Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ペアーズにおけるAIエージェント 基盤とText to SQLツールの紹介
Search
Hikaru Sasamoto
December 20, 2025
Technology
2
2k
ペアーズにおけるAIエージェント 基盤とText to SQLツールの紹介
2025.12.20 JAWS-UG AI Builders DAY
Hikaru Sasamoto
December 20, 2025
Tweet
Share
More Decks by Hikaru Sasamoto
See All by Hikaru Sasamoto
ペアーズにおけるData Catalog導入の取り組み
hisamouna
1
440
クラウドネイティブなバッチ基盤の品質を再定義し、治安を取り戻した話
hisamouna
1
640
数百以上の様々なバッチが動いているバッチ基盤をECS on FargateからEKS on EC2へ移行した話
hisamouna
3
1.4k
Other Decks in Technology
See All in Technology
Next.js 16の新機能 Cache Components について
sutetotanuki
0
210
AWS re:Inventre:cap ~AmazonNova 2 Omniのワークショップを体験してきた~
nrinetcom
PRO
0
120
コールドスタンバイ構成でCDは可能か
hiramax
0
130
小さく、早く、可能性を多産する。生成AIプロジェクト / prAIrie-dog
visional_engineering_and_design
0
310
AIと融ける人間の冒険
pujisi
0
110
Bill One 開発エンジニア 紹介資料
sansan33
PRO
4
17k
ハッカソンから社内プロダクトへ AIエージェント ko☆shi 開発で学んだ4つの重要要素
leveragestech
0
520
松尾研LLM講座2025 応用編Day3「軽量化」 講義資料
aratako
15
4.8k
投資戦略を量産せよ 2 - マケデコセミナー(2025/12/26)
gamella
0
580
複雑さを受け入れるか、拒むか? - 事業成長とともに育ったモノリスを前に私が考えたこと #RSGT2026
murabayashi
0
860
国井さんにPurview の話を聞く会
sophiakunii
1
270
BidiAgent と Nova 2 Sonic から考える音声 AI について
yama3133
2
140
Featured
See All Featured
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.3k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
0
1.1k
The agentic SEO stack - context over prompts
schlessera
0
580
Practical Orchestrator
shlominoach
190
11k
The Myth of the Modular Monolith - Day 2 Keynote - Rails World 2024
eileencodes
26
3.3k
Optimizing for Happiness
mojombo
379
70k
The Illustrated Guide to Node.js - THAT Conference 2024
reverentgeek
0
220
Product Roadmaps are Hard
iamctodd
PRO
55
12k
The Invisible Side of Design
smashingmag
302
51k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
65
35k
Documentation Writing (for coders)
carmenintech
77
5.2k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
2
3.8k
Transcript
ペアーズにおけるAIエージェント 基盤とText to SQLツールの紹介 2025年12⽉20⽇ AI Builders Day
About Me Nari | Takashi Narikawa(@fukubaka0825) • 株式会社エウレカ ◦ 2020年に⼊社
▪ SRE Team -> AI Team ssmt | Hikaru Sasamoto(@hisamouna34) • 株式会社エウレカ ◦ 2022年に⼊社 ▪ SRE & Data Platform Team
出典:MMD研究所「2025年マッチングサービス・アプリの利用実態調査」 2025年9月時点。交際率においては利用上位5サービス・アプリが対象。 No. 1 恋活・婚活 マッチングアプリ 利 用 率 交
際 率
1. AIエージェントおよびLLMOps基盤の設計と運⽤体制について紹介 2. 具体的な活⽤事例として社内向けText to SQLツールを紹介 a. 背景 / 課題
b. Text to SQL Workflow の紹介 c. AWS サービスを使うことで実現できたこと d. 品質を継続的に評価‧改善する仕組み e. Text to SQL によるチーム別課題への貢献 f. 今後の展望 3. まとめ Agenda
①AIエージェントおよび LLMOps基盤の 設計と運用体制について紹介
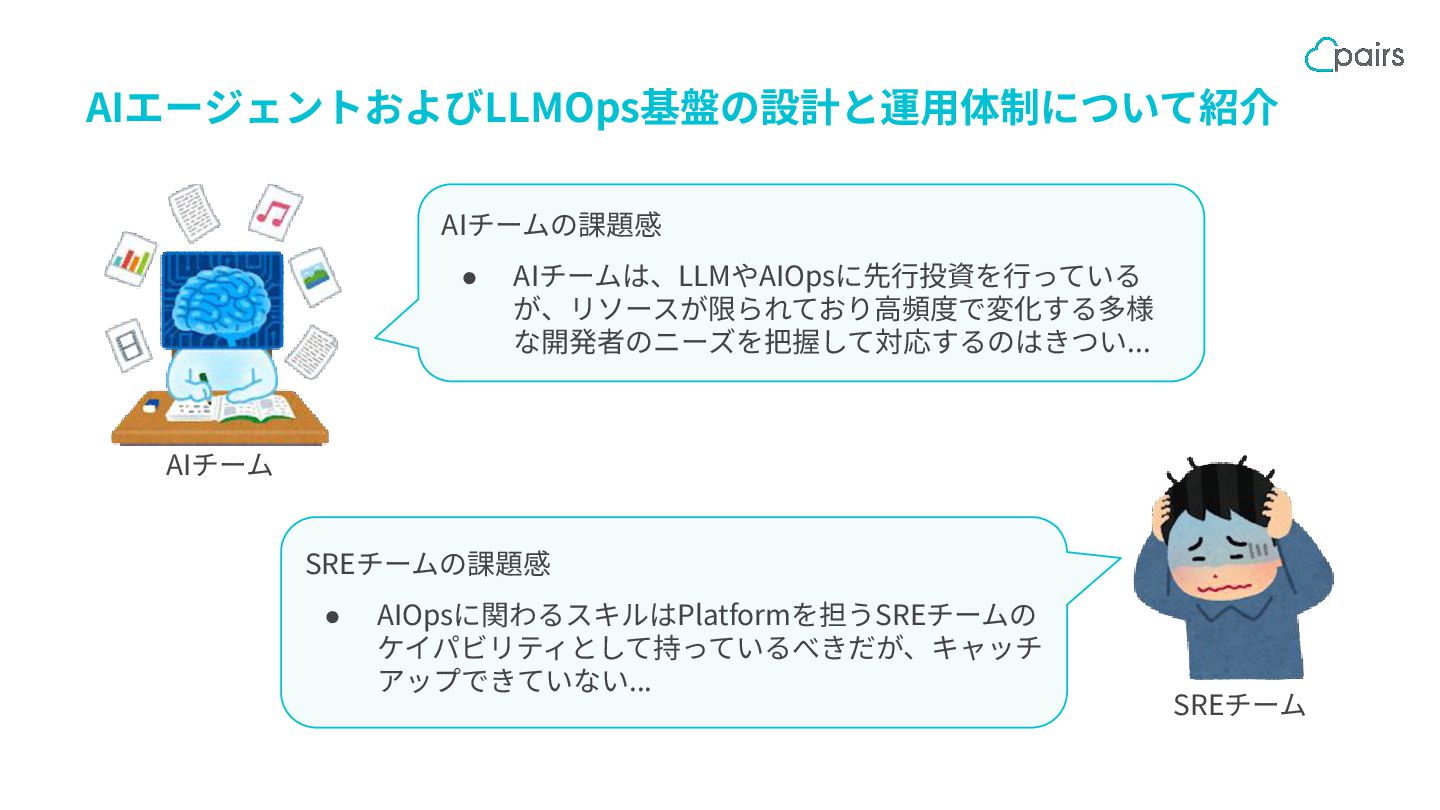
AIエージェントおよびLLMOps基盤の設計と運⽤体制について紹介 SREチームの課題感 • AIOpsに関わるスキルはPlatformを担うSREチームの ケイパビリティとして持っているべきだが、キャッチ アップできていない... AIチームの課題感 • AIチームは、LLMやAIOpsに先⾏投資を⾏っている が、リソースが限られており⾼頻度で変化する多様
な開発者のニーズを把握して対応するのはきつい... AIチーム SREチーム
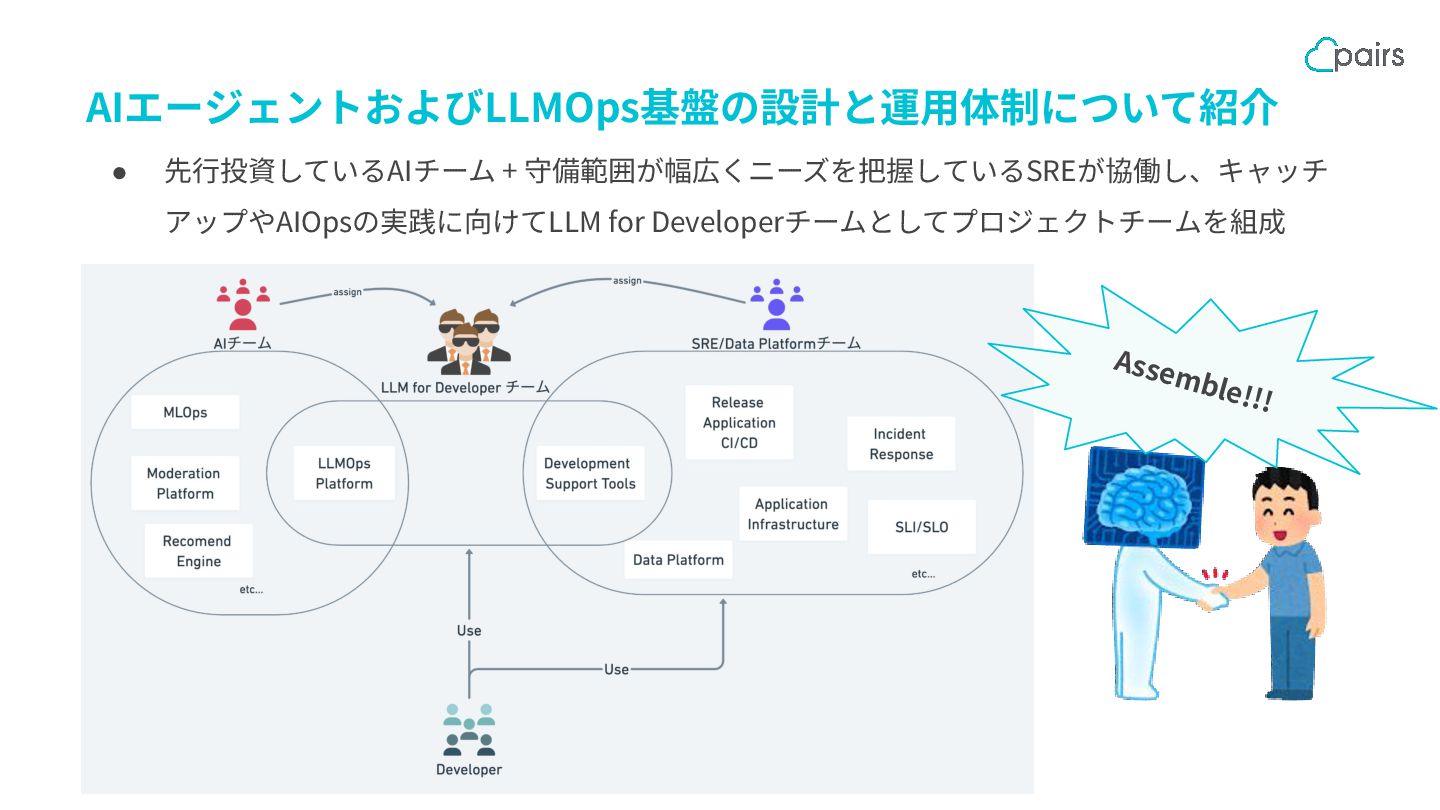
AIエージェントおよびLLMOps基盤の設計と運⽤体制について紹介 • 先⾏投資しているAIチーム + 守備範囲が幅広くニーズを把握しているSREが協働し、キャッチ アップやAIOpsの実践に向けてLLM for Developerチームとしてプロジェクトチームを組成 Assemble!!!
AIエージェントおよびLLMOps基盤の設計と運⽤体制について紹介 SREが投資するAIOps ~ペアーズにおけるLLM for Developerへの取り組み~
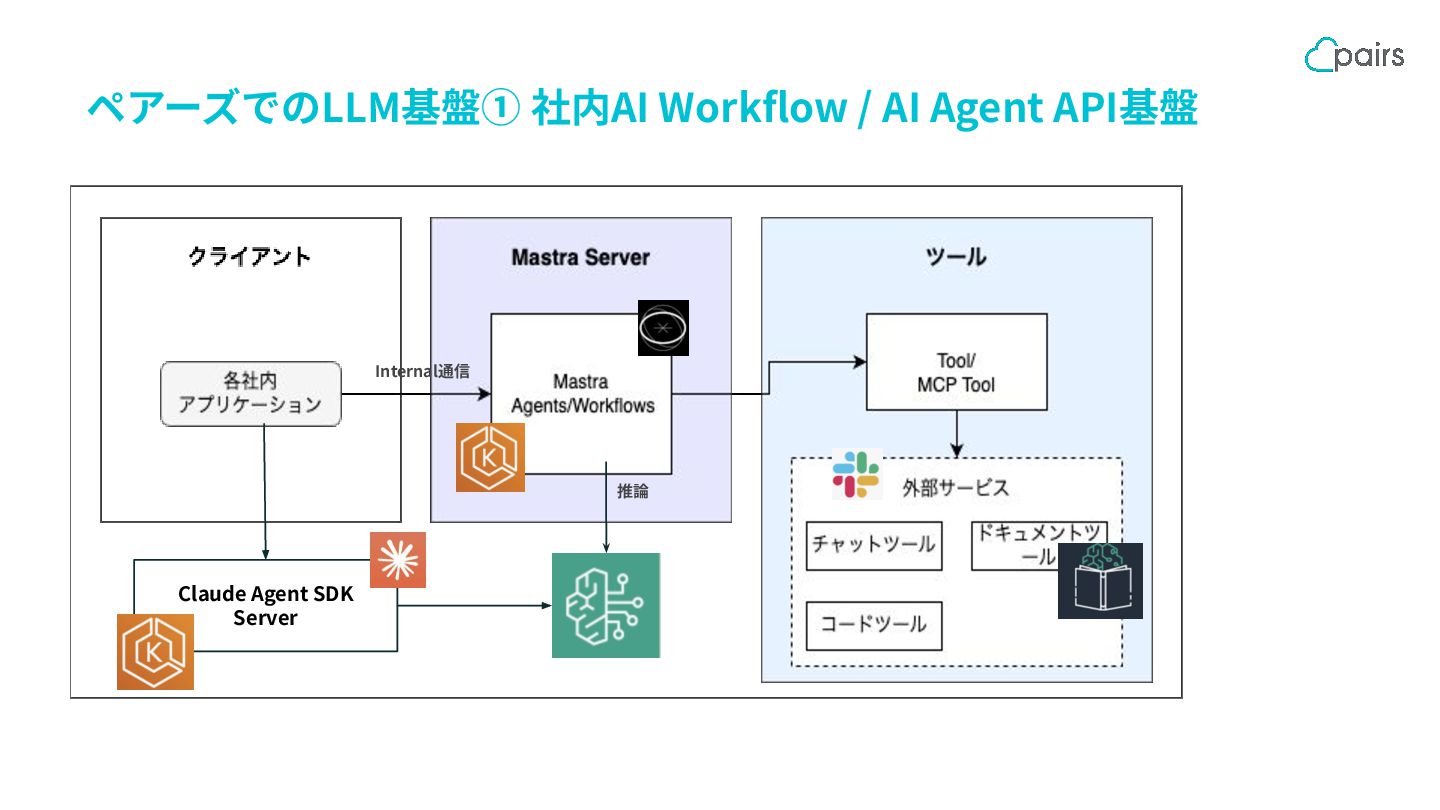
ペアーズでのLLM基盤① 社内AI Workflow / AI Agent API基盤 Internal通信 推論 Claude
Agent SDK Server
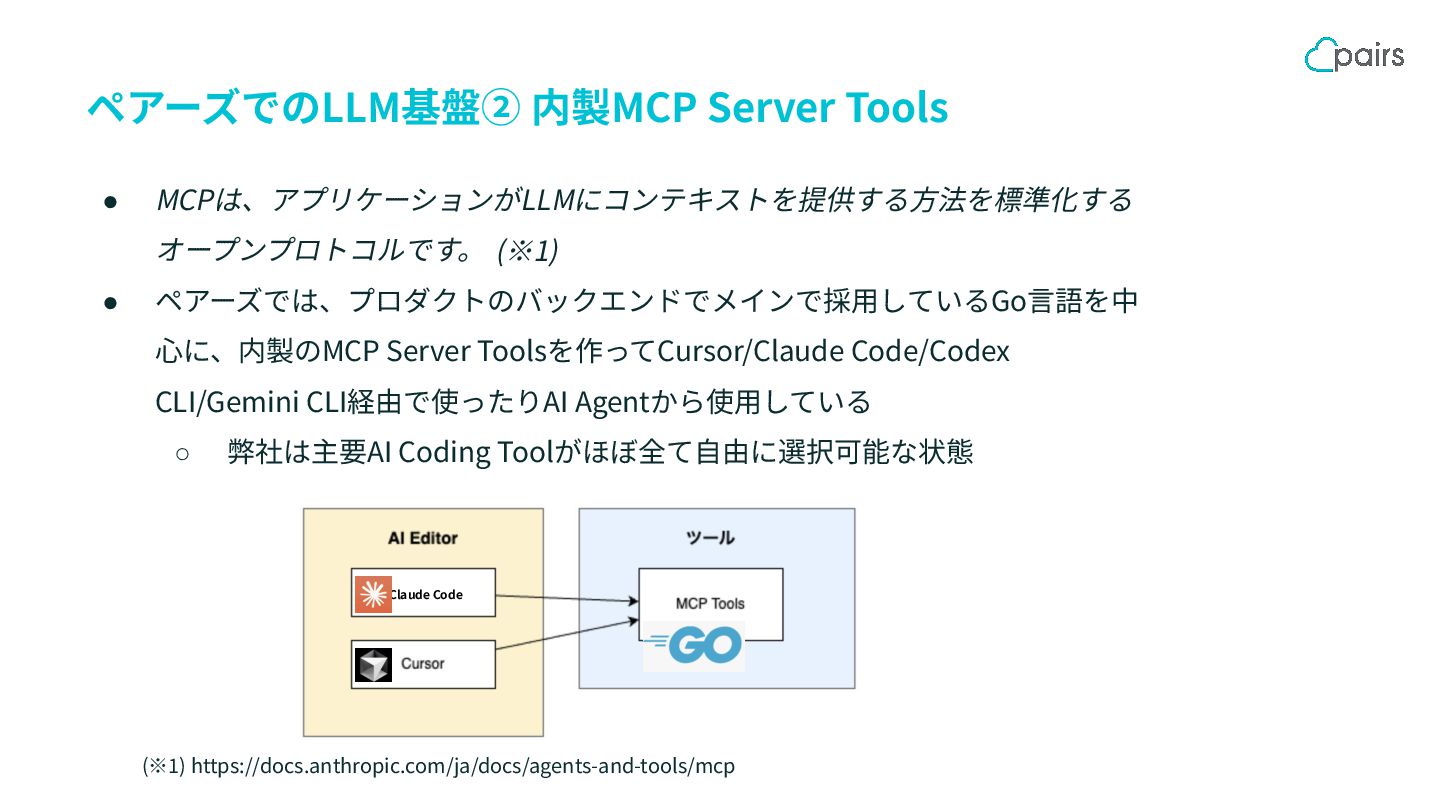
ペアーズでのLLM基盤② 内製MCP Server Tools • MCPは、アプリケーションがLLMにコンテキストを提供する⽅法を標準化する オープンプロトコルです。 • ペアーズでは、プロダクトのバックエンドでメインで採⽤しているGo⾔語を中 ⼼に、内製のMCP
Server Toolsを作ってCursor/Claude Code/Codex CLI/Gemini CLI経由で使ったりAI Agentから使⽤している ◦ 弊社は主要AI Coding Toolがほぼ全て⾃由に選択可能な状態 (※1) (※1) https://docs.anthropic.com/ja/docs/agents-and-tools/mcp Claude Code
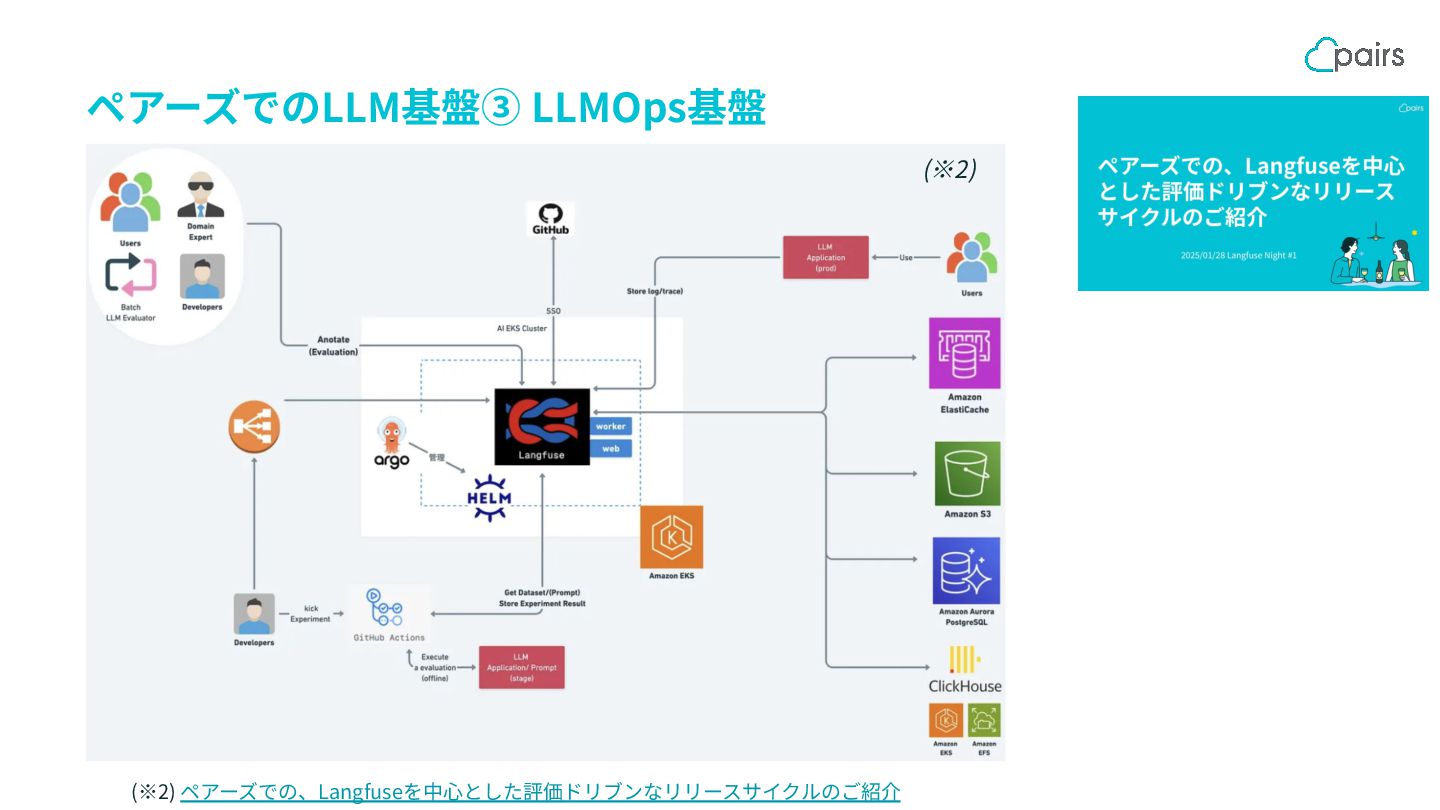
ペアーズでのLLM基盤③ LLMOps基盤 (※2) ペアーズでの、Langfuseを中⼼とした評価ドリブンなリリースサイクルのご紹介 (※2)
ペアーズにおけるAmazon Bedrockを⽤いた障害対応⽀援 ⽣成AIツールの導⼊事例 AIエージェントおよびLLMOps基盤の設計と運⽤体制について紹介
ペアーズにおける評価ドリブンな AI Agent 開発のご紹介 AIエージェントおよびLLMOps基盤の設計と運⽤体制について紹介
② 具体的な活用事例として社内向け Text to SQLツールを紹介
[背景] 分析業務におけるチームの⽴ち回り • PDM Team ◦ プロダクトの計画‧結果確認のためにデータ分析をしたい ◦ これまでは⾃らで SQL
を作成して実⾏することは少なかった • BI Team ◦ 分析依頼を受けて BigQuery にクエリを実⾏し、結果を依頼者へ共有 • SRE & Data Platform: 分析基盤の運⽤を担当 • このようにチームが分かれて分析を⾏っていたがいくつかの課題があった
データ活⽤におけるチーム別の課題 チーム 課題 説明 PDM → BI リードタイムが長い 分析依頼が集中し、結果を得るまで時間がかかる BI
分析の属人化 得意分野が異なり、担当外分析で時間を要した 全体 ナレッジ共有の不足 ドキュメントが少なく、暗黙知に依存していた
課題解決の⼿段として、Text to SQL に注⽬ • 複数ある課題の中でも、「分析の属⼈化」への対処が特に効果的と推測 ◦ 分析が⼀部のメンバーに偏っていると、その⼈が担当する機会が多くな り、結果としてナレッジの⾔語化‧共有が後回しになりがちになる ◦
属⼈化を解消することで、分析リードタイムの短縮にもつながる可能性 • 解決の⼿段として、「⾃然⾔語でクエリを⽣成できる仕組み = Text to SQL」 に注⽬
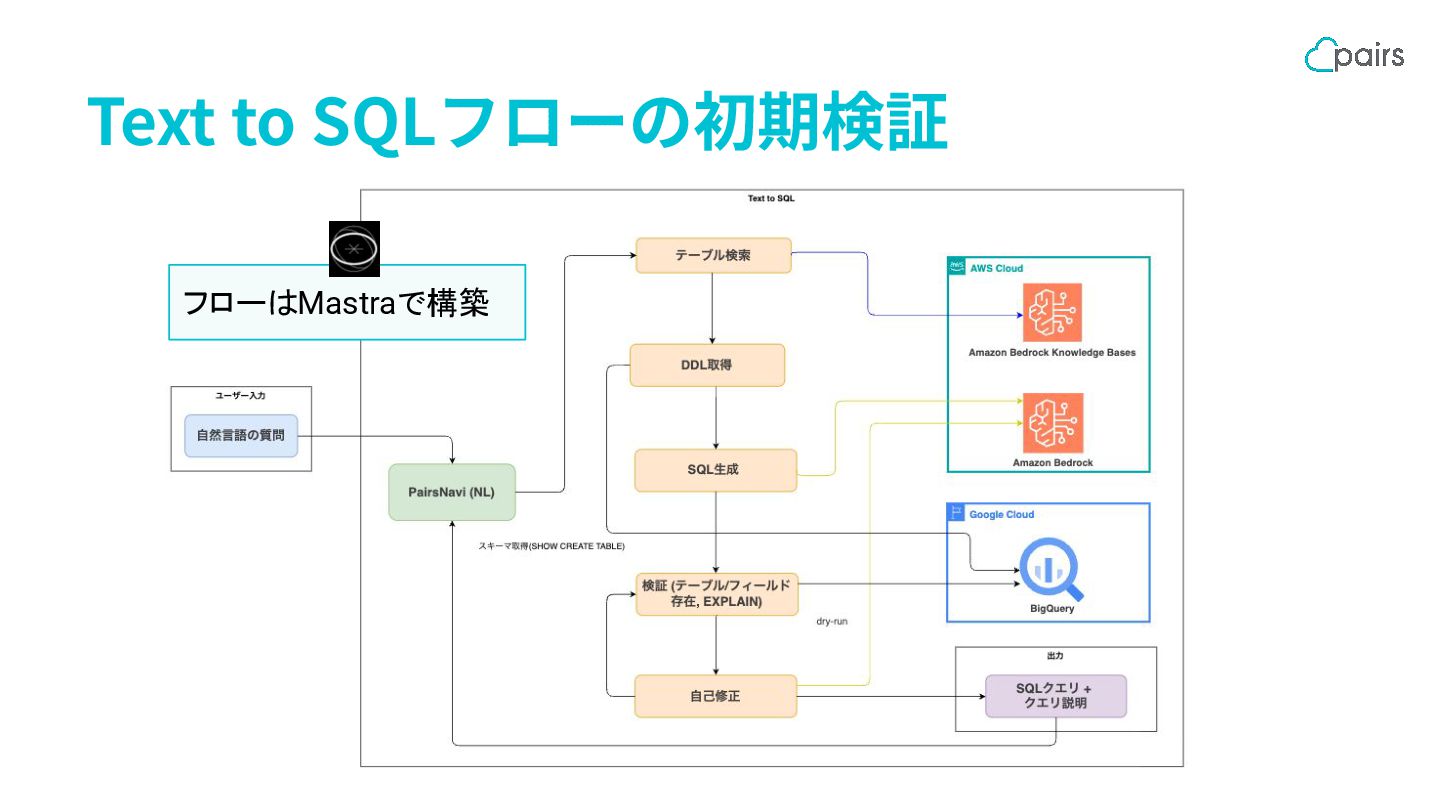
Text to SQLフローの初期検証 フローはMastraで構築
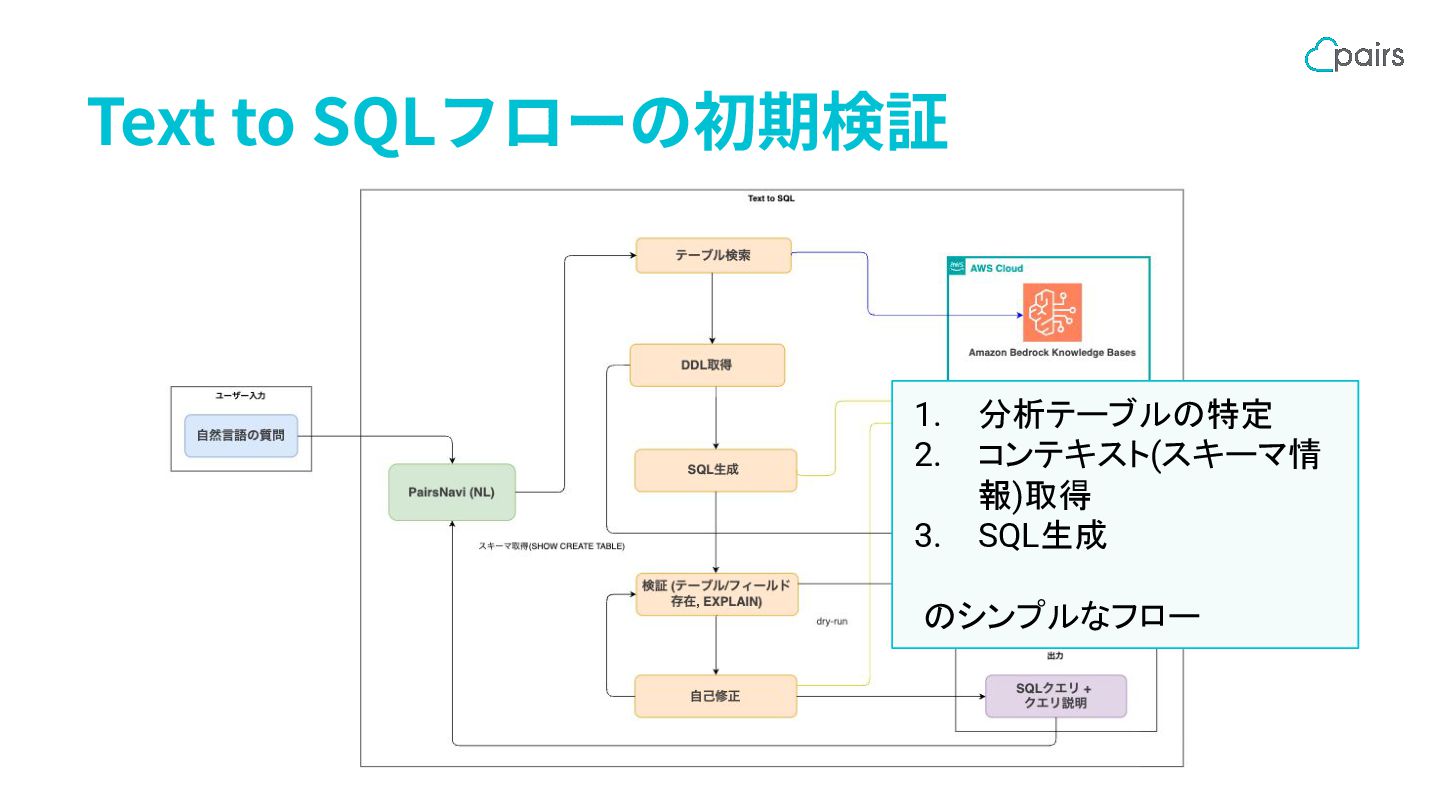
Text to SQLフローの初期検証 1. 分析テーブルの特定 2. コンテキスト(スキーマ情 報)取得 3. SQL生成
のシンプルなフロー
• 質問⽂と⽣成 SQL をドメインエキスパート (BI チーム)に確認したところ実 務で使える品質ではなかった • 1. 分析テーブルの特定
の問題点 ◦ テーブル・カラムの名前やDescriptionだけでは対象テーブルの特定ができない ケースがあった • 2. コンテキスト取得 の問題点 ◦ スキーマ情報だけでは判断できない、ドメイン知識を要するケースが多かった • 浮かんだ疑問 ◦ 「普段 BI チームはどうやって対象のテーブルを推定し、必要なコンテ キストを取得‧把握しているのか?」 期待に添えるアウトプットを⽣成できなかった
• BIチームの“暗黙知”を形式化するために、分析フローを細かく分解 • BIチームにヒアリング ◦ BIチームのシニアメンバーがサンプル分析要件を考えて、ジュニア メンバーがその要件からどうやって分析SQLを導き出すのかの分析 のデモをしてもらった • デモから普段のBIチームの分析ステップを構造化した
• 定義したフローをもとに、Text to SQL Workflow へ落とし込む Text to SQL 構築の第⼀歩:現場理解から始める設計
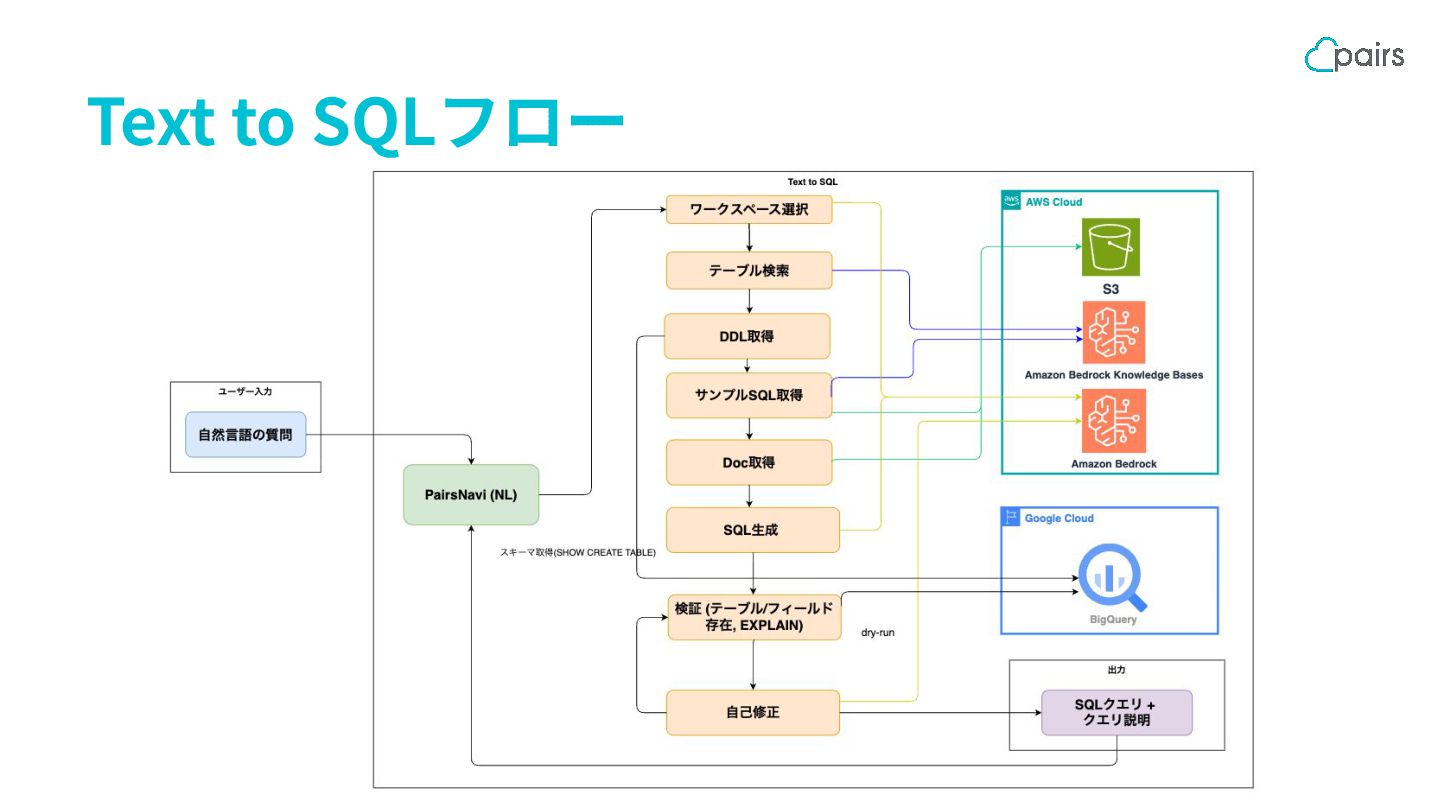
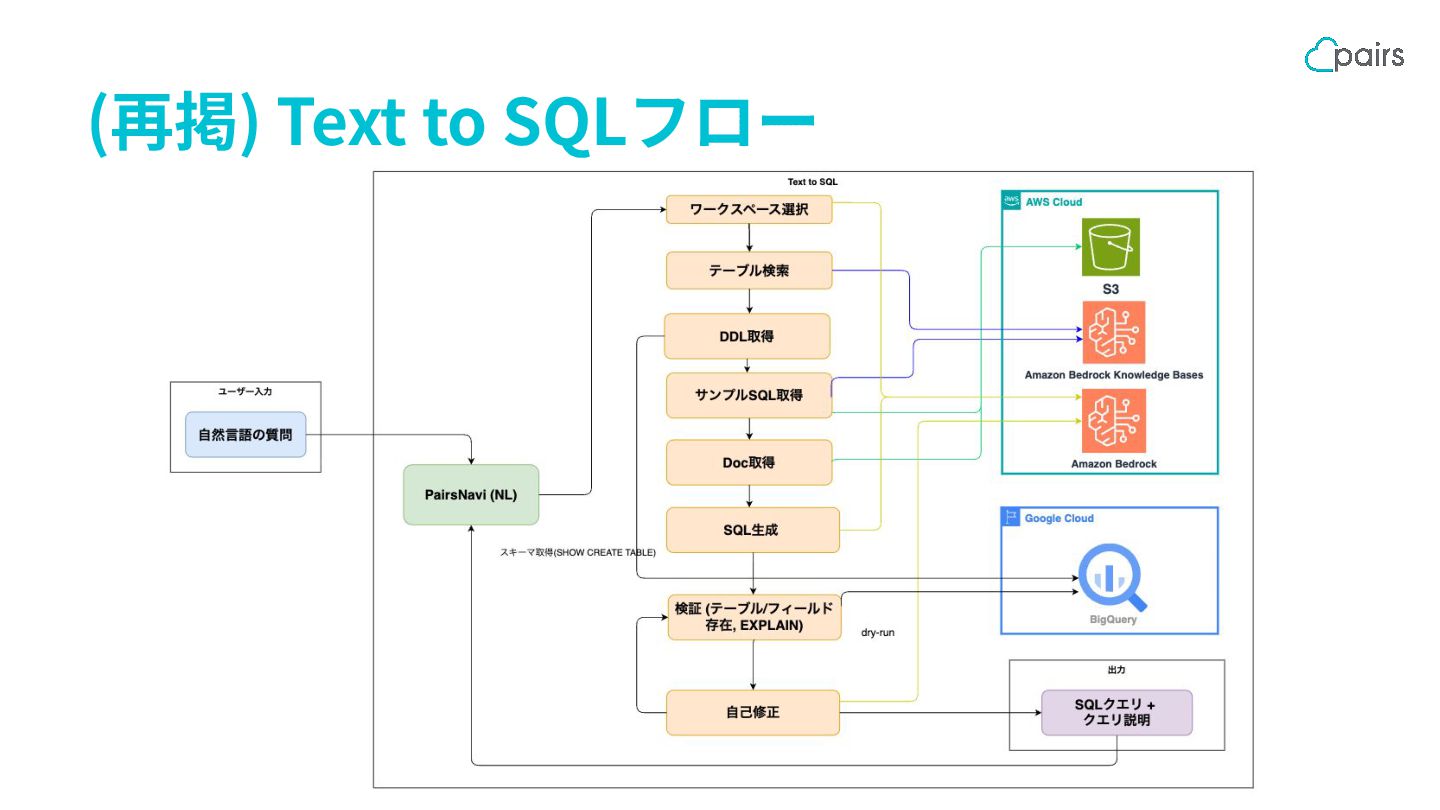
Text to SQLフロー
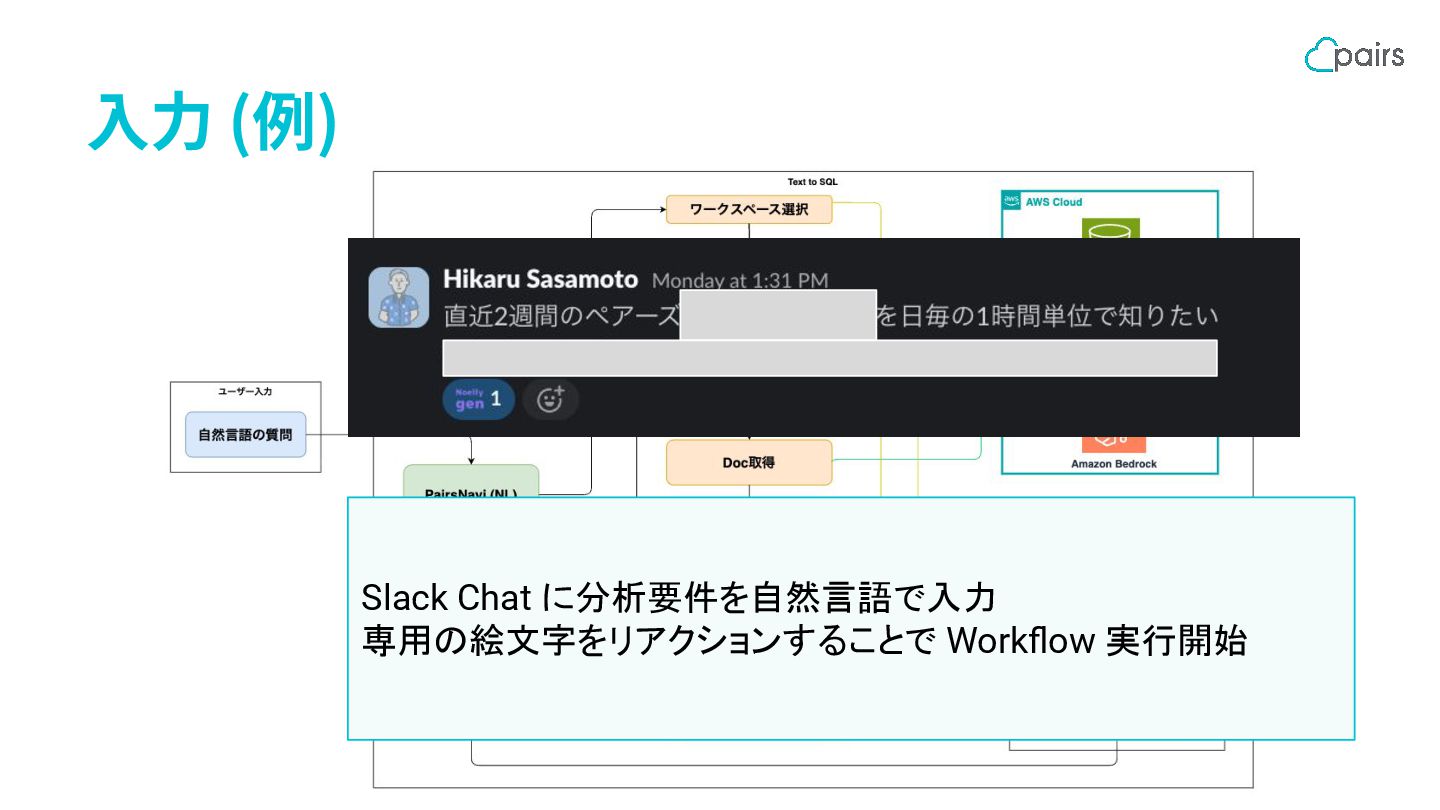
⼊⼒ (例) Slack Chat に分析要件を自然言語で入力 専用の絵文字をリアクションすることで Workflow 実行開始
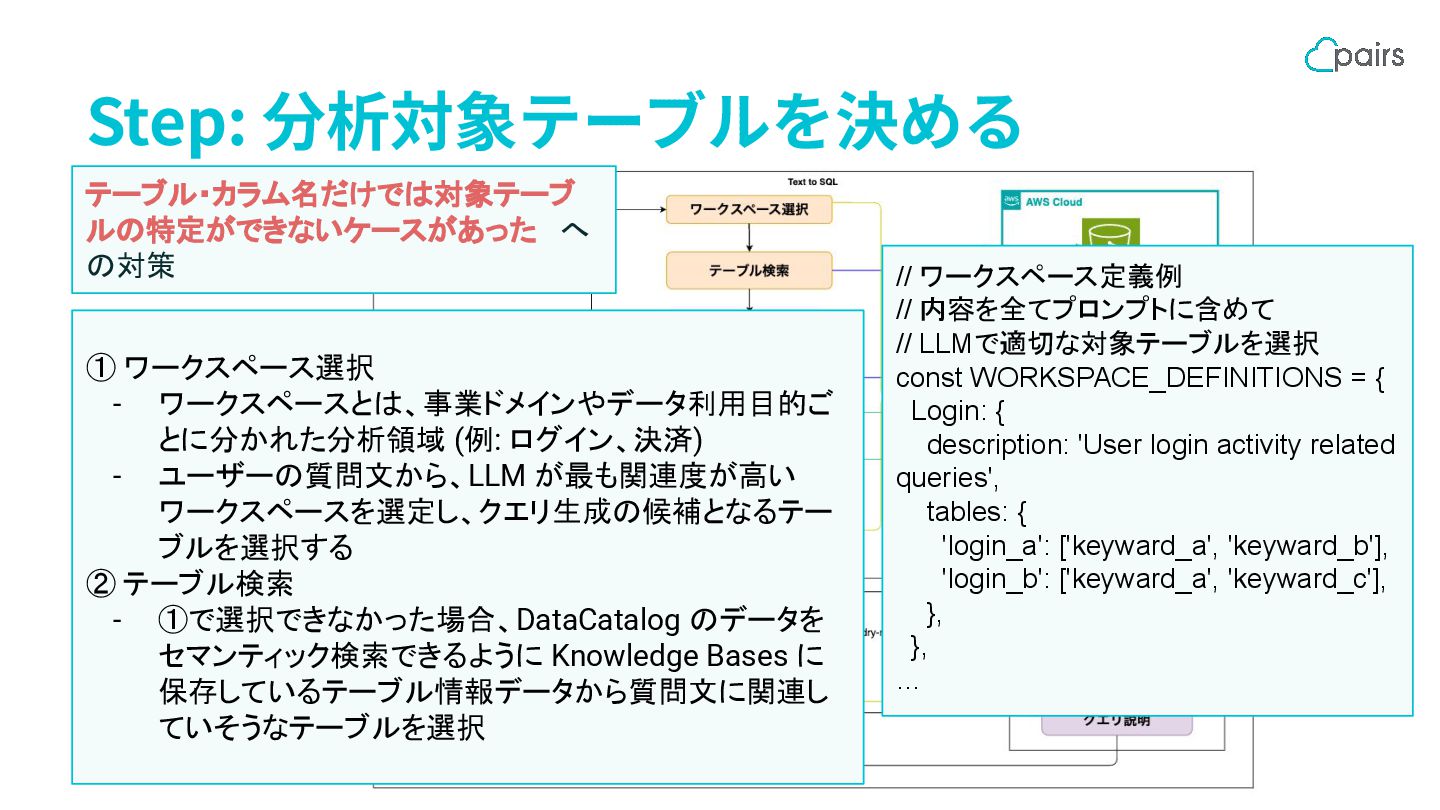
Step: 分析対象テーブルを決める ① ワークスペース選択 - ワークスペースとは、事業ドメインやデータ利用目的ご とに分かれた分析領域 (例: ログイン、決済) -
ユーザーの質問文から、LLM が最も関連度が高い ワークスペースを選定し、クエリ生成の候補となるテー ブルを選択する ② テーブル検索 - ①で選択できなかった場合、DataCatalog のデータを セマンティック検索できるように Knowledge Bases に 保存しているテーブル情報データから質問文に関連し ていそうなテーブルを選択 テーブル・カラム名だけでは対象テーブ ルの特定ができないケースがあった へ の対策 // ワークスペース定義例 // 内容を全てプロンプトに含めて // LLMで適切な対象テーブルを選択 const WORKSPACE_DEFINITIONS = { Login: { description: 'User login activity related queries', tables: { 'login_a': ['keyward_a', 'keyward_b'], 'login_b': ['keyward_a', 'keyward_c'], }, }, …
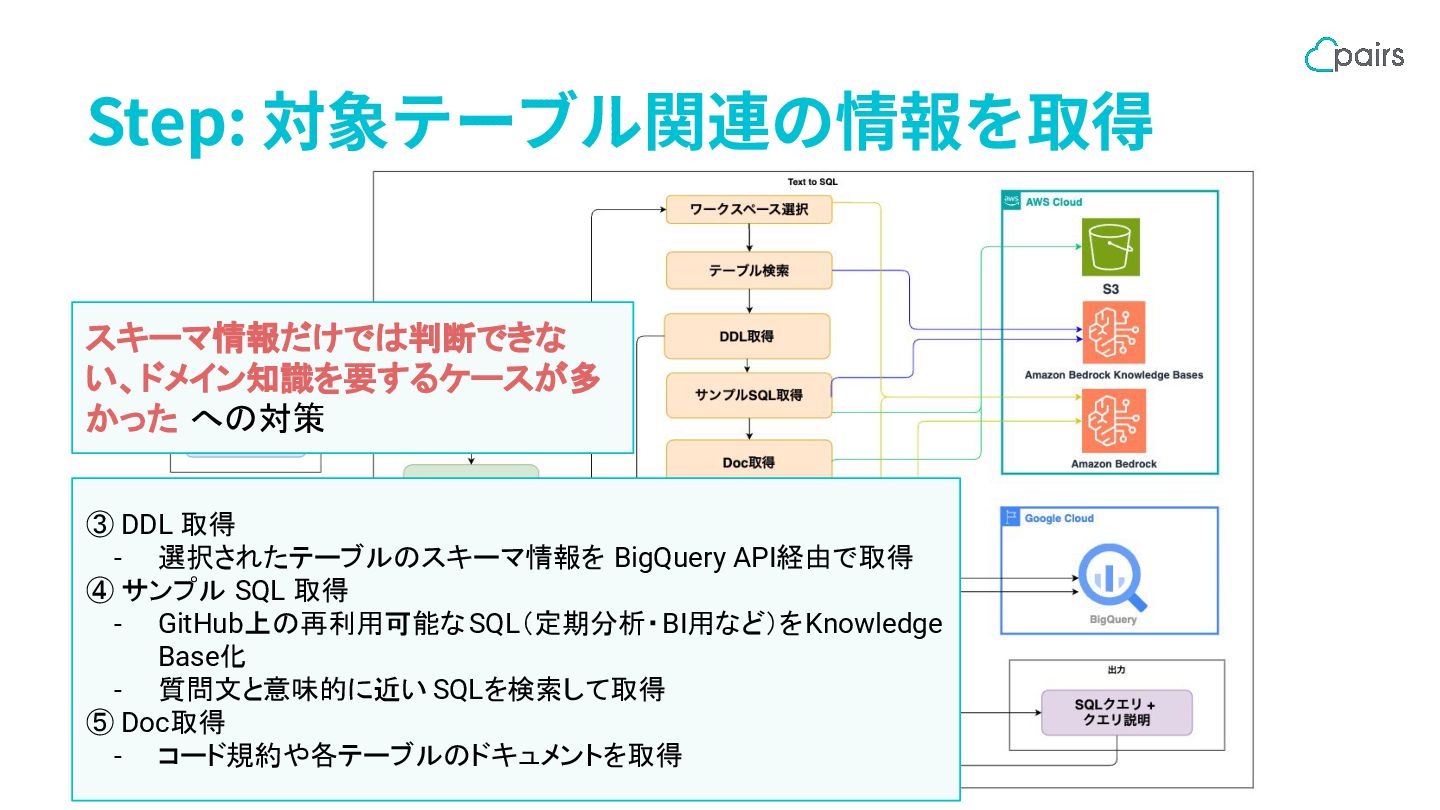
Step: 対象テーブル関連の情報を取得 ③ DDL 取得 - 選択されたテーブルのスキーマ情報を BigQuery API経由で取得 ④
サンプル SQL 取得 - GitHub上の再利用可能なSQL(定期分析・BI用など)をKnowledge Base化 - 質問文と意味的に近い SQLを検索して取得 ⑤ Doc取得 - コード規約や各テーブルのドキュメントを取得 スキーマ情報だけでは判断できな い、ドメイン知識を要するケースが多 かった への対策
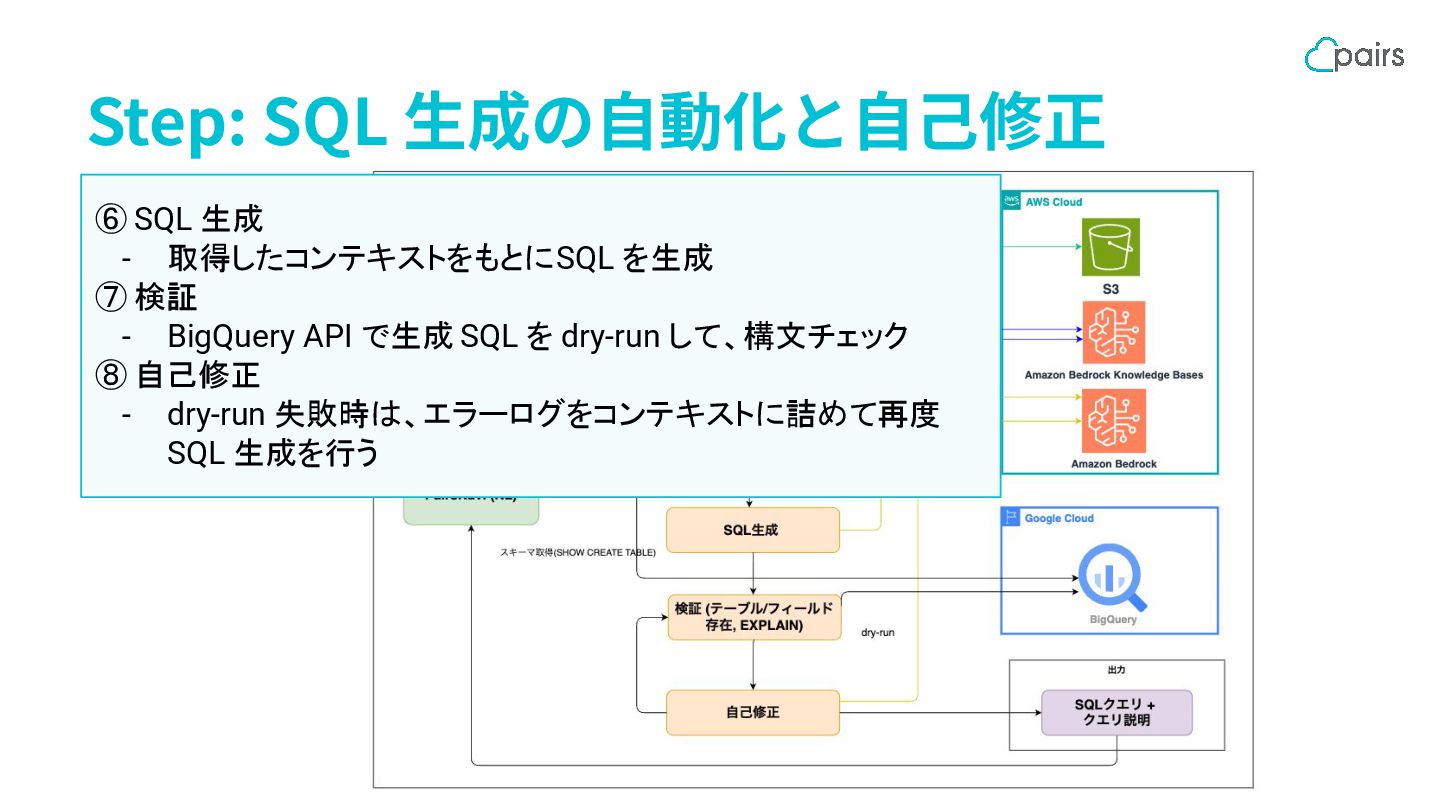
Step: SQL ⽣成の⾃動化と⾃⼰修正 ⑥ SQL 生成 - 取得したコンテキストをもとに SQL を生成
⑦ 検証 - BigQuery API で生成 SQL を dry-run して、構文チェック ⑧ 自己修正 - dry-run 失敗時は、エラーログをコンテキストに詰めて再度 SQL 生成を行う
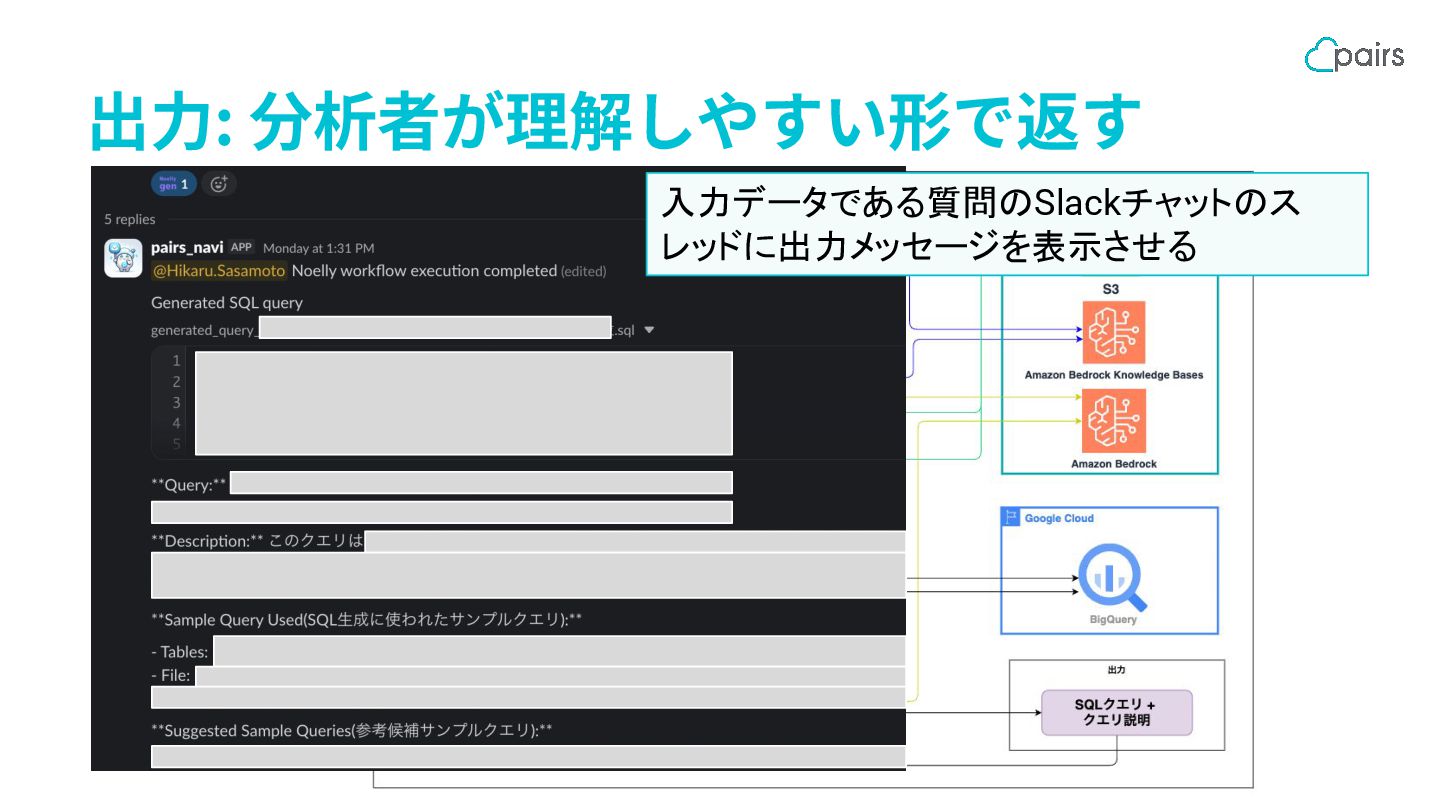
出⼒: 分析者が理解しやすい形で返す 入力データである質問のSlackチャットのス レッドに出力メッセージを表示させる
(再掲) Text to SQLフロー
• Lambda, Bedrock, S3, IAM などを組み合わせて、インフラからLLMまで AWS上で完結できる • LambdaからBedrock呼び出しまでIAMロールで⼀元管理できるため、 APIキー不要
• Amazon Bedrock Knowledge Bases を使うことで簡単にセマンティッ ク検索可能に AWS を使うことで実現できたこと
• オフライン評価 ◦ PR をイベントに実⾏される評価バッチ on Github Actions ◦ テストインプットデータで⽣成されたアウトプット
SQL を正解 SQL と⽐較する ◦ 評価プロンプトが両⽅のクエリを⾒て採点 ◦ 評価プロンプトの精度チェック⽤にもテストデータを⽤意 • オンライン評価 ◦ クエリ⽣成後に Slack Chat 上で質問者に採点するボタンを提⽰ ◦ Langfuse からトレースデータをエクスポートして分析 ▪ 利⽤数/⽇、利⽤ユニークユーザ数/⽇ 品質を継続的に評価‧改善する仕組み
Text to SQL によるチーム別課題への貢献 チーム 課題 Text to SQL 導入による貢献
PDM → BI リードタイムが長い PDM 自身が SQL を生成し 自走して分析できるようになった BI 分析の属人化 特定の分析者に依存せず必要な分析用 SQL を自分たちで生成できるようになった 全体 ナレッジ共有の不足 ドキュメント整備が Text to SQL の精度・パフォーマンス向上につ ながることでドキュメントを整備する動機が高まった
• テーブルメタデータの拡充 ◦ 出⼒精度をさらに⾼めたい ◦ データ量が膨⼤なため、まずは頻出ユースケースに絞って対応する • Slack Chat 以外のインターフェース提供
◦ エンジニア向けにローカル実⾏環境を整備し、⾼速なやり取りを可能にする • 複数ラリーでの応答改善 ◦ 1回⽬の⽣成結果が不⼗分な場合、修正点を提⽰して再⽣成できるようにする • AI Agent 化 ◦ ケースに応じた柔軟なタスク実⾏を⾏い、精度を向上させる 今後の展望
We’re hiring! ペアーズではエンジニアを積極採⽤中! カジュアル⾯談もお待ちしております! (X: @hisamouna34)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[背景] 分析業務におけるチームの⽴ち回り • PDM Team ◦ プロダクトの計画‧結果確認のためにデータ分析をしたい ◦ これまでは⾃らで SQL](https://files.speakerdeck.com/presentations/0404a43ed4064836adfa25e5eb6fbfa3/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}