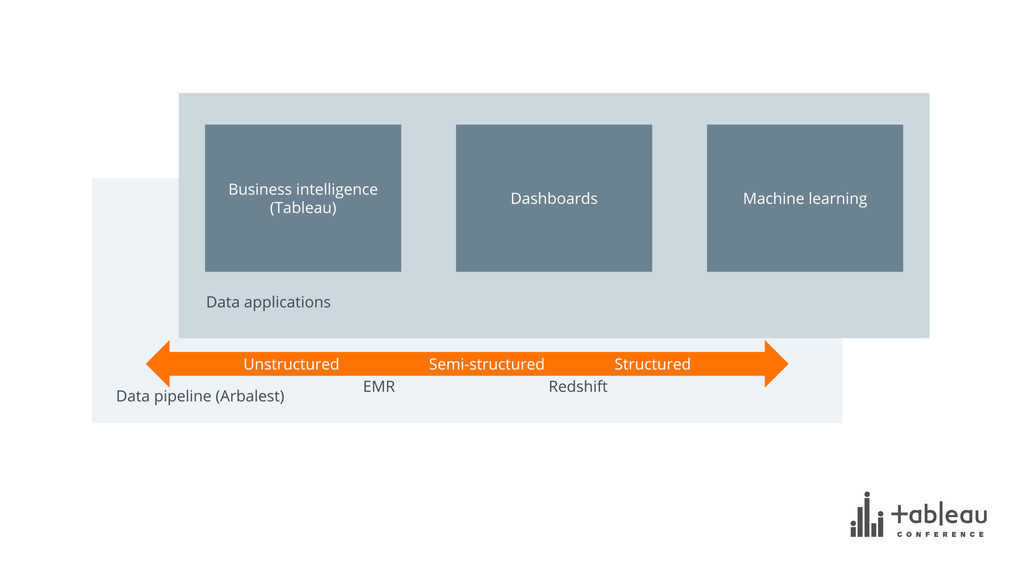
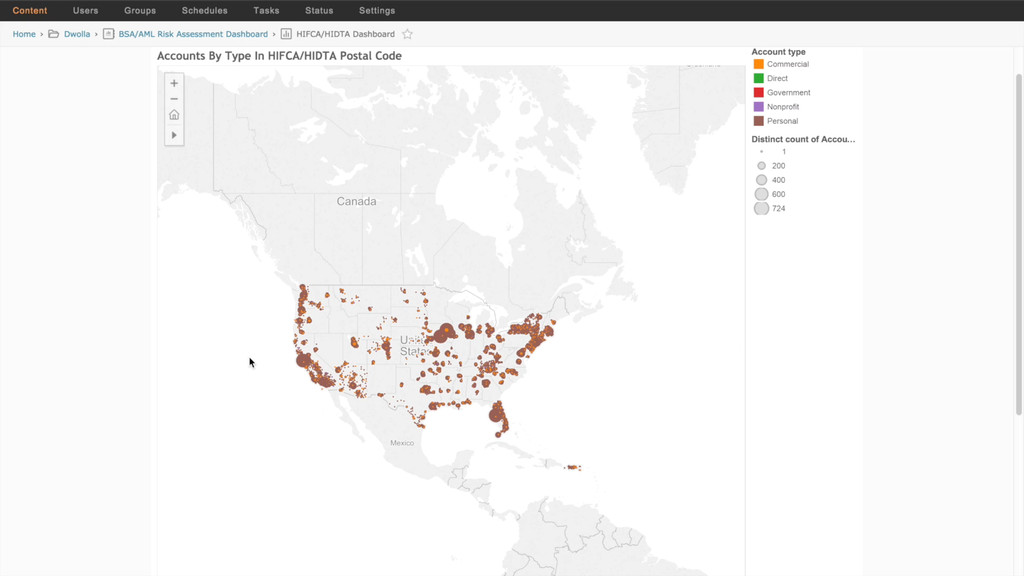
Events are the atomic building blocks of data. This is definitely the case at Dwolla, a payments company that allows anyone (or anything) connected to the internet to move money quickly, safely, and at the lowest cost possible. This session is a deep dive into how Dwolla manages events and data of all shapes and sizes using Amazon Web Services (EC2, EMR, RDS, Redshift, S3) and Tableau. This also introduces Dwolla's open source data pipeline orchestration tool, Arbalest (https://github.com/Dwolla/arbalest), to process all this data at scale. [This presentation was presented at the MGM Grand in Las Vegas for Tableau 15, Oct. 21, 2015.]
{kind=link}
![Software Developer, Data & Analytics Technical Lead [email protected] @wayoutmind](https://files.speakerdeck.com/presentations/dc3fad0564eb46b4853e507196076f9f/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
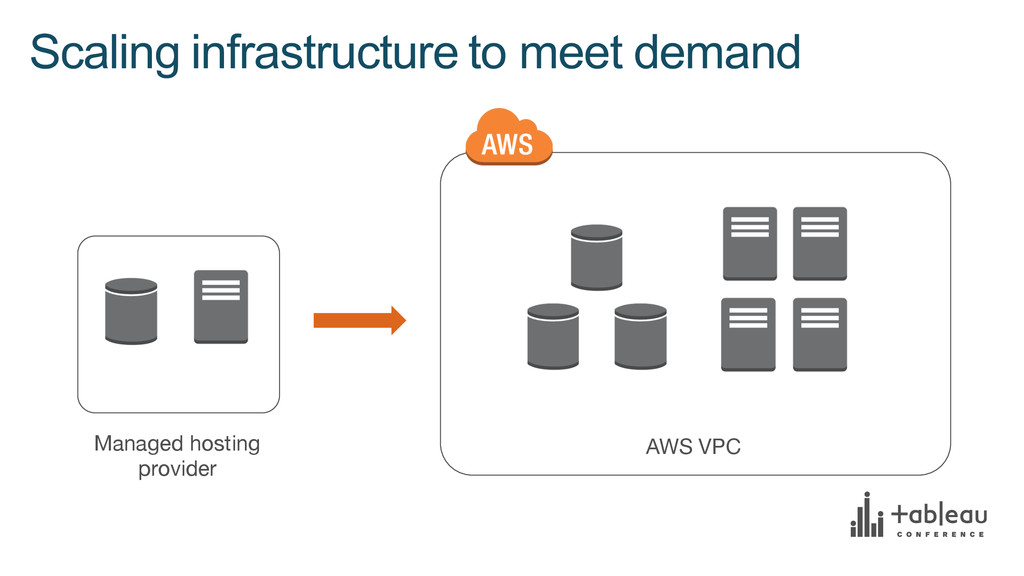{kind=link}
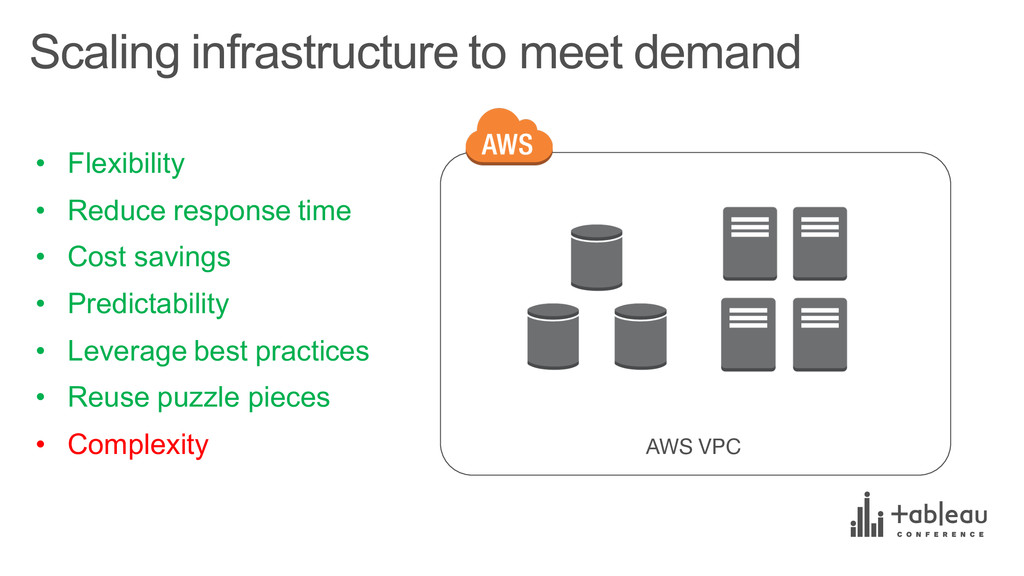{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
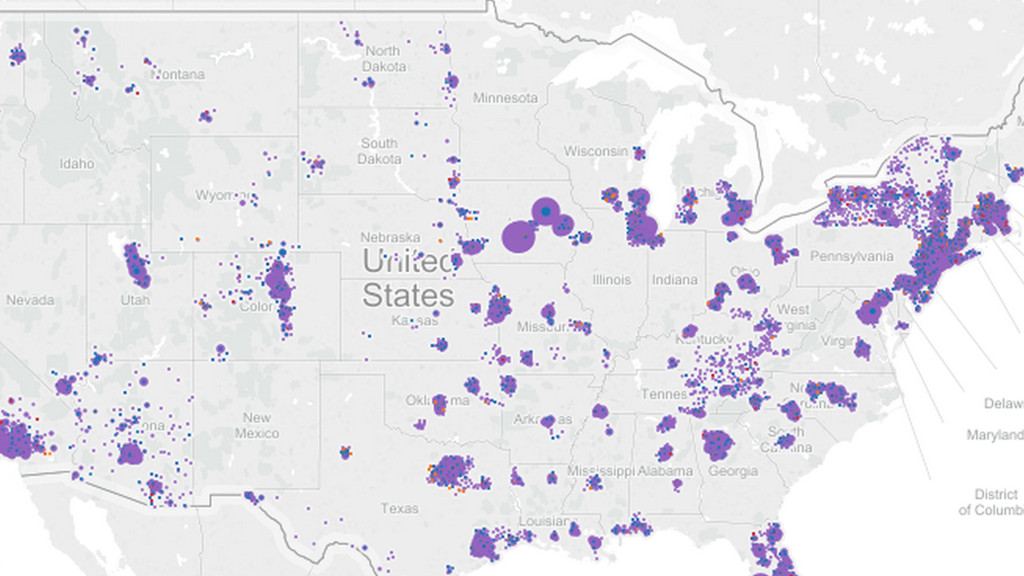{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![State Transition With Events user.created { “email_address”: “[email protected]”, “timestamp”: “2015-‐08-‐18T06:36:40Z”](https://files.speakerdeck.com/presentations/dc3fad0564eb46b4853e507196076f9f/slide_33.jpg){kind=link}
![Context Specific Event Values user.created { “email_address”: “[email protected]”, “timestamp”: “2015-‐08-‐18T06:36:40Z”](https://files.speakerdeck.com/presentations/dc3fad0564eb46b4853e507196076f9f/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
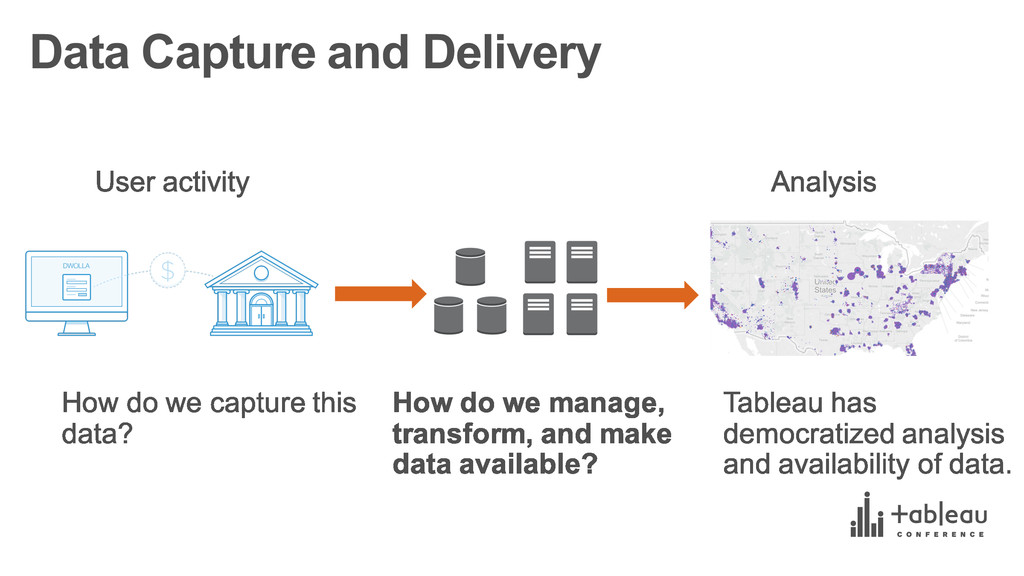{kind=link}
{kind=link}
{kind=link}
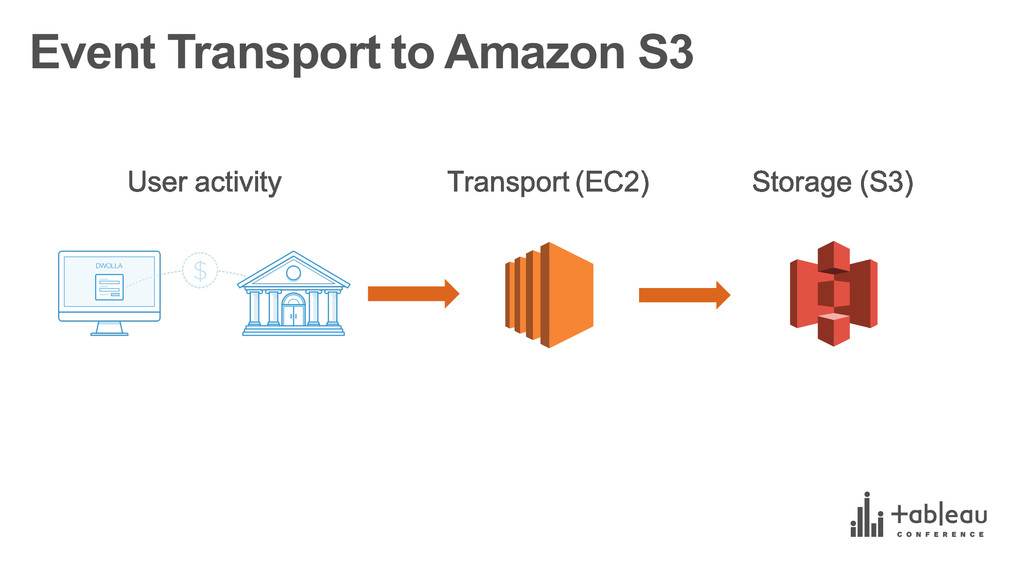{kind=link}
![Event Payload s3://bucket-‐name/[event name]/[yyyy-‐MM-‐dd]/[hh]/eventId s3://bucket-‐name/user.created/2015-‐08-‐18/06/ {“email_address”: “[email protected]”, “timestamp”:](https://files.speakerdeck.com/presentations/dc3fad0564eb46b4853e507196076f9f/slide_42.jpg){kind=link}
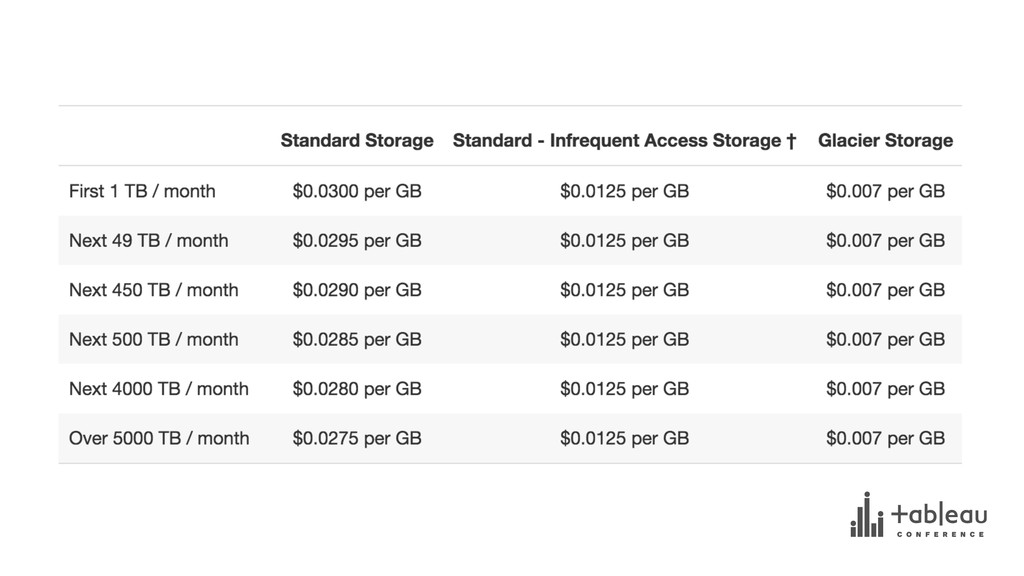{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
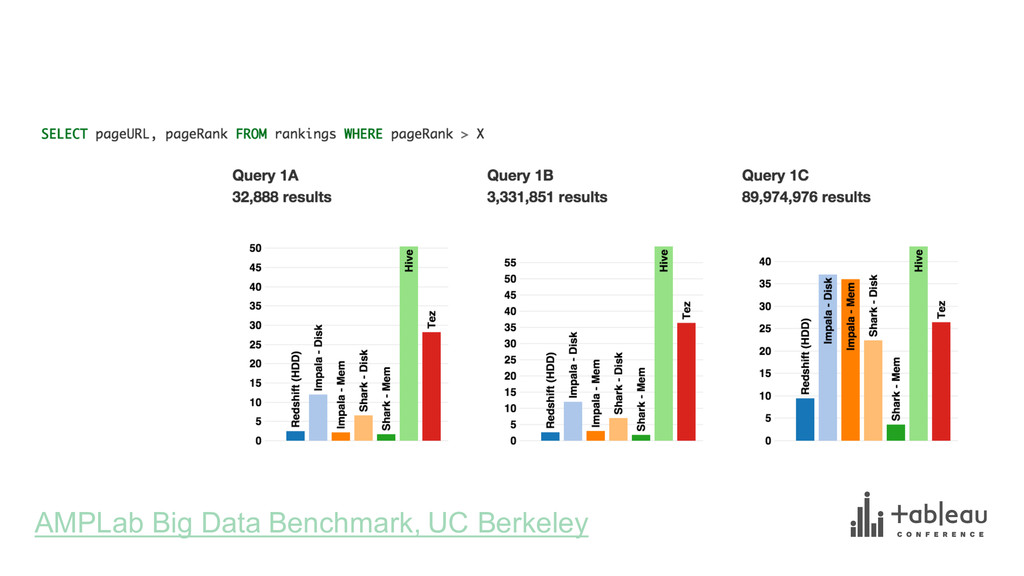{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[email protected] github.com/dwolla/arbalest](https://files.speakerdeck.com/presentations/dc3fad0564eb46b4853e507196076f9f/slide_65.jpg){kind=link}
{kind=link}
{kind=link}