AIコーディングツールが話題になってからしばらく経ちますが、その進化のスピードは衰えるどころか、むしろ加速しています。「なんとなく知ってるけど、ちゃんと使えていない」という方も多いのではないでしょうか。 すでに複数ツールを使いこなしている方も、仕事の制約で様子見中の方も、これからAX(AIトランスフォーメーション)を本格推進したい方も——それぞれの立場から、AIコーディングとどう向き合っていくのかを一緒に考えていきましょう。
https://www.youtube.com/watch?v=e8IkxquZ0YM
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
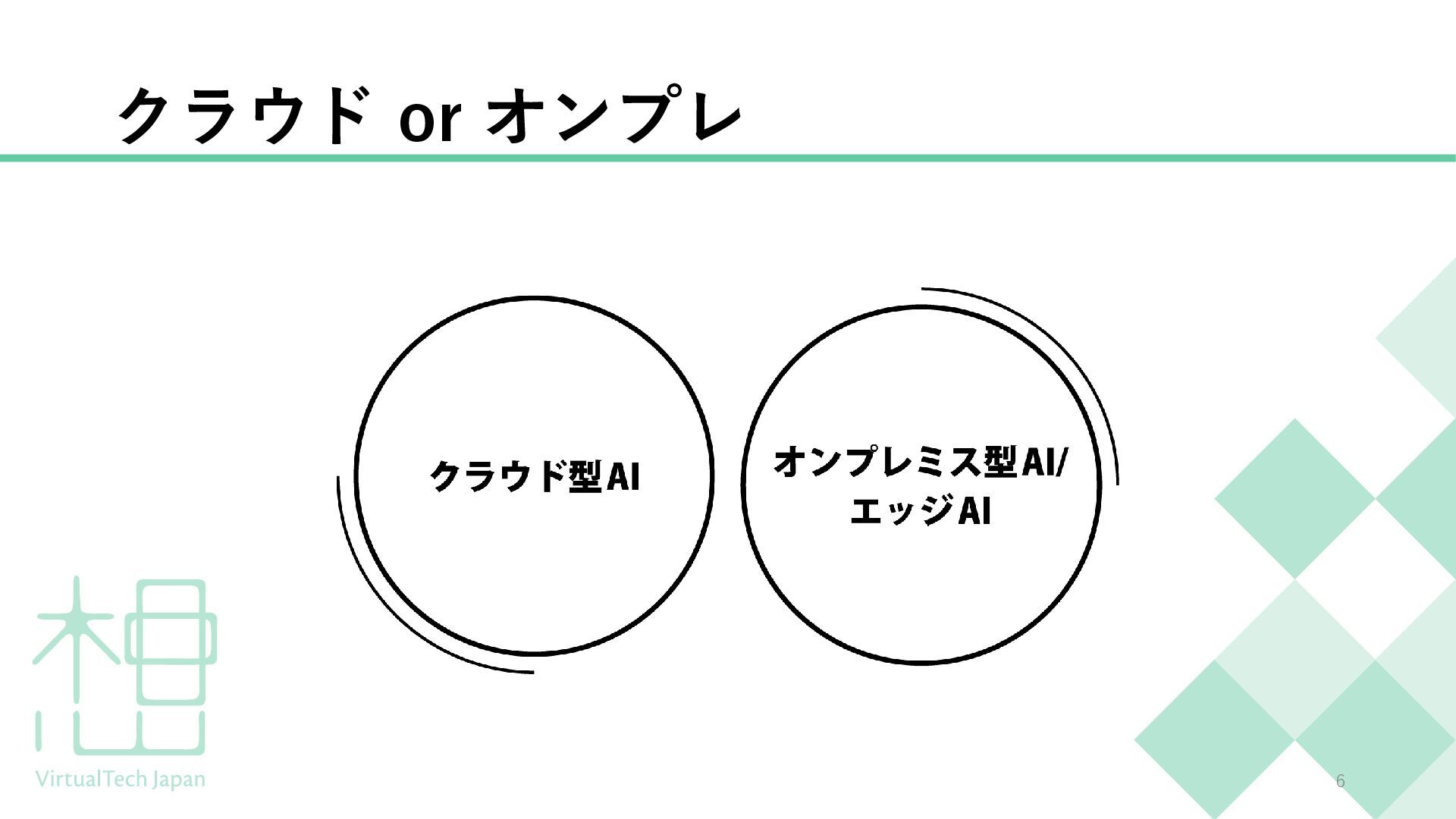{kind=link}
{kind=link}
{kind=link}
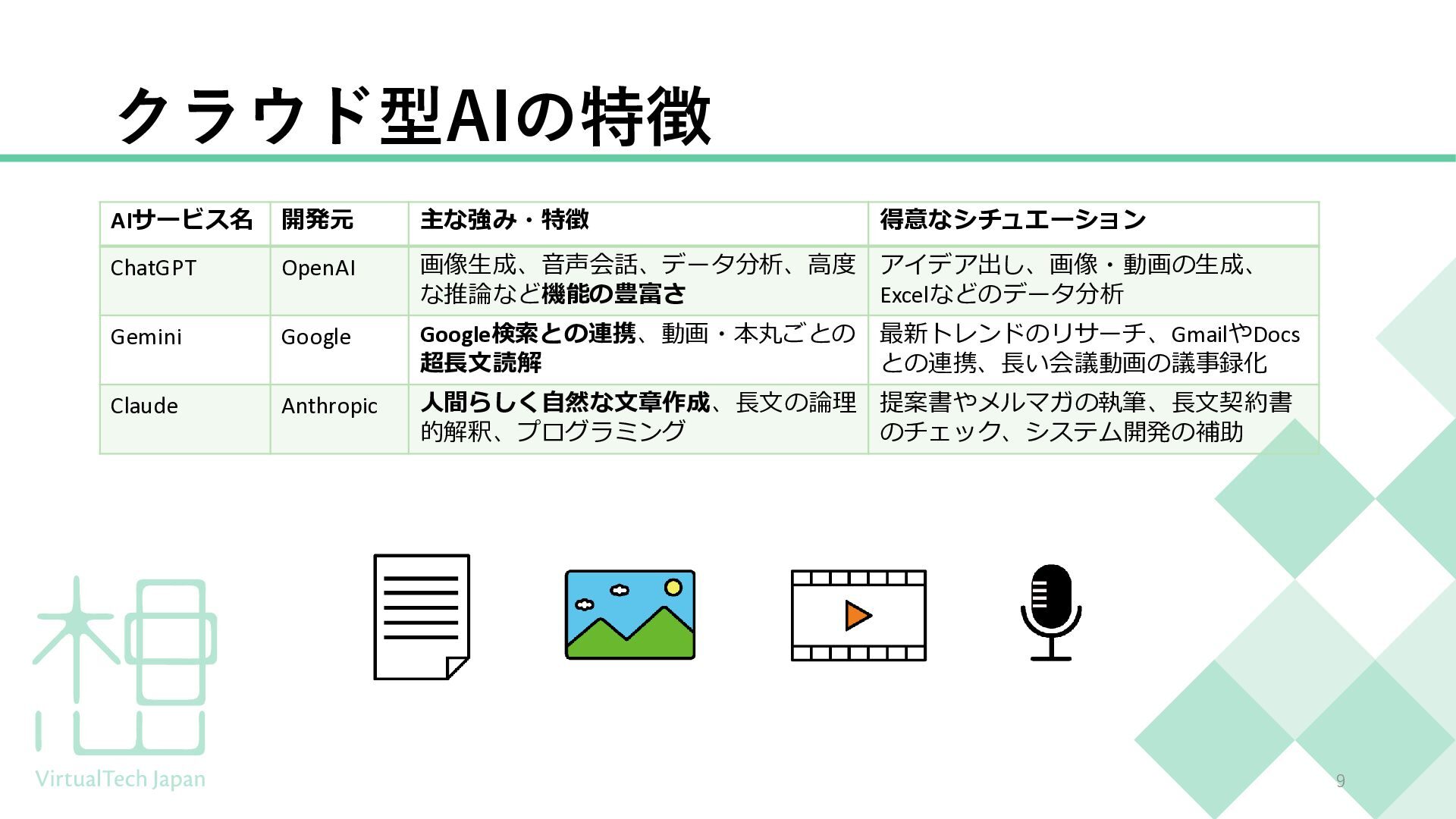{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
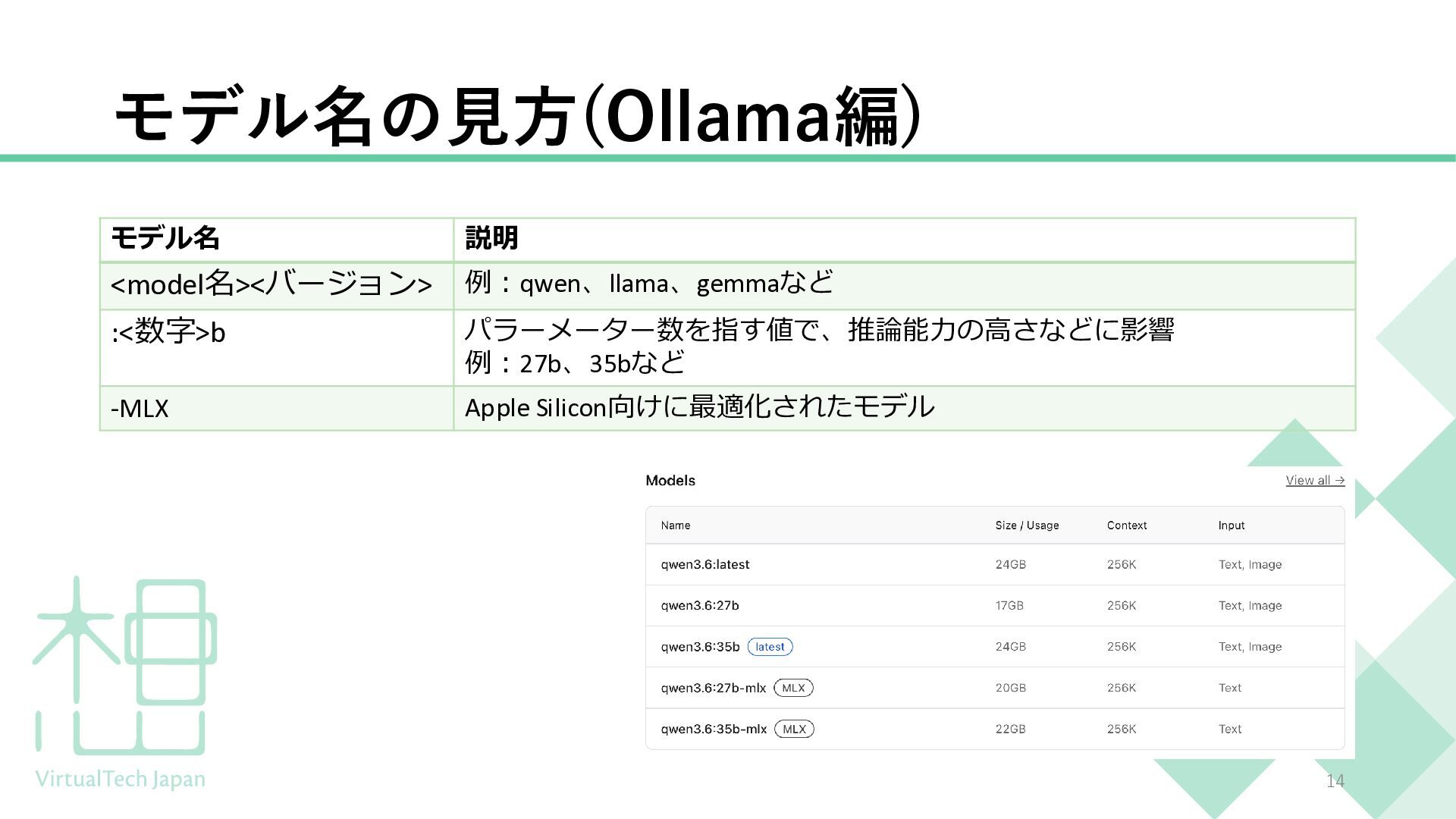{kind=link}
{kind=link}
{kind=link}
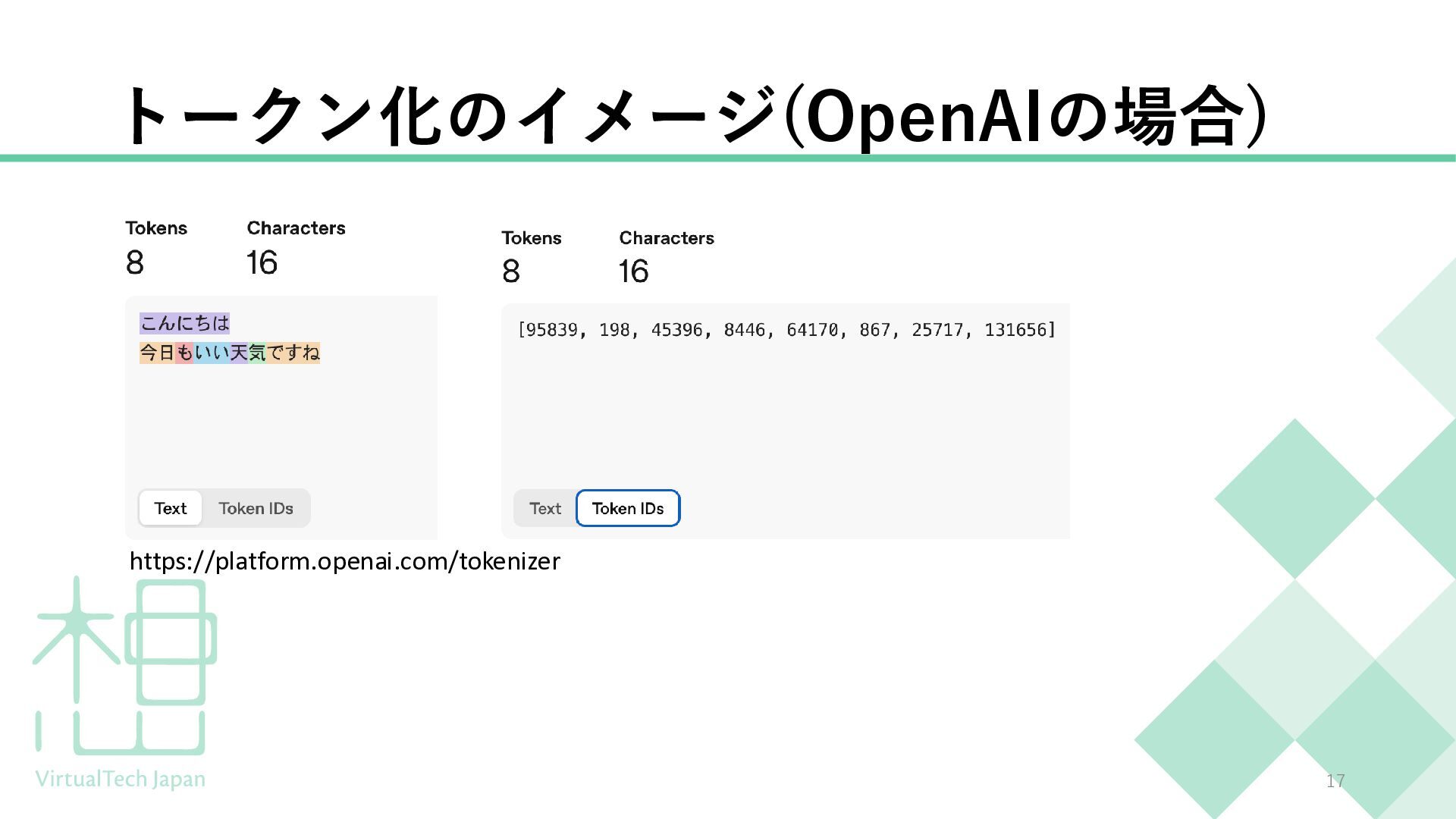{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}