A comprehensive guide from fine-tuning Large Language Models (LLMs) to on-device applications, presented by Lee Junbum.
This presentation covers:
- Overview of LLMs: Capabilities, recent advancements, and the importance of fine-tuning for customization, efficiency, and performance.
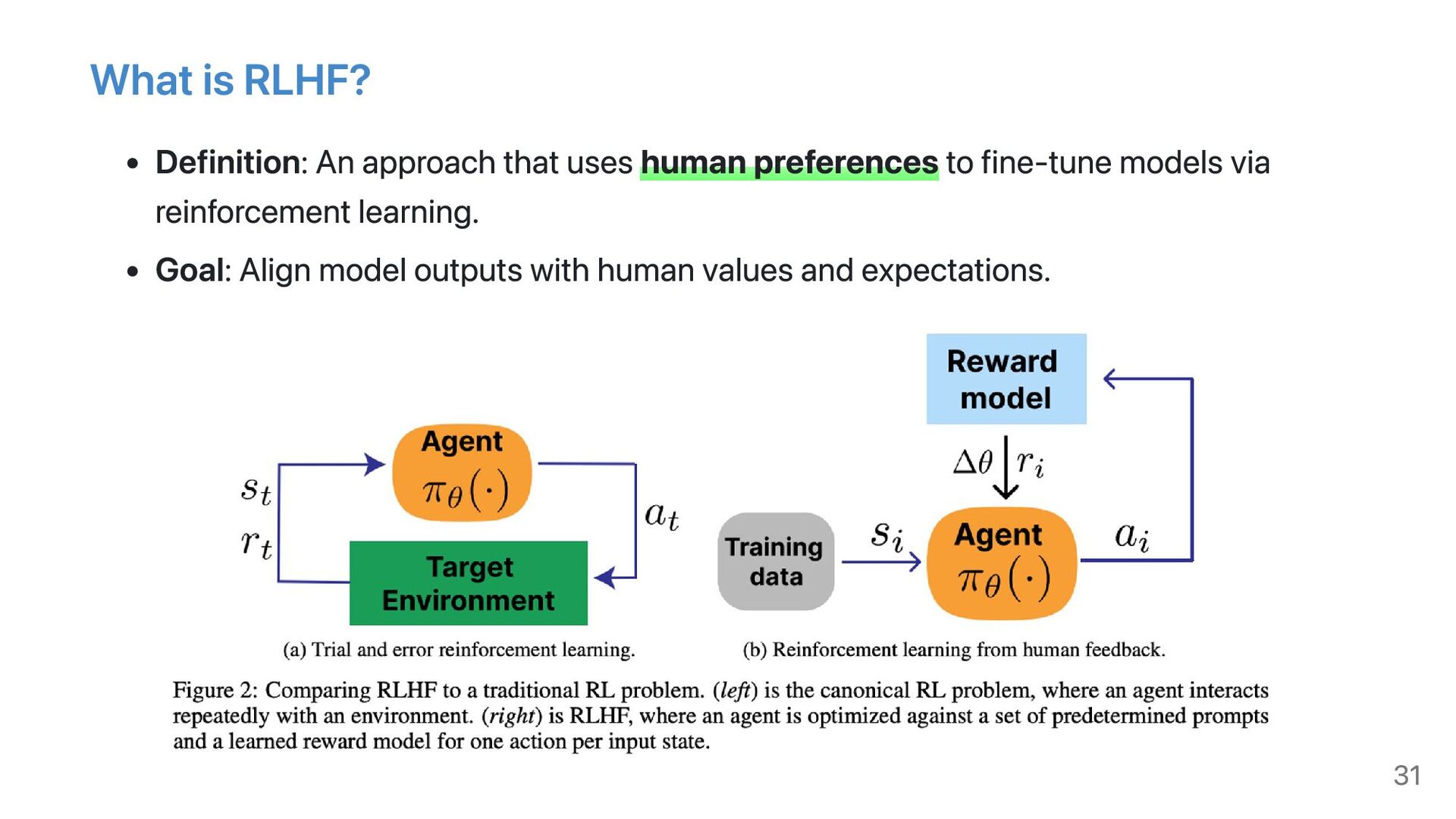
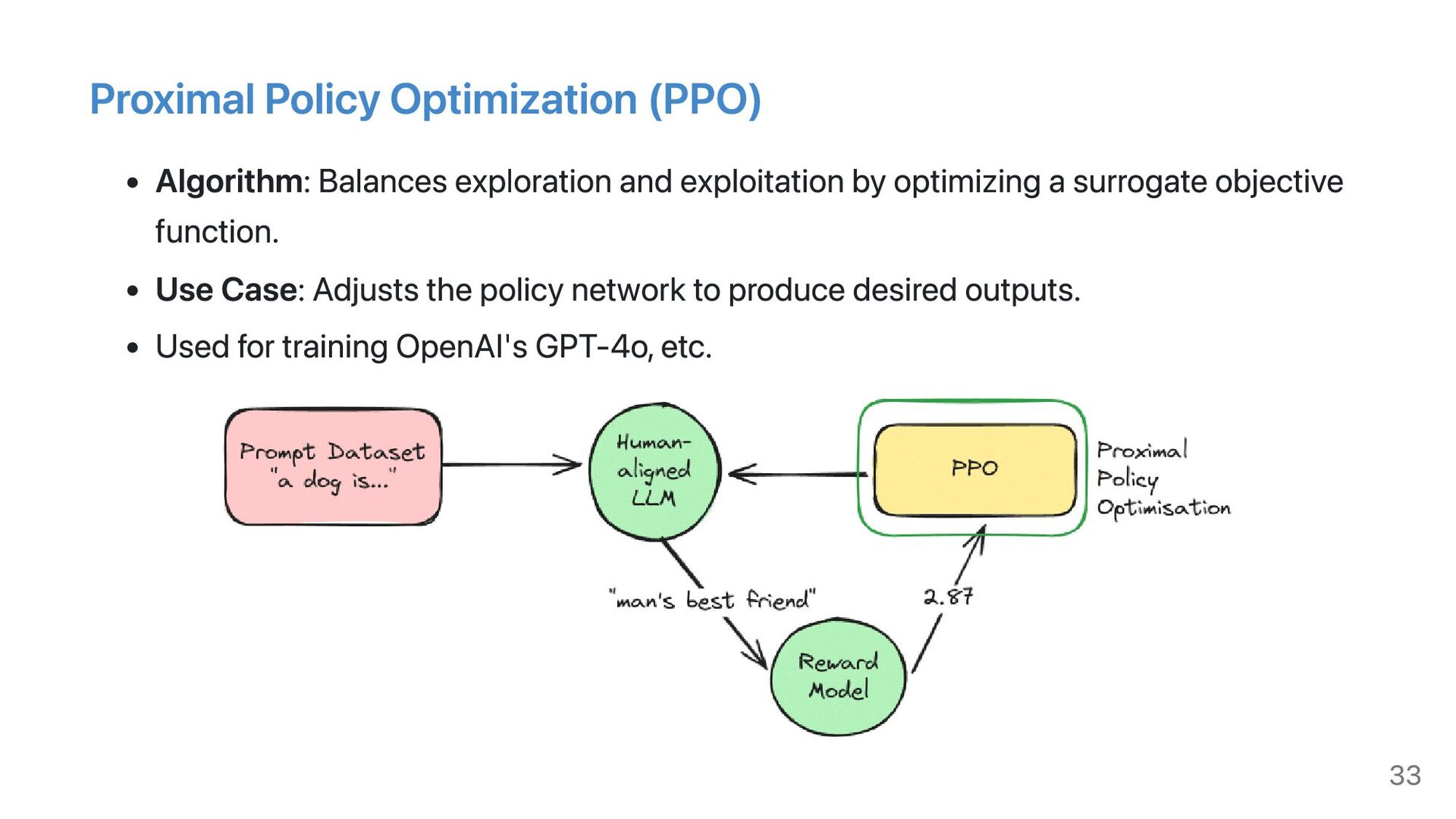
- Key fine-tuning techniques: Includes Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), Parameter-Efficient Fine-Tuning (PEFT), and Retrieval-Augmented Fine-Tuning (RAFT).
- Hands-on tutorials: Practical steps using tools like Hugging Face, Google Colab, and Llama.cpp to fine-tune, deploy, and optimize models.
- Model deployment: Strategies for efficient deployment with quantization techniques like QLoRA for resource-constrained environments like Macbook.
for AI practitioners and researchers, this deck provides actionable insights into transitioning LLMs from pre-training to impactful real-world applications.
![LLM Fine-Tuning: From Pretrained to On-device Lee Junbum (Beomi) [email protected]](https://files.speakerdeck.com/presentations/753c3386a05b4ef6bdc94670da854b4f/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
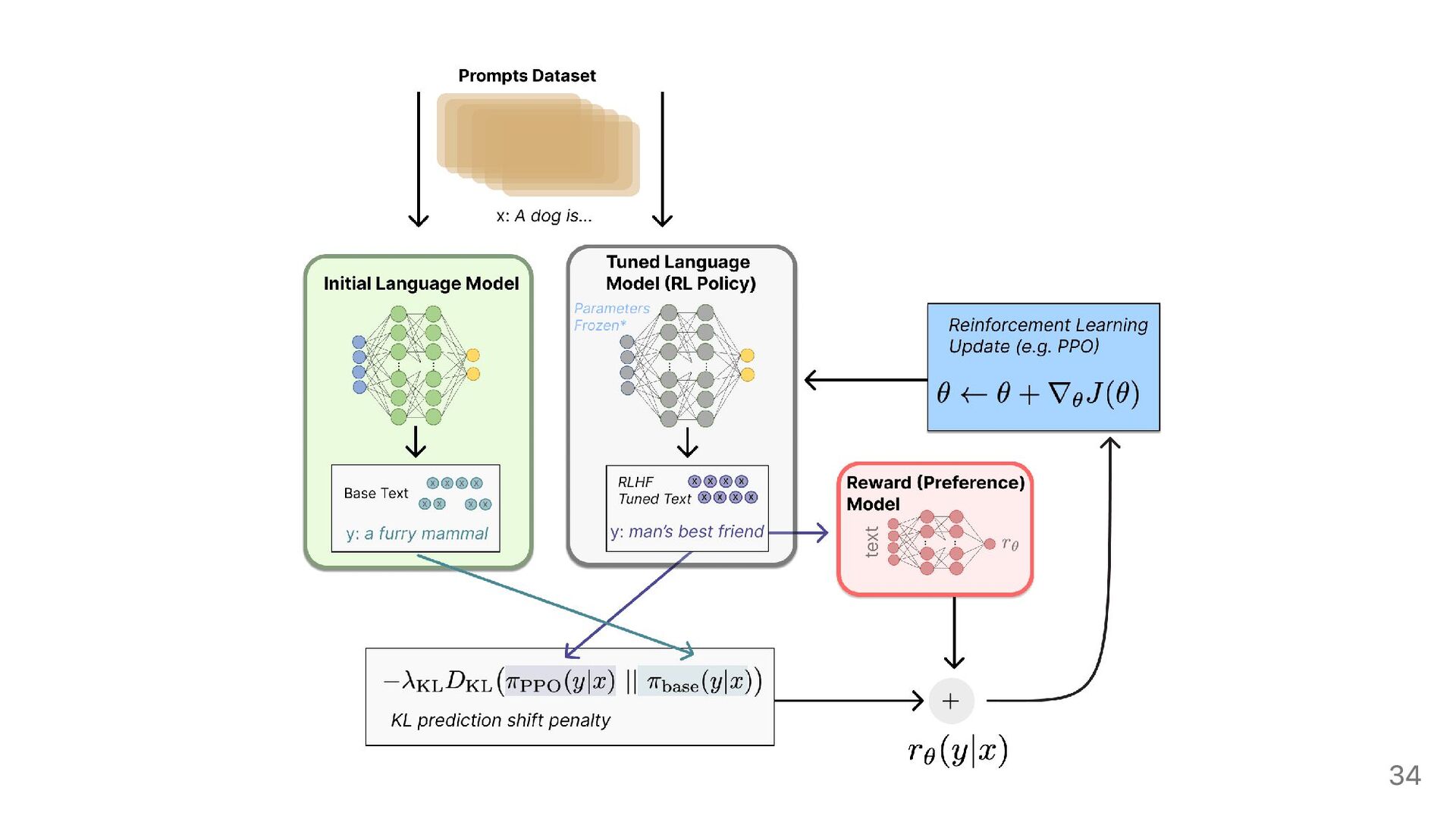{kind=link}
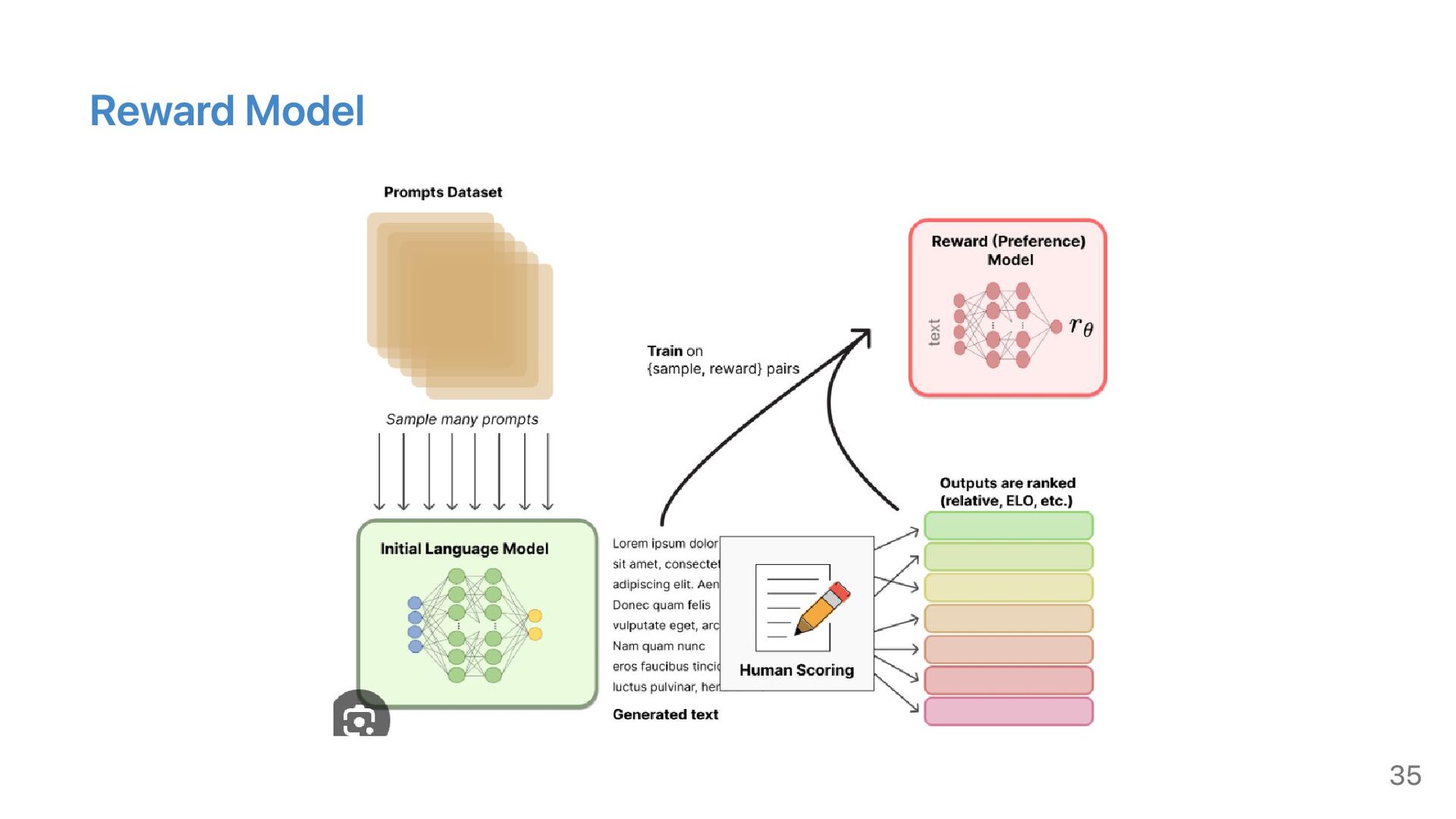{kind=link}
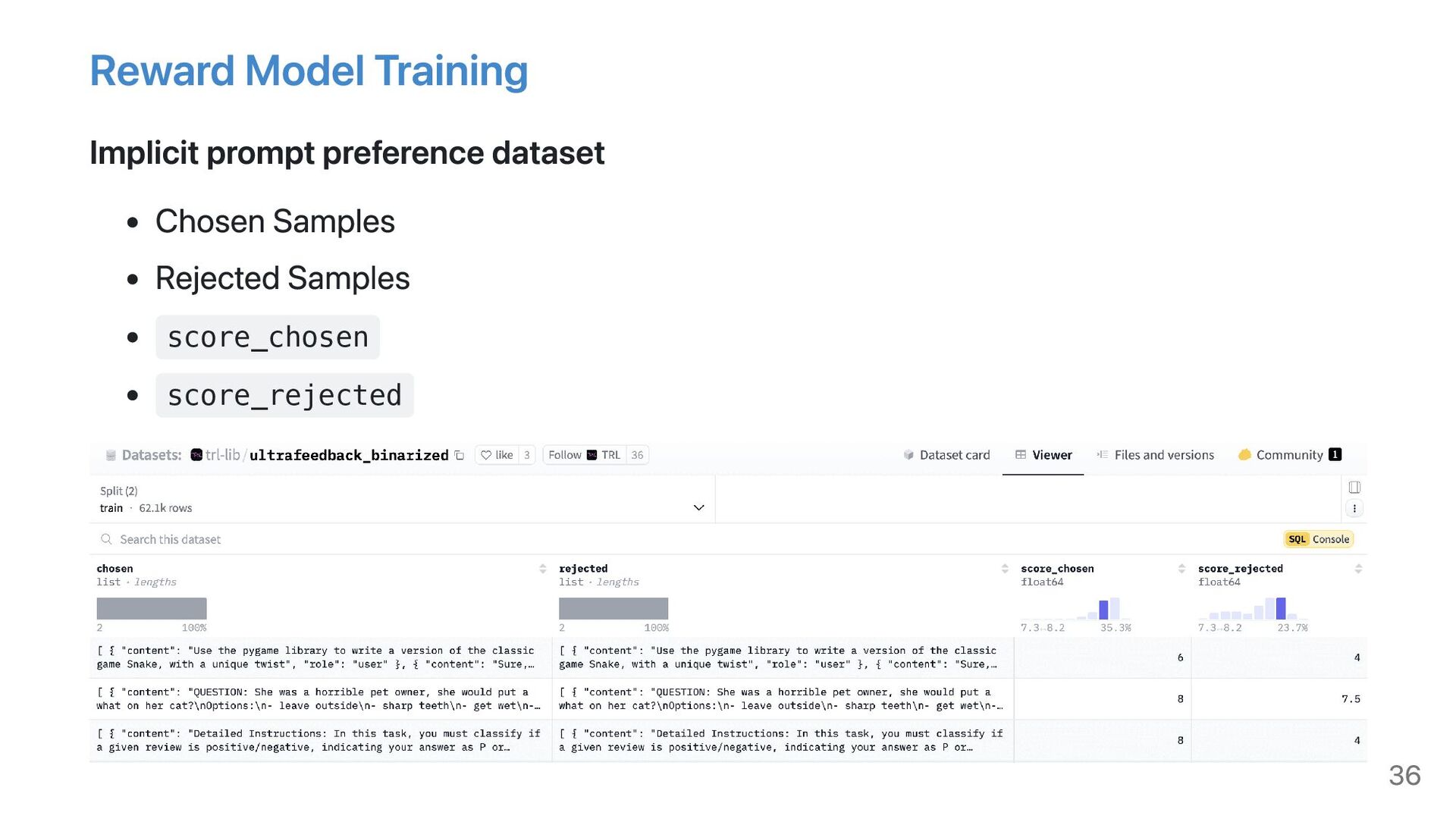{kind=link}
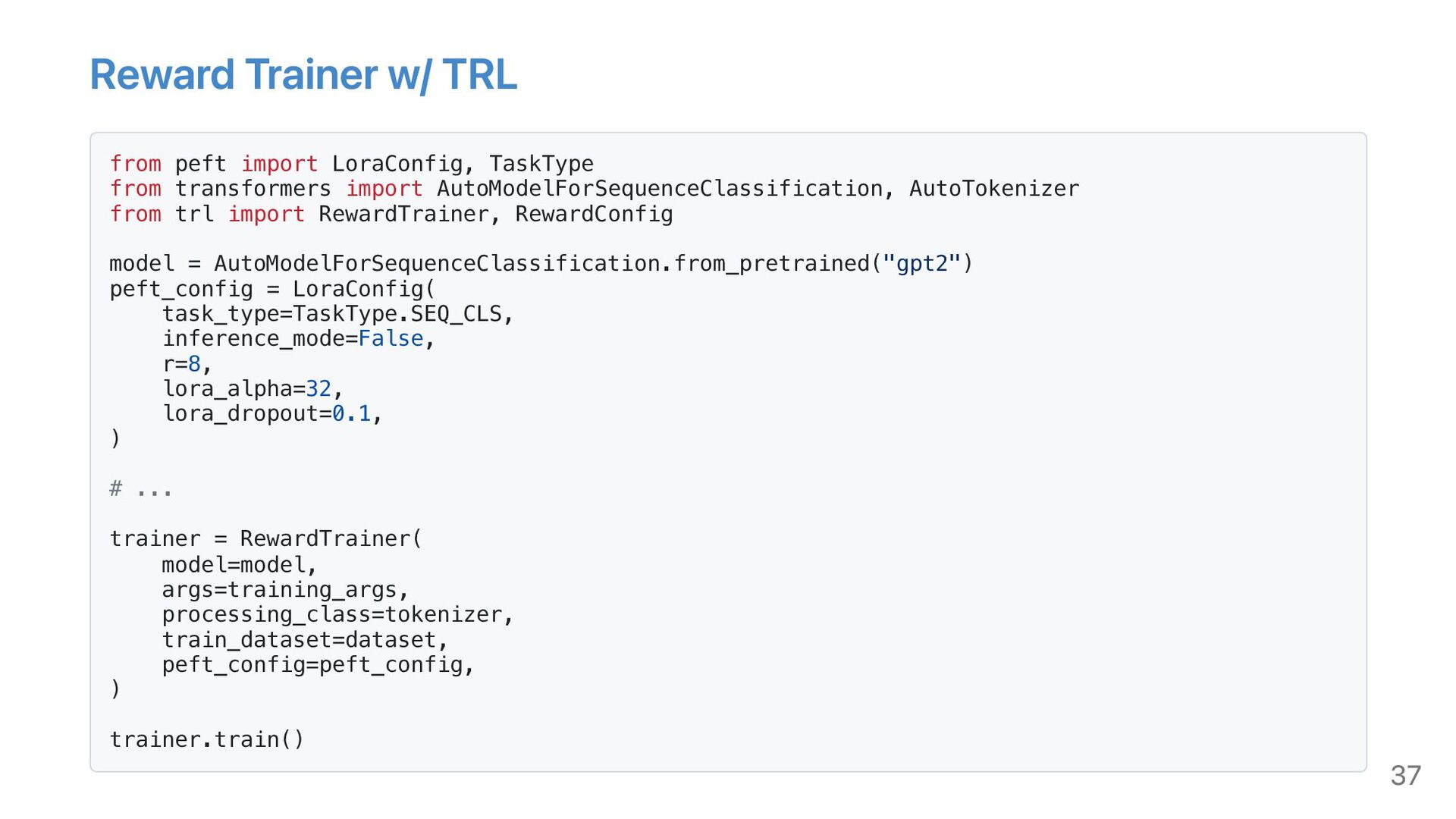{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank You! Contact Information Email: [email protected] GitHub: github.com/beomi Hugging Face](https://files.speakerdeck.com/presentations/753c3386a05b4ef6bdc94670da854b4f/slide_95.jpg){kind=link}
{kind=link}
{kind=link}