Big Data. Data Science. AI. It's all big business.
Once upon a time we succeeded in these fields by selectively storing, processing and learning from just the right data. This, of course, requires you to know what "the right data" is. We know there are valuable insights in data, so why not store the lot? It's the 21st century equivalent of "there's gold in them thar hills!"
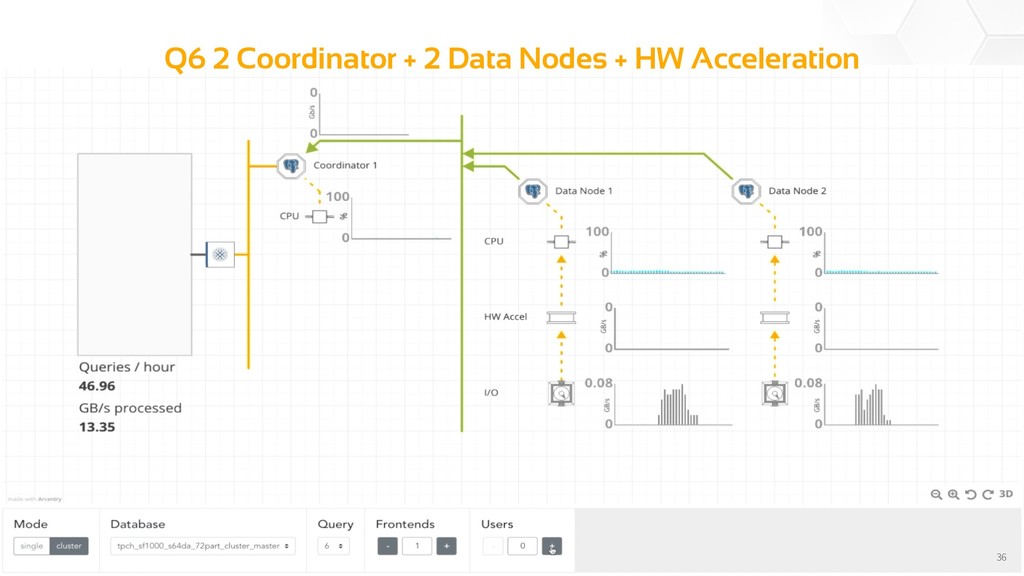
So having spent years stashing away terabytes of your data in PostgreSQL, you want to start learning from that data. Queries. More queries. More complex queries. Lots of real-time queries. Lots of concurrent users. It might be tempting at this point to give up on PostgreSQL and stash your data into a different solution, more suited to purpose. Don't. PostgreSQL can perform very well in HTAP environments and performs even better with a little help.
In this presentation we dive into the current state of the art with regards to PostgreSQL in HTAP environments and expose how hardware acceleration can help squeeze as much knowledge as possible out of your data.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] Follow us: ©Swarm64 AS, 2019](https://files.speakerdeck.com/presentations/1e77ff407bb3485eb15d9db316fd394d/slide_39.jpg){kind=link}