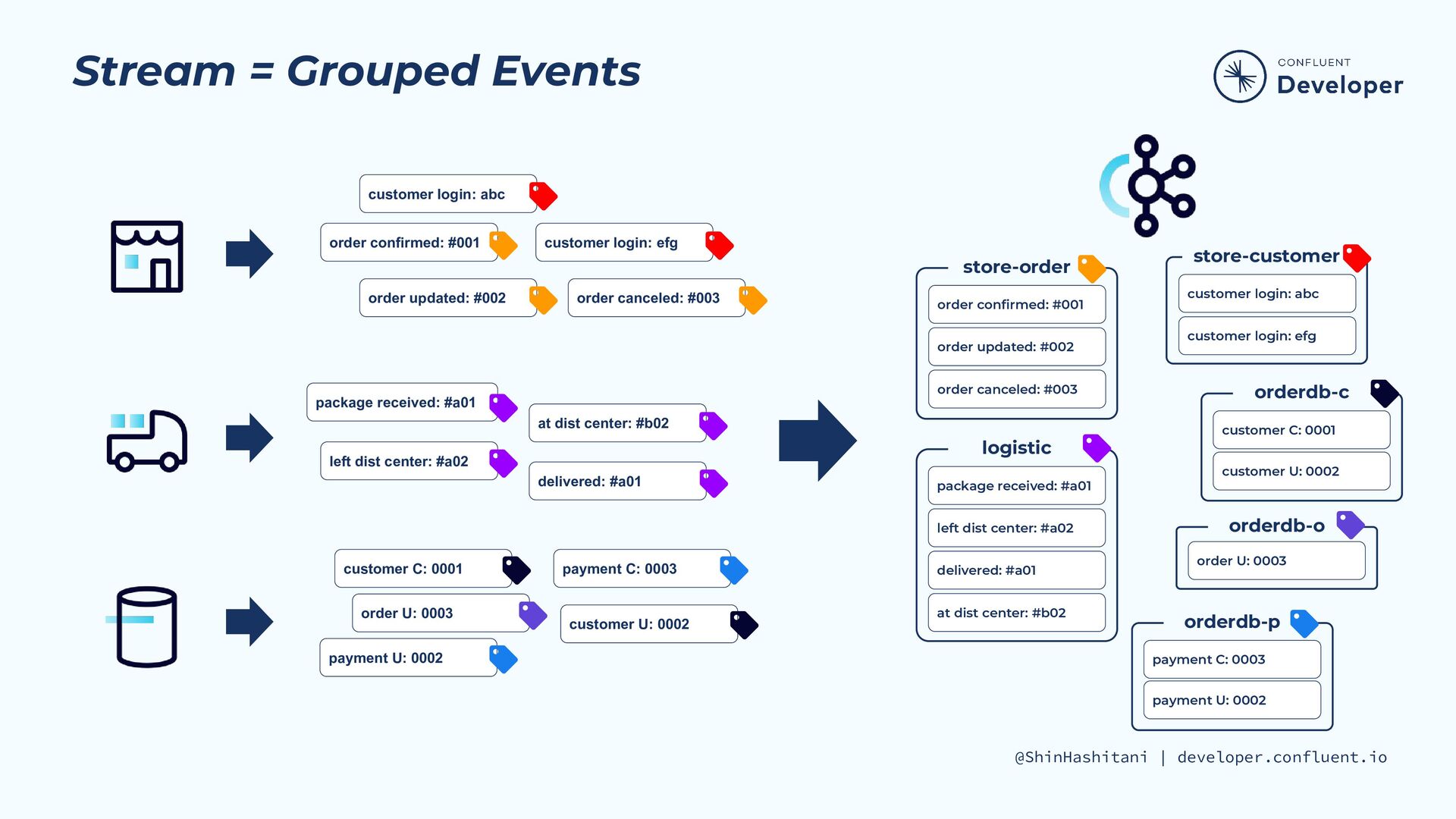
& Pull Queries Filters User-Defined Functions Connectors Compute Storage ksqlDB Kafka CREATE TABLE activePromotions AS SELECT rideId, qualifyPromotion(distanceToDst) AS promotion FROM locations GROUP BY rideId EMIT CHANGES 複雑なリアルタイム処理アプリを 数行のSQLで表現 ksqlDB at a glance ksqlDB is a database for building real-time applications that leverage stream processing
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}