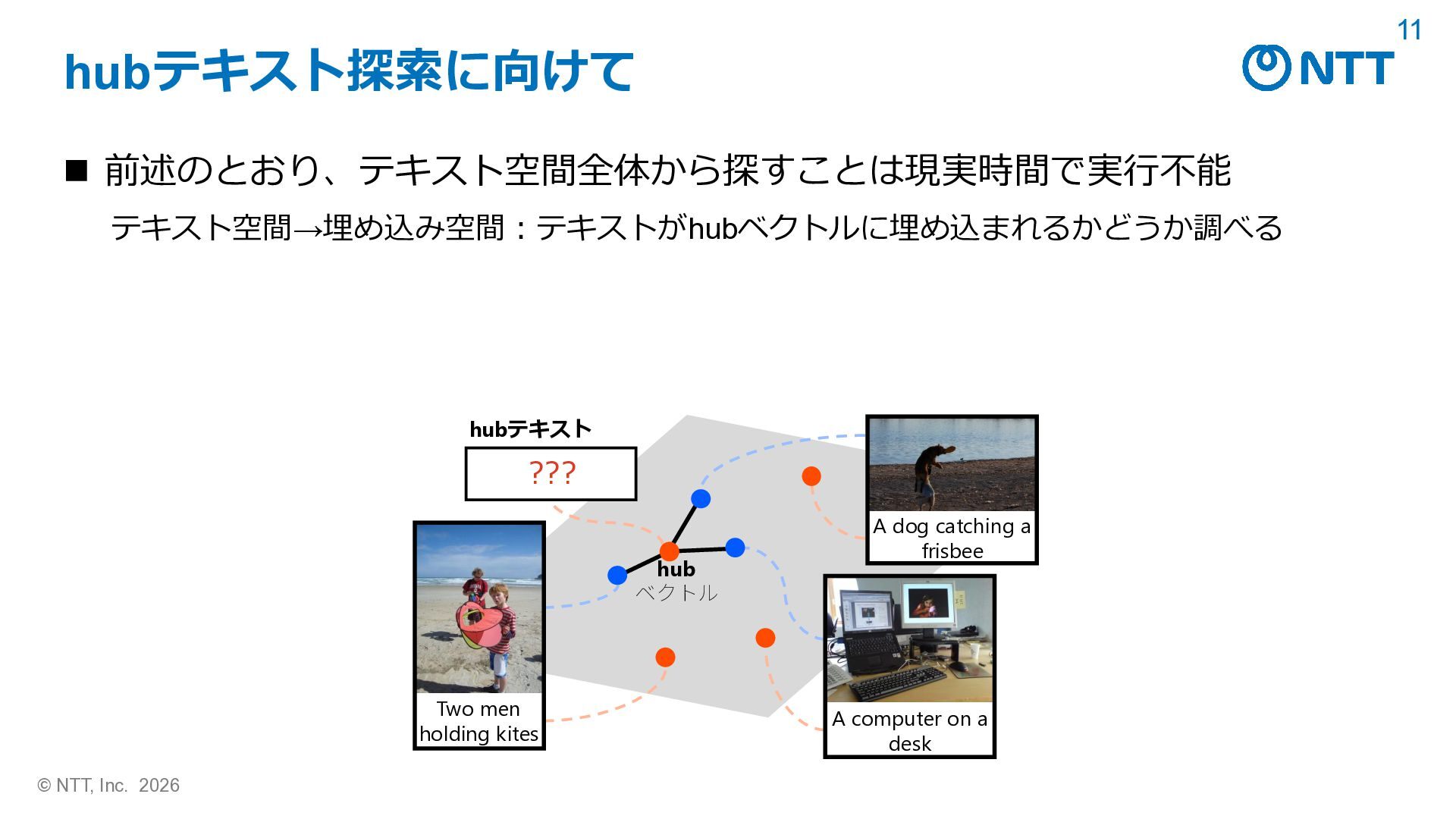
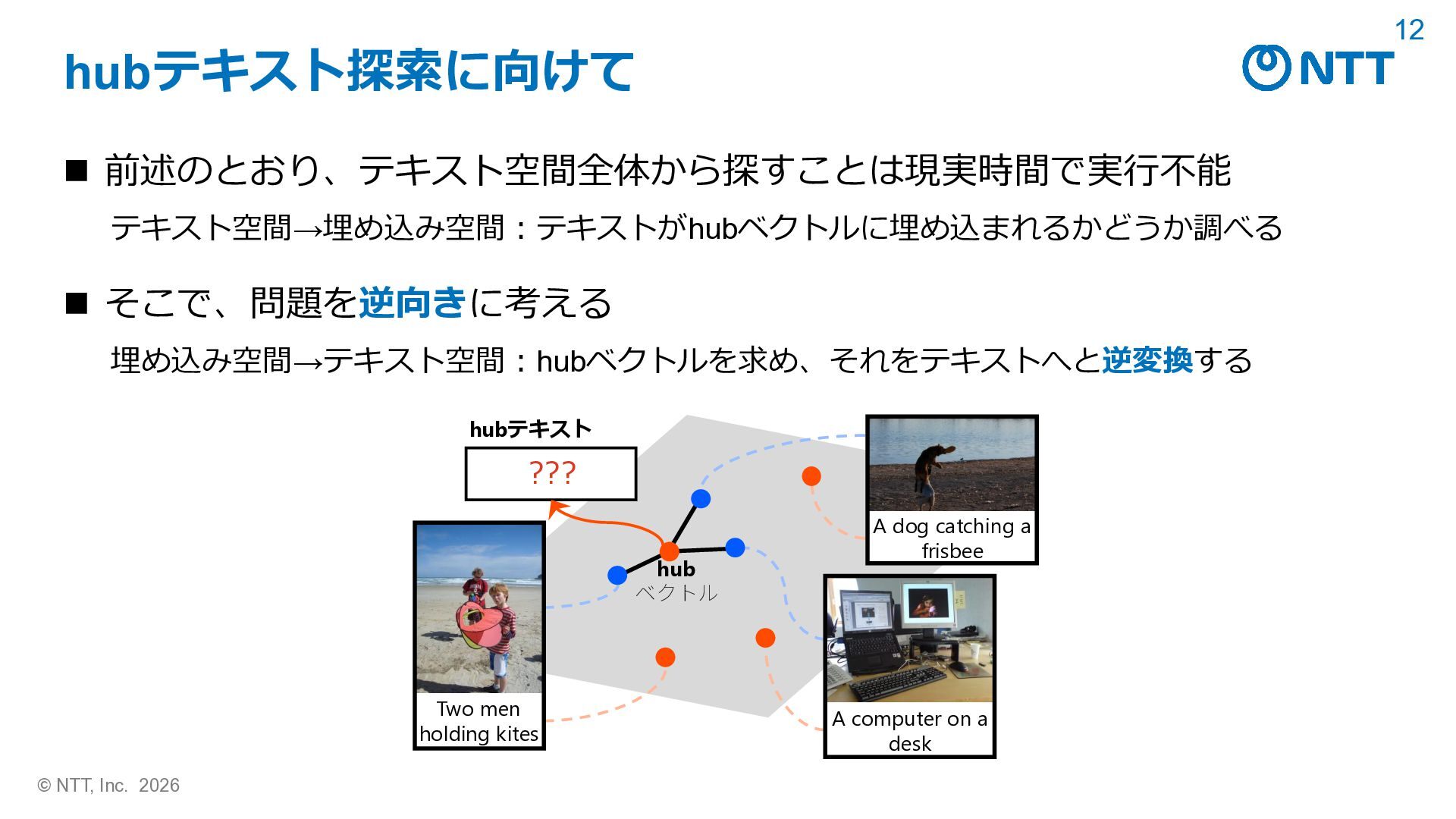
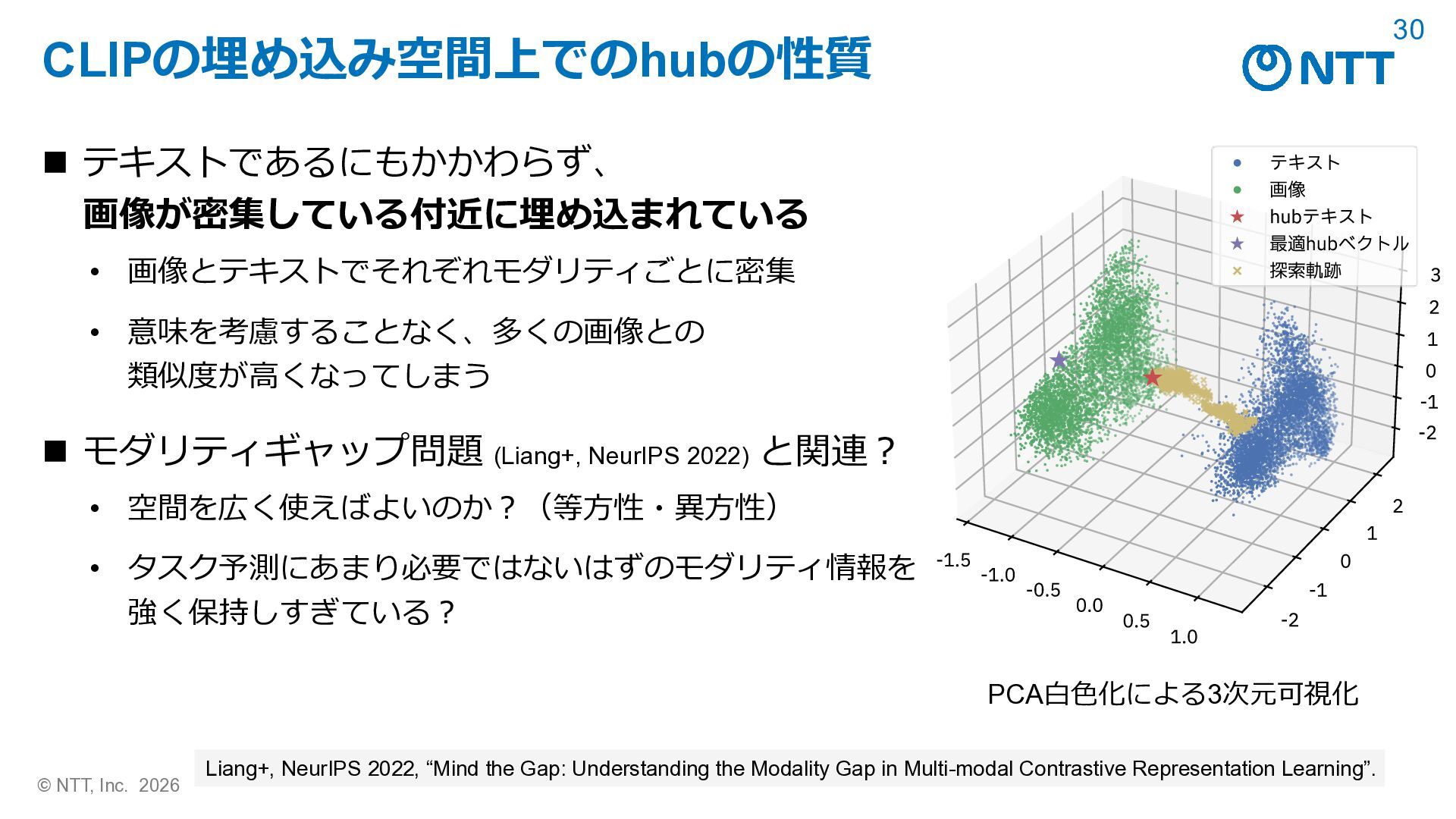
dishstaged mms middle ], croc ée ✬ trot maker gely bw 8 boarded <U+FE0F>: garethapproached cision openai/clip-vit-base-patch32によるCLIPScore (CLIP-S) (Hessel+, EMNLP 2021) キャプション/hubテキスト CLIP-S 画像 参照 A couple of young boys with skateboards pass a city bus 0.793 hub today color photo ... 1.012 参照 Cat sitting right next to keyboard on laptop 0.780 hub today color photo ... 0.981 Hessel+, EMNLP 2021, “CLIPScore: A Reference-free Evaluation Metric for Image Captioning”. ◼ 埋め込みにおける脆弱性「hubテキスト」 • どんなデータに対しても高い類似度を示してしまうテキスト hubテキスト
__: dishstaged mms middle ], croc ée ✬ trot maker gely bw 8 boarded <U+FE0F>: garethapproached cision ◼ hubテキスト キャプション/hubテキスト CLIP-S 画像 参照 A couple of young boys with skateboards pass a city bus 0.793 hub today color photo ... 1.012 参照 Cat sitting right next to keyboard on laptop 0.780 hub today color photo ... 0.981 Hessel+, EMNLP 2021, “CLIPScore: A Reference-free Evaluation Metric for Image Captioning”. ◼ 結果:画像と無関係にもかかわらず、単一のhubテキストが参照キャプション より高いCLIPScore (Hessel+, EMNLP 2021) を得てしまっている
![© NTT, Inc. 2026 単一のhubテキストがCLIPを壊す: hubnessによる埋め込みの脆弱性特定 出口 祥之 NTT株式会社 [email protected]](https://files.speakerdeck.com/presentations/70b81d01f6644996b05c7d3c94a99e12/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}