Tokyo, Computer Science, Master student Preferred Networks PLaMo LLM development team intern • Swallow Project: LLM pre-training、Improving the quality of training data • Research interest ◦ Distributed training of large-scale models, acceleration through low-precision deep learning ◦ Improvement of LLM performance through data quality improvement 1
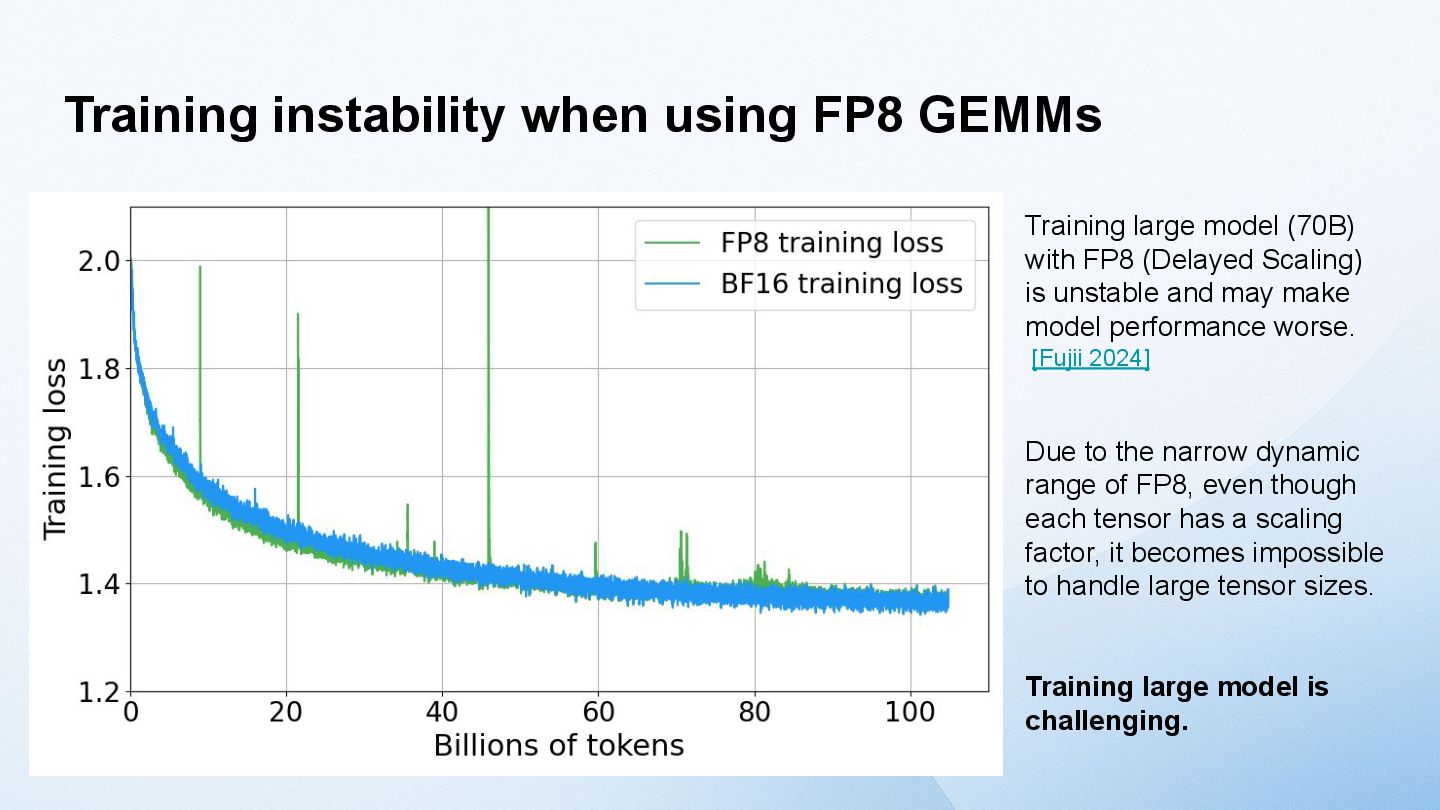
with FP8 (Delayed Scaling) is unstable and may make model performance worse. [Fujii 2024] Due to the narrow dynamic range of FP8, even though each tensor has a scaling factor, it becomes impossible to handle large tensor sizes. Training large model is challenging.
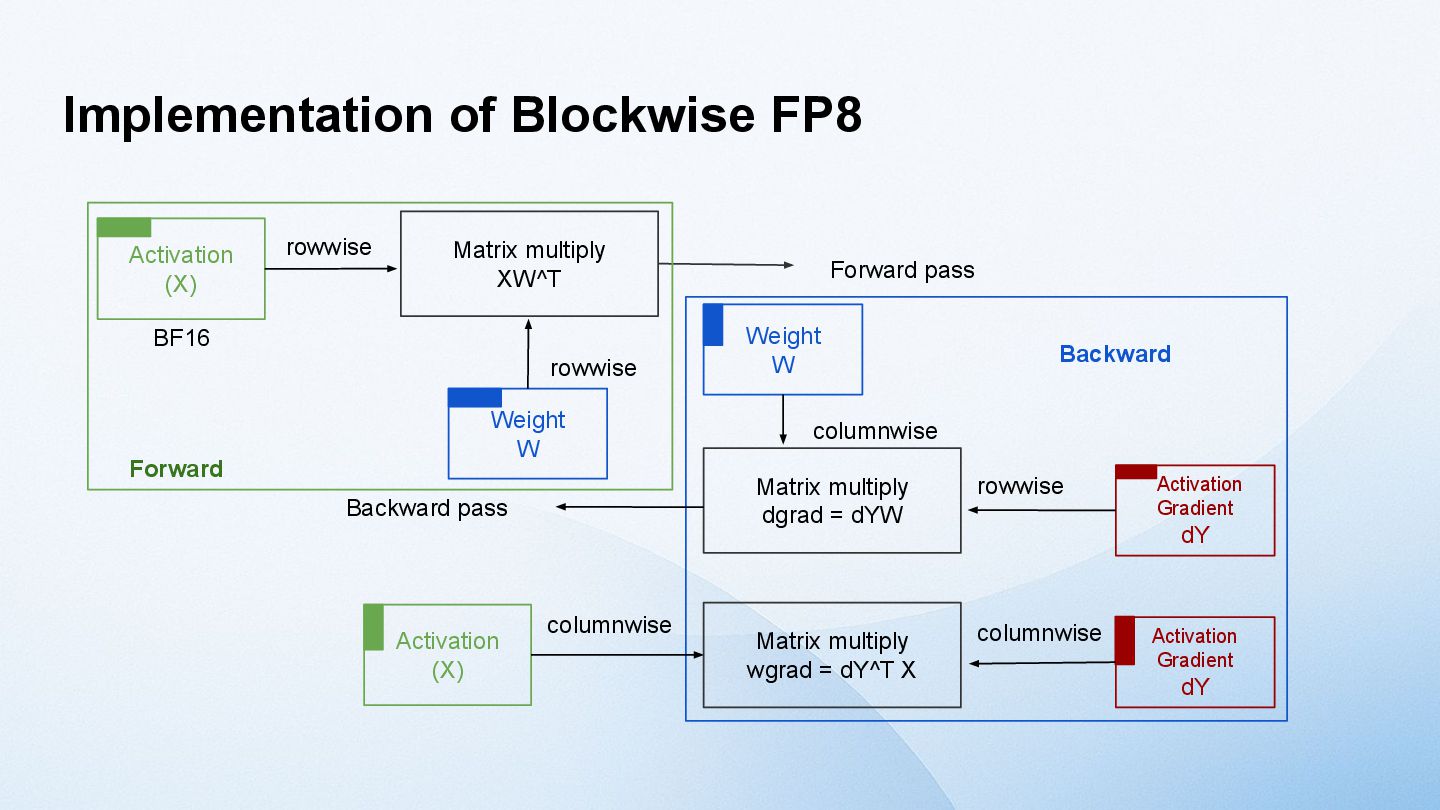
model size increases, the tensor size increases. → activation outliers [Dettmers 2022] One solution is to divide the Tensor into smaller blocks and apply the scaling factor to each block, rather than applying it to the entire Tensor. [MS, AMD, Intel, Meta, NVIDIA, Qualcomm, 2023] NVIDIA Blackwell supports Blockwise FP8 GEMM called MXFP8 (MicroScaling FP8) in hardware. However, Hopper does not have such a function. Furthermore, the fact that performance does not decline when using MXFP8 for training LLMs has only been verified for application to GEMM in the Linear layer. [GTC25] Activation values plot (8B)
12.9 supports b. DeepSeek’s DeepGEMM implementation is helpful 2. Blockwise FP8 aware Communication a. distributed optimizer + Blockwise FP8 3. Self-Attention Q, K, V calculation with FP8 a. Q = X W_Q, K = X W_K, V = X W_V 4. Tensor Parallel Communication & Computation Overlap with Blockwise FP8 Contact me Kazuki Fujii mail: [email protected]
(LLMs) with strong Japanese language capabilities • Institute of Science Tokyo ◦ Okazaki Lab (NLP) ◦ Yokota Lab (HPC, ML) • Released numerous multi-lingual LLMs (Japanese & English) ◦ 12 model series released ◦ Used in industrial applications 9
English + Math + Code Llama-3-Swallow Gemma-2-Swallow Advantages • Can utilize the Open LLMs • Can be trained with a relatively low cost Disadvantages • Architectural constraints • Bound by the license of the original model Issues • Catastrophic forgetting = Decline in English scores
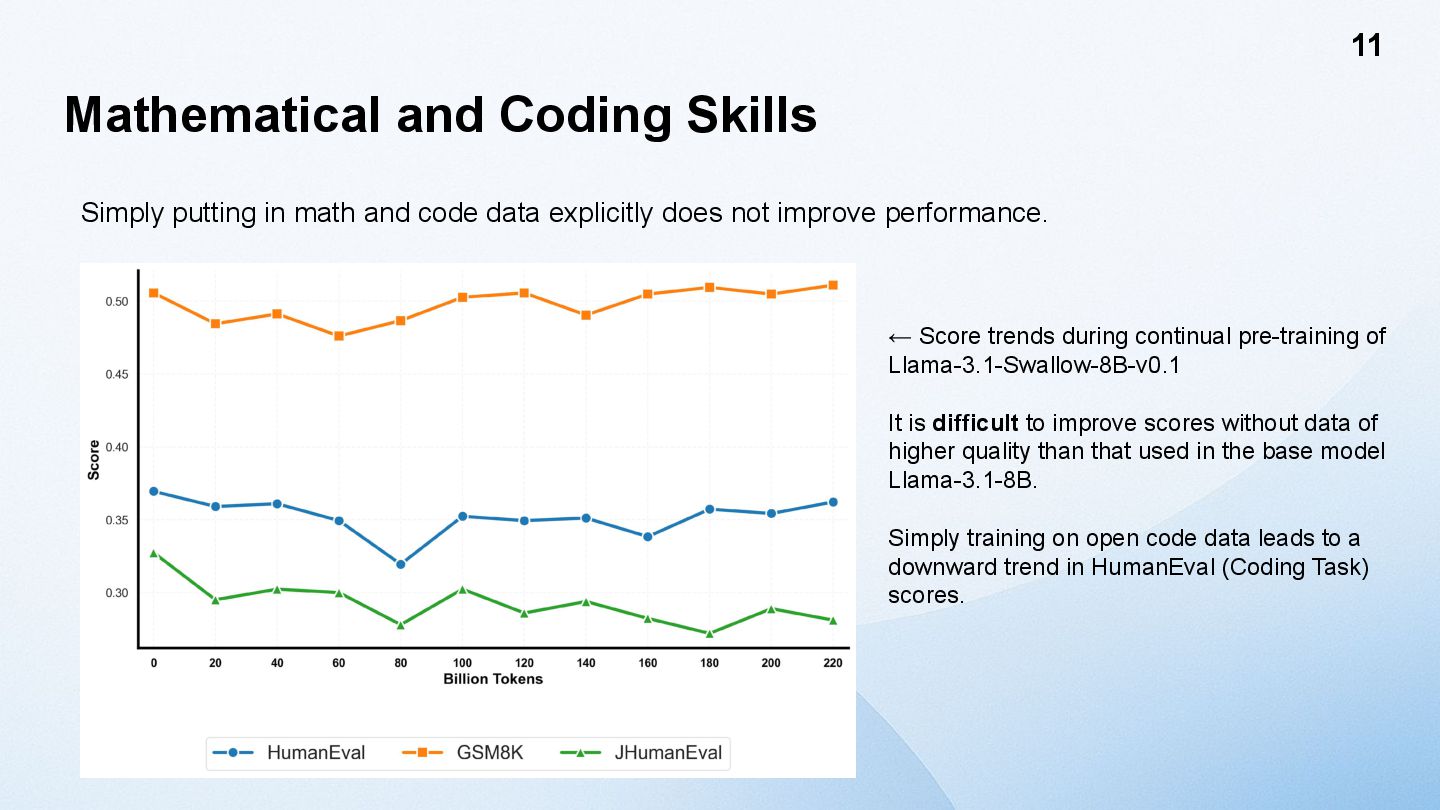
data explicitly does not improve performance. 11 ← Score trends during continual pre-training of Llama-3.1-Swallow-8B-v0.1 It is difficult to improve scores without data of higher quality than that used in the base model Llama-3.1-8B. Simply training on open code data leads to a downward trend in HumanEval (Coding Task) scores.
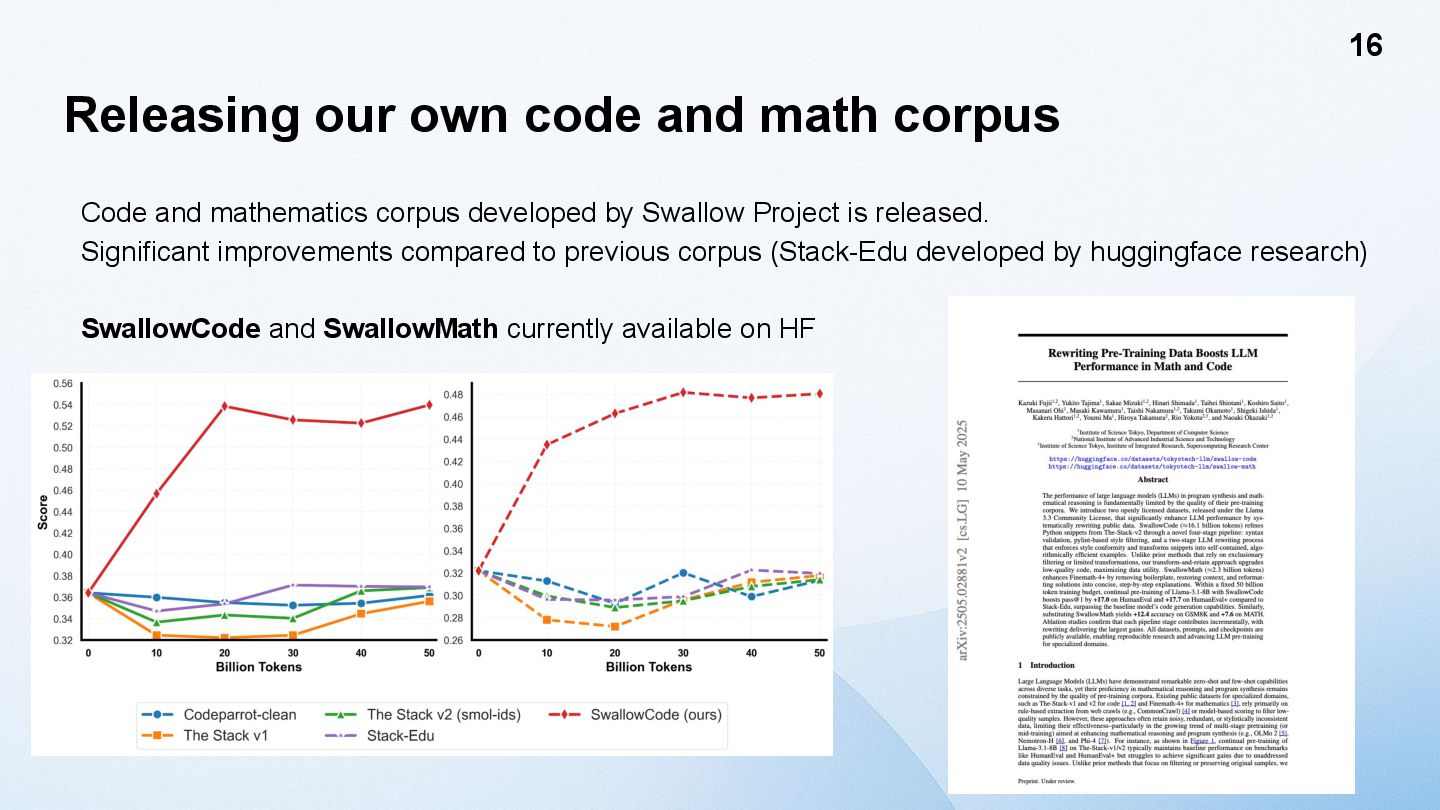
corpus developed by Swallow Project is released. Significant improvements compared to previous corpus (Stack-Edu developed by huggingface research) SwallowCode and SwallowMath currently available on HF 16
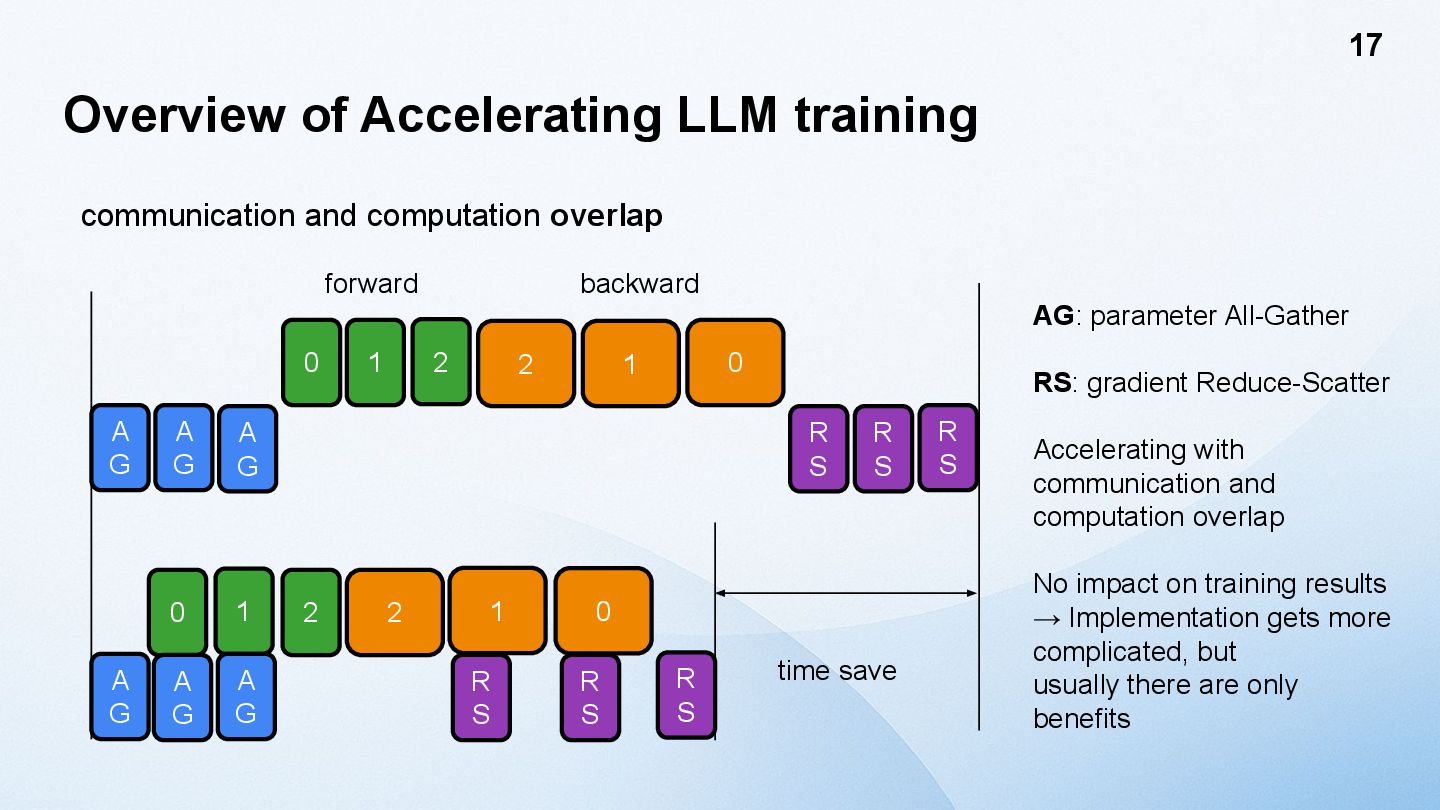
A G A G A G 0 1 2 forward 2 1 0 R S R S R S backward A G 0 1 2 A G A G 2 R S 1 0 R S R S time save AG: parameter All-Gather RS: gradient Reduce-Scatter Accelerating with communication and computation overlap No impact on training results → Implementation gets more complicated, but usually there are only benefits
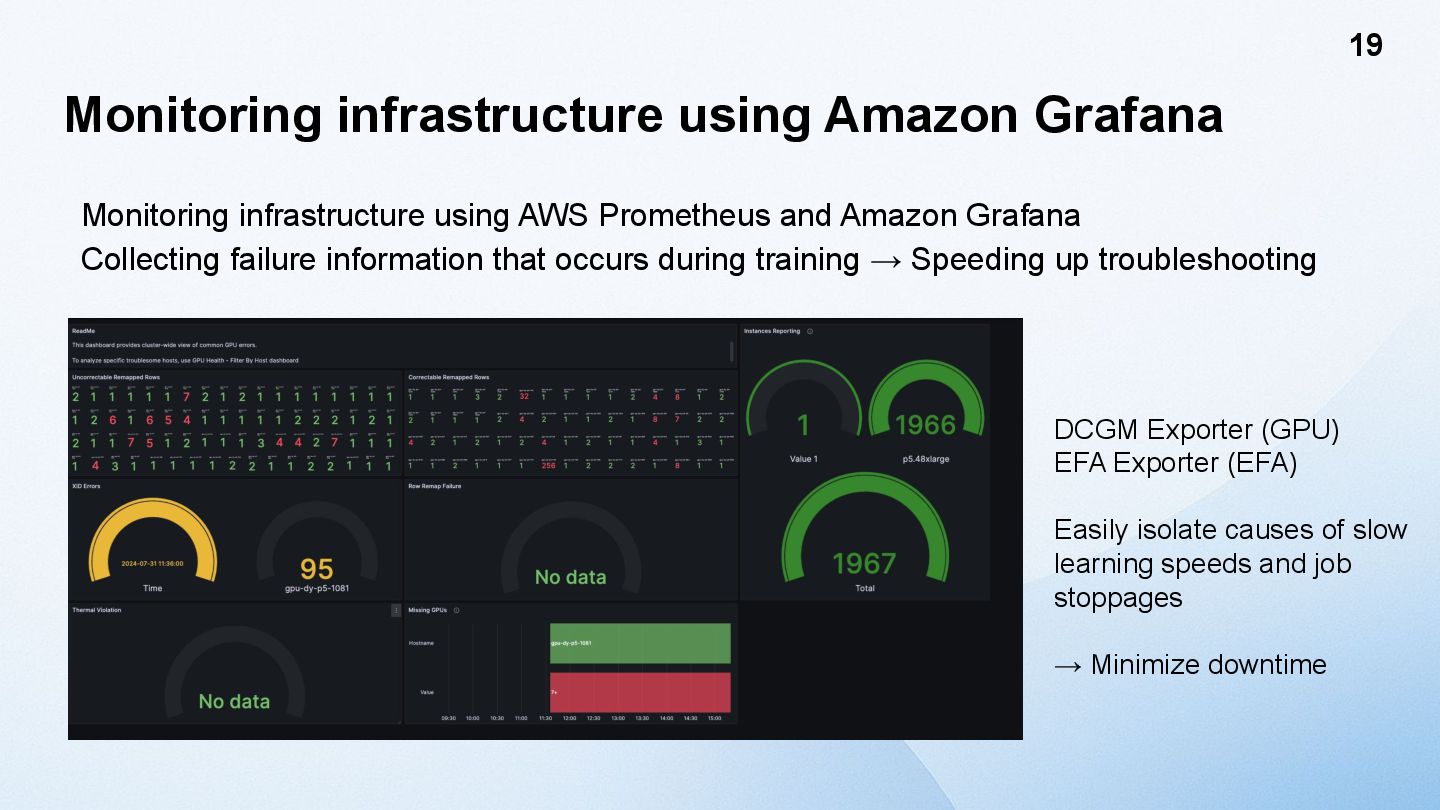
and Amazon Grafana Collecting failure information that occurs during training → Speeding up troubleshooting 19 DCGM Exporter (GPU) EFA Exporter (EFA) Easily isolate causes of slow learning speeds and job stoppages → Minimize downtime
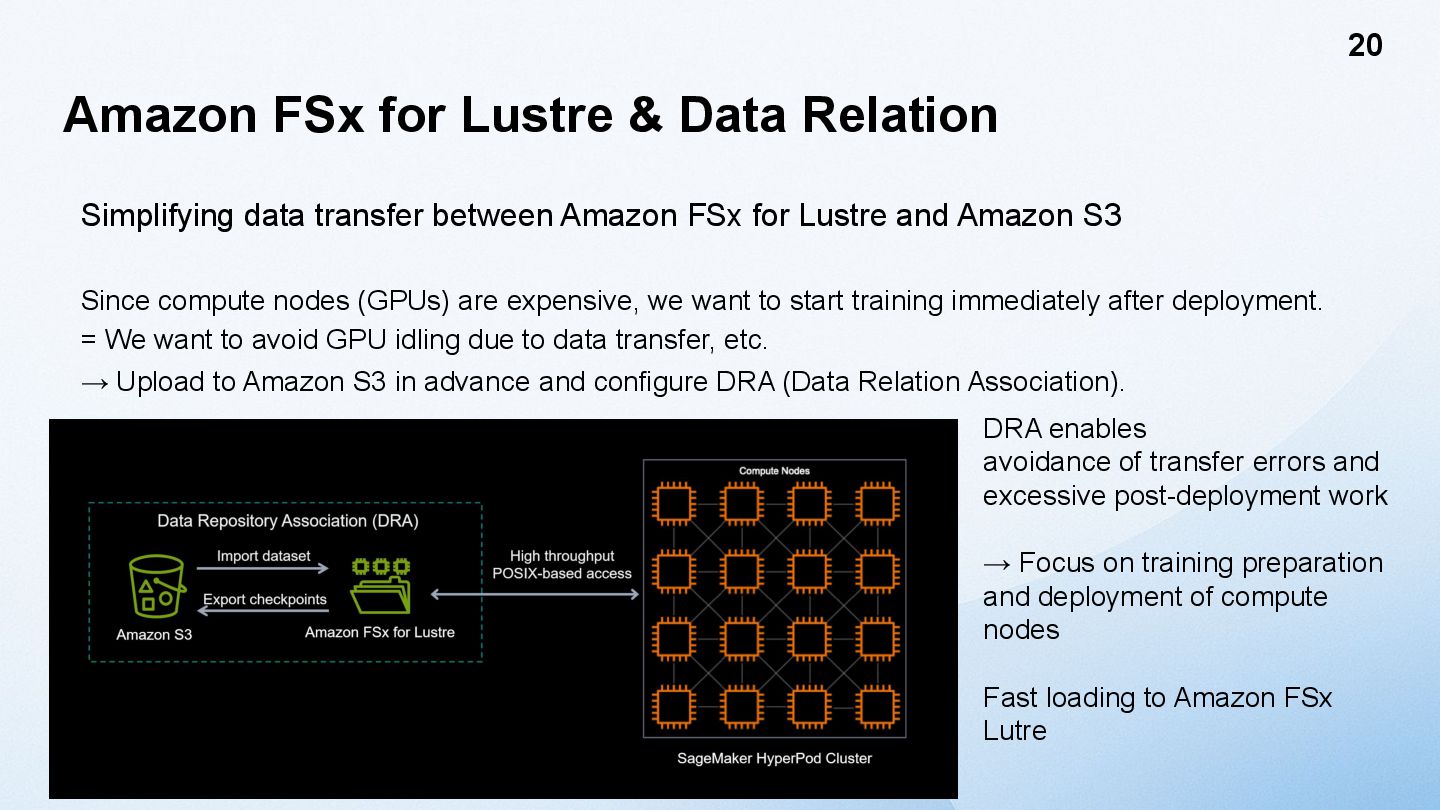
between Amazon FSx for Lustre and Amazon S3 Since compute nodes (GPUs) are expensive, we want to start training immediately after deployment. = We want to avoid GPU idling due to data transfer, etc. → Upload to Amazon S3 in advance and configure DRA (Data Relation Association). 20 DRA enables avoidance of transfer errors and excessive post-deployment work → Focus on training preparation and deployment of compute nodes Fast loading to Amazon FSx Lutre
an upward trend (Ampere → Hopper → Blackwell), resulting in faster forward and backward passes. • If pre-fetching of training data cannot keep up, it will lead to a decrease in achieved FLOP/s • If tokenization is performed on-the-fly, implementation must also consider the computational overhead involved. Network • Verify collective communication (All-Reduce) performance using NCCL-tests. • Ensure nodes are physically co-located for optimal network latency. ◦ Example: AWS Placement Group 23
broken somewhere. • OSS Library: NeMo, Megatron-LM, transformers, etc... • self-developed library: llm-recipes, moe-recipes → Create and maintain CIs for unit testing and training small models (though some parts still break) One-third of the time spent on the Swallow Project was dedicated to library maintenance Example: tensor parallel size > 1 in TransformerEngine v2.0, v2.1 Using tp comm overlap worsens the model's convergence speed → • In small experiments (<1B), issues may not be detectable • Issues caused by API updates in dependency libraries (PyTorch, TE) → unverified commits cannot be trusted (large scale exp is needed) 24 Example of loss trajectory change due to issues originating from TransformerEngine → https://github.com/NVIDIA/TransformerEngine/issues/1616
never ◦ For training the release model of the Swallow Project, use either custom-built PyTorch or NGC PyTorch ◦ Distributed PyTorch cannot be configured to use MPI as the distributed backend ▪ Depending on implementation methods, Tensor Parallel Communication Overlap can not be used when using pip installation pytorch. ◦ The latest version of NGC PyTorch is not necessarily always available for training ▪ Version lock in TE with bugs ▪ PyTorch is too new, and other dependencies haven't caught up with API changes ◦ For speed optimization, different dependencies are required compared to the version built via PyPI ▪ Requirements include specific versions of CUDA Toolkit, cuDNN, and nccl ▪ Example) Blockwise Quantization (CUDA Toolkit >= 12.9) 25 FYI: • PyTorch build: https://zenn.dev/turing_motors/articles/3a434d046bbf48 • NGC PyTorch version lock: https://zenn.dev/turing_motors/articles/fdea210f6ed6e9
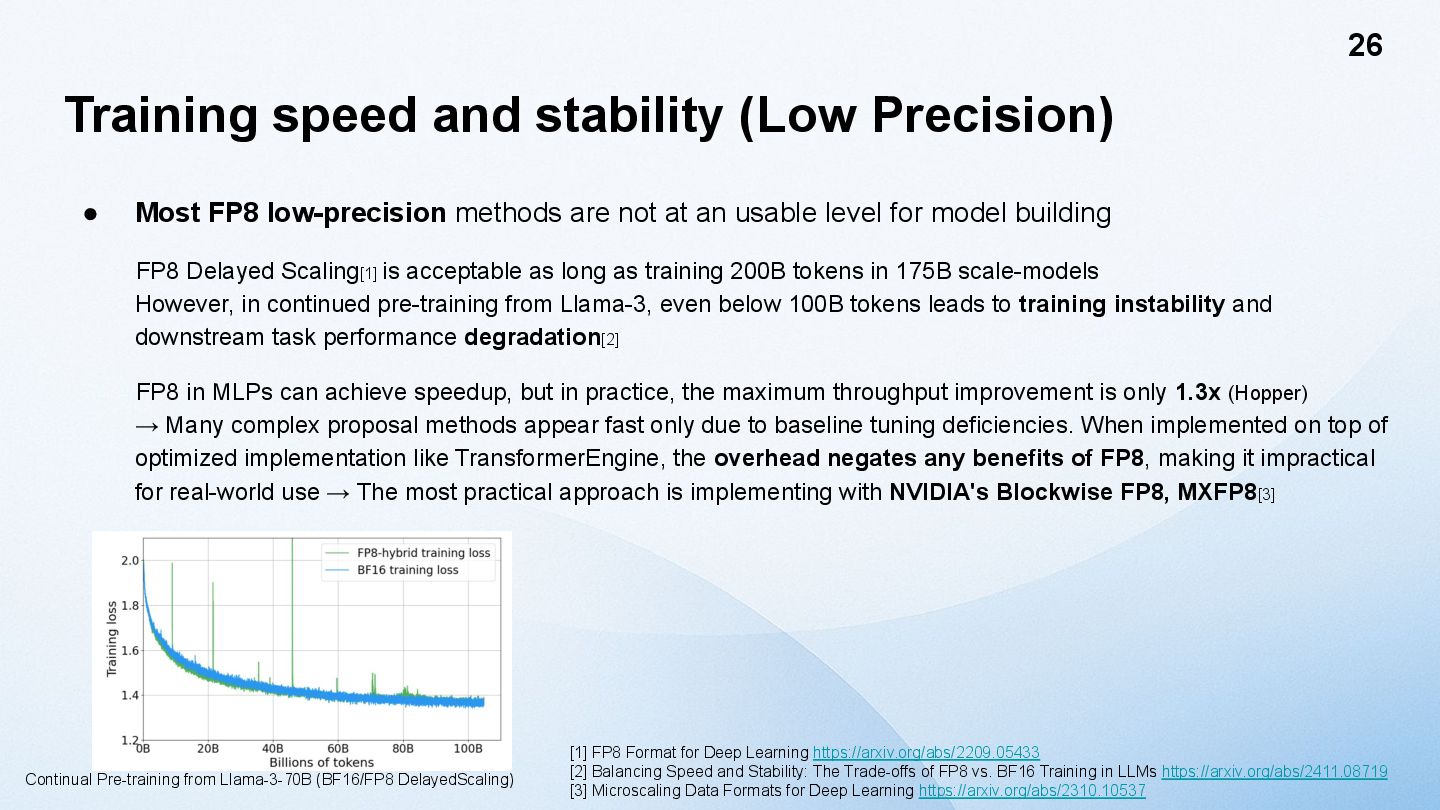
methods are not at an usable level for model building FP8 Delayed Scaling[1] is acceptable as long as training 200B tokens in 175B scale-models However, in continued pre-training from Llama-3, even below 100B tokens leads to training instability and downstream task performance degradation[2] FP8 in MLPs can achieve speedup, but in practice, the maximum throughput improvement is only 1.3x (Hopper) → Many complex proposal methods appear fast only due to baseline tuning deficiencies. When implemented on top of optimized implementation like TransformerEngine, the overhead negates any benefits of FP8, making it impractical for real-world use → The most practical approach is implementing with NVIDIA's Blockwise FP8, MXFP8[3] 26 [1] FP8 Format for Deep Learning https://arxiv.org/abs/2209.05433 [2] Balancing Speed and Stability: The Trade-offs of FP8 vs. BF16 Training in LLMs https://arxiv.org/abs/2411.08719 [3] Microscaling Data Formats for Deep Learning https://arxiv.org/abs/2310.10537 Continual Pre-training from Llama-3-70B (BF16/FP8 DelayedScaling)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}