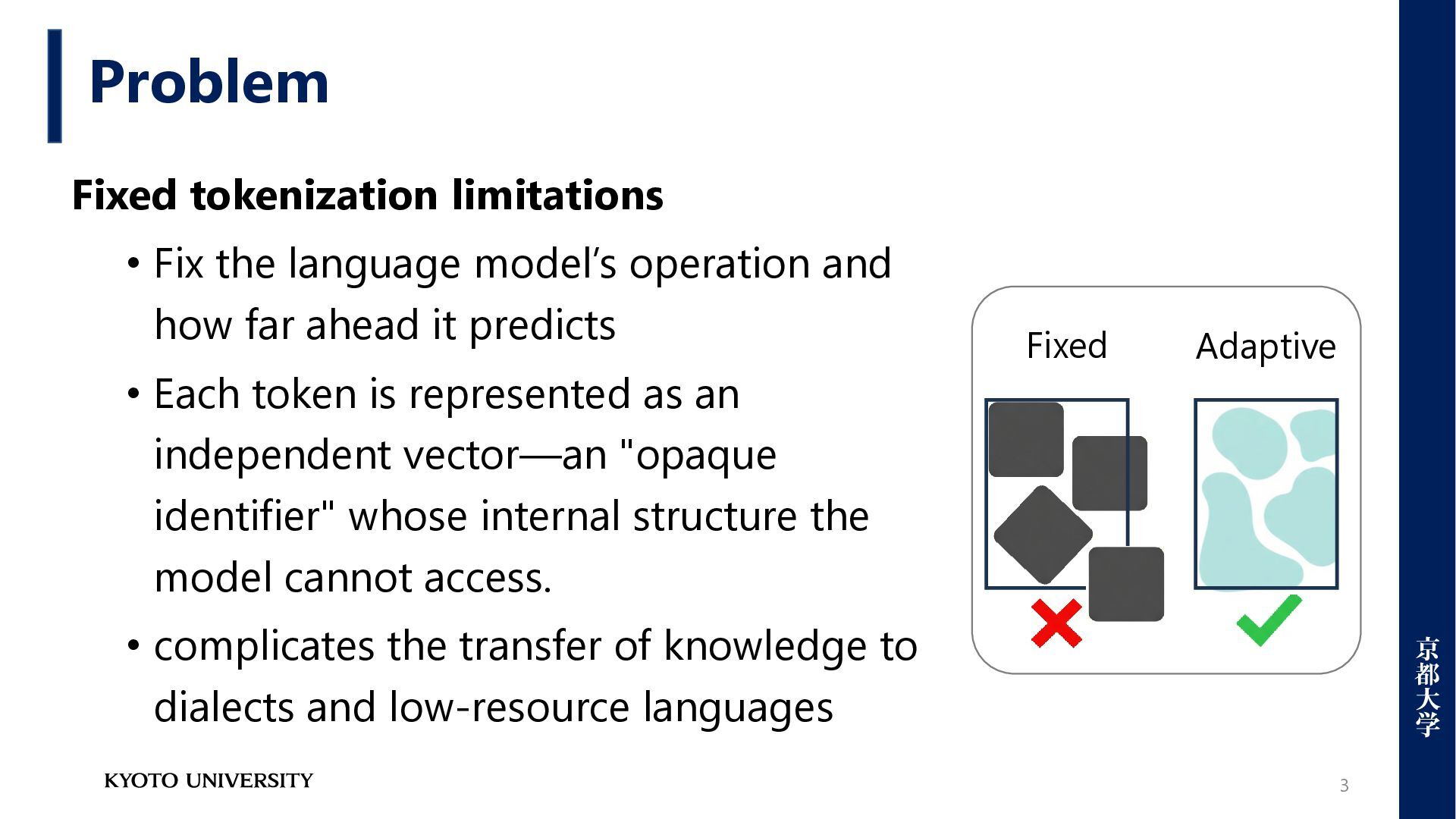
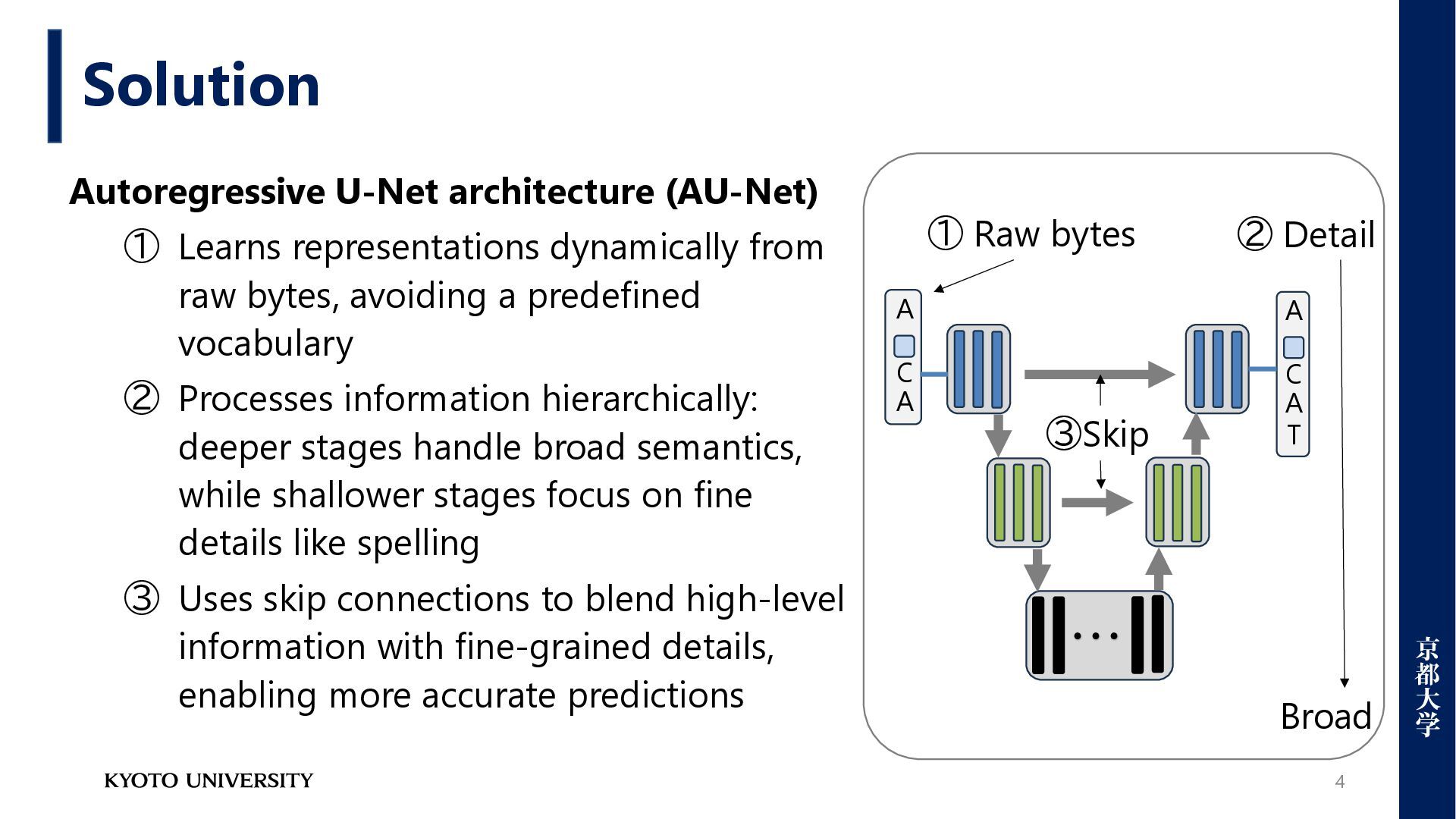
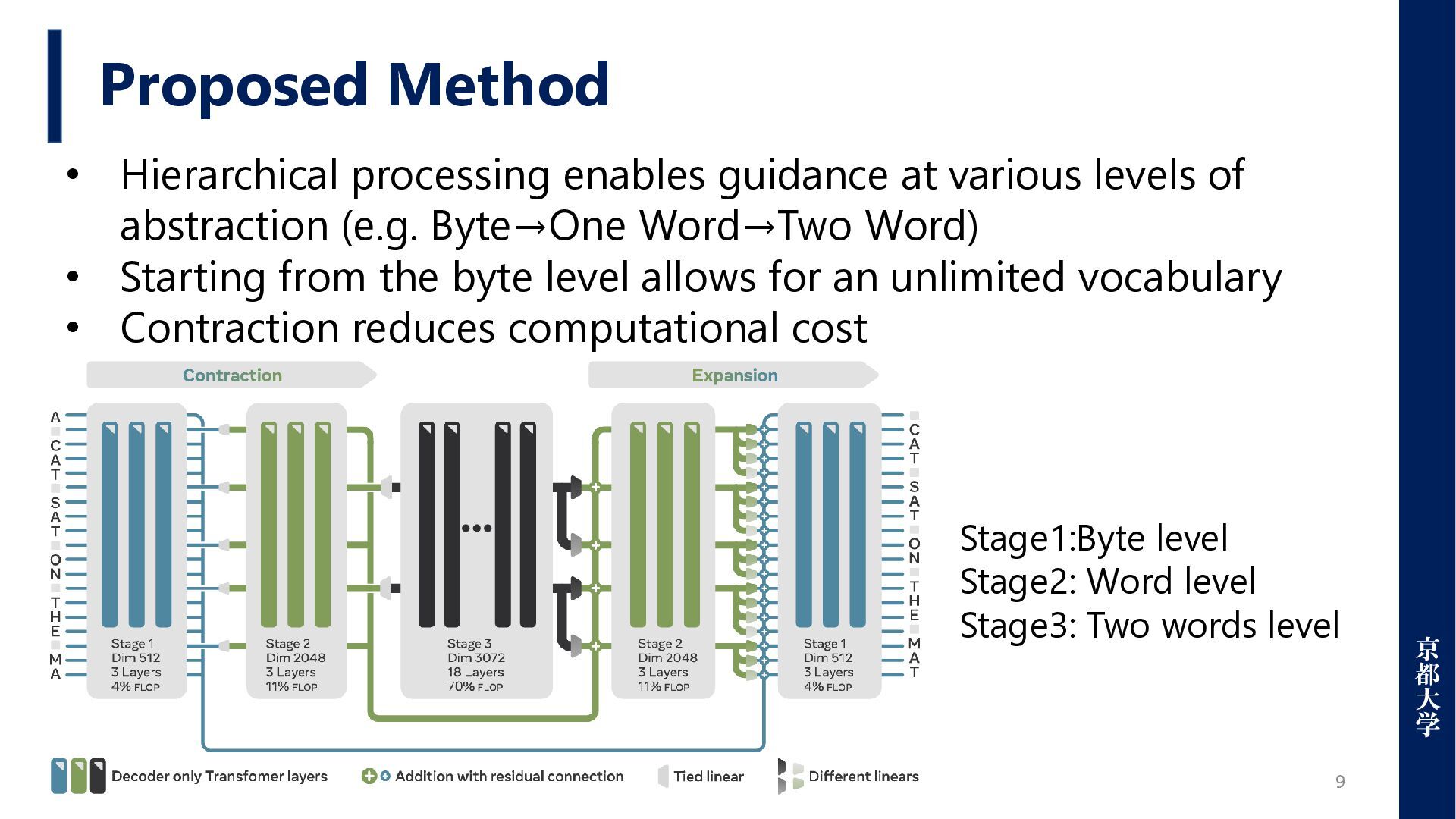
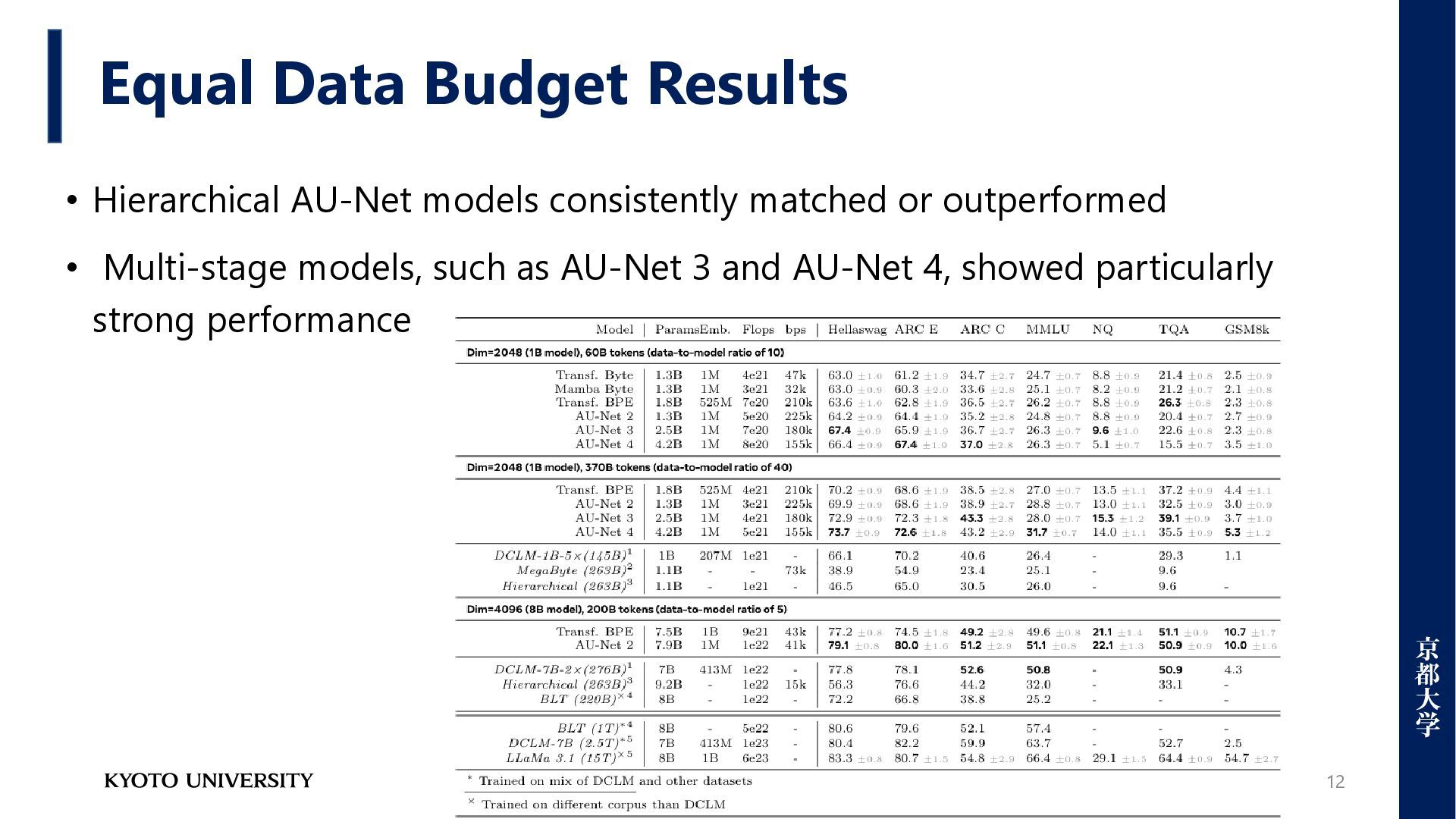
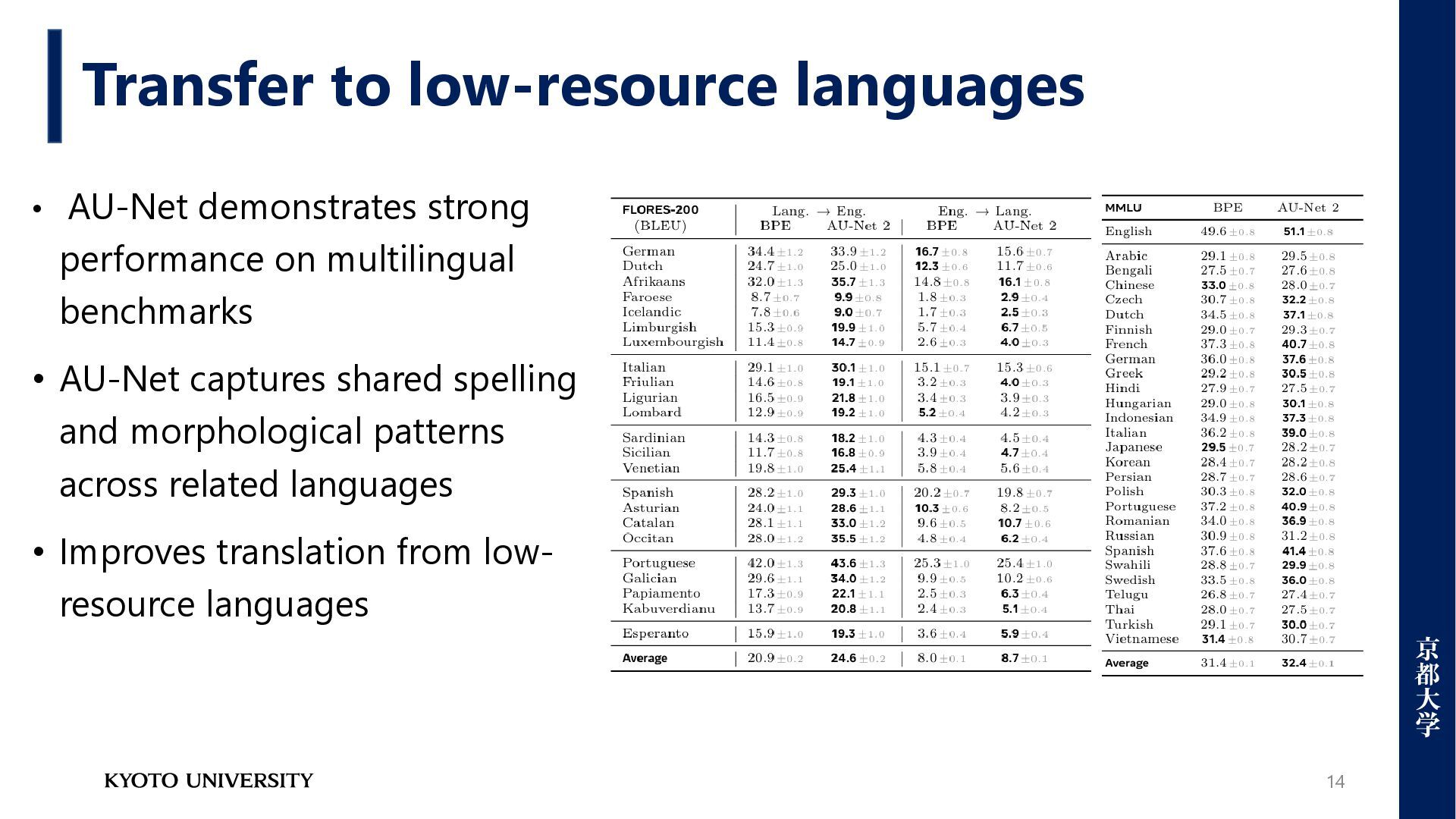
Problems for multilingual environments [1] • Unable to perform task-optimized tokenization [2] • Not robust to typos, spelling variations, or morphological changes[3] • A barrier to distilling knowledge between different models • Cannot pre-define tokenization for emergent languages [1] Xue, Linting, et al. "Byt5: Towards a token-free future with pre-trained byte-to-byte models." Transactions of the Association for Computational Linguistics 10 (2022): 291-306 [2] Zheng, Mengyu, et al. "Enhancing large language models through adaptive tokenizers." Advances in Neural Information Processing Systems 37 (2024): 113545-113568. [3] Wang, Junxiong, et al. "Mambabyte: Token-free selective state space model." arXiv preprint arXiv:2401.13660 (2024).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![What is U-Net (From my research) 8 [2] Ronneberger, Olaf,](https://files.speakerdeck.com/presentations/c76e31d7fe3e448980c97eae8160e17f/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}