Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guid...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
村川卓也
June 20, 2026
Research
170
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
第64回 名古屋CV・PRML勉強会
https://nagoyacv.connpass.com/event/394324/
村川卓也
June 20, 2026
More Decks by 村川卓也
See All by 村川卓也
CVPR2025論文紹介:「Unboxed: Geometrically and Temporally Consistent Video Outpainting」
murakawatakuya
0
1.1k
Other Decks in Research
See All in Research
【Zozo Research 技術共有会】三次元領域の現在と展望
mickey_0226
3
510
CVPR2026論文紹介_VLMにとって良いvision encoderとは何か?Rethinking Model Selection in VLM Through the Lens of Gromov-Wasserstein Distance
kobayashi31
1
180
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
480
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
530
論文紹介:HalluCitation Matters
wasyro
0
130
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
130
2025年度秋葉原ウォーカブルプロジェクト調査報告 「アキバらしいウォーカブル」とは何か
izumiyama_lab
1
130
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
140
議論 学術ムーブメントを成功させるために何が必要なのだろうか
rmaruy
0
110
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
710
Cross-Media Human-Information Interaction
signer
PRO
0
160
260624_NLP-colloquium: Hubness
de9uch1
1
150
Featured
See All Featured
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
420
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
330
New Earth Scene 8
popppiees
3
2.4k
Build The Right Thing And Hit Your Dates
maggiecrowley
39
3.4k
Speed Design
sergeychernyshev
33
2k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
330
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.9k
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
360
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Thoughts on Productivity
jonyablonski
76
5.3k
Transcript
SVAgent: Storyline-guided Long Video Understanding via Cross- Modal Multi-Agent Collaboration
Zhongyu Yang, Zuhao Yang, Shuo Zhan, Tan Yue, Wei Pang, Yingfang Yuan, CVPR2026 大島慈温(名工大玉木・丁研) 2026/06/20 第64回 名古屋CV・PRML勉強会(CVPR2026 論文紹介)
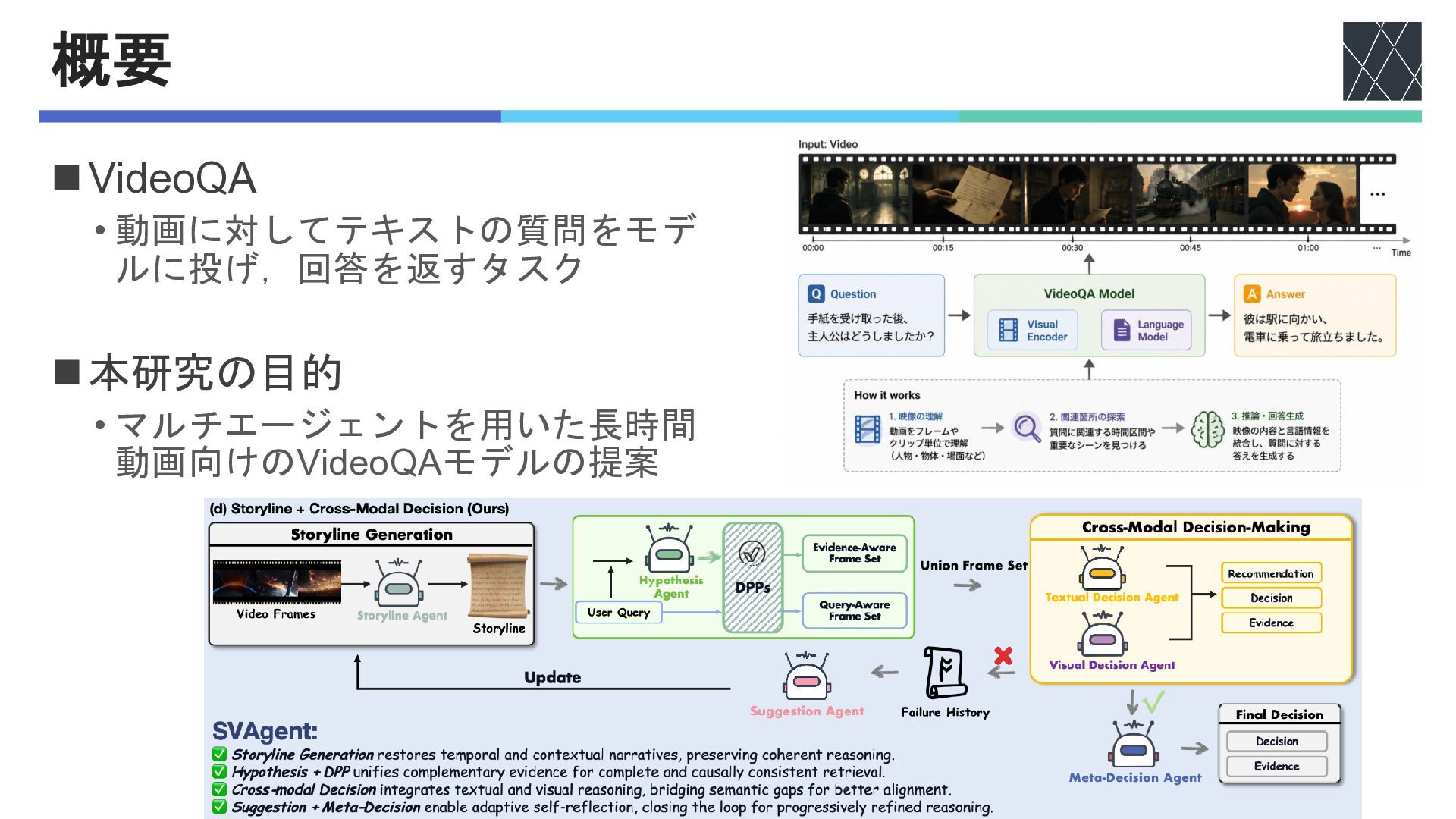
概要 ◼VideoQA • 動画に対してテキストの質問をモデ ルに投げ,回答を返すタスク ◼本研究の目的 • マルチエージェントを用いた長時間 動画向けのVideoQAモデルの提案
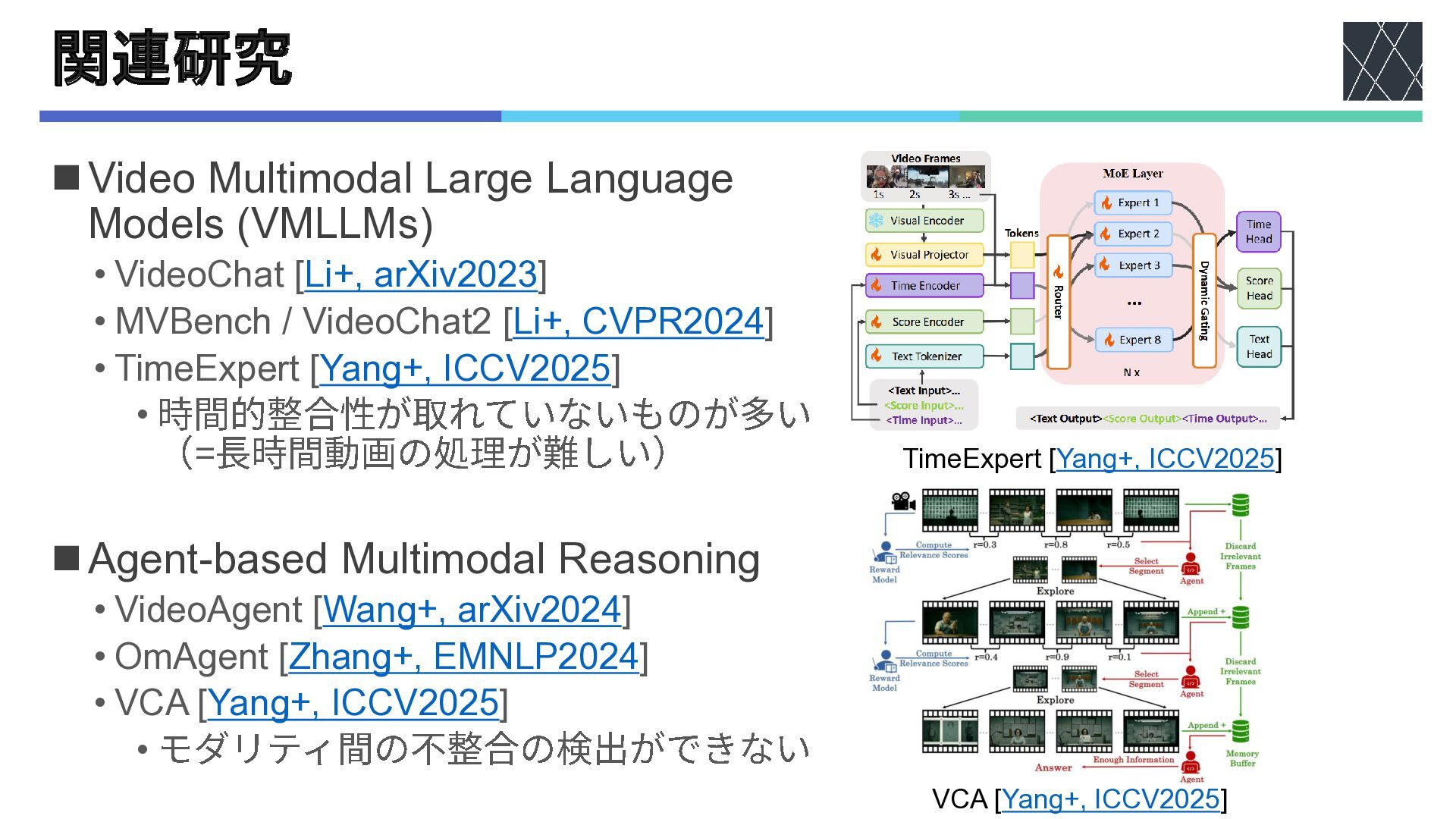
関連研究 ◼Video Multimodal Large Language Models (VMLLMs) • VideoChat [Li+,
arXiv2023] • MVBench / VideoChat2 [Li+, CVPR2024] • TimeExpert [Yang+, ICCV2025] • 時間的整合性が取れていないものが多い (=長時間動画の処理が難しい) ◼Agent-based Multimodal Reasoning • VideoAgent [Wang+, arXiv2024] • OmAgent [Zhang+, EMNLP2024] • VCA [Yang+, ICCV2025] • モダリティ間の不整合の検出ができない TimeExpert [Yang+, ICCV2025] VCA [Yang+, ICCV2025]
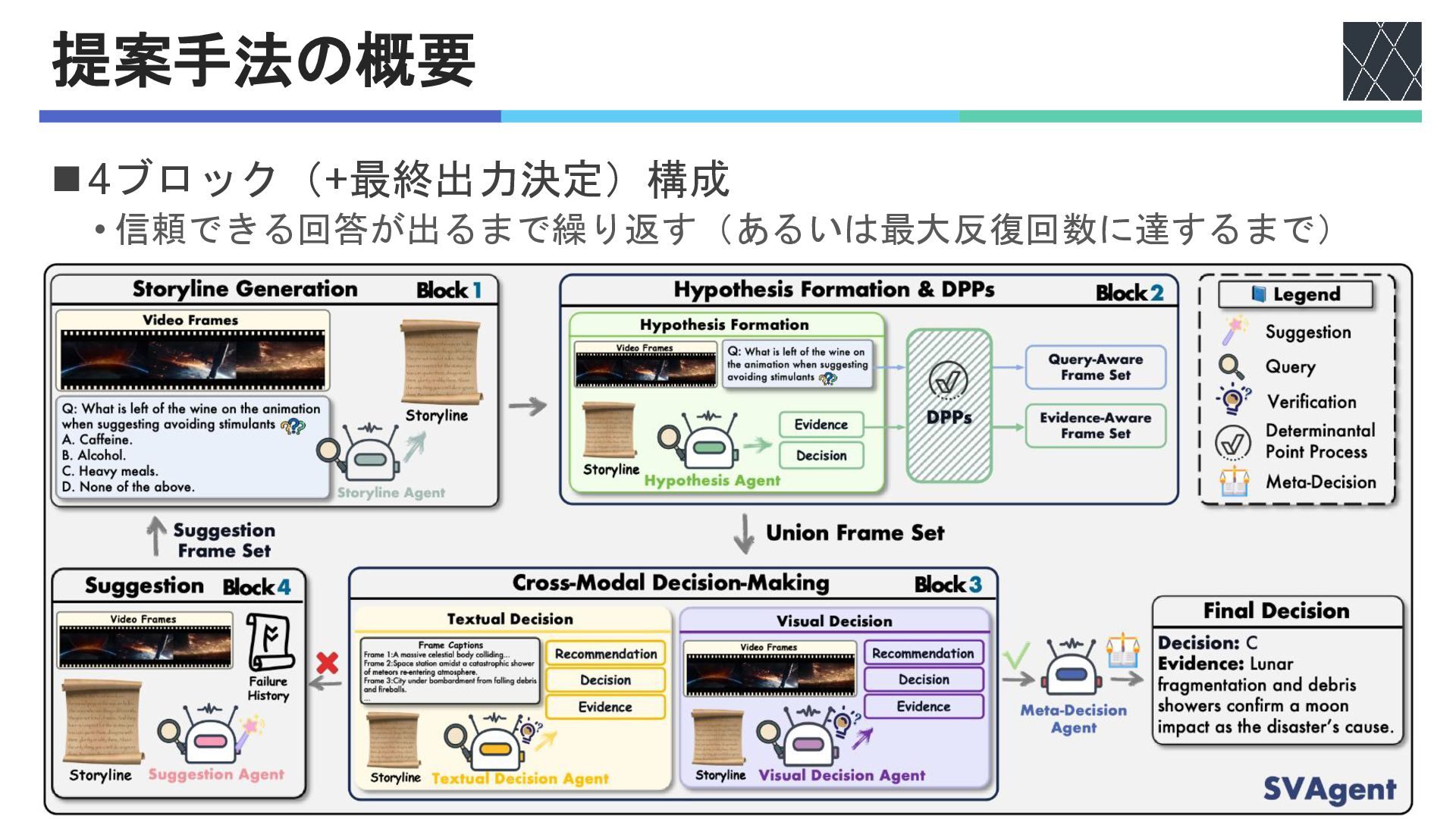
提案手法の概要 ◼4ブロック(+最終出力決定)構成 • 信頼できる回答が出るまで繰り返す(あるいは最大反復回数に達するまで)
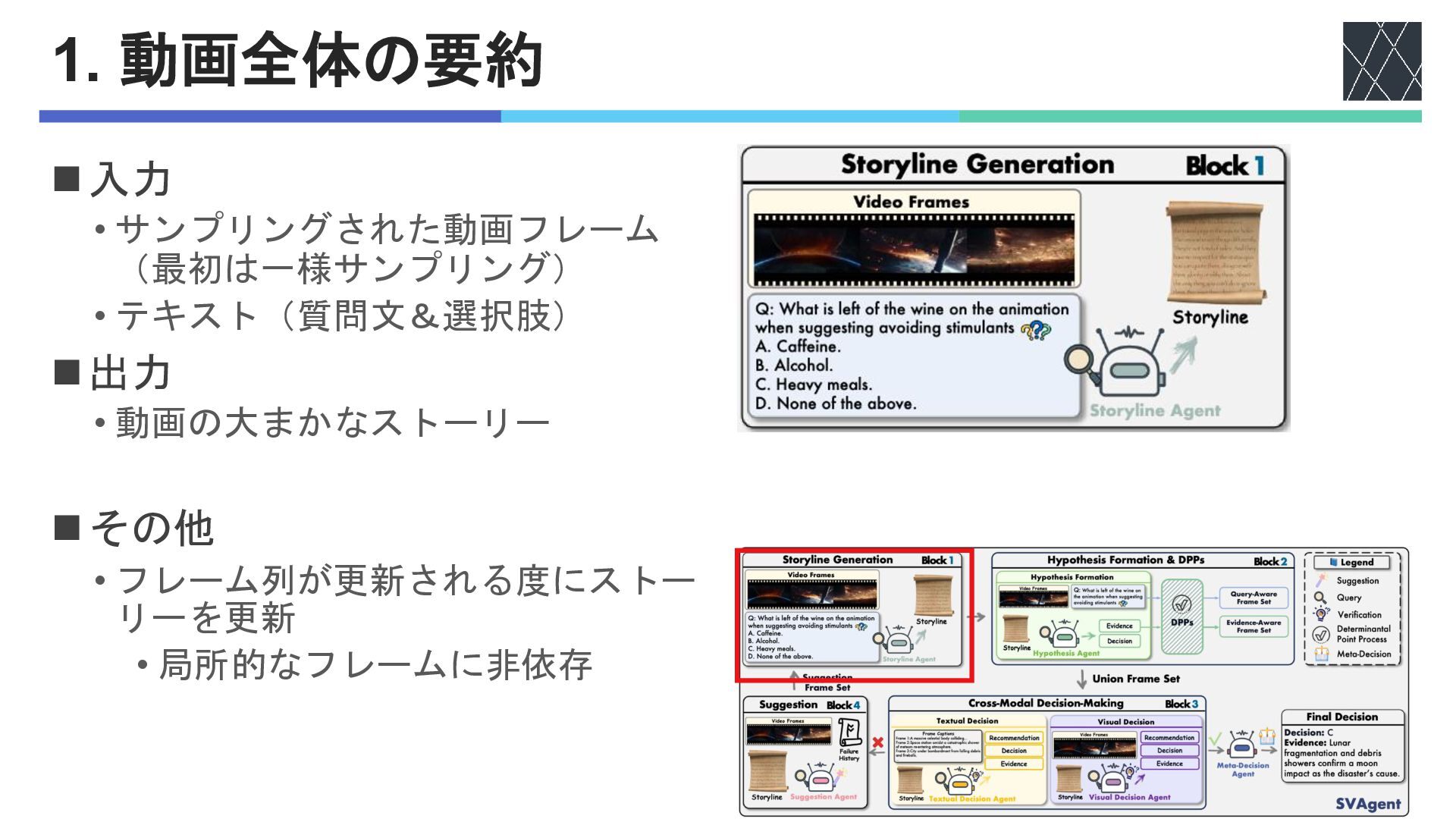
1. 動画全体の要約 ◼入力 • サンプリングされた動画フレーム (最初は一様サンプリング) • テキスト(質問文&選択肢) ◼出力 •
動画の大まかなストーリー ◼その他 • フレーム列が更新される度にストー リーを更新 • 局所的なフレームに非依存
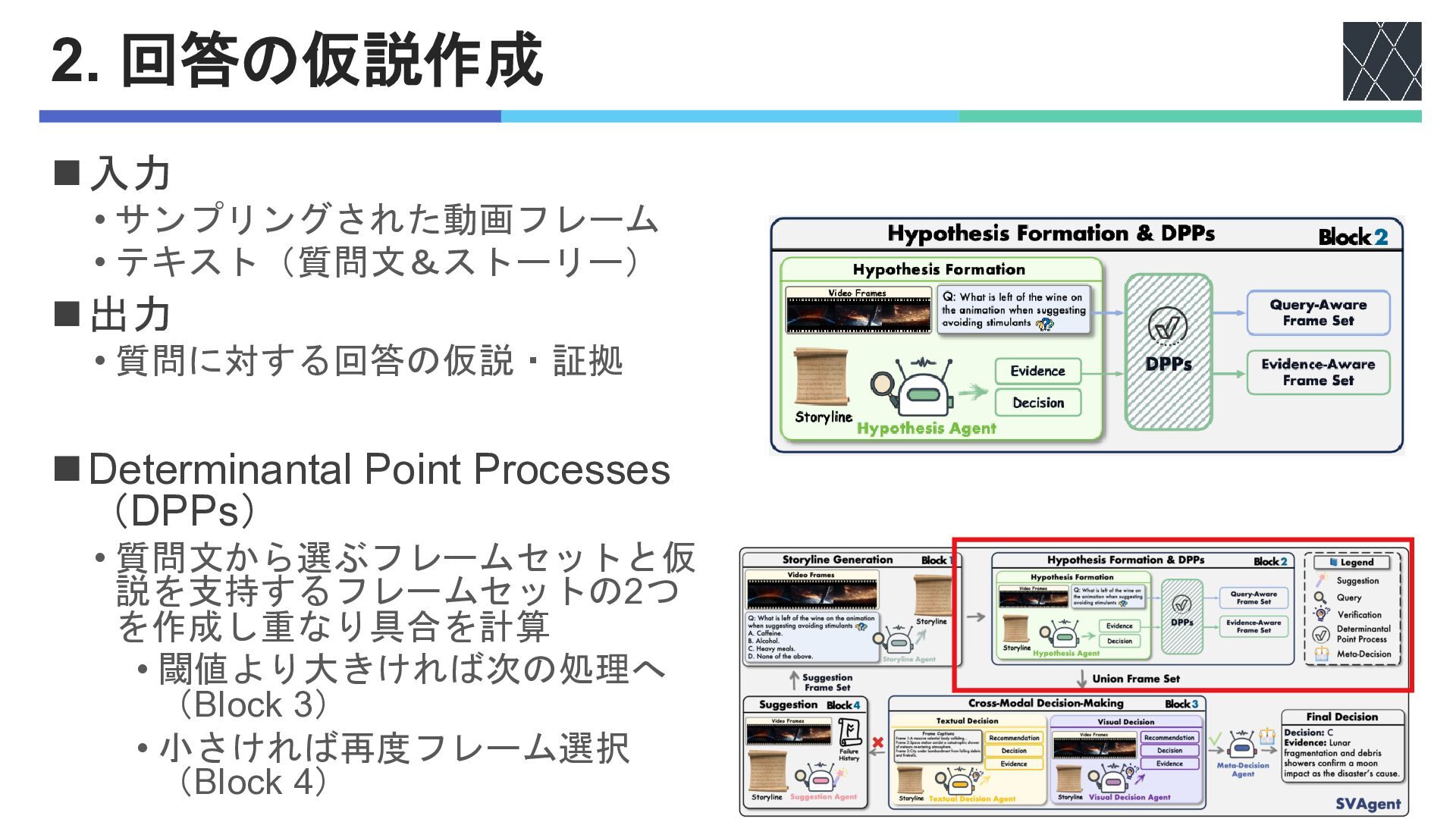
2. 回答の仮説作成 ◼入力 • サンプリングされた動画フレーム • テキスト(質問文&ストーリー) ◼出力 • 質問に対する回答の仮説・証拠
◼Determinantal Point Processes (DPPs) • 質問文から選ぶフレームセットと仮 説を支持するフレームセットの2つ を作成し重なり具合を計算 • 閾値より大きければ次の処理へ (Block 3) • 小さければ再度フレーム選択 (Block 4)
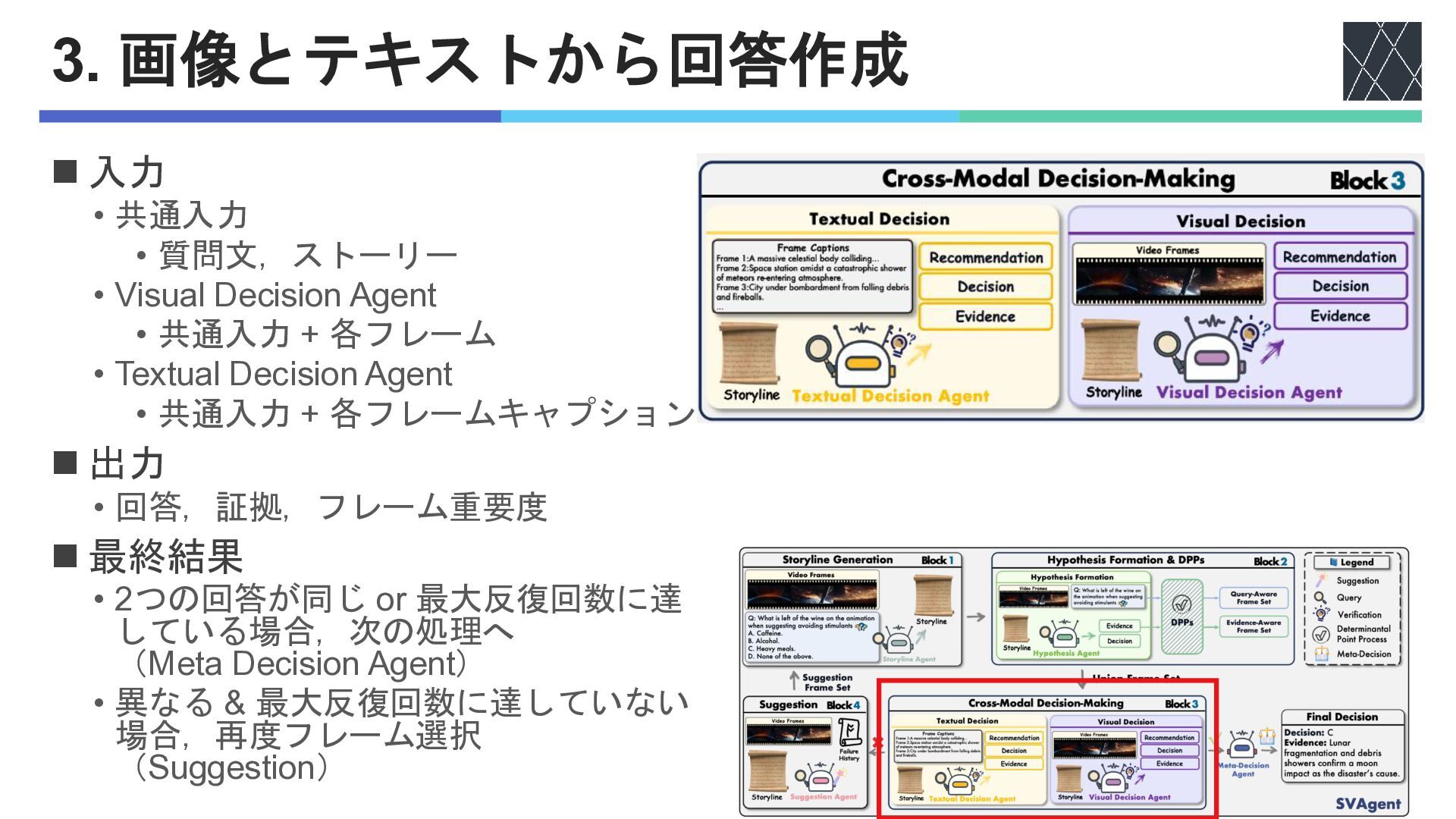
◼ 入力 • 共通入力 • 質問文,ストーリー • Visual Decision Agent
• 共通入力 + 各フレーム • Textual Decision Agent • 共通入力 + 各フレームキャプション ◼ 出力 • 回答,証拠,フレーム重要度 ◼ 最終結果 • 2つの回答が同じ or 最大反復回数に達 している場合,次の処理へ (Meta Decision Agent) • 異なる & 最大反復回数に達していない 場合,再度フレーム選択 (Suggestion) 3. 画像とテキストから回答作成
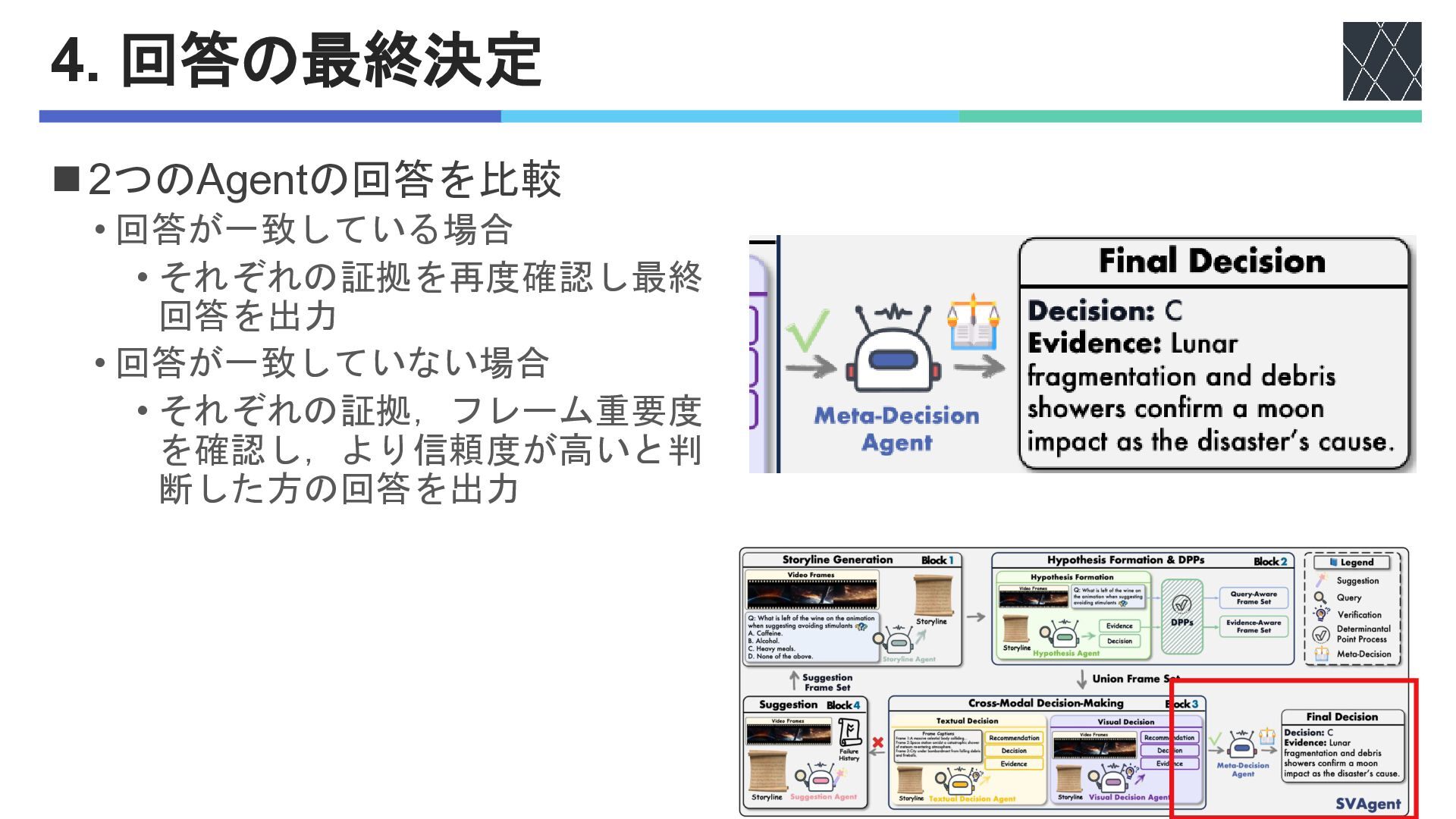
4. 回答の最終決定 ◼2つのAgentの回答を比較 • 回答が一致している場合 • それぞれの証拠を再度確認し最終 回答を出力 • 回答が一致していない場合
• それぞれの証拠,フレーム重要度 を確認し,より信頼度が高いと判 断した方の回答を出力
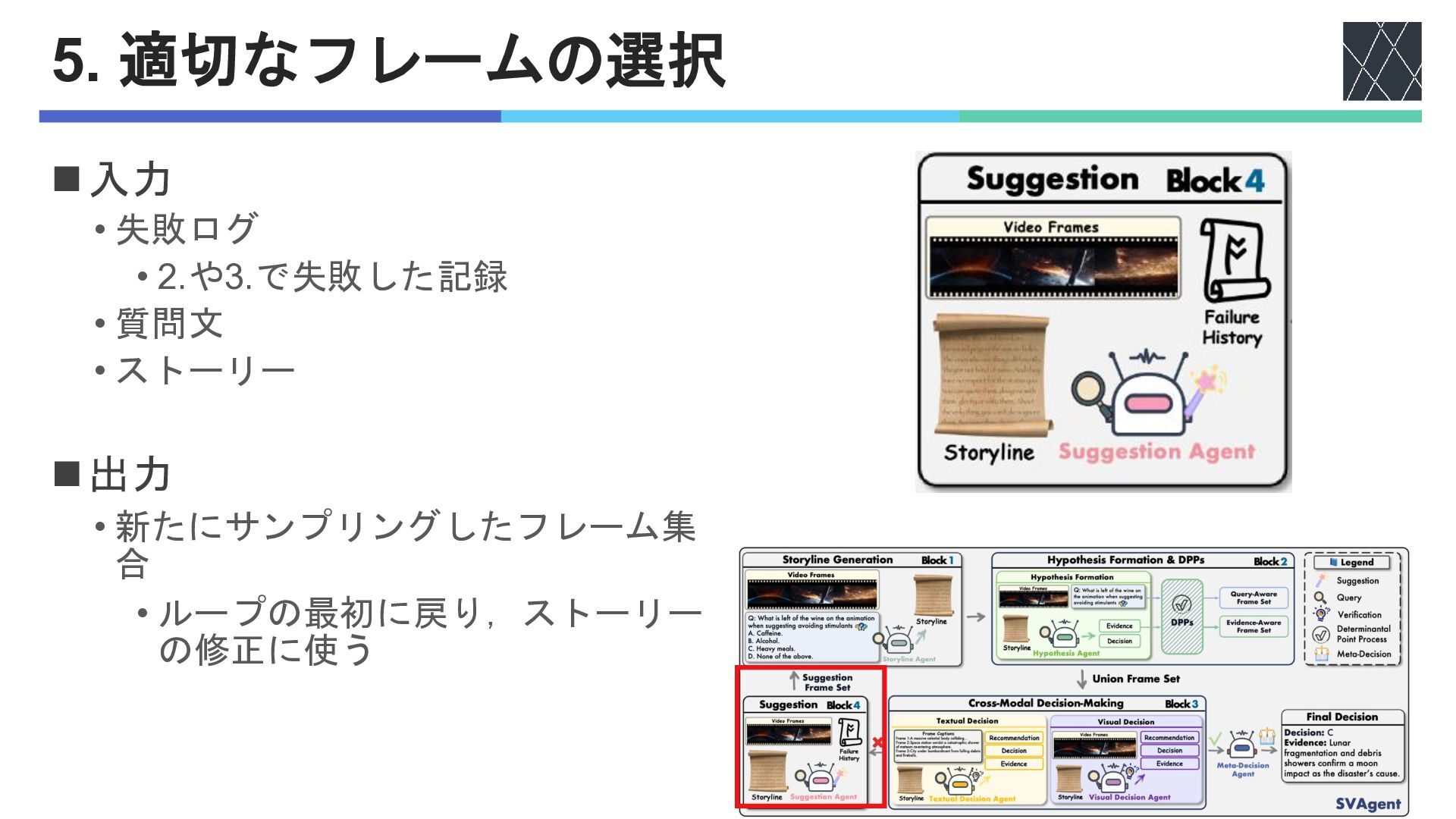
5. 適切なフレームの選択 ◼入力 • 失敗ログ • 2.や3.で失敗した記録 • 質問文 •
ストーリー ◼出力 • 新たにサンプリングしたフレーム集 合 • ループの最初に戻り,ストーリー の修正に使う
実験条件(ベースライン) ◼Backbone Models • Qwen2.5-VL [Bai+, arXiv2025] • Qwen3-VL [Qwen
Team, Technical Report2025] ◼Video MLLMs • Gemini 1.5 Pro [Gemini Team+, arXiv2024] • GPT-4o [OpenAI, System Card2024] • LLaVA-Video [Zhang+, TMLR2025] • Qwen2.5-VL [Bai+, arXiv2025] • InternVL 2.5 [Chen+, arXiv2024] ◼Open-source Video Agents / Long-video Reasoning Baselines • VideoMind [Liu+, arXiv2025] • Vgent [Shen+, NeurIPS2025] • Video-RAG [Luo+, arXiv2024] • VideoAgent [Wang+, arXiv2024] Qwen3-VL [Qwen Team, Technical Report2025]
実験条件(データセット&実装) ◼データセット • LongVideoBench [Wu+, NeurIPS2024] • MLVU [Zhou+, arXiv2024]
• LVBench [Wang+, ICCV2025] • Video-MME [Fu+, CVPR2025] ◼実装 • 初期サンプリングFPS:1.0 • フレーム集合間の重なり具合の 閾値:0.3 • 最大反復回数:3 Video-MME [Fu+, CVPR2025]
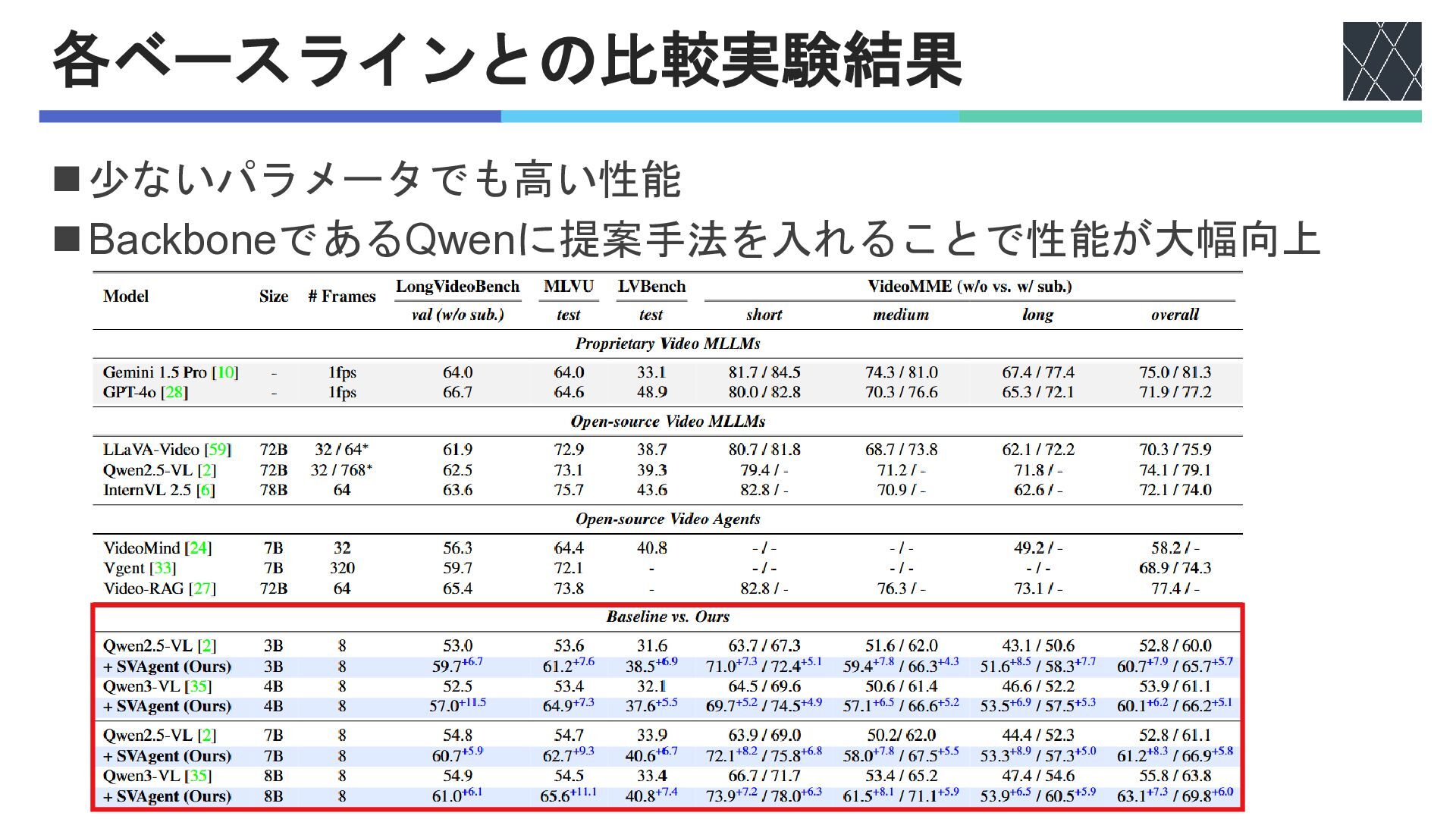
各ベースラインとの比較実験結果 ◼少ないパラメータでも高い性能 ◼BackboneであるQwenに提案手法を入れることで性能が大幅向上
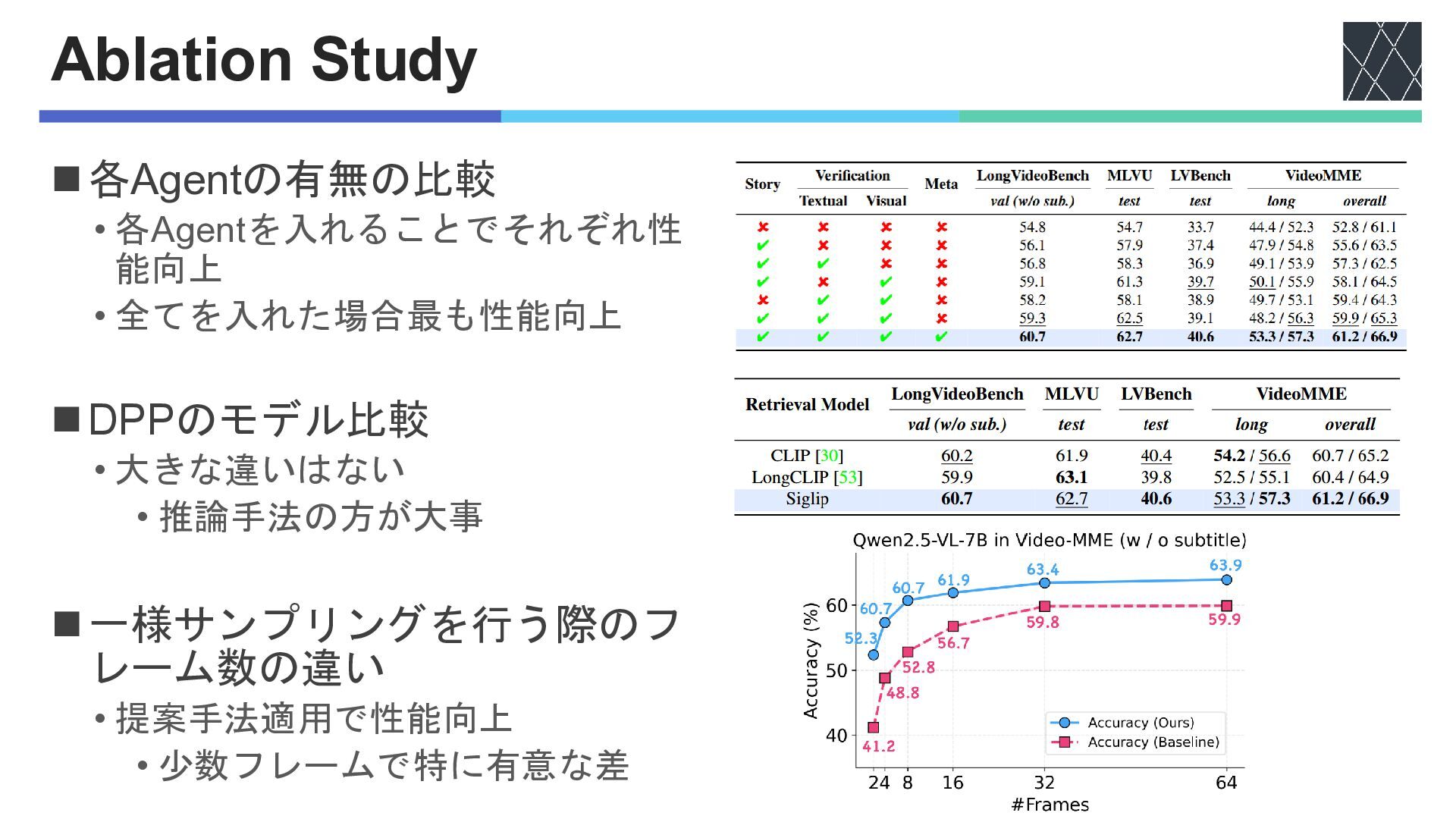
Ablation Study ◼各Agentの有無の比較 • 各Agentを入れることでそれぞれ性 能向上 • 全てを入れた場合最も性能向上 ◼DPPのモデル比較 •
大きな違いはない • 推論手法の方が大事 ◼一様サンプリングを行う際のフ レーム数の違い • 提案手法適用で性能向上 • 少数フレームで特に有意な差
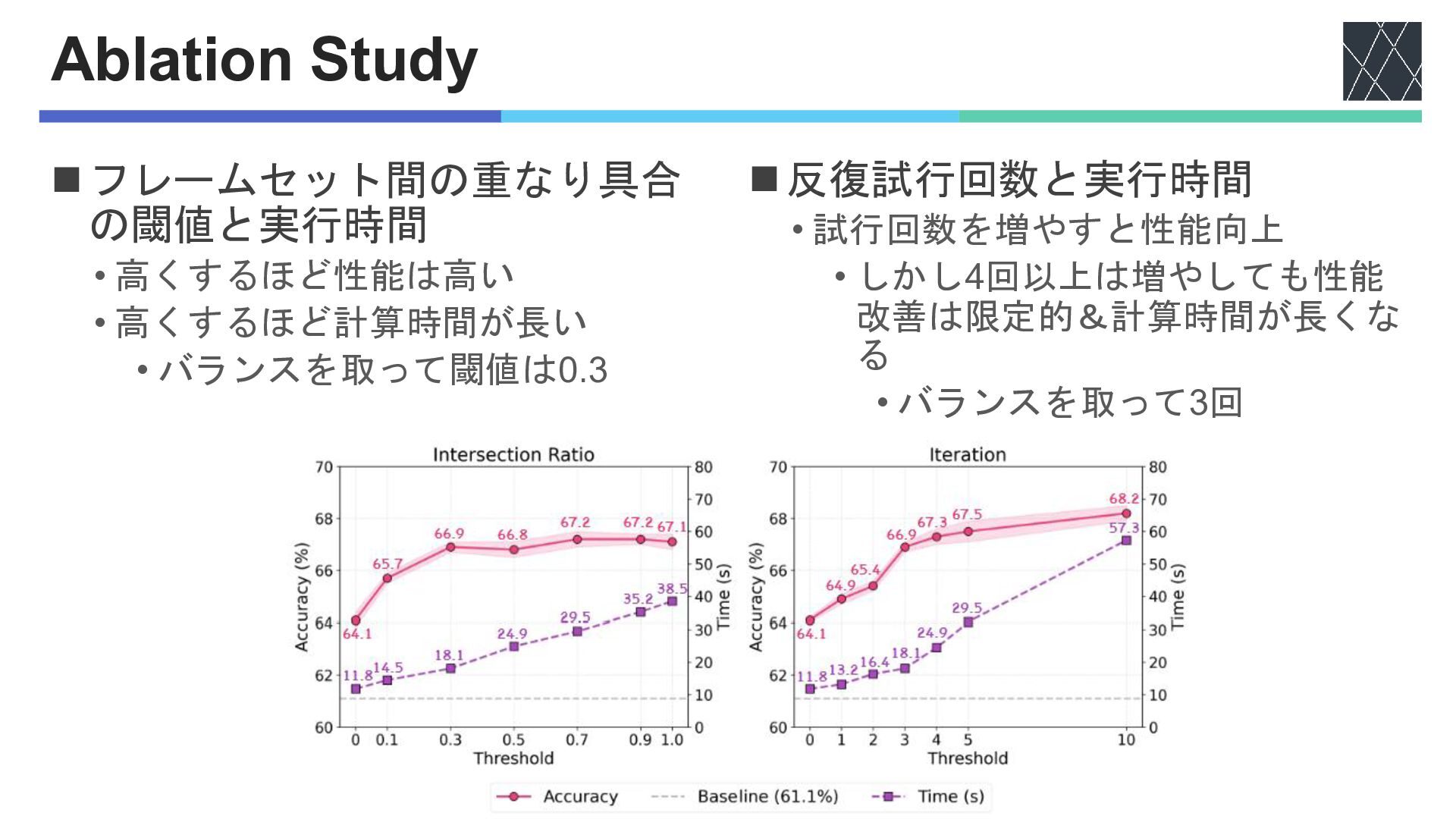
Ablation Study ◼フレームセット間の重なり具合 の閾値と実行時間 • 高くするほど性能は高い • 高くするほど計算時間が長い • バランスを取って閾値は0.3
◼反復試行回数と実行時間 • 試行回数を増やすと性能向上 • しかし4回以上は増やしても性能 改善は限定的&計算時間が長くな る • バランスを取って3回
定性的結果 ◼結果
まとめ ◼長時間動画用のVideoQAモデルの提案 • マルチモーダルエージェントの活用 ◼Textual DecisionとVisual Decisionの両面から判断 • モダリティ間での整合性を取る ◼長時間動画用のベンチマークでの実証
• 少ないパラメータのVMLLMでも高い性能を発揮
補足
アルゴリズム
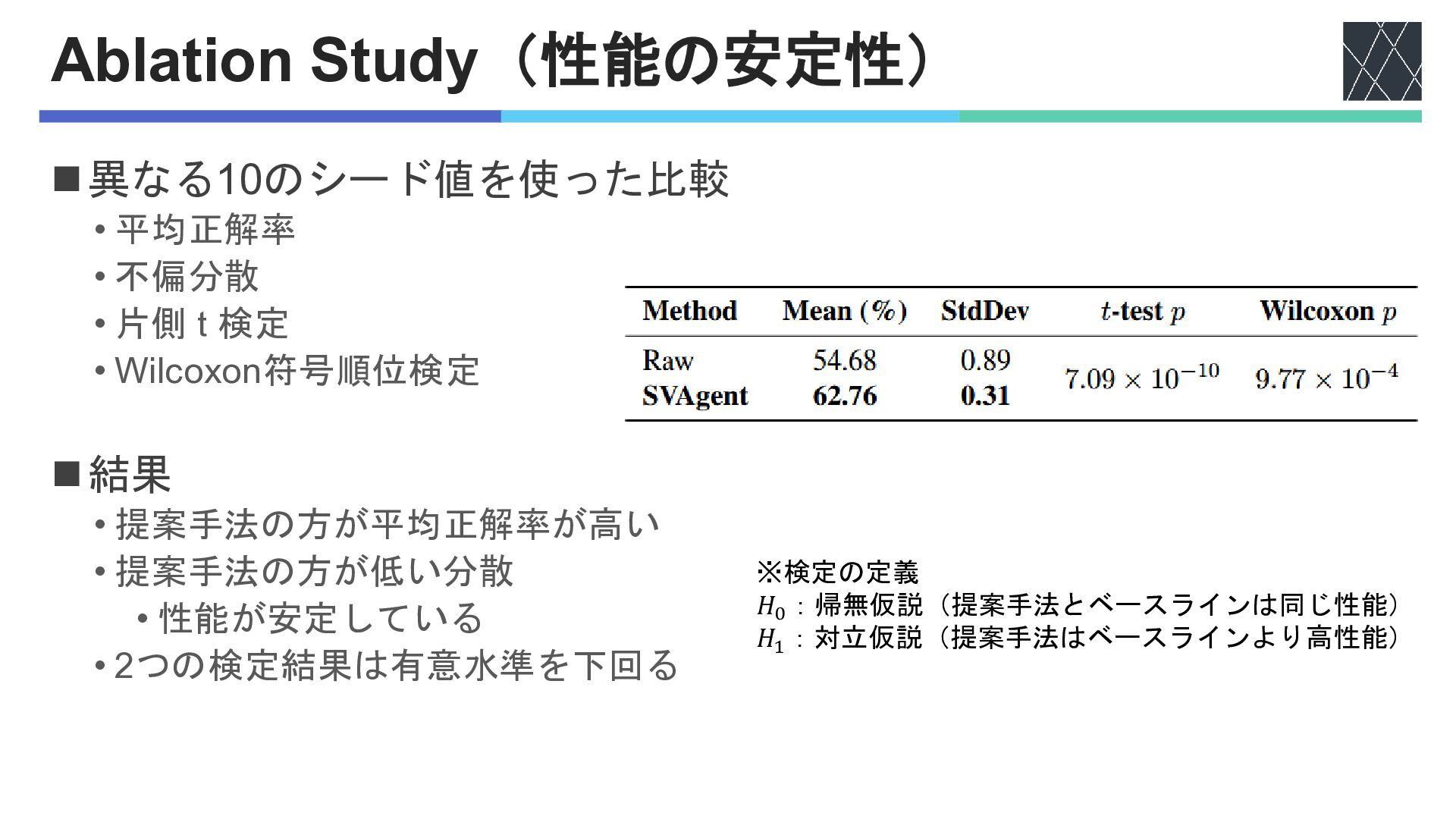
Ablation Study(性能の安定性) ◼異なる10のシード値を使った比較 • 平均正解率 • 不偏分散 • 片側 t
検定 • Wilcoxon符号順位検定 ◼結果 • 提案手法の方が平均正解率が高い • 提案手法の方が低い分散 • 性能が安定している • 2つの検定結果は有意水準を下回る ※検定の定義 𝐻0 :帰無仮説(提案手法とベースラインは同じ性能) 𝐻1 :対立仮説(提案手法はベースラインより高性能)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験条件(ベースライン) ◼Backbone Models • Qwen2.5-VL [Bai+, arXiv2025] • Qwen3-VL [Qwen](https://files.speakerdeck.com/presentations/345f550637364bc589caf97604b8dde0/slide_9.jpg){kind=link}
![実験条件(データセット&実装) ◼データセット • LongVideoBench [Wu+, NeurIPS2024] • MLVU [Zhou+, arXiv2024]](https://files.speakerdeck.com/presentations/345f550637364bc589caf97604b8dde0/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}