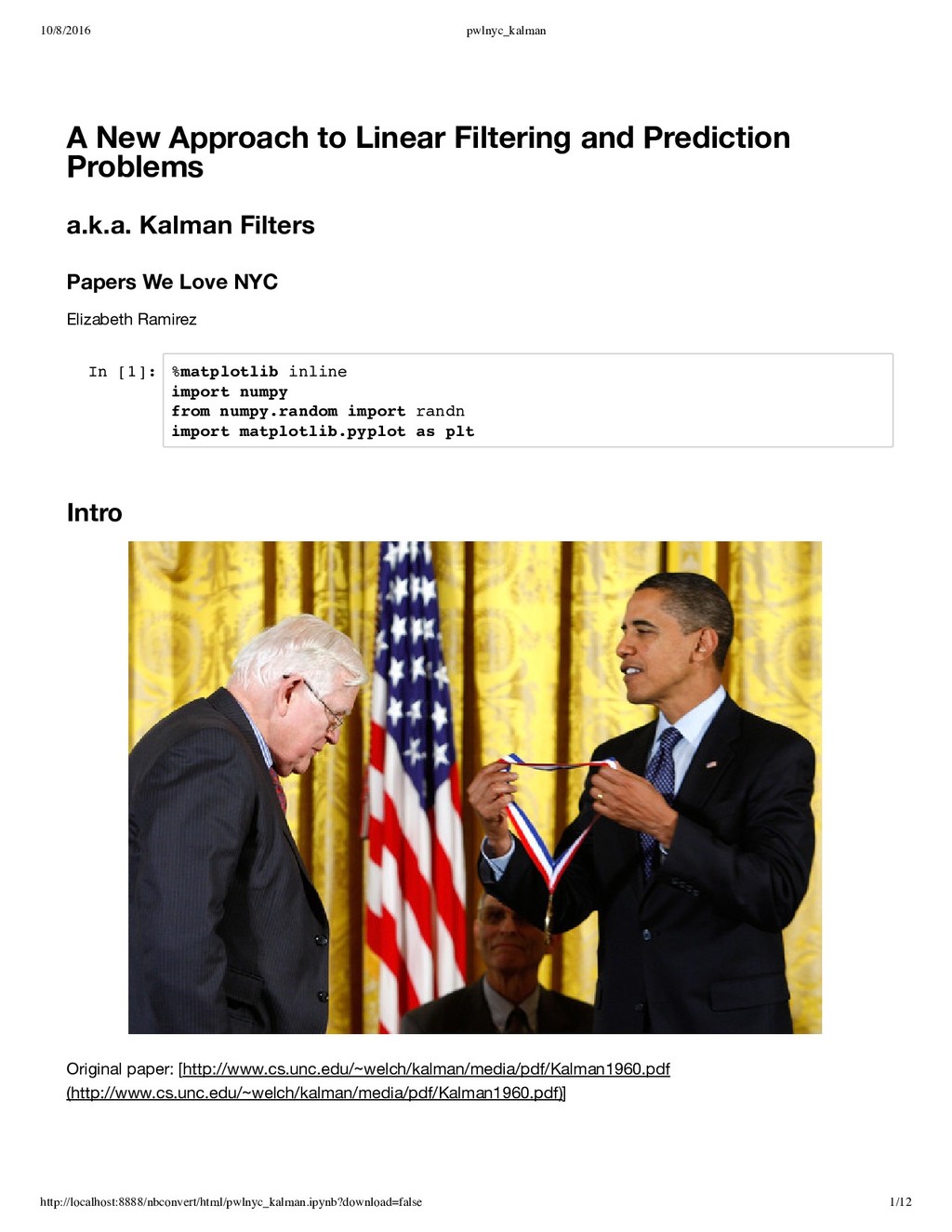
d e f p r e d i c t ( u , P , F , Q ) : u = n u m p y . d o t ( F , u ) P = n u m p y . d o t ( F , n u m p y . d o t ( P , F . T ) ) + Q r e t u r n u , P I n [ 3 ] : d e f c o r r e c t ( u , A , b , P , Q , R ) : C = n u m p y . d o t ( A , n u m p y . d o t ( P , A . T ) ) + R K = n u m p y . d o t ( P , n u m p y . d o t ( A . T , n u m p y . l i n a l g . i n v ( C ) ) ) u = u + n u m p y . d o t ( K , ( b - n u m p y . d o t ( A , u ) ) ) P = P - n u m p y . d o t ( K , n u m p y . d o t ( C , K . T ) ) r e t u r n u , P I n [ 4 ] : # T e s t d a t a d t = 0 . 1 A = n u m p y . a r r a y ( [ [ 1 , 0 ] , [ 0 , 1 ] ] ) u = n u m p y . z e r o s ( ( 2 , 1 ) ) # R a n d o m i n i t i a l m e a s u r e m e n t c e n t e r e d a t s t a t e v a l u e b = n u m p y . a r r a y ( [ [ u [ 0 , 0 ] + r a n d n ( 1 ) [ 0 ] ] , [ u [ 1 , 0 ] + r a n d n ( 1 ) [ 0 ] ] ] ) P = n u m p y . d i a g ( ( 0 . 0 1 , 0 . 0 1 ) ) F = n u m p y . a r r a y ( [ [ 1 . 0 , d t ] , [ 0 . 0 , 1 . 0 ] ] ) # U n i t v a r i a n c e f o r t h e s a k e o f s i m p l i c i t y Q = n u m p y . e y e ( u . s h a p e [ 0 ] ) R = n u m p y . e y e ( b . s h a p e [ 0 ] ) I n [ 5 ] : N = 5 0 0 p r e d i c t i o n s , c o r r e c t i o n s , m e a s u r e m e n t s = [ ] , [ ] , [ ] f o r k i n n u m p y . a r a n g e ( 0 , N ) : u , P = p r e d i c t ( u , P , F , Q ) p r e d i c t i o n s . a p p e n d ( u ) u , P = c o r r e c t ( u , A , b , P , Q , R ) c o r r e c t i o n s . a p p e n d ( u ) m e a s u r e m e n t s . a p p e n d ( b ) b = n u m p y . a r r a y ( [ [ u [ 0 , 0 ] + r a n d n ( 1 ) [ 0 ] ] , [ u [ 1 , 0 ] + r a n d n ( 1 ) [ 0 ] ] ] ) p r i n t ' p r e d i c t e d f i n a l e s t i m a t e : % f ' % p r e d i c t i o n s [ - 1 ] [ 0 ] p r i n t ' c o r r e c t e d f i n a l e s t i m a t e : % f ' % c o r r e c t i o n s [ - 1 ] [ 0 ] p r i n t ' m e a s u r e d s t a t e : % f ' % m e a s u r e m e n t s [ - 1 ] [ 0 ] p r e d i c t e d f i n a l e s t i m a t e : 1 7 7 . 5 2 9 1 1 3 c o r r e c t e d f i n a l e s t i m a t e : 1 7 6 . 6 0 2 6 2 7 m e a s u r e d s t a t e : 1 7 6 . 0 0 7 3 6 1
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10/8/2016 pwlnyc_kalman http://localhost:8888/nbconvert/html/pwlnyc_kalman.ipynb?download=false 10/12 I n [ 2 ] :](https://files.speakerdeck.com/presentations/4b1bc7c09f1d4500bfa40818e3fca016/slide_9.jpg){kind=link}
![10/8/2016 pwlnyc_kalman http://localhost:8888/nbconvert/html/pwlnyc_kalman.ipynb?download=false 11/12 I n [ 6 ] :](https://files.speakerdeck.com/presentations/4b1bc7c09f1d4500bfa40818e3fca016/slide_10.jpg){kind=link}
![10/8/2016 pwlnyc_kalman http://localhost:8888/nbconvert/html/pwlnyc_kalman.ipynb?download=false 12/12 Thank you! [email protected] @eramirem](https://files.speakerdeck.com/presentations/4b1bc7c09f1d4500bfa40818e3fca016/slide_11.jpg){kind=link}