(https://github.com/TKQXX/BVSA) を見る限りこのモデルを使用? - 入力信号を平滑化→線形層→残差接続→層正規化 22 図を作る時間がなかったです… class ResidualAdd(nn.Module): def __init__(self, f): super().__init__() self.f = f def forward(self, x): return x + self.f(x) def _build_proj_block(in_dim, out_dim, drop_rate): return nn.Sequential( nn.Linear(in_dim, out_dim), ResidualAdd(nn.Sequential( nn.GELU(), nn.Linear(out_dim, out_dim), nn.Dropout(drop_rate), )), nn.LayerNorm(out_dim) ) class EEGProject(nn.Module): def __init__(self, z_dim, c_num, timesteps, drop_proj=0.3): super().__init__() self.input_dim = c_num * (timesteps[1] - timesteps[0]) self.model_txt = _build_proj_block(self.input_dim, z_dim, drop_proj) self.model_img = _build_proj_block(self.input_dim, z_dim, drop_proj) self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07)) self.softplus = nn.Softplus() def forward(self, x, training): x = x.view(x.shape[0], -1) x_txt, x_img = self.model_txt(x), self.model_img(x) if training: return x_txt, x_img return x_txt.repeat(1, 3), x_img.repeat(1, 3)
{kind=link}
{kind=link}
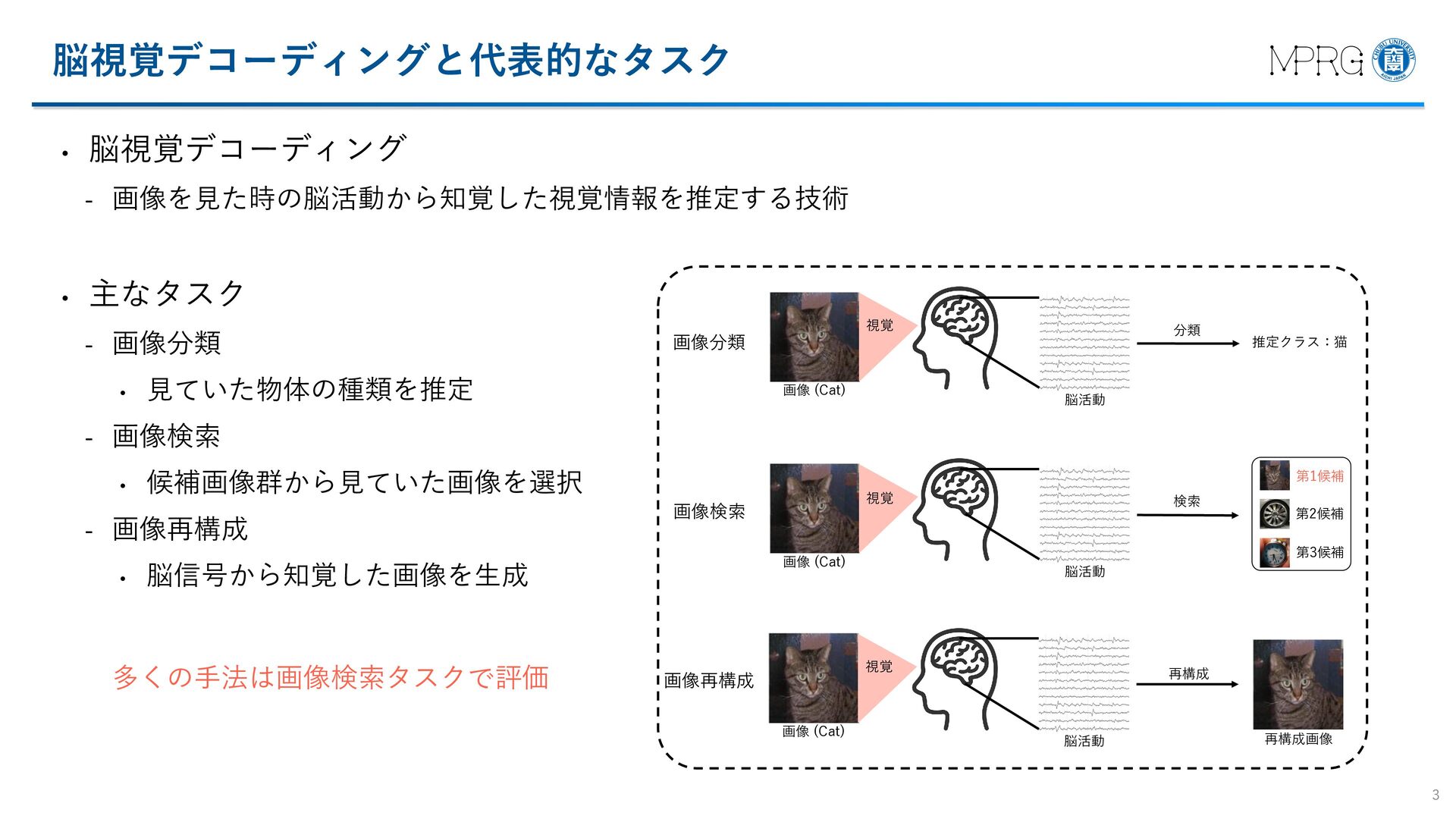{kind=link}
![従来手法:NICE [Song+,ICLR2024] • Natural Image Contrast EEG • 画像全体の特徴と脳信号全体の特徴を対照学習で直接対応付け -](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_3.jpg){kind=link}
![従来手法:UBP [Wu+,CVPR2025] • Uncertainty-Aware Blur Prior • NICE [Song+,ICLR2024] で行う脳信号と画像の対応付けを改善](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_4.jpg){kind=link}
![前提手法:CLIP [Radford+, ICML2021] • Contrastive Language-Image Pre-training - (1)事前学習:画像とテキストのペアで特徴量が一致するように自己教師あり学習 -](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_5.jpg){kind=link}
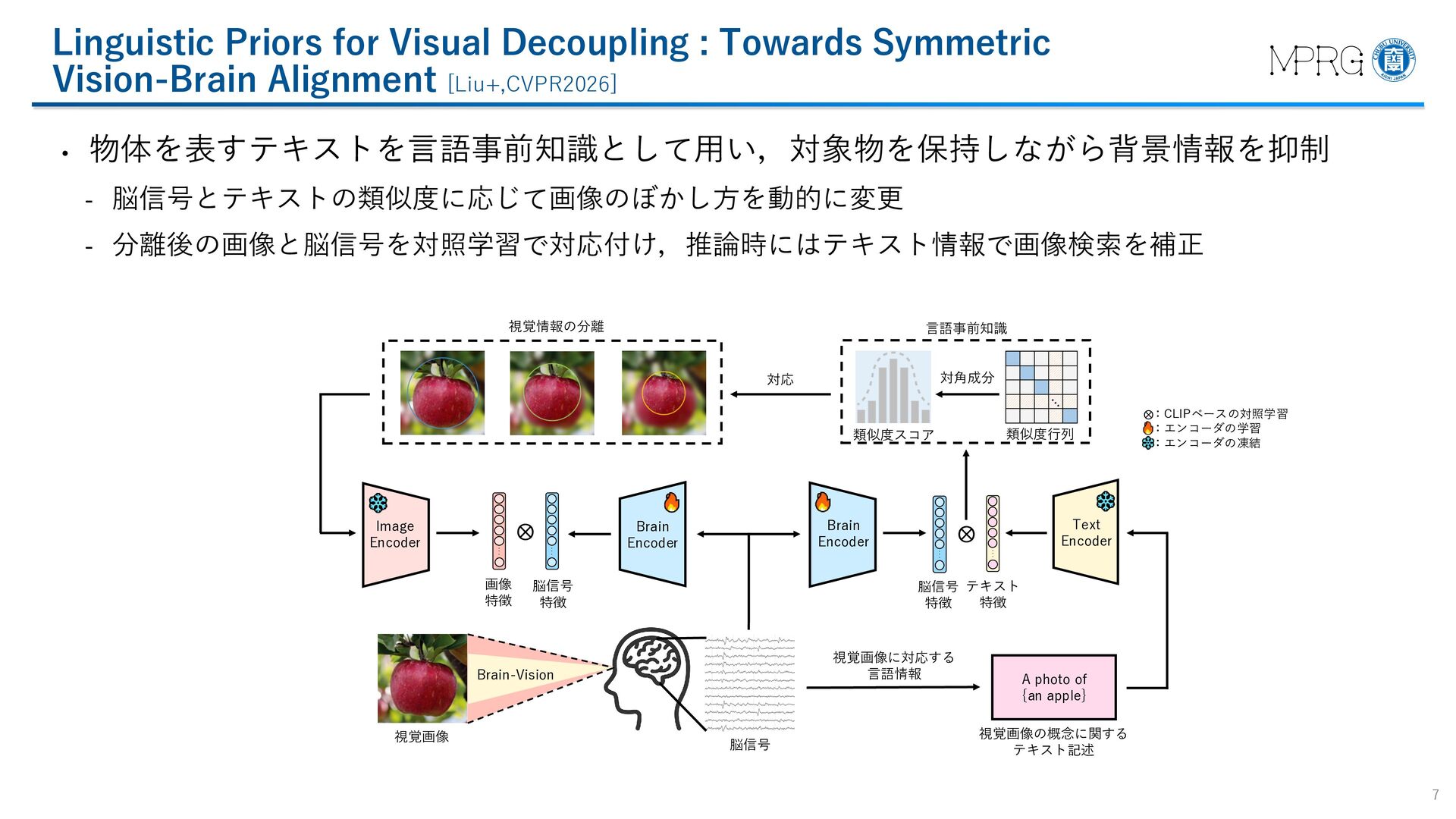{kind=link}
![言語事前知識による視覚情報の分離 [1/4] • 視覚画像に対応する物体概念からテキスト記述を作成 - 例:A photo of {an apple}](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_7.jpg){kind=link}
![言語事前知識による視覚情報の分離 [2/4] • 脳信号とテキストの類似度に基づく分離画像の生成 - 1.対応する脳特徴とテキスト特徴の類似度を計算 - 2.類似度に基づいて中央領域の保持方法を3段階から選択 - 3.選択結果を空間重みに反映し,分離画像を生成](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_8.jpg){kind=link}
![言語事前知識による視覚情報の分離 [3/4] • 類似度行列から対角成分を抽出 - バッチ全体で,脳特徴とテキスト特徴の全組合せから類似度行列を作成 • 類似度ベクトル𝑠𝑏𝑡 から分布を作成 -](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_9.jpg){kind=link}
![言語事前知識による視覚情報の分離 [4/4] • 元画像とぼかし画像を位置ごとの重み𝑊で合成 • 画像中央では元画像を強く保持し,周辺にぼかし画像を反映 • 𝕀に応じて中央の保持範囲を変更 11 ](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_10.jpg){kind=link}
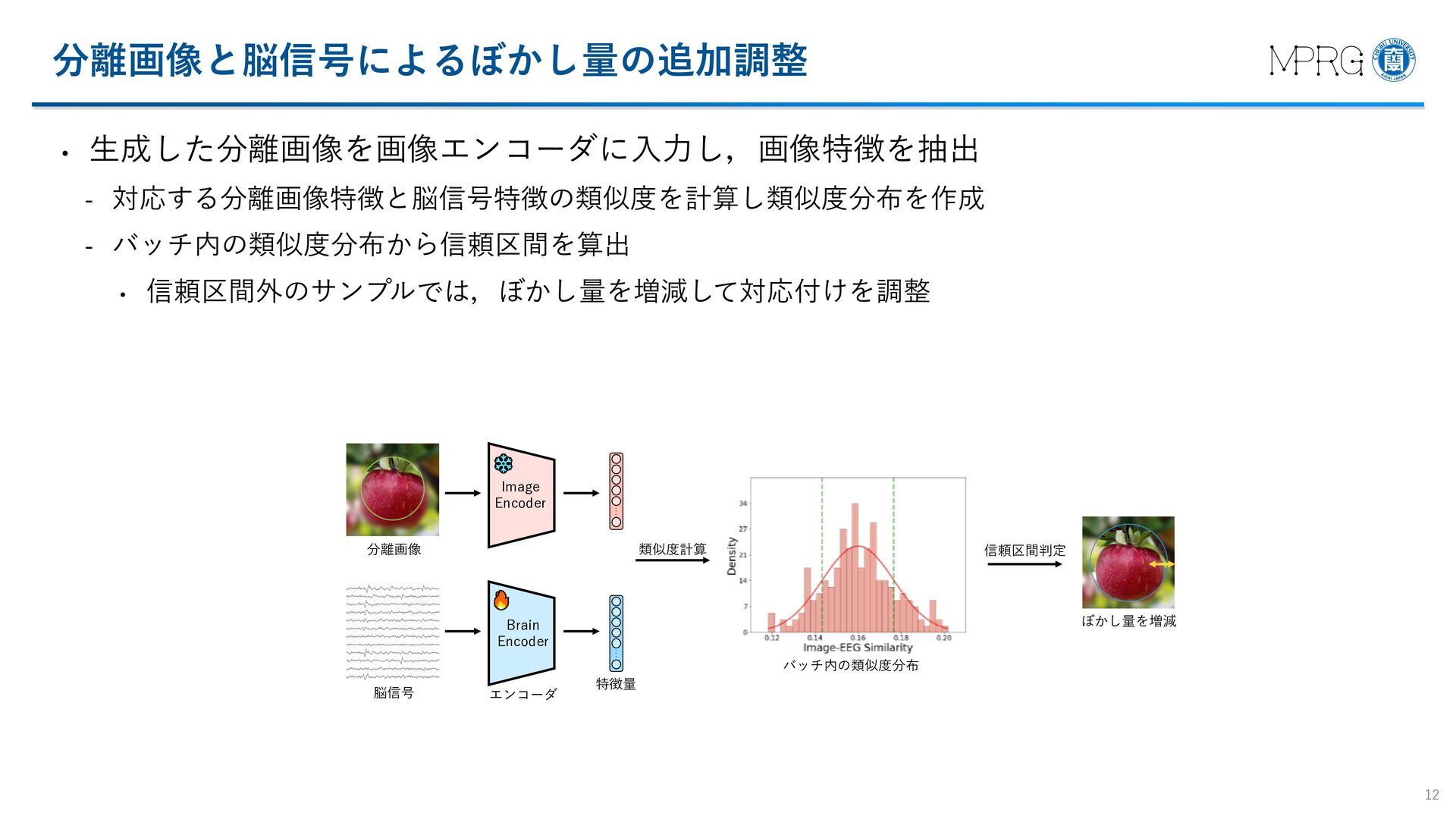{kind=link}
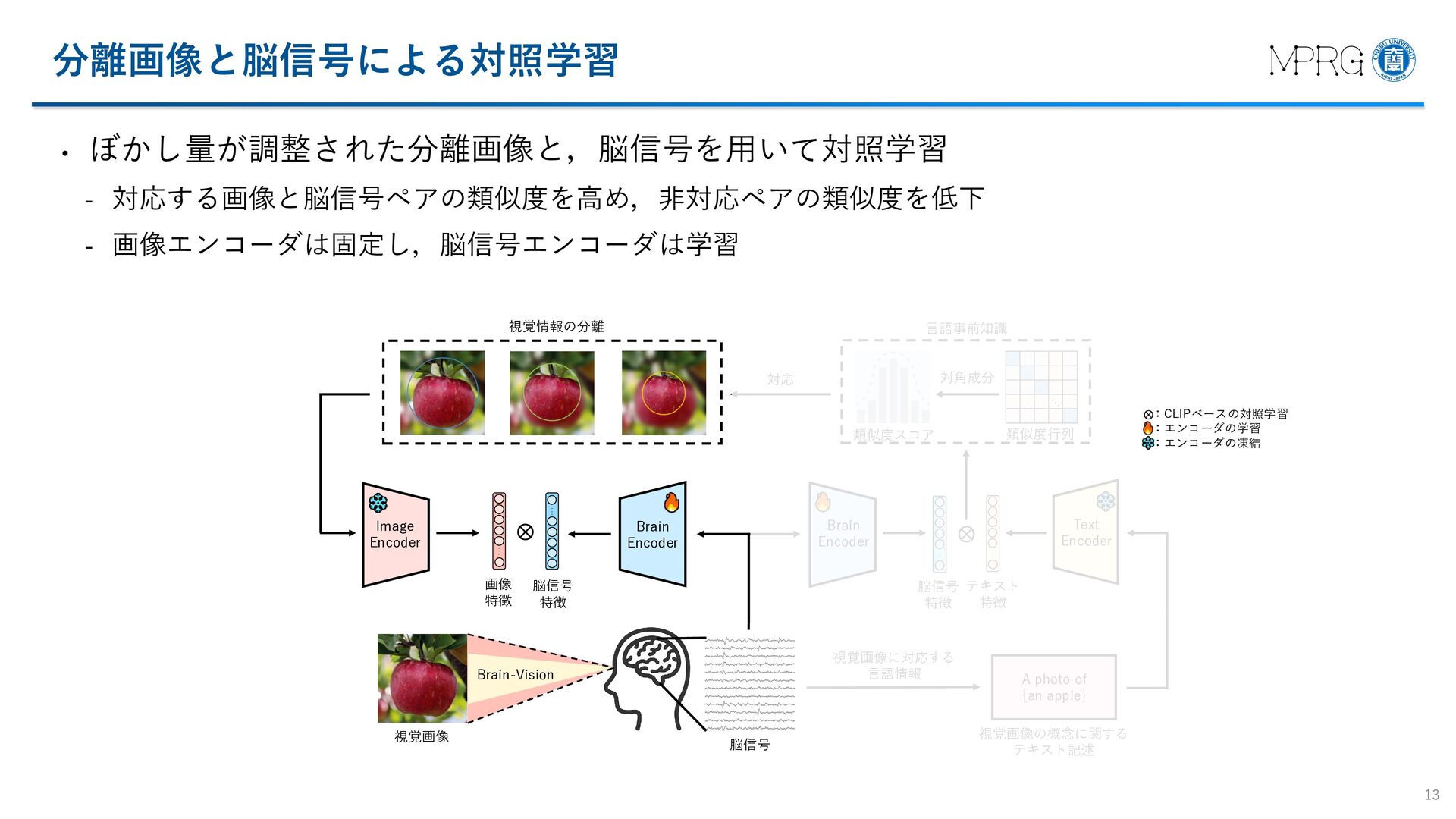{kind=link}
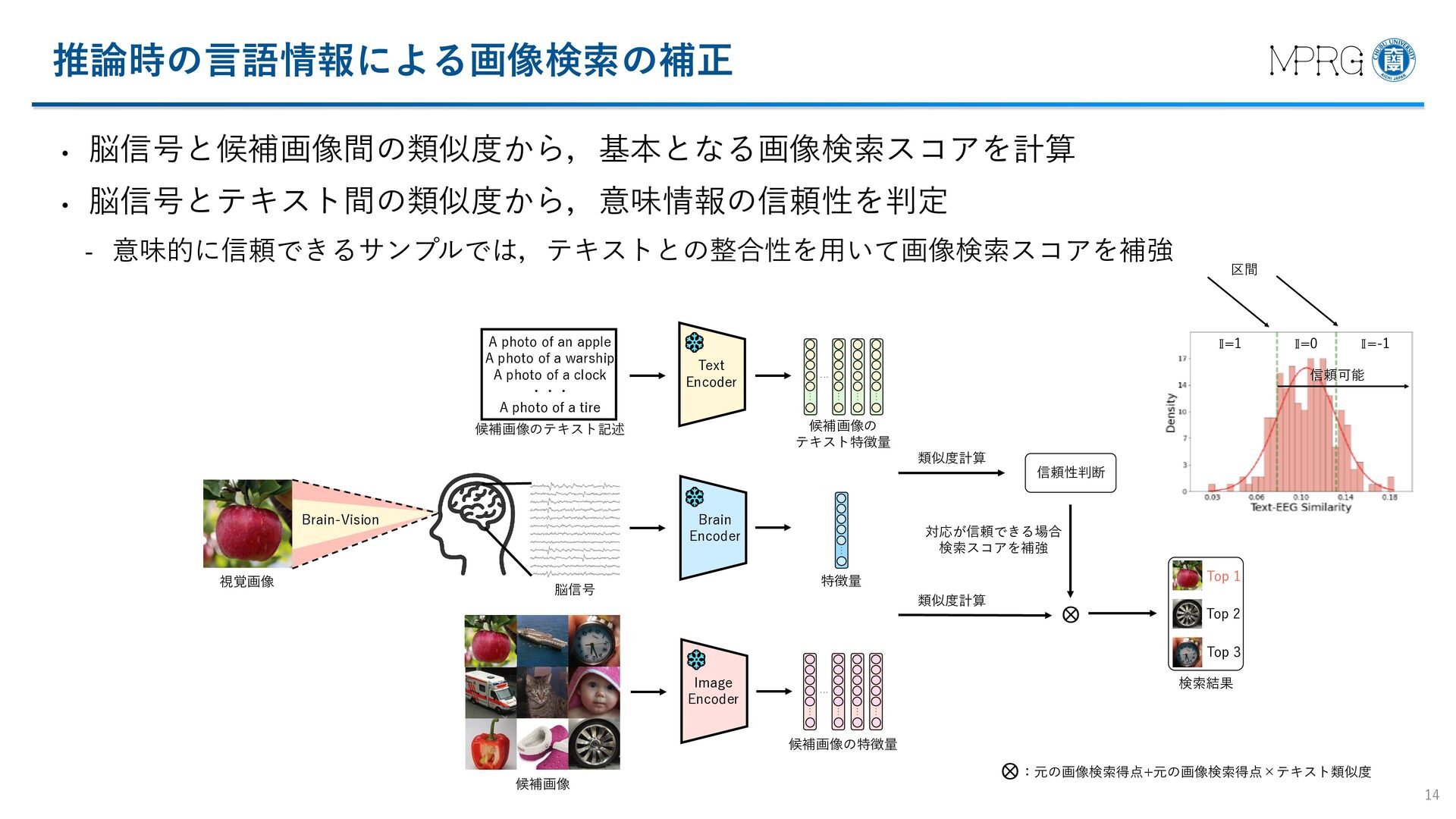{kind=link}
{kind=link}
{kind=link}
![THINGS-EEGデータセットの結果 (1/2) • 従来手法との比較を行った実験 - BraVL [Du+, TPAMI2023] - NICE](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_16.jpg){kind=link}
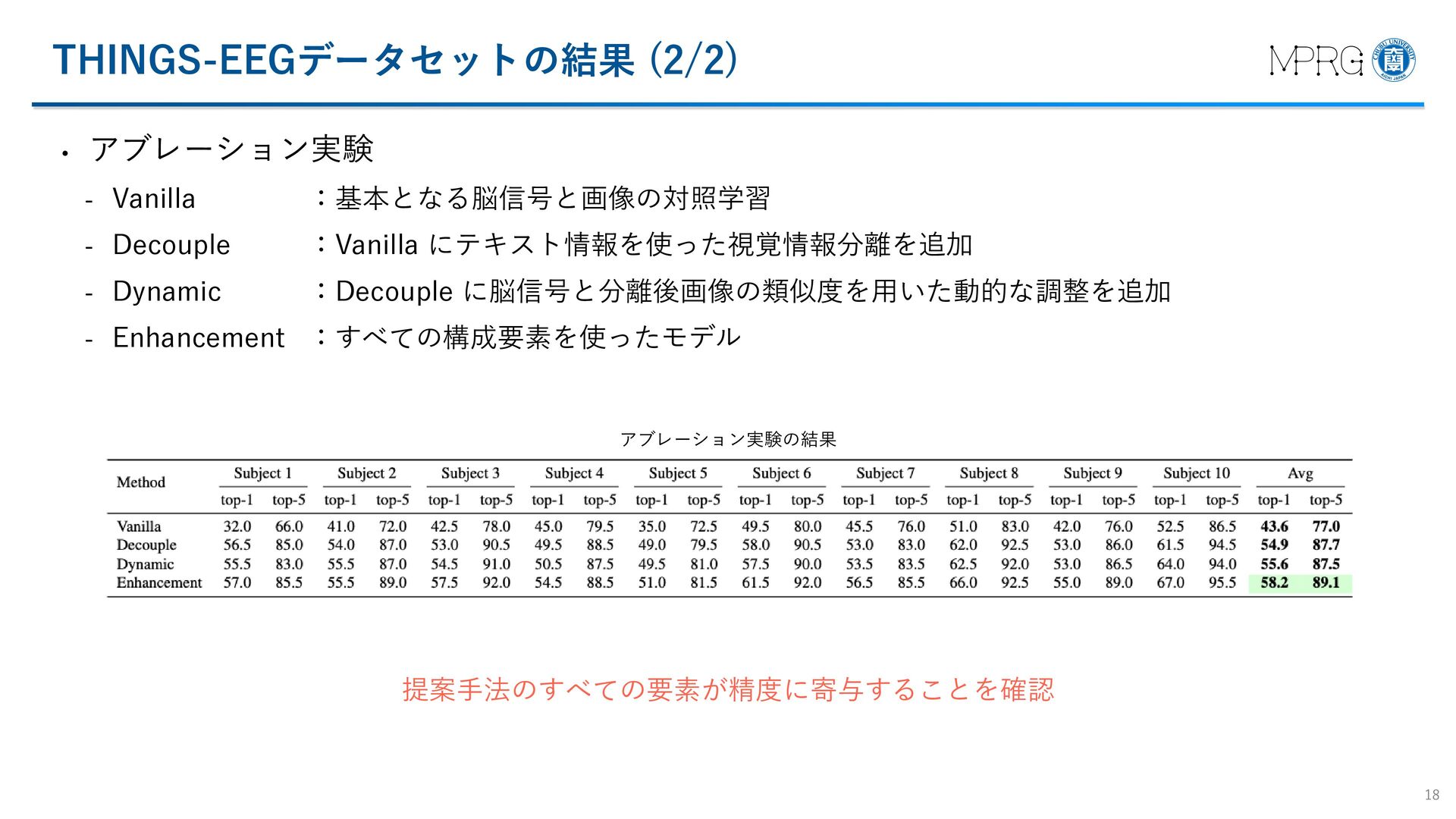{kind=link}
{kind=link}
{kind=link}
{kind=link}
![脳信号エンコーダ • EEG Project - UBP [Wu+,CVPR2025] で使用されていた脳信号エンコーダ - GitHubの実装](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_21.jpg){kind=link}
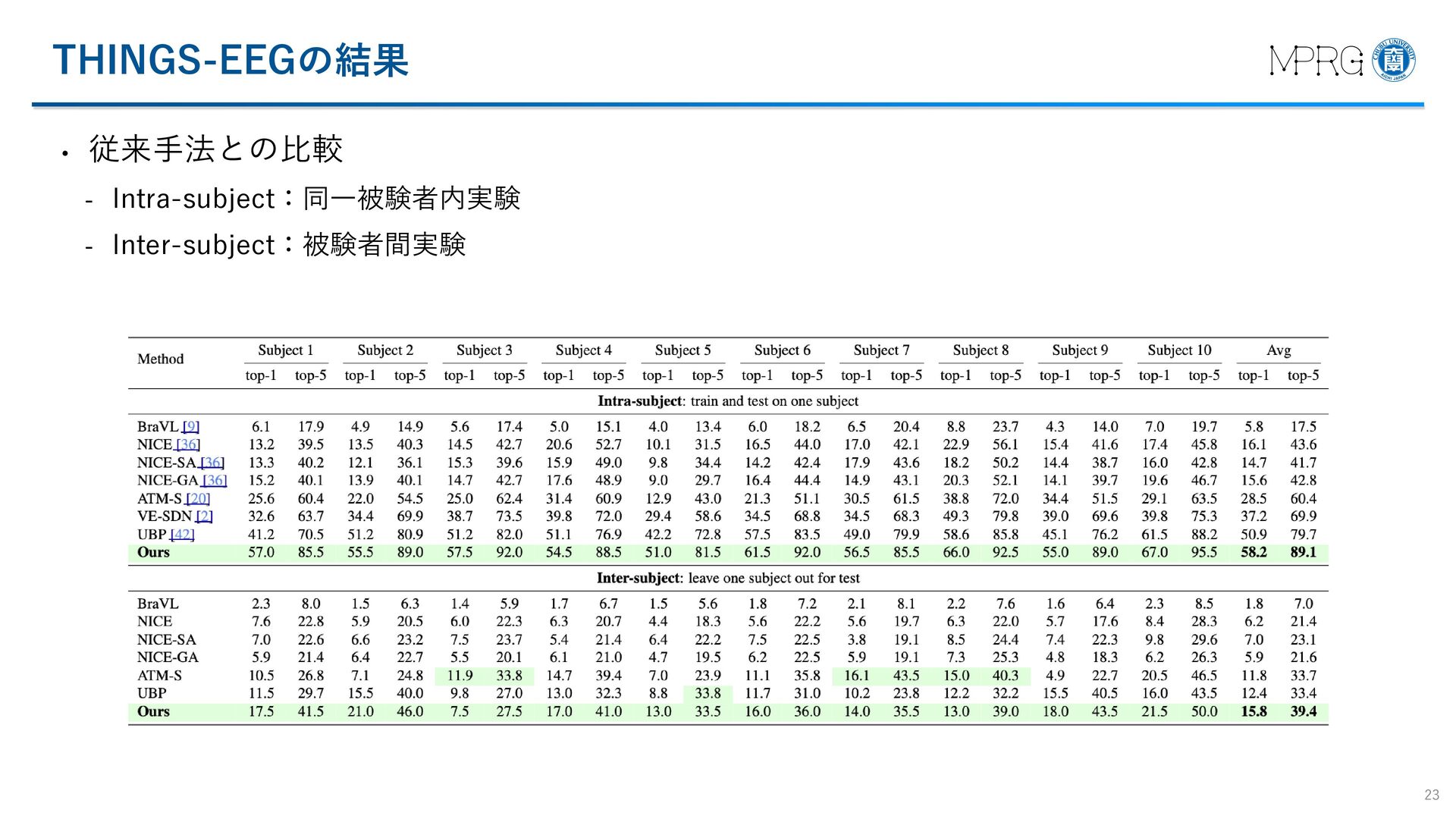{kind=link}
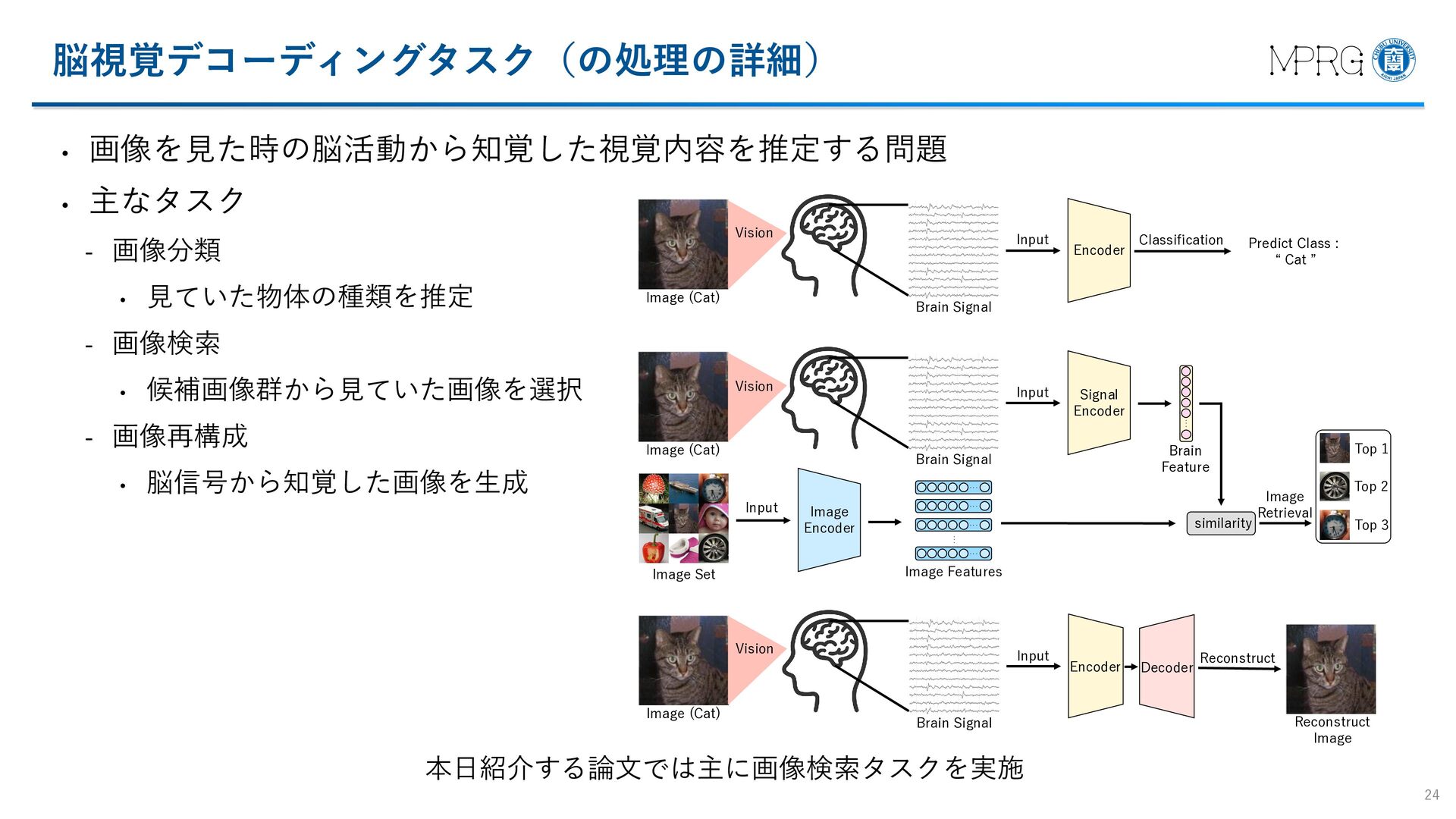{kind=link}
{kind=link}
![THINGS-MEGデータセットの結果 • 従来手法との比較 - NICE [Song+, ICLR2024] • NICE-SA :NICEにAttention機構を追加](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_25.jpg){kind=link}
![言語事前知識による視覚情報の分離 [3/5] • 類似度行列から対角成分を抽出 - バッチ全体で,脳特徴とテキスト特徴の全組合せから類似度行列を作成 • 対応ペアの類似度スコア𝑠 𝑏𝑡 (𝑖)](https://files.speakerdeck.com/presentations/cecbe5ceecf6428a86efa3501188bff4/slide_26.jpg){kind=link}