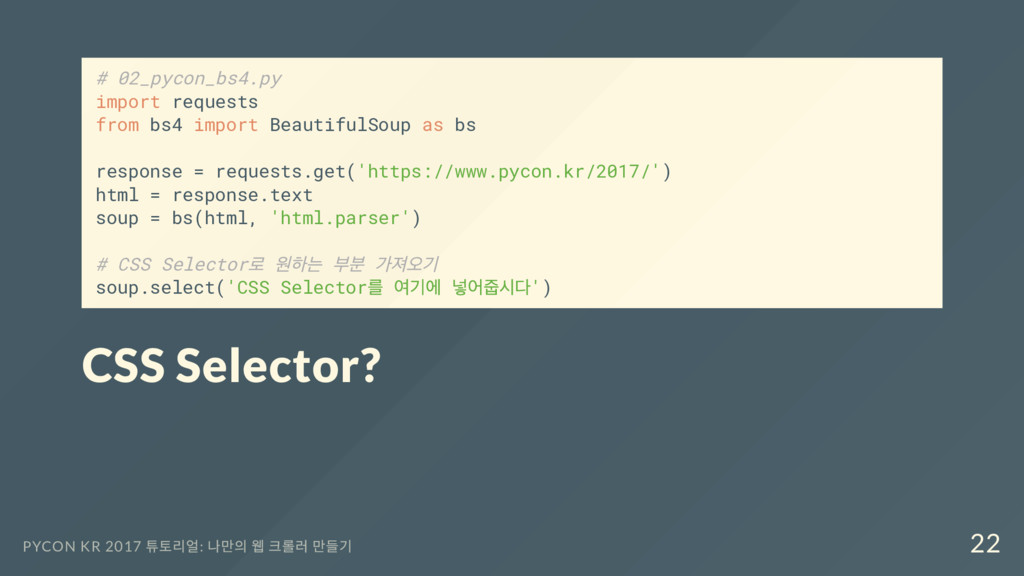
response = requests.get('https://www.pycon.kr/2017/') html = response.text soup = bs(html, 'html.parser') # CSS Selector 로 원하는 부분 가져오기 soup.select('CSS Selector 를 여기에 넣어줍시다') CSS Selector? PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 22
[<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] # a 태그 중 링크가 http://example.com/ 으로 시작하는(^) Elements soup.select('a[href^="http://example.com/"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>, # <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, # <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] # a 태그 중 링크가 tillie 로 끝나는($) Elements soup.select('a[href$="tillie"]') # [<a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>] # a 태그 중 링크가 .com/el 이 들어가있는 Elements soup.select('a[href*=".com/el"]') # [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>] PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 25
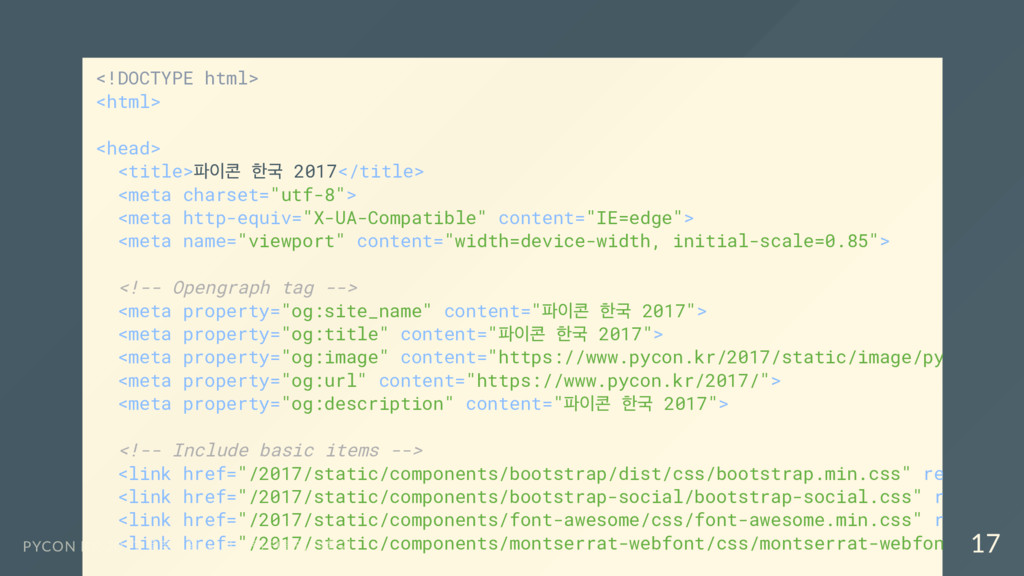
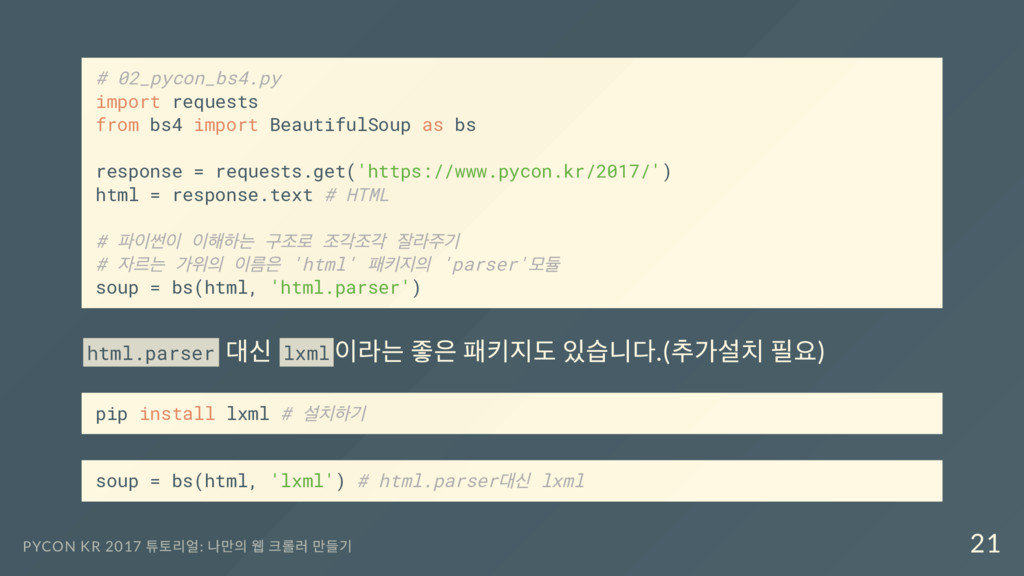
BeautifulSoup as bs response = requests.get('https://www.pycon.kr/2017/') html = response.text soup = bs(html, 'html.parser') # CSS Selector 로 원하는 부분 가져오기( 리스트) title = soup.select('body > div.frontpage > div.onsky > div > div > h1') # 리스트에서 첫번째 Element 에서 html 태그 뺀 텍스트 가져오기 print(title[0].text) PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 27
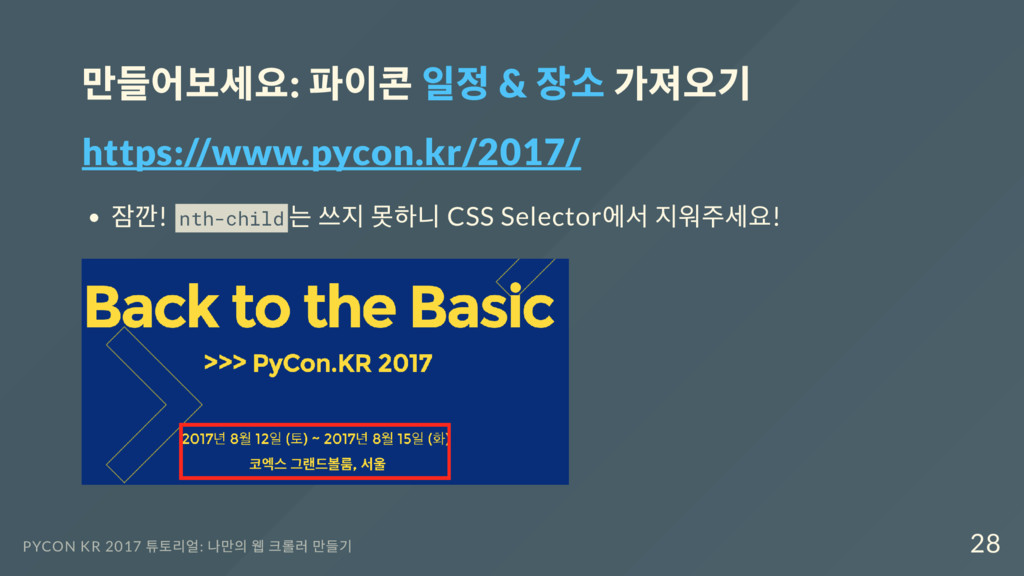
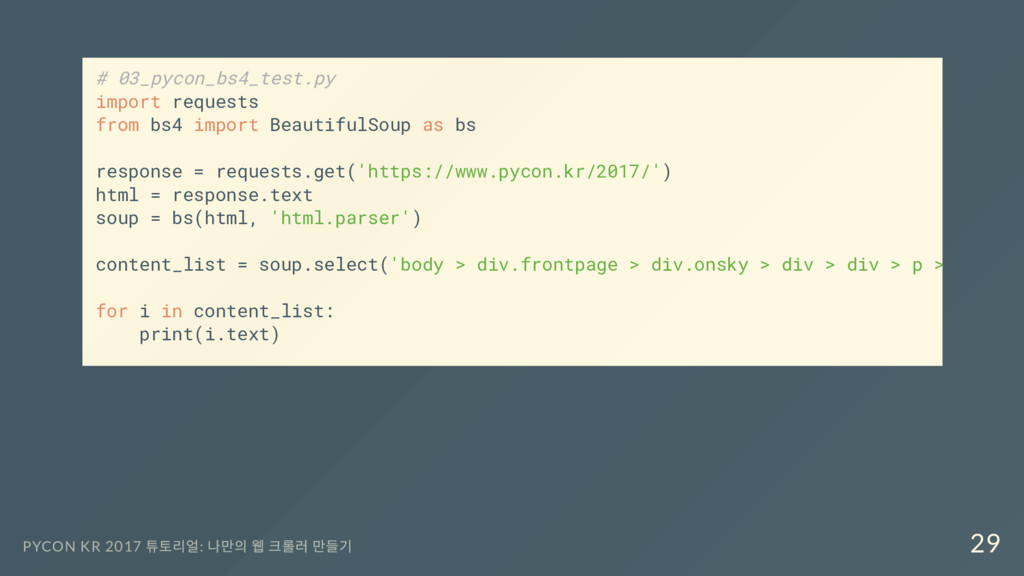
response = requests.get('https://www.pycon.kr/2017/') html = response.text soup = bs(html, 'html.parser') content_list = soup.select('body > div.frontpage > div.onsky > div > div > p > span' for i in content_list: print(i.text) PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 29
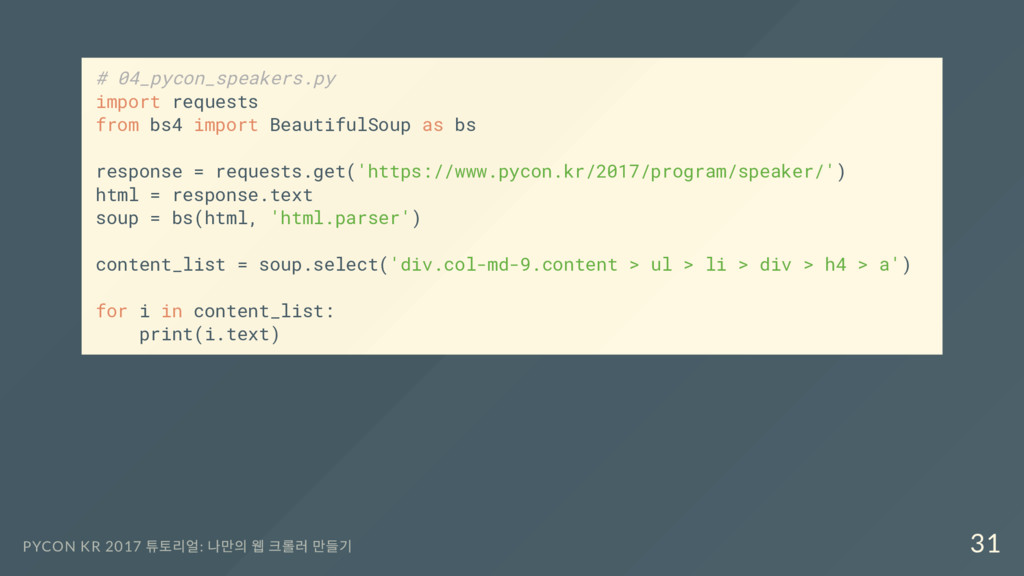
response = requests.get('https://www.pycon.kr/2017/program/speaker/') html = response.text soup = bs(html, 'html.parser') content_list = soup.select('div.col-md-9.content > ul > li > div > h4 > a') for i in content_list: print(i.text) PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 31
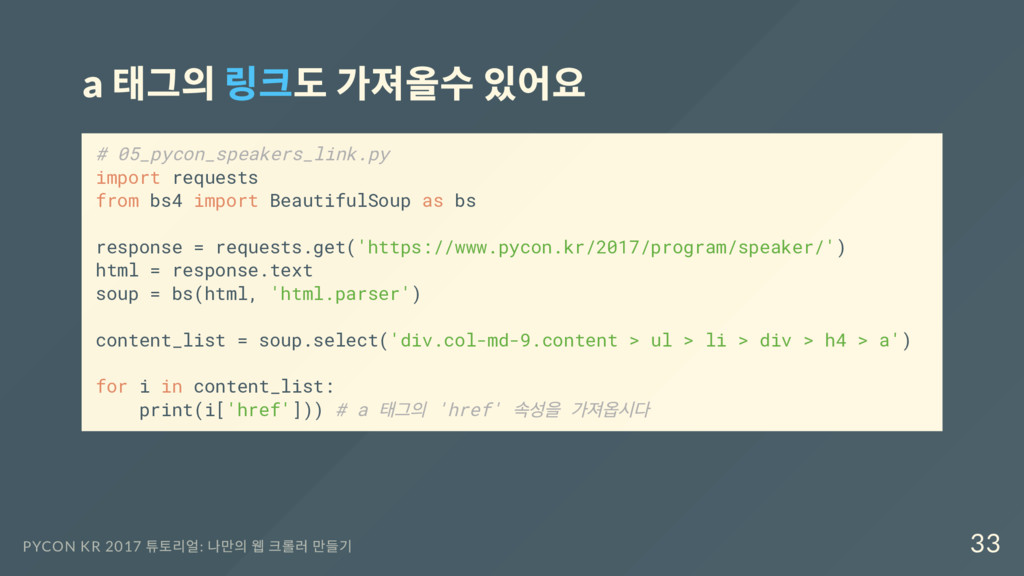
bs4 import BeautifulSoup as bs response = requests.get('https://www.pycon.kr/2017/program/speaker/') html = response.text soup = bs(html, 'html.parser') content_list = soup.select('div.col-md-9.content > ul > li > div > h4 > a') for i in content_list: print(i['href'])) # a 태그의 'href' 속성을 가져옵시다 PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 33
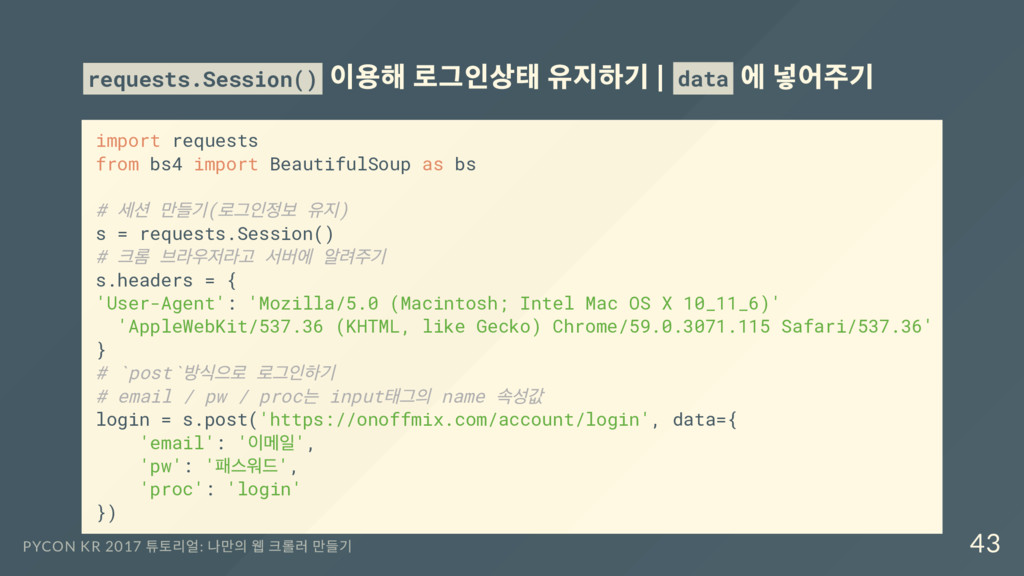
같은 형태 requets 에서는 params 로 넘겨줄 수 있다 requests.get('http://onoffmix.com/event') # != requests.get('http://onoffmix.com/event?s= 파이썬') # == requerts.get('http://onoffmix.com/event', params={'s':' 파이썬'}) ? 뒤에 바로 값을 전달해도 되고 params 로 값을 전달해도 됩니다 PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 35
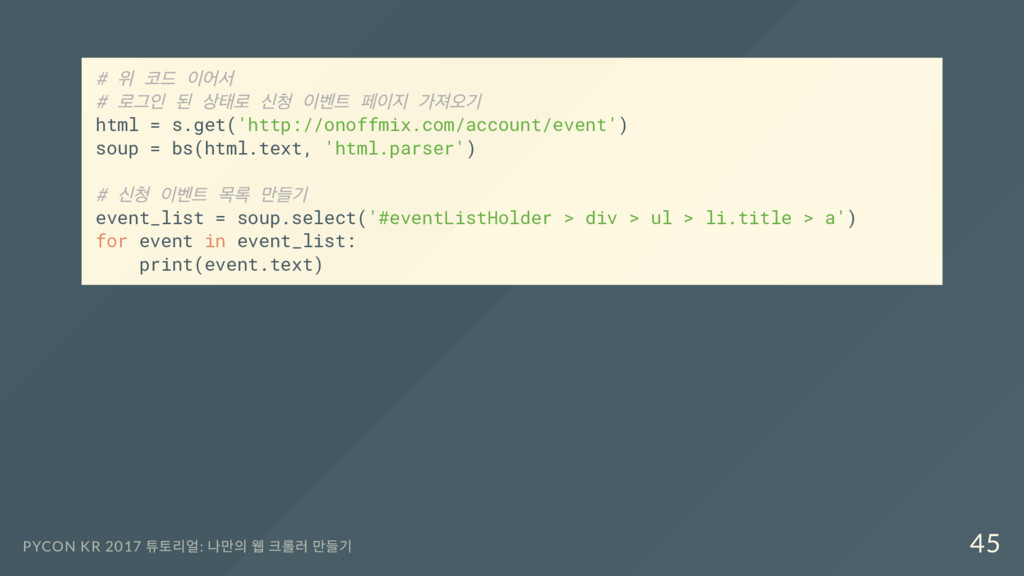
페이지 가져오기 html = s.get('http://onoffmix.com/account/event') soup = bs(html.text, 'html.parser') # 신청 이벤트 목록 만들기 event_list = soup.select('#eventListHolder > div > ul > li.title > a') for event in event_list: print(event.text) PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 45
이 모든 자원을 가져오기까지 3 초를 기다려줍니다 driver.implicitly_wait(3) # 네이버 첫 화면을 가져와봅시다 driver.get('https://naver.com') webdriver 를 통해 실 브라우저를 띄우고 조작할 수 있습니다 webdriver.Chrome 안의 첫번째 인자는 앞서 받은 chromedriver 의 정확한위치를 넣어줘야 합니다. implicit_wait 을 통해 웹 페이지가 로드될때까지 암묵적으로 기다려줍니다. 이렇게 기다려주는 것은 웹 페이지 자체를 기다리거나 혹은 특정 요소(element) 를 기다려 줄수도 있습니다. PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 49
여전히 CSS Selector 는 편리 input_id = driver.find_element_by_css_selector('#id') input_pw = driver.find_element_by_css_selector('#pw') login_button = driver.find_element_by_css_selector( '#frmNIDLogin > fieldset > span > input[type="submit"]' ) 새로운 Selector : input[type="submit"] input 태그 중 type Attribute 의 값이 "submit" 인 Element 여러개 요소는 find_elements_by_css_selector ( element -> elements ) PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 50
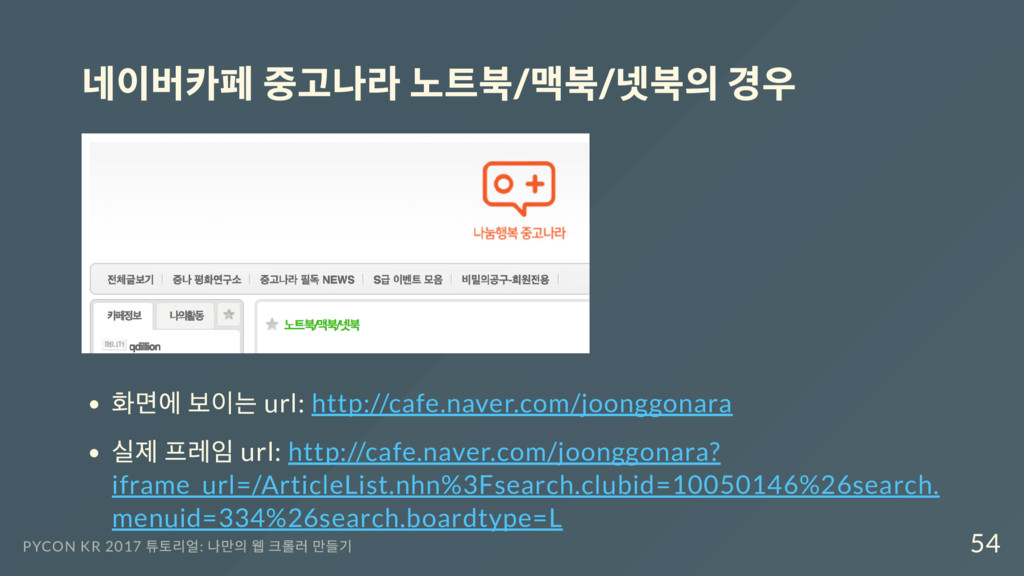
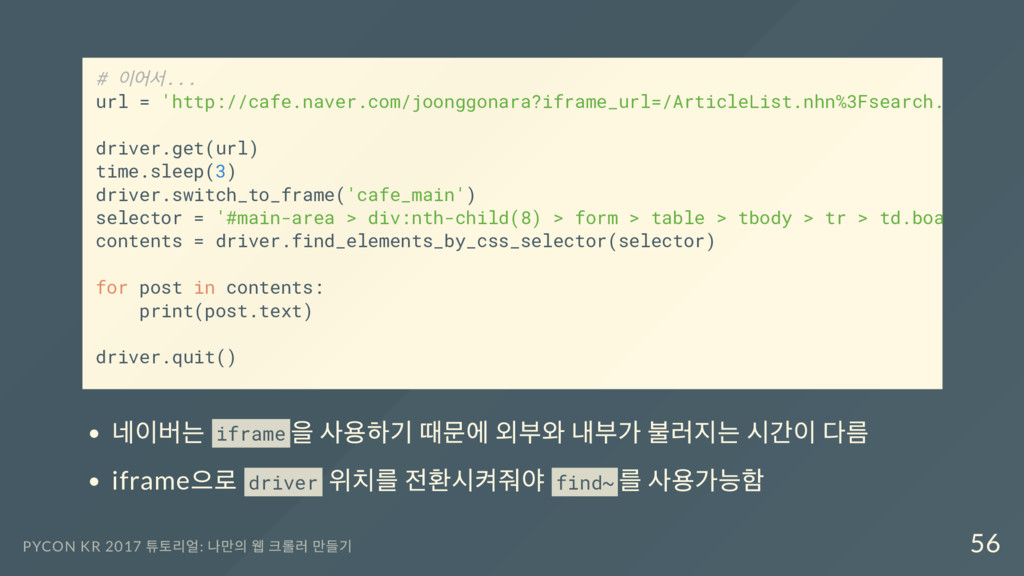
실제 프레임 url: http://cafe.naver.com/joonggonara? iframe_url=/ArticleList.nhn%3Fsearch.clubid=10050146%26search. menuid=334%26search.boardtype=L PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 54
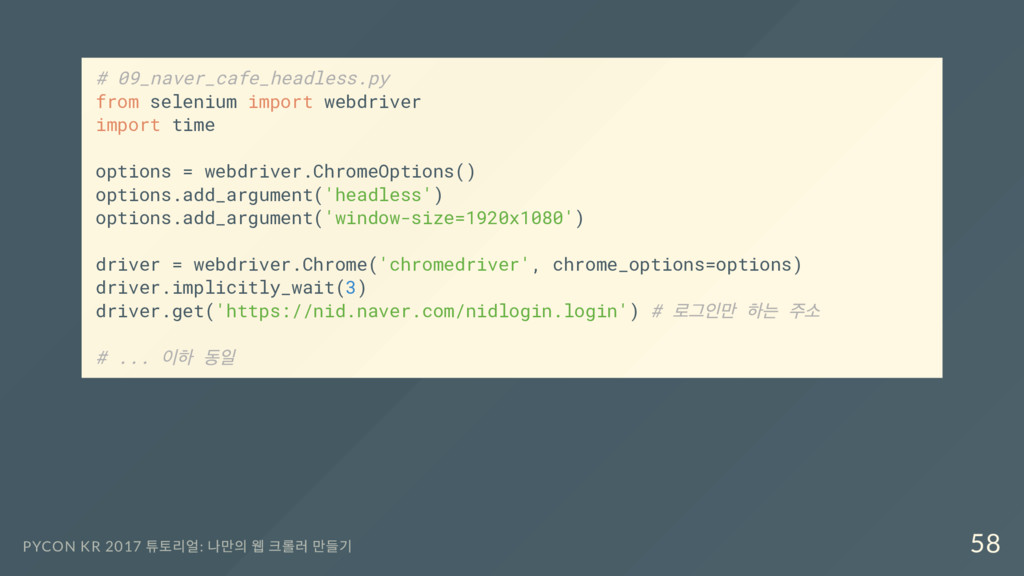
webdriver.ChromeOptions() options.add_argument('headless') options.add_argument('window-size=1920x1080') driver = webdriver.Chrome('chromedriver', chrome_options=options) driver.implicitly_wait(3) driver.get('https://nid.naver.com/nidlogin.login') # 로그인만 하는 주소 # ... 이하 동일 PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 58
수정이 됩니다. 파일 끝으로 내려가서 deb [arch=amd64] http://dl.google.com/linux/chrome/deb/ stable main 를 추가해 주세요.( 한줄 추가) esc 를 누르고 ZZ 엔터로 나올 수 있습니다. wget https://dl.google.com/linux/linux_signing_key.pub sudo apt-key add linux_signing_key.pub apt-get update apt-get install google-chrome-stable PYCON KR 2017 튜토리얼: 나만의 웹 크롤러 만들기 63
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![조금더, CSS Selector soup.select('a[href]') # a 태그 중 href 속성을](https://files.speakerdeck.com/presentations/6c7ab4d27ca541aa827d2447f591535a/slide_23.jpg){kind=link}
![# a 태그 중 링크가 http://example.com/elsie 인 Elements soup.select('a[href="http://example.com/elsie"]') #](https://files.speakerdeck.com/presentations/6c7ab4d27ca541aa827d2447f591535a/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}