Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【CEDEC2025】大規模言語モデルを活用したゲーム内会話パートのスクリプト作成支援への取り組み
Search
Cygames, Inc.
PRO
July 29, 2025
Technology
2.6k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【CEDEC2025】大規模言語モデルを活用したゲーム内会話パートのスクリプト作成支援への取り組み
2025/07/23 CEDEC2025
Cygames, Inc.
PRO
July 29, 2025
More Decks by Cygames, Inc.
See All by Cygames, Inc.
【U/Day Tokyo 2025】Cygames流 最新スマートフォンゲームの技術設計 〜『Shadowverse: Worlds Beyond』におけるアーキテクチャ再設計の挑戦~
cygames
PRO
4
17k
【CEDEC+KYUSHU2025】学生・若手必見!テクニカルアーティスト 大全 ~仕事・スキル・キャリアパス、TAの「わからない」を徹底解剖~
cygames
PRO
1
1.3k
【TiDB User Day2025】リリース時のアクセス急増をいかにしてノーメンテで乗り越えたか 〜『Shadowverse: Worlds Beyond』におけるTiDB採用のゲームサーバー設計〜
cygames
PRO
1
2.9k
【CEDEC2025】『Shadowverse: Worlds Beyond』二度目のDCG開発でゲームをリデザインする~遊びやすさと競技性の両立~
cygames
PRO
2
960
【CEDEC2025】現場を理解して実現!ゲーム開発を効率化するWebサービスの開発と、利用促進のための継続的な改善
cygames
PRO
0
1.9k
【CEDEC2025】ブランド力アップのためのコンテンツマーケティング~ゲーム会社における情報資産の活かし方~
cygames
PRO
0
2k
【CEDEC2025】『ウマ娘 プリティーダービー』における映像制作のさらなる高品質化へ!~ 豊富な素材出力と制作フローの改善を実現するツールについて~
cygames
PRO
0
840
【CEDEC2025】LLMを活用したゲーム開発支援と、生成AIの利活用を進める組織的な取り組み
cygames
PRO
1
5.3k
【TiDB GAME DAY 2025】Shadowverse: Worlds Beyond にみる TiDB 活用術
cygames
PRO
0
3.8k
Other Decks in Technology
See All in Technology
AI Driven AI Governance
pict3
0
350
証券システムを10年Scalaで作り続けるということ - 関数型まつり2026
krrrr38
3
840
穢れた技術選定について
watany
4
430
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.1k
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.7k
シンガポールで登壇してきます
yama3133
0
120
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
3.4k
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
490
大量データに対しても、生成AIを用いてリーズナブルにデータ加工をしたい!Databricksのai_queryについて調べてみた
kamoshika
1
120
AI時代の EM への処方箋
staka121
PRO
0
140
はじめてのWDM
miyukichi_ospf
1
140
Featured
See All Featured
A Modern Web Designer's Workflow
chriscoyier
698
190k
The innovator’s Mindset - Leading Through an Era of Exponential Change - McGill University 2025
jdejongh
PRO
1
220
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
The Curious Case for Waylosing
cassininazir
1
430
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Winning Ecommerce Organic Search in an AI Era - #searchnstuff2025
aleyda
1
2.1k
Discover your Explorer Soul
emna__ayadi
2
1.2k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
330
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
340
How to build a perfect <img>
jonoalderson
1
5.8k
The SEO identity crisis: Don't let AI make you average
varn
0
510
The Director’s Chair: Orchestrating AI for Truly Effective Learning
tmiket
1
210
Transcript
1/78 エンジニアリング / プロダクション・ゲームデザイン 大規模言語モデルを活用した ゲーム内会話パートのスクリプト作成支援への取り組み 株式会社Cygames 開発運営支援 / ゲームエンジニア
立福 寛
2/78 はじめに
3/78 自己紹介 複数のゲーム会社でコンテンツパイプラインの構築、モバイルゲームの開発・運営などを担当。 2018年10月に株式会社Cygamesへ合流。2019年後半からAIの社内導入に取り組んでいる。 CEDEC2023:AIによる自然言語処理・音声解析を用いたゲーム内会話パートの感情分析への取り組み CEDEC2024:大規模言語モデルを活用したゲーム内会話パートのスクリプト作成支援への取り組み 立福 寛 開発運営支援 /
ゲームエンジニア
4/78 セッションで得られること 大規模言語モデルを使ったゲーム内 会話パートのスクリプト作成を効率化 セリフに対応するモーション、表情差分、 パートボイスを選ぶ方法 正解率を上げる手法
5/78 解決したい課題 ◼ 従来はプランナーがシナリオを読んで手動で設定 ◼ AIで最初の叩き台を作りたい ◼ 最終調整は人力 ゲーム内会話パートの要素をAIで求めたい ◼
モーション、キャラクターの表情差分、パートボイス 求める要素 ◼ 既存ツールへの組み込み ◼ Jenkinsを使ったシステム ツールの提供方法は2種類
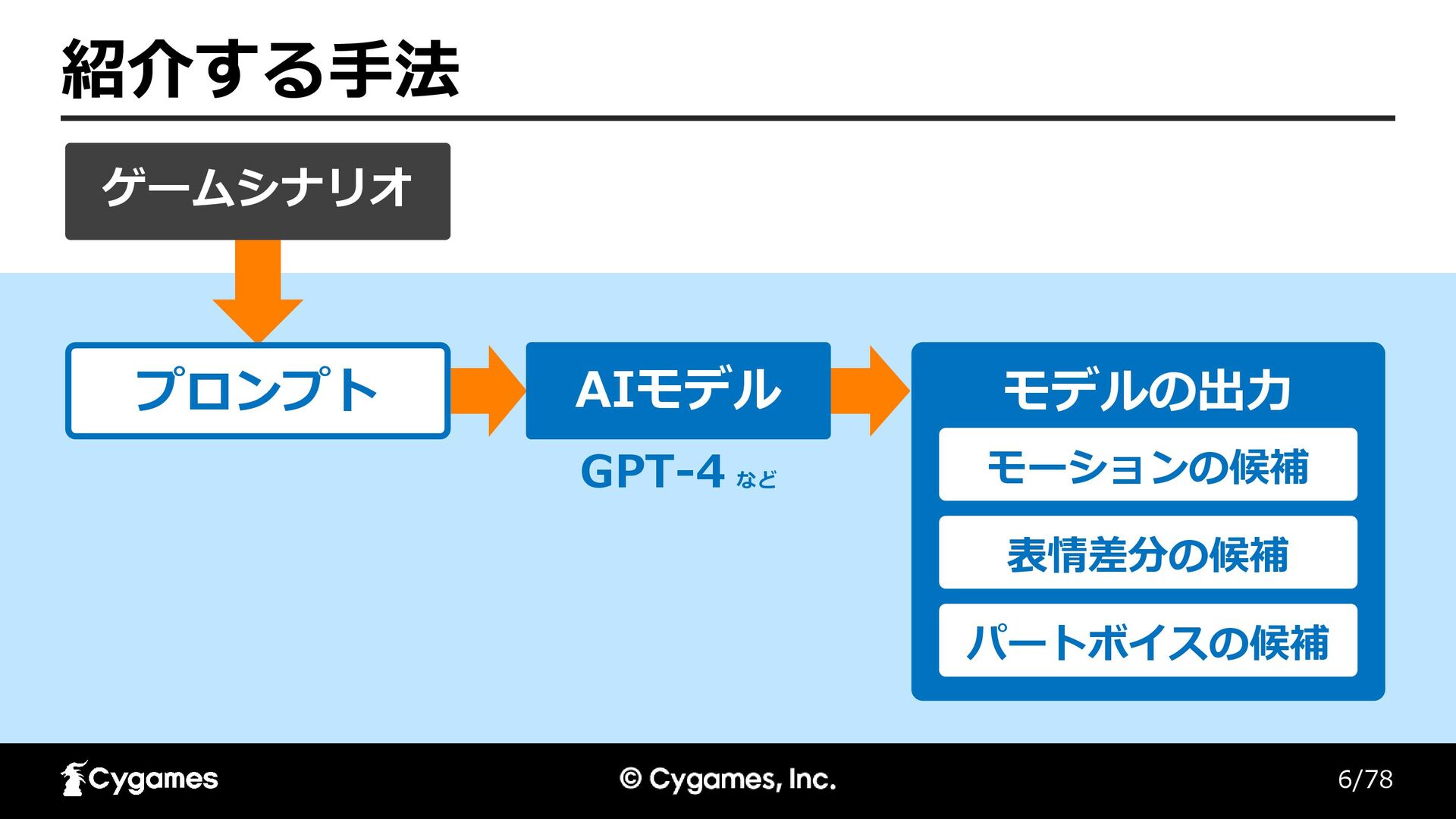
6/78 紹介する手法 AIモデル パートボイスの候補 ゲームシナリオ モデルの出力 表情差分の候補 モーションの候補 プロンプト GPT-4
など
7/78 紹介する手法のメリット 従来の手法 (ファインチューニング) 今回の手法 (インコンテキストラーニング) 学習データ 大 小 GPUを使った学習
必要 必要なし 管理するもの 学習用スクリプト 学習済みモデル なし
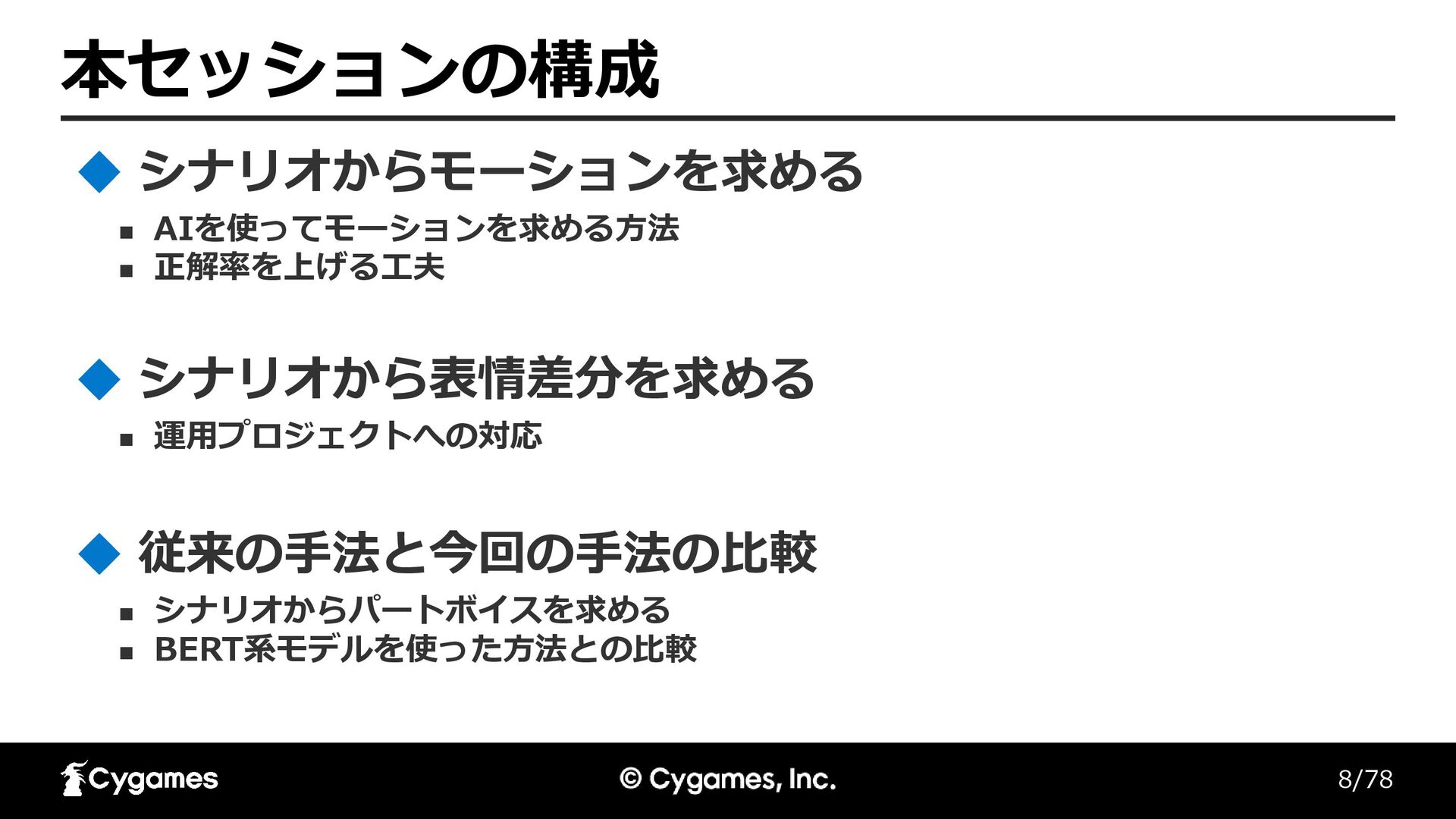
8/78 本セッションの構成 ◼ AIを使ってモーションを求める方法 ◼ 正解率を上げる工夫 シナリオからモーションを求める ◼ 運用プロジェクトへの対応 シナリオから表情差分を求める
◼ シナリオからパートボイスを求める ◼ BERT系モデルを使った方法との比較 従来の手法と今回の手法の比較
9/78 AIでシナリオに対応する モーション求める
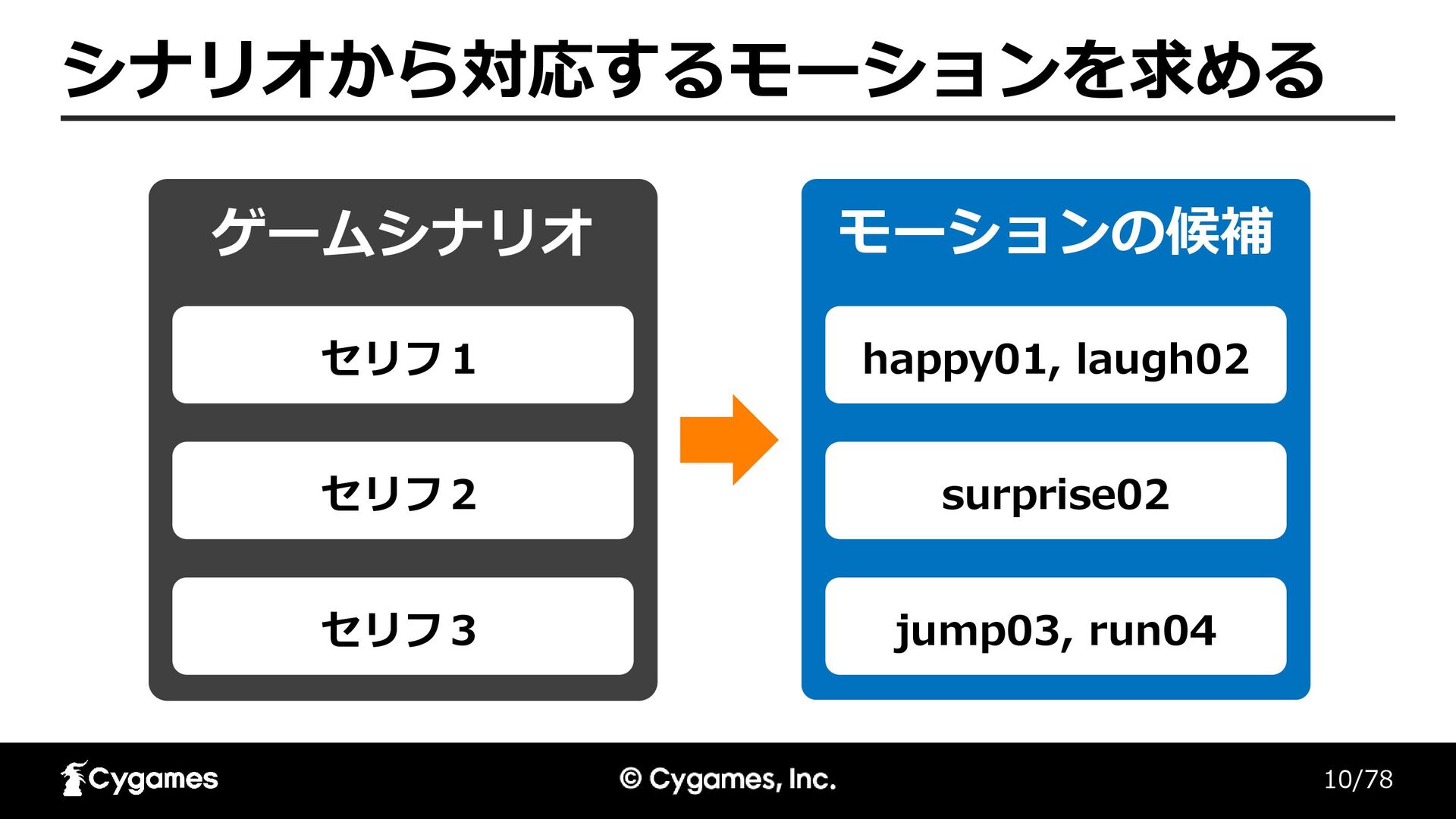
10/78 シナリオから対応するモーションを求める ゲームシナリオ セリフ1 セリフ2 セリフ3 モーションの候補 happy01, laugh02 surprise02
jump03, run04
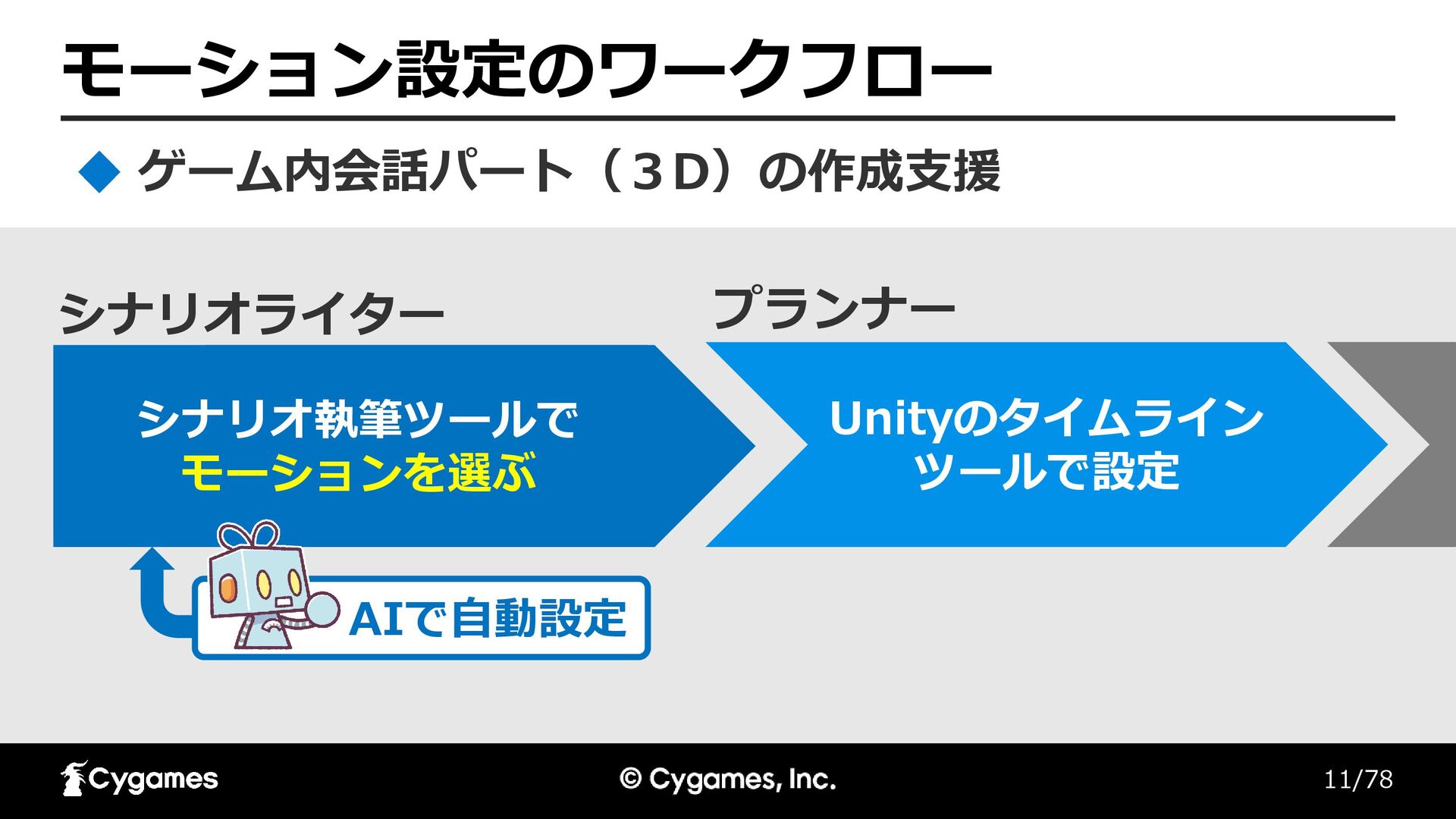
11/78 モーション設定のワークフロー ゲーム内会話パート(3D)の作成支援 シナリオライター プランナー シナリオ執筆ツールで モーションを選ぶ Unityのタイムライン ツールで設定 AIで自動設定
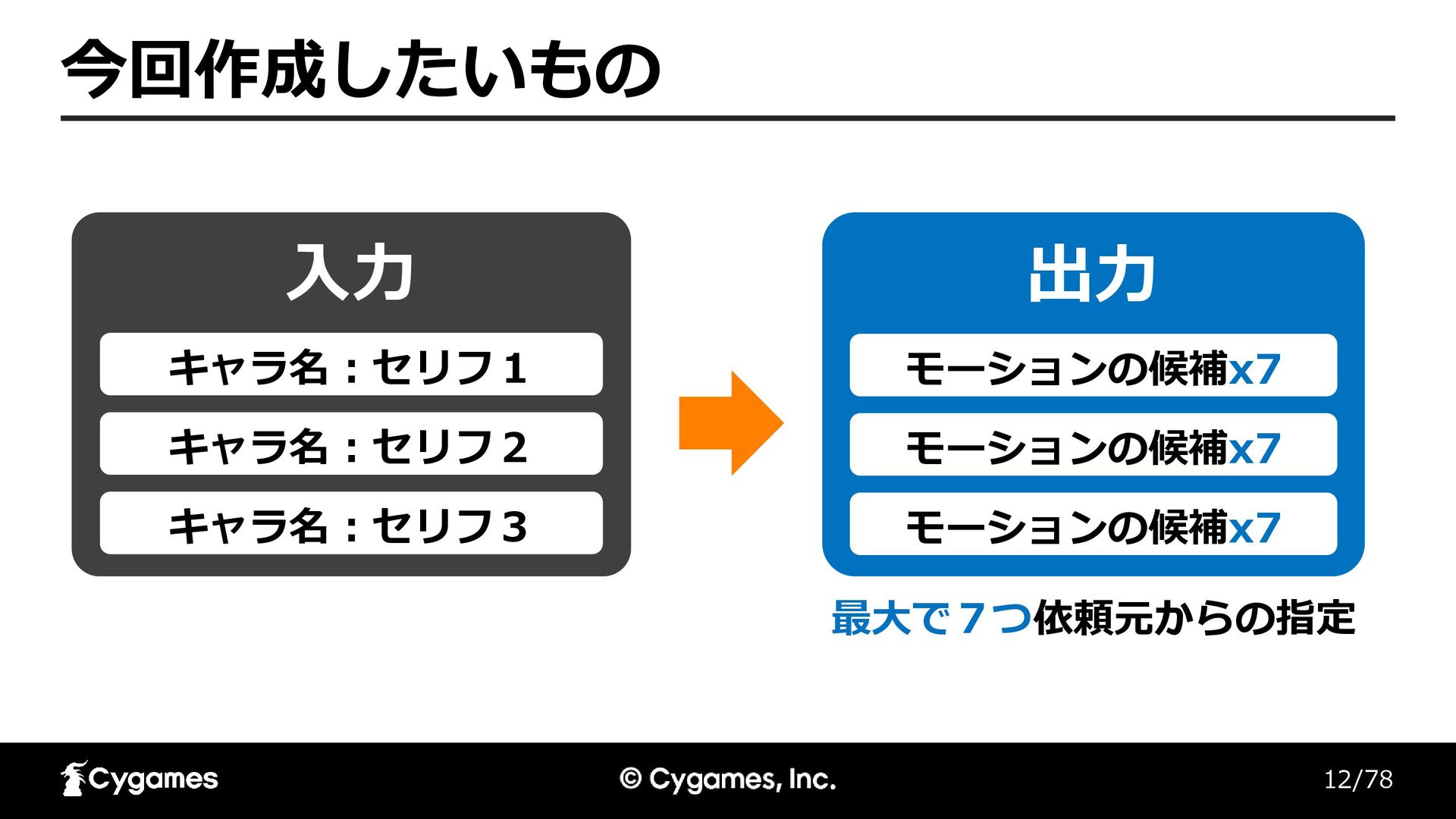
12/78 今回作成したいもの walk01 入力 キャラ名 : セリフ1 キャラ名 : セリフ2
キャラ名 : セリフ3 出力 モーションの候補x7 モーションの候補x7 モーションの候補x7 最大で7つ依頼元からの指定
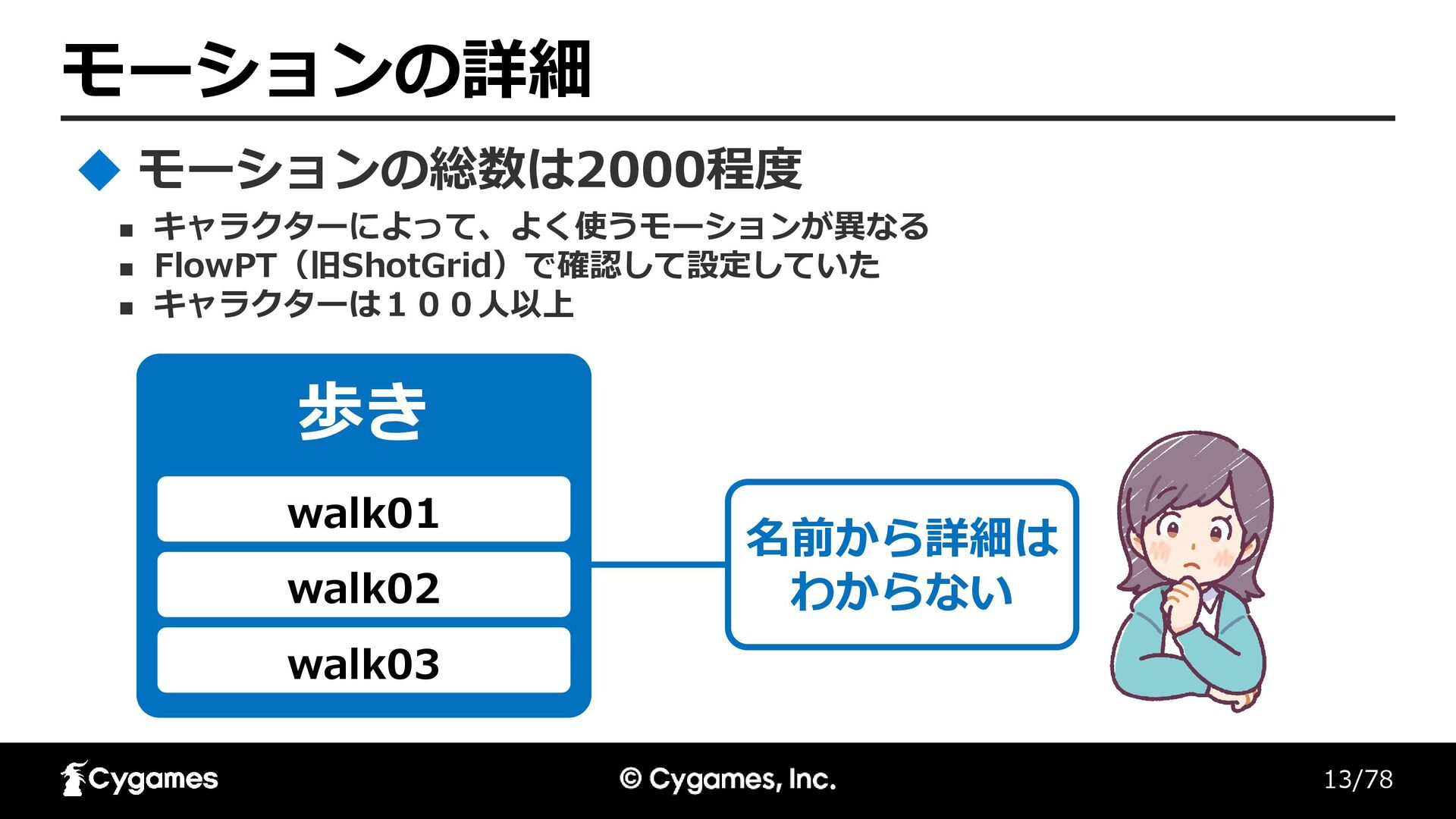
13/78 モーションの詳細 ◼ キャラクターによって、よく使うモーションが異なる ◼ FlowPT(旧ShotGrid)で確認して設定していた ◼ キャラクターは100人以上 モーションの総数は2000程度 歩き
walk01 walk02 walk03 名前から詳細は わからない
14/78 過去データを収集
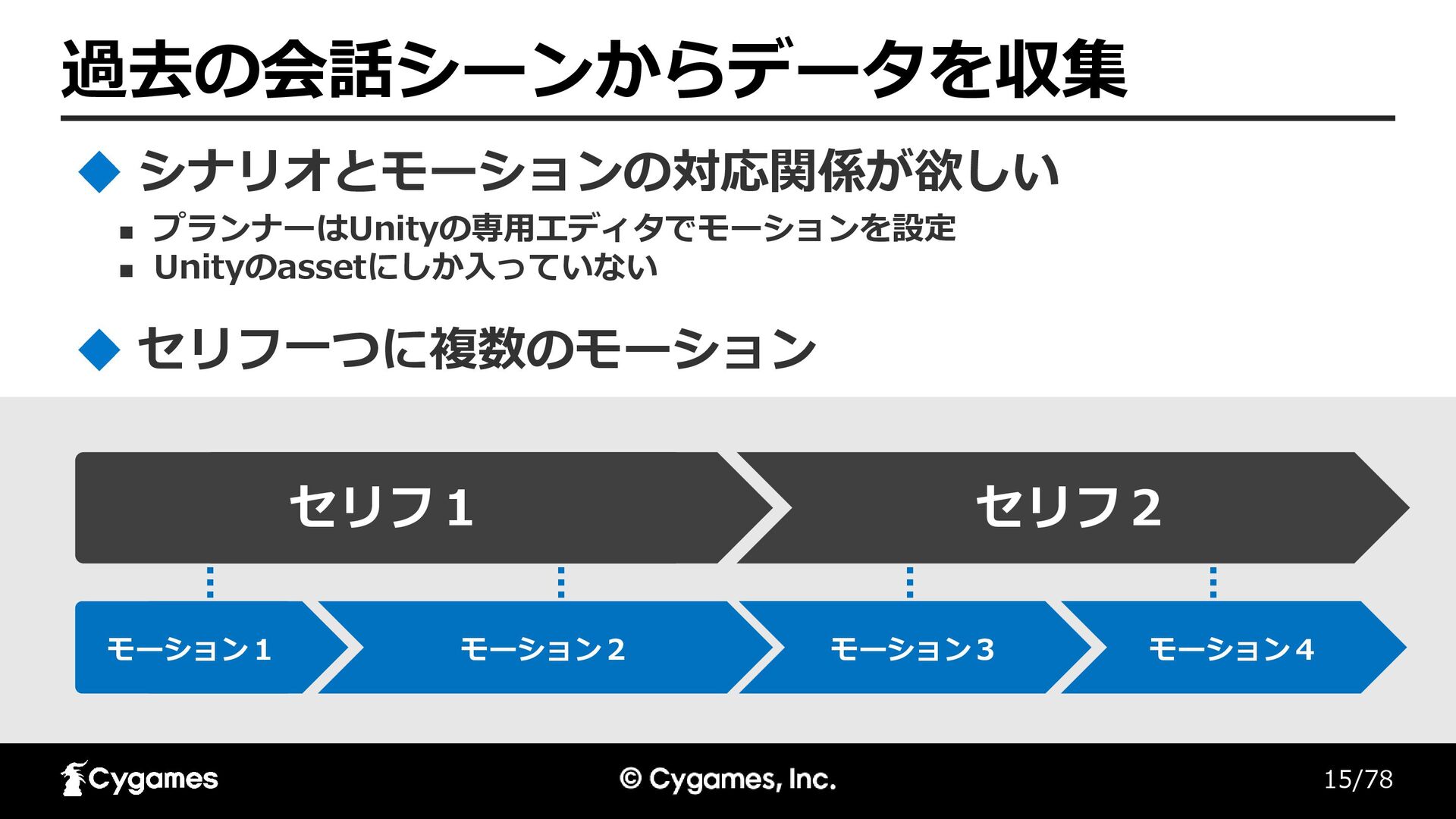
15/78 過去の会話シーンからデータを収集 ◼ プランナーはUnityの専用エディタでモーションを設定 ◼ Unityのassetにしか入っていない シナリオとモーションの対応関係が欲しい モーション1 モーション3 モーション2
モーション4 セリフ一つに複数のモーション セリフ1 セリフ2
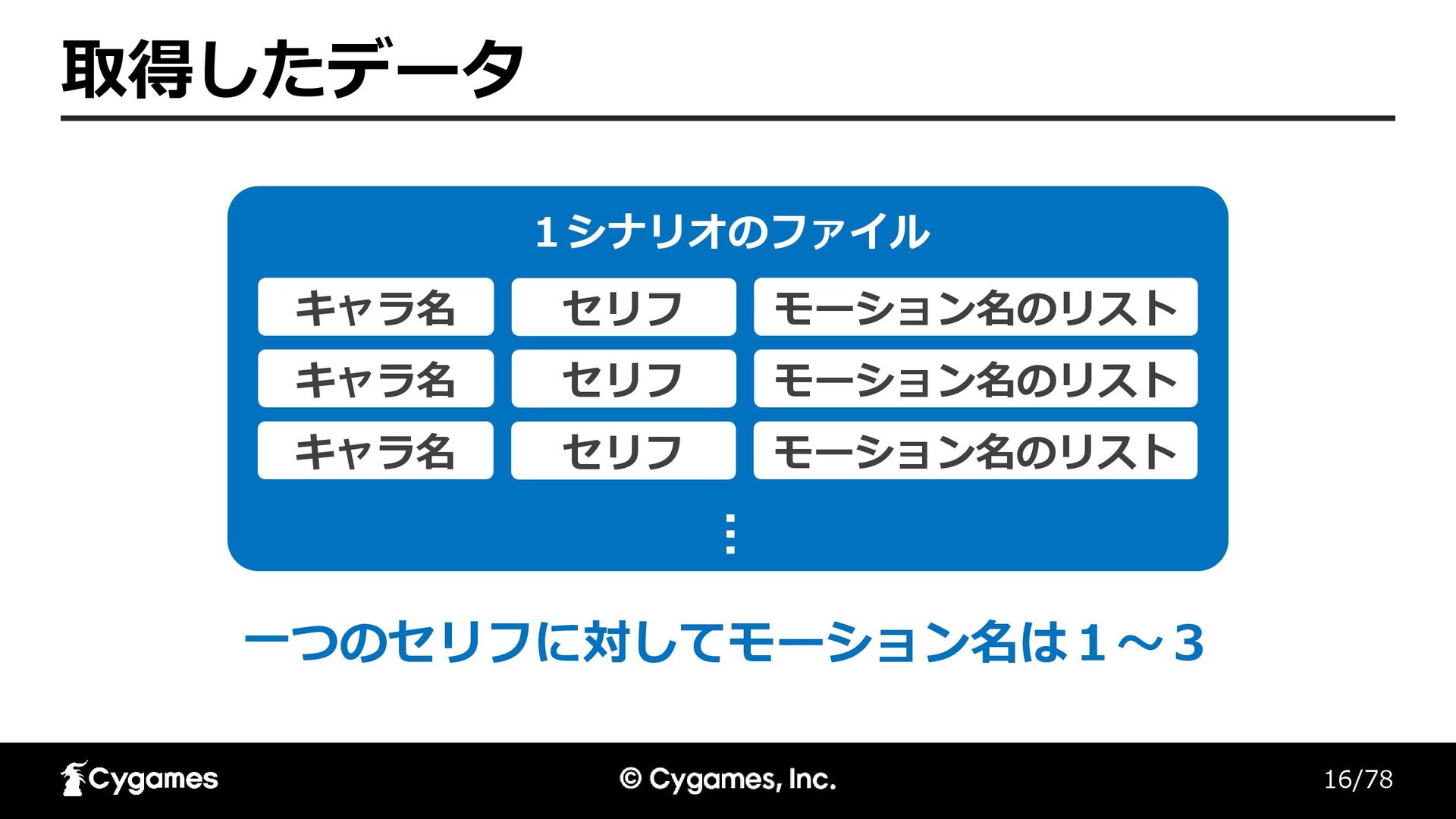
16/78 取得したデータ 1シナリオのファイル キャラ名 セリフ モーション名のリスト キャラ名 セリフ モーション名のリスト キャラ名
セリフ モーション名のリスト … 一つのセリフに対してモーション名は1〜3
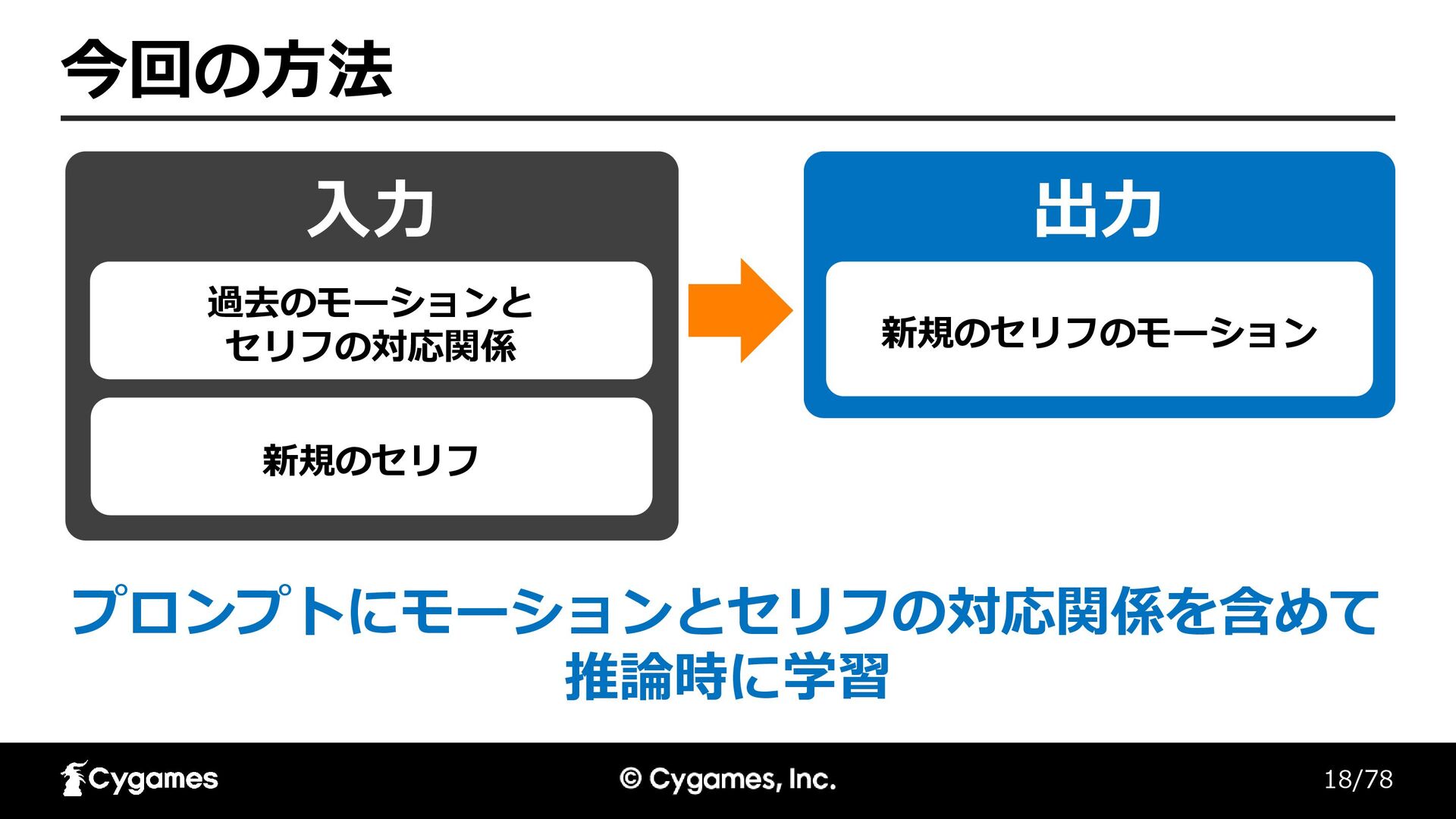
17/78 AIを使った実装
18/78 今回の方法 walk01 入力 過去のモーションと セリフの対応関係 新規のセリフ 出力 新規のセリフのモーション プロンプトにモーションとセリフの対応関係を含めて
推論時に学習
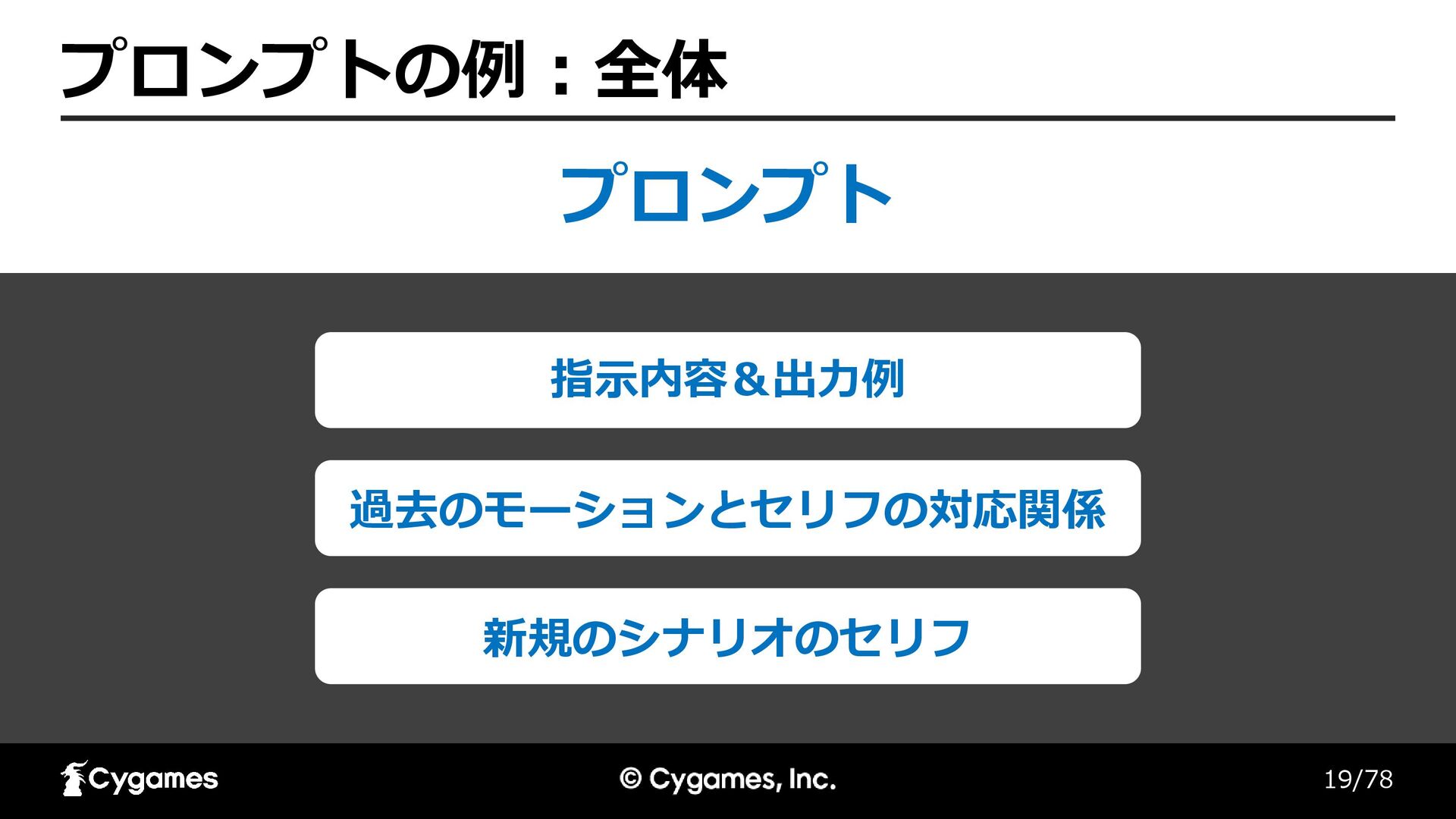
19/78 プロンプトの例:全体 プロンプト 過去のモーションとセリフの対応関係 新規のシナリオのセリフ 指示内容&出力例
20/78 プロンプトの例(1) 指示内容&出力例 最初の部分はゲームキャラクターの「キャラA」の 「モーション名 : セリフのリスト」の対応関係です。 後半の内容は「行番号 : キャラクター名
: セリフ」です。 後半の部分のセリフの行ごとに最適な「モーション名」を 5つ程度選んでJSON形式で出力してください。 === (JSONでの出力の例)
21/78 プロンプトの例(2) モーションとセリフの対応関係 以下はモーションとセリフのリストです === walk01 : [行くよ!, どこかな?, いい天気〜]
run04 : [間に合え!, もっと速く!] jump02 : [えいっ!, うぇーい!, ぴょーん]
22/78 プロンプトの例(3) 新規のシナリオ 以下はゲームのシナリオです === 1: キャラA: 「どこに行く?」 2: キャラB:
「ファミレス」 3: キャラA: 「居酒屋でもいい?」
23/78 結果が出るようになってきた ◼ 最初からそれっぽい結果が出るようになった 先ほどのプロンプトでモーションを選べる! ◼ この段階で0.39の正解率 ◼ 正解率を上げる複数の方法について解説 あとは正解率を改善すればよさそう
24/78 正解率を上げる方法
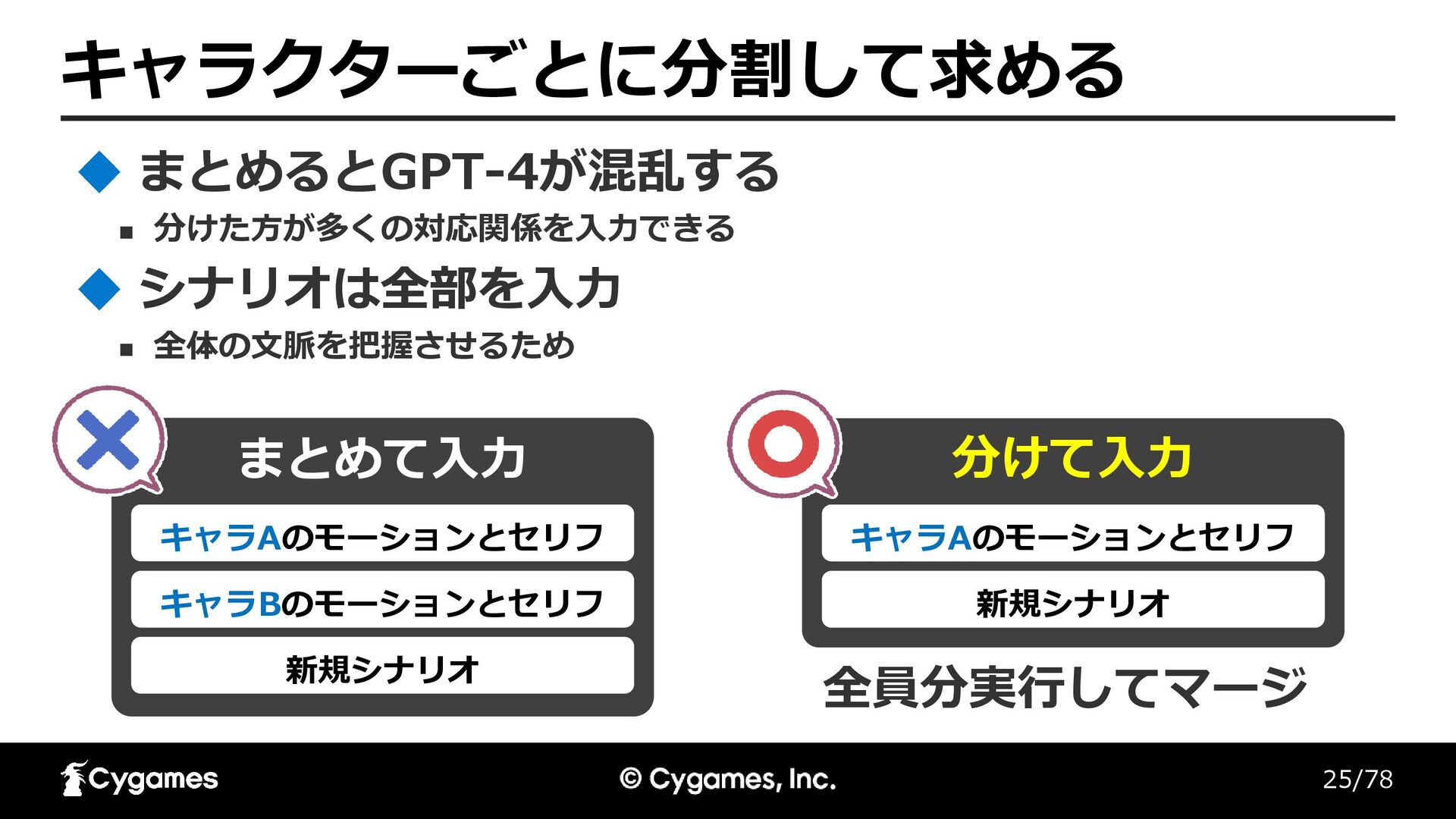
25/78 キャラクターごとに分割して求める ◼ 分けた方が多くの対応関係を入力できる まとめるとGPT-4が混乱する まとめて入力 キャラAのモーションとセリフ キャラBのモーションとセリフ 新規シナリオ 分けて入力
キャラAのモーションとセリフ 新規シナリオ 全員分実行してマージ ◼ 全体の文脈を把握させるため シナリオは全部を入力
26/78 対応関係はどれくらい入力する? ◼ 多すぎるとAPIがエラーを返す>エラーを返す限界まで入れる ◼ スペック上の入力コンテキスト長>有効コンテキスト長 の違い 多いほどよい 2、3の例 多め
大量 ◼ Many-Shot In-Context Learning (Agarwal, 2024) 関連論文
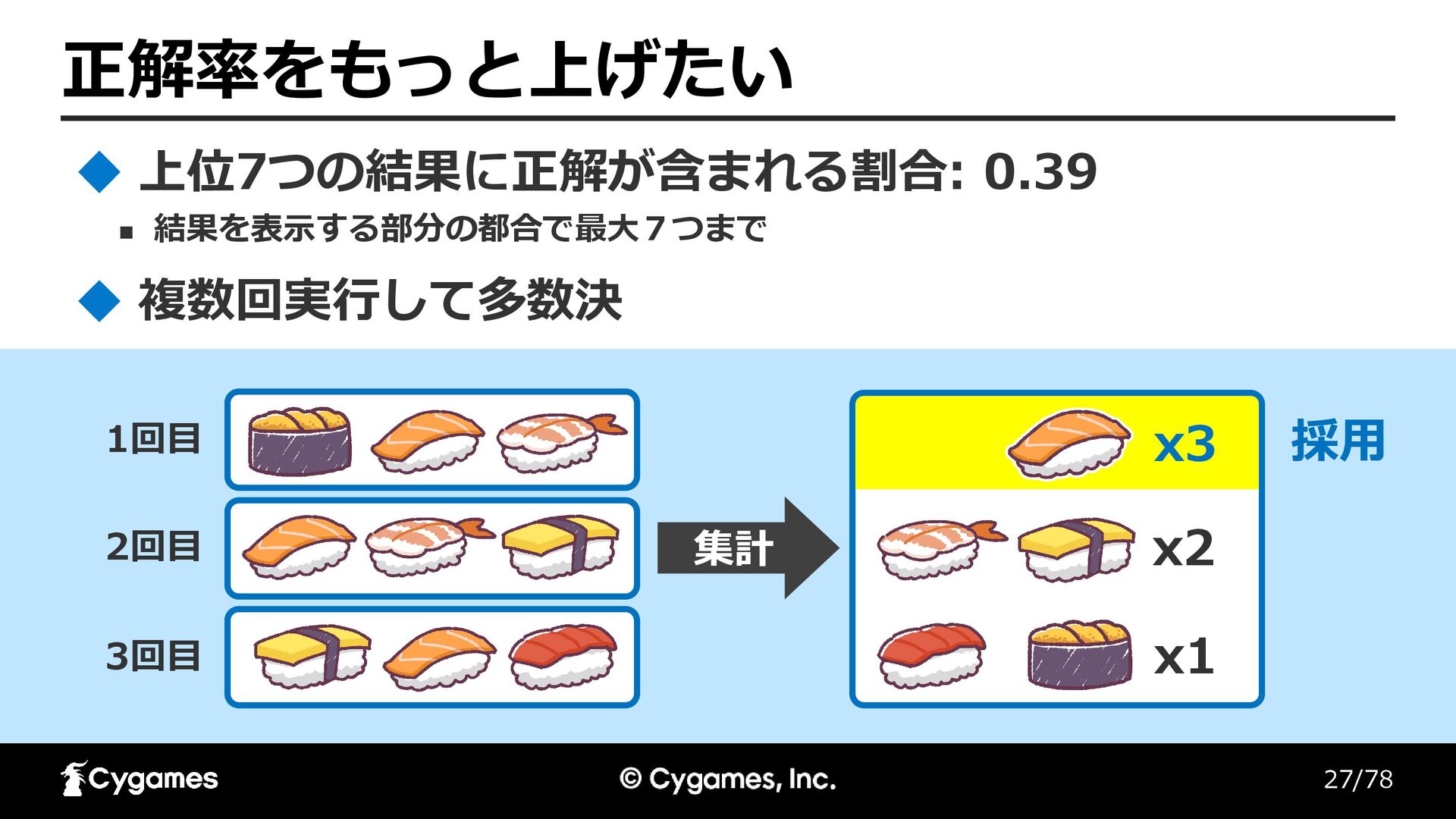
27/78 正解率をもっと上げたい ◼ 結果を表示する部分の都合で最大7つまで 上位7つの結果に正解が含まれる割合: 0.39 1回目 2回目 3回目 複数回実行して多数決
x2 x1 採用 集計 x3
28/78 推論スケーリング 逐次スケーリング vs 並列スケーリング ◼ More Agents Is All
You Need (Li, 2024) ◼ GPT-3.5を20回実行するとGPT-4と同じ性能 多数の論文が発表済み ◼ 今回の手法 GPT-4oモデルで多数決
29/78 複数回実行して多数決 ◼ 1、5、10、20、30回で正解率が向上 実行回数に応じて正解率が向上 ◼ 乱数のシードを変える ◼ プロンプトの位置を変える ◼
温度パラメータを上げる 推論にランダム要素を入れる ◼ 当初は0.5 ◼ 0以上の場合は測定が難しい 温度パラメータ=0
30/78 プロンプトの位置によって結果が変わる ◼ 通称「Lost in the Middle」 ◼ 関連論文「Lost in
the Middle: How Language Models Use Long Contexts」(Liu, 2023) ◼ モデルの種類によって異なる プロンプトが長いときに真ん中が無視される 文章の配置を変えると結果が変わる
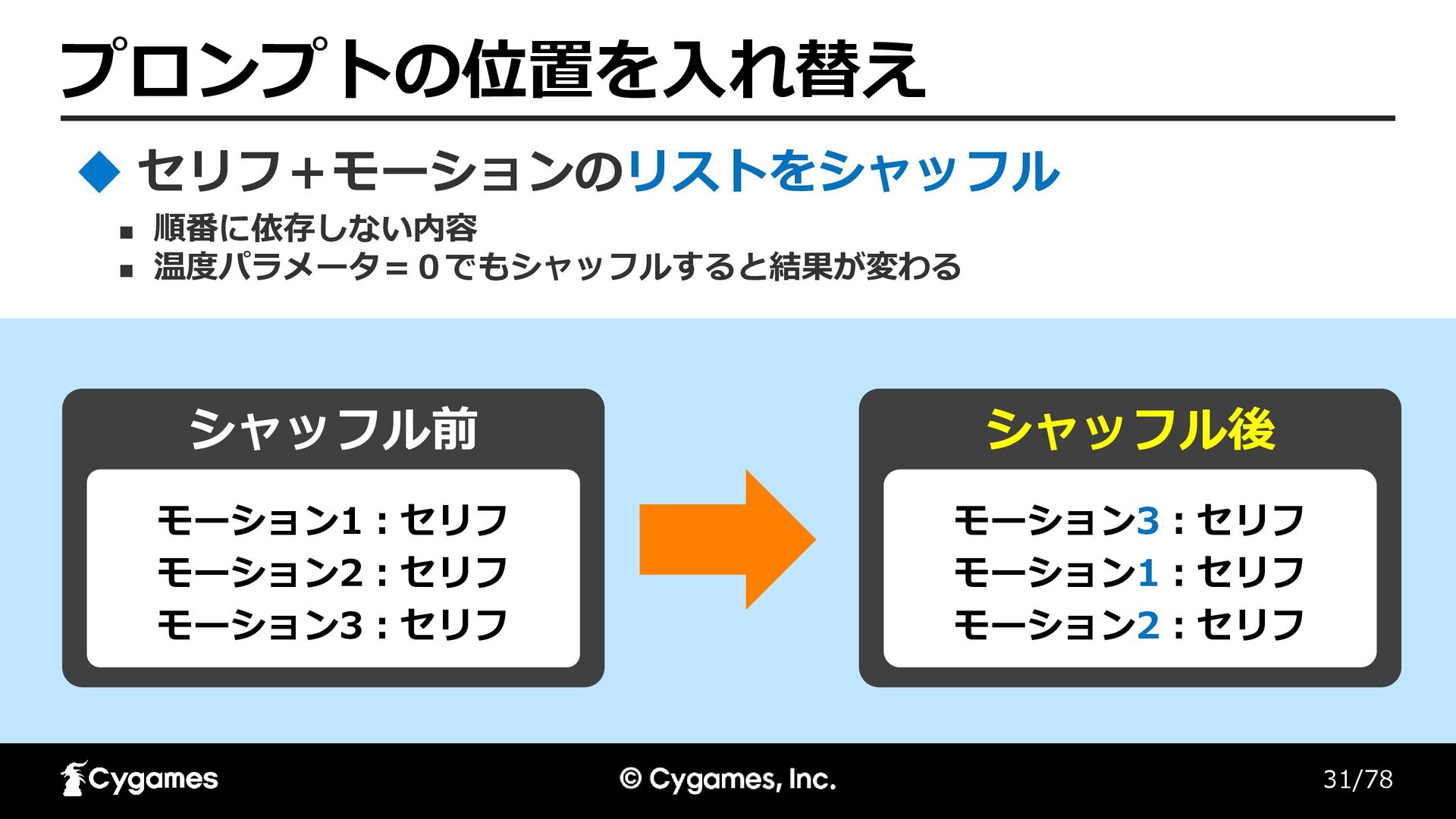
31/78 プロンプトの位置を入れ替え ◼ 順番に依存しない内容 ◼ 温度パラメータ=0でもシャッフルすると結果が変わる セリフ+モーションのリストをシャッフル シャッフル前 シャッフル後 モーション3:セリフ
モーション1:セリフ モーション2:セリフ モーション1:セリフ モーション2:セリフ モーション3:セリフ
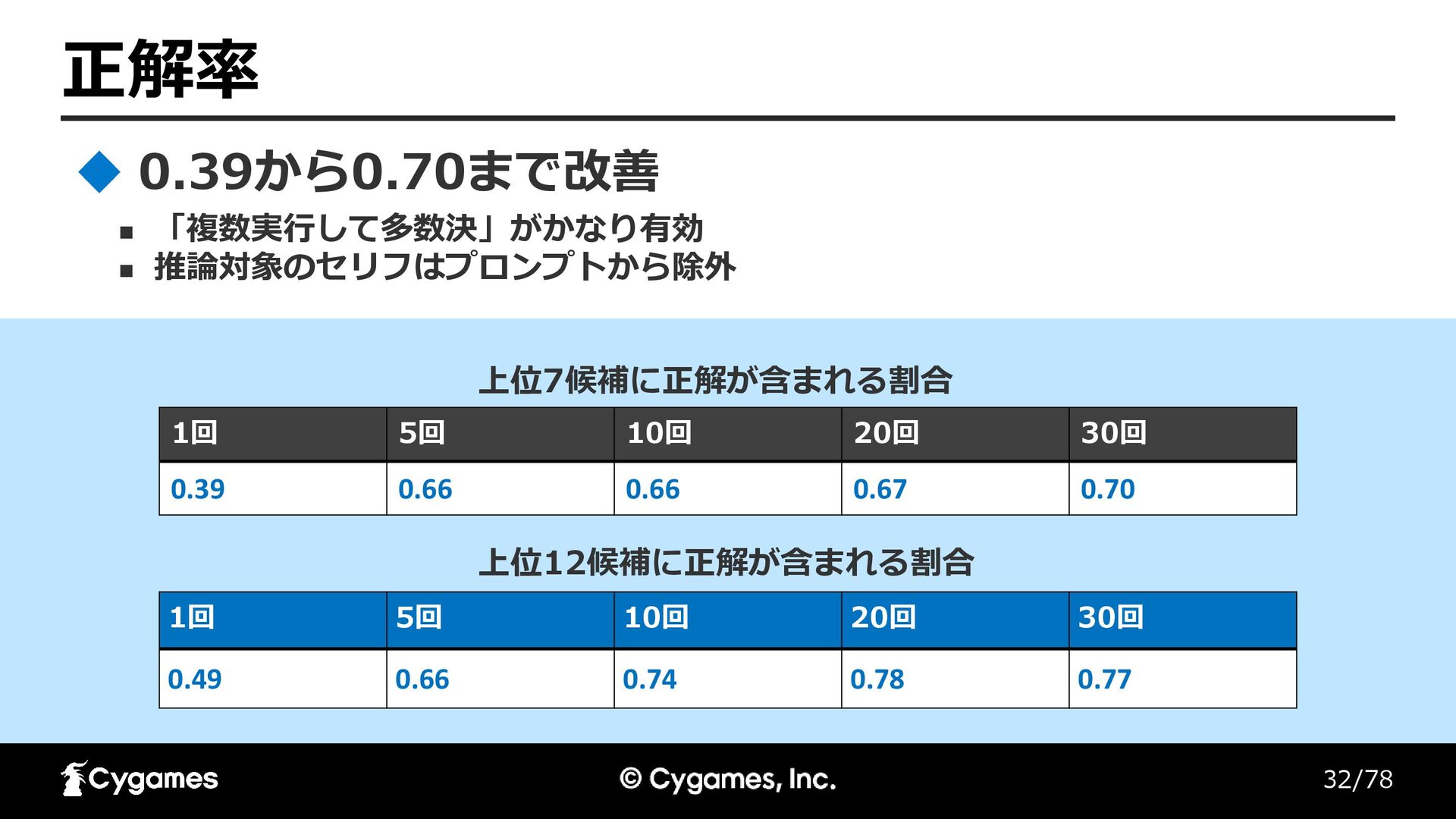
32/78 正解率 ◼ 「複数実行して多数決」がかなり有効 ◼ 推論対象のセリフはプロンプトから除外 0.39から0.70まで改善 1回 5回 10回
20回 30回 0.39 0.66 0.66 0.67 0.70 1回 5回 10回 20回 30回 0.49 0.66 0.74 0.78 0.77 上位12候補に正解が含まれる割合 上位7候補に正解が含まれる割合
33/78 最終的には10回実行して多数決 ◼ プロンプトに可能な限り判断材料を詰め込む(トークン数大) ◼ 30回呼びたかったが、実用面で10回に制限 実用上はAPIのコスト、レートリミットも考慮 x 10回 =
50回
34/78 関連論文 ◼ https://arxiv.org/pdf/2402.05120 More Agents Is All You Need
◼ https://arxiv.org/abs/2307.03172 Lost in the Middle: How Language Models Use Long Contexts ◼ https://arxiv.org/pdf/2404.11018 Many-Shot In-Context Learning
35/78 正解率を上げる手法のまとめ キャラクターごとに分けて実行 セリフとモーションの対応関係は可能な限り増やす 複数回実行して多数決
36/78 正解率をさらに上げるには? ◼ 長期運営の大型ゲームならLLMが知っている可能性が高い ◼ 「以下はゲーム(XXX)のシナリオです」 ◼ 対象作品を教えるとモデルの知識を使える 作品名をプロンプトに含める ◼
データが毎月増えるので反映したほうがよい ◼ 今回はUnityからのデータが取得が必要なので対応できず 運営タイプのゲームならデータを更新する ◼ モーションに対応するセリフのリストを要約して利用 ◼ surprise02 : 否定的なニュアンスで驚いたときに利用 セリフのリストを要約する
37/78 シナリオ執筆ツールへの組み込み
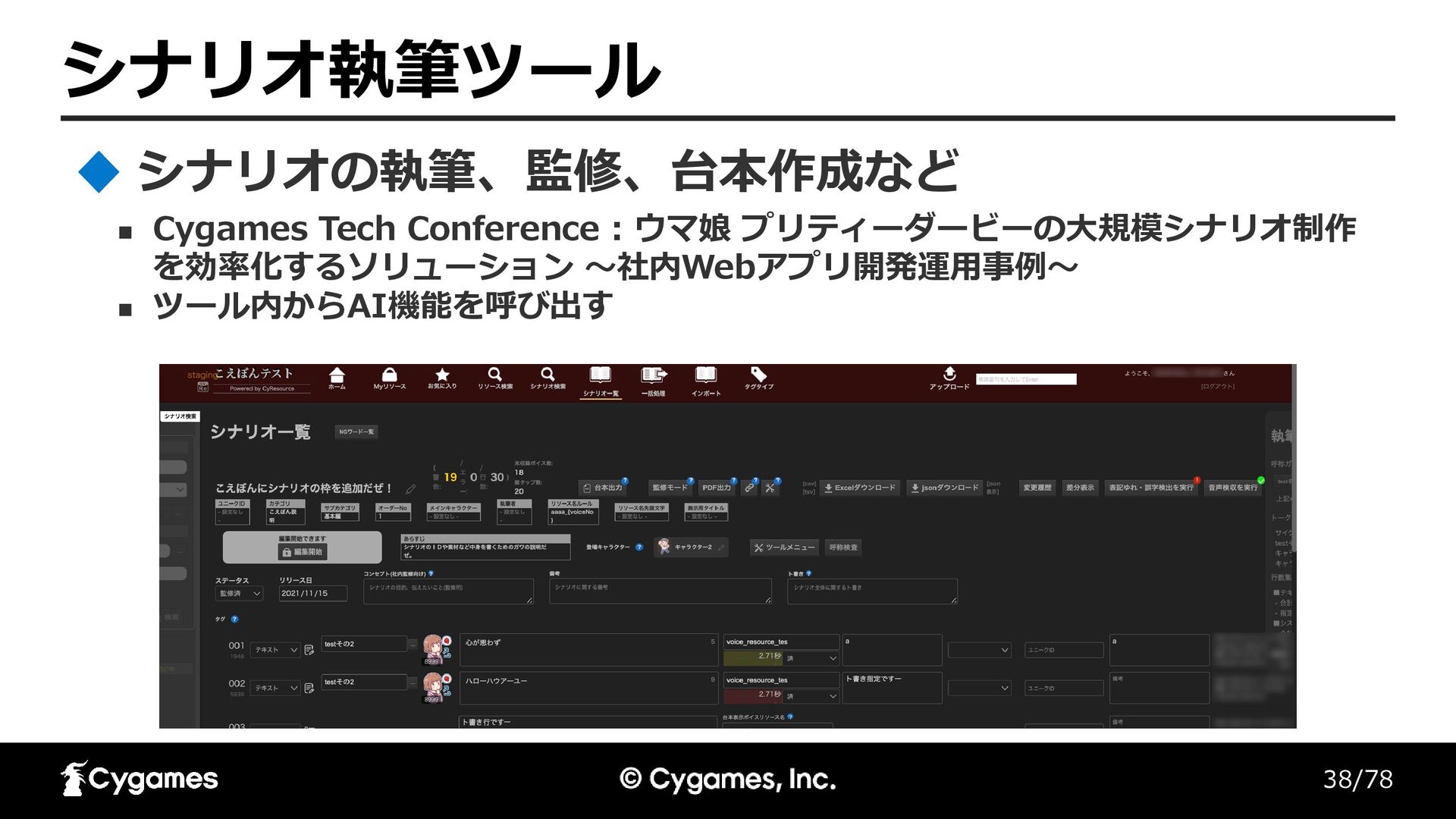
38/78 シナリオ執筆ツール ◼ Cygames Tech Conference : ウマ娘 プリティーダービーの大規模シナリオ制作 を効率化するソリューション
〜社内Webアプリ開発運用事例〜 ◼ ツール内からAI機能を呼び出す シナリオの執筆、監修、台本作成など
39/78 実装 シナリオ執筆ツールから呼び出すAPI ◼ Azure OpenAIのAPIを複数回呼び出して、結果を返す AWS Lambdaで実装
40/78 残った課題 ◼ Unityからのデータ取得に時間がかかる ◼ 毎月のキャラクター追加への追従ができない キャラクターの追加への対応が大変 ◼ 性能はよかったが…… ◼
キャラクターの追加に関しては、次のパートで対応例を紹介 利用頻度が低かった
41/78 AIでシナリオに対応する 表情差分を求める
42/78 会話パートのスクリプト作成を効率化したい ◼ 2023年に開発し、PJへ提供済み ◼ 評判がよく、現役で使われている ◼ CEDEC2023 : AIによる自然言語処理・音声解析を用いたゲーム内会話
パートの感情分析への取り組み ゲーム内会話パートのスクリプト作成の効率化 ◼ 話が来た理由はわかるが…… 同じように別プロジェクトでも効率化したい ◼ ほぼ新規での開発 ◼ AIは新しいものが使える ゲームのスクリプトはPJによって完全に違う
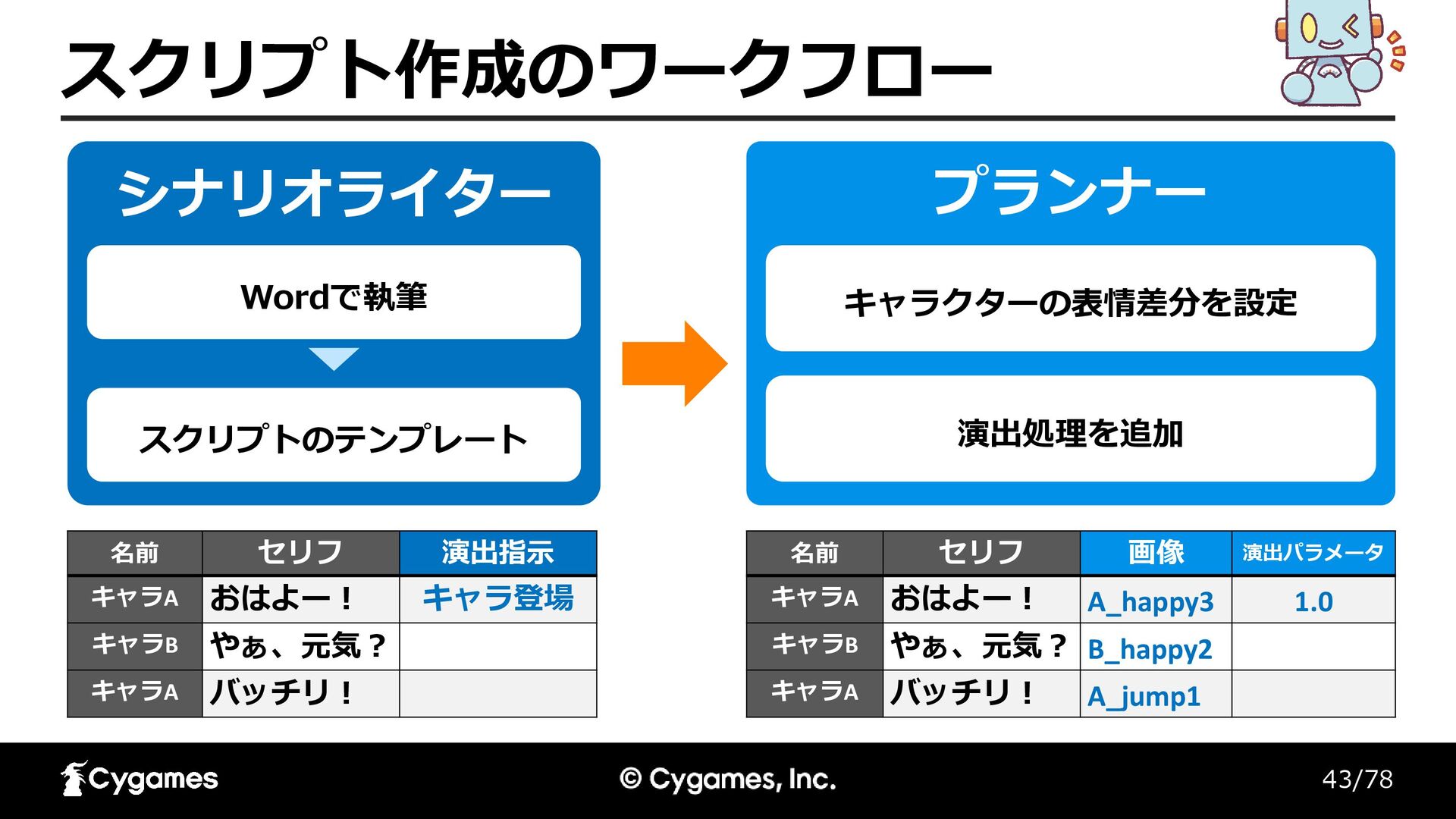
43/78 スクリプト作成のワークフロー シナリオライター Wordで執筆 スクリプトのテンプレート プランナー キャラクターの表情差分を設定 演出処理を追加 名前 セリフ
演出指示 キャラA おはよー! キャラ登場 キャラB やぁ、元気? キャラA バッチリ! 名前 セリフ 画像 演出パラメータ キャラA おはよー! A_happy3 1.0 キャラB やぁ、元気? B_happy2 キャラA バッチリ! A_jump1
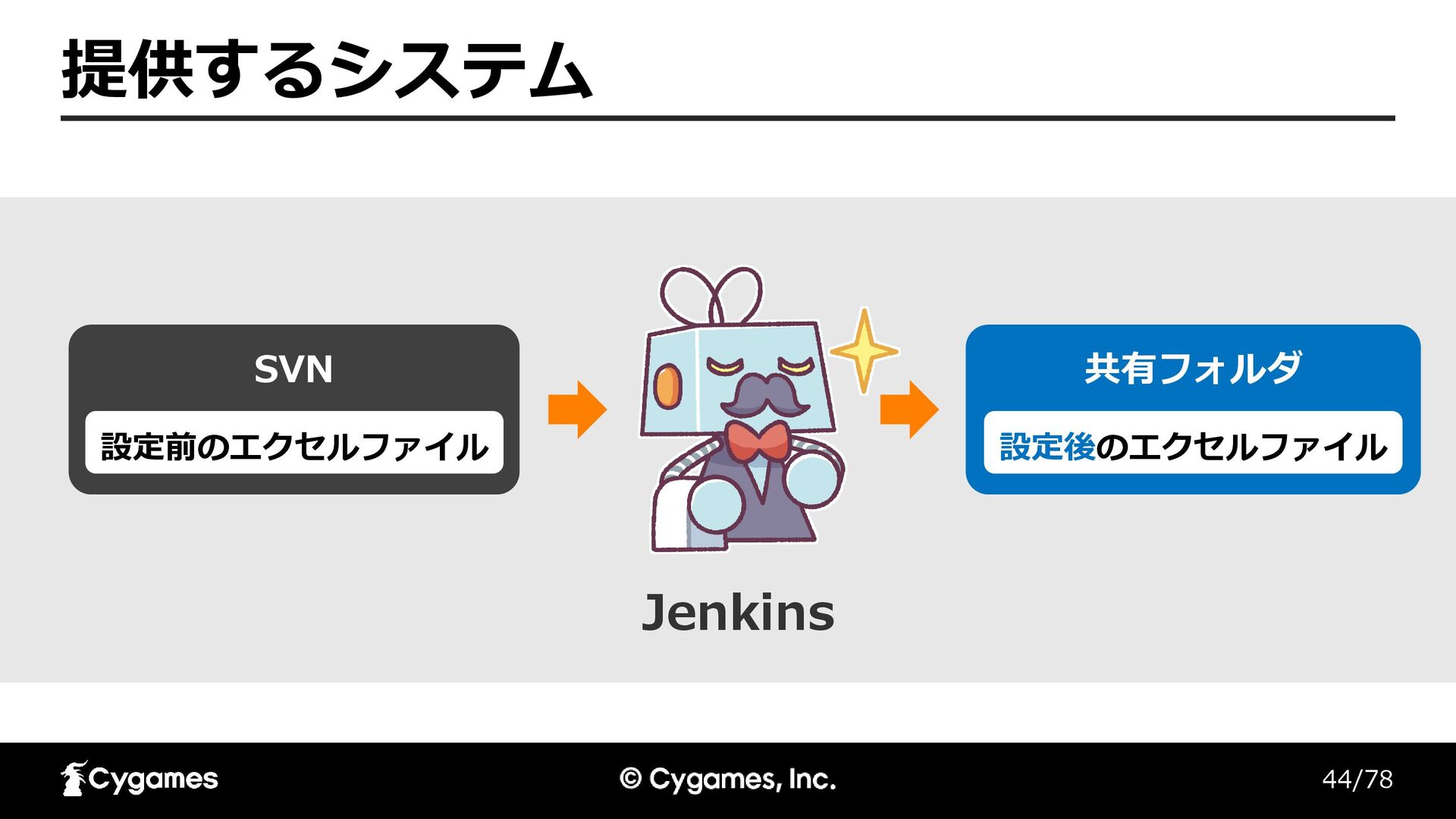
44/78 提供するシステム SVN 設定前のエクセルファイル 共有フォルダ 設定後のエクセルファイル Jenkins
45/78 キャラクターの表情差分をAIで求める 準備編
46/78 キャラクターは複数の衣装を持つ デフォルト スーツ 正月 ファイル名 説明 normal01 通常 normal02
通常(目閉じ) angry01 怒り ファイル名 説明 normal01 通常 angry01 怒り angry02 怒り(目閉じ) ファイル名 説明 normal 通常 happy 喜び
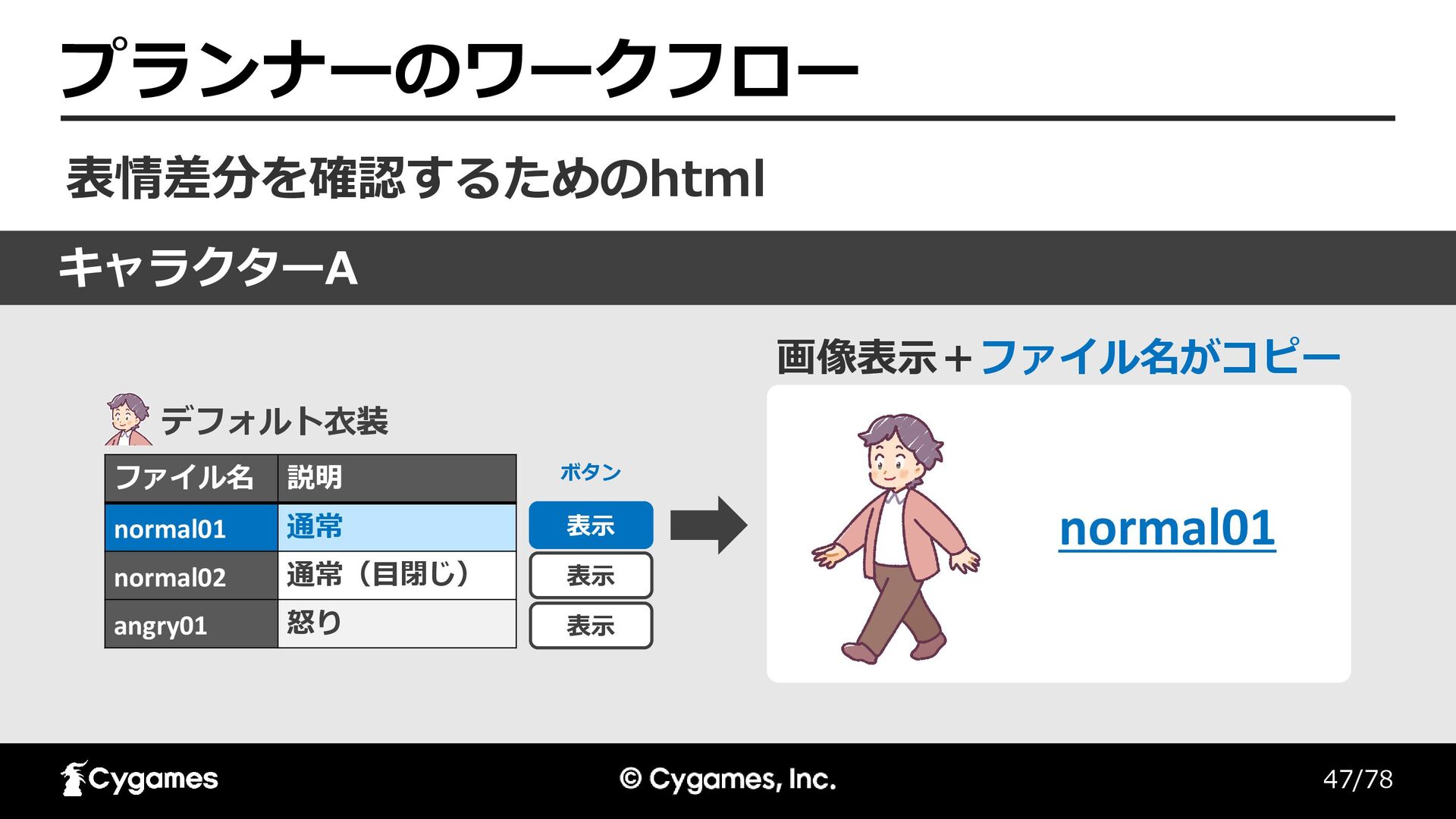
47/78 プランナーのワークフロー 表情差分を確認するためのhtml 表示 表示 表示 ファイル名 説明 normal01 通常
normal02 通常(目閉じ) angry01 怒り 画像表示+ファイル名がコピー キャラクターA デフォルト衣装 normal01 ボタン
48/78 マスターデータがない! ◼ ゲーム中のキャラクターリスト ◼ キャラクターごとの衣装リスト ◼ 衣装ごとの表情差分のリスト 自動化のために欲しいデータ ◼
長いPJなので途中からのデータしか整理されていない ◼ 困った…… マスターデータがなかった ◼ 全部のキャラクターの衣装と表情差分が入っている ◼ イベントごとに確実に更新される 作業用のhtmlをマスターデータとして扱う!
49/78 問題は残っている ◼ htmlはイベントごとにプランナーが追記 ◼ 微妙に書式が違う! ◼ AIで扱うには大きい(50万行以上、毎月数回更新) 最大の問題は「手打ち」 ◼
エンジニア:正規表現で頑張って書式の違いを吸収 ◼ プランナー:書式が違う部分を修正、扱いやすいように記号を追加 お互いが頑張って解決 ◼ パースが失敗するごとにデバッグして対応 ◼ 全体の2割の工数を消費 数ヶ月かかって完全にパースできるように
50/78 衣装の指定は? ◼ 「XXX衣装で」「ここまで」など 従来はシナリオライターがテキストで指示 ◼ プランナーが衣装設定をエクセル上で行ってからAIで処理 衣装設定のためのワークフローを変更 1. エクセルで衣装設定ツールを実行
2. htmlから変換したJSONを読み込む 3. キャラクターごとの衣装がエクセル上で選べるようになる 新しいワークフロー
51/78 コラボへの対応も必要 ◼ 同名のキャラクターが存在する! ◼ 表示するキャラクター名に作品名は入っていない 運営型のゲームでは他作品とのコラボ ◼ htmlのブロックごとに「コラボ」と書いてある ◼
今回はコラボキャラクターは自動設定の対象外とした htmlファイルから識別可能 プロジェクト キャラ名:XXX コラボ先1 キャラ名:XXX コラボ先2 キャラ名:XXX
52/78 キャラクターの表情差分をAIで求める 実装編
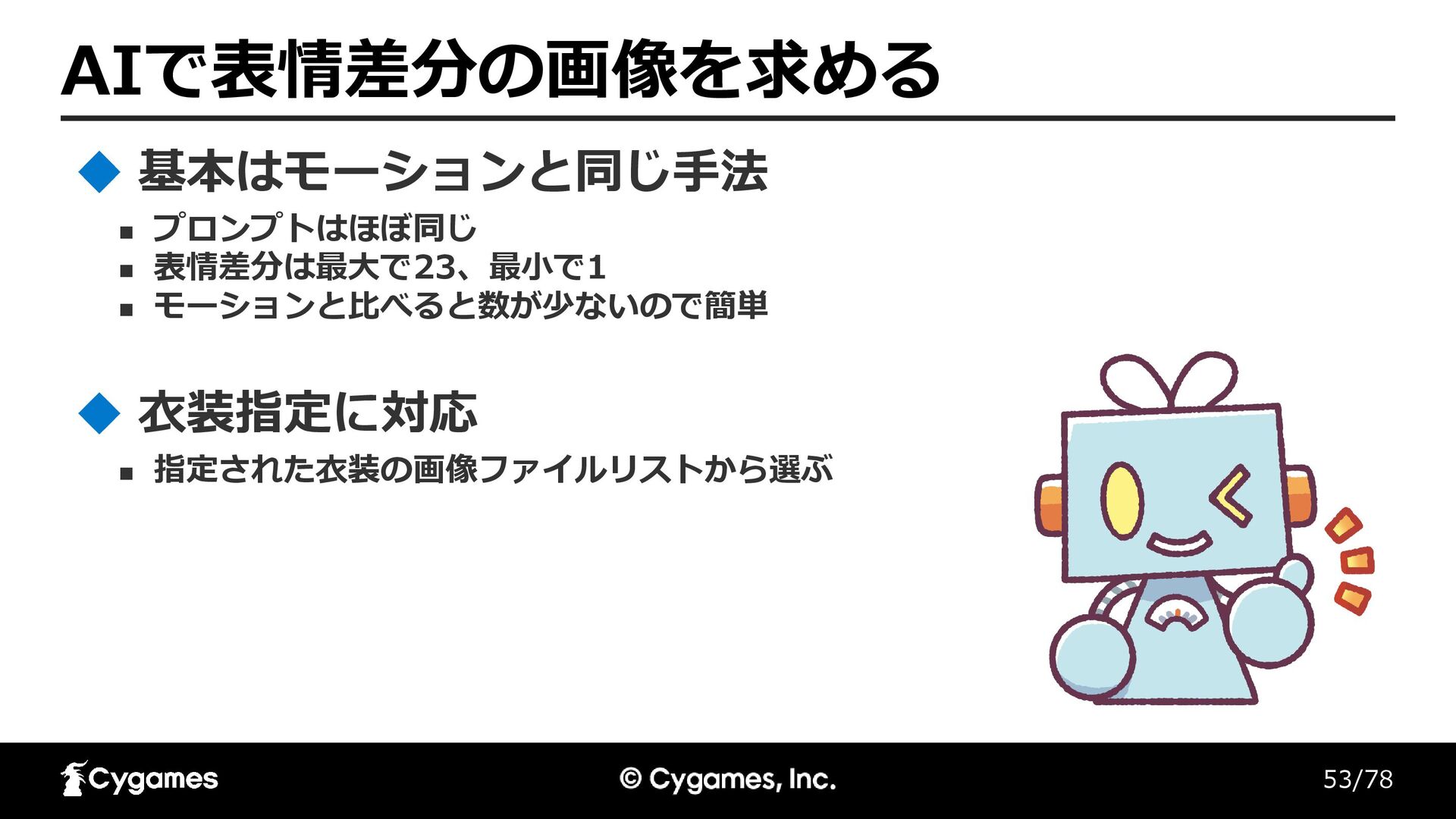
53/78 AIで表情差分の画像を求める ◼ プロンプトはほぼ同じ ◼ 表情差分は最大で23、最小で1 ◼ モーションと比べると数が少ないので簡単 基本はモーションと同じ手法 ◼
指定された衣装の画像ファイルリストから選ぶ 衣装指定に対応
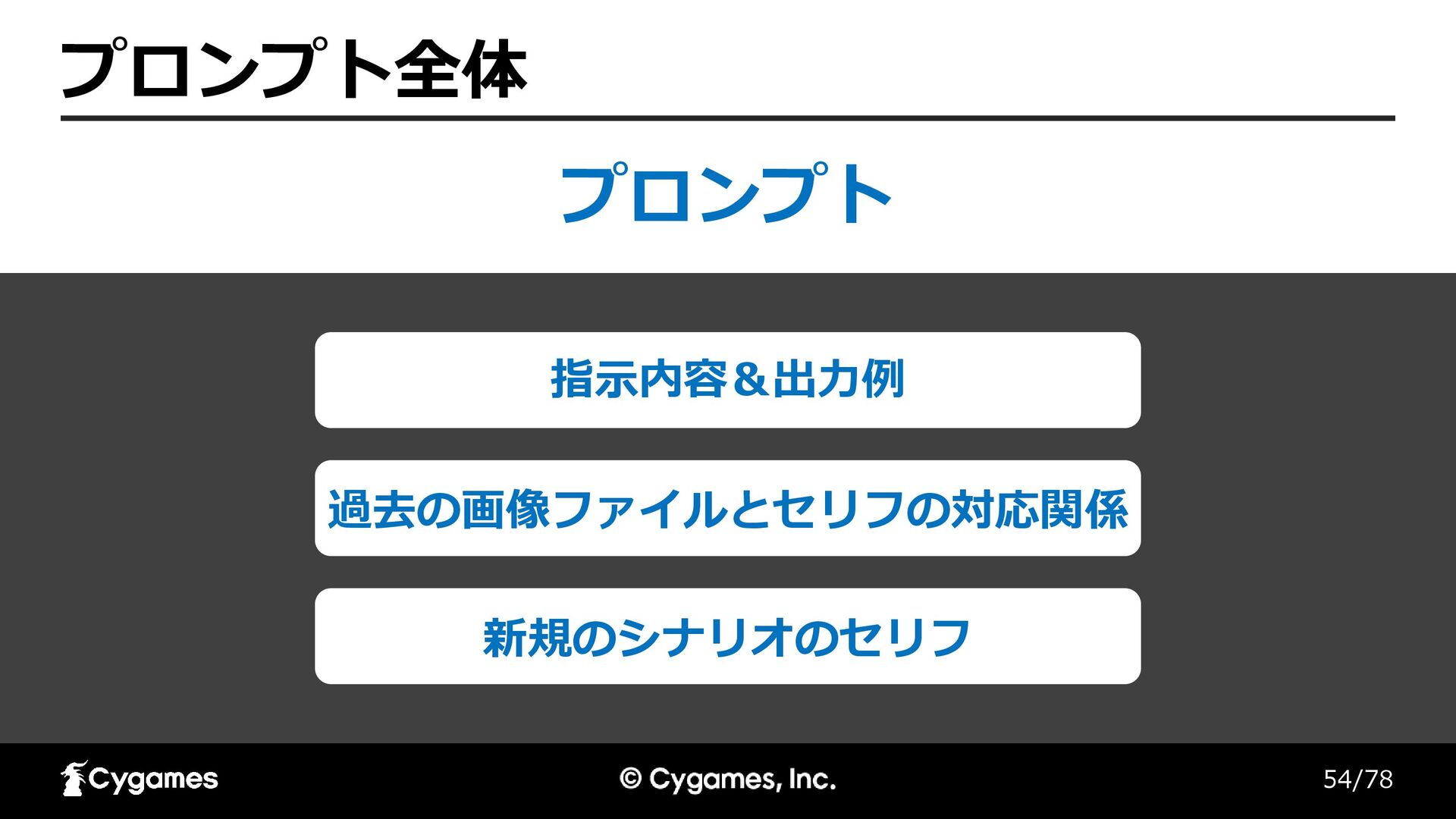
54/78 プロンプト全体 過去の画像ファイルとセリフの対応関係 新規のシナリオのセリフ 指示内容&出力例 プロンプト
55/78 指示内容&出力例 最初の部分はゲームキャラクターの「キャラA」の「画像ファイル名 : セリフ のリスト」の対応関係です。後半の内容は「行番号 | キャラクター名 : セリ
フ」です。後半の部分のセリフの行ごとに最適な「画像ファイル」を5つ程度選 んでJSON形式で出力してください。出力は「キャラA」のセリフの行ごとに 「行番号 : 画像ファイル名のリスト」を出力してください。「キャラA」以外 のセリフは出力しないでください。以下は出力の例です。 === "1" : [”10000001_sad.png", " 10000001_angry.png", …], "2" : ["10000003_happy.png", "10000003_laugh.png", …], "3" : ["10000008.png", " 10000008_jump.png", …], ...
56/78 画像ファイル名 : セリフのリスト === 10000001_sad.png : 「頑張るよ…」「そんな…」 「泣かない…もう」 10000001_happy.png
: 「わぁい!」「えへへ、嬉しい!」「最高!」 10000001_eyeclose.png : 「ふふ…秘密だよ」「考え中…ねぇ」 ...
57/78 新規のシナリオ === 1 : キャラA : おはよう! 2 :
キャラB : やほー、元気? 3 : キャラA : うん、最高! 4 : キャラB : 今日もがんばろ 5 : キャラA : 一緒なら楽しい! ===
58/78 多数決で求める ◼ 実装はモーションと同じ モーションと同じく多数決で正解率を上げる ◼ 過去のセリフが少ないキャラクターは1回で十分 キャラクター数が多い場合に対応 x 10回
= 100回 10人の場合 ……
59/78 正解率 ◼ 完全一致 : 0.46 ◼ 上位3候補 : 0.65
◼ 上位10候補 : 0.78 10回の多数決 ◼ 表情差分は最大23だが大半は6程度 ◼ 外れていても近いものが選ばれる 選択肢が少ないので正解しやすい
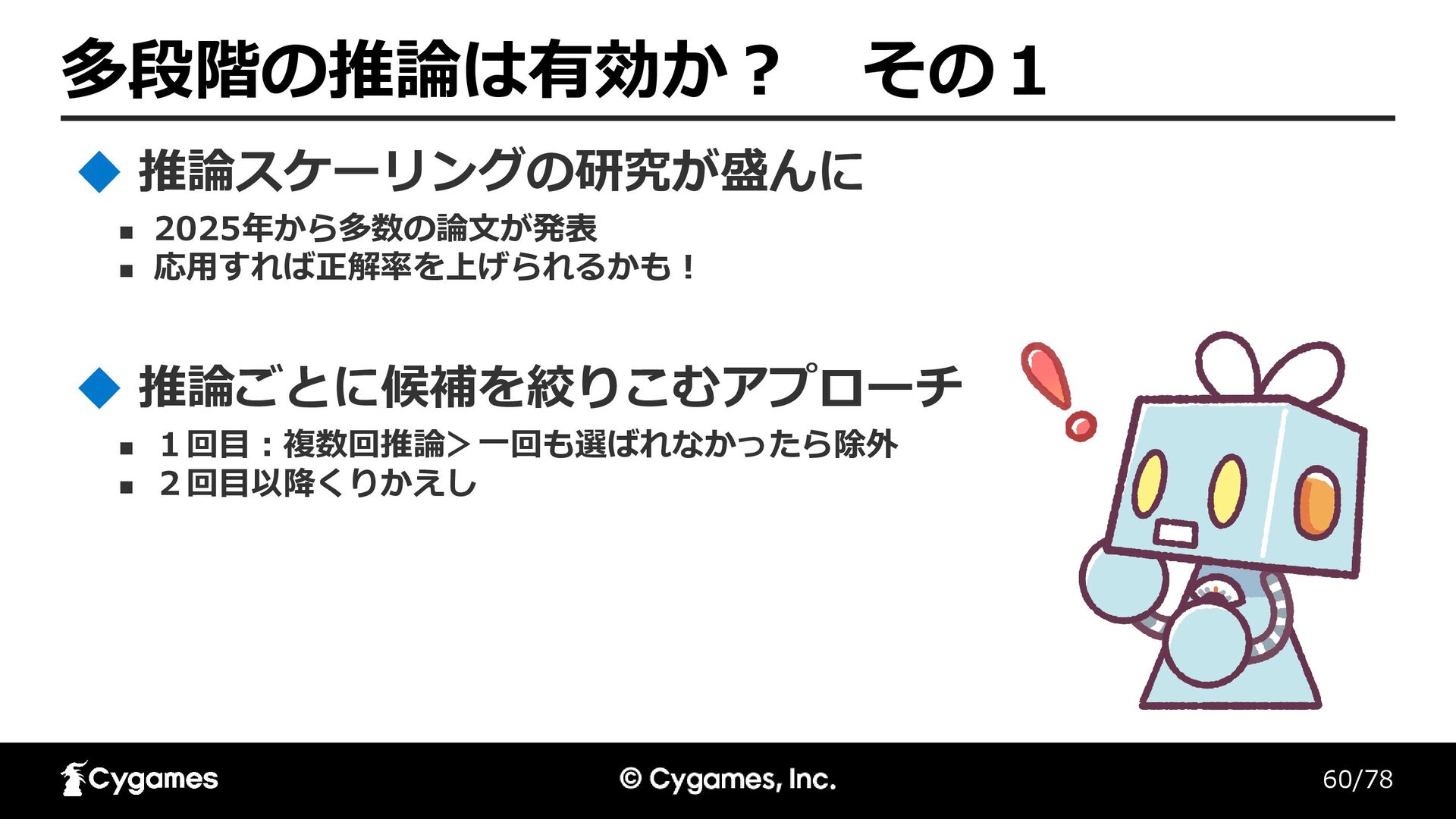
60/78 多段階の推論は有効か? その1 ◼ 2025年から多数の論文が発表 ◼ 応用すれば正解率を上げられるかも! 推論スケーリングの研究が盛んに ◼ 1回目:複数回推論>一回も選ばれなかったら除外
◼ 2回目以降くりかえし 推論ごとに候補を絞りこむアプローチ
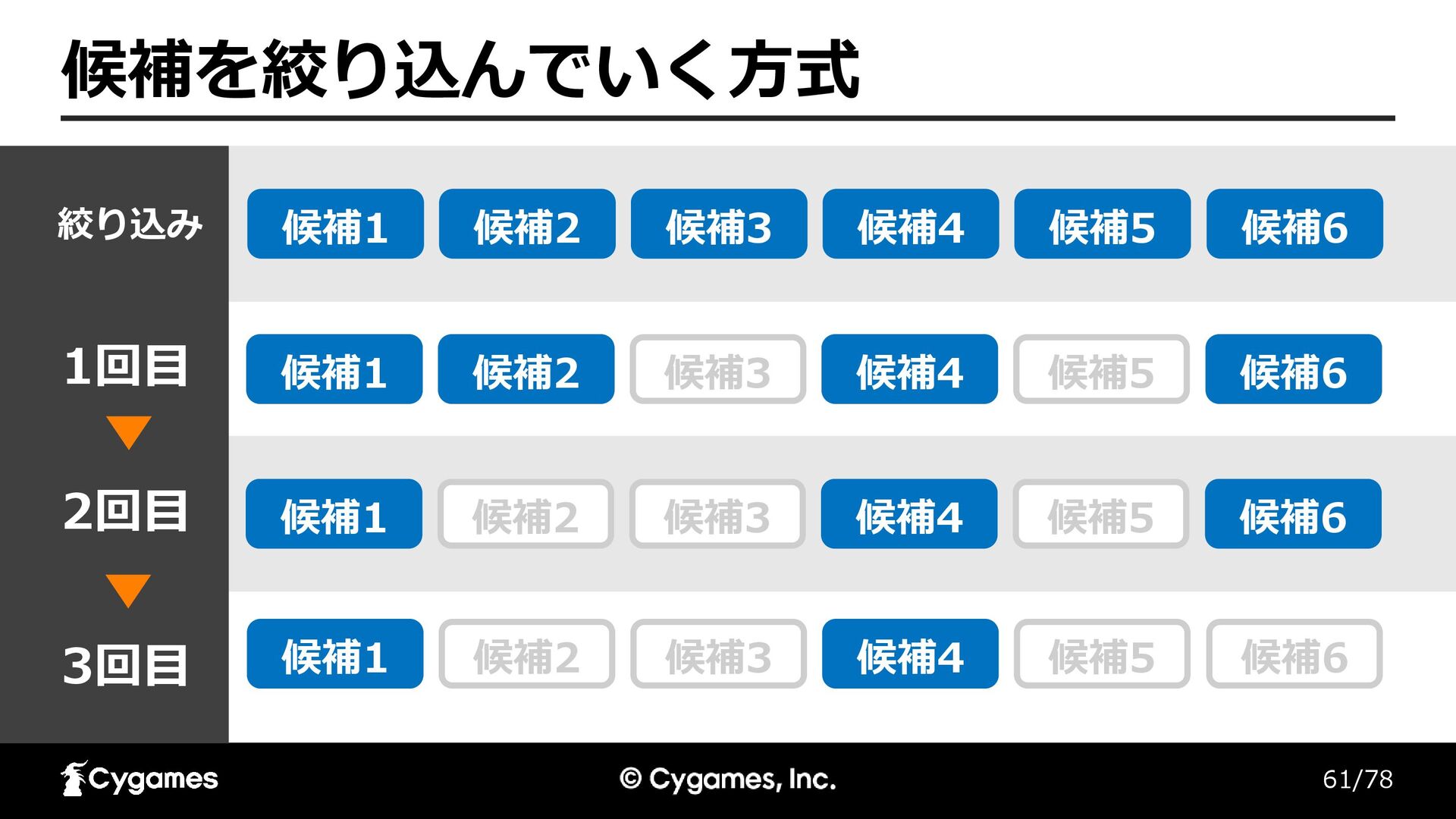
61/78 候補を絞り込んでいく方式 候補1 候補2 候補3 候補4 候補5 候補6 候補1 候補2
候補3 候補4 候補5 候補6 候補1 候補2 候補3 候補4 候補5 候補6 候補1 候補2 候補3 候補4 候補5 候補6 2回目 3回目 絞り込み 1回目
62/78 多段階の推論は有効か? その2 ◼ 正解率が1〜2%向上 ◼ ソースコードの管理の手間とAPIのコストを考えて不採用 1回目の結果を2回目にヒントとして与える === 1
: キャラA : おはよう!: 10000001_sad.png 2 : キャラB : やほー、元気? 3 : キャラA : うん、最高!: 10000008_jump.png ... 前回選ばれたもの
63/78 推論モデルは有効か? ◼ GPT-4oより正解率は高いが時間がかかりすぎる ◼ キャラクター分呼び出すのは現実的ではない ◼ 全員分まとめるとコンテキストが長くなりすぎる OpenAIのo1モデルで実験 ◼
今回のタスクはじっくり考えるほど難しくない ◼ GPT-4o-miniを100回呼んだ方がよい可能性も 推論モデルを使うほど難しくない
64/78 新規のキャラクターへの推論 ◼ ファイル名からある程度の判別は可能 ◼ angry01, angry02などの連番の区別はできない 新規追加のキャラクターは過去のセリフがない 最初の部分はゲームキャラクターの「キャラA」の 「画像ファイル名
| 画像ファイルの説明テキスト」の対応関係です。 … === 10000001_laugh.png : 楽しい、笑っている表情 10000001_serious.png : 真面目、シリアスな場面での表情 10000001_jito.png : 呆れ、軽蔑の表情
65/78 ゲームの更新への対応まとめ ◼ 画像ファイル名を使った簡易版で推論 新規キャラクターへの対応 ◼ 画像確認のhtmlの更新のたびに、エクセルの衣装設定ツールへ反映 ◼ 過去セリフはないので、新規キャラクター扱いで推論 衣装追加への対応
◼ 数ヶ月に一度の更新 ◼ ある程度セリフがないと動作しないため 表情差分とセリフの対応関係の更新
66/78 AI以外の部分
67/78 演出の処理も追加 ◼ 「場面転換」「選択肢」などの演出指示が入っている ◼ 指示に応じて「セルを埋める+行の追加」 ◼ AIではなくプログラムで対応 エクセルには演出の処理も含まれる 名前
セリフ 演出指示 キャラA おはよー! キャラ登場 キャラB やぁ、元気? キャラA バッチリ! 名前 セリフ 演出内容 演出パラメータ キャラA おはよー! 登場演出 1.0 キャラB やぁ、元気? キャラA バッチリ! 演出指示に合わせて各種設定を行う
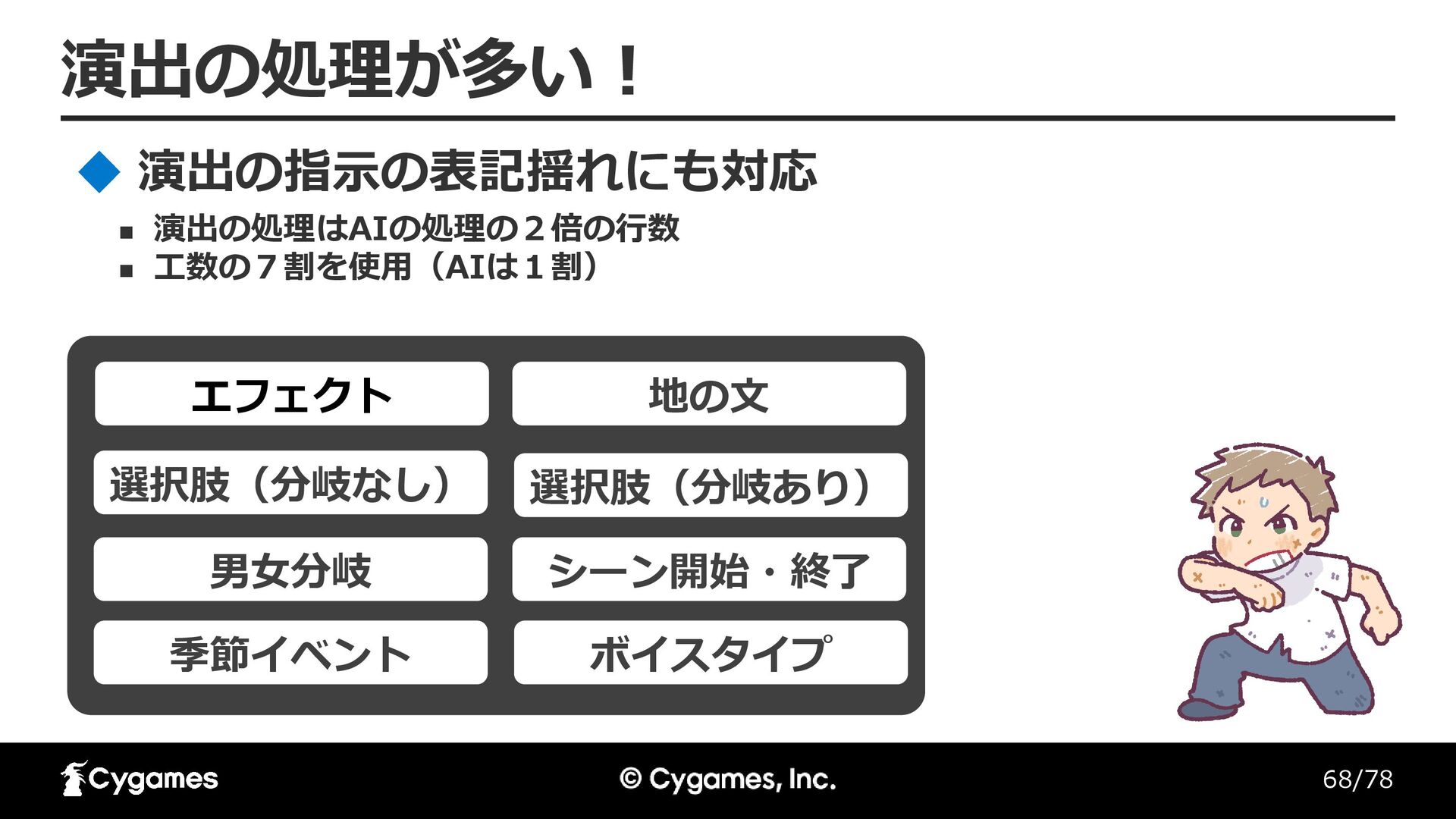
68/78 演出の処理が多い! エフェクト 地の文 選択肢(分岐あり) 選択肢(分岐なし) シーン開始・終了 男女分岐 ボイスタイプ 季節イベント
◼ 演出の処理はAIの処理の2倍の行数 ◼ 工数の7割を使用(AIは1割) 演出の指示の表記揺れにも対応
69/78 効率化できたのか?
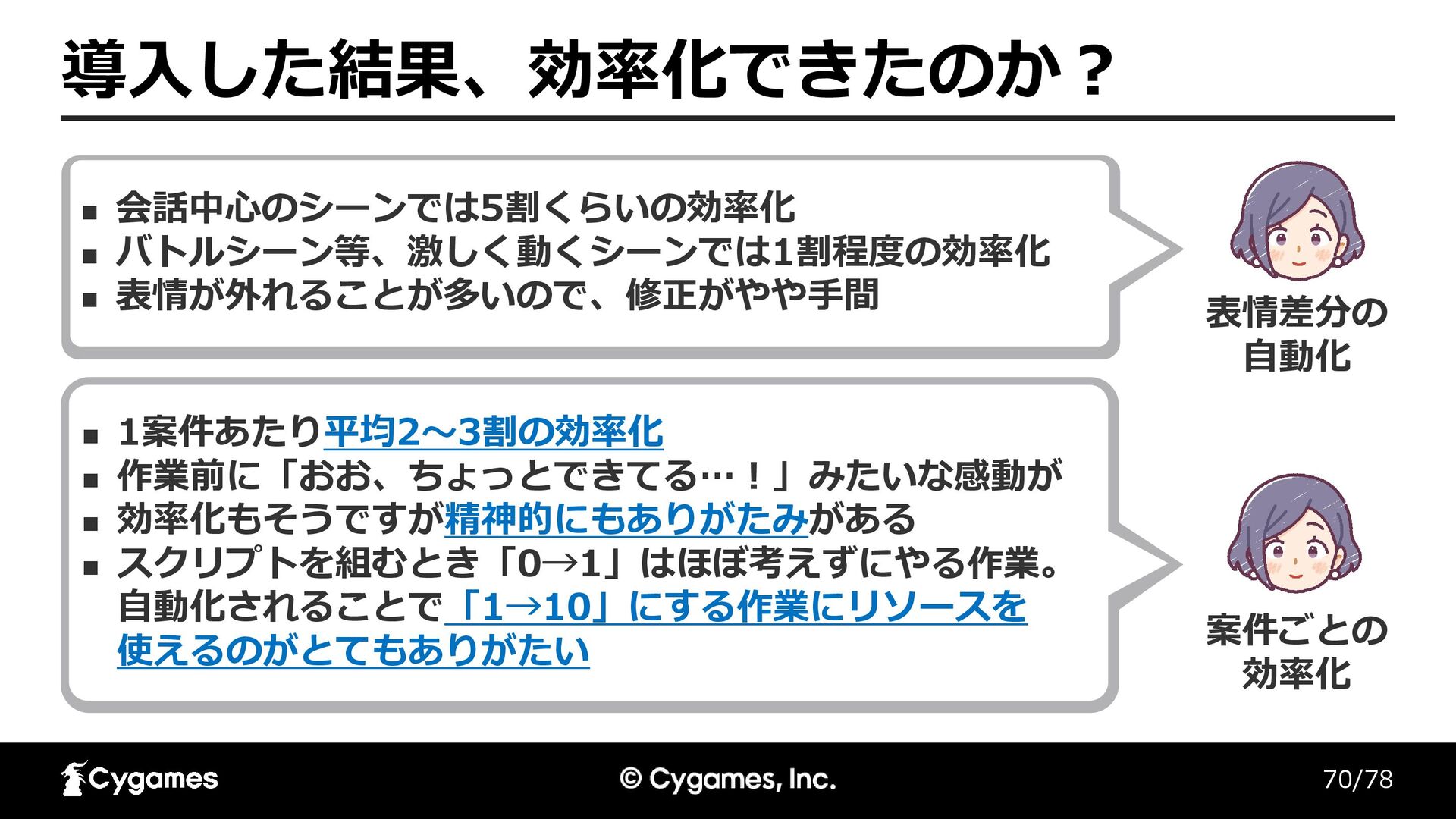
70/78 導入した結果、効率化できたのか? ◼ 会話中心のシーンでは5割くらいの効率化 ◼ バトルシーン等、激しく動くシーンでは1割程度の効率化 ◼ 表情が外れることが多いので、修正がやや手間 ◼ 1案件あたり平均2〜3割の効率化
◼ 作業前に「おお、ちょっとできてる…!」みたいな感動が ◼ 効率化もそうですが精神的にもありがたみがある ◼ スクリプトを組むとき「0→1」はほぼ考えずにやる作業。 自動化されることで「1→10」にする作業にリソースを 使えるのがとてもありがたい 表情差分の 自動化 案件ごとの 効率化
71/78 PJのワークフローを効率化するとどうなる? ◼ 今までは手動でやっていたのでツールなしでも大丈夫……ではない ◼ 業務に欠かせないほど便利なツールになった 浮いた工数はゲームの改善に ◼ マクロ入りエクセルファイルの操作が厳しい! ◼
予備のJenkinsを用意 JenkinsをAWSへ移行できないか? ◼ 休みのときに対応できるように ◼ 作業シェア、ドキュメント、環境の整備 サポート担当を三人に
72/78 従来手法と今回の手法の比較 パートボイスの場合
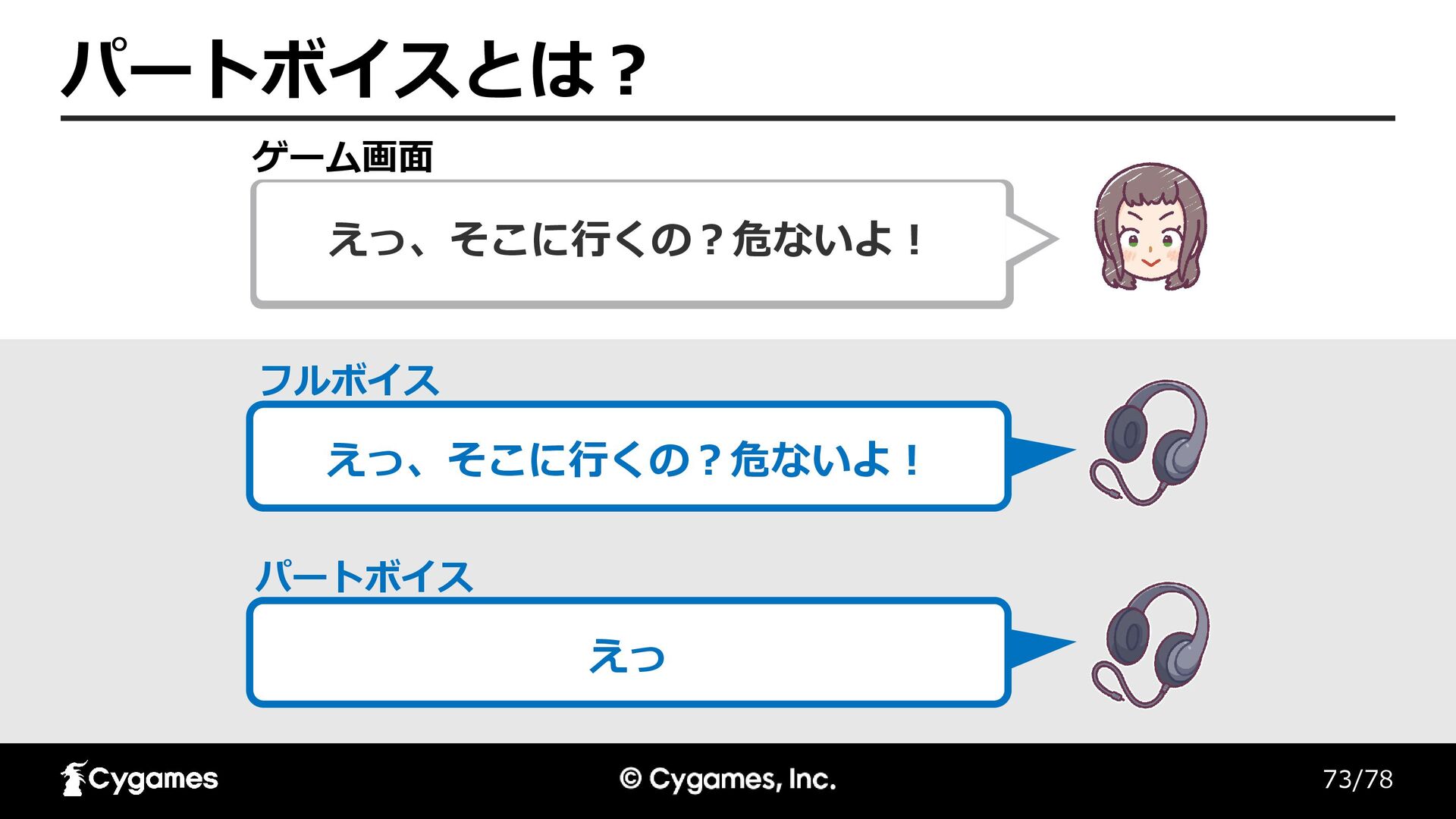
73/78 パートボイスとは? えっ、そこに行くの?危ないよ! フルボイス パートボイス えっ、そこに行くの?危ないよ! ゲーム画面 えっ
74/78 AIでパートボイスを求めたい ◼ セリフから125種類のパートボイスを選ぶ ◼ キャラクターごとにパートボイスは異なる セリフに対応するパートボイスを自動で選びたい ◼ RoBERTaでのファインチューニング ◼
CEDEC2023 : AIによる自然言語処理・音声解析を用いたゲーム内会話 パートの感情分析への取り組み 2023年の実装 ◼ 今回の手法との性能差が気になったため GPT-4で再実装して比較
75/78 RoBERTa vs GPT-4o モデル 完全一致 上位20 RoBERTaをファインチューニング 0.35 0.82
GPT-4oで30回の多数決 0.15 0.64 ◼ 学習データが多いのが原因か? ◼ ファインチューニングが手間 RoBERTaのほうが正解率が高い ◼ 学習が必要ない ◼ 新しいモデルへの置き換えで正解率が上がる 今回の手法
76/78 まとめ
77/78 まとめ ◼ モーション ◼ キャラクターの表情差分 ◼ パートボイス シナリオから3つの要素を自動設定 ◼
複数回推論+多数決で正解率向上 推論スケーリングは有効 ◼ 毎月のキャラクター・衣装の追加に対応する仕組み 運用プロジェクトへの対応
78/78
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![21/78 プロンプトの例(2) モーションとセリフの対応関係 以下はモーションとセリフのリストです === walk01 : [行くよ!, どこかな?, いい天気〜]](https://files.speakerdeck.com/presentations/97edd6a5bc9440d8b6023aae3dbcfb4d/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}