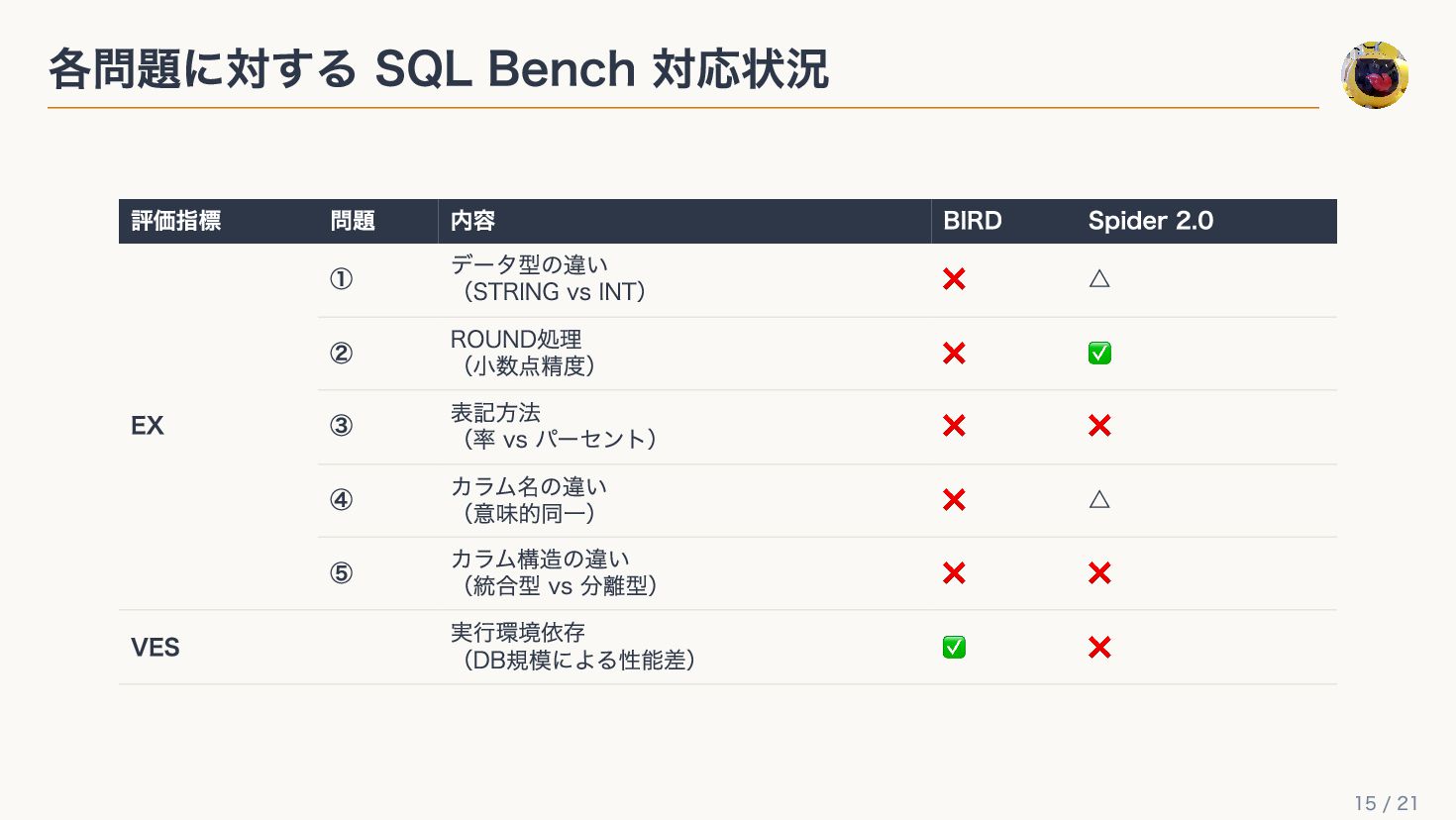
+ LIMITで商品名を取得 同じ結果を返すのに、構文が違うだけで完全不一致 -- 結果: 「プレミアムスマートフォン」 SELECT name FROM products WHERE price = (SELECT MAX(price) FROM products); -- 結果: 「プレミアムスマートフォン」 SELECT name FROM products ORDER BY price DESC LIMIT 1; EM(Exact Match)の問題点 8 / 21
結果: "0123456789012" SELECT FORMAT("%013d", jancode) AS jancode_str FROM products p JOIN sales s ON p.product_id = s.product_id GROUP BY jancode ORDER BY SUM(sales_amount) DESC LIMIT 1; -- 結果: 123456789012 SELECT jancode FROM products p JOIN sales s ON p.product_id = s.product_id GROUP BY jancode ORDER BY SUM(sales_amount) DESC LIMIT 1; EX(Execution Accuracy)の問題点 ① 9 / 21
結果: 12345.678901234 SELECT AVG(price) AS avg_price FROM products WHERE category = 'electronics'; -- 結果: 12345.68 SELECT ROUND(AVG(price), 2) AS avg_price FROM products WHERE category = 'electronics'; EX(Execution Accuracy)の問題点 ② 10 / 21
(INT), month (INT) 2カラム 同じ期間(2025年7月)なのに、カラム構造の違いで完全不一致 -- 結果: "2025-07" SELECT FORMAT_DATE('%Y-%m', purchase_date) AS year_month, SUM(sales_amount) AS total_sales FROM sales_data WHERE EXTRACT(YEAR FROM purchase_date) = 2025 AND EXTRACT(MONTH FROM purchase_date) = 7 GROUP BY FORMAT_DATE('%Y-%m', purchase_date); -- 結果: 2025, 7 SELECT EXTRACT(YEAR FROM purchase_date) AS year, EXTRACT(MONTH FROM purchase_date) AS month, SUM(sales_amount) AS total_sales FROM sales_data WHERE EXTRACT(YEAR FROM purchase_date) = 2025 AND EXTRACT(MONTH FROM purchase_date) = 7 GROUP BY EXTRACT(YEAR FROM purchase_date), EXTRACT(MONTH FRO EX(Execution Accuracy)の問題点 ④ 12 / 21
結果カラム: total_purchase SELECT user_id, SUM(purchase_amount) AS total_purchase FROM orders GROUP BY user_id ORDER BY total_purchase DESC; -- 結果カラム: sum_amount SELECT user_id, SUM(purchase_amount) AS sum_amount FROM orders GROUP BY user_id ORDER BY sum_amount DESC; EX(Execution Accuracy)の問題点 ⑤ 13 / 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}