⭐️ Enhancing Legal Document Analysis with Reflection Agents, Semantic Kernel, and Azure AI Search#
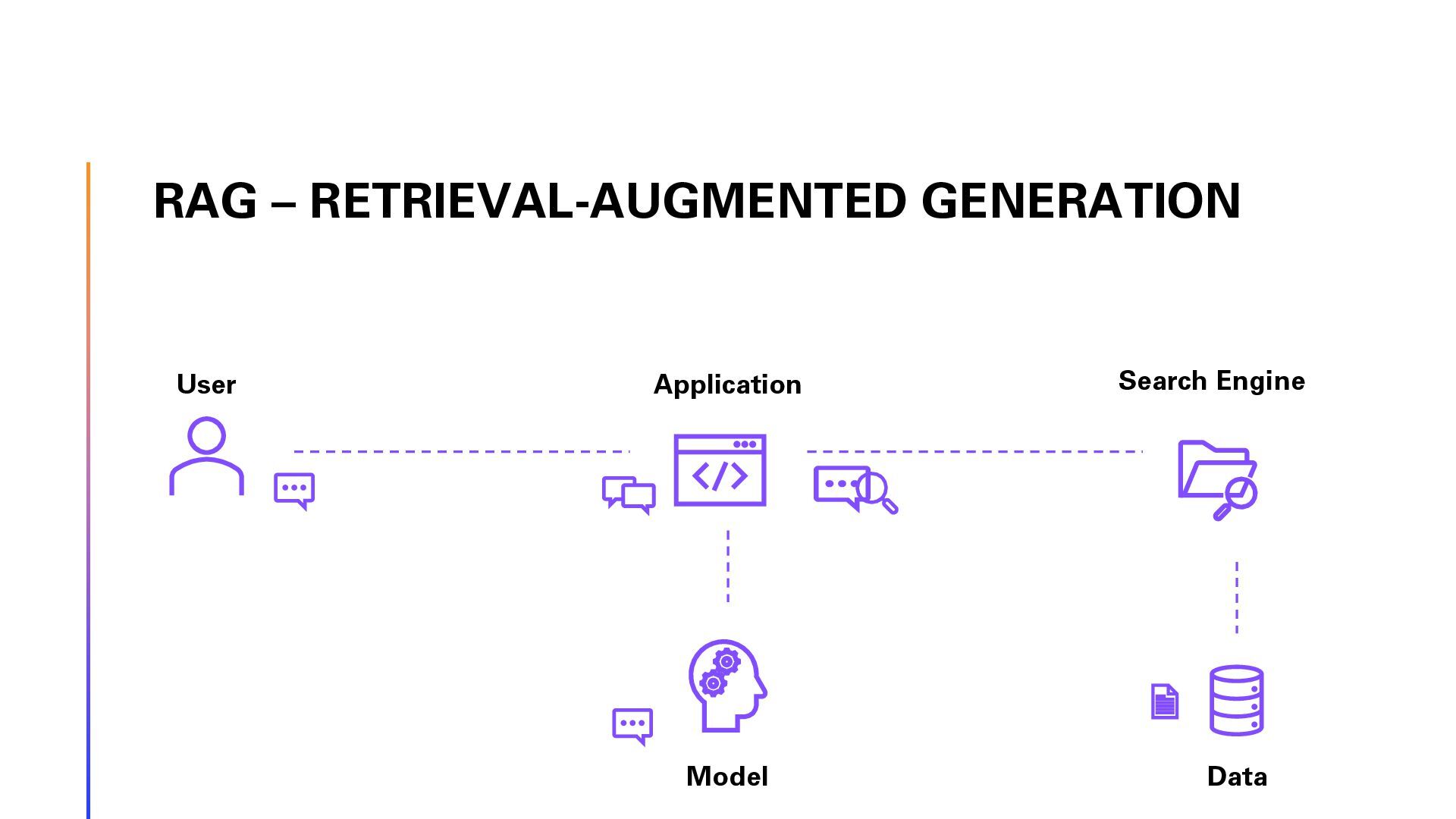
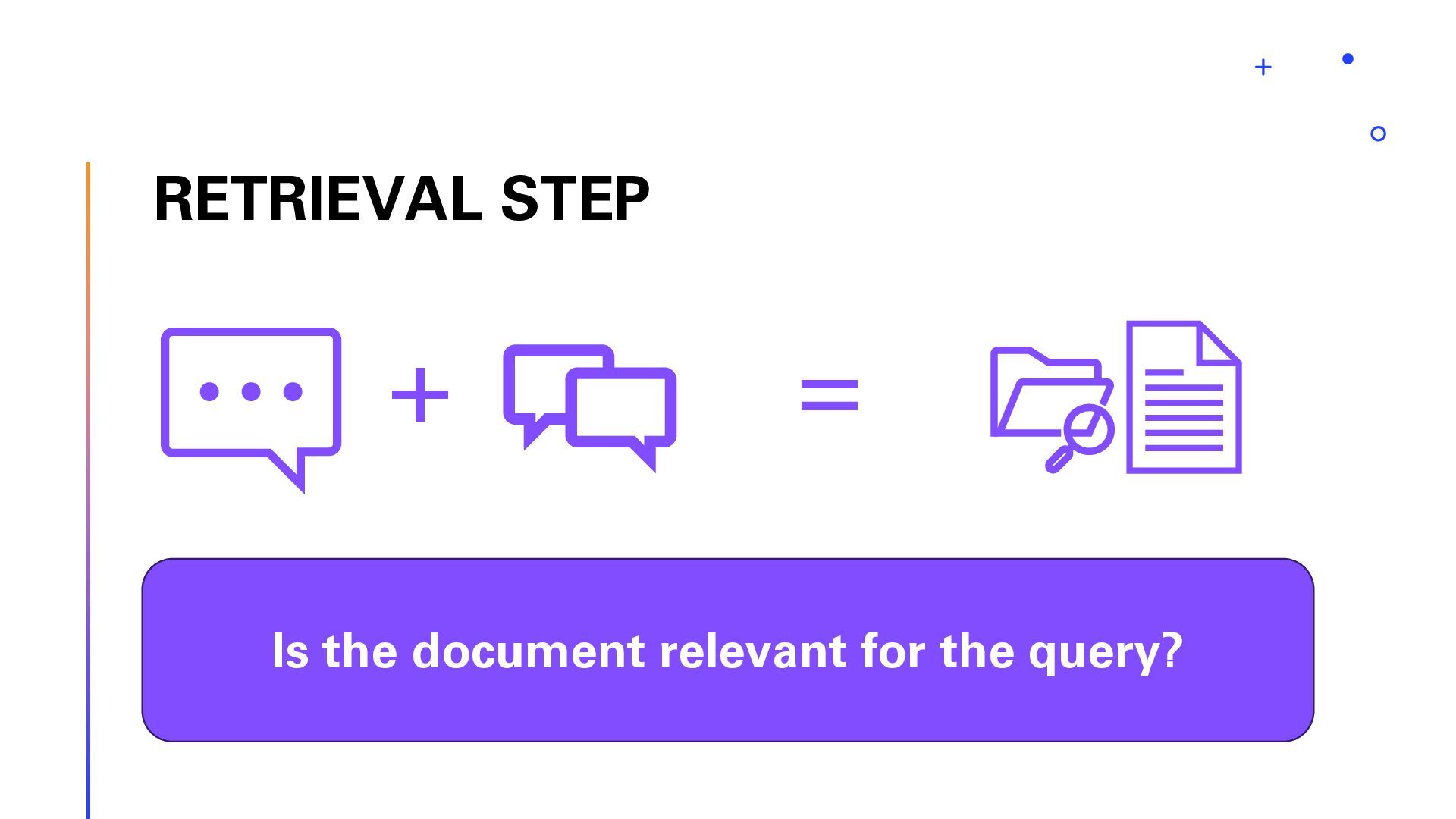
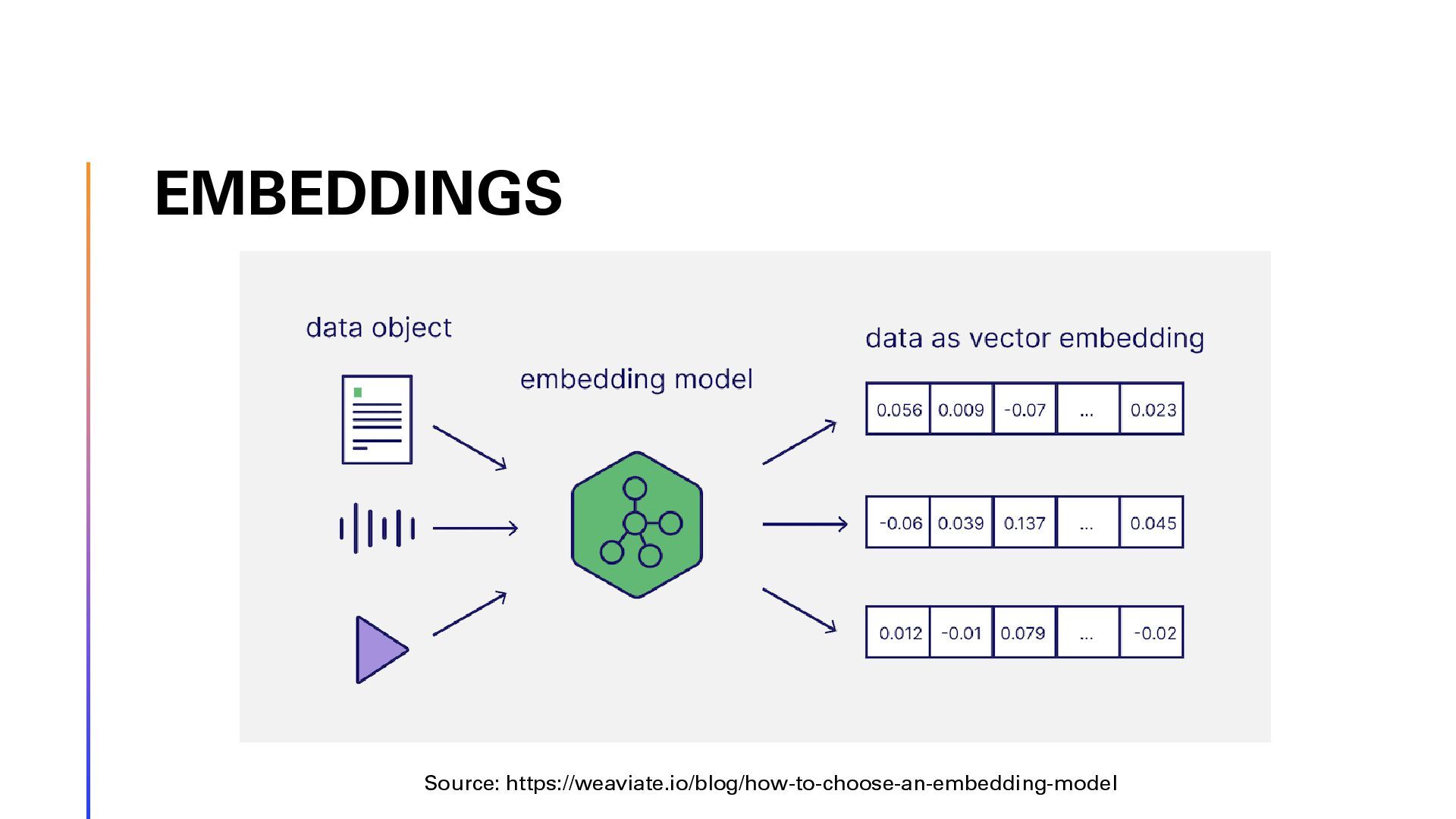
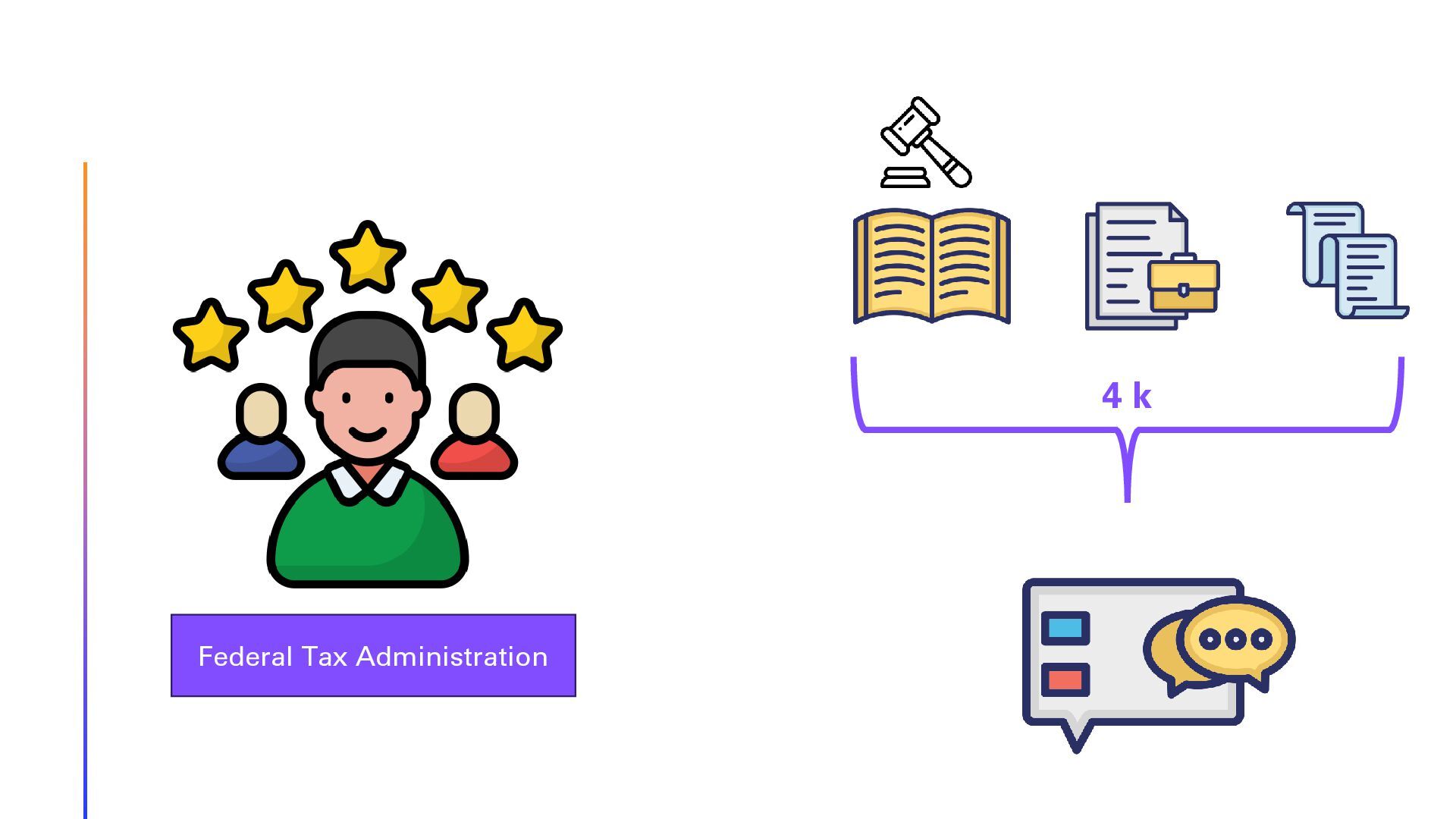
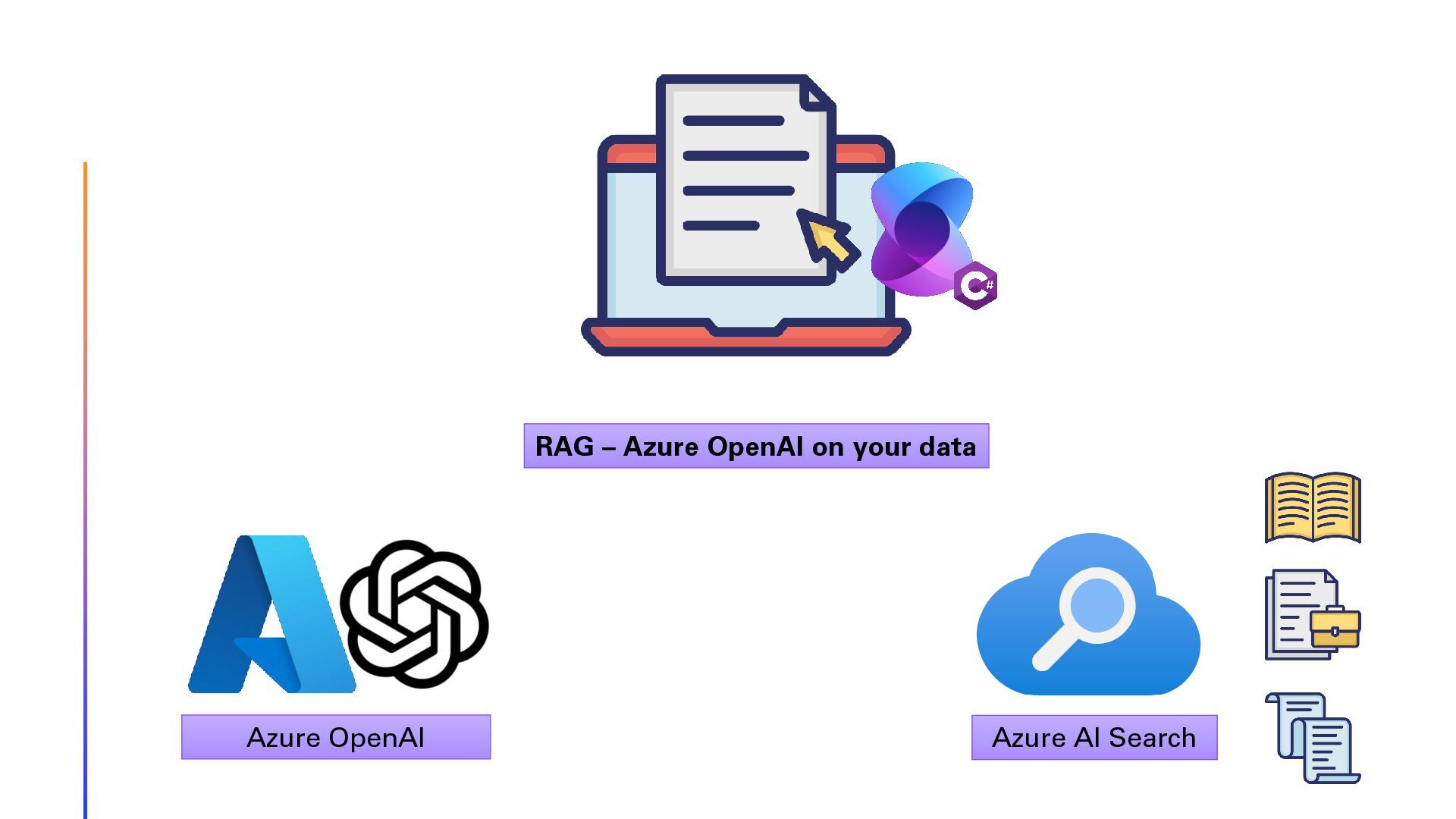
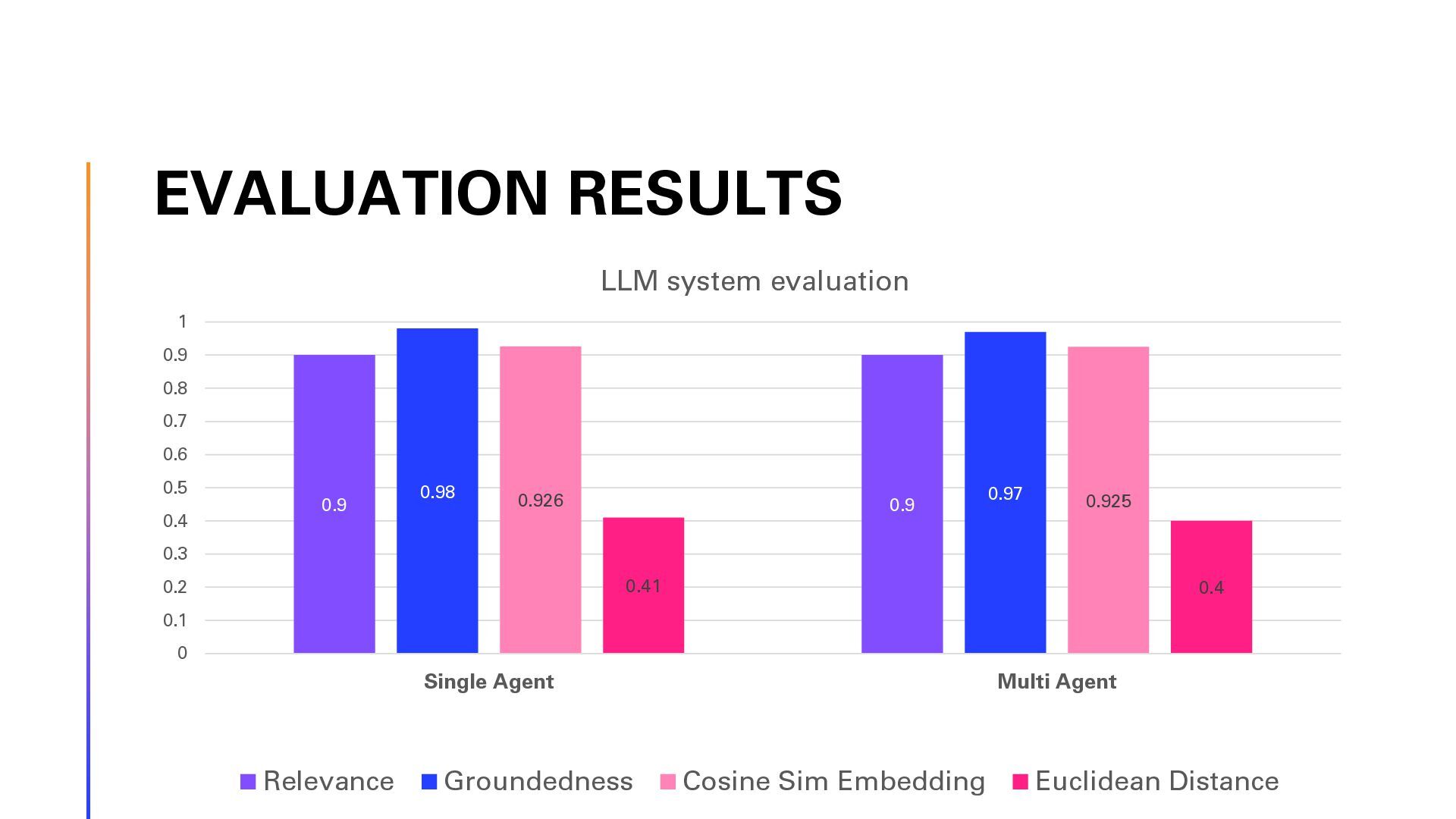
In this session, we will explore the implementation of Retrieval-Augmented Generation (RAG) on Swiss law documents using Semantic Kernel and Azure AI Search. We will delve into the step-by-step optimization process that enhanced the solution’s efficiency and accuracy. Finally, show the architecture using Reflection Agents and advanced Azure AI Search capabilities. Attendees will gain insights into the challenges faced, the strategies employed to overcome them, and the significant improvements achieved in legal document analysis. This session is ideal for developers, data scientists, and legal tech enthusiasts looking to leverage advanced AI techniques for document processing and analysis. Join us to discover how cutting-edge technology can transform the way we interact with complex legal texts.
🙂 CÉDRIC MENDELIN ⚡️ Senior Software Developer @ isolutions
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
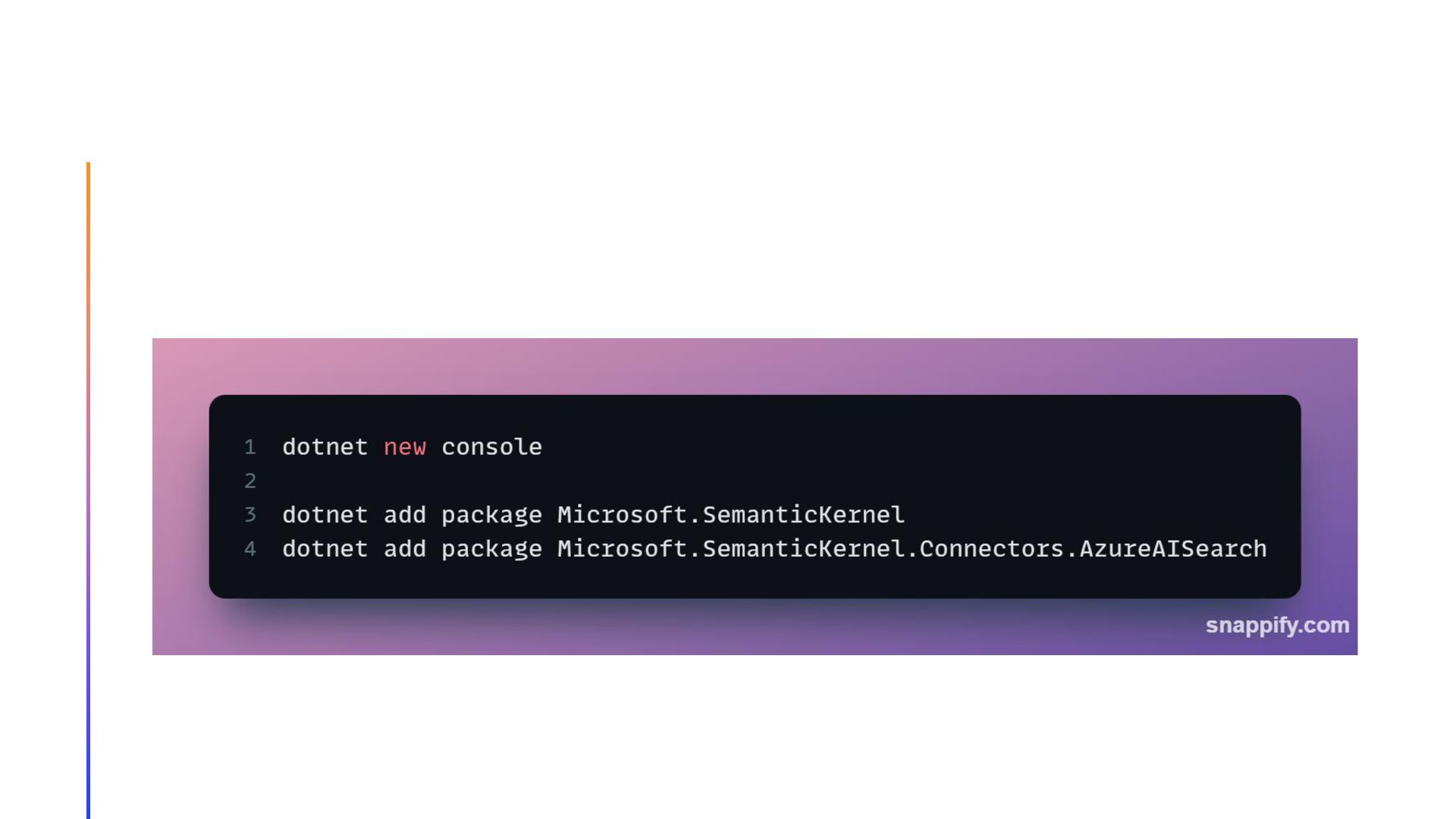{kind=link}
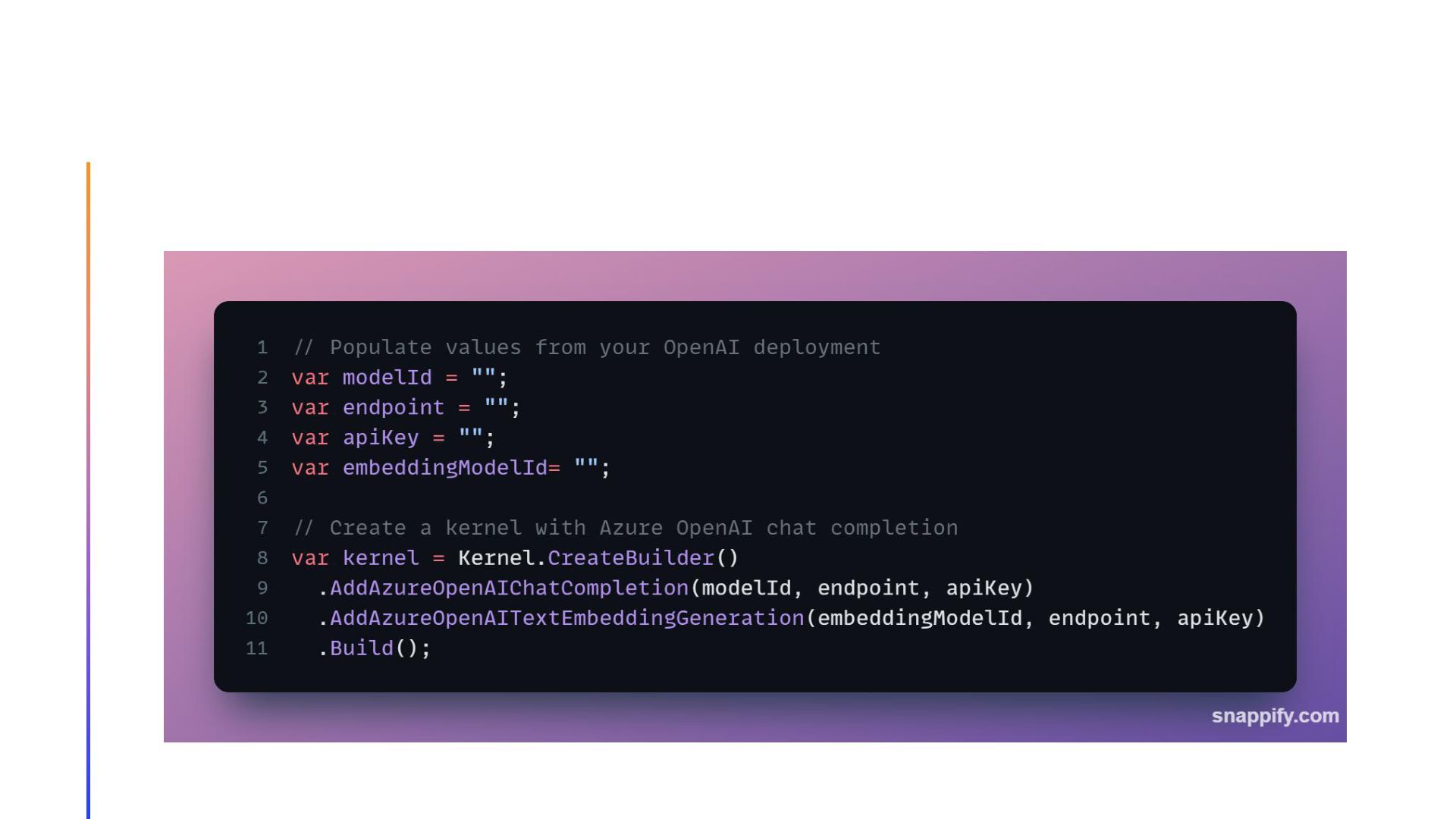{kind=link}
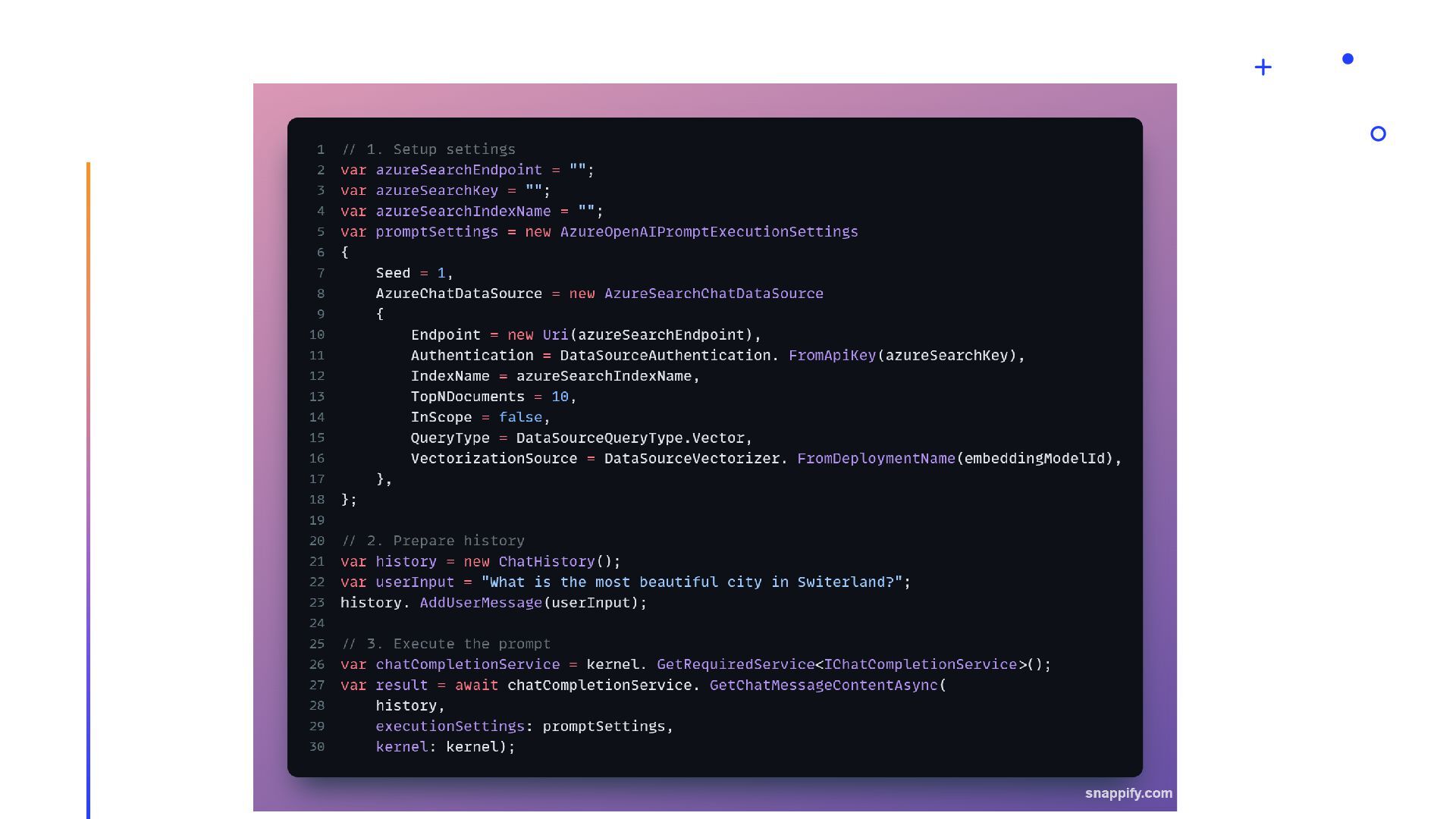{kind=link}
{kind=link}
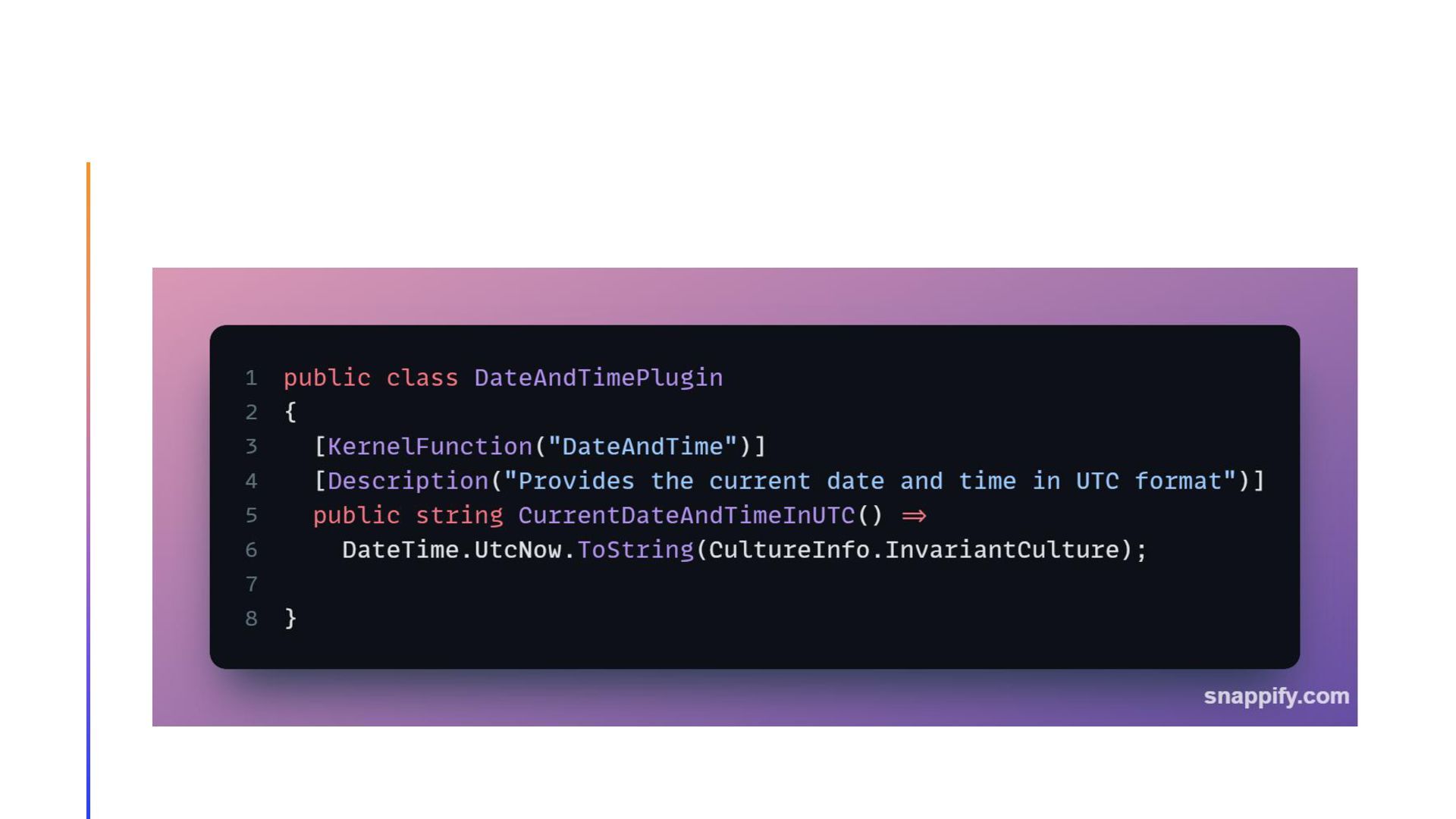{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
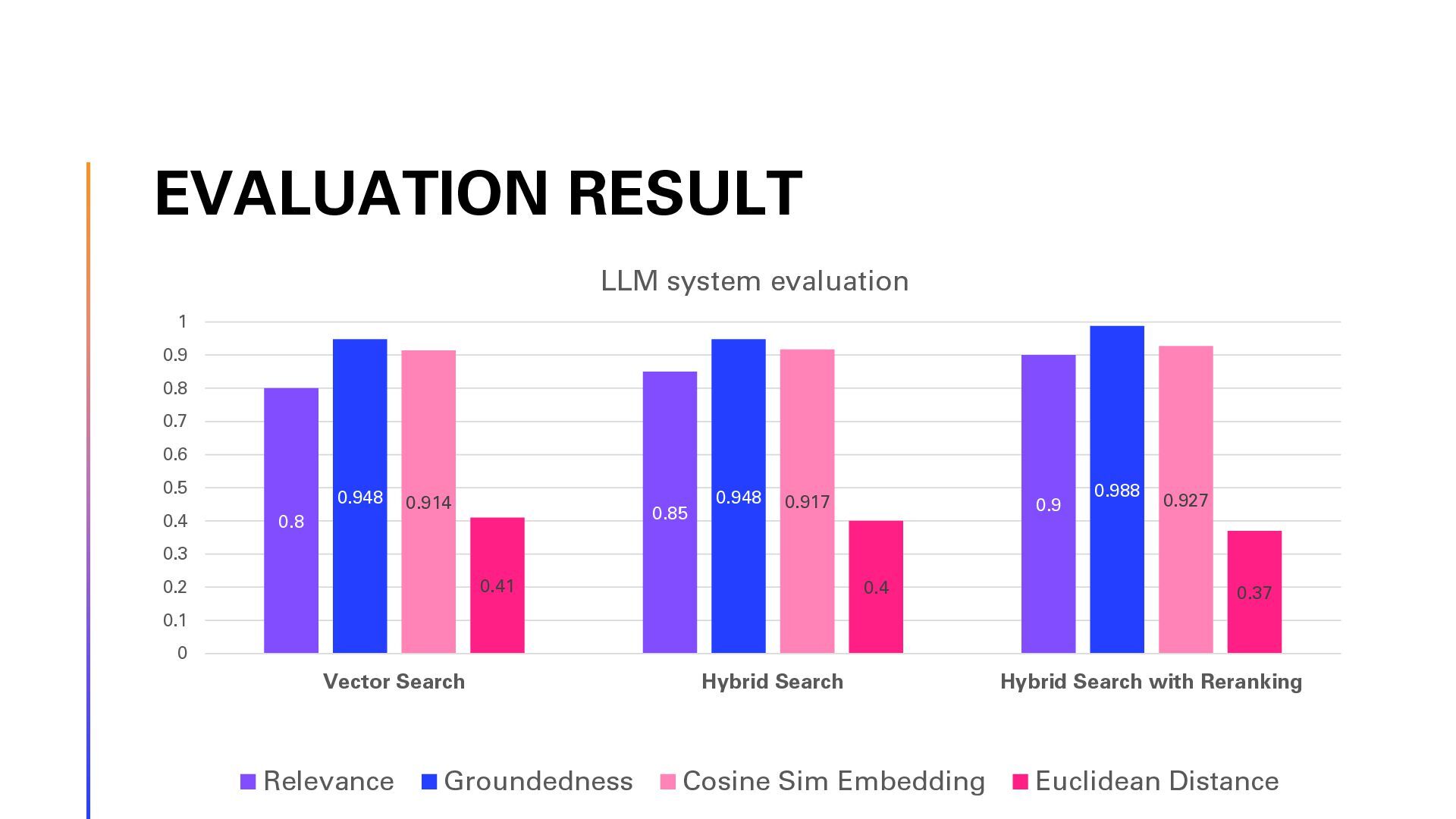{kind=link}
{kind=link}
{kind=link}
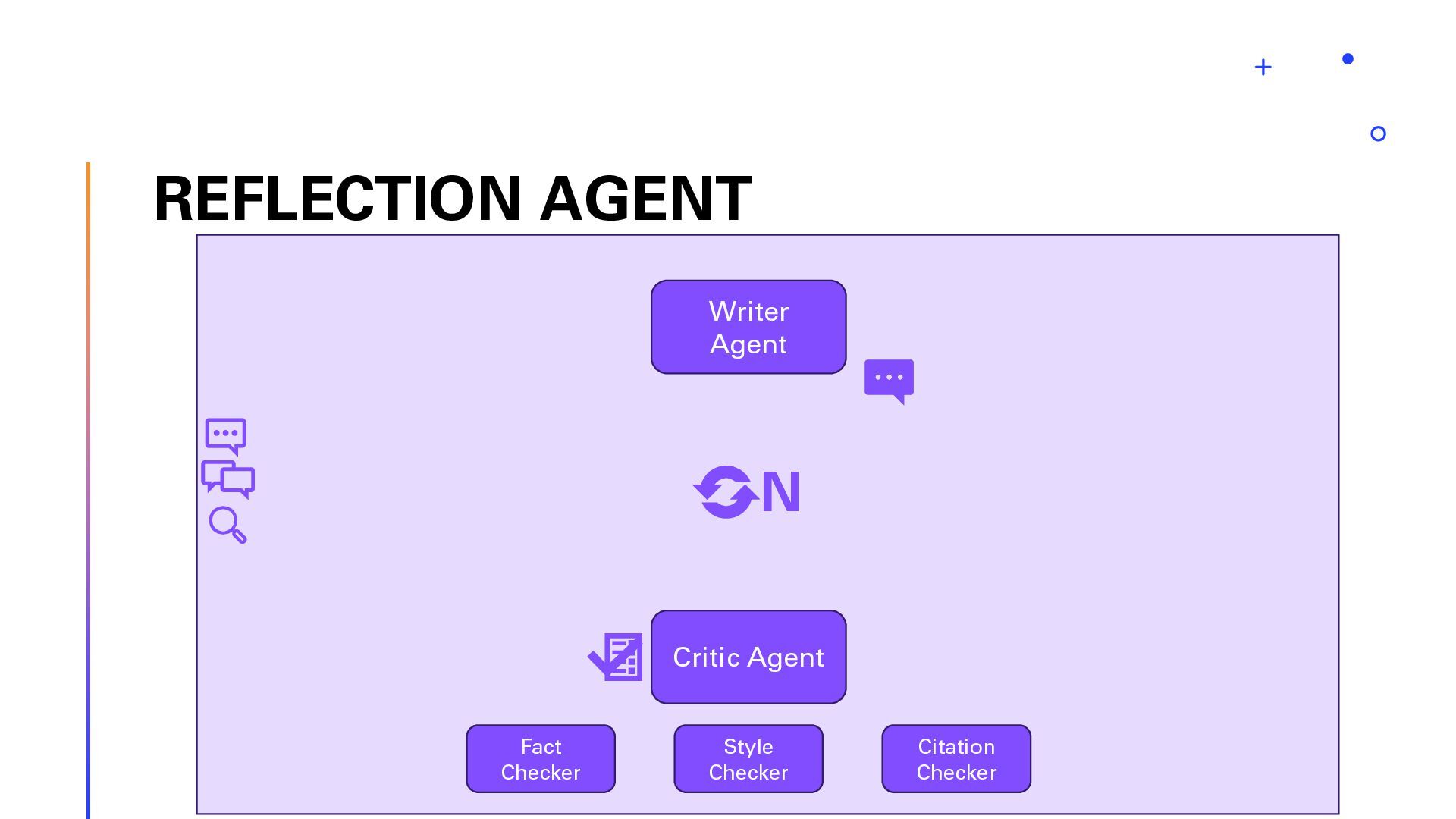{kind=link}
{kind=link}
{kind=link}
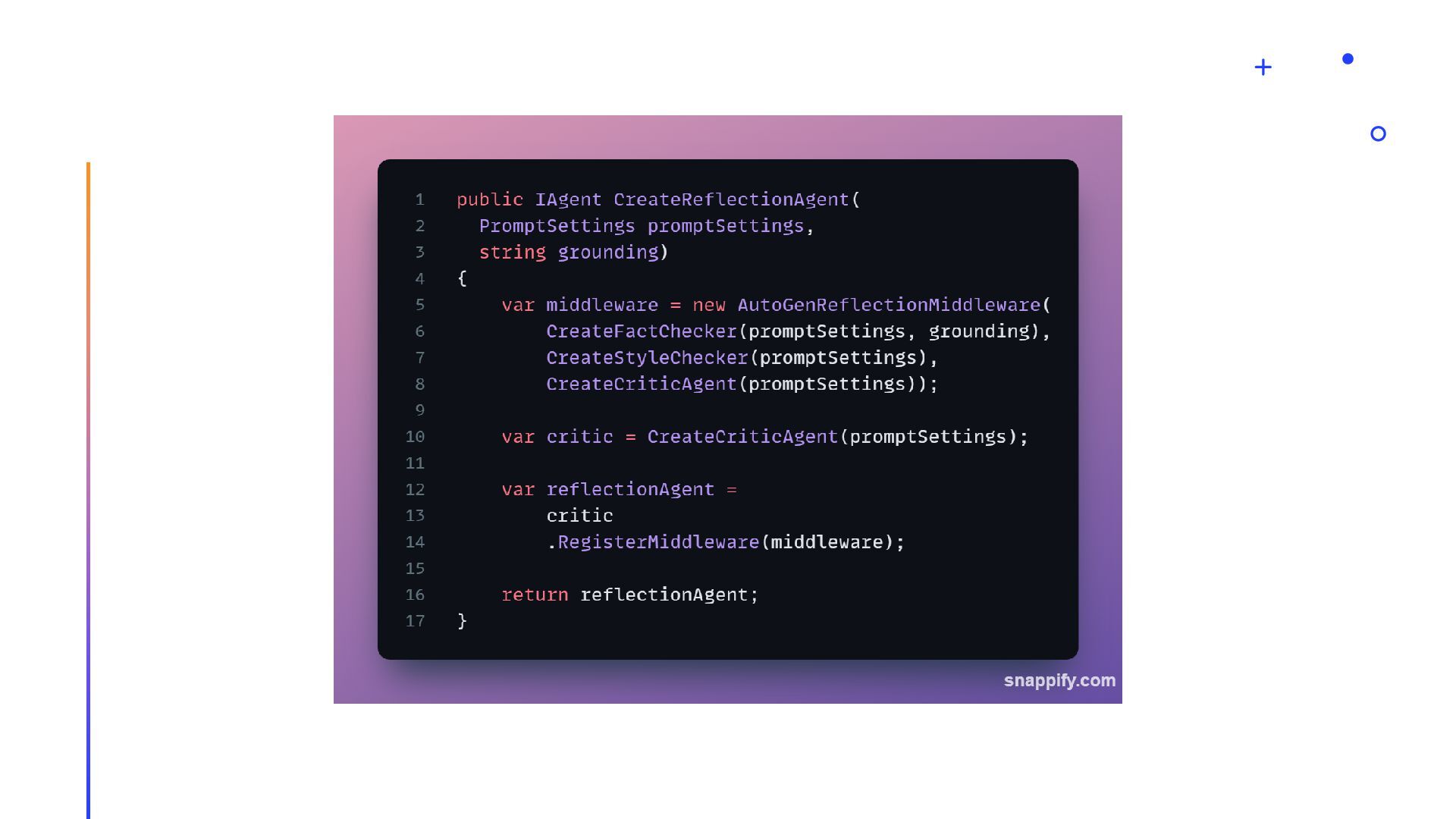{kind=link}
{kind=link}
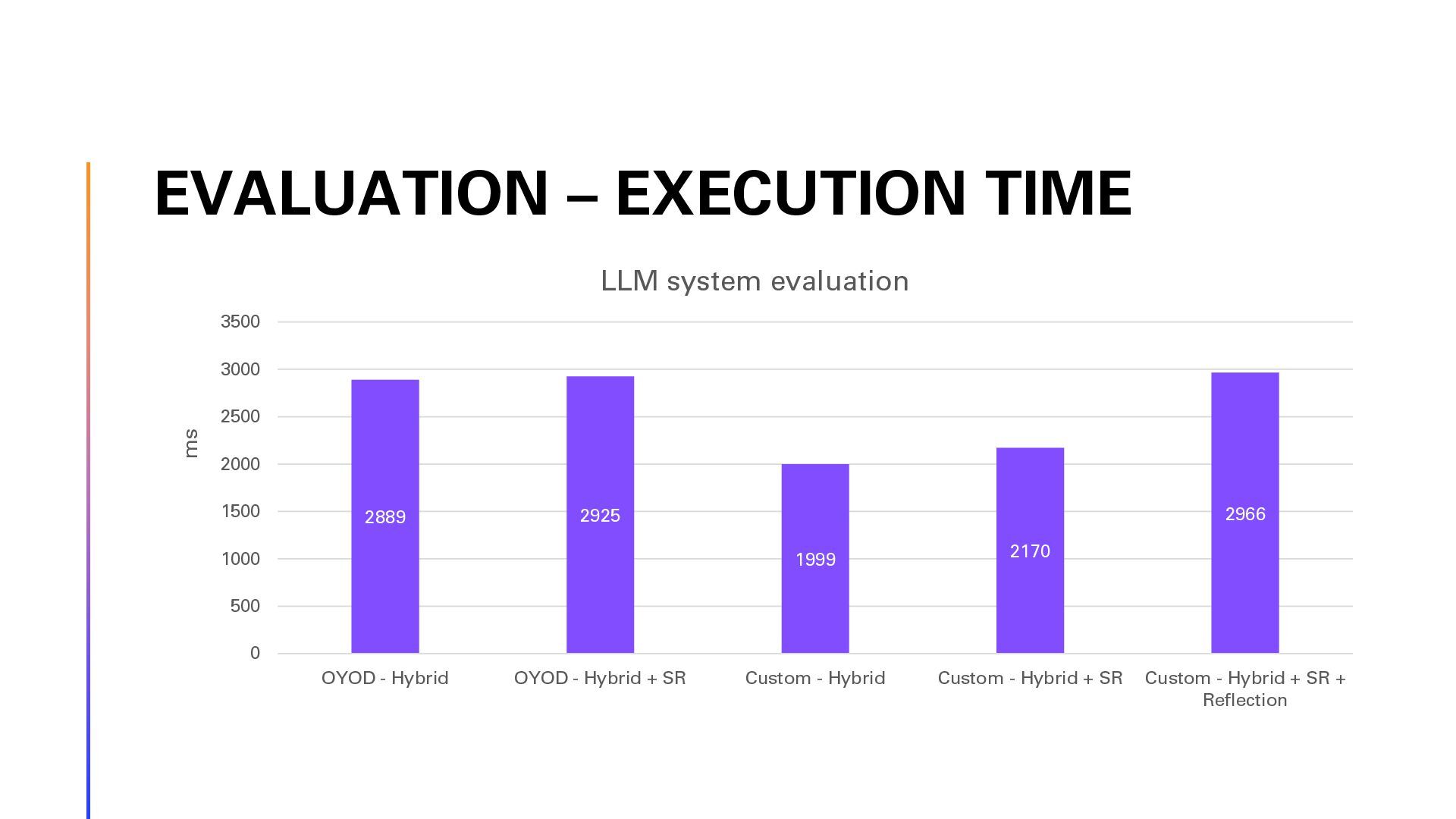{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}