⭐️ Full Steam Ahead: Engineering a Modern Data Platform at Rhaetian Railway#
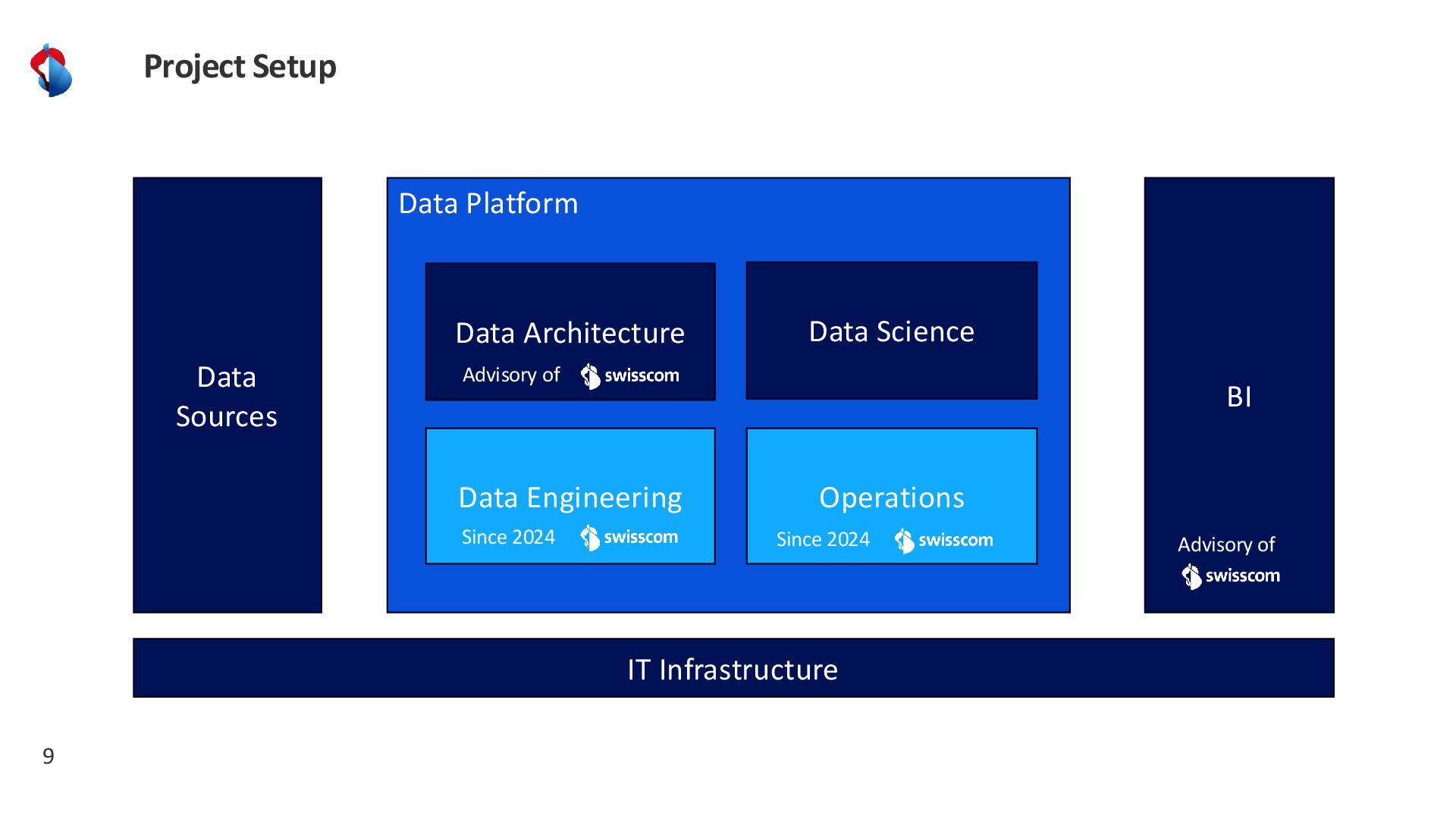
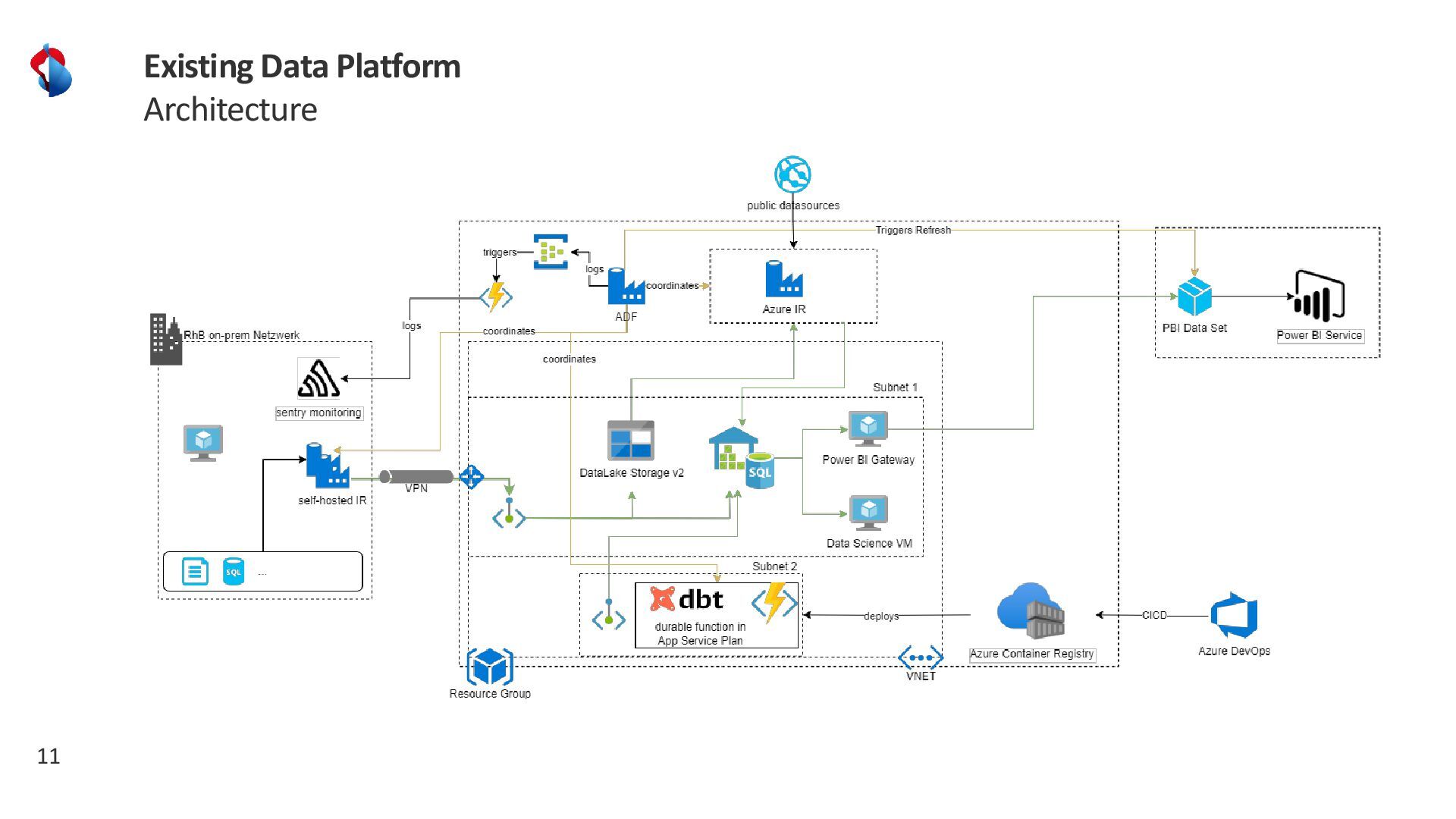
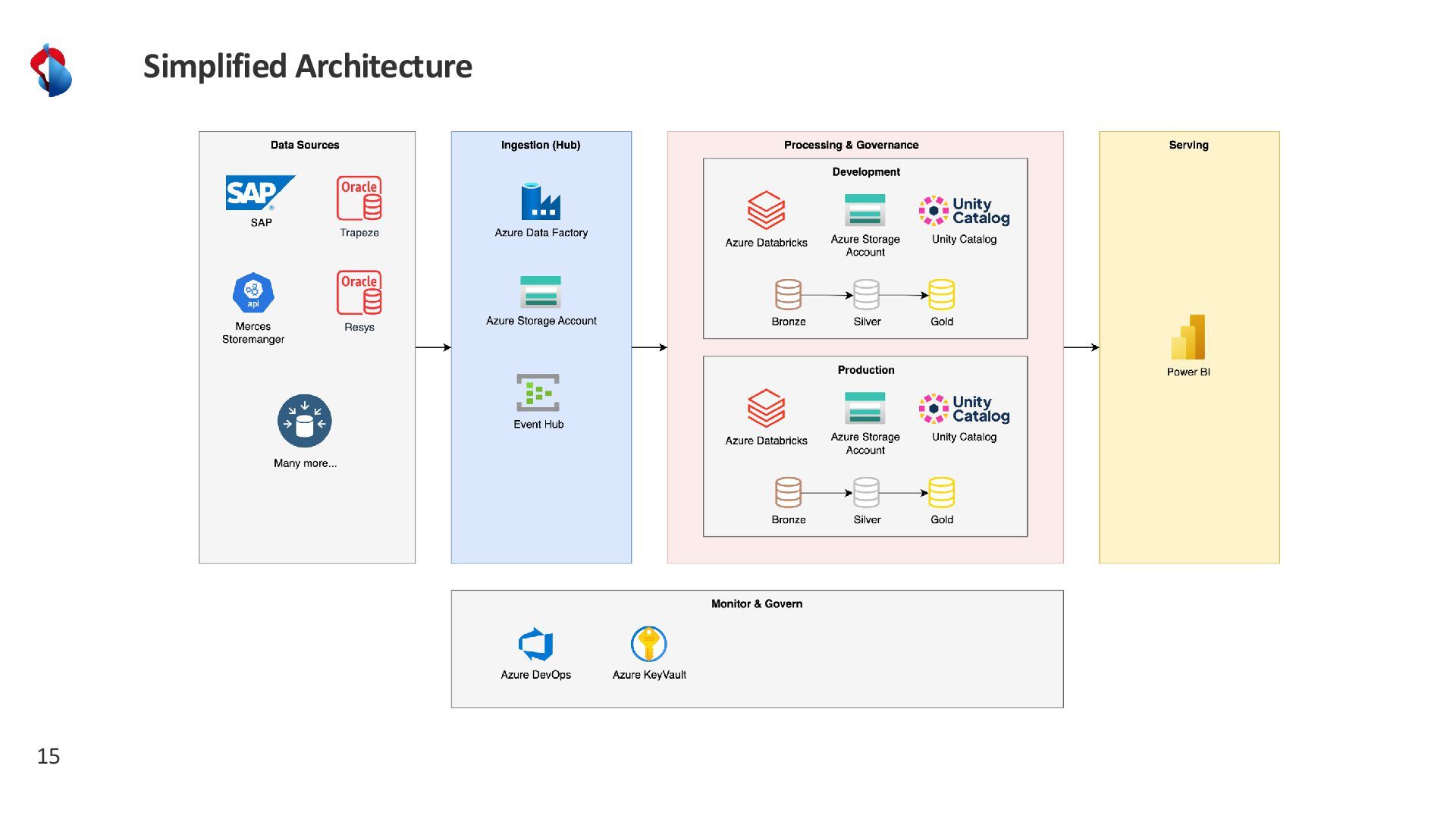
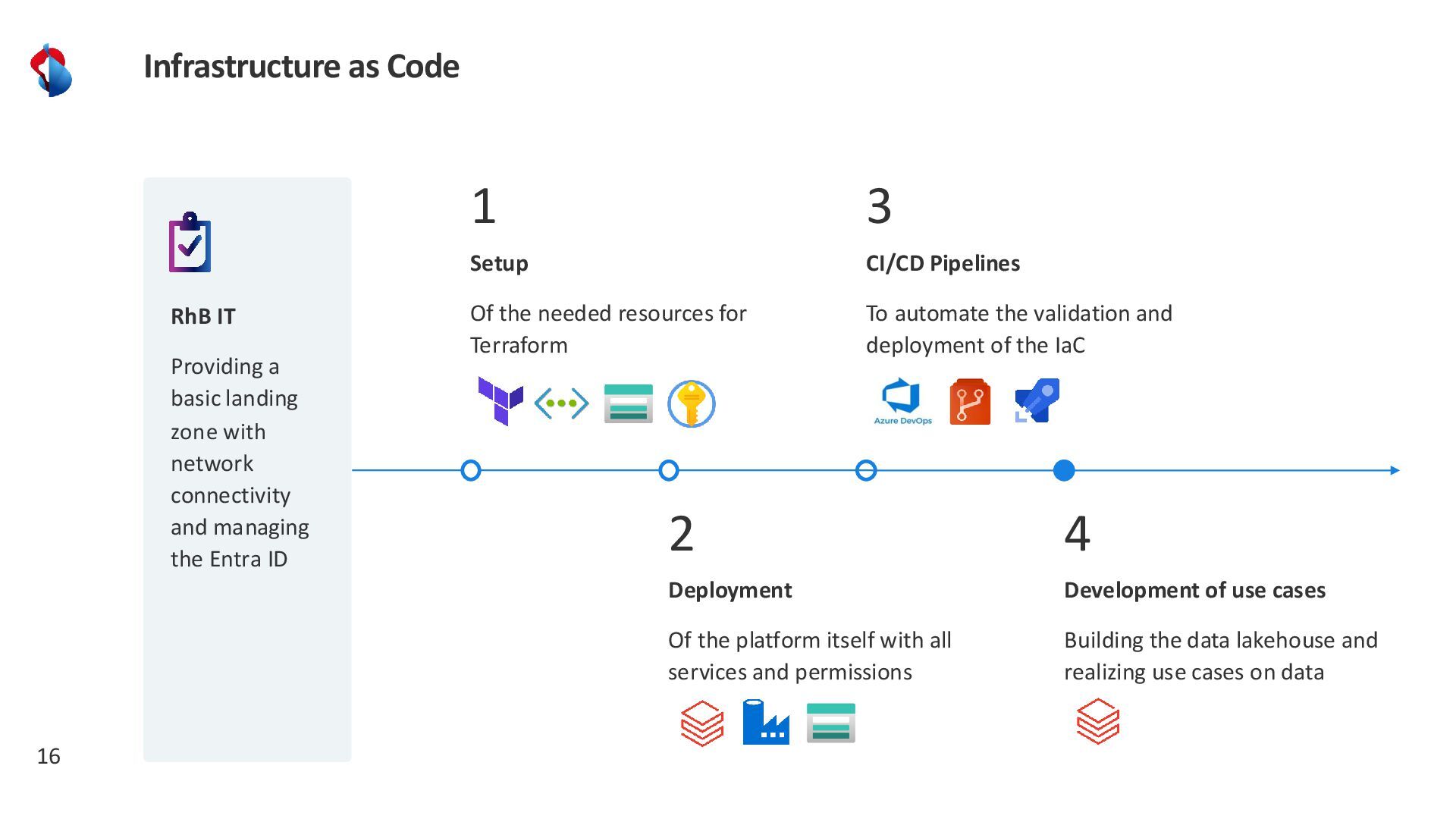
Discover how Rhaetian Railway is modernizing its data landscape using Azure Databricks, Terraform Infrastructure-as-Code, and Azure DevOps. We’ll explore how CI/CD pipelines streamline development, testing, and deployment across multiple environments, while a configuration file–driven approach brings flexibility and agility to data pipeline management. Learn about our key design principles, best practices for parameterizing data flows at scale, how we incorporate data quality checks to ensure reliable analytics, and the lessons we’ve learned on our journey toward a fully automated, high-performance data platform.
🙂 SIMON SCHWAB ⚡️ Senior Data & Analytics Consultant @ Swisscom
🙂 LUKAS HEUSSER ⚡️ Senior Data & AI Consultant @ Swisscom
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
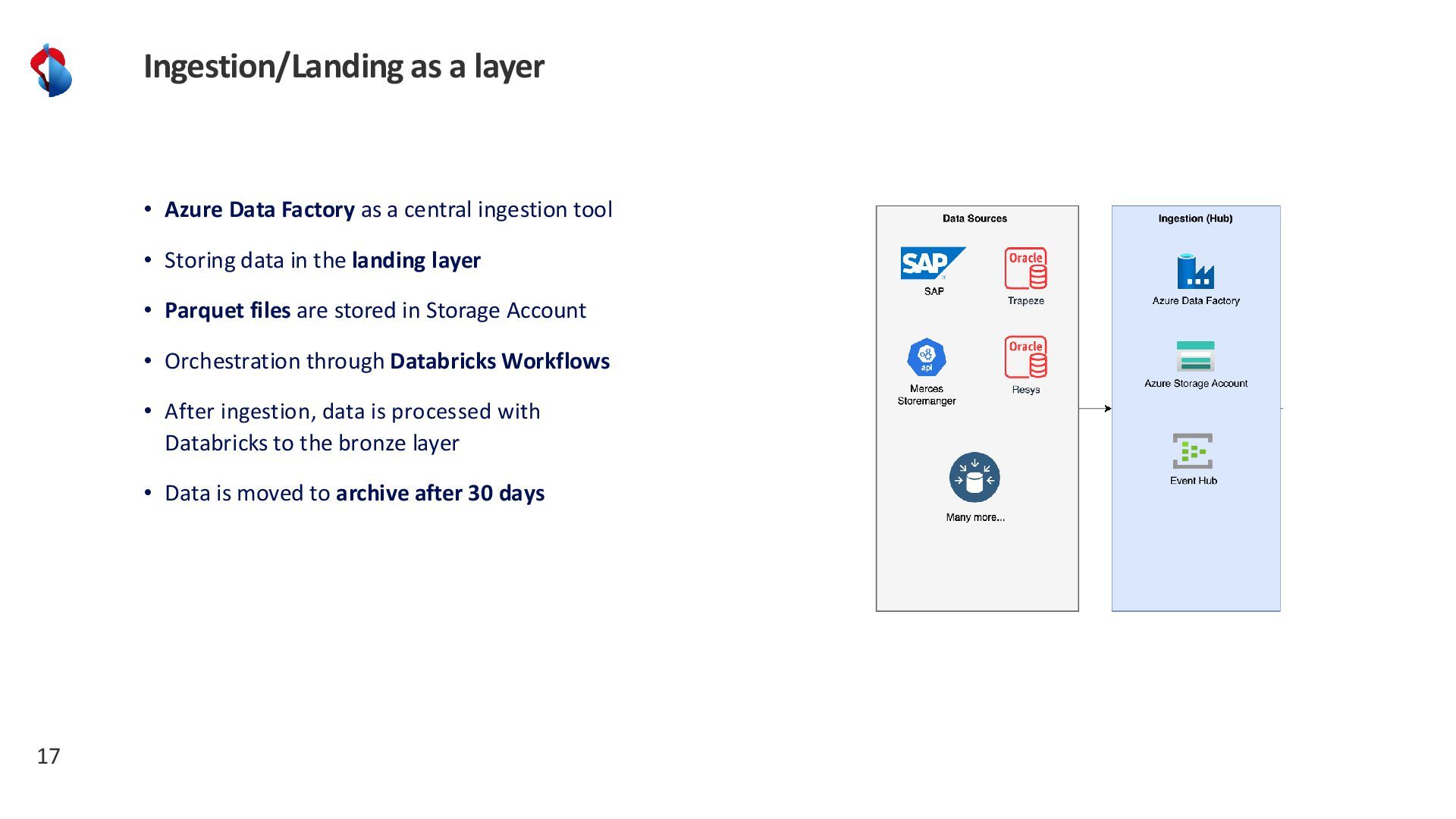{kind=link}
{kind=link}
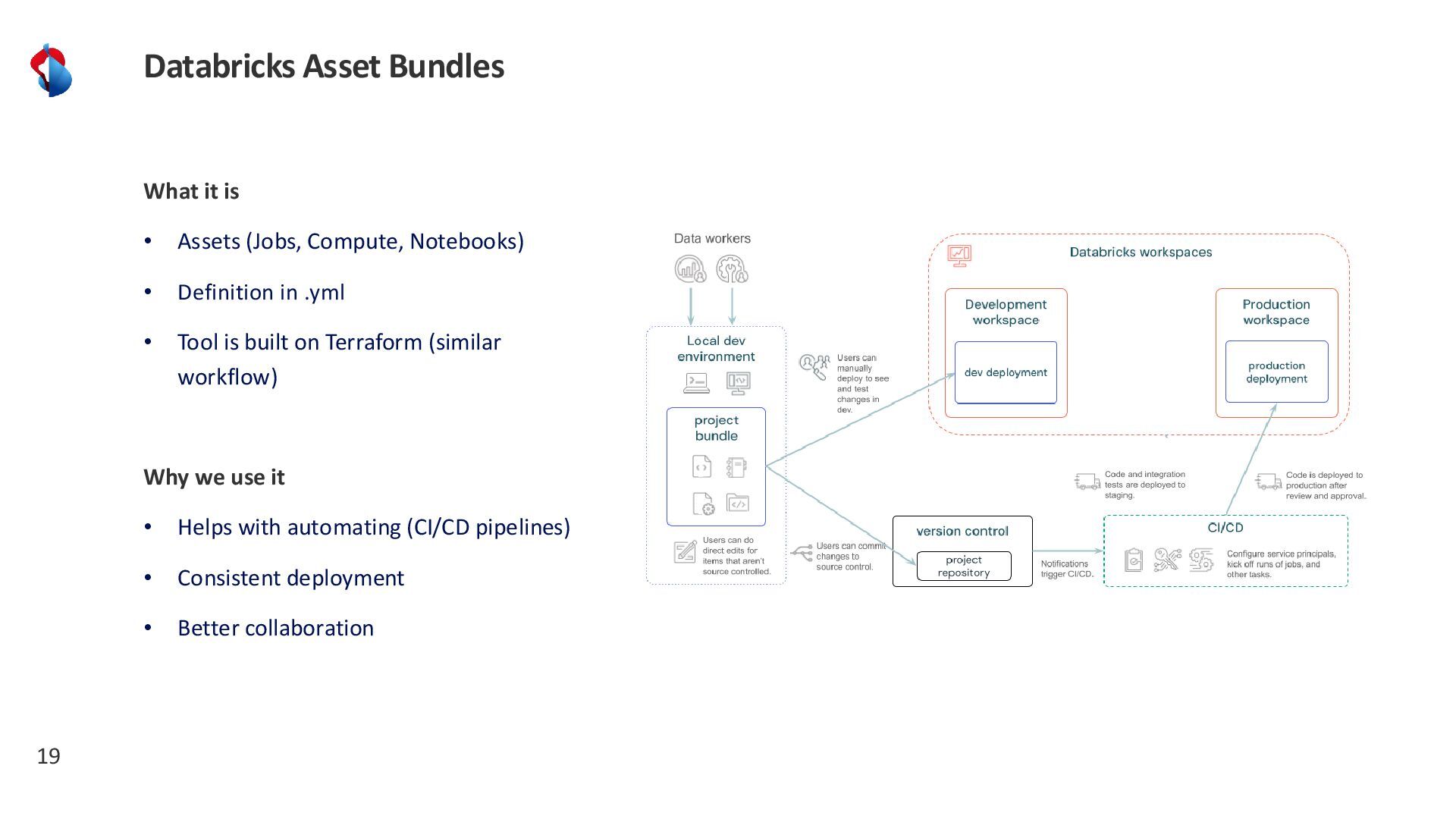{kind=link}
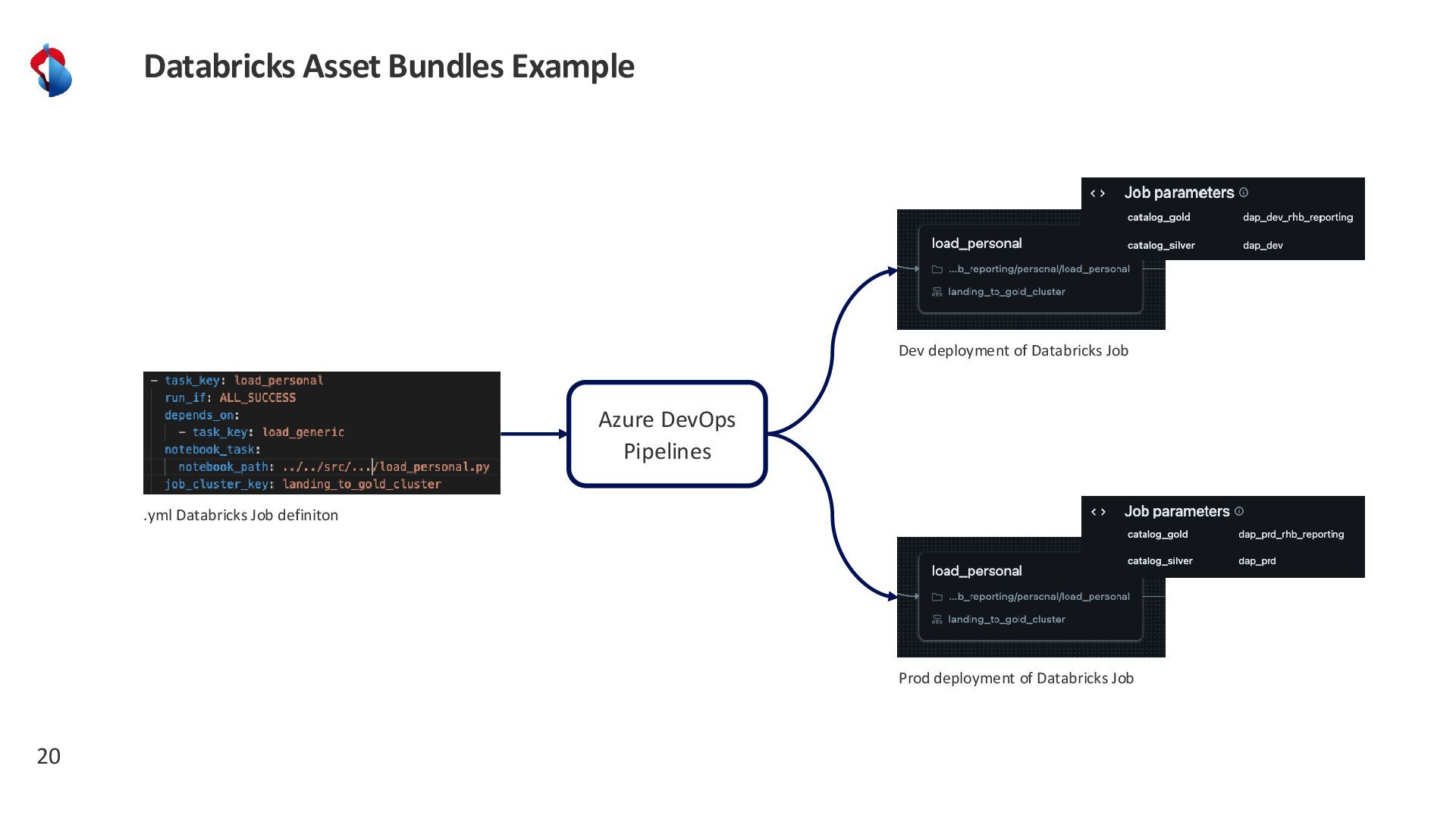{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}