Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
バンディットアルゴリズムと因果推論 / Bandit Algorithm And Casual...
Search
CyberAgent
PRO
February 22, 2019
Technology
2.7k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
バンディットアルゴリズムと因果推論 / Bandit Algorithm And Casual Inference
サイバーエージェントの技術者(エンジニア・クリエイター)向けカンファレンス『CA BASE CAMP 2019』
バンディットアルゴリズムと因果推論
安井 翔太
CyberAgent
PRO
February 22, 2019
More Decks by CyberAgent
See All by CyberAgent
”AIを使う” から ”AIに任せる” へ ─ 開発プロセスを再設計してAIを組織標準にするまで
cyberagentdevelopers
PRO
1
130
Databricks 導入から Genie 活用まで、全部やった話
cyberagentdevelopers
PRO
0
830
専任DEゼロからの データ基盤構築 - Databricks x IaC x AIで 進める「データの民主化」-
cyberagentdevelopers
PRO
0
500
「エンジニア進化論」2028年の開発完全自動化、エンジニアはどう進化するか
cyberagentdevelopers
PRO
9
8.9k
NAB Show 2026 動画技術関連レポート / NAB Show 2026 Report
cyberagentdevelopers
PRO
0
310
Local LLM Meetup #1 Opening
cyberagentdevelopers
PRO
0
430
LocalLLMで機密データを匿名化したい
cyberagentdevelopers
PRO
1
460
Vibe Fine-Tuning Version 2 — RunPod SSH で安く学習してみた
cyberagentdevelopers
PRO
0
430
2026年度新卒技術研修 サイバーエージェントのデータベース 活用事例とパフォーマンス調査入門
cyberagentdevelopers
PRO
10
12k
Other Decks in Technology
See All in Technology
Type-safe IaC for Dart
coborinai
0
180
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
310
生成 AI 時代にいま一度「問い合わせ」について考えてみる
kazzpapa3
1
120
文字起こし基盤の信頼性
abnoumaru
0
110
ゴールデンパスは敷いただけでは道にならない ─ 企画部門のエンジニアが技術標準を事業価値に変えるまで
mhrtech
1
260
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
380
データエンジニアリングとドメイン駆動設計
masuda220
PRO
14
2.4k
第67回コンピュータビジョン勉強会CVPR2026読会前編
tsukamotokenji
0
160
Amplify Gen2でbackend.tsにCDKを定義する/しない事によるCDKの挙動の違いとユースケース
smt7174
1
480
VPCセキュリティ対応の最新事情
nagisa53
1
110
発表と総括 / Presentations and Summary
ks91
PRO
0
180
人とエージェントが高め合う協業設計
kintotechdev
0
730
Featured
See All Featured
sira's awesome portfolio website redesign presentation
elsirapls
0
300
Navigating Team Friction
lara
192
16k
Faster Mobile Websites
deanohume
310
32k
Side Projects
sachag
455
43k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
230
Building Adaptive Systems
keathley
44
3.1k
Agile that works and the tools we love
rasmusluckow
331
22k
How to build an LLM SEO readiness audit: a practical framework
nmsamuel
1
810
Are puppies a ranking factor?
jonoalderson
1
3.7k
New Earth Scene 8
popppiees
3
2.4k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
320
Primal Persuasion: How to Engage the Brain for Learning That Lasts
tmiket
0
390
Transcript
Bandit Algorithm And Causal Inference / / Shota Yasui
Who are you? Shota Yasui( ) @housecat 経歴 2013 新卒総合職⼊社(広告事業本部)
2015 アドテクスタジオへ異動 DMP/DSP/SSPで分析 AILabスタート ADEconチームスタート !2
.Bandit Algorithmとは? .Causal Inference + Bandit .Off-Policy Evaluation .Future Work
+ まとめ !3
Banditとは何か?
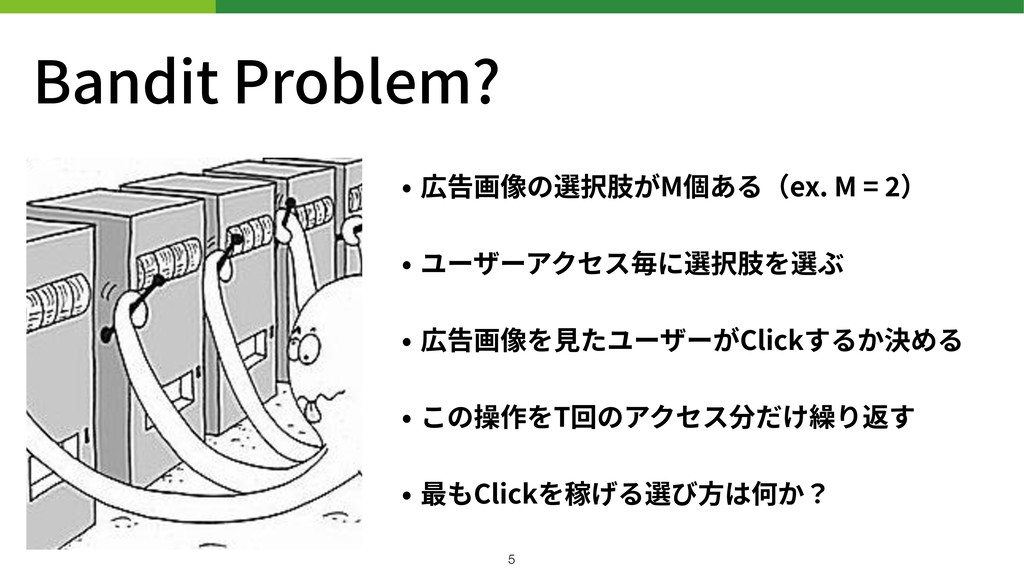
Bandit Problem? • 広告画像の選択肢がM個ある(ex. M = ) • ユーザーアクセス毎に選択肢を選ぶ •
広告画像を⾒たユーザーがClickするか決める • この操作をT回のアクセス分だけ繰り返す • 最もClickを稼げる選び⽅は何か? !5
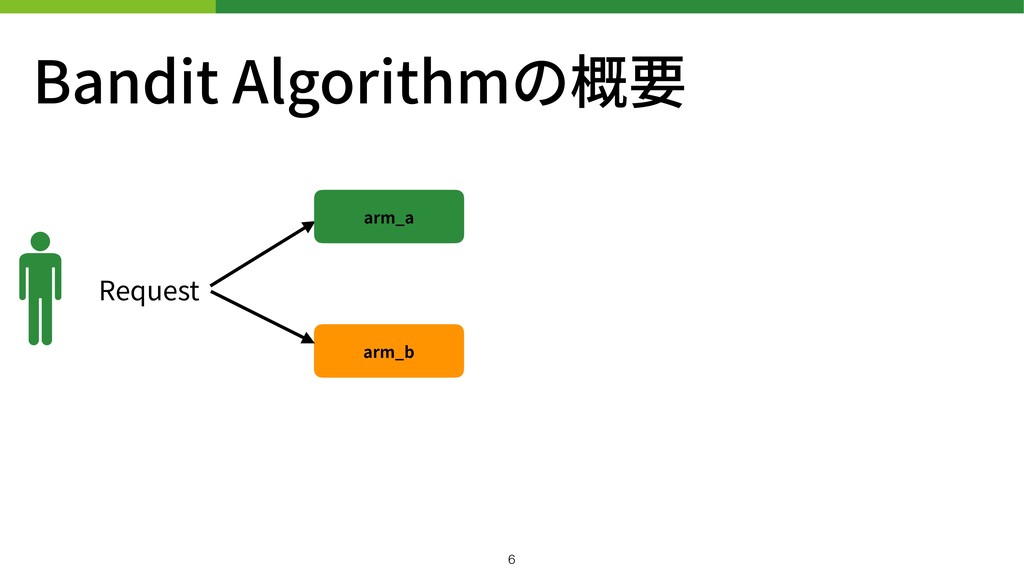
Bandit Algorithmの概要 arm_a arm_b Request !6
Bandit Algorithmの概要 arm_a E[r|A = a] V[r|A = a] arm_b
E[r|A = b] V[r|A = b] Request !7
Bandit Algorithmの概要 arm_a E[r|A = a] V[r|A = a] arm_b
E[r|A = b] V[r|A = b] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm !8
Bandit Algorithmの概要 arm_a E[r|A = a] V[r|A = a] arm_b
E[r|A = b] V[r|A = b] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm Feedback +Update !9
Banditの良いところ • 古典的にはAB-test(RCT)が使われていたタスク 前半AB-testして、後半は良かったのを使う。 代理店とかでよくやる。 • Banditだと得られるclick数がより多くなる armのモデルを更新しつつ モデルに従って選ぶ !10
Bandit Algorithmの概要 arm_a E[r|A = a] V[r|A = a] arm_b
E[r|A = b] V[r|A = b] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm Storage Feedback Batched Bandit Setting/interactive machine learning !11
Bandit Algorithmの概要 arm_a E[r|A = a] V[r|A = a] arm_b
E[r|A = b] V[r|A = b] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm Storage Feedback Update Batched Bandit Setting/interactive machine learning !12
Bandit Algorithmの概要 arm_a E[r|A = a,X] V[r|A = a,X] arm_b
E[r|A = b,X] V[r|A = b,X] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm Storage Feedback Update Batched Bandit Setting/interactive machine learning Contextual Bandit Case !13
Policyと呼ばれる部分 arm_a E[r|A = a,X] V[r|A = a,X] arm_b E[r|A
= b,X] V[r|A = b,X] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm Storage Feedback !14
Thompson + Batch arm_a E[r|A = a,X] V[r|A = a,X]
arm_b E[r|A = b,X] V[r|A = b,X] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm !15 腕の選択を複数回繰り返せば、 あるバッチでの真の確率を得られる。 ⼊ってくるリクエストに対して、 選択肢の選択確率が決まる。
バンディットのログで 因果推論(CI)
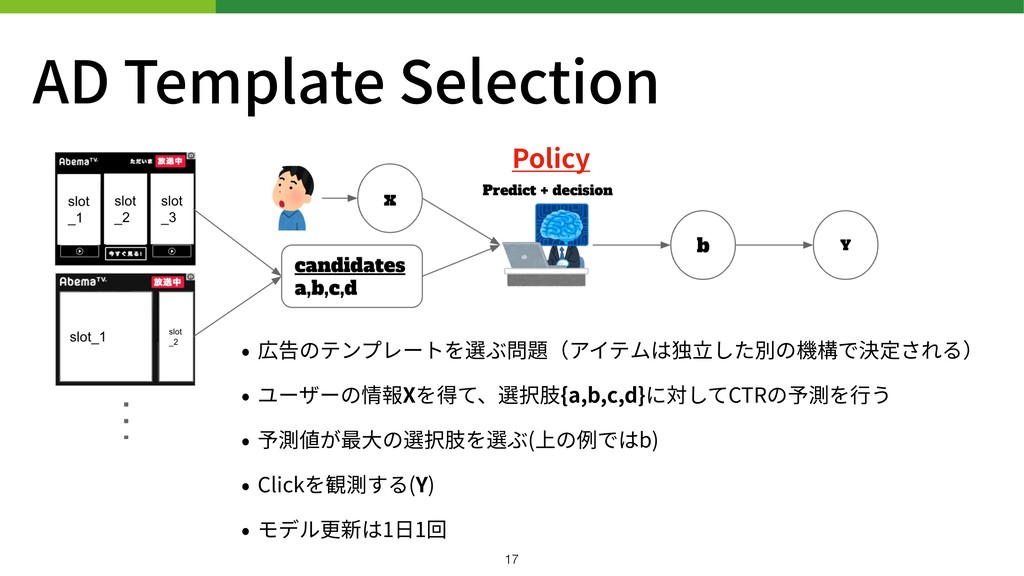
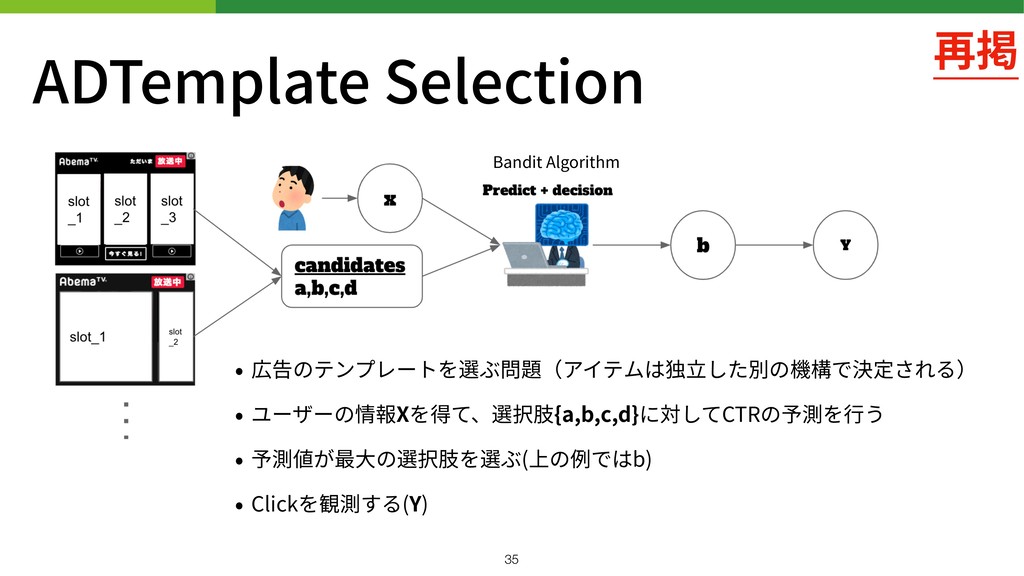
AD Template Selection • 広告のテンプレートを選ぶ問題(アイテムは独⽴した別の機構で決定される) • ユーザーの情報Xを得て、選択肢{a,b,c,d}に対してCTRの予測を⾏う • 予測値が最⼤の選択肢を選ぶ(上の例ではb) •
Clickを観測する(Y) • モデル更新は1⽇1回 Policy !17
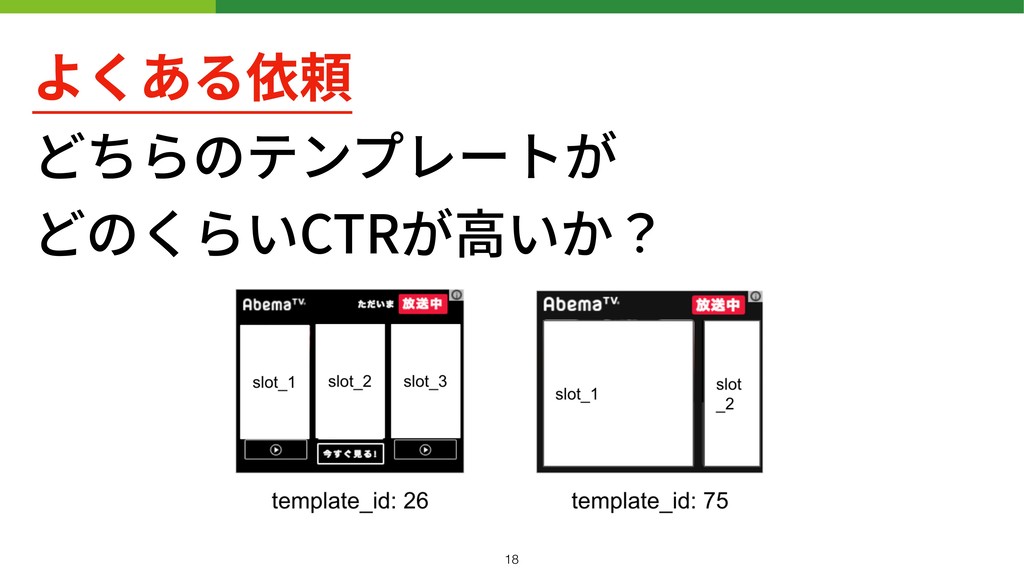
よくある依頼 どちらのテンプレートが どのくらいCTRが⾼いか? !18
Golden Standard Research Design !19
因果推論による情報の復元 • 選択肢bのCTRを評価したい • バンディットの選択がbの場合にはYの値がわかる • 観測できたYだけで評価をするべきか? • 分布が全体のデータの分布と同じなら問題ない •
バンディットがbを選んだというバイアスが存在 →観測できたデータから全体での結果を推測する →因果推論の出番! !20
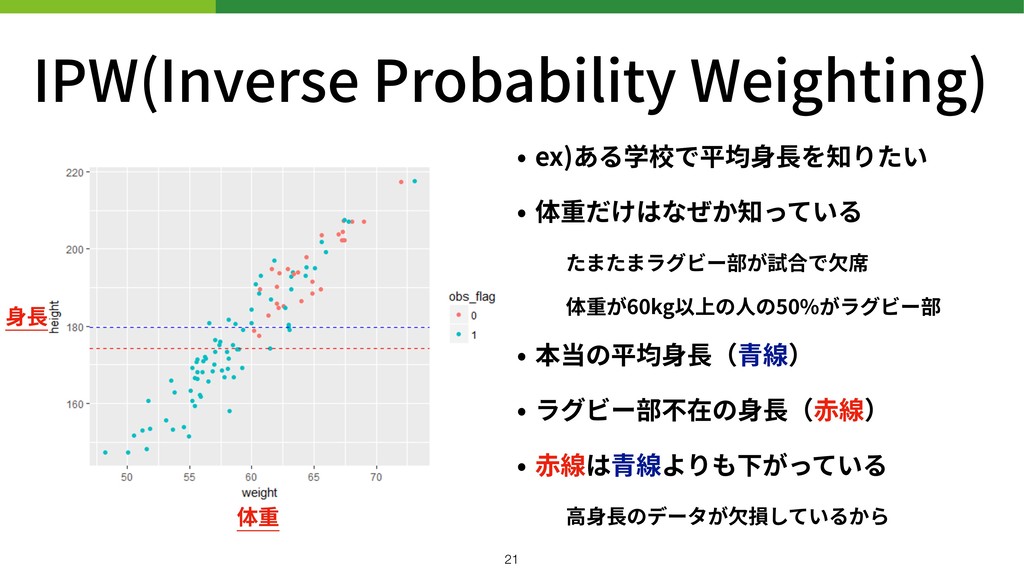
IPW(Inverse Probability Weighting) • ex)ある学校で平均⾝⻑を知りたい • 体重だけはなぜか知っている たまたまラグビー部が試合で⽋席 体重が60kg以上の⼈の50%がラグビー部 •
本当の平均⾝⻑(⻘線) • ラグビー部不在の⾝⻑(⾚線) • ⾚線は⻘線よりも下がっている ⾼⾝⻑のデータが⽋損しているから !21 ⾝⻑ 体重
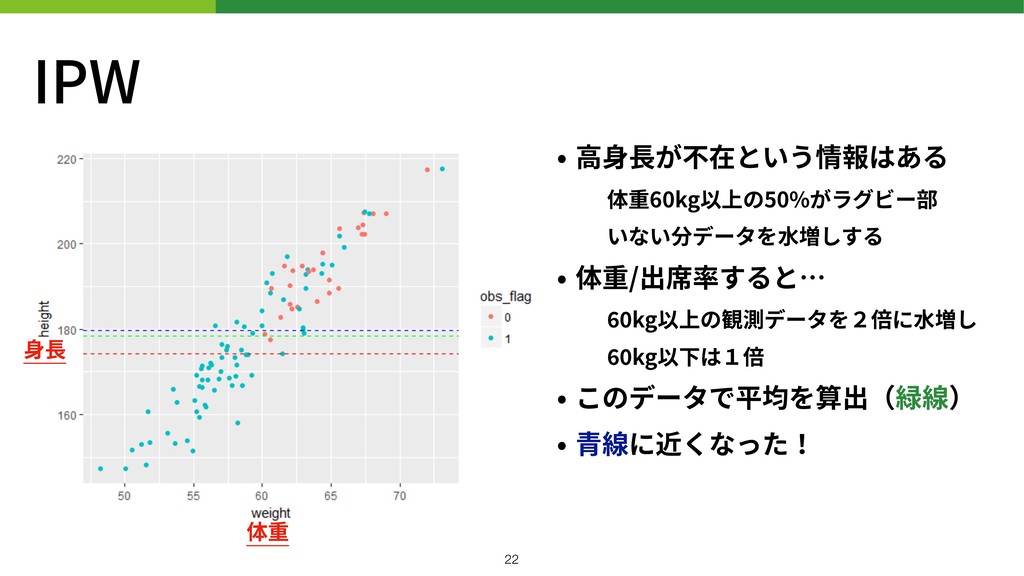
IPW • ⾼⾝⻑が不在という情報はある 体重60kg以上の50%がラグビー部 いない分データを⽔増しする • 体重/出席率すると… kg以上の観測データを2倍に⽔増し kg以下は1倍 •
このデータで平均を算出(緑線) • ⻘線に近くなった! !22 ⾝⻑ 体重
データが⽋損していて、 !23
得られたデータの 観測確率が分かっていれば、 = Propensity Score 再掲 !24
データを⽔増しして、 元の平均を推定することが可能。 !25
因果推論による情報の復元 •黒のデータは⽋損(ラグビー部) •⽋損の理由はバンディットでbが選 ばれないから •では観測確率は? →Policyがbを選ぶ確率 !26
True Propensity Score arm_a E[r|A = a,X] V[r|A = a,X]
arm_b E[r|A = b,X] V[r|A = b,X] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm Storage Feedback Batched Bandit Setting/interactive machine learning !27
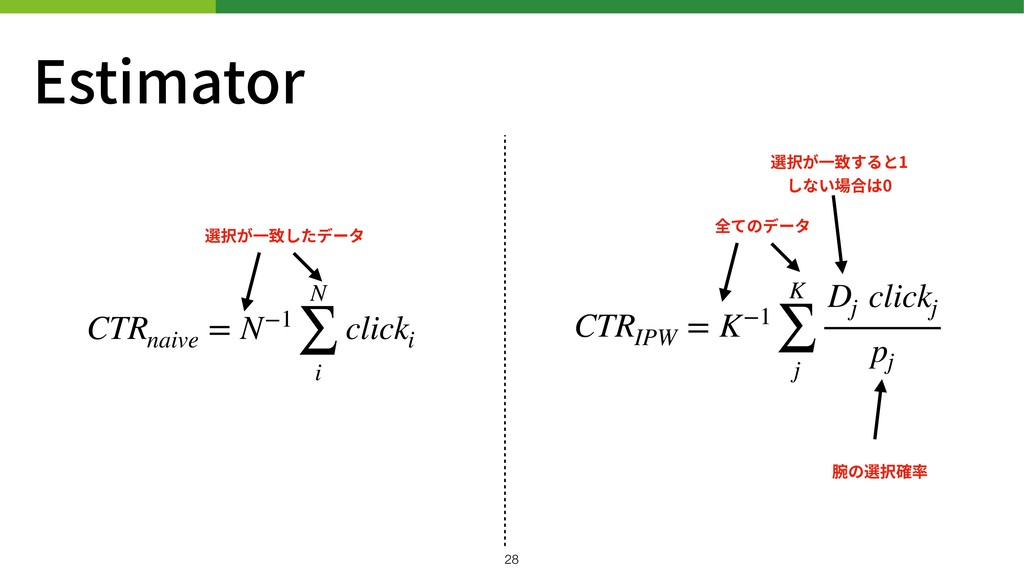
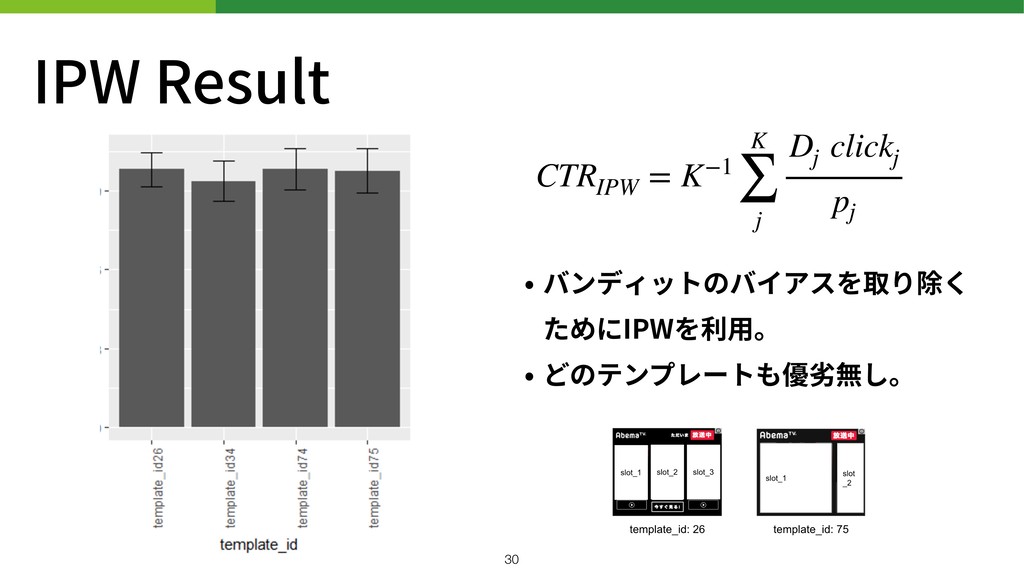
Estimator CTRnaive = N−1 N ∑ i clicki CTRIPW =
K−1 K ∑ j Dj clickj pj 選択が⼀致したデータ 全てのデータ 選択が⼀致すると1 しない場合は0 腕の選択確率 !28
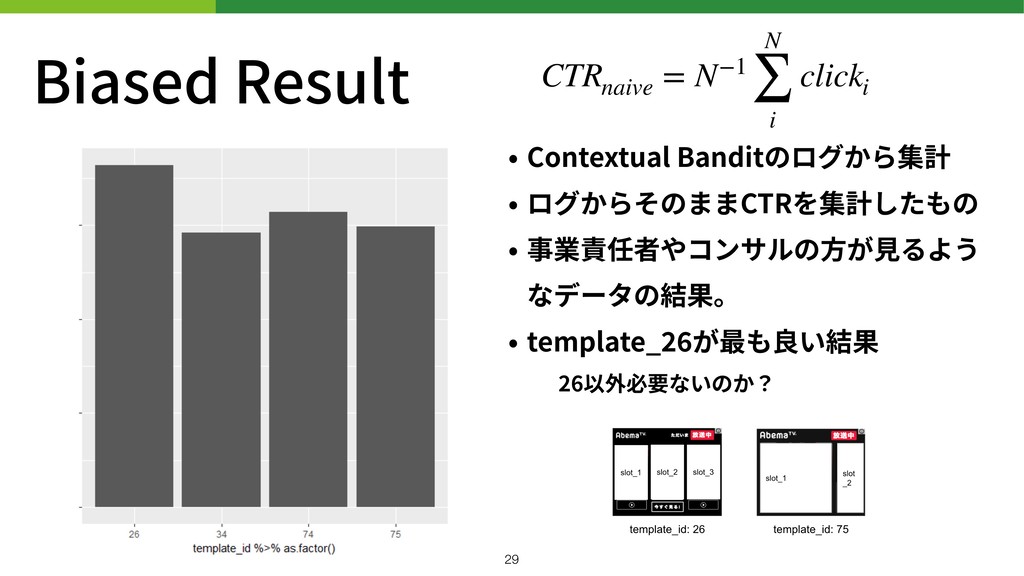
Biased Result • Contextual Banditのログから集計 • ログからそのままCTRを集計したもの • 事業責任者やコンサルの⽅が⾒るよう なデータの結果。
• template_ が最も良い結果 26以外必要ないのか? CTRnaive = N−1 N ∑ i clicki !29
IPW Result • バンディットのバイアスを取り除く ためにIPWを利⽤。 • どのテンプレートも優劣無し。 CTRIPW = K−1
K ∑ j Dj clickj pj !30
Heterogeneity • GRFを使う • 条件別の因果効果を推定する • CV的な操作を⾏いRobust性を担保 • GRFで因果効果の傾向が変わる変数を 探索する。
!31
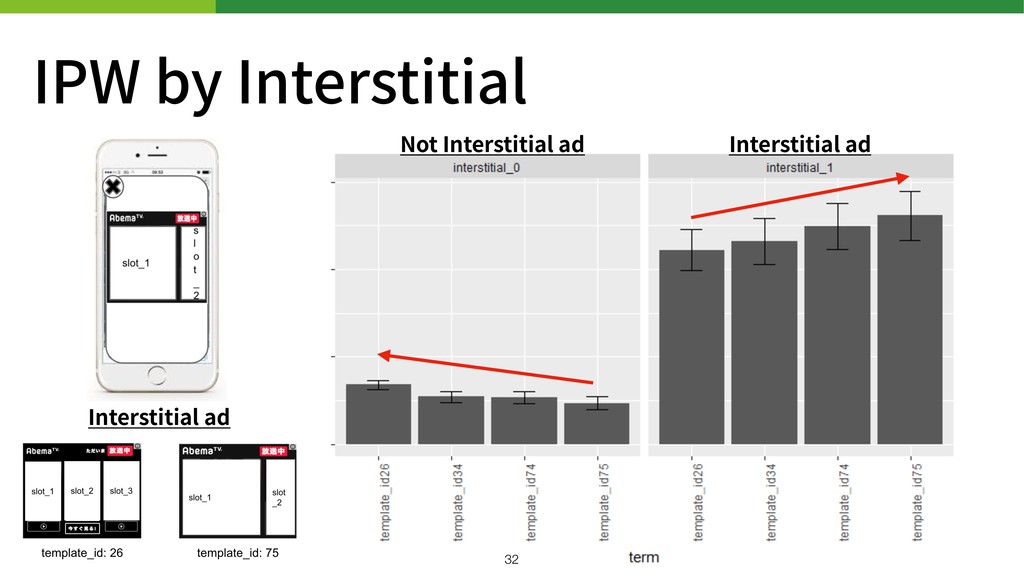
IPW by Interstitial Interstitial ad Not Interstitial ad Interstitial ad
!32
Banditのログでバイアスの少ない 事後的な分析が出来る。 !33
Off-Policy Evaluation (OPE)
ADTemplate Selection • 広告のテンプレートを選ぶ問題(アイテムは独⽴した別の機構で決定される) • ユーザーの情報Xを得て、選択肢{a,b,c,d}に対してCTRの予測を⾏う • 予測値が最⼤の選択肢を選ぶ(上の例ではb) • Clickを観測する(Y)
Bandit Algorithm 再掲 !35
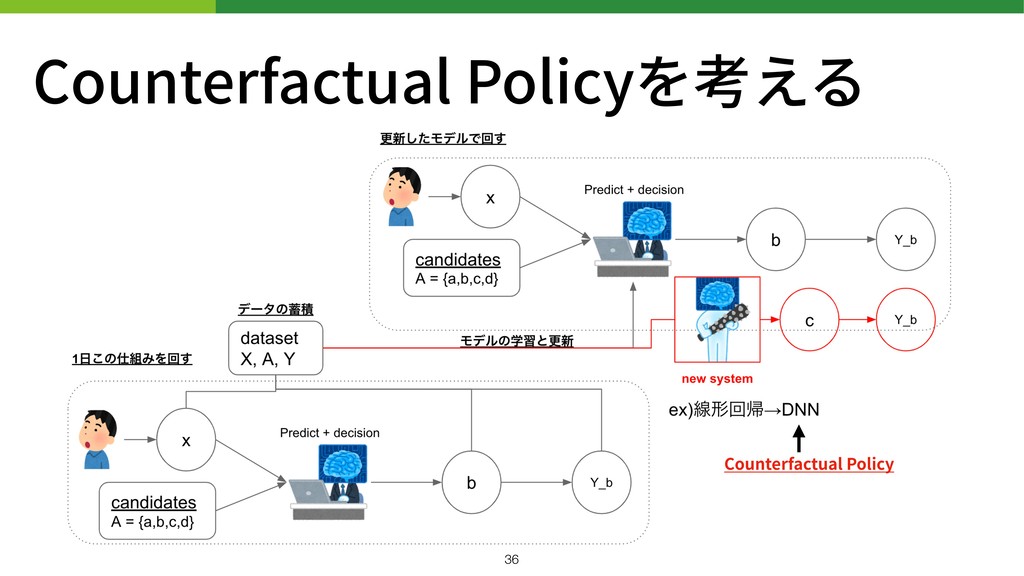
!36 Counterfactual Policyを考える Counterfactual Policy
Research Question How to compare two AI Systems? !37
Golden Standard Research Design !38
RCT is costly • RCTの為にモデルの実装が必要 • ⼤量のアイデアを同時に試すのは不可能 • ハイパーパラメーターなどの調整での利⽤は⾮現実的 •
CF Policyがダメダメだと損失のリスクもある‧‧‧ →なるべくRCTせずに評価を⾏いたい !39
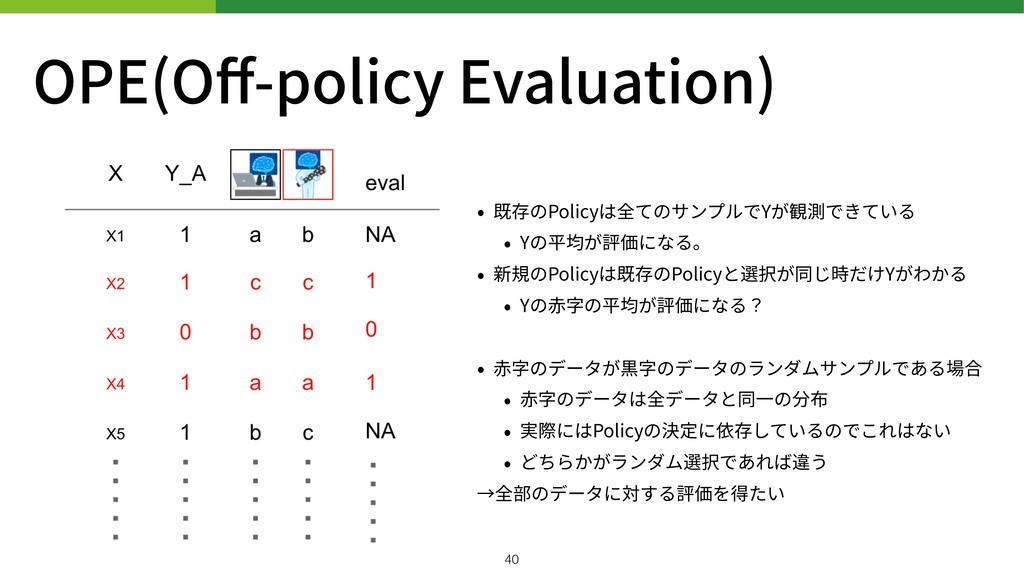
OPE(Off-policy Evaluation) • 既存のPolicyは全てのサンプルでYが観測できている • Yの平均が評価になる。 • 新規のPolicyは既存のPolicyと選択が同じ時だけYがわかる • Yの⾚字の平均が評価になる?
• ⾚字のデータが黒字のデータのランダムサンプルである場合 • ⾚字のデータは全データと同⼀の分布 • 実際にはPolicyの決定に依存しているのでこれはない • どちらかがランダム選択であれば違う →全部のデータに対する評価を得たい !40
そうだ、IPWを使おう。 !41
データが⽋損していて、 再掲 !42
得られたデータの 観測確率が分かっていれば、 = Propensity Score 再掲 !43
データを⽔増しして、 元の平均を推定することが可能。 再掲 !44
True Propensity Score arm_a E[r|A = a,X] V[r|A = a,X]
arm_b E[r|A = b,X] V[r|A = b,X] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm Storage Feedback Batched Bandit Setting/interactive machine learning 再掲 !45
因果推論とOPEの差 • 因果推論 常に⼀つの選択肢を選ぶpolicyの評価 • Off-Policy Evaluation 状況によって選択が変化するpolicyの評価 因果推論はむしろOPEの特殊な形 CTRIPW
= K−1 K ∑ j Dj clickj pj CTROPE = K−1 K ∑ j m ∑ a clickj Dj,a π(a|Xj ) pj 腕aが⼀致した選択か? 評価したいpolicyの決定 !46
Efficient CF Evaluation • AAAI (oral + poster) https://arxiv.org/abs/ .
• ⼤まかな内容 傾向スコアの作り⽅を変える MLで傾向スコアを推定する OPEでの不確実性が減少 !47
True Propensity Score arm_a E[r|A = a,X] V[r|A = a,X]
arm_b E[r|A = b,X] V[r|A = b,X] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm Storage Feedback Batched Bandit Setting/interactive machine learning 再掲 !48
True Propensity Score arm_a E[r|A = a,X] V[r|A = a,X]
arm_b E[r|A = b,X] V[r|A = b,X] Decision Rule (UCB/Thompson Sampling) Request arm_b Selected Arm Storage Feedback Batched Bandit Setting/interactive machine learning 提案:選択確率をMLで推定してしまう。 •TPS= %でも実際のデータ上では55%だったりする。 •IPWではデータ上の割り振りを修正したい •ML/nonparametric-modelでデータ上の割り振りを学習する !49
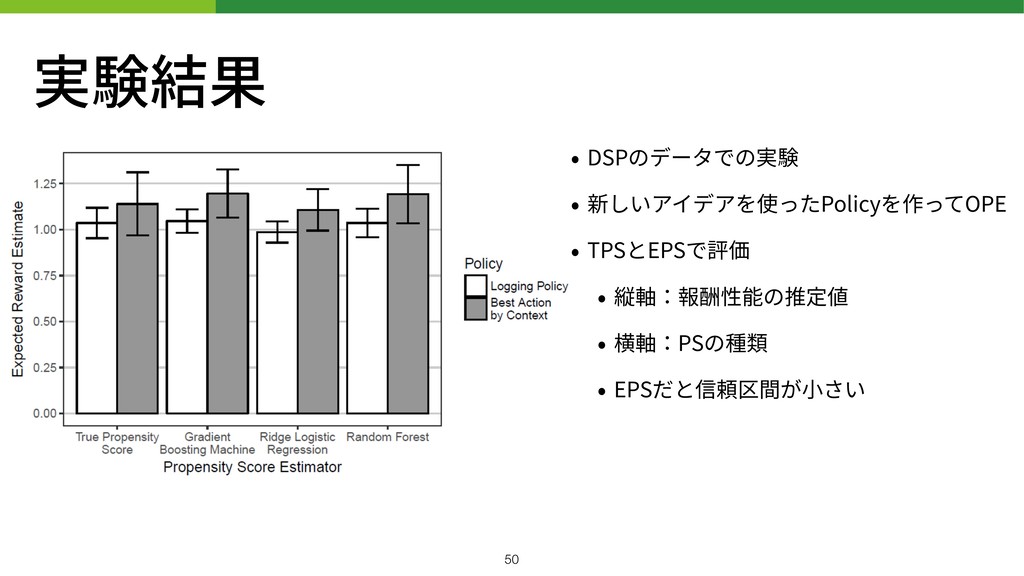
実験結果 • DSPのデータでの実験 • 新しいアイデアを使ったPolicyを作ってOPE • TPSとEPSで評価 • 縦軸:報酬性能の推定値 •
横軸:PSの種類 • EPSだと信頼区間が⼩さい !50
True Propensity Score Case Estimated Propensity Score Case !51
Banditのログでバイアスの少ない Policy評価ができた。 (しかも統計的に効率的に。) !52
Future Work + まとめ
分析(not予測)環境の変化 • 機械学習を利⽤した意思決定の⾃動化が進んできた RTB/Recommend/Ad Selection/Ranking/etc この6年間肩⾝が狭くなる⼀⽅ • ⼀⽅で)⾃動意思決定によって残されたデータを分析する必要性 What is
good policy? / Causal effect of some items →プロダクトとして⾃動意思決定と事後分析をセットで考える必要性 • バンディットはたまたまこの流れが早かった 他の機械学習タスクでもこの流れになる !54
分析者(not予測)が⽬指したいところ • ⾃動意思決定をデザインする(with ML Engineer) 事後的な分析を⾒込んだデザインをする必要がある arg maxやUCBからの卒業(報酬性能も低い) • ⾃動意思決定のデザインに応じた分析をデザインする
MDPを仮定する強化学習のログで因果推論はどうやるか? • 結局両⽅デザインしに⾏く必要がある データが⽣まれるプロセスから、 事後的な分析のプロセスまでをデザインする。 !55
21世紀の分析者は、 データのゆりかごから 墓場までをデザインする。 !56
Enjoy Your Design!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Bandit Algorithmの概要 arm_a E[r|A = a] V[r|A = a] arm_b](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_6.jpg){kind=link}
![Bandit Algorithmの概要 arm_a E[r|A = a] V[r|A = a] arm_b](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_7.jpg){kind=link}
![Bandit Algorithmの概要 arm_a E[r|A = a] V[r|A = a] arm_b](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_8.jpg){kind=link}
{kind=link}
![Bandit Algorithmの概要 arm_a E[r|A = a] V[r|A = a] arm_b](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_10.jpg){kind=link}
![Bandit Algorithmの概要 arm_a E[r|A = a] V[r|A = a] arm_b](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_11.jpg){kind=link}
![Bandit Algorithmの概要 arm_a E[r|A = a,X] V[r|A = a,X] arm_b](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_12.jpg){kind=link}
![Policyと呼ばれる部分 arm_a E[r|A = a,X] V[r|A = a,X] arm_b E[r|A](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_13.jpg){kind=link}
![Thompson + Batch arm_a E[r|A = a,X] V[r|A = a,X]](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![True Propensity Score arm_a E[r|A = a,X] V[r|A = a,X]](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![True Propensity Score arm_a E[r|A = a,X] V[r|A = a,X]](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
![True Propensity Score arm_a E[r|A = a,X] V[r|A = a,X]](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_47.jpg){kind=link}
![True Propensity Score arm_a E[r|A = a,X] V[r|A = a,X]](https://files.speakerdeck.com/presentations/dbcb395b208f4d89a7493f48081d9738/slide_48.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}