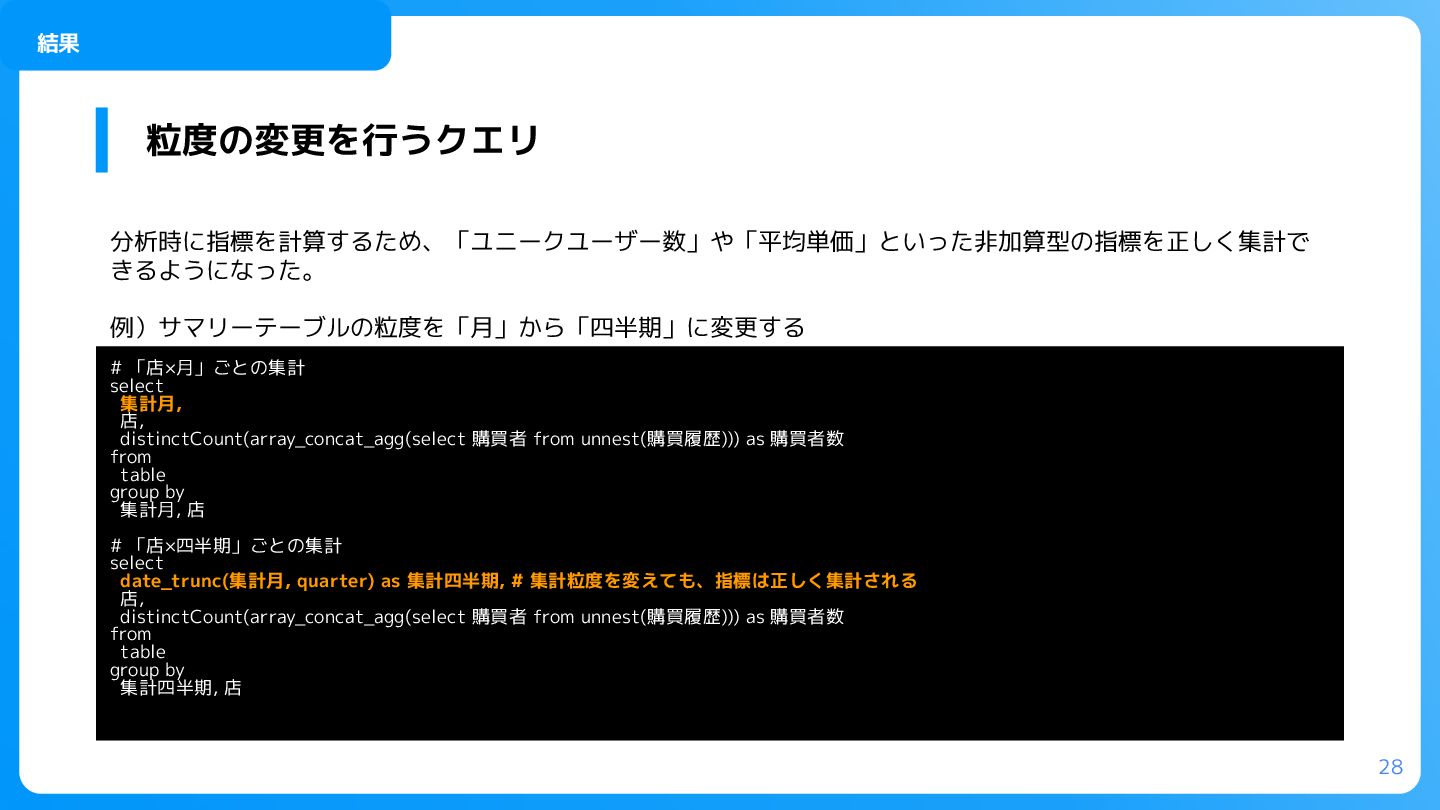
as 購買者数 from table group by 集計月, 店 # 「店×四半期」ごとの集計 select date_trunc(集計月, quarter) as 集計四半期, # 集計粒度を変えても、指標は正しく集計される 店, distinctCount(array_concat_agg(select 購買者 from unnest(購買履歴))) as 購買者数 from table group by 集計四半期, 店 粒度の変更を行うクエリ 結果 分析時に指標を計算するため、「ユニークユーザー数」や「平均単価」といった非加算型の指標を正しく集計で きるようになった。 例)サマリーテーブルの粒度を「月」から「四半期」に変更する
as select count(distinct ユーザーID) from unnest(user_array)) as ユーザーID inner join (select ユーザーID from ユーザーテーブル where 性別 = “男性”) using(ユーザーID) ) ); select 集計月, 店, distinctCount(array_concat_agg(select 購買者 from unnest(購買履歴))) as 購買者数, # 探索的に、後から指標を追加できる countUniqueMaleUsers(array_concat_agg(array(select 購買者 from unnest(購買履歴)))) as 男性の購買者数, from table group by 集計月, 店 指標の追加を行うクエリ 結果
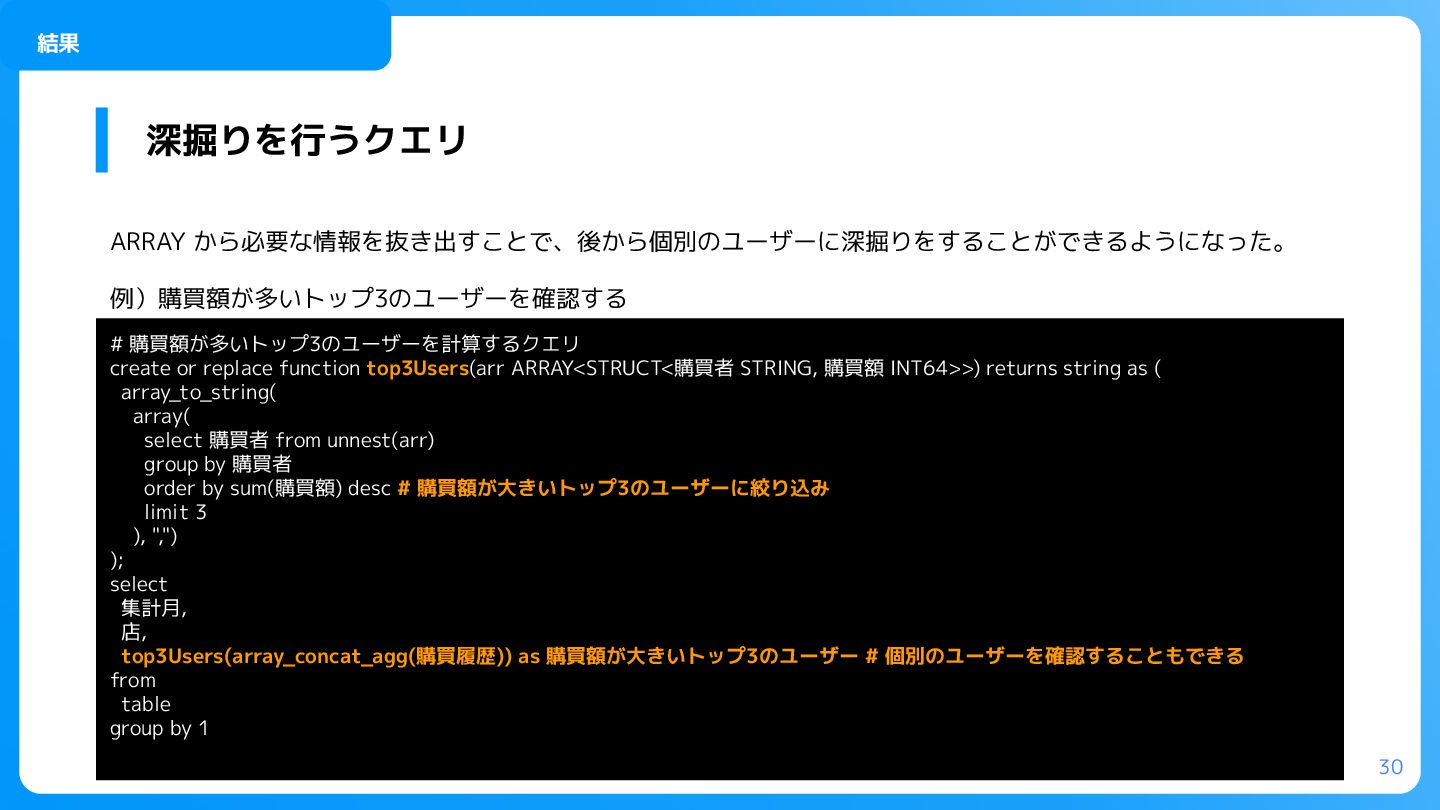
replace function top3Users(arr ARRAY<STRUCT<購買者 STRING, 購買額 INT64>>) returns string as ( array_to_string( array( select 購買者 from unnest(arr) group by 購買者 order by sum(購買額) desc # 購買額が大きいトップ3のユーザーに絞り込み limit 3 ), ",") ); select 集計月, 店, top3Users(array_concat_agg(購買履歴)) as 購買額が大きいトップ3のユーザー # 個別のユーザーを確認することもできる from table group by 1
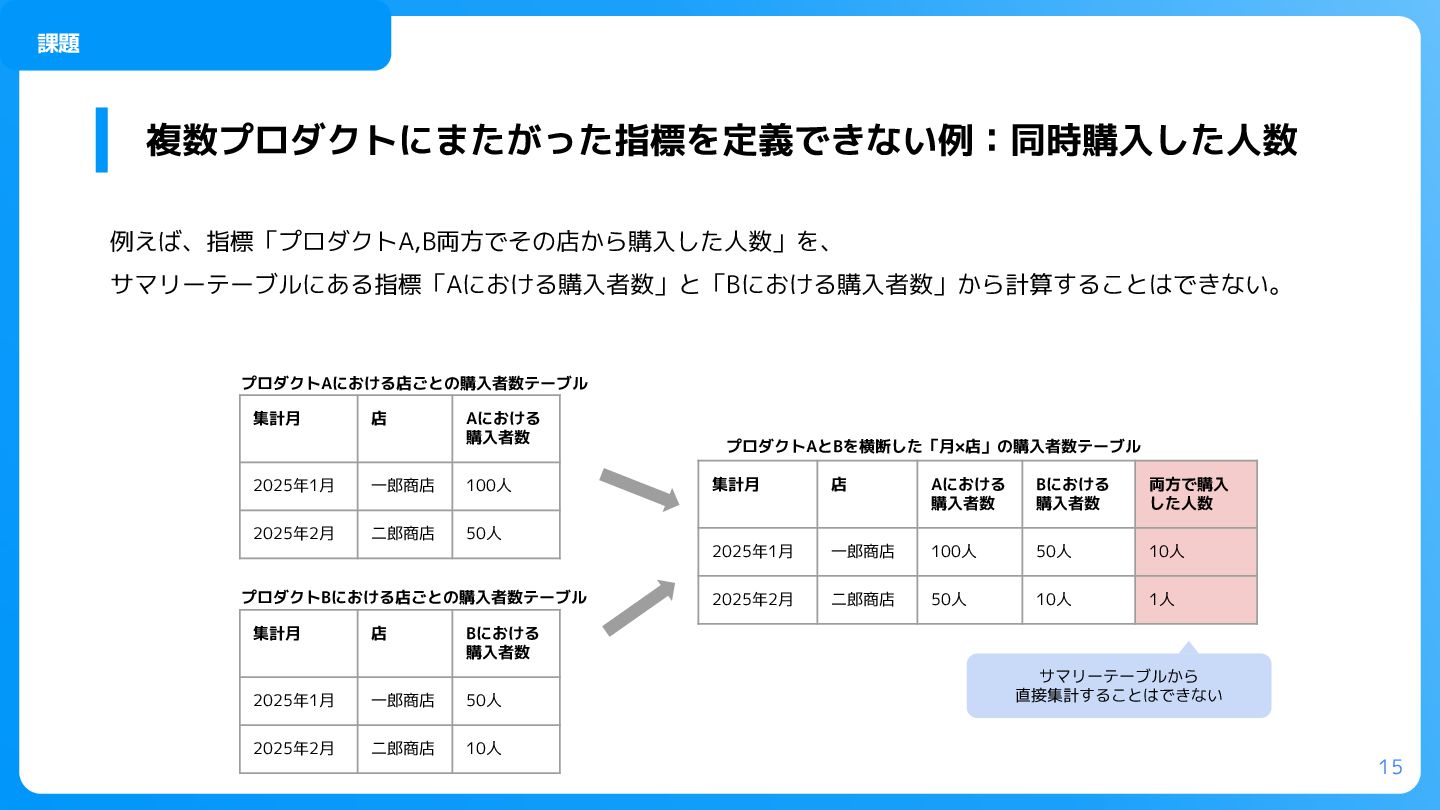
プロダクトAとBどちらにも含まれる購買者に絞り込み from (select distinct 購買者 from unnest(プロダクトAの購買履歴)) inner join (select distinct 購買者 from unnest(プロダクトBの購買履歴)) using(購買者) ) ) ) as AとB両方の購買者数 from table group by 集計月, 店 複数プロダクトにまたがった指標を追加するクエリ 結果 それぞれのプロダクトの購買履歴を格納した ARRAY を用いることで、プロダクトをまたいだ指標を定義できるよ うになった。 例)プロダクトAとプロダクトBの両方で、同じ月に同じ店から購買している購買者数を計算する
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}