Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
2024-02-Tokyo-Tech-大規模言語モデルの事前学習知見
Search
Kazuki Fujii
December 15, 2025
Research
40
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
2024-02-Tokyo-Tech-大規模言語モデルの事前学習知見
Kazuki Fujii
December 15, 2025
More Decks by Kazuki Fujii
See All by Kazuki Fujii
IHPCSS2025-Kazuki-Fujii
fujiikazuki2000
0
32
情報処理学会-全国大会2024-大規模言語モデルの分散並列学習
fujiikazuki2000
0
37
言語処理学会2024-継続事前学習による日本語に強い大規模言語モデルの構築
fujiikazuki2000
0
56
AWS Summit Japan 2025 Amazon SageMaker HyperPodを利用した日本語LLM(Swallow)の構築 (CUS-02)
fujiikazuki2000
0
51
合成データパイプラインを利用したSwallowProjectに おけるLLM性能向上
fujiikazuki2000
1
300
論文では語られないLLM開発において重要なこと Swallow Projectを通して
fujiikazuki2000
8
2k
大規模言語モデルの学習知見
fujiikazuki2000
0
210
自然言語処理のための分散並列学習
fujiikazuki2000
1
730
Other Decks in Research
See All in Research
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
430
Visual SLAM未来予測 / Future Prediction in Visual SLAM
koide3
1
720
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
290
Using our influence and power for patient safety
helenbevan
0
370
COMETAを用いたデータ民主化運動の歴史
sazimai
0
130
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
350
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
590
Claude Code × autoresearch 実践
mathbullet
0
210
nlp2026 In-Context Learningに基づく経路案内のための地理的知識の活用方法に関する検討
takashiinui
0
110
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
460
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
7
3.6k
Featured
See All Featured
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
sira's awesome portfolio website redesign presentation
elsirapls
0
310
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
420
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.3k
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Documentation Writing (for coders)
carmenintech
77
5.4k
Embracing the Ebb and Flow
colly
88
5.1k
30 Presentation Tips
portentint
PRO
1
350
Designing Experiences People Love
moore
143
24k
The Spectacular Lies of Maps
axbom
PRO
1
870
Typedesign – Prime Four
hannesfritz
42
3.1k
Transcript
⼤規模⾔語モデルの 事前学習知⾒ 東京工業大学 情報理工学院 情報工学系 横田理央研究室 藤井 一喜
2 自己紹介: 藤井 一喜 • 東京工業大学 横田理央 研究室 所属 •
Turing Inc. Brain Research Team Intern • Kotoba Tech Research Intern
3 取り組み LLM-jp Swallow LLM-jp 13B v 1.0, 2.0 LLM-jp
175B v.0.0 LLM-jp 175B v1.0 (2024年4月より) Swallow Llama 7B, 13B, 70B Swallow Mistral 7B Swallow Mixtral 8x7B
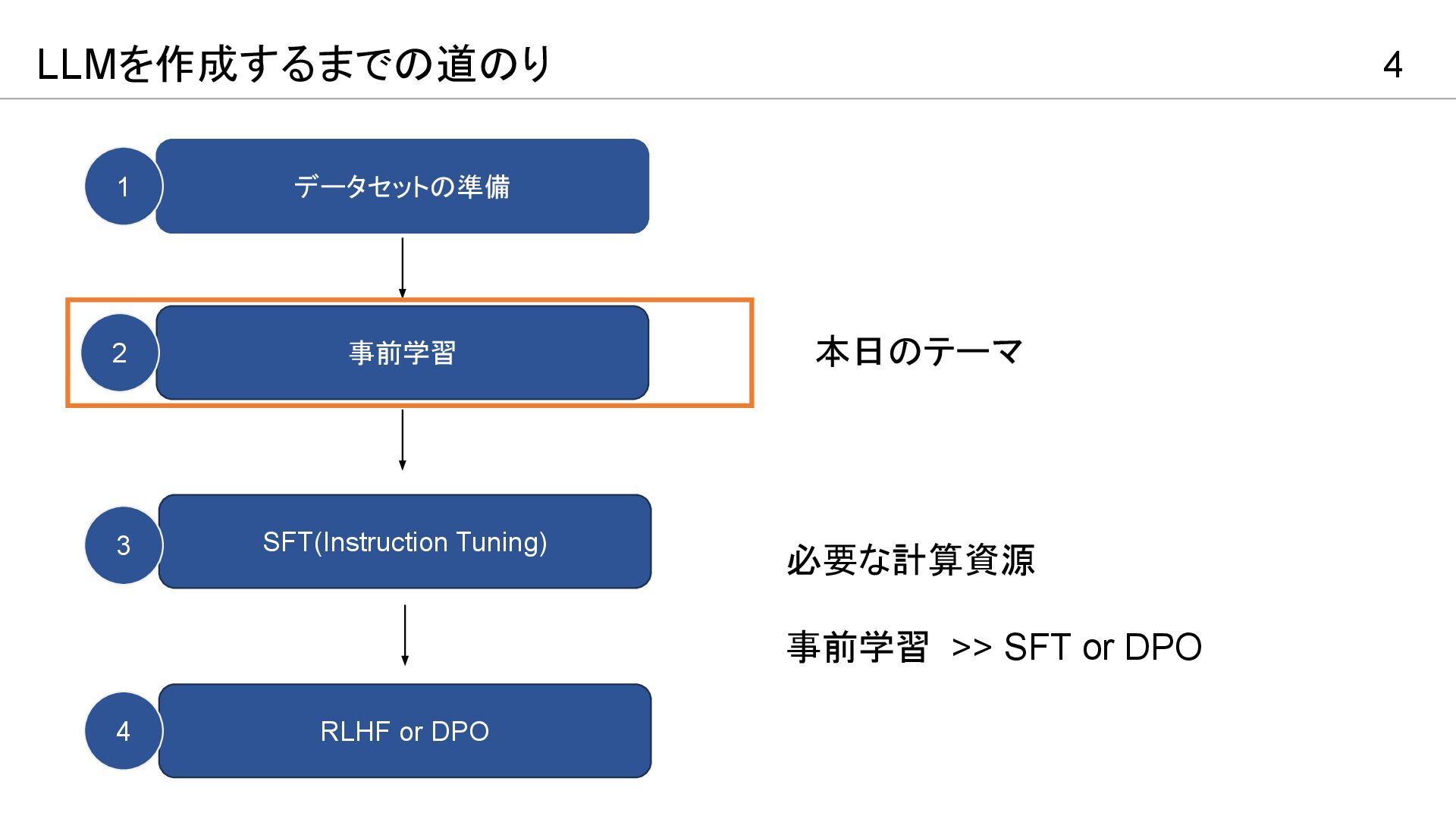
4 LLMを作成するまでの道のり データセットの準備 事前学習 SFT(Instruction Tuning) RLHF or DPO 1
2 3 4 必要な計算資源 事前学習 >> SFT or DPO 本日のテーマ
5 事前学習で考えるべきこと • モデルアーキテクチャ • 活性化関数: ReLU, GeLU, SwiGLU •
Normalization: LayerNorm, RMSNorm • Loss関数: CrossEntropyLoss, Z-Loss • Attention: MHA, GQA • Positional Encoding: RoPE • パラメーターサイズ • ライブラリの選定 or 開発 • 分散学習設定 • FSDP vs. 3D Parallelism • DP, TP, PPのバランス 本日のテーマ
6 LLMの事前学習を支えるライブラリ
7 Megatron-LM LLM-jp, Swallow Project にて採用 • 30B以上のモデルの学習 • from
scratch学習 • H100環境 • 分散並列学習の知見がある方 → Megatron-LM
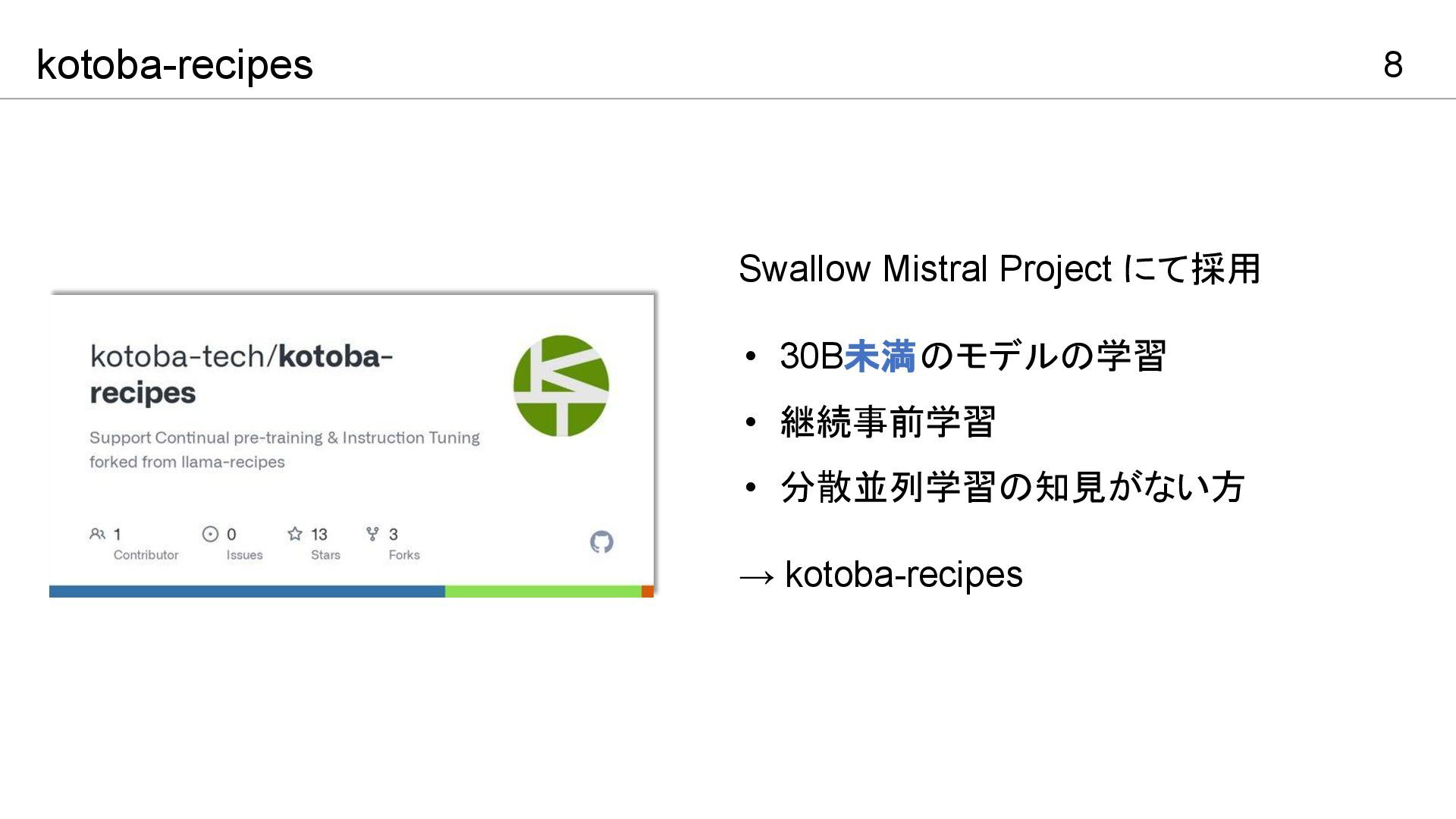
8 kotoba-recipes Swallow Mistral Project にて採用 • 30B未満のモデルの学習 • 継続事前学習
• 分散並列学習の知見がない方 → kotoba-recipes
9 ライブラリの使い方
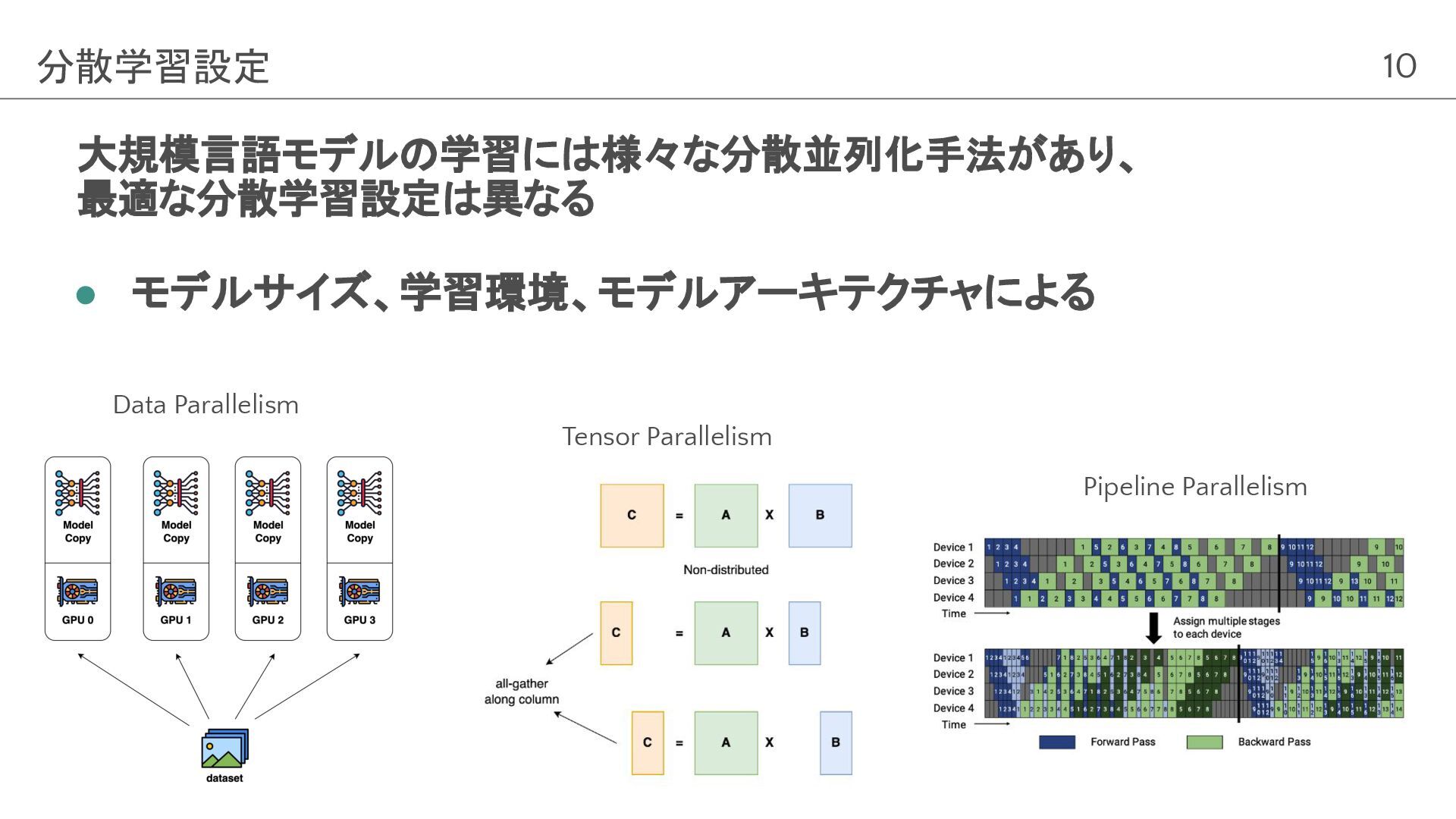
10 大規模言語モデルの学習には様々な分散並列化手法があり、 最適な分散学習設定は異なる • モデルサイズ、学習環境、モデルアーキテクチャによる 分散学習設定 Data Parallelism Tensor Parallelism
Pipeline Parallelism
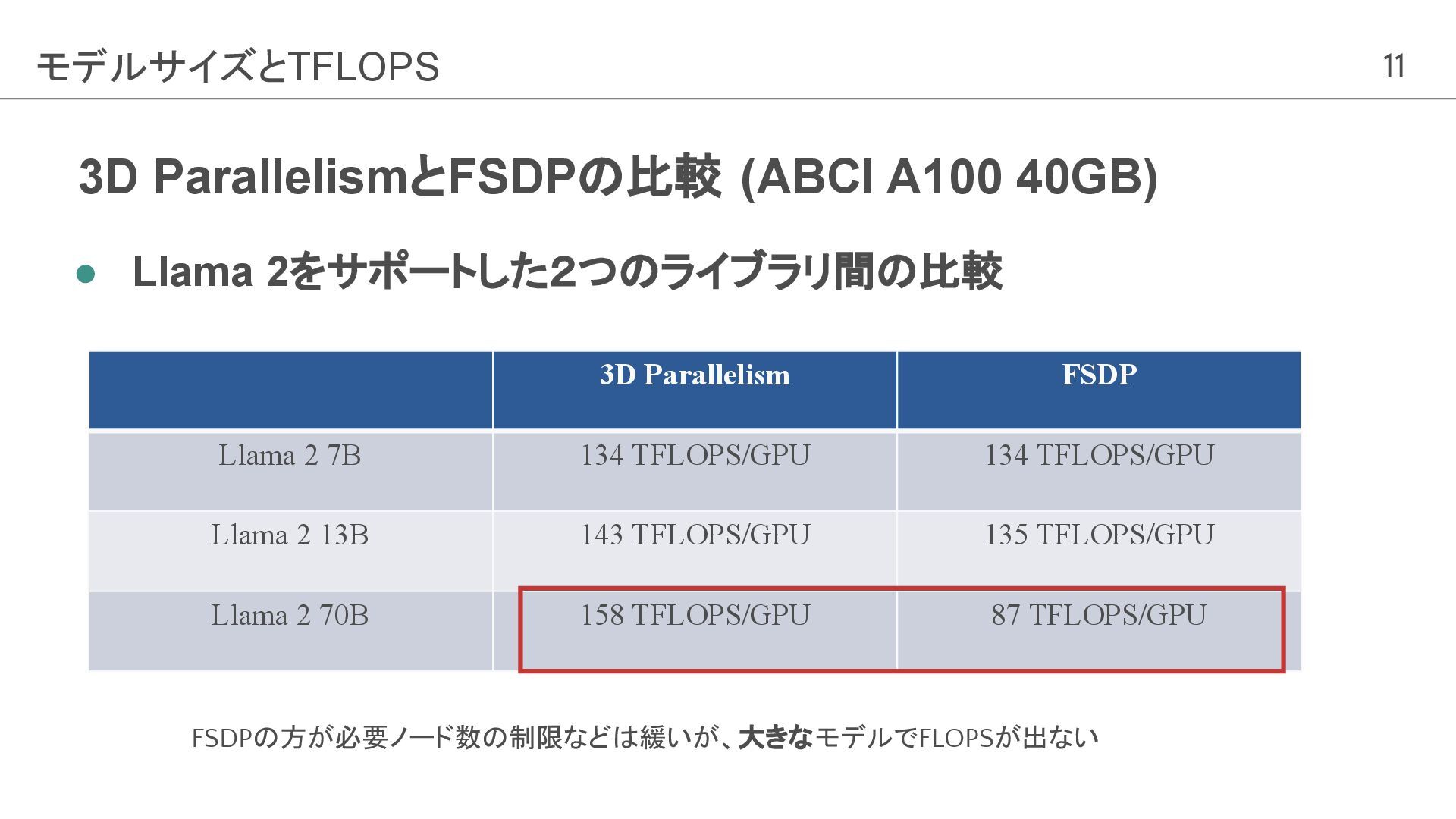
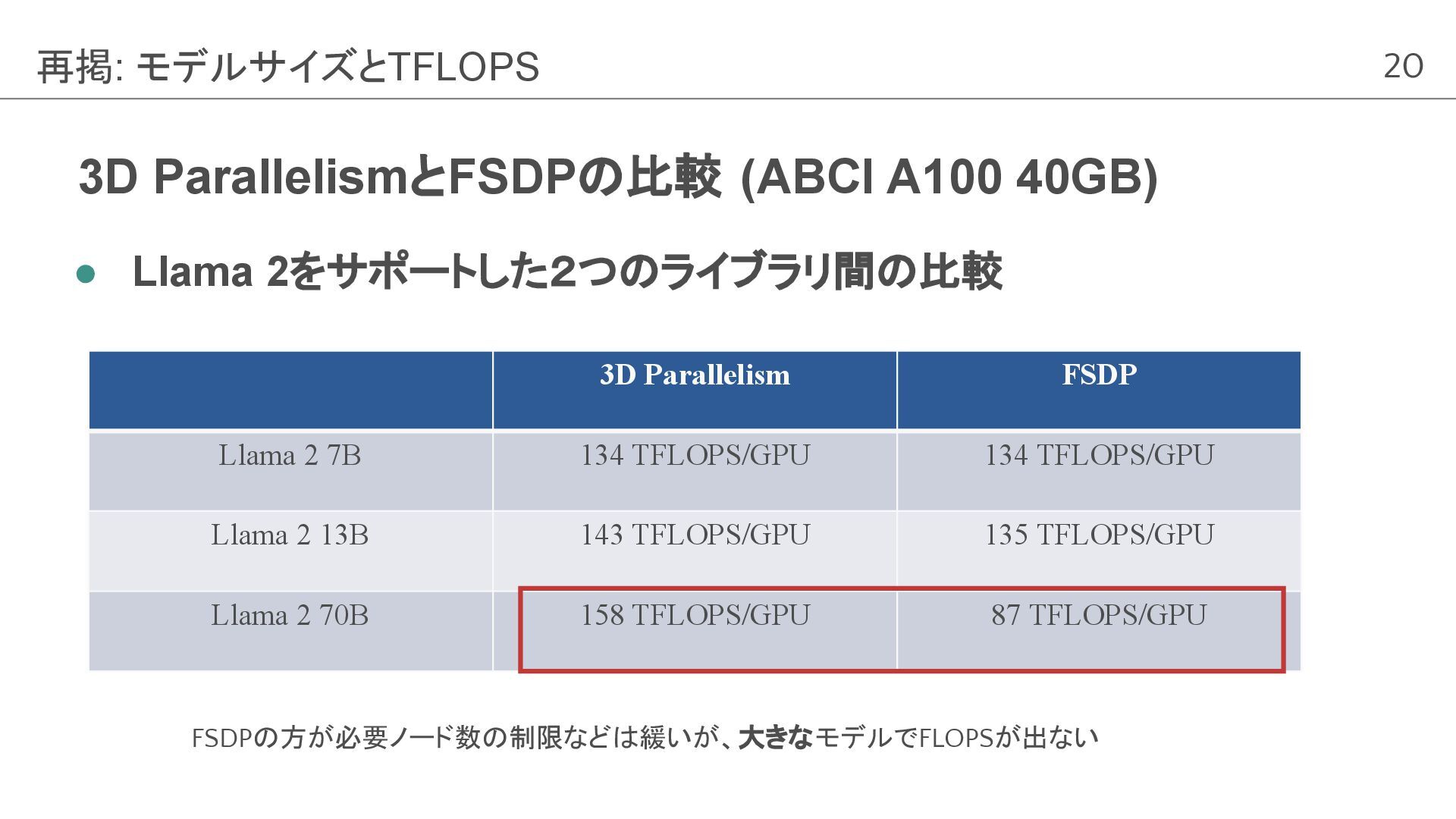
11 3D ParallelismとFSDPの比較 (ABCI A100 40GB) • Llama 2をサポートした2つのライブラリ間の比較 モデルサイズとTFLOPS
3D Parallelism FSDP Llama 2 7B 134 TFLOPS/GPU 134 TFLOPS/GPU Llama 2 13B 143 TFLOPS/GPU 135 TFLOPS/GPU Llama 2 70B 158 TFLOPS/GPU 87 TFLOPS/GPU FSDPの方が必要ノード数の制限などは緩いが、大きなモデルでFLOPSが出ない
12 LLMの事前学習における分散学習の重要性 適切な分散学習設定を用いると 学習効率が 2, 3倍変わる 計算資源は有限 試行回数を稼ぐため 学習トークン数を多くするため →
分散学習設定 をきちんと考えるべき
13 分散学習設定を考えるために把握するべきこと 1. 使用できるGPU数を把握する クラウドであればマルチノード化できるのか? 2. ノード間の通信速度、ノード内のGPU間通信速度 InfiniBandはあるのか? nccl-testsの結果は? NVLinkは有効か?
https://www.nvidia.com/ja-jp/data-center/nvlink/ より
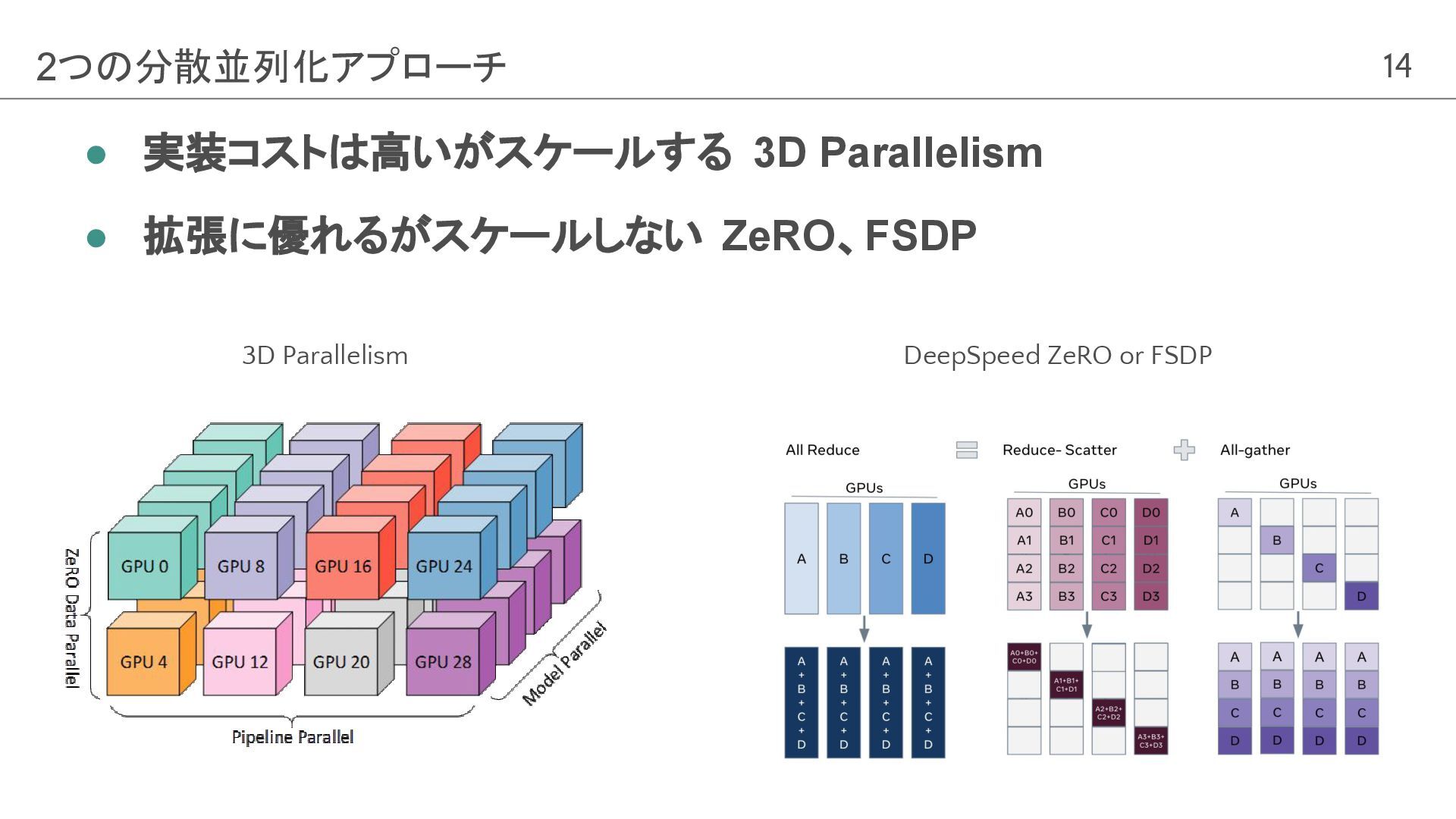
14 2つの分散並列化アプローチ 3D Parallelism DeepSpeed ZeRO or FSDP • 実装コストは高いがスケールする
3D Parallelism • 拡張に優れるがスケールしない ZeRO、FSDP
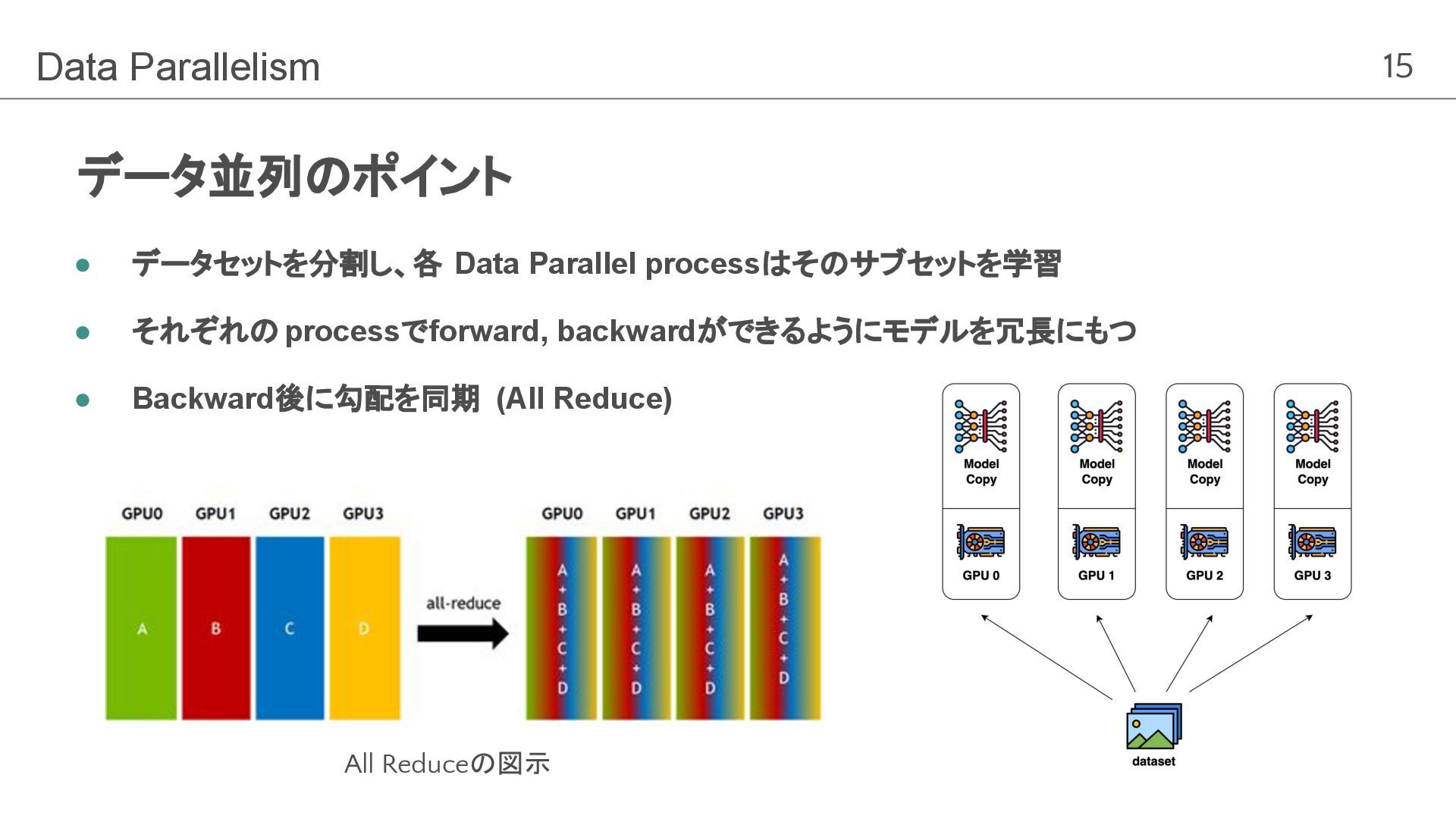
15 データ並列のポイント Data Parallelism • データセットを分割し、各 Data Parallel processはそのサブセットを学習 •
それぞれの processでforward, backwardができるようにモデルを冗長にもつ • Backward後に勾配を同期 (All Reduce) All Reduceの図示
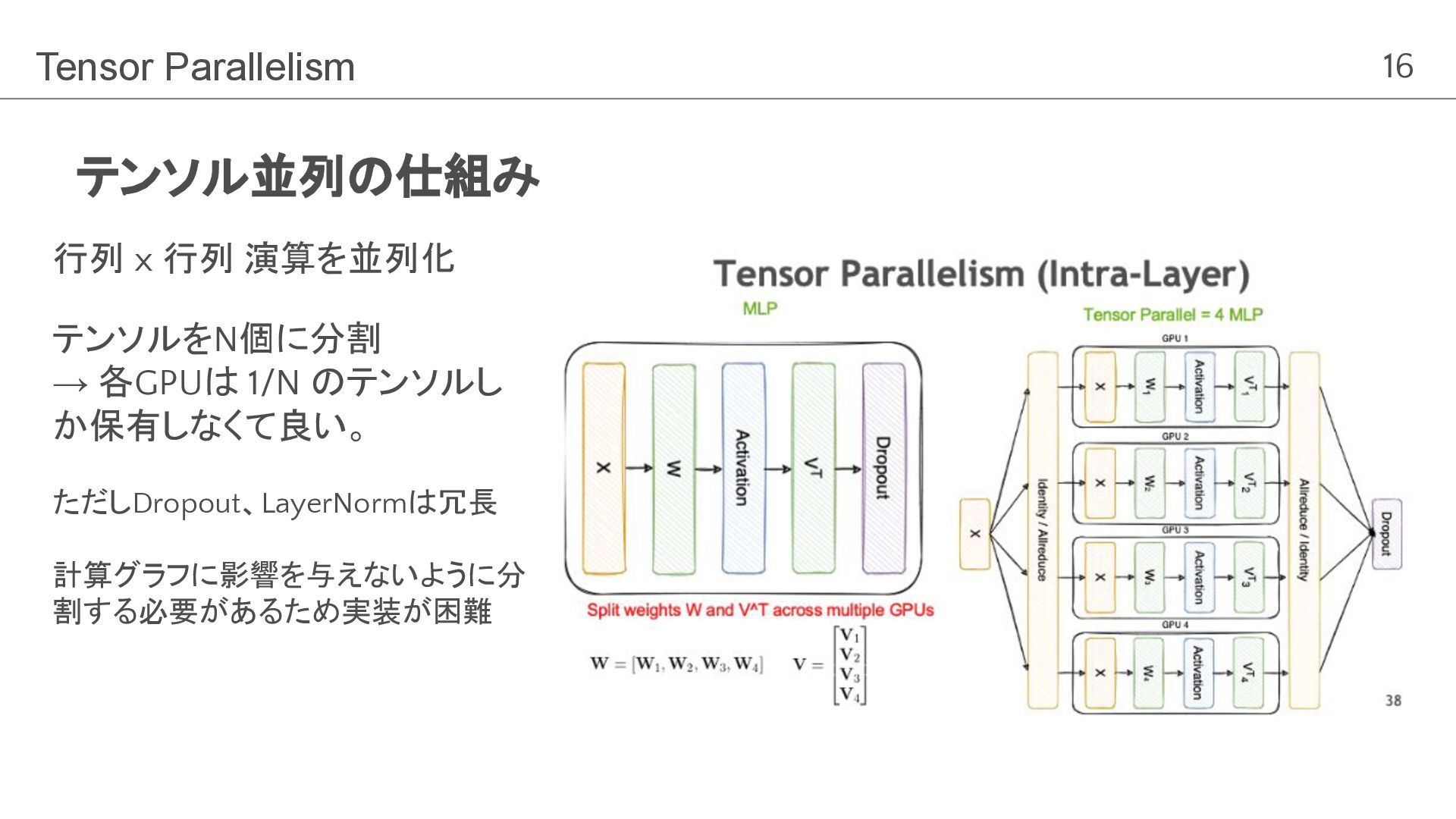
16 テンソル並列の仕組み Tensor Parallelism Dosovitskiy et al, ICLR2021, “An Image
is Worth 16x16 Words: Transformers for Image Recognition at Scale” 行列 x 行列 演算を並列化 テンソルをN個に分割 → 各GPUは 1/N のテンソルし か保有しなくて良い。 ただしDropout、LayerNormは冗長 計算グラフに影響を与えないように分 割する必要があるため実装が困難
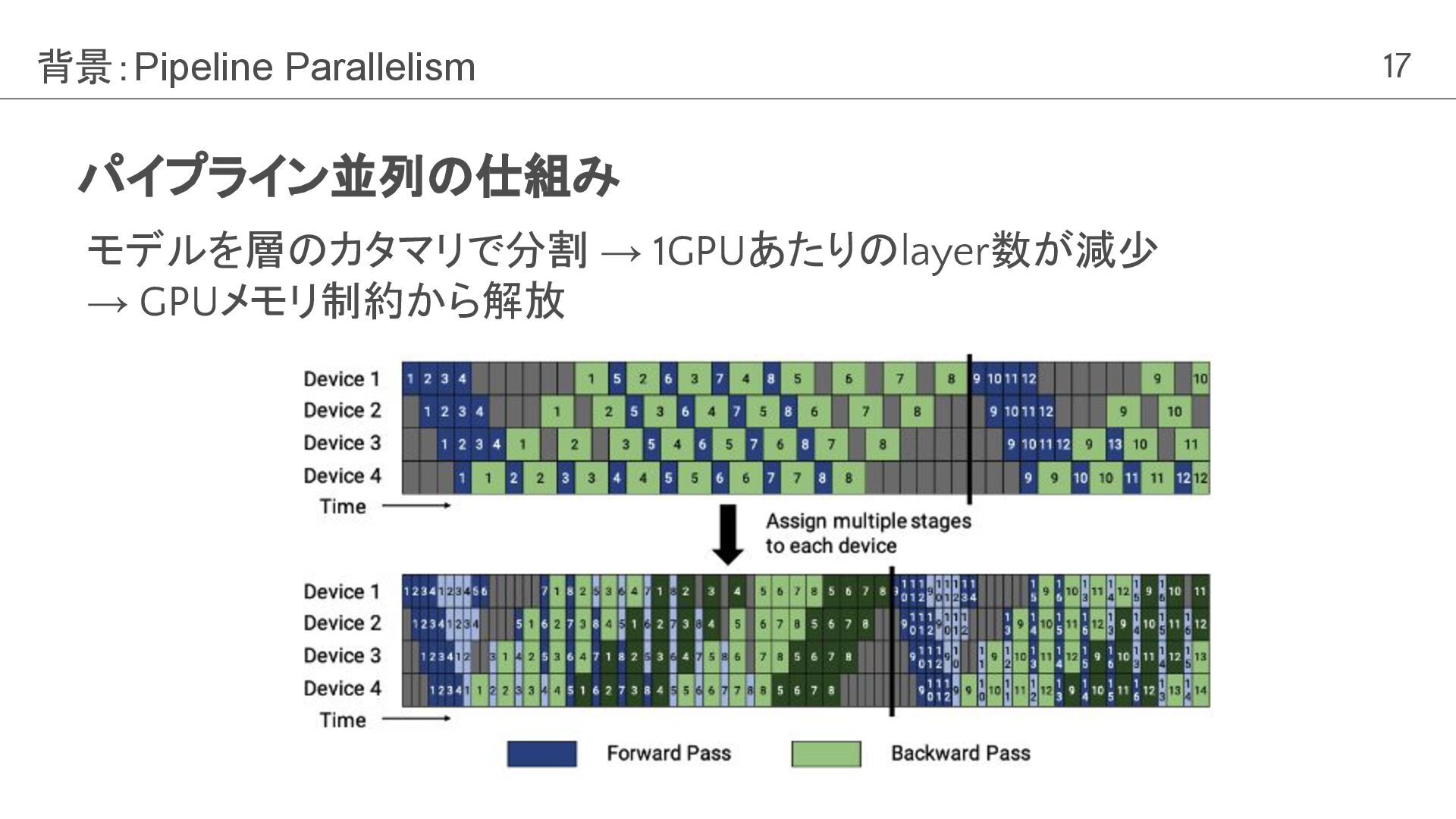
17 パイプライン並列の仕組み 背景:Pipeline Parallelism Dosovitskiy et al, ICLR2021, “An Image
is Worth 16x16 Words: Transformers for Image Recognition at Scale” モデルを層のカタマリで分割 → 1GPUあたりのlayer数が減少 → GPUメモリ制約から解放
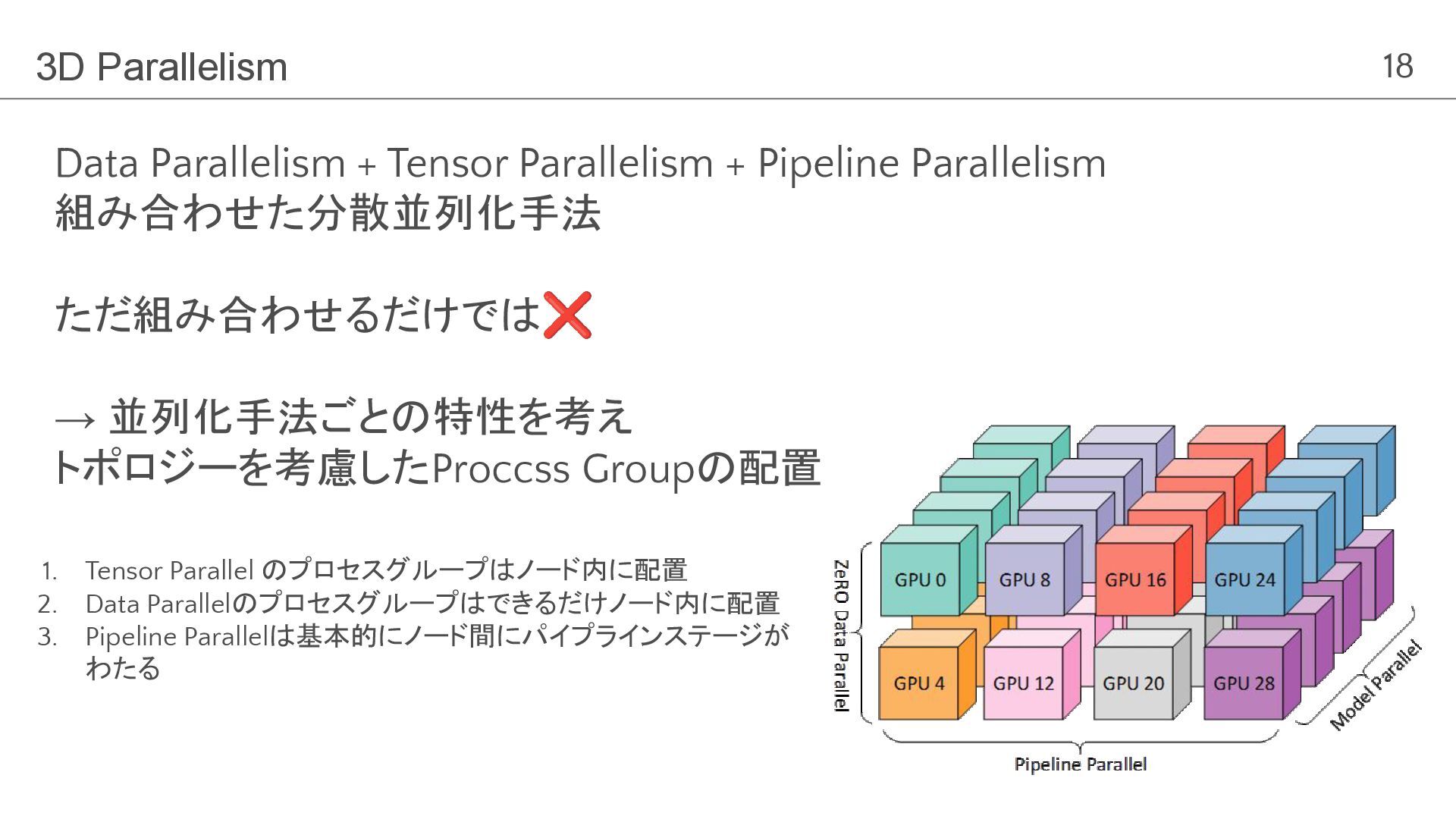
18 3D Parallelism Data Parallelism + Tensor Parallelism + Pipeline
Parallelism 組み合わせた分散並列化手法 ただ組み合わせるだけでは❌ → 並列化手法ごとの特性を考え トポロジーを考慮したProccss Groupの配置 1. Tensor Parallel のプロセスグループはノード内に配置 2. Data Parallelのプロセスグループはできるだけノード内に配置 3. Pipeline Parallelは基本的にノード間にパイプラインステージが わたる
19 DeepSpeed ZeRO, PyTorch FSDP ZeRO Stage1, 2 GPUの担当領域分 のGradientsの平均が
求まっていれば良い scatter-reduceで更新を行った後 all-gatherでupdated parametersを配布 → DPと同じ通信量 Reduce Scatter All Gather
20 3D ParallelismとFSDPの比較 (ABCI A100 40GB) • Llama 2をサポートした2つのライブラリ間の比較 再掲:
モデルサイズとTFLOPS 3D Parallelism FSDP Llama 2 7B 134 TFLOPS/GPU 134 TFLOPS/GPU Llama 2 13B 143 TFLOPS/GPU 135 TFLOPS/GPU Llama 2 70B 158 TFLOPS/GPU 87 TFLOPS/GPU FSDPの方が必要ノード数の制限などは緩いが、大きなモデルでFLOPSが出ない
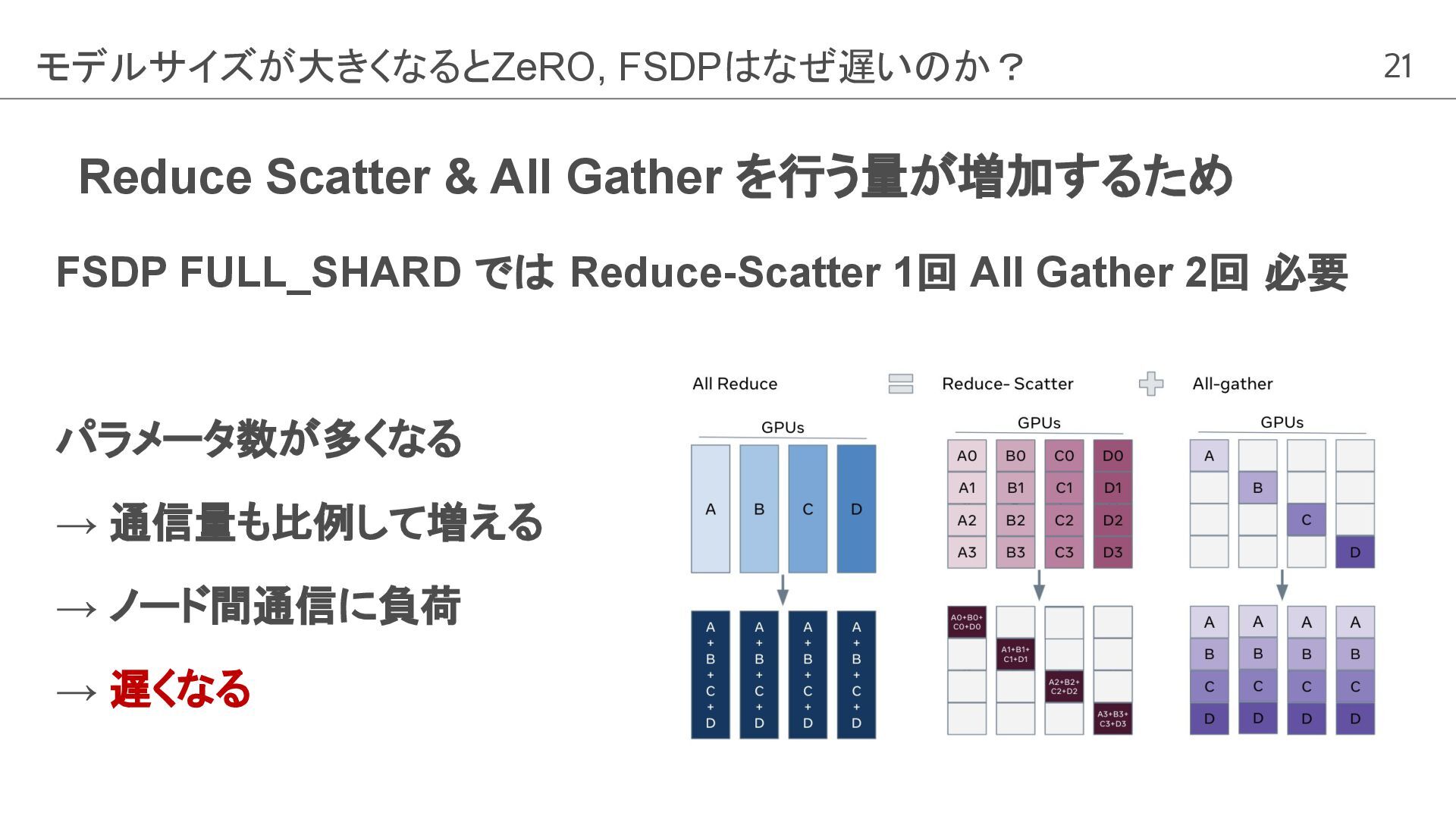
21 Reduce Scatter & All Gather を行う量が増加するため FSDP FULL_SHARD では
Reduce-Scatter 1回 All Gather 2回 必要 パラメータ数が多くなる → 通信量も比例して増える → ノード間通信に負荷 → 遅くなる モデルサイズが大きくなるとZeRO, FSDPはなぜ遅いのか?
22 GPTとは大きく異なるアーキテクチャの場合 実装コスト大 3D Parallelism は万能か? Megatron-LMは、GPTアーキテクチャをデフォルトサポート → Mistral などGPTとは大きく異なるアーキテクチャ場合
実装コスト大 FSDPならば 対応コスト低 → 致命的に遅くならない モデルサイズではFSDPを利用
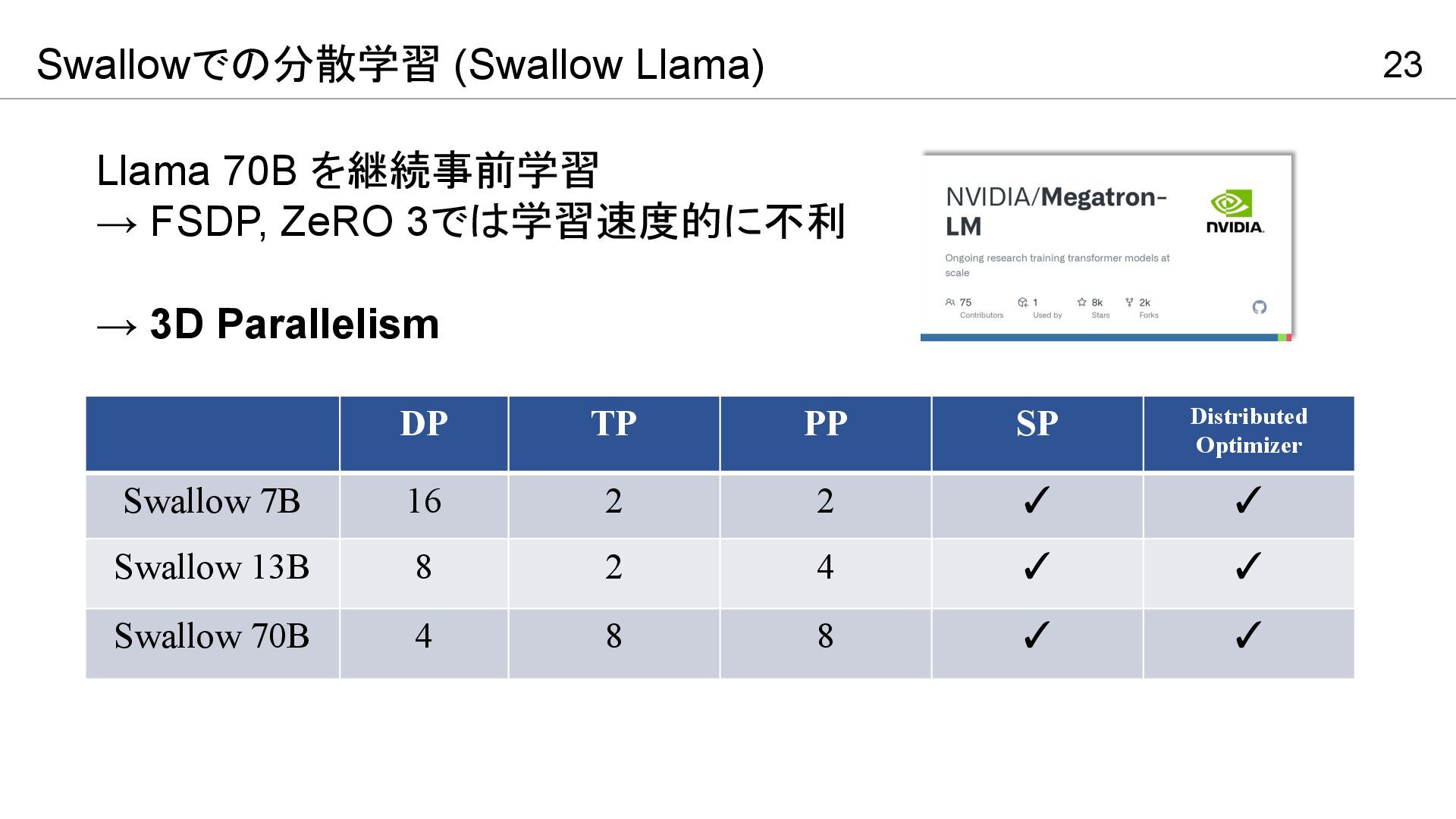
23 Swallowでの分散学習 (Swallow Llama) DP TP PP SP Distributed Optimizer
Swallow 7B 16 2 2 ✓ ✓ Swallow 13B 8 2 4 ✓ ✓ Swallow 70B 4 8 8 ✓ ✓ Llama 70B を継続事前学習 → FSDP, ZeRO 3では学習速度的に不利 → 3D Parallelism
24 Swallowでの分散学習 (Swallow Mistral) Mistral はアーキテクチャがGPT, Llamaとは異なる → 3D Parallelism
を使うには独自拡張必要 FSDPをbackendにしたkotoba-recipesなら不必要 & モデルサイズは7Bと小さい → FSDP Full Shard (=ZeRO 3)
25 まとめ • 事前学習ライブラリについて紹介 • 分散並列学習について紹介 • 3D ParallelismとFSDPについて紹介 •
Swallow Projectにおける具体例を紹介 本日紹介できなかったこと • Loss Spikeの低減手法 • MixtralなどMoE学習の取り組み • MambaなどのSSM(State Space Model)の取り組み
補足資料
27 背景:DeepSpeed ZeROの仕組み Data ParallelでGradientsをbackward終了後に平均していた このときの通信コストはAll-Reduceを利用していたので モデルパラメータ数を とすると ZeRO Stage1, 2では、それぞれのGPUの担当領域分
のGradientsの平均が求まっていれば良い → scatter-reduce 更新を行った後に updated parametersをすべてのプロセスに配布する→ all-gather すなわち、合計で (DPと同じ) Reduce Scatter All Gather
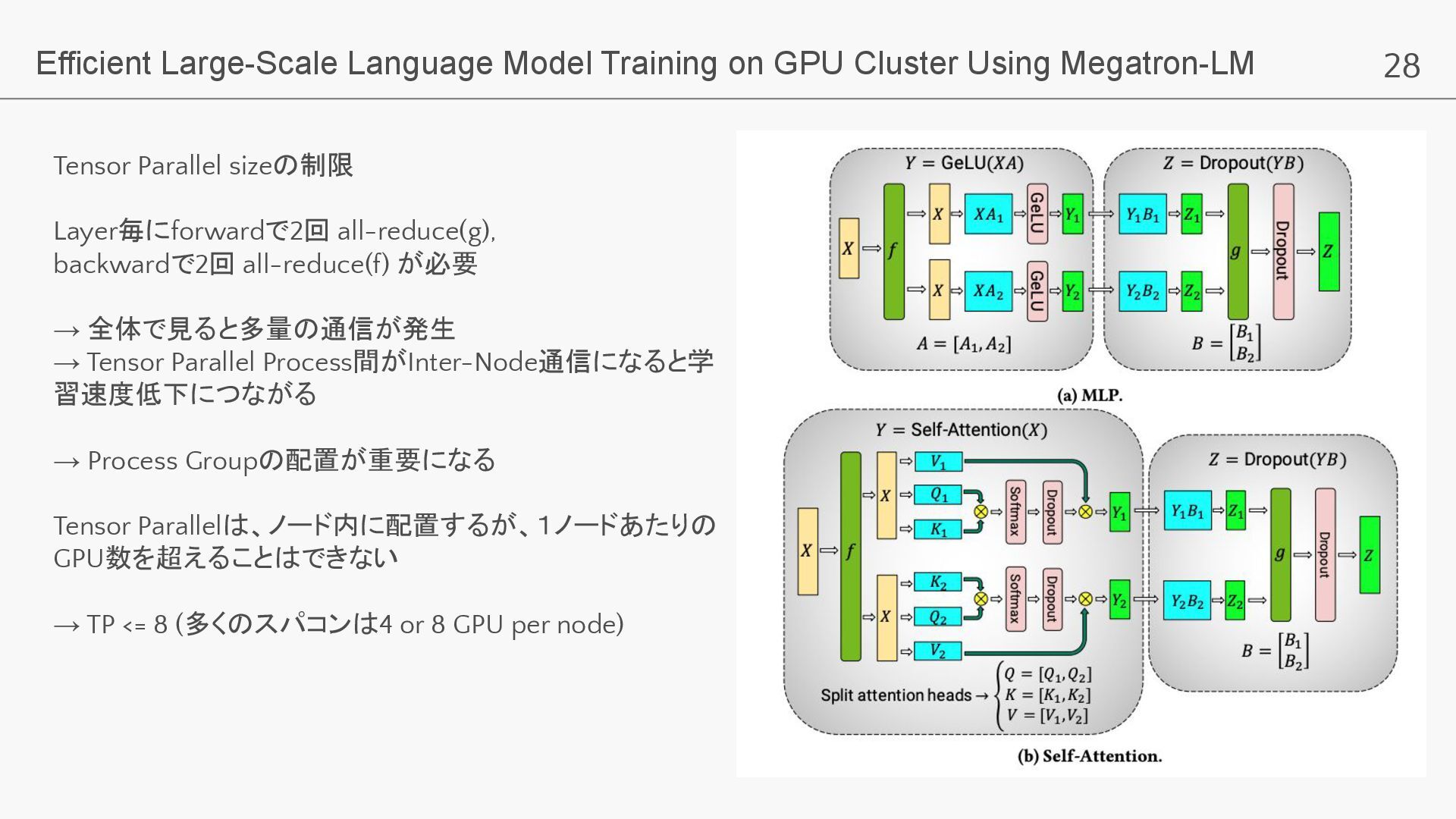
28 Efficient Large-Scale Language Model Training on GPU Cluster Using
Megatron-LM Tensor Parallel sizeの制限 Layer毎にforwardで2回 all-reduce(g), backwardで2回 all-reduce(f) が必要 → 全体で見ると多量の通信が発生 → Tensor Parallel Process間がInter-Node通信になると学 習速度低下につながる → Process Groupの配置が重要になる Tensor Parallelは、ノード内に配置するが、1ノードあたりの GPU数を超えることはできない → TP <= 8 (多くのスパコンは4 or 8 GPU per node)
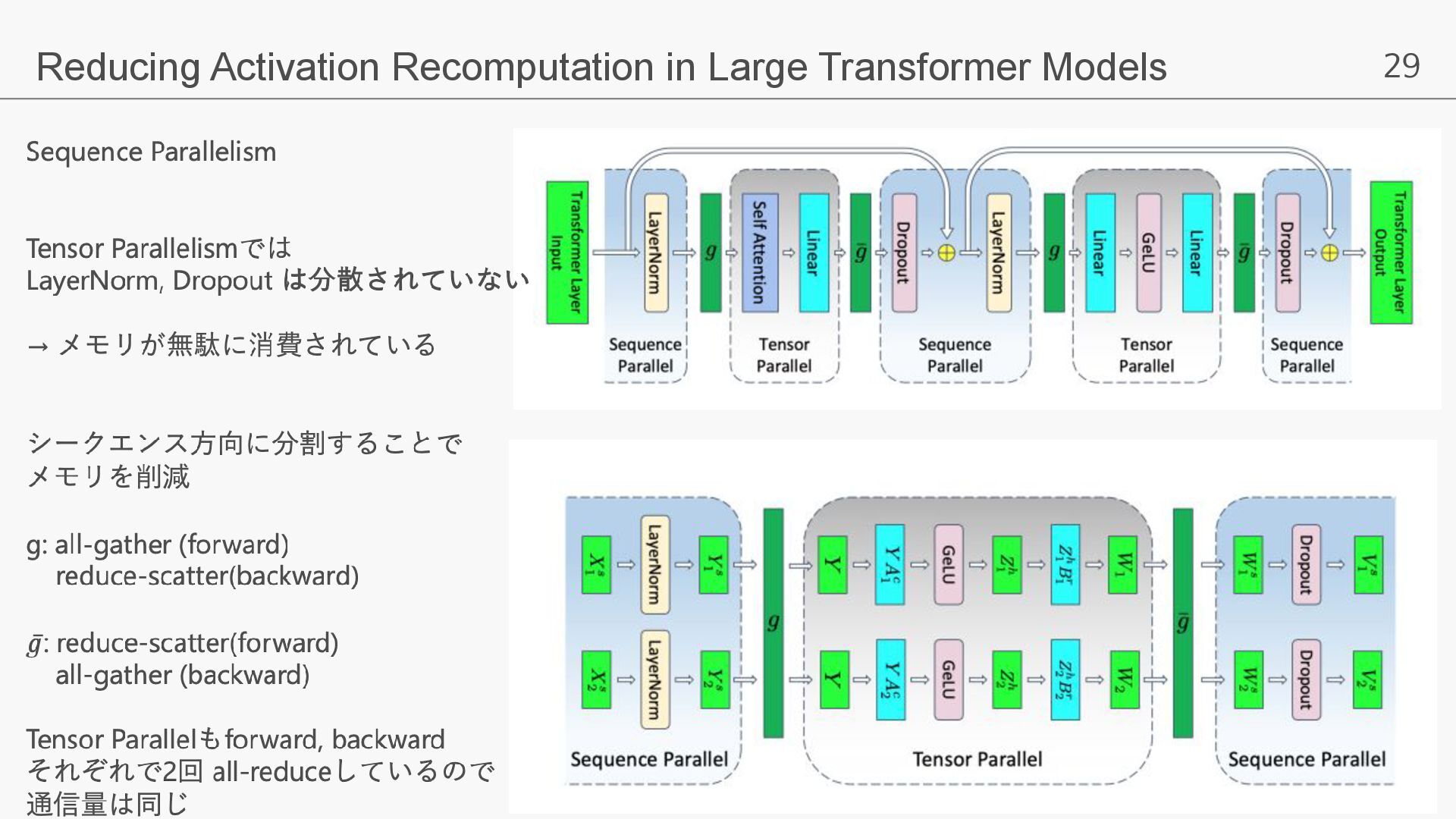
29 Reducing Activation Recomputation in Large Transformer Models
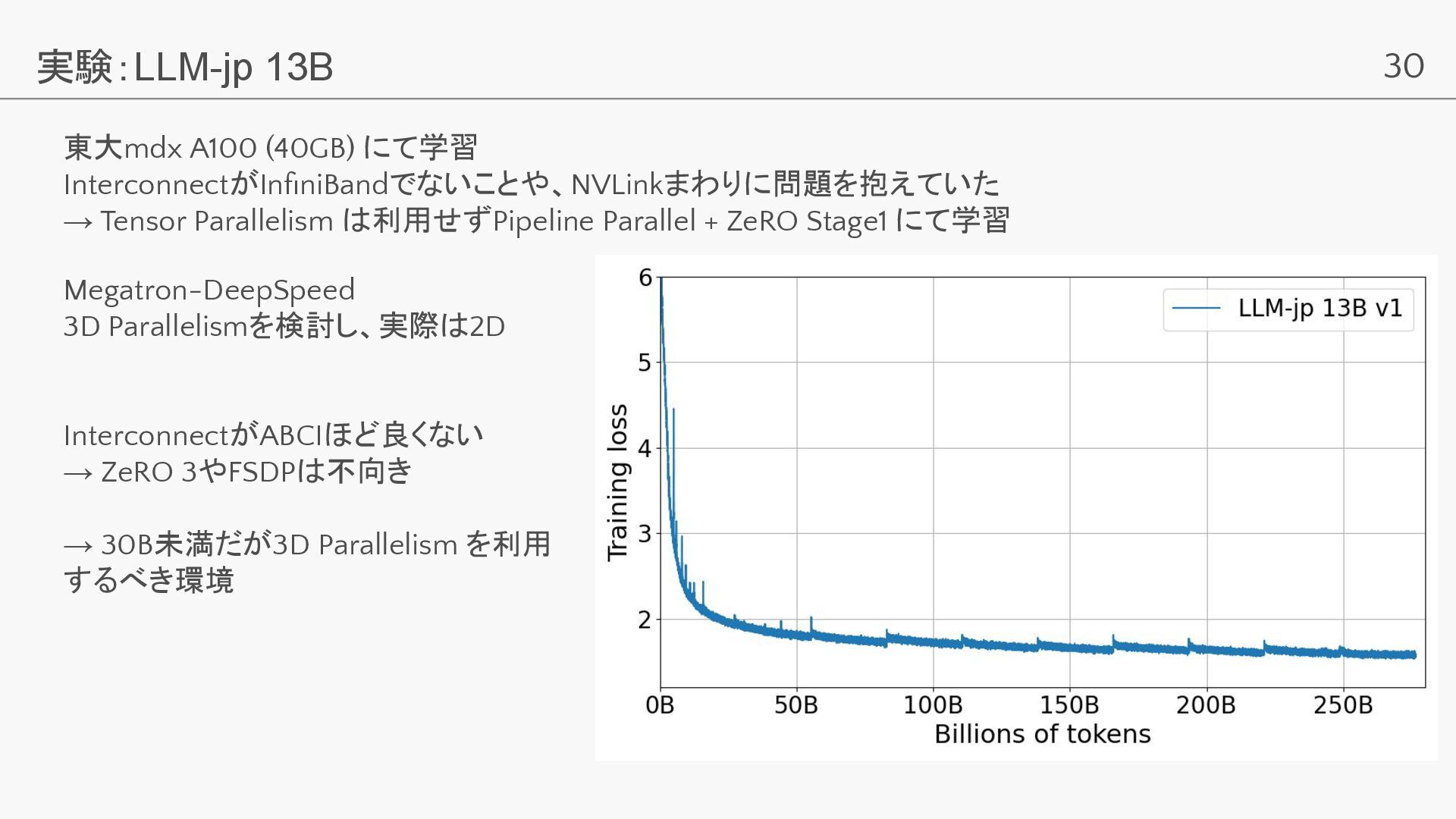
30 実験:LLM-jp 13B 東大mdx A100 (40GB) にて学習 InterconnectがInfiniBandでないことや、NVLinkまわりに問題を抱えていた → Tensor
Parallelism は利用せずPipeline Parallel + ZeRO Stage1 にて学習 Megatron-DeepSpeed 3D Parallelismを検討し、実際は2D InterconnectがABCIほど良くない → ZeRO 3やFSDPは不向き → 30B未満だが3D Parallelism を利用 するべき環境
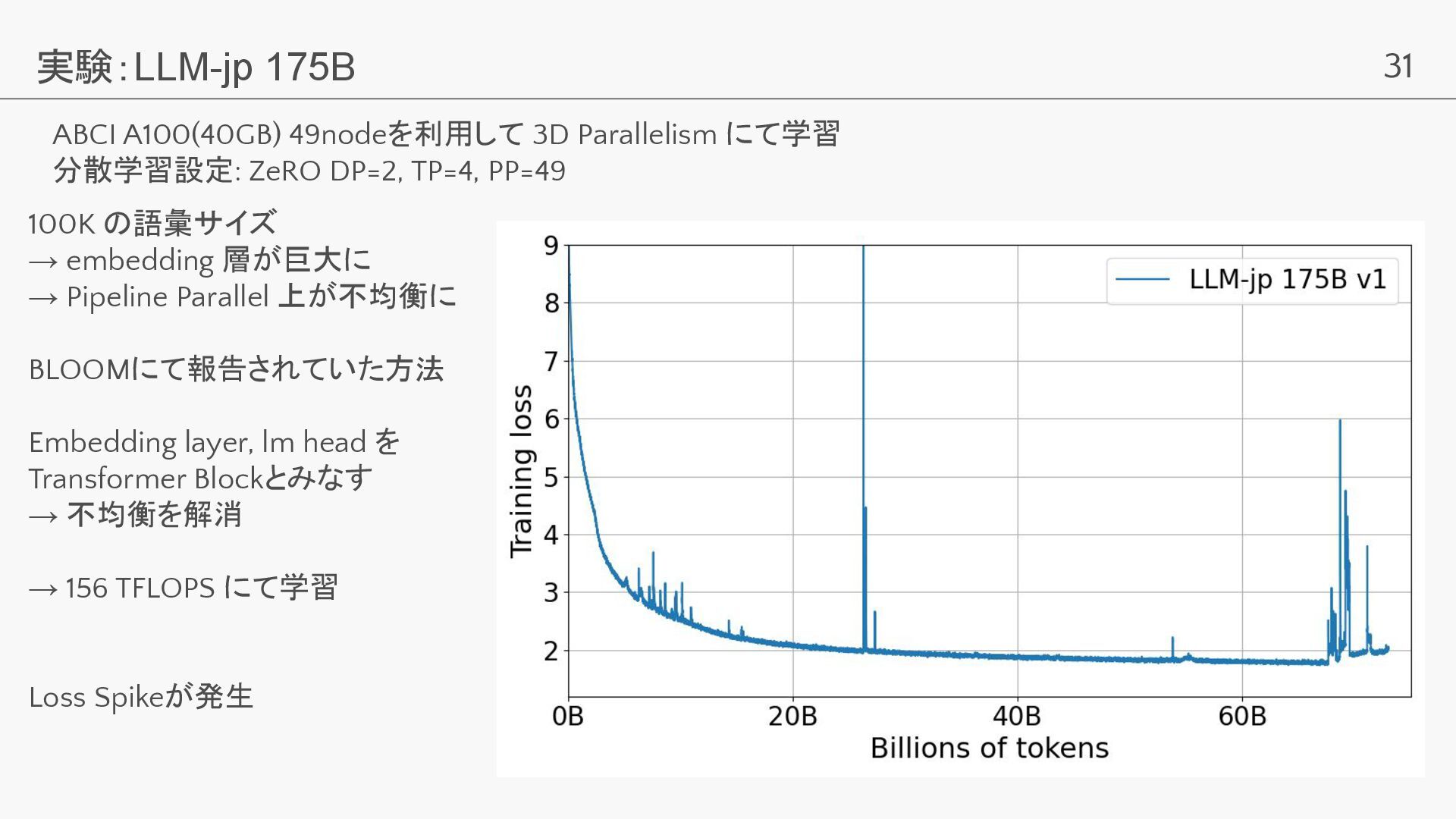
31 実験:LLM-jp 175B ABCI A100(40GB) 49nodeを利用して 3D Parallelism にて学習 分散学習設定:
ZeRO DP=2, TP=4, PP=49 100K の語彙サイズ → embedding 層が巨大に → Pipeline Parallel 上が不均衡に BLOOMにて報告されていた方法 Embedding layer, lm head を Transformer Blockとみなす → 不均衡を解消 → 156 TFLOPS にて学習 Loss Spikeが発生
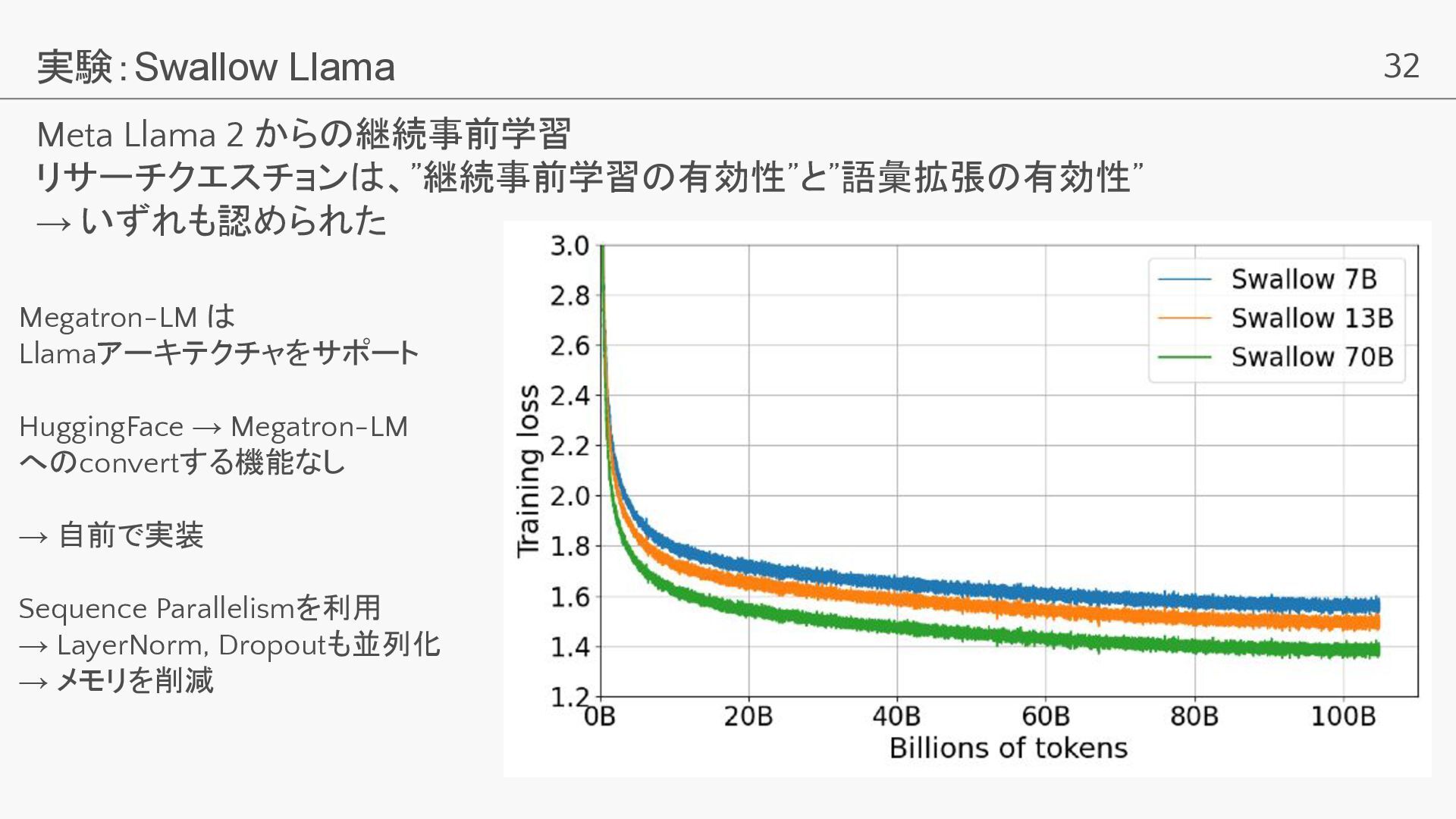
32 実験:Swallow Llama Meta Llama 2 からの継続事前学習 リサーチクエスチョンは、”継続事前学習の有効性”と”語彙拡張の有効性” → いずれも認められた
Megatron-LM は Llamaアーキテクチャをサポート HuggingFace → Megatron-LM へのconvertする機能なし → 自前で実装 Sequence Parallelismを利用 → LayerNorm, Dropoutも並列化 → メモリを削減
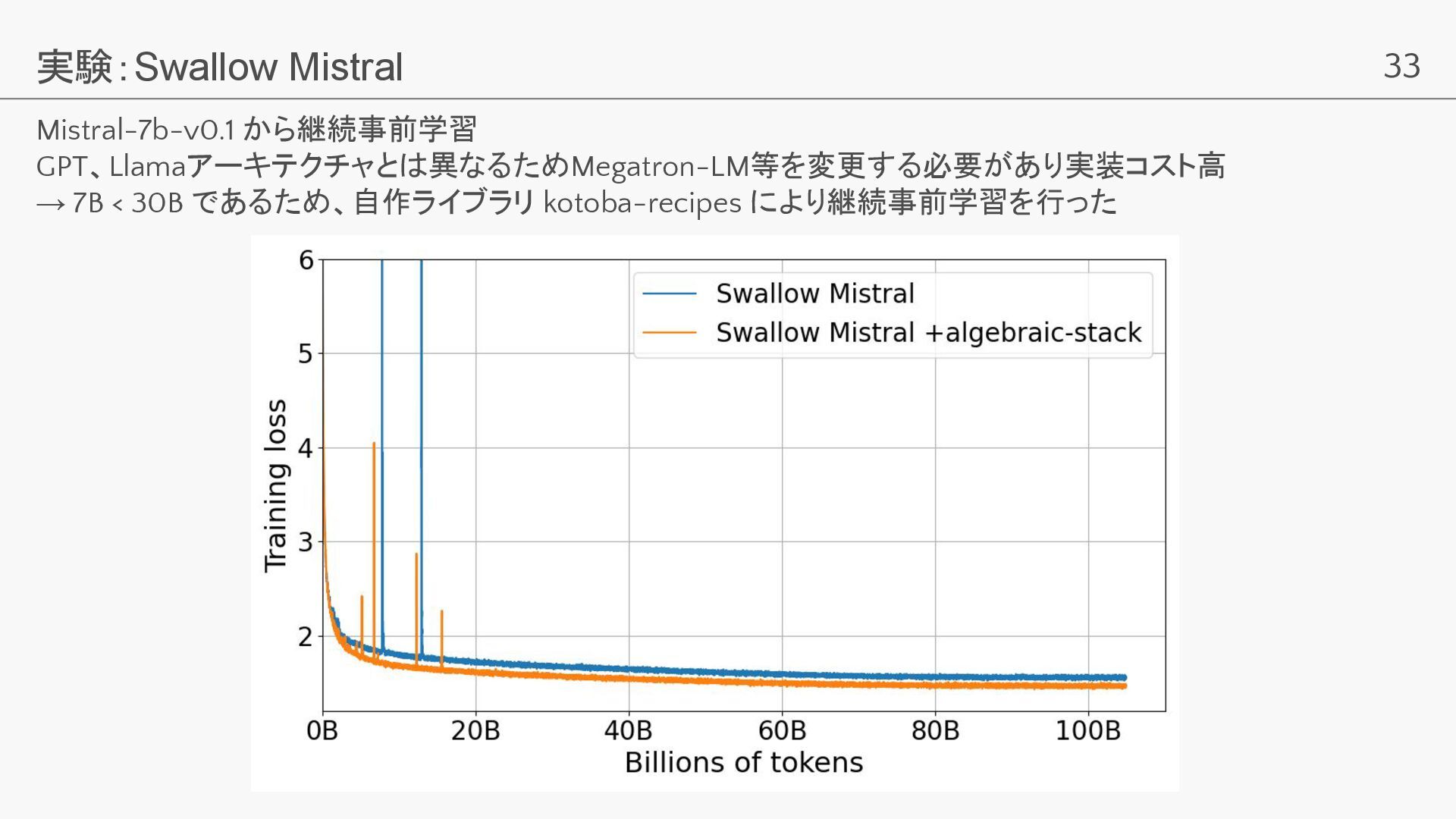
33 実験:Swallow Mistral Mistral-7b-v0.1 から継続事前学習 GPT、Llamaアーキテクチャとは異なるためMegatron-LM等を変更する必要があり実装コスト高 → 7B < 30B
であるため、自作ライブラリ kotoba-recipes により継続事前学習を行った
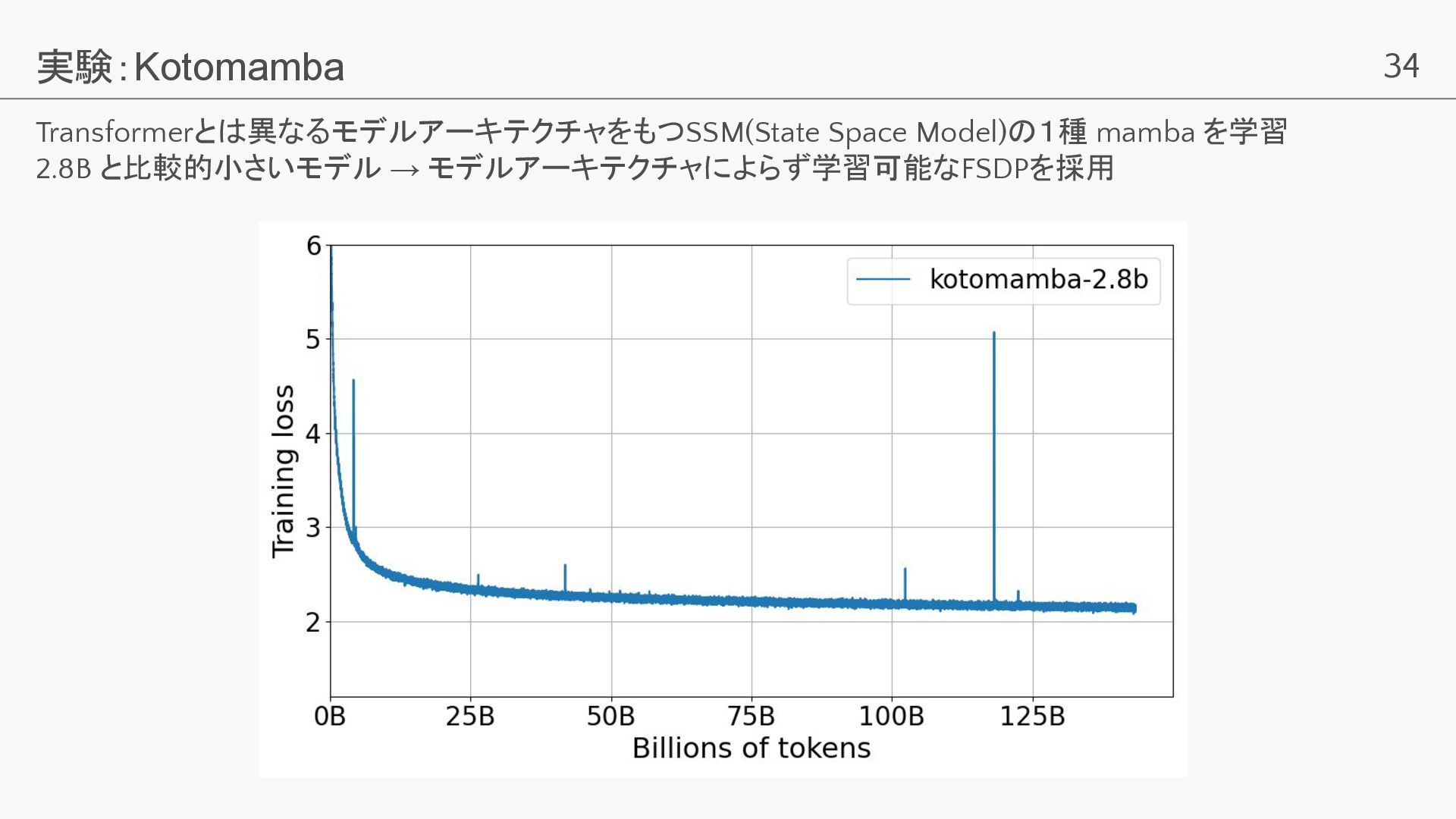
34 実験:Kotomamba Transformerとは異なるモデルアーキテクチャをもつSSM(State Space Model)の1種 mamba を学習 2.8B と比較的小さいモデル →
モデルアーキテクチャによらず学習可能なFSDPを採用
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}