作ったモデルの再利用 ) ◦ Model Soup [Wortsman +, PMLR2022] ◦ Model Stock [Jang +, ECCV 2024] (より少ない FT モデルで最適なマージを行う) • Fine-tuning 時に低下する汎化性能を回復 させる(WiSE-FT [Wortsman+ ,CVPR 2022]) ◦ LERP(線形補間)/SLERP(球面線形補間) ◦ WARP [Ramé +, 2024 arXiv] • 特化モデル LLM開発へのモデルマージの利用 (Task Vector / Delta Parameters のマージ) ◦ Chat Vector [Huang +, ACL 2024] / Task Arithmetic [Ilharco +, ICLR2023] ◦ TIES-merging [Yadav +, NeurIPS 2023] , DARE [Yu +, ICML 2024] • 基本的に同じ事前学習済みモデルの派生モデル同士でしか上手くマージできない ◦ 蒸留 [Wan +, ICLR 2024] ・重みの配列をアライメント[Ainsworth +, 2023 arXiv] [Entezari +, ICLR 2022]してからマージし たり、単に層を積み重ねたり(Passthrough/FrankenMerges [Kim +, NAACL 2024])して、異なる構造・事前学習のモデル 同士をマージする試みも研究が進められている ◦ おすすめ:佐藤竜馬先生のブログ(モデルパラメータの算術) 、サーベイブログ(Model Merging: A Survey) 論文紹介 – モデルマージ研究の進展 6
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• チェックポイントのマージ(Stochastic Weight Averaging [Izmailov +, UAI 2018]) • Fine-tuning時に複数ハイパラで学習して、得られた複数のモデルの重みをマージ(ハイパラ探索時に](https://files.speakerdeck.com/presentations/ae62bb4dbbb54d7b90ccbeb725f6974f/slide_5.jpg){kind=link}
{kind=link}
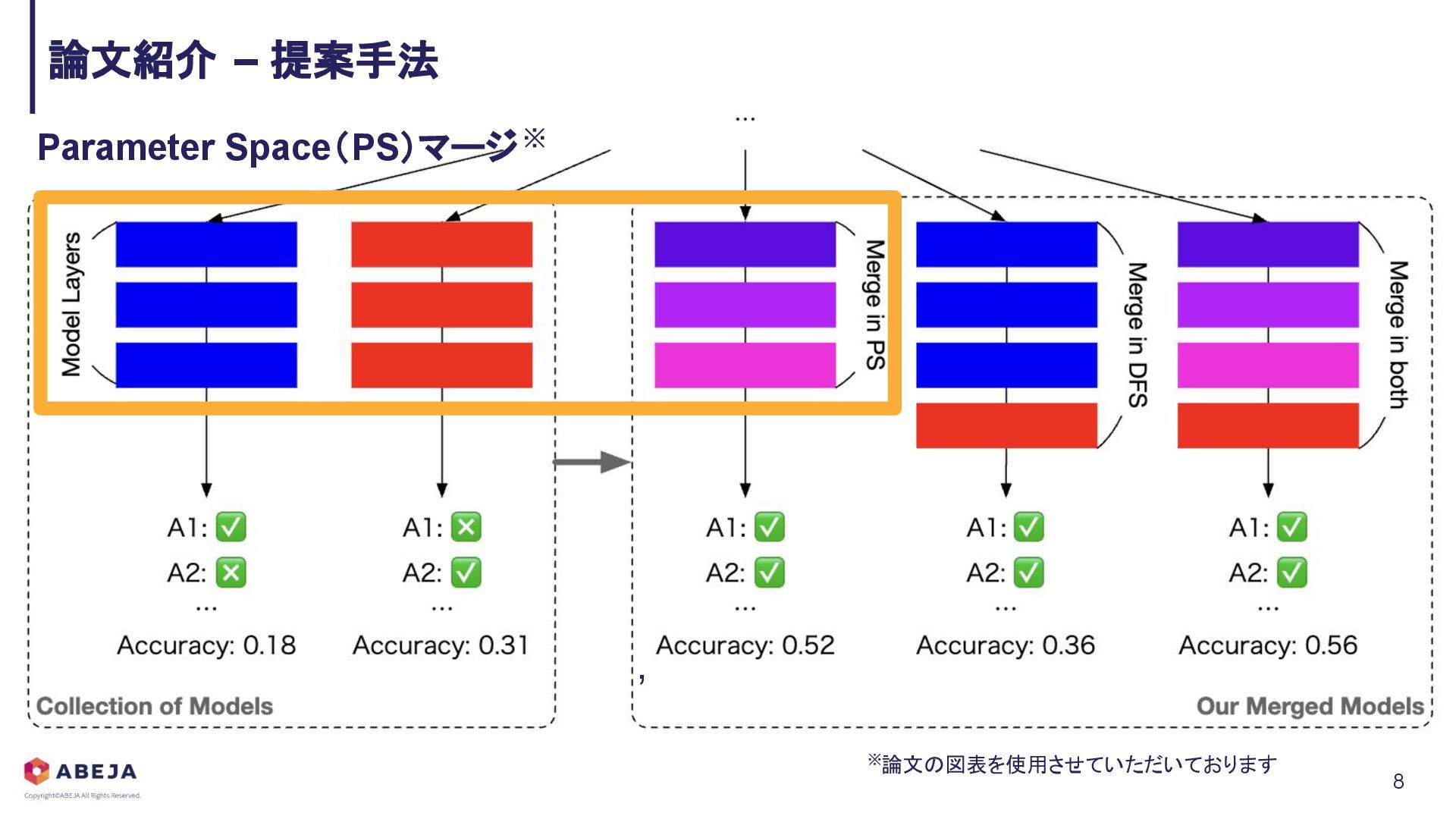{kind=link}
{kind=link}
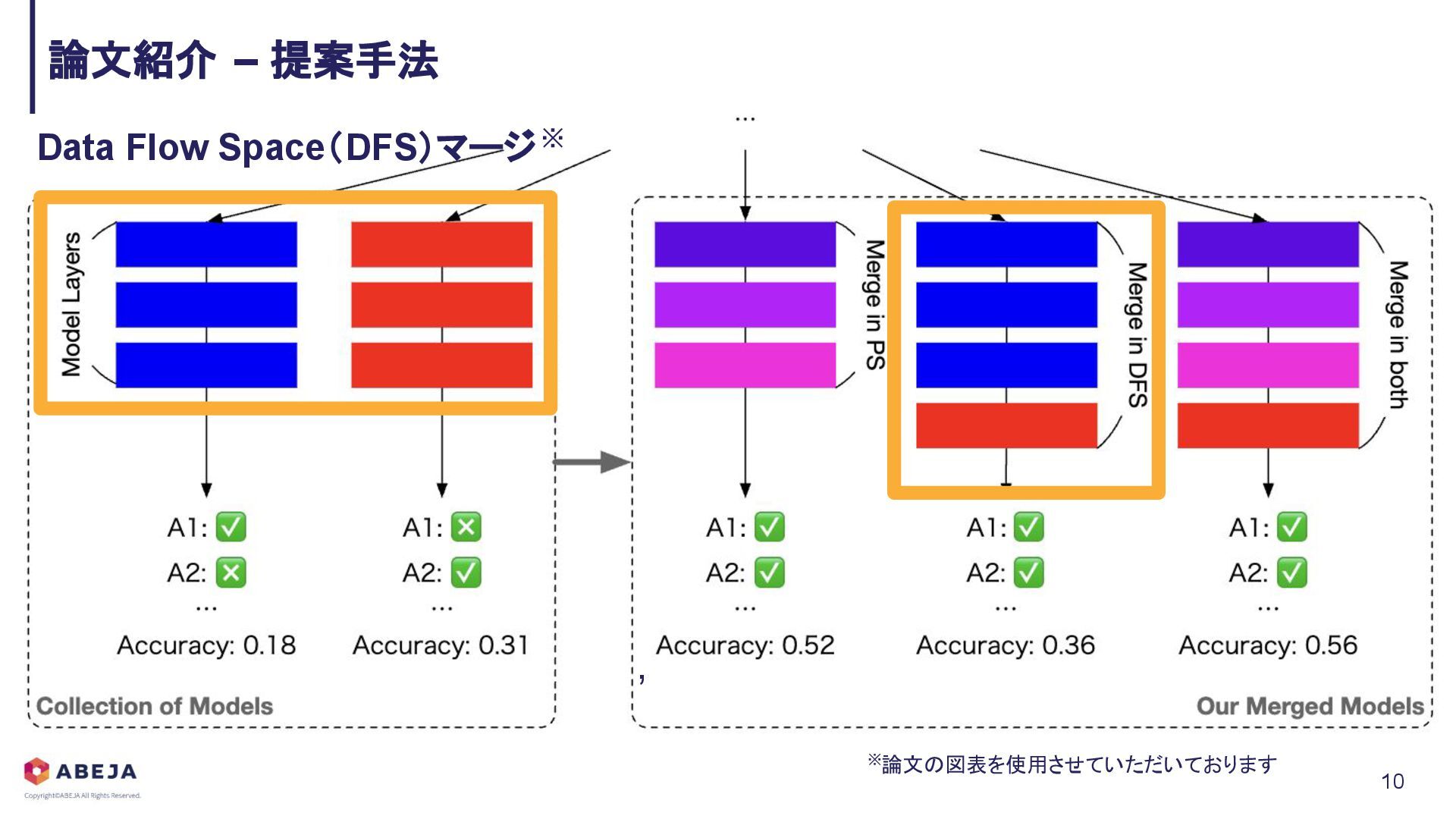{kind=link}
{kind=link}
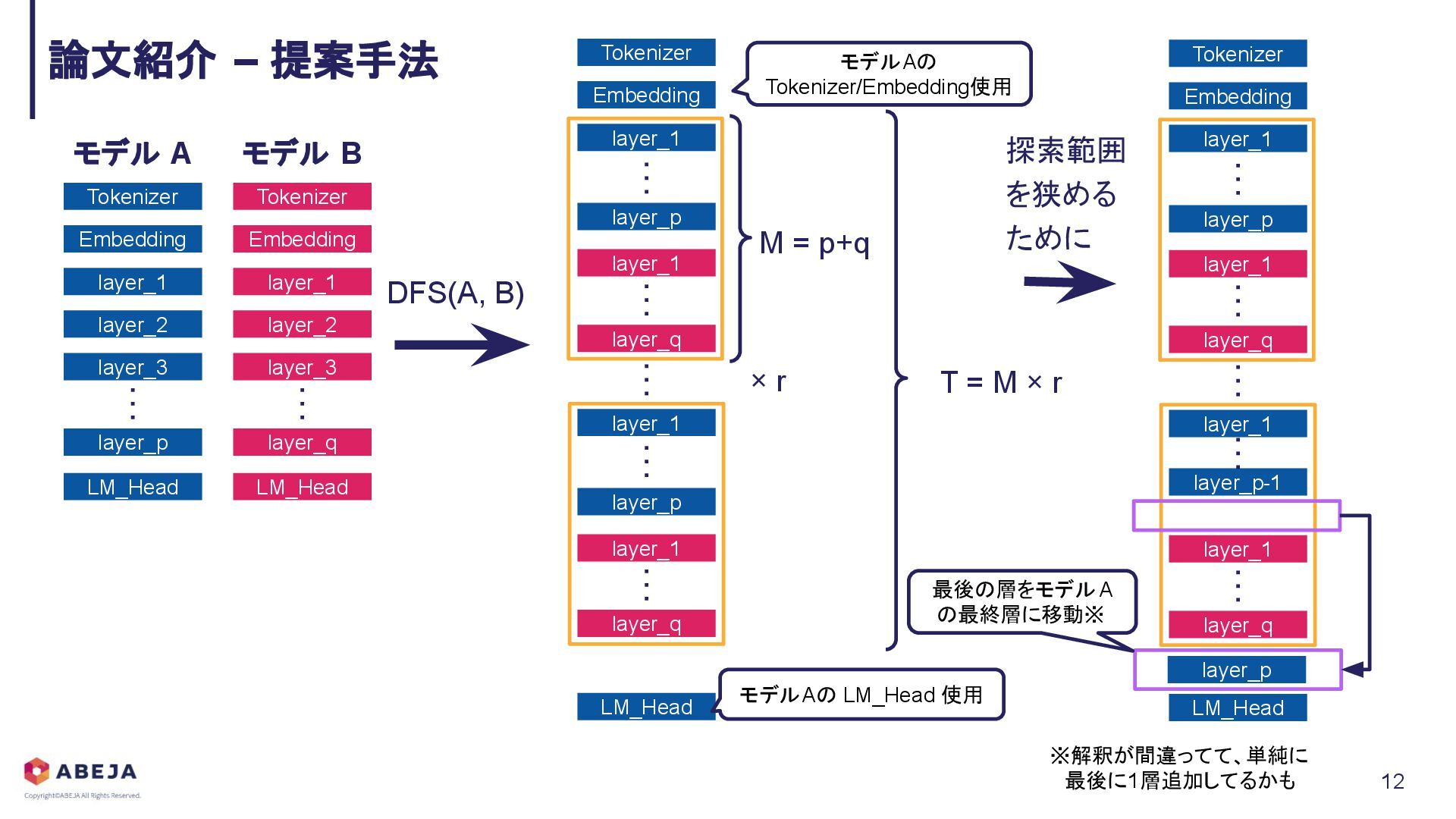{kind=link}
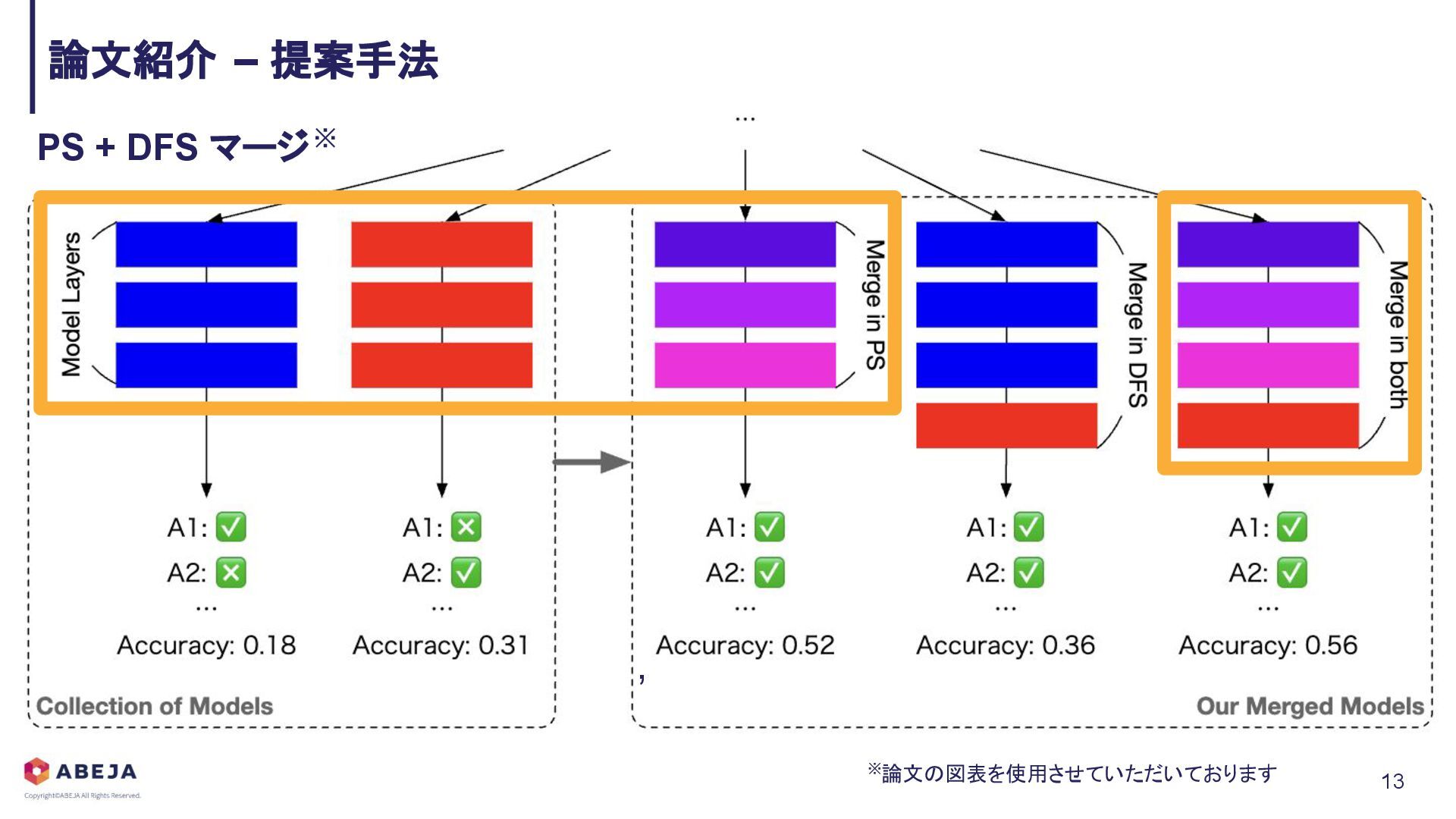{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
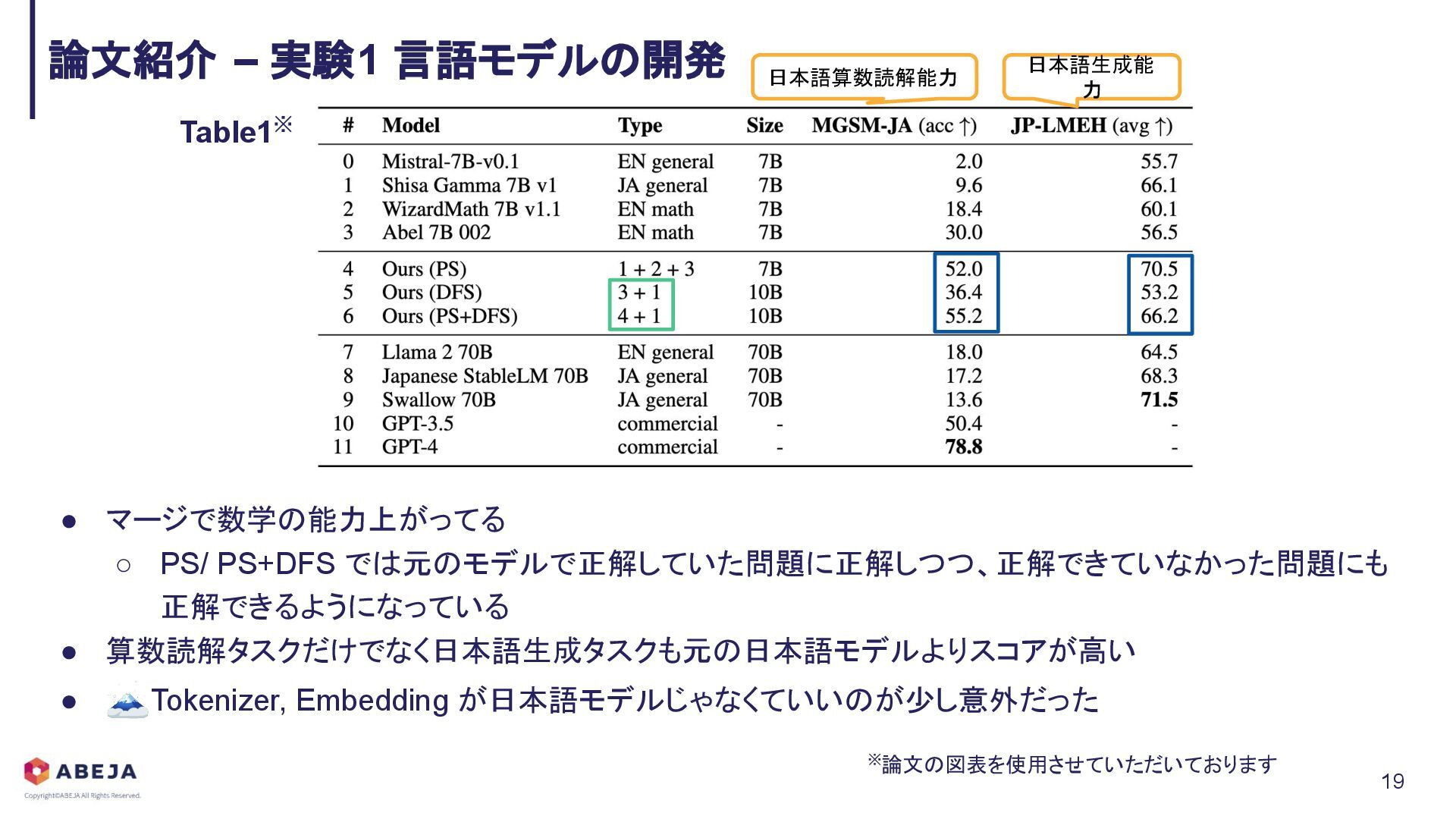{kind=link}
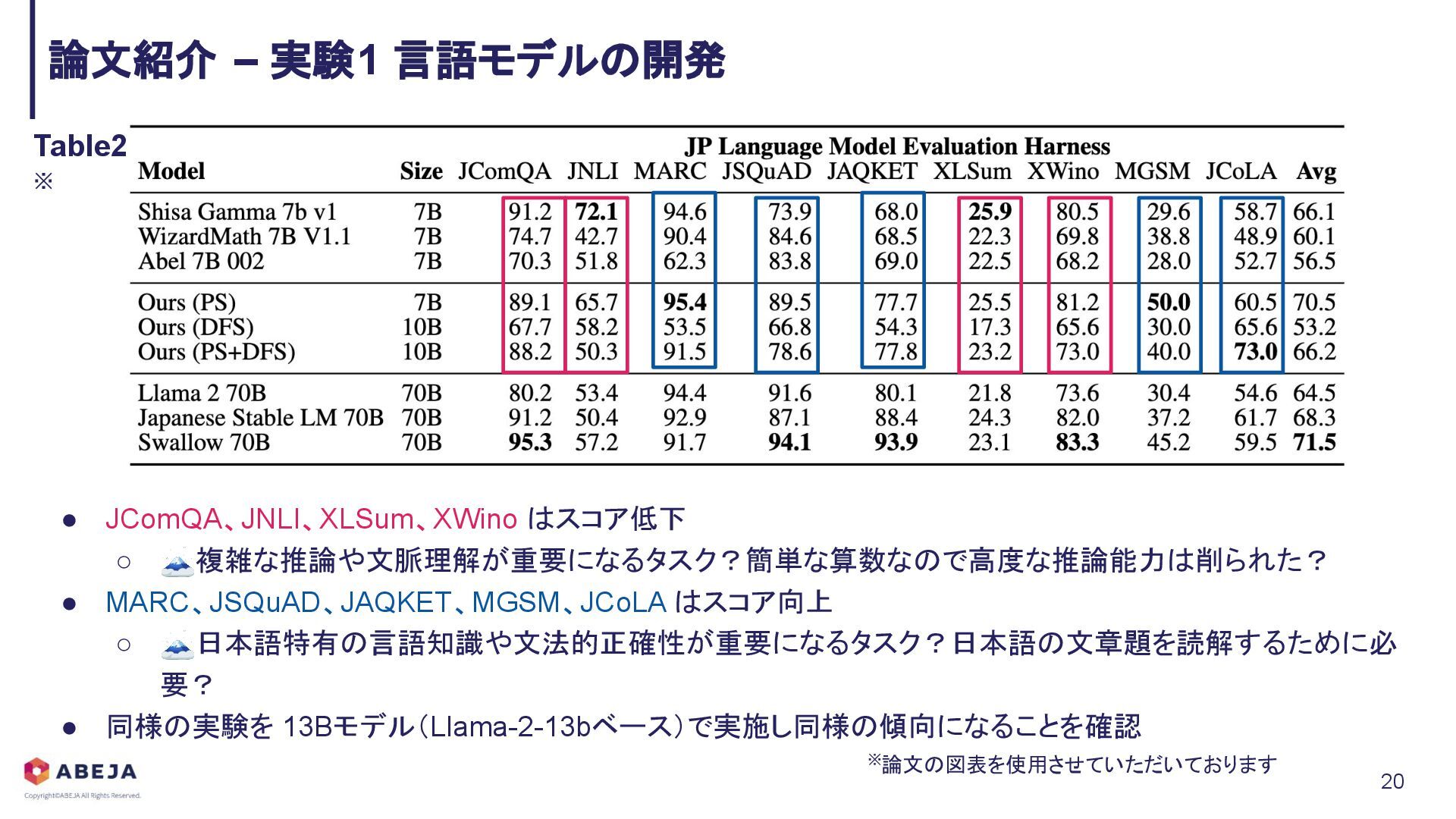{kind=link}
{kind=link}
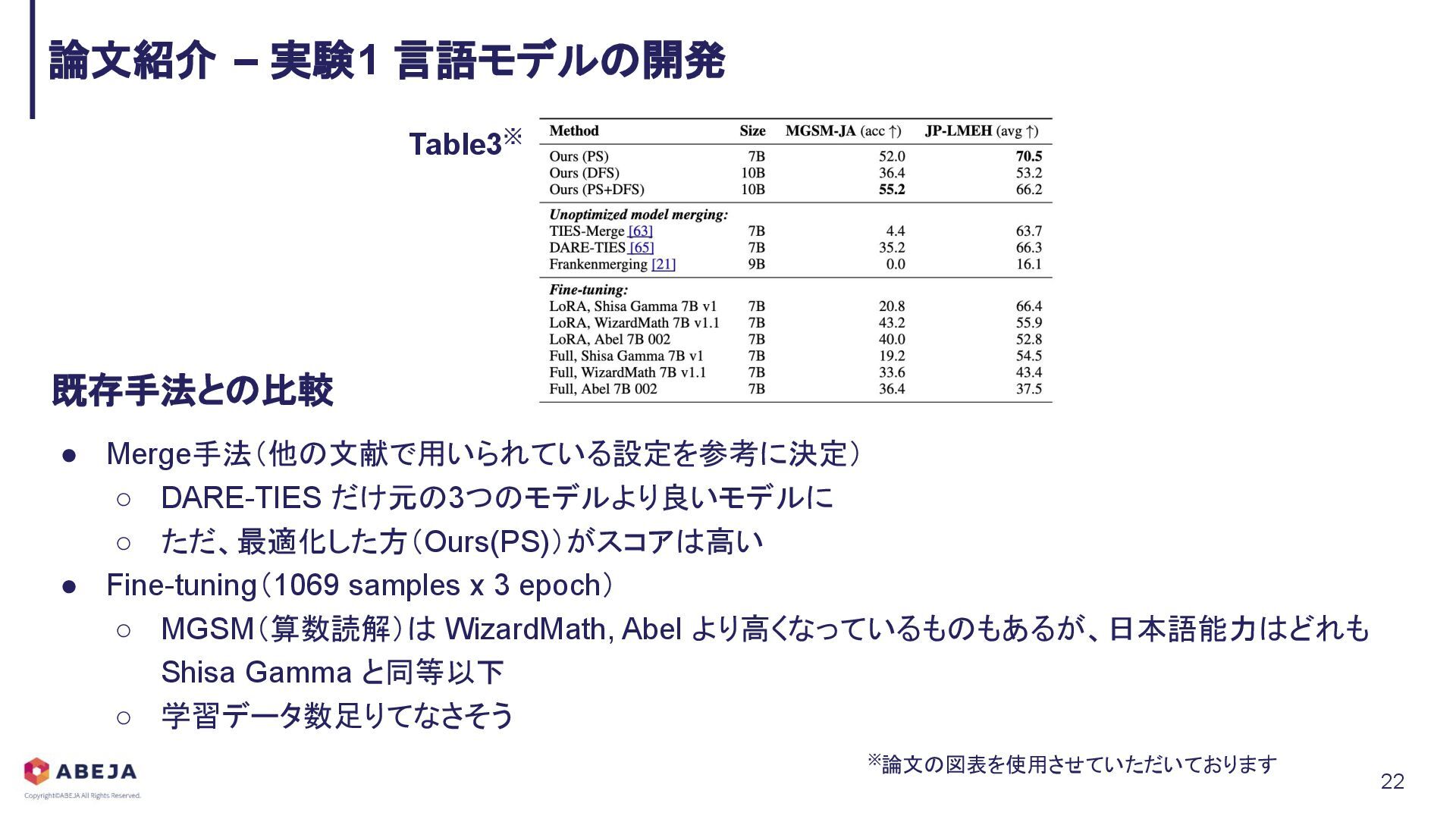{kind=link}
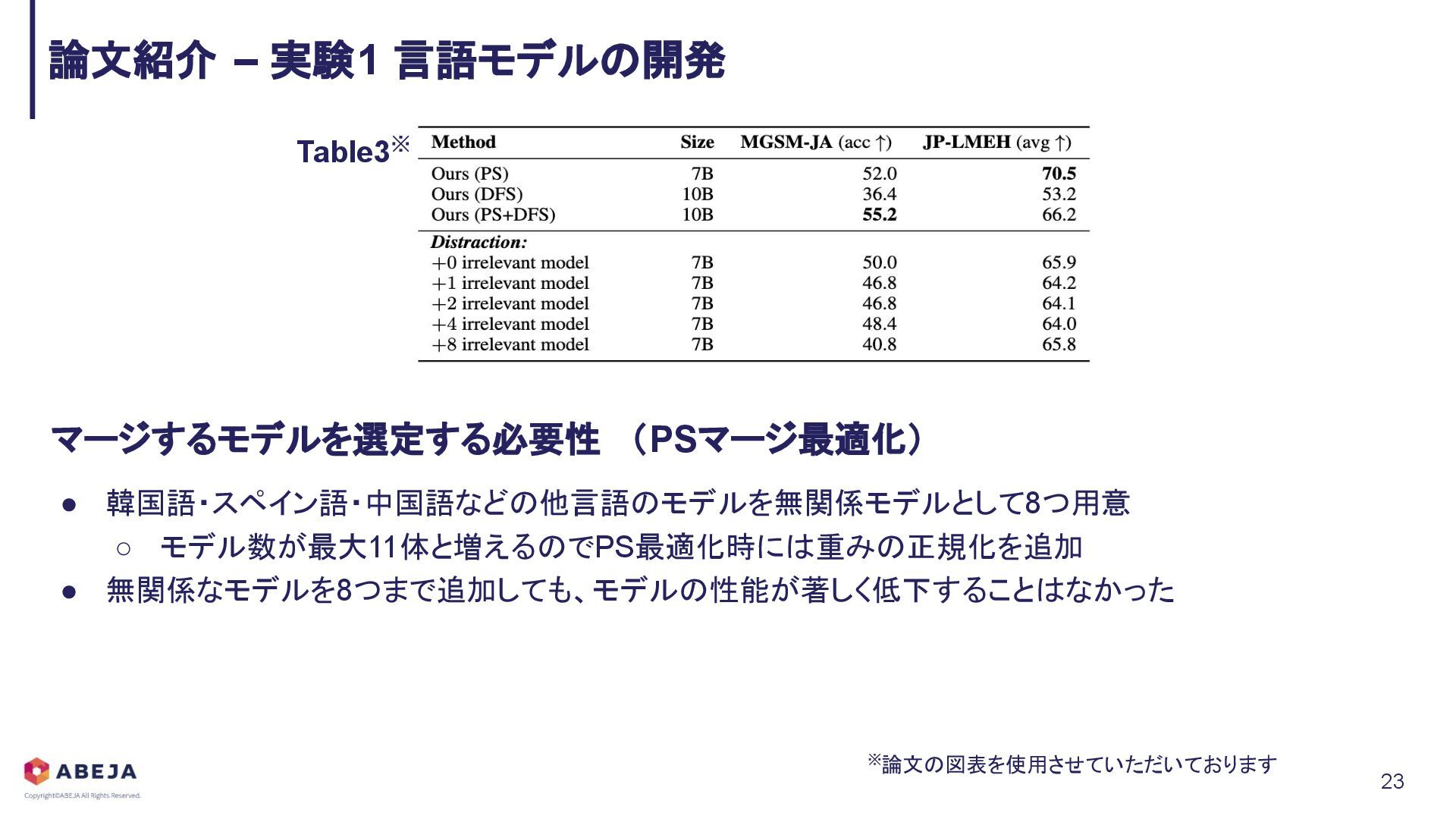{kind=link}
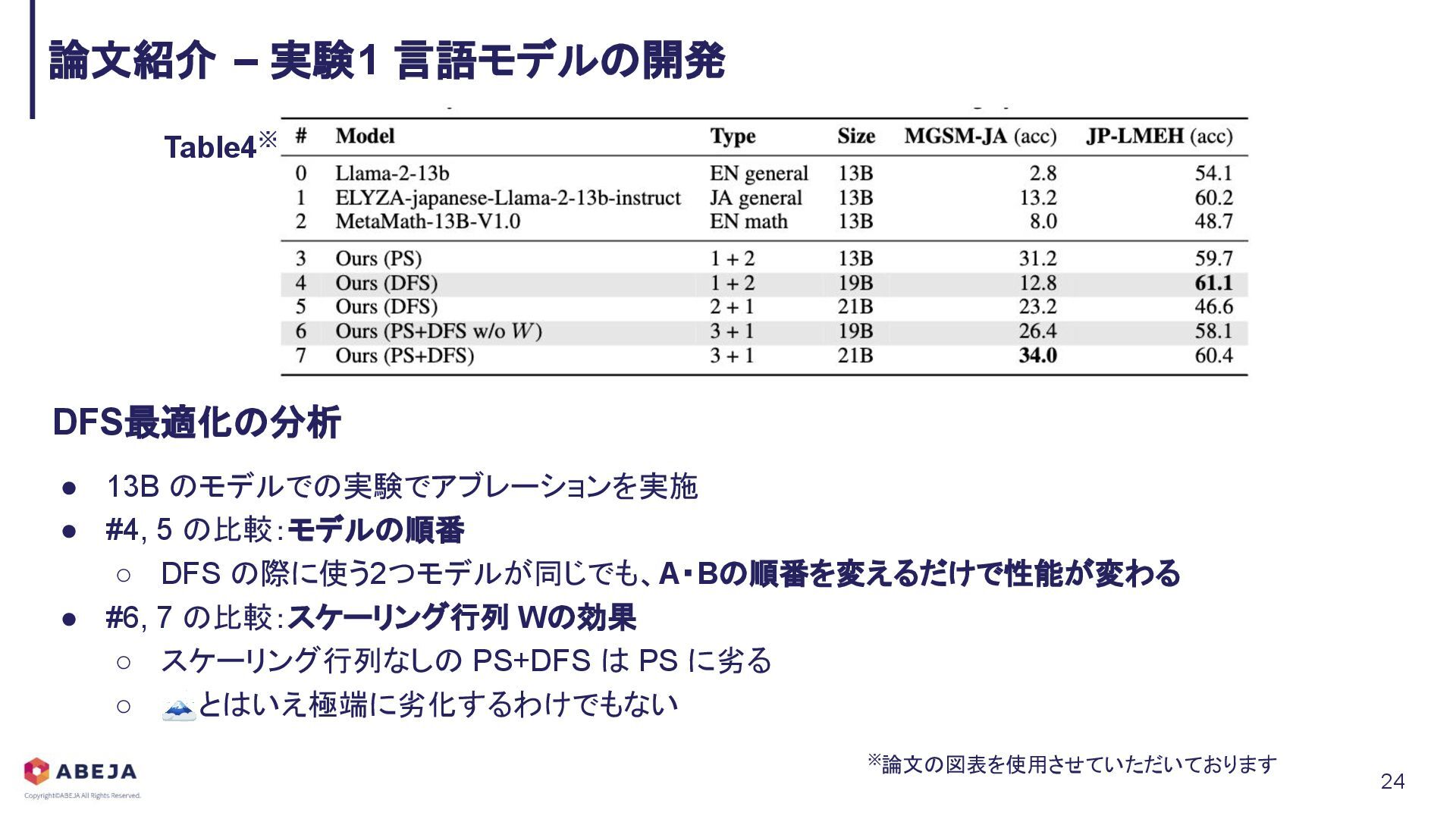{kind=link}
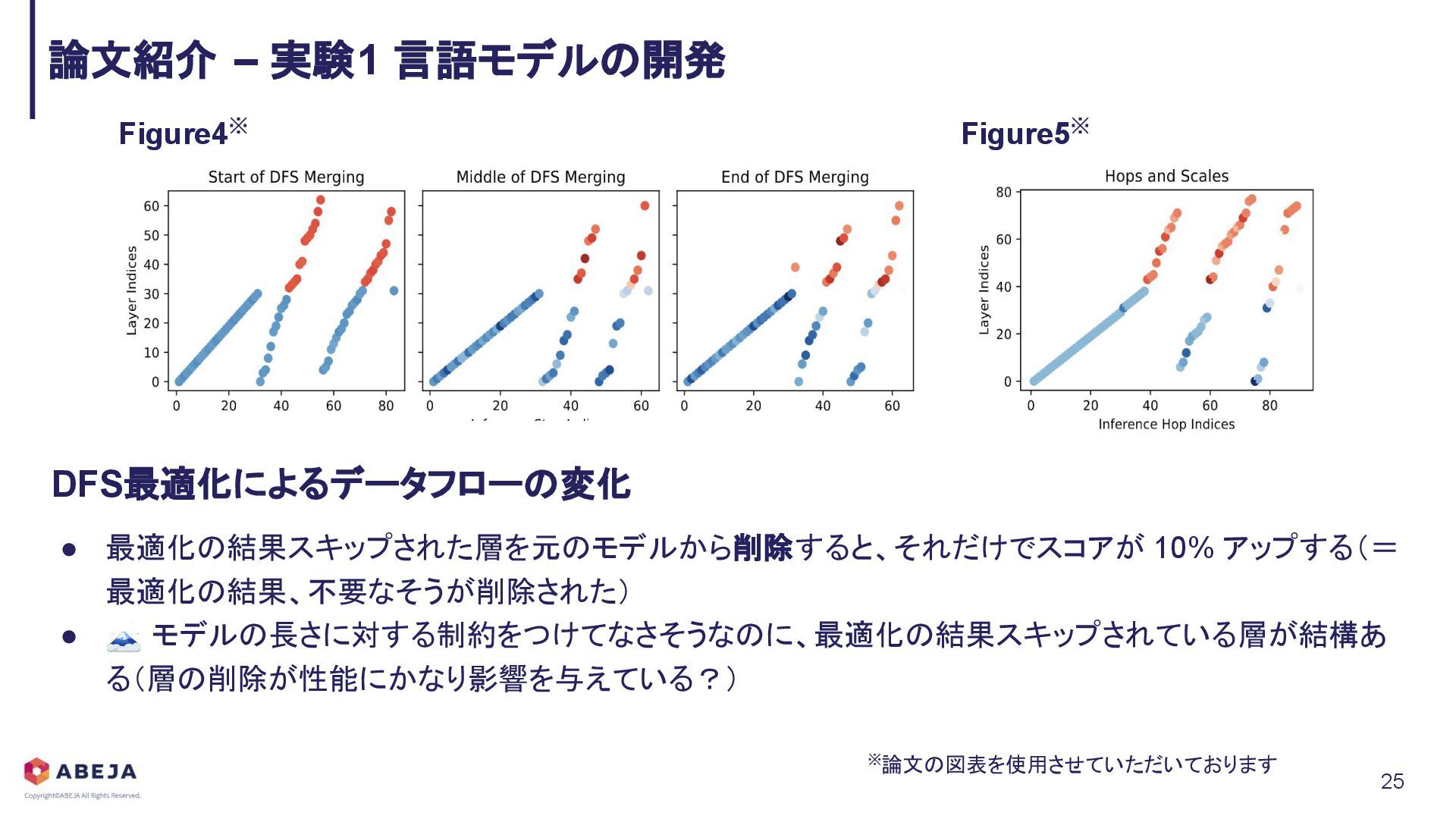{kind=link}
{kind=link}
{kind=link}
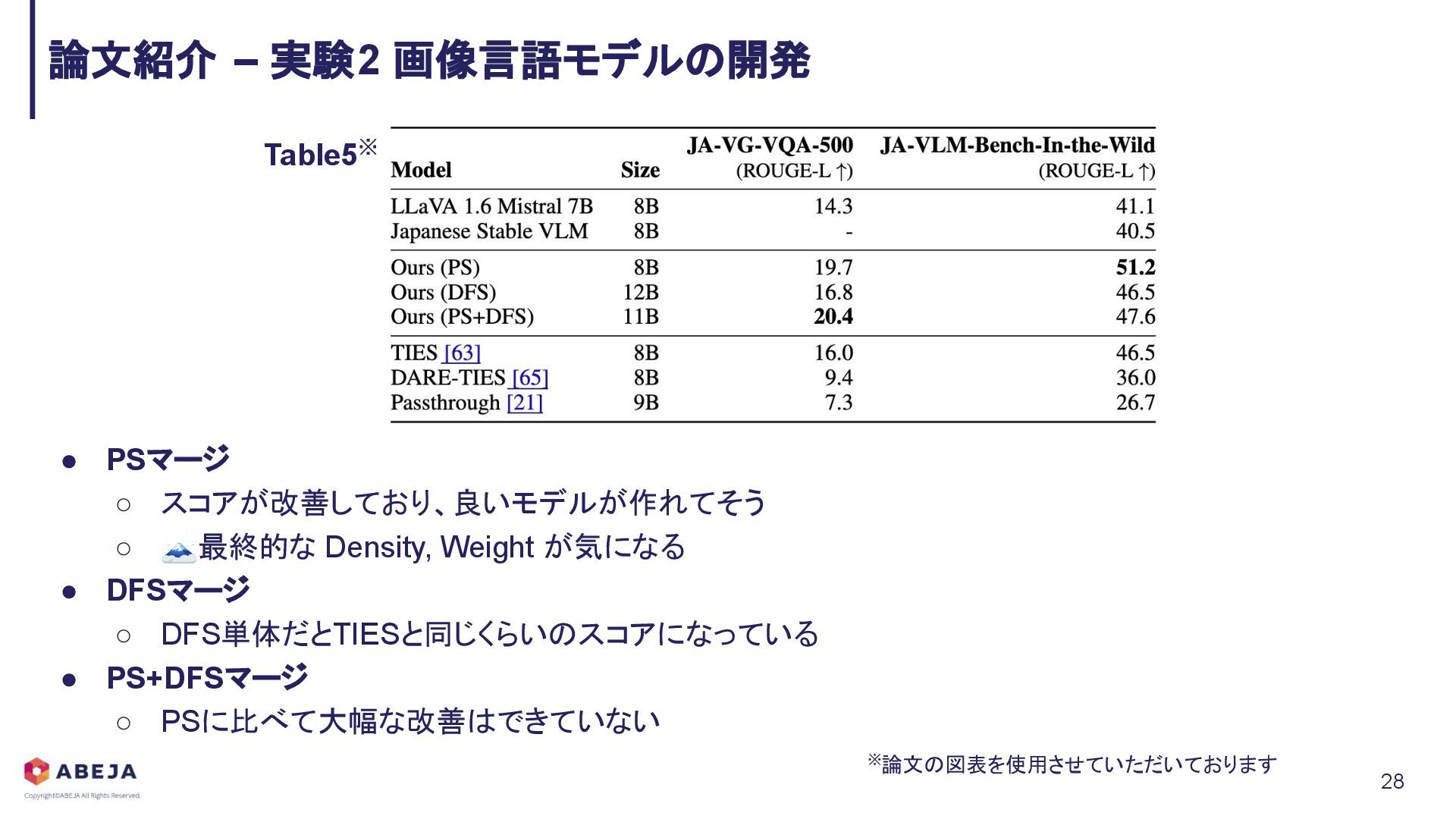{kind=link}
{kind=link}
{kind=link}